 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Features Integration in Last Mile Delivery Robots
Apr 15, 2024
Delivery services have undergone technological advancements, with robots now directly delivering packages to recipients. While these robots are designed for efficient functionality, they have not been specifically designed for interactions with humans. Building on the premise that incorporating human-like characteristics into a robot has the potential to positively impact technology acceptance, this study explores human reactions to a robot characterized with facial expressions. The findings indicate a correlation between anthropomorphic features and the observed responses.
AUEditNet: Dual-Branch Facial Action Unit Intensity Manipulation with Implicit Disentanglement
Apr 10, 2024Facial action unit (AU) intensity plays a pivotal role in quantifying fine-grained expression behaviors, which is an effective condition for facial expression manipulation. However, publicly available datasets containing intensity annotations for multiple AUs remain severely limited, often featuring a restricted number of subjects. This limitation places challenges to the AU intensity manipulation in images due to disentanglement issues, leading researchers to resort to other large datasets with pretrained AU intensity estimators for pseudo labels. In addressing this constraint and fully leveraging manual annotations of AU intensities for precise manipulation, we introduce AUEditNet. Our proposed model achieves impressive intensity manipulation across 12 AUs, trained effectively with only 18 subjects. Utilizing a dual-branch architecture, our approach achieves comprehensive disentanglement of facial attributes and identity without necessitating additional loss functions or implementing with large batch sizes. This approach offers a potential solution to achieve desired facial attribute editing despite the dataset's limited subject count. Our experiments demonstrate AUEditNet's superior accuracy in editing AU intensities, affirming its capability in disentangling facial attributes and identity within a limited subject pool. AUEditNet allows conditioning by either intensity values or target images, eliminating the need for constructing AU combinations for specific facial expression synthesis. Moreover, AU intensity estimation, as a downstream task, validates the consistency between real and edited images, confirming the effectiveness of our proposed AU intensity manipulation method.
FaceFilterSense: A Filter-Resistant Face Recognition and Facial Attribute Analysis Framework
Apr 12, 2024With the advent of social media, fun selfie filters have come into tremendous mainstream use affecting the functioning of facial biometric systems as well as image recognition systems. These filters vary from beautification filters and Augmented Reality (AR)-based filters to filters that modify facial landmarks. Hence, there is a need to assess the impact of such filters on the performance of existing face recognition systems. The limitation associated with existing solutions is that these solutions focus more on the beautification filters. However, the current AR-based filters and filters which distort facial key points are in vogue recently and make the faces highly unrecognizable even to the naked eye. Also, the filters considered are mostly obsolete with limited variations. To mitigate these limitations, we aim to perform a holistic impact analysis of the latest filters and propose an user recognition model with the filtered images. We have utilized a benchmark dataset for baseline images, and applied the latest filters over them to generate a beautified/filtered dataset. Next, we have introduced a model FaceFilterNet for beautified user recognition. In this framework, we also utilize our model to comment on various attributes of the person including age, gender, and ethnicity. In addition, we have also presented a filter-wise impact analysis on face recognition, age estimation, gender, and ethnicity prediction. The proposed method affirms the efficacy of our dataset with an accuracy of 87.25% and an optimal accuracy for facial attribute analysis.
Multi-scale Dynamic and Hierarchical Relationship Modeling for Facial Action Units Recognition
Apr 09, 2024Human facial action units (AUs) are mutually related in a hierarchical manner, as not only they are associated with each other in both spatial and temporal domains but also AUs located in the same/close facial regions show stronger relationships than those of different facial regions. While none of existing approach thoroughly model such hierarchical inter-dependencies among AUs, this paper proposes to comprehensively model multi-scale AU-related dynamic and hierarchical spatio-temporal relationship among AUs for their occurrences recognition. Specifically, we first propose a novel multi-scale temporal differencing network with an adaptive weighting block to explicitly capture facial dynamics across frames at different spatial scales, which specifically considers the heterogeneity of range and magnitude in different AUs' activation. Then, a two-stage strategy is introduced to hierarchically model the relationship among AUs based on their spatial distribution (i.e., local and cross-region AU relationship modelling). Experimental results achieved on BP4D and DISFA show that our approach is the new state-of-the-art in the field of AU occurrence recognition. Our code is publicly available at https://github.com/CVI-SZU/MDHR.
Music Recommendation Based on Facial Emotion Recognition
Apr 06, 2024Introduction: Music provides an incredible avenue for individuals to express their thoughts and emotions, while also serving as a delightful mode of entertainment for enthusiasts and music lovers. Objectives: This paper presents a comprehensive approach to enhancing the user experience through the integration of emotion recognition, music recommendation, and explainable AI using GRAD-CAM. Methods: The proposed methodology utilizes a ResNet50 model trained on the Facial Expression Recognition (FER) dataset, consisting of real images of individuals expressing various emotions. Results: The system achieves an accuracy of 82% in emotion classification. By leveraging GRAD-CAM, the model provides explanations for its predictions, allowing users to understand the reasoning behind the system's recommendations. The model is trained on both FER and real user datasets, which include labelled facial expressions, and real images of individuals expressing various emotions. The training process involves pre-processing the input images, extracting features through convolutional layers, reasoning with dense layers, and generating emotion predictions through the output layer. Conclusion: The proposed methodology, leveraging the Resnet50 model with ROI-based analysis and explainable AI techniques, offers a robust and interpretable solution for facial emotion detection paper.
