 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Towards Fine-grained Image Classification with Generative Adversarial Networks and Facial Landmark Detection
Aug 28, 2021
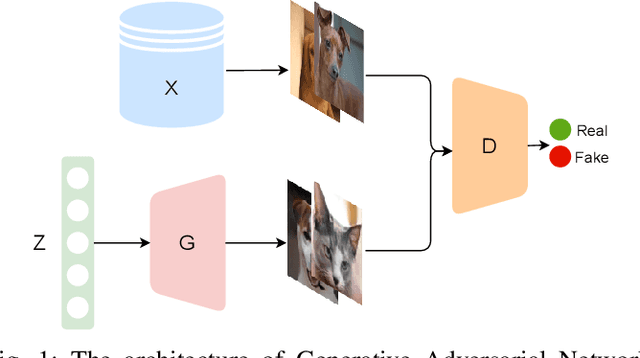
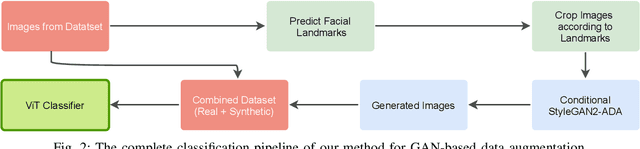


Fine-grained classification remains a challenging task because distinguishing categories needs learning complex and local differences. Diversity in the pose, scale, and position of objects in an image makes the problem even more difficult. Although the recent Vision Transformer models achieve high performance, they need an extensive volume of input data. To encounter this problem, we made the best use of GAN-based data augmentation to generate extra dataset instances. Oxford-IIIT Pets was our dataset of choice for this experiment. It consists of 37 breeds of cats and dogs with variations in scale, poses, and lighting, which intensifies the difficulty of the classification task. Furthermore, we enhanced the performance of the recent Generative Adversarial Network (GAN), StyleGAN2-ADA model to generate more realistic images while preventing overfitting to the training set. We did this by training a customized version of MobileNetV2 to predict animal facial landmarks; then, we cropped images accordingly. Lastly, we combined the synthetic images with the original dataset and compared our proposed method with standard GANs augmentation and no augmentation with different subsets of training data. We validated our work by evaluating the accuracy of fine-grained image classification on the recent Vision Transformer (ViT) Model.
Attentive One-Dimensional Heatmap Regression for Facial Landmark Detection and Tracking
Apr 11, 2020
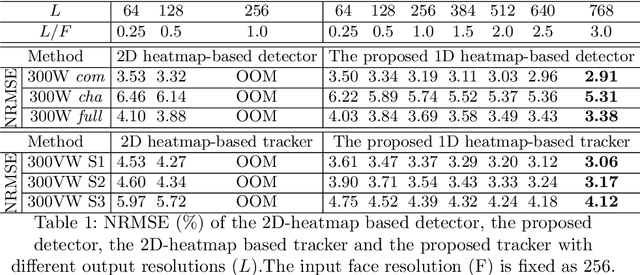
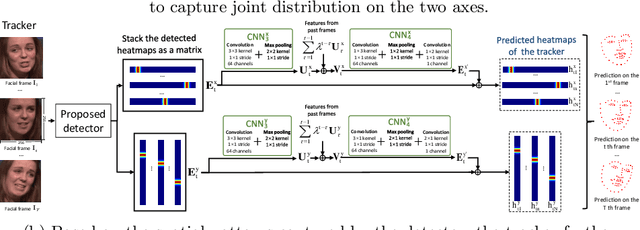

Although heatmap regression is considered a state-of-the-art method to locate facial landmarks, it suffers from huge spatial complexity and is prone to quantization error. To address this, we propose a novel attentive one-dimensional heatmap regression method for facial landmark localization. First, we predict two groups of 1D heatmaps to represent the marginal distributions of the x and y coordinates. These 1D heatmaps reduce spatial complexity significantly compared to current heatmap regression methods, which use 2D heatmaps to represent the joint distributions of x and y coordinates. With much lower spatial complexity, the proposed method can output high-resolution 1D heatmaps despite limited GPU memory, significantly alleviating the quantization error. Second, a co-attention mechanism is adopted to model the inherent spatial patterns existing in x and y coordinates, and therefore the joint distributions on the x and y axes are also captured. Third, based on the 1D heatmap structures, we propose a facial landmark detector capturing spatial patterns for landmark detection on an image; and a tracker further capturing temporal patterns with a temporal refinement mechanism for landmark tracking. Experimental results on four benchmark databases demonstrate the superiority of our method.
Face-to-Face Contrastive Learning for Social Intelligence Question-Answering
Jul 29, 2022