 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition
May 10, 2019
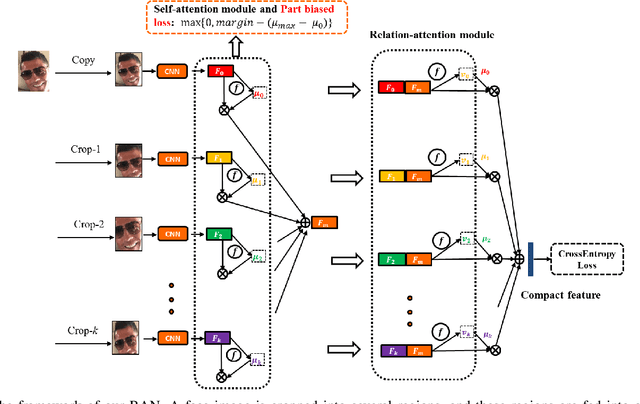
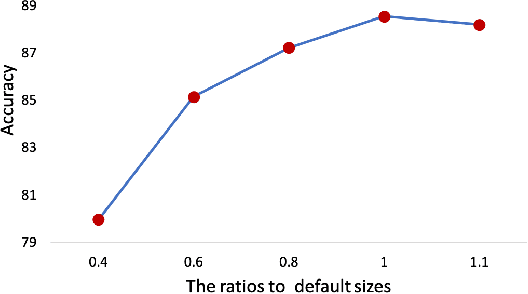
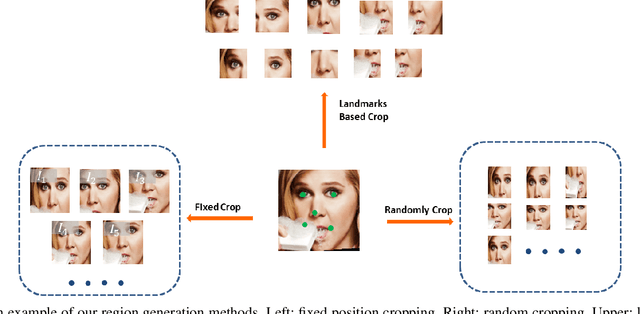

Occlusion and pose variations, which can change facial appearance significantly, are two major obstacles for automatic Facial Expression Recognition (FER). Though automatic FER has made substantial progresses in the past few decades, occlusion-robust and pose-invariant issues of FER have received relatively less attention, especially in real-world scenarios. This paper addresses the real-world pose and occlusion robust FER problem with three-fold contributions. First, to stimulate the research of FER under real-world occlusions and variant poses, we build several in-the-wild facial expression datasets with manual annotations for the community. Second, we propose a novel Region Attention Network (RAN), to adaptively capture the importance of facial regions for occlusion and pose variant FER. The RAN aggregates and embeds varied number of region features produced by a backbone convolutional neural network into a compact fixed-length representation. Last, inspired by the fact that facial expressions are mainly defined by facial action units, we propose a region biased loss to encourage high attention weights for the most important regions. We validate our RAN and region biased loss on both our built test datasets and four popular datasets: FERPlus, AffectNet, RAF-DB, and SFEW. Extensive experiments show that our RAN and region biased loss largely improve the performance of FER with occlusion and variant pose. Our method also achieves state-of-the-art results on FERPlus, AffectNet, RAF-DB, and SFEW. Code and the collected test data will be publicly available.
