 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Face Morphing Attack Detection Using Privacy-Aware Training Data
Jul 02, 2022
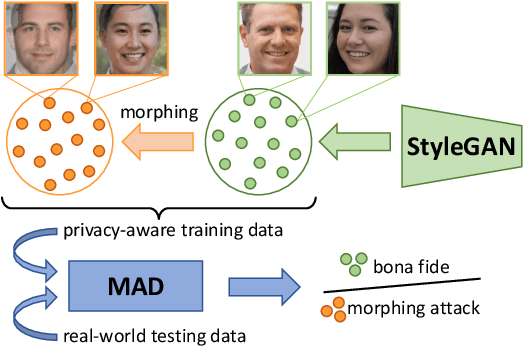


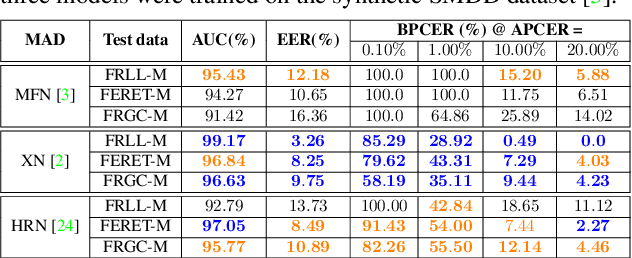
Images of morphed faces pose a serious threat to face recognition--based security systems, as they can be used to illegally verify the identity of multiple people with a single morphed image. Modern detection algorithms learn to identify such morphing attacks using authentic images of real individuals. This approach raises various privacy concerns and limits the amount of publicly available training data. In this paper, we explore the efficacy of detection algorithms that are trained only on faces of non--existing people and their respective morphs. To this end, two dedicated algorithms are trained with synthetic data and then evaluated on three real-world datasets, i.e.: FRLL-Morphs, FERET-Morphs and FRGC-Morphs. Our results show that synthetic facial images can be successfully employed for the training process of the detection algorithms and generalize well to real-world scenarios.
A Peek at Peak Emotion Recognition
May 19, 2022


Despite much progress in the field of facial expression recognition, little attention has been paid to the recognition of peak emotion. Aviezer et al. [1] showed that humans have trouble discerning between positive and negative peak emotions. In this work we analyze how deep learning fares on this challenge. We find that (i) despite using very small datasets, features extracted from deep learning models can achieve results significantly better than humans. (ii) We find that deep learning models, even when trained only on datasets tagged by humans, still outperform humans in this task.
Deepfake Face Traceability with Disentangling Reversing Network
Jul 08, 2022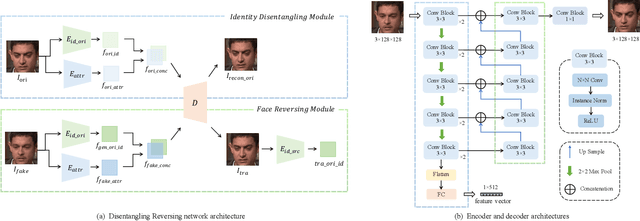



Deepfake face not only violates the privacy of personal identity, but also confuses the public and causes huge social harm. The current deepfake detection only stays at the level of distinguishing true and false, and cannot trace the original genuine face corresponding to the fake face, that is, it does not have the ability to trace the source of evidence. The deepfake countermeasure technology for judicial forensics urgently calls for deepfake traceability. This paper pioneers an interesting question about face deepfake, active forensics that "know it and how it happened". Given that deepfake faces do not completely discard the features of original faces, especially facial expressions and poses, we argue that original faces can be approximately speculated from their deepfake counterparts. Correspondingly, we design a disentangling reversing network that decouples latent space features of deepfake faces under the supervision of fake-original face pair samples to infer original faces in reverse.
Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning
Mar 26, 2022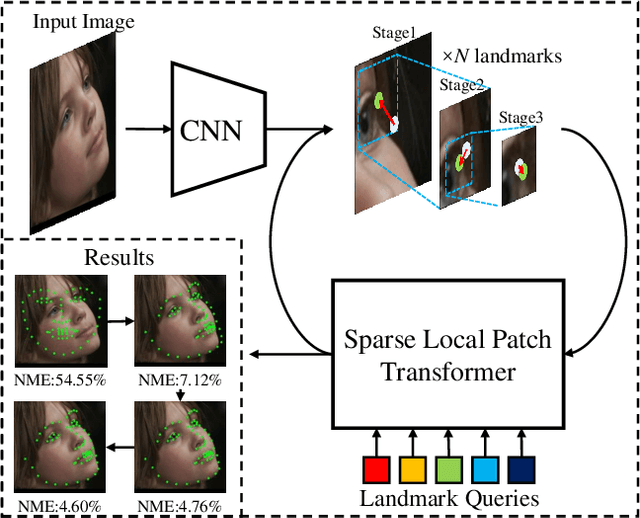
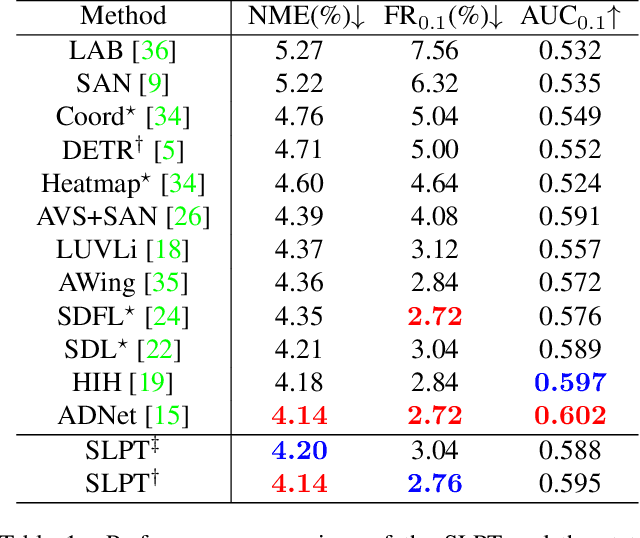
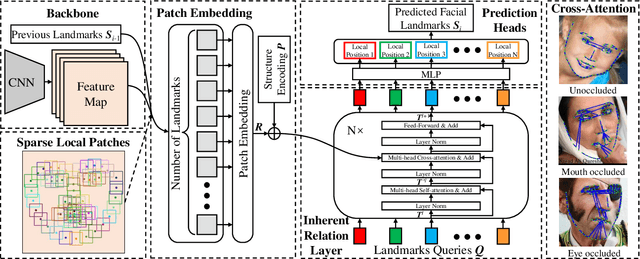
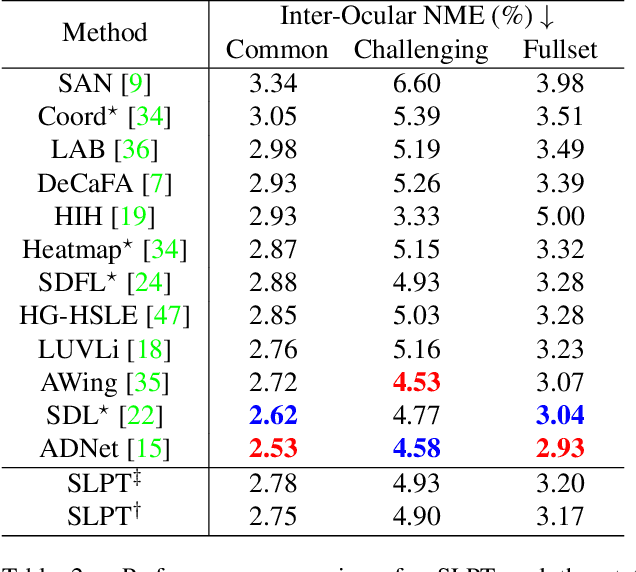
Heatmap regression methods have dominated face alignment area in recent years while they ignore the inherent relation between different landmarks. In this paper, we propose a Sparse Local Patch Transformer (SLPT) for learning the inherent relation. The SLPT generates the representation of each single landmark from a local patch and aggregates them by an adaptive inherent relation based on the attention mechanism. The subpixel coordinate of each landmark is predicted independently based on the aggregated feature. Moreover, a coarse-to-fine framework is further introduced to incorporate with the SLPT, which enables the initial landmarks to gradually converge to the target facial landmarks using fine-grained features from dynamically resized local patches. Extensive experiments carried out on three popular benchmarks, including WFLW, 300W and COFW, demonstrate that the proposed method works at the state-of-the-art level with much less computational complexity by learning the inherent relation between facial landmarks. The code is available at the project website.
