 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
Aug 17, 2022


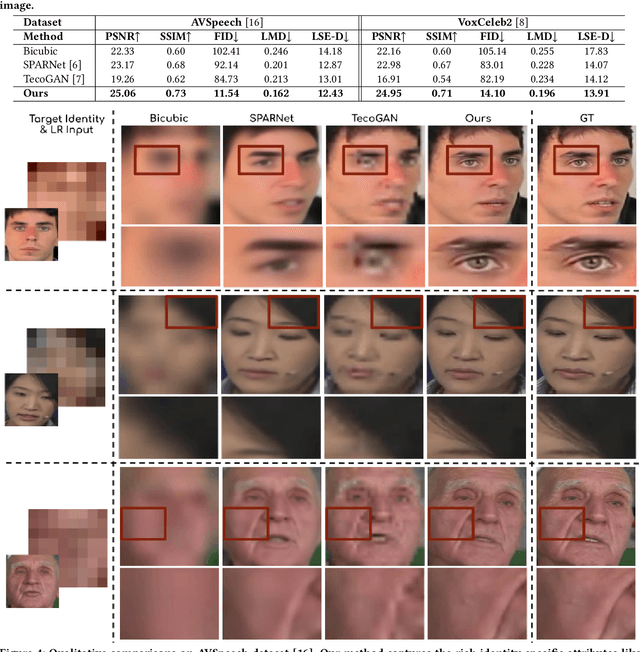
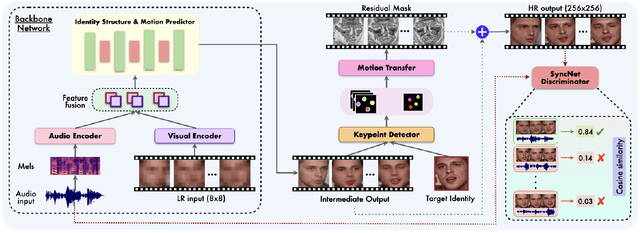
In this paper, we explore an interesting question of what can be obtained from an $8\times8$ pixel video sequence. Surprisingly, it turns out to be quite a lot. We show that when we process this $8\times8$ video with the right set of audio and image priors, we can obtain a full-length, $256\times256$ video. We achieve this $32\times$ scaling of an extremely low-resolution input using our novel audio-visual upsampling network. The audio prior helps to recover the elemental facial details and precise lip shapes and a single high-resolution target identity image prior provides us with rich appearance details. Our approach is an end-to-end multi-stage framework. The first stage produces a coarse intermediate output video that can be then used to animate single target identity image and generate realistic, accurate and high-quality outputs. Our approach is simple and performs exceedingly well (an $8\times$ improvement in FID score) compared to previous super-resolution methods. We also extend our model to talking-face video compression, and show that we obtain a $3.5\times$ improvement in terms of bits/pixel over the previous state-of-the-art. The results from our network are thoroughly analyzed through extensive ablation experiments (in the paper and supplementary material). We also provide the demo video along with code and models on our website: \url{http://cvit.iiit.ac.in/research/projects/cvit-projects/talking-face-video-upsampling}.