Protecting President Zelenskyy against Deep Fakes
Jun 24, 2022
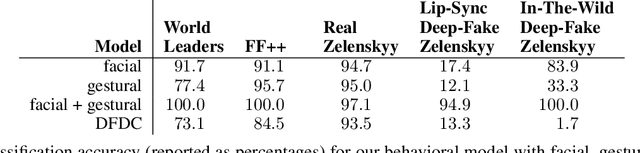

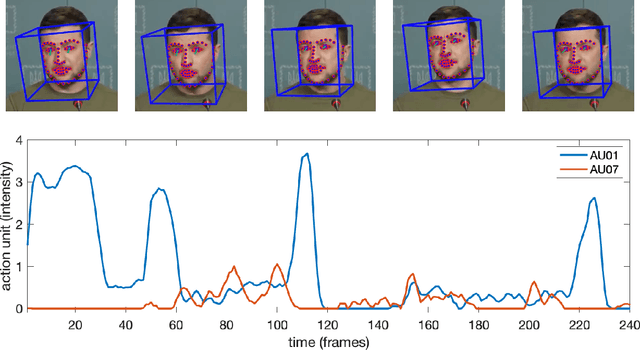
The 2022 Russian invasion of Ukraine is being fought on two fronts: a brutal ground war and a duplicitous disinformation campaign designed to conceal and justify Russia's actions. This campaign includes at least one example of a deep-fake video purportedly showing Ukrainian President Zelenskyy admitting defeat and surrendering. In anticipation of future attacks of this form, we describe a facial and gestural behavioral model that captures distinctive characteristics of Zelenskyy's speaking style. Trained on over eight hours of authentic video from four different settings, we show that this behavioral model can distinguish Zelenskyy from deep-fake imposters.This model can play an important role -- particularly during the fog of war -- in distinguishing the real from the fake.
Self-Supervised 3D Face Reconstruction via Conditional Estimation
Oct 10, 2021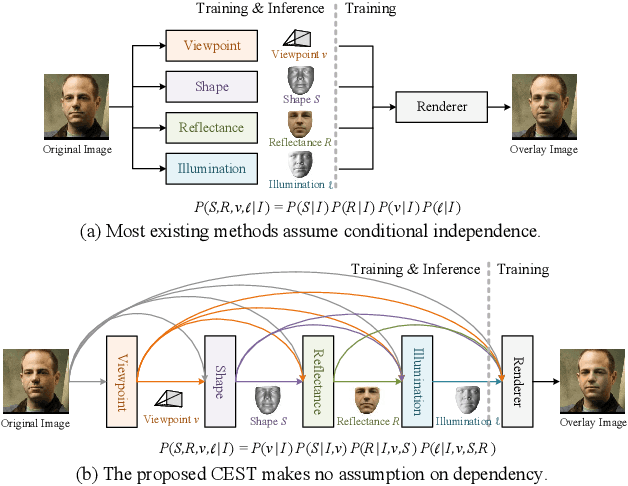

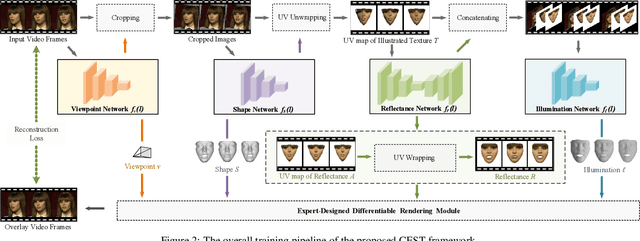
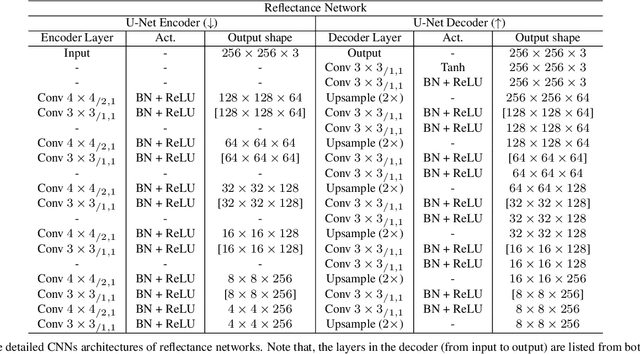
We present a conditional estimation (CEST) framework to learn 3D facial parameters from 2D single-view images by self-supervised training from videos. CEST is based on the process of analysis by synthesis, where the 3D facial parameters (shape, reflectance, viewpoint, and illumination) are estimated from the face image, and then recombined to reconstruct the 2D face image. In order to learn semantically meaningful 3D facial parameters without explicit access to their labels, CEST couples the estimation of different 3D facial parameters by taking their statistical dependency into account. Specifically, the estimation of any 3D facial parameter is not only conditioned on the given image, but also on the facial parameters that have already been derived. Moreover, the reflectance symmetry and consistency among the video frames are adopted to improve the disentanglement of facial parameters. Together with a novel strategy for incorporating the reflectance symmetry and consistency, CEST can be efficiently trained with in-the-wild video clips. Both qualitative and quantitative experiments demonstrate the effectiveness of CEST.