Deep Covariance Descriptors for Facial Expression Recognition
May 10, 2018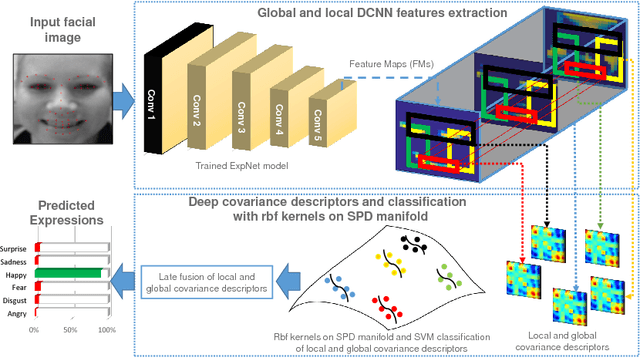

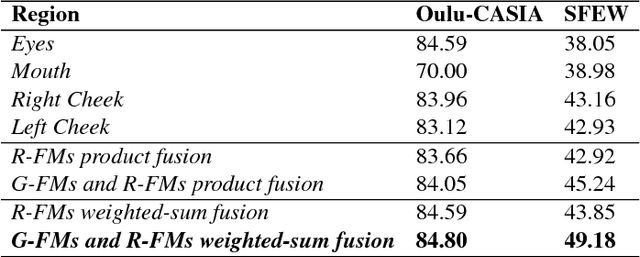
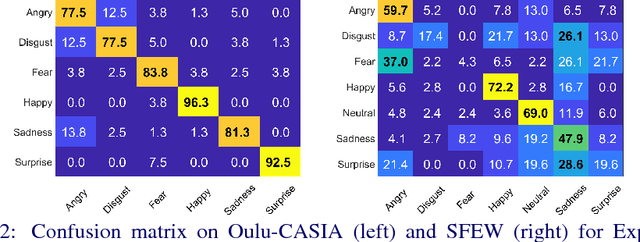
In this paper, covariance matrices are exploited to encode the deep convolutional neural networks (DCNN) features for facial expression recognition. The space geometry of the covariance matrices is that of Symmetric Positive Definite (SPD) matrices. By performing the classification of the facial expressions using Gaussian kernel on SPD manifold, we show that the covariance descriptors computed on DCNN features are more efficient than the standard classification with fully connected layers and softmax. By implementing our approach using the VGG-face and ExpNet architectures with extensive experiments on the Oulu-CASIA and SFEW datasets, we show that the proposed approach achieves performance at the state of the art for facial expression recognition.
Conditional Adversarial Synthesis of 3D Facial Action Units
Mar 15, 2018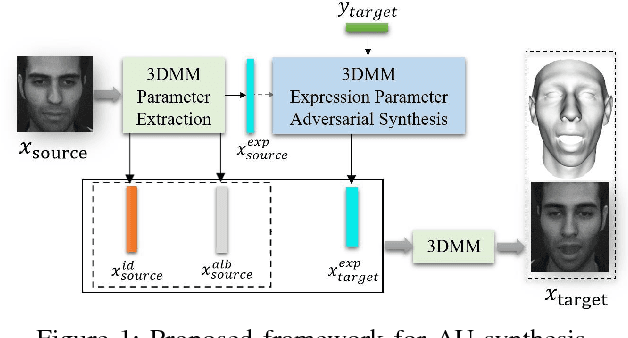
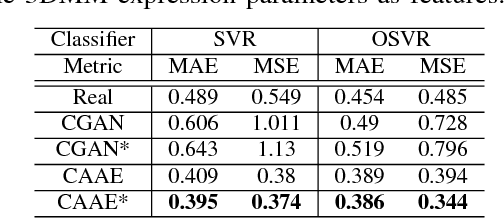
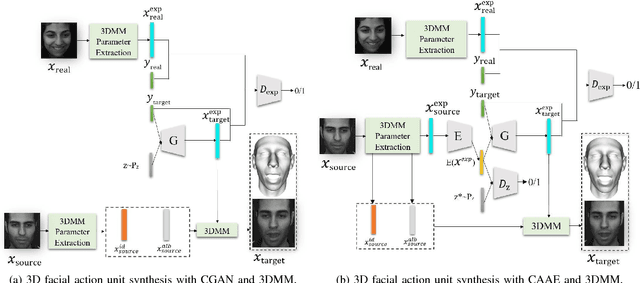