Intelligent Sight and Sound: A Chronic Cancer Pain Dataset
Apr 07, 2022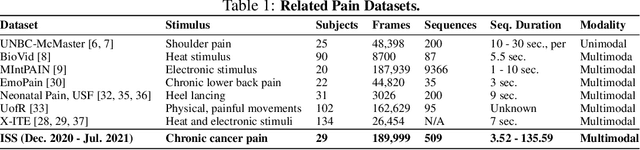
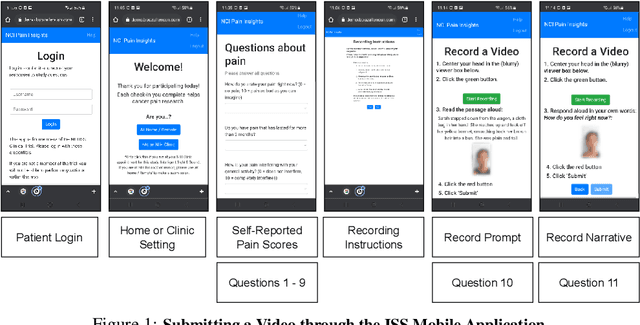
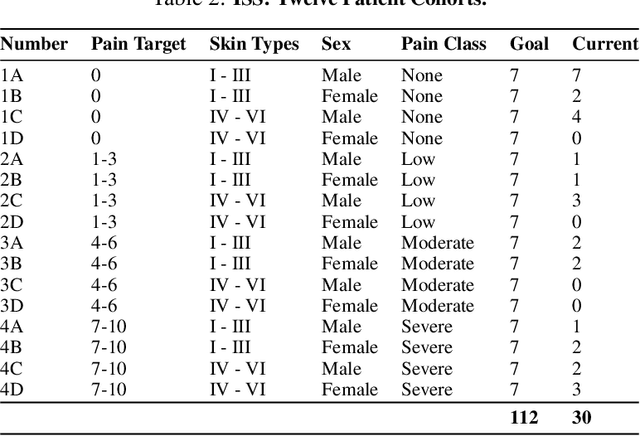

Cancer patients experience high rates of chronic pain throughout the treatment process. Assessing pain for this patient population is a vital component of psychological and functional well-being, as it can cause a rapid deterioration of quality of life. Existing work in facial pain detection often have deficiencies in labeling or methodology that prevent them from being clinically relevant. This paper introduces the first chronic cancer pain dataset, collected as part of the Intelligent Sight and Sound (ISS) clinical trial, guided by clinicians to help ensure that model findings yield clinically relevant results. The data collected to date consists of 29 patients, 509 smartphone videos, 189,999 frames, and self-reported affective and activity pain scores adopted from the Brief Pain Inventory (BPI). Using static images and multi-modal data to predict self-reported pain levels, early models show significant gaps between current methods available to predict pain today, with room for improvement. Due to the especially sensitive nature of the inherent Personally Identifiable Information (PII) of facial images, the dataset will be released under the guidance and control of the National Institutes of Health (NIH).
Synthesizing Normalized Faces from Facial Identity Features
Oct 17, 2017
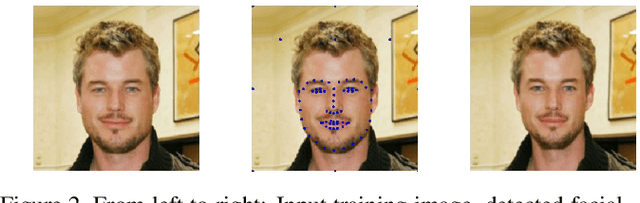
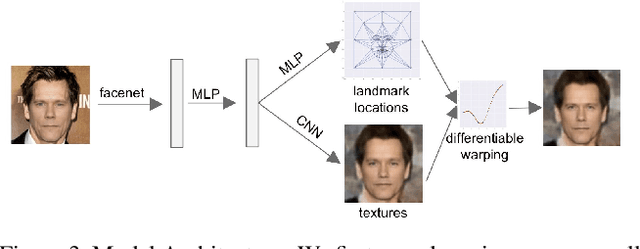
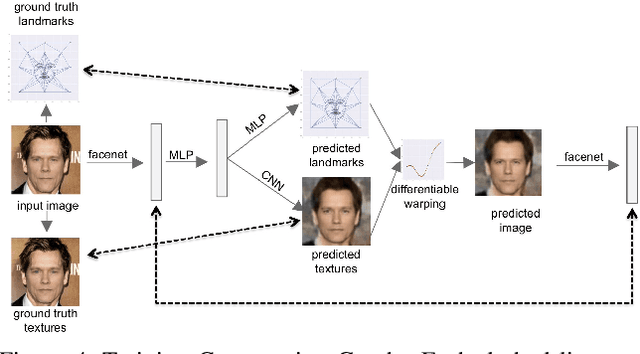
We present a method for synthesizing a frontal, neutral-expression image of a person's face given an input face photograph. This is achieved by learning to generate facial landmarks and textures from features extracted from a facial-recognition network. Unlike previous approaches, our encoding feature vector is largely invariant to lighting, pose, and facial expression. Exploiting this invariance, we train our decoder network using only frontal, neutral-expression photographs. Since these photographs are well aligned, we can decompose them into a sparse set of landmark points and aligned texture maps. The decoder then predicts landmarks and textures independently and combines them using a differentiable image warping operation. The resulting images can be used for a number of applications, such as analyzing facial attributes, exposure and white balance adjustment, or creating a 3-D avatar.