Fine-Grained Facial Expression Analysis Using Dimensional Emotion Model
May 02, 2018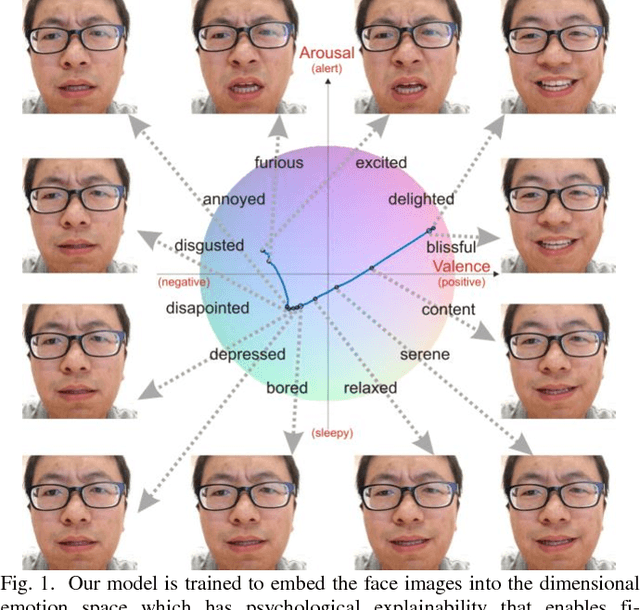
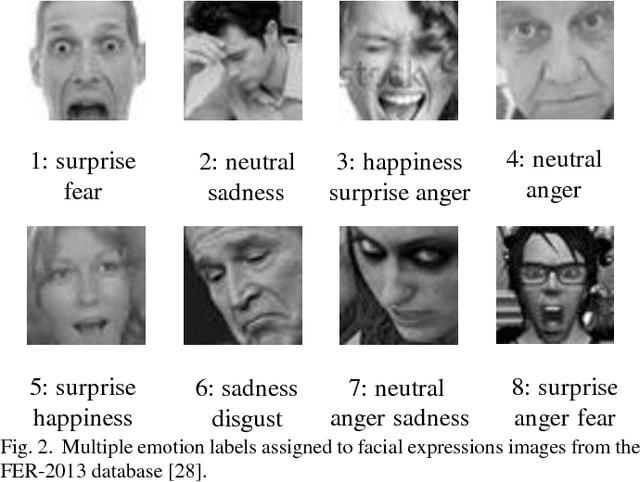
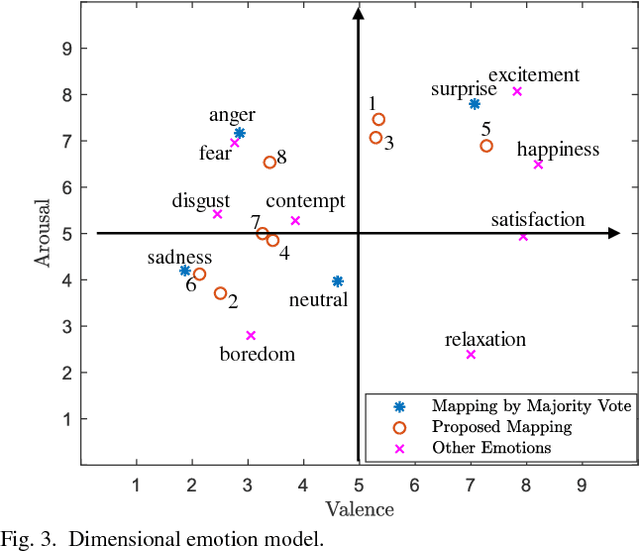
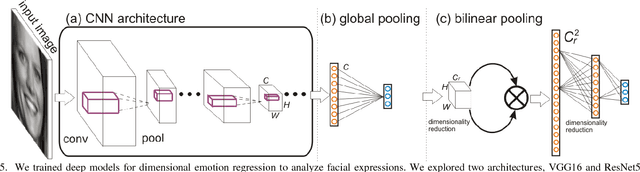
Automated facial expression analysis has a variety of applications in human-computer interaction. Traditional methods mainly analyze prototypical facial expressions of no more than eight discrete emotions as a classification task. However, in practice, spontaneous facial expressions in naturalistic environment can represent not only a wide range of emotions, but also different intensities within an emotion family. In such situation, these methods are not reliable or adequate. In this paper, we propose to train deep convolutional neural networks (CNNs) to analyze facial expressions explainable in a dimensional emotion model. The proposed method accommodates not only a set of basic emotion expressions, but also a full range of other emotions and subtle emotion intensities that we both feel in ourselves and perceive in others in our daily life. Specifically, we first mapped facial expressions into dimensional measures so that we transformed facial expression analysis from a classification problem to a regression one. We then tested our CNN-based methods for facial expression regression and these methods demonstrated promising performance. Moreover, we improved our method by a bilinear pooling which encodes second-order statistics of features. We showed such bilinear-CNN models significantly outperformed their respective baselines.