Employing deep learning-based approaches for fine-grained facial expression analysis, such as those involving the estimation of Action Unit (AU) intensities, is difficult due to the lack of a large-scale dataset of real faces with sufficiently diverse AU labels for training. In this paper, we consider how AU-level facial image synthesis can be used to substantially augment such a dataset. We propose an AU synthesis framework that combines the well-known 3D Morphable Model (3DMM), which intrinsically disentangles expression parameters from other face attributes, with models that adversarially generate 3DMM expression parameters conditioned on given target AU labels, in contrast to the more conventional approach of generating facial images directly. In this way, we are able to synthesize new combinations of expression parameters and facial images from desired AU labels. Extensive quantitative and qualitative results on the benchmark DISFA dataset demonstrate the effectiveness of our method on 3DMM facial expression parameter synthesis and data augmentation for deep learning-based AU intensity estimation.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018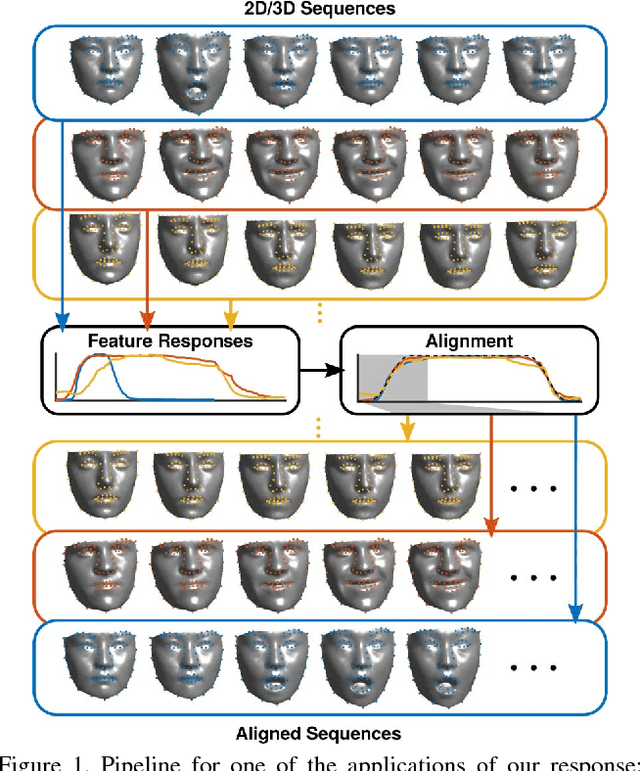
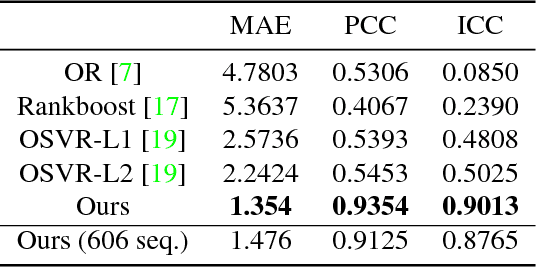
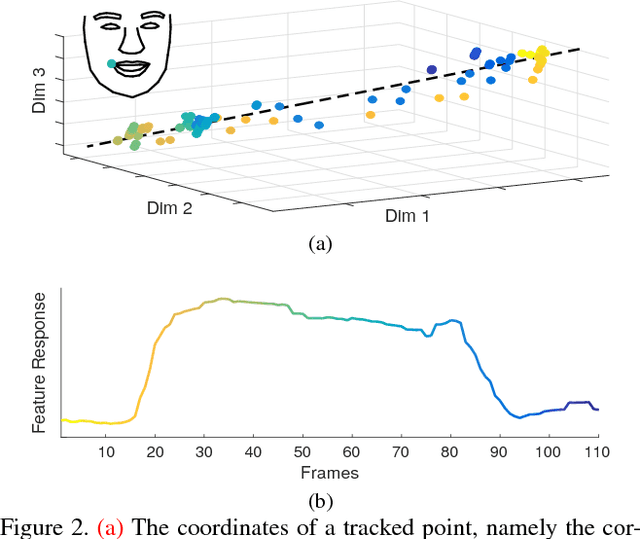