Graph-based Generative Face Anonymisation with Pose Preservation
Dec 10, 2021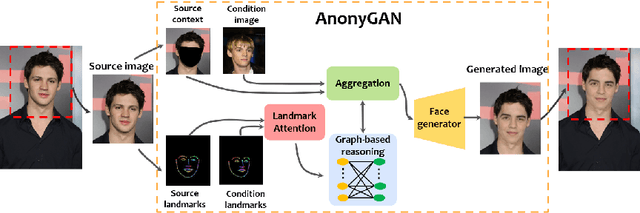
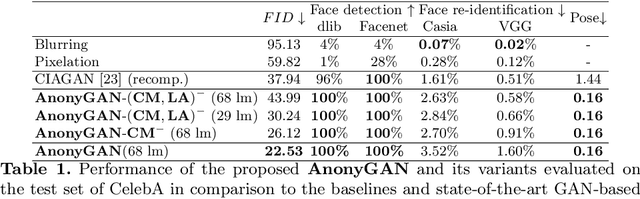
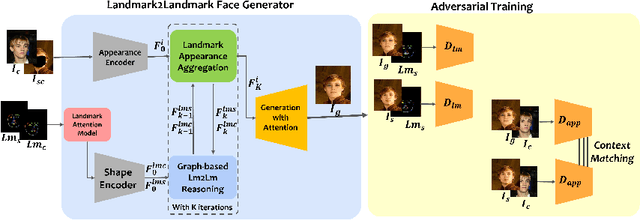
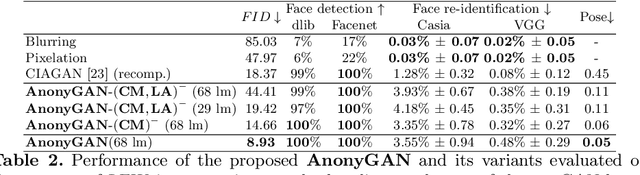
We propose AnonyGAN, a GAN-based solution for face anonymisation which replaces the visual information corresponding to a source identity with a condition identity provided as any single image. With the goal to maintain the geometric attributes of the source face, i.e., the facial pose and expression, and to promote more natural face generation, we propose to exploit a Bipartite Graph to explicitly model the relations between the facial landmarks of the source identity and the ones of the condition identity through a deep model. We further propose a landmark attention model to relax the manual selection of facial landmarks, allowing the network to weight the landmarks for the best visual naturalness and pose preservation. Finally, to facilitate the appearance learning, we propose a hybrid training strategy to address the challenge caused by the lack of direct pixel-level supervision. We evaluate our method and its variants on two public datasets, CelebA and LFW, in terms of visual naturalness, facial pose preservation and of its impacts on face detection and re-identification. We prove that AnonyGAN significantly outperforms the state-of-the-art methods in terms of visual naturalness, face detection and pose preservation.