Speech Fusion to Face: Bridging the Gap Between Human's Vocal Characteristics and Facial Imaging
Jun 10, 2020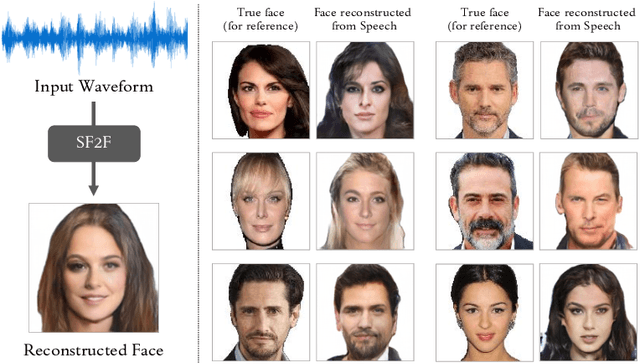


While deep learning technologies are now capable of generating realistic images confusing humans, the research efforts are turning to the synthesis of images for more concrete and application-specific purposes. Facial image generation based on vocal characteristics from speech is one of such important yet challenging tasks. It is the key enabler to influential use cases of image generation, especially for business in public security and entertainment. Existing solutions to the problem of speech2face renders limited image quality and fails to preserve facial similarity due to the lack of quality dataset for training and appropriate integration of vocal features. In this paper, we investigate these key technical challenges and propose Speech Fusion to Face, or SF2F in short, attempting to address the issue of facial image quality and the poor connection between vocal feature domain and modern image generation models. By adopting new strategies on data model and training, we demonstrate dramatic performance boost over state-of-the-art solution, by doubling the recall of individual identity, and lifting the quality score from 15 to 19 based on the mutual information score with VGGFace classifier.
Deep Convolutional Neural Network Based Facial Expression Recognition in the Wild
Oct 03, 2020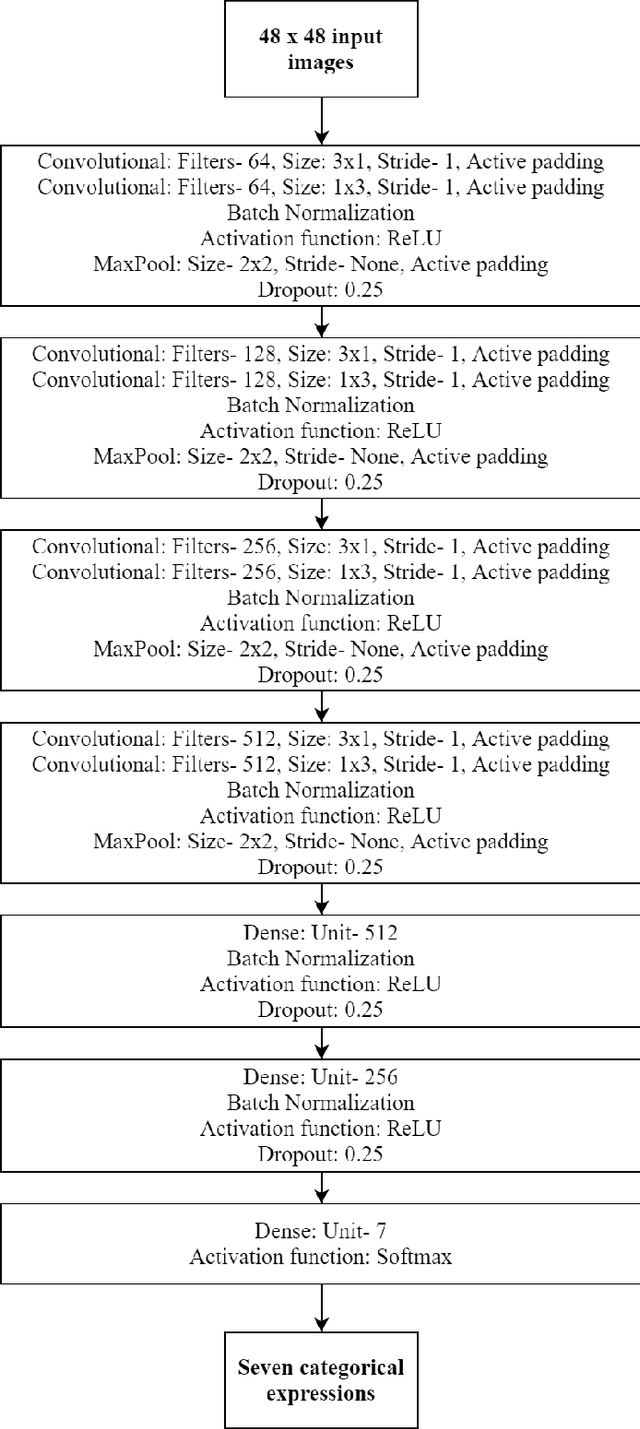
This paper describes the proposed methodology, data used and the results of our participation in the ChallengeTrack 2 (Expr Challenge Track) of the Affective Behavior Analysis in-the-wild (ABAW) Competition 2020. In this competition, we have used a proposed deep convolutional neural network (CNN) model to perform automatic facial expression recognition (AFER) on the given dataset. Our proposed model has achieved an accuracy of 50.77% and an F1 score of 29.16% on the validation set.