Monocular Identity-Conditioned Facial Reflectance Reconstruction
Mar 30, 2024Recent 3D face reconstruction methods have made remarkable advancements, yet there remain huge challenges in monocular high-quality facial reflectance reconstruction. Existing methods rely on a large amount of light-stage captured data to learn facial reflectance models. However, the lack of subject diversity poses challenges in achieving good generalization and widespread applicability. In this paper, we learn the reflectance prior in image space rather than UV space and present a framework named ID2Reflectance. Our framework can directly estimate the reflectance maps of a single image while using limited reflectance data for training. Our key insight is that reflectance data shares facial structures with RGB faces, which enables obtaining expressive facial prior from inexpensive RGB data thus reducing the dependency on reflectance data. We first learn a high-quality prior for facial reflectance. Specifically, we pretrain multi-domain facial feature codebooks and design a codebook fusion method to align the reflectance and RGB domains. Then, we propose an identity-conditioned swapping module that injects facial identity from the target image into the pre-trained autoencoder to modify the identity of the source reflectance image. Finally, we stitch multi-view swapped reflectance images to obtain renderable assets. Extensive experiments demonstrate that our method exhibits excellent generalization capability and achieves state-of-the-art facial reflectance reconstruction results for in-the-wild faces. Our project page is https://xingyuren.github.io/id2reflectance/.
MSSTNet: A Multi-Scale Spatio-Temporal CNN-Transformer Network for Dynamic Facial Expression Recognition
Apr 12, 2024Unlike typical video action recognition, Dynamic Facial Expression Recognition (DFER) does not involve distinct moving targets but relies on localized changes in facial muscles. Addressing this distinctive attribute, we propose a Multi-Scale Spatio-temporal CNN-Transformer network (MSSTNet). Our approach takes spatial features of different scales extracted by CNN and feeds them into a Multi-scale Embedding Layer (MELayer). The MELayer extracts multi-scale spatial information and encodes these features before sending them into a Temporal Transformer (T-Former). The T-Former simultaneously extracts temporal information while continually integrating multi-scale spatial information. This process culminates in the generation of multi-scale spatio-temporal features that are utilized for the final classification. Our method achieves state-of-the-art results on two in-the-wild datasets. Furthermore, a series of ablation experiments and visualizations provide further validation of our approach's proficiency in leveraging spatio-temporal information within DFER.
* Accepted to 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2024)
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Apr 09, 2024Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
Disentangling Racial Phenotypes: Fine-Grained Control of Race-related Facial Phenotype Characteristics
Mar 29, 2024
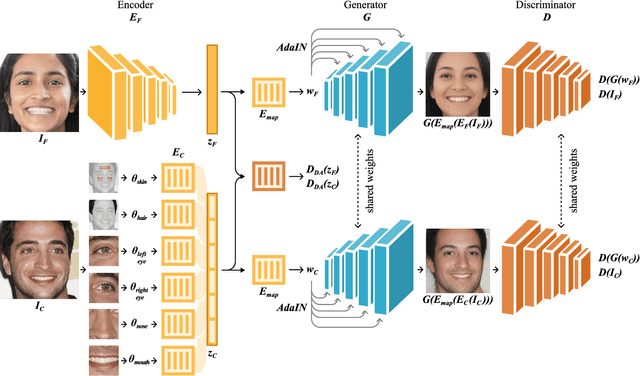

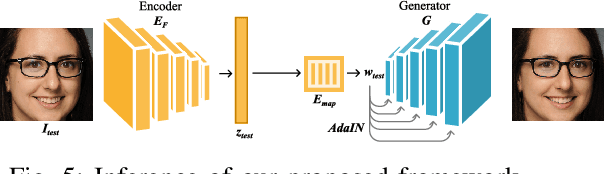
Achieving an effective fine-grained appearance variation over 2D facial images, whilst preserving facial identity, is a challenging task due to the high complexity and entanglement of common 2D facial feature encoding spaces. Despite these challenges, such fine-grained control, by way of disentanglement is a crucial enabler for data-driven racial bias mitigation strategies across multiple automated facial analysis tasks, as it allows to analyse, characterise and synthesise human facial diversity. In this paper, we propose a novel GAN framework to enable fine-grained control over individual race-related phenotype attributes of the facial images. Our framework factors the latent (feature) space into elements that correspond to race-related facial phenotype representations, thereby separating phenotype aspects (e.g. skin, hair colour, nose, eye, mouth shapes), which are notoriously difficult to annotate robustly in real-world facial data. Concurrently, we also introduce a high quality augmented, diverse 2D face image dataset drawn from CelebA-HQ for GAN training. Unlike prior work, our framework only relies upon 2D imagery and related parameters to achieve state-of-the-art individual control over race-related phenotype attributes with improved photo-realistic output.
Generalizable Face Landmarking Guided by Conditional Face Warping
Apr 18, 2024As a significant step for human face modeling, editing, and generation, face landmarking aims at extracting facial keypoints from images. A generalizable face landmarker is required in practice because real-world facial images, e.g., the avatars in animations and games, are often stylized in various ways. However, achieving generalizable face landmarking is challenging due to the diversity of facial styles and the scarcity of labeled stylized faces. In this study, we propose a simple but effective paradigm to learn a generalizable face landmarker based on labeled real human faces and unlabeled stylized faces. Our method learns the face landmarker as the key module of a conditional face warper. Given a pair of real and stylized facial images, the conditional face warper predicts a warping field from the real face to the stylized one, in which the face landmarker predicts the ending points of the warping field and provides us with high-quality pseudo landmarks for the corresponding stylized facial images. Applying an alternating optimization strategy, we learn the face landmarker to minimize $i)$ the discrepancy between the stylized faces and the warped real ones and $ii)$ the prediction errors of both real and pseudo landmarks. Experiments on various datasets show that our method outperforms existing state-of-the-art domain adaptation methods in face landmarking tasks, leading to a face landmarker with better generalizability. Code is available at https://plustwo0.github.io/project-face-landmarker}{https://plustwo0.github.io/project-face-landmarker.