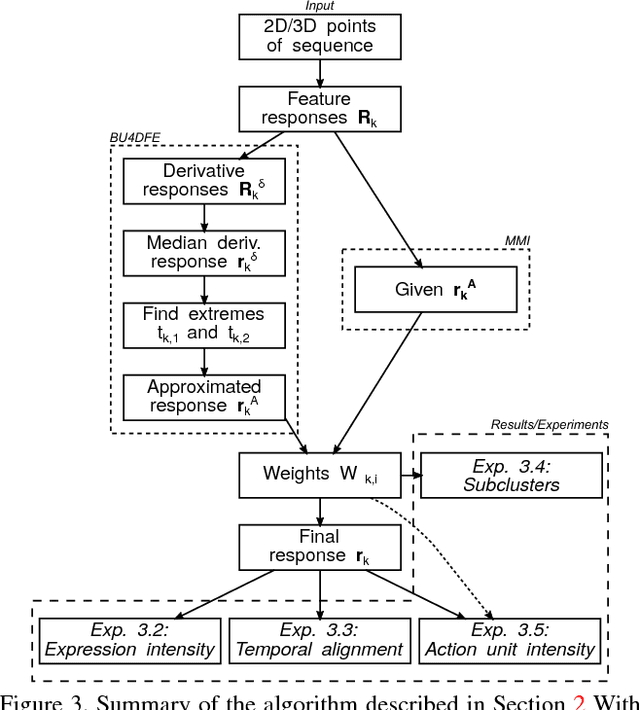
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.
Video Coding Using Learned Latent GAN Compression
Jul 12, 2022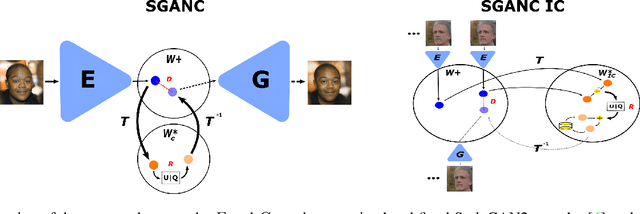

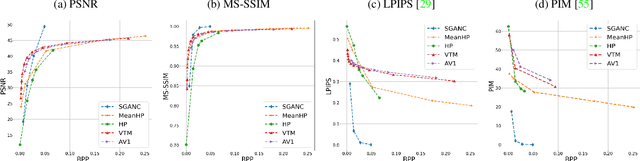

We propose in this paper a new paradigm for facial video compression. We leverage the generative capacity of GANs such as StyleGAN to represent and compress a video, including intra and inter compression. Each frame is inverted in the latent space of StyleGAN, from which the optimal compression is learned. To do so, a diffeomorphic latent representation is learned using a normalizing flows model, where an entropy model can be optimized for image coding. In addition, we propose a new perceptual loss that is more efficient than other counterparts. Finally, an entropy model for video inter coding with residual is also learned in the previously constructed latent representation. Our method (SGANC) is simple, faster to train, and achieves better results for image and video coding compared to state-of-the-art codecs such as VTM, AV1, and recent deep learning techniques. In particular, it drastically minimizes perceptual distortion at low bit rates.