Pre-Trained Language Transformers are Universal Image Classifiers
Jan 25, 2022Facial images disclose many hidden personal traits such as age, gender, race, health, emotion, and psychology. Understanding these traits will help to classify the people in different attributes. In this paper, we have presented a novel method for classifying images using a pretrained transformer model. We apply the pretrained transformer for the binary classification of facial images in criminal and non-criminal classes. The pretrained transformer of GPT-2 is trained to generate text and then fine-tuned to classify facial images. During the finetuning process with images, most of the layers of GT-2 are frozen during backpropagation and the model is frozen pretrained transformer (FPT). The FPT acts as a universal image classifier, and this paper shows the application of FPT on facial images. We also use our FPT on encrypted images for classification. Our FPT shows high accuracy on both raw facial images and encrypted images. We hypothesize the meta-learning capacity FPT gained because of its large size and trained on a large size with theory and experiments. The GPT-2 trained to generate a single word token at a time, through the autoregressive process, forced to heavy-tail distribution. Then the FPT uses the heavy-tail property as its meta-learning capacity for classifying images. Our work shows one way to avoid bias during the machine classification of images.The FPT encodes worldly knowledge because of the pretraining of one text, which it uses during the classification. The statistical error of classification is reduced because of the added context gained from the text.Our paper shows the ethical dimension of using encrypted data for classification.Criminal images are sensitive to share across the boundary but encrypted largely evades ethical concern.FPT showing good classification accuracy on encrypted images shows promise for further research on privacy-preserving machine learning.