Local Gradient Hexa Pattern: A Descriptor for Face Recognition and Retrieval
Jan 03, 2022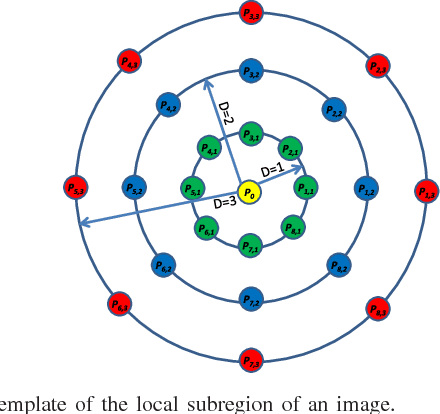
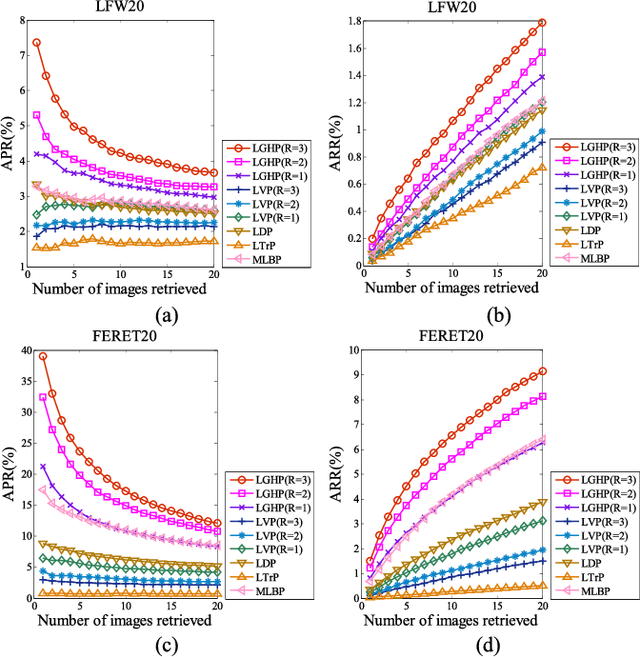
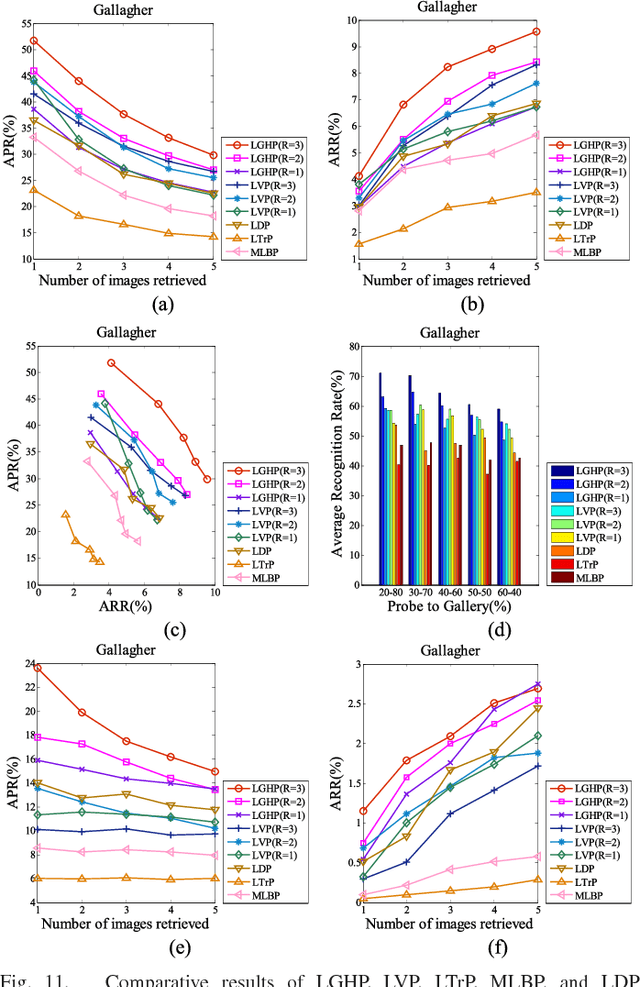
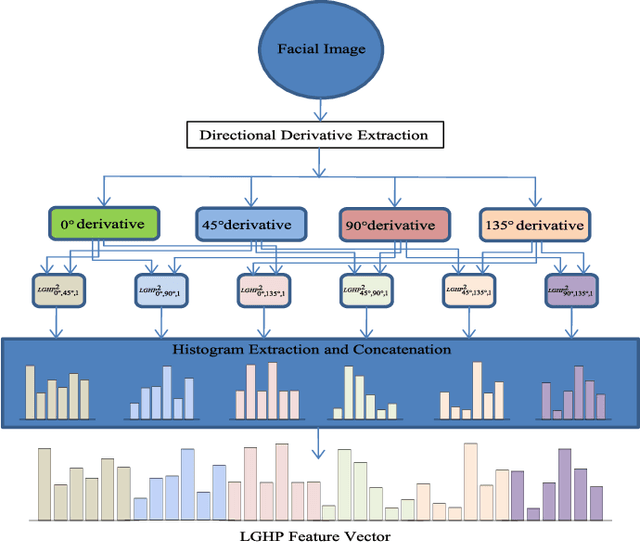
Local descriptors used in face recognition are robust in a sense that these descriptors perform well in varying pose, illumination and lighting conditions. Accuracy of these descriptors depends on the precision of mapping the relationship that exists in the local neighborhood of a facial image into microstructures. In this paper a local gradient hexa pattern (LGHP) is proposed that identifies the relationship amongst the reference pixel and its neighboring pixels at different distances across different derivative directions. Discriminative information exists in the local neighborhood as well as in different derivative directions. Proposed descriptor effectively transforms these relationships into binary micropatterns discriminating interclass facial images with optimal precision. Recognition and retrieval performance of the proposed descriptor has been compared with state-of-the-art descriptors namely LDP and LVP over the most challenging and benchmark facial image databases, i.e. Cropped Extended Yale-B, CMU-PIE, color-FERET, and LFW. The proposed descriptor has better recognition as well as retrieval rates compared to state-of-the-art descriptors.