FaceTuneGAN: Face Autoencoder for Convolutional Expression Transfer Using Neural Generative Adversarial Networks
Dec 01, 2021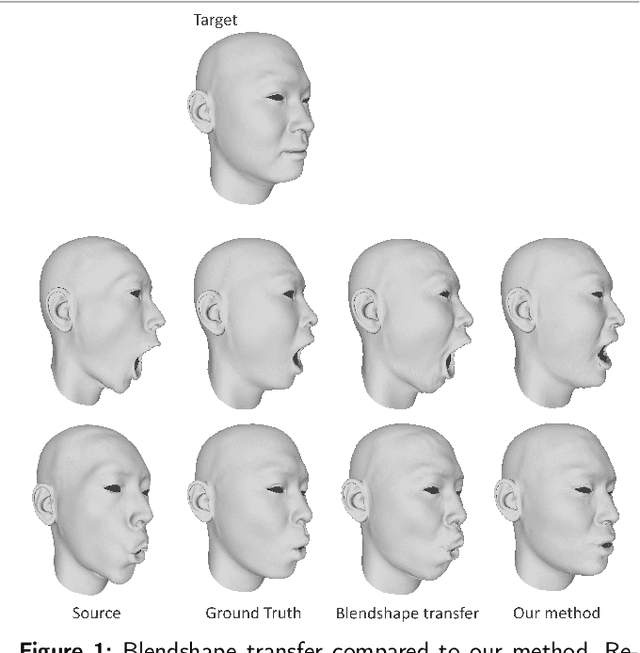

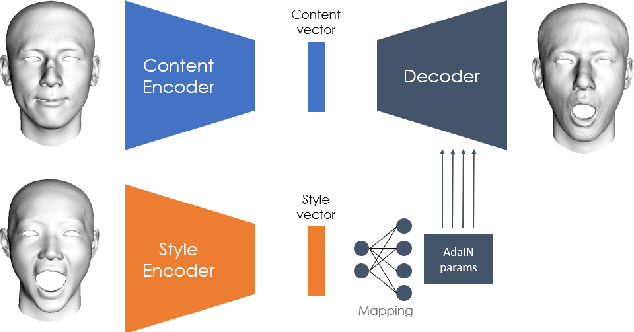
In this paper, we present FaceTuneGAN, a new 3D face model representation decomposing and encoding separately facial identity and facial expression. We propose a first adaptation of image-to-image translation networks, that have successfully been used in the 2D domain, to 3D face geometry. Leveraging recently released large face scan databases, a neural network has been trained to decouple factors of variations with a better knowledge of the face, enabling facial expressions transfer and neutralization of expressive faces. Specifically, we design an adversarial architecture adapting the base architecture of FUNIT and using SpiralNet++ for our convolutional and sampling operations. Using two publicly available datasets (FaceScape and CoMA), FaceTuneGAN has a better identity decomposition and face neutralization than state-of-the-art techniques. It also outperforms classical deformation transfer approach by predicting blendshapes closer to ground-truth data and with less of undesired artifacts due to too different facial morphologies between source and target.
BReG-NeXt: Facial Affect Computing Using Adaptive Residual Networks With Bounded Gradient
Apr 18, 2020
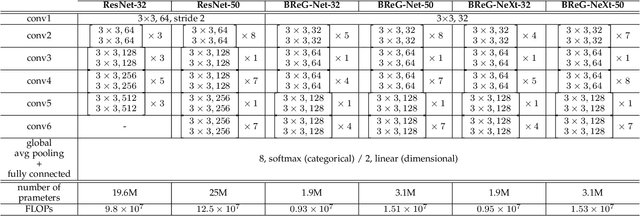
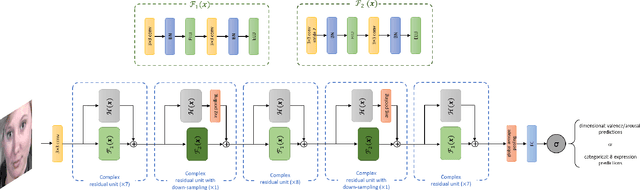

This paper introduces BReG-NeXt, a residual-based network architecture using a function wtih bounded derivative instead of a simple shortcut path (a.k.a. identity mapping) in the residual units for automatic recognition of facial expressions based on the categorical and dimensional models of affect. Compared to ResNet, our proposed adaptive complex mapping results in a shallower network with less numbers of training parameters and floating point operations per second (FLOPs). Adding trainable parameters to the bypass function further improves fitting and training the network and hence recognizing subtle facial expressions such as contempt with a higher accuracy. We conducted comprehensive experiments on the categorical and dimensional models of affect on the challenging in-the-wild databases of AffectNet, FER2013, and Affect-in-Wild. Our experimental results show that our adaptive complex mapping approach outperforms the original ResNet consisting of a simple identity mapping as well as other state-of-the-art methods for Facial Expression Recognition (FER). Various metrics are reported in both affect models to provide a comprehensive evaluation of our method. In the categorical model, BReG-NeXt-50 with only 3.1M training parameters and 15 MFLOPs, achieves 68.50% and 71.53% accuracy on AffectNet and FER2013 databases, respectively. In the dimensional model, BReG-NeXt achieves 0.2577 and 0.2882 RMSE value on AffectNet and Affect-in-Wild databases, respectively.