Face Anti-Spoofing from the Perspective of Data Sampling
Aug 28, 2022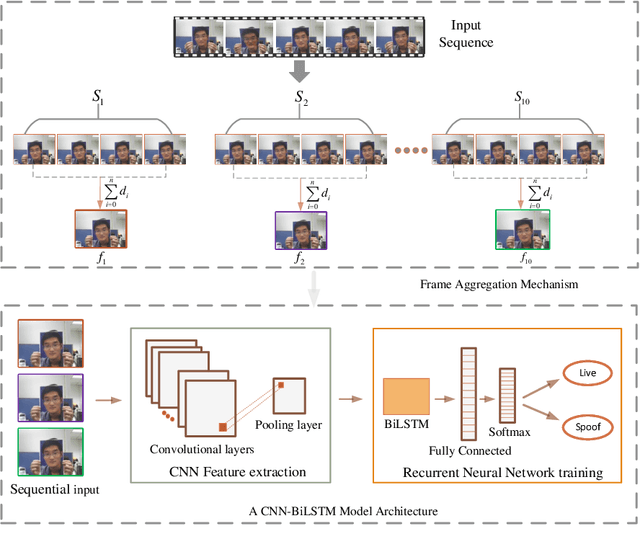

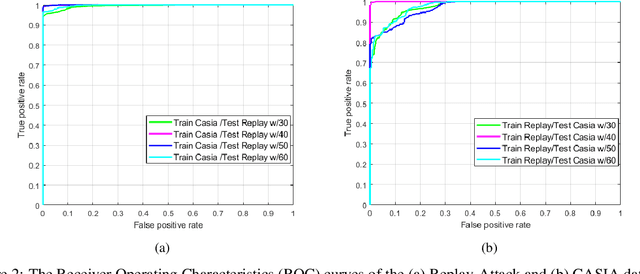
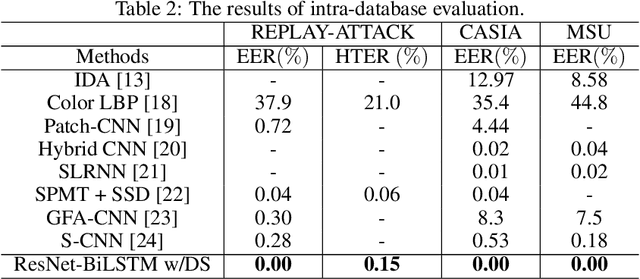
Without deploying face anti-spoofing countermeasures, face recognition systems can be spoofed by presenting a printed photo, a video, or a silicon mask of a genuine user. Thus, face presentation attack detection (PAD) plays a vital role in providing secure facial access to digital devices. Most existing video-based PAD countermeasures lack the ability to cope with long-range temporal variations in videos. Moreover, the key-frame sampling prior to the feature extraction step has not been widely studied in the face anti-spoofing domain. To mitigate these issues, this paper provides a data sampling approach by proposing a video processing scheme that models the long-range temporal variations based on Gaussian Weighting Function. Specifically, the proposed scheme encodes the consecutive t frames of video sequences into a single RGB image based on a Gaussian-weighted summation of the t frames. Using simply the data sampling scheme alone, we demonstrate that state-of-the-art performance can be achieved without any bells and whistles in both intra-database and inter-database testing scenarios for the three public benchmark datasets; namely, Replay-Attack, MSU-MFSD, and CASIA-FASD. In particular, the proposed scheme provides a much lower error (from 15.2% to 6.7% on CASIA-FASD and 5.9% to 4.9% on Replay-Attack) compared to baselines in cross-database scenarios.
GenderRobustness: Robustness of Gender Detection in Facial Recognition Systems with variation in Image Properties
Nov 26, 2020In recent times, there have been increasing accusations on artificial intelligence systems and algorithms of computer vision of possessing implicit biases. Even though these conversations are more prevalent now and systems are improving by performing extensive testing and broadening their horizon, biases still do exist. One such class of systems where bias is said to exist is facial recognition systems, where bias has been observed on the basis of gender, ethnicity, skin tone and other facial attributes. This is even more disturbing, given the fact that these systems are used in practically every sector of the industries today. From as critical as criminal identification to as simple as getting your attendance registered, these systems have gained a huge market, especially in recent years. That in itself is a good enough reason for developers of these systems to ensure that the bias is kept to a bare minimum or ideally non-existent, to avoid major issues like favoring a particular gender, race, or class of people or rather making a class of people susceptible to false accusations due to inability of these systems to correctly recognize those people.