Mugeetion: Musical Interface Using Facial Gesture and Emotion
Oct 07, 2018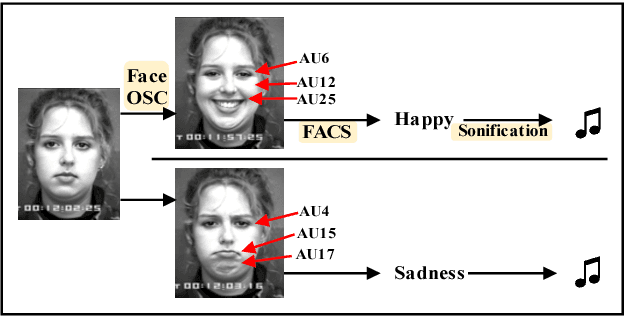
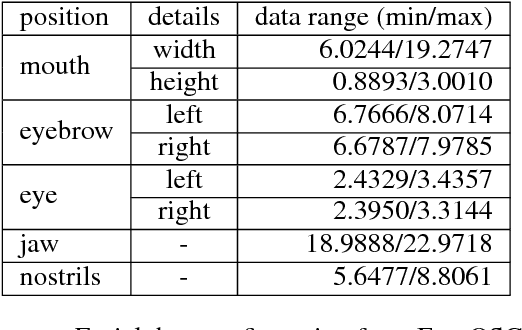
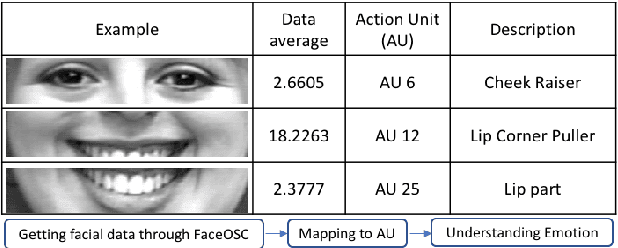

People feel emotions when listening to music. However, emotions are not tangible objects that can be exploited in the music composition process as they are difficult to capture and quantify in algorithms. We present a novel musical interface, Mugeetion, designed to capture occurring instances of emotional states from users' facial gestures and relay that data to associated musical features. Mugeetion can translate qualitative data of emotional states into quantitative data, which can be utilized in the sound generation process. We also presented and tested this work in the exhibition of sound installation, Hearing Seascape, using the audiences' facial expressions. Audiences heard changes in the background sound based on their emotional state. The process contributes multiple research areas, such as gesture tracking systems, emotion-sound modeling, and the connection between sound and facial gesture.
Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning
Mar 13, 2022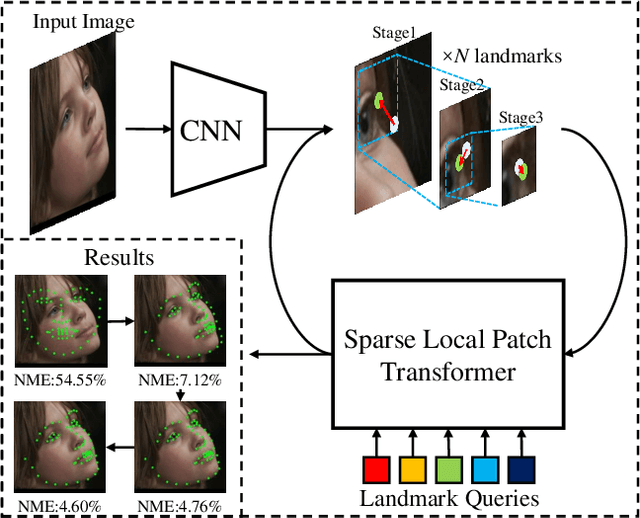
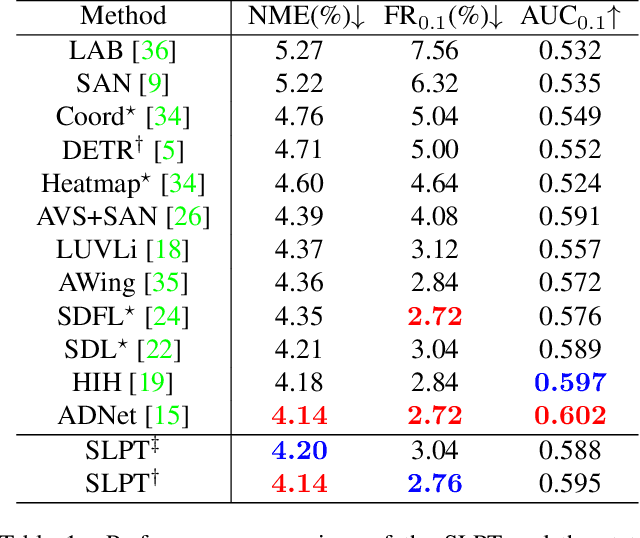
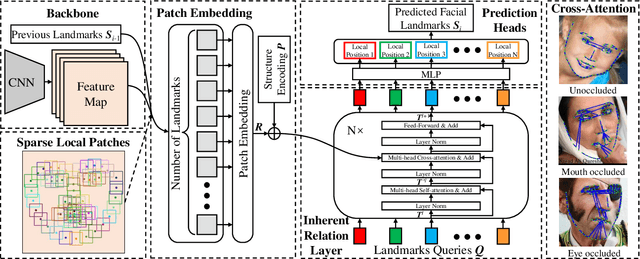
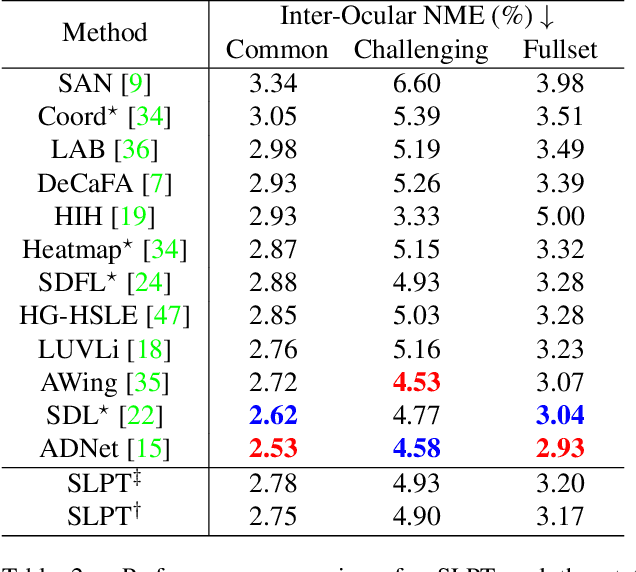
Heatmap regression methods have dominated face alignment area in recent years while they ignore the inherent relation between different landmarks. In this paper, we propose a Sparse Local Patch Transformer (SLPT) for learning the inherent relation. The SLPT generates the representation of each single landmark from a local patch and aggregates them by an adaptive inherent relation based on the attention mechanism. The subpixel coordinate of each landmark is predicted independently based on the aggregated feature. Moreover, a coarse-to-fine framework is further introduced to incorporate with the SLPT, which enables the initial landmarks to gradually converge to the target facial landmarks using fine-grained features from dynamically resized local patches. Extensive experiments carried out on three popular benchmarks, including WFLW, 300W and COFW, demonstrate that the proposed method works at the state-of-the-art level with much less computational complexity by learning the inherent relation between facial landmarks. The code is available at the project website.
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 11, 2019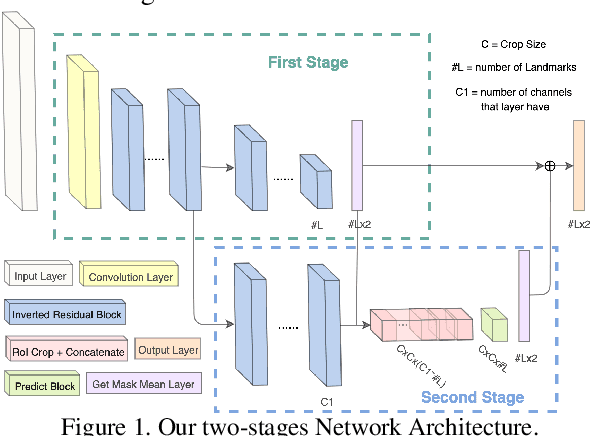

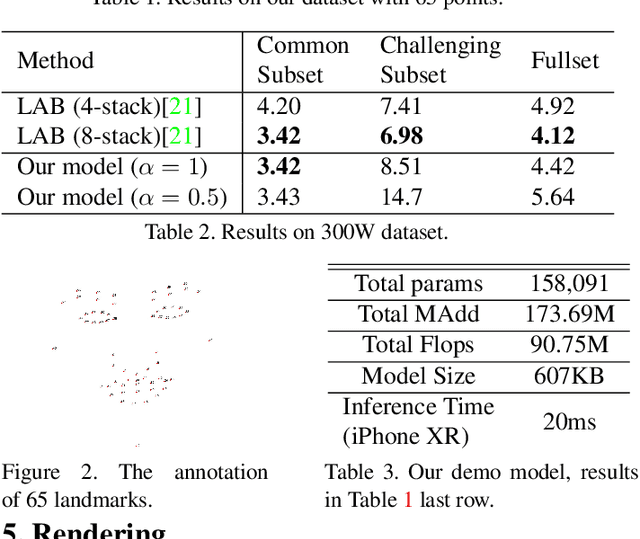
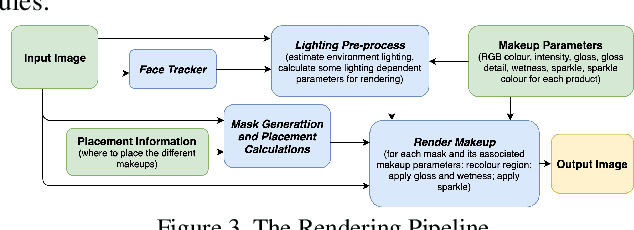
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. More results and demo are in our project page: http://research.modiface.com/makeup-try-on-cvprw2019/
Multi-task Learning of Cascaded CNN for Facial Attribute Classification
May 03, 2018
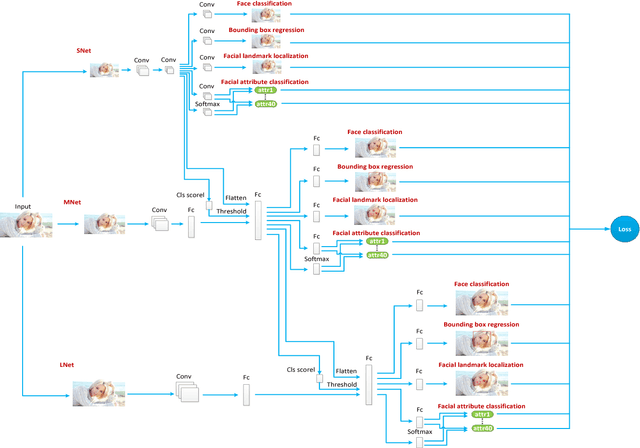
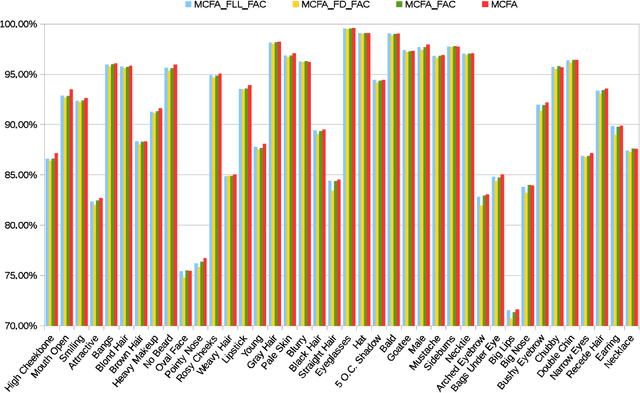

Recently, facial attribute classification (FAC) has attracted significant attention in the computer vision community. Great progress has been made along with the availability of challenging FAC datasets. However, conventional FAC methods usually firstly pre-process the input images (i.e., perform face detection and alignment) and then predict facial attributes. These methods ignore the inherent dependencies among these tasks (i.e., face detection, facial landmark localization and FAC). Moreover, some methods using convolutional neural network are trained based on the fixed loss weights without considering the differences between facial attributes. In order to address the above problems, we propose a novel multi-task learning of cas- caded convolutional neural network method, termed MCFA, for predicting multiple facial attributes simultaneously. Specifically, the proposed method takes advantage of three cascaded sub-networks (i.e., S_Net, M_Net and L_Net corresponding to the neural networks under different scales) to jointly train multiple tasks in a coarse-to-fine manner, which can achieve end-to-end optimization. Furthermore, the proposed method automatically assigns the loss weight to each facial attribute based on a novel dynamic weighting scheme, thus making the proposed method concentrate on predicting the more difficult facial attributes. Experimental results show that the proposed method outperforms several state-of-the-art FAC methods on the challenging CelebA and LFWA datasets.
Generating Complex 4D Expression Transitions by Learning Face Landmark Trajectories
Jul 29, 2022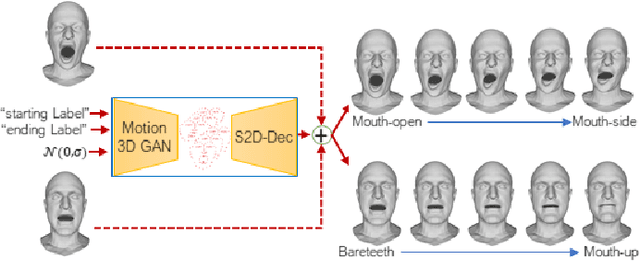

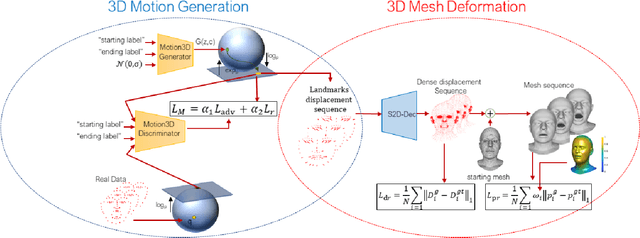

In this work, we address the problem of 4D facial expressions generation. This is usually addressed by animating a neutral 3D face to reach an expression peak, and then get back to the neutral state. In the real world though, people show more complex expressions, and switch from one expression to another. We thus propose a new model that generates transitions between different expressions, and synthesizes long and composed 4D expressions. This involves three sub-problems: (i) modeling the temporal dynamics of expressions, (ii) learning transitions between them, and (iii) deforming a generic mesh. We propose to encode the temporal evolution of expressions using the motion of a set of 3D landmarks, that we learn to generate by training a manifold-valued GAN (Motion3DGAN). To allow the generation of composed expressions, this model accepts two labels encoding the starting and the ending expressions. The final sequence of meshes is generated by a Sparse2Dense mesh Decoder (S2D-Dec) that maps the landmark displacements to a dense, per-vertex displacement of a known mesh topology. By explicitly working with motion trajectories, the model is totally independent from the identity. Extensive experiments on five public datasets show that our proposed approach brings significant improvements with respect to previous solutions, while retaining good generalization to unseen data.