SFF-DA: Sptialtemporal Feature Fusion for Detecting Anxiety Nonintrusively
Aug 12, 2022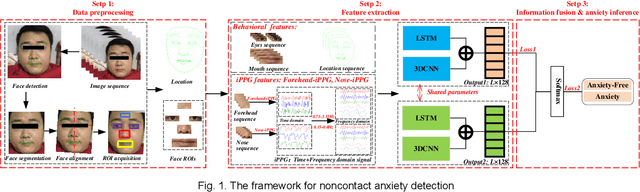
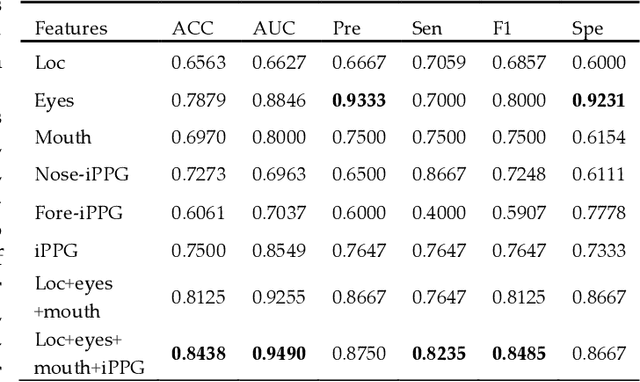
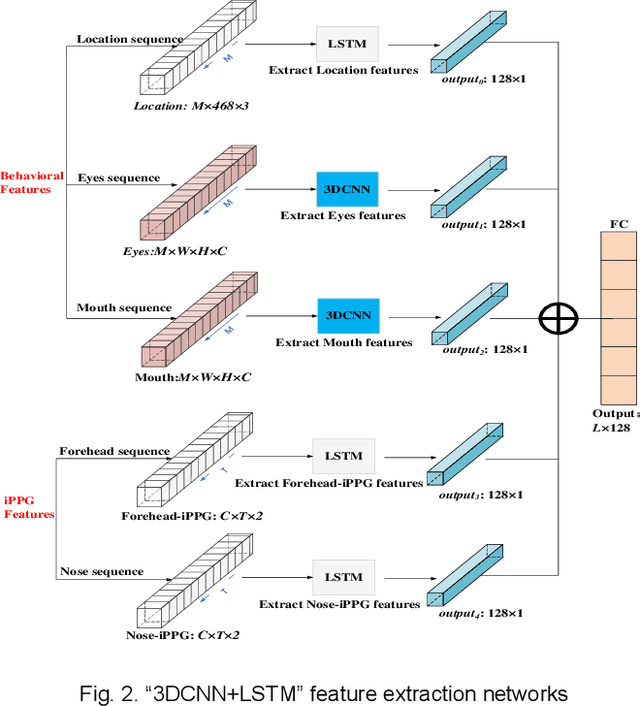
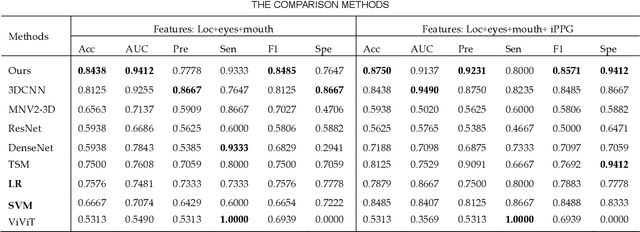
Early detection of anxiety disorders is essential to reduce the suffering of people with mental disorders and to improve treatment outcomes. Anxiety screening based on the mHealth platform is of particular practical value in improving screening efficiency and reducing screening costs. In practice, differences in mobile devices in subjects' physical and mental evaluations and the problems faced with uneven data quality and small sample sizes of data in the real world have made existing methods ineffective. Therefore, we propose a framework based on spatiotemporal feature fusion for detecting anxiety nonintrusively. To reduce the impact of uneven data quality, we constructed a feature extraction network based on "3DCNN+LSTM" and fused spatiotemporal features of facial behavior and noncontact physiology. Moreover, we designed a similarity assessment strategy to solve the problem that the small sample size of data leads to a decline in model accuracy. Our framework was validated with our crew dataset from the real world and two public datasets, UBFC-PHYS and SWELL-KW. The experimental results show that the overall performance of our framework was better than that of the state-of-the-art comparison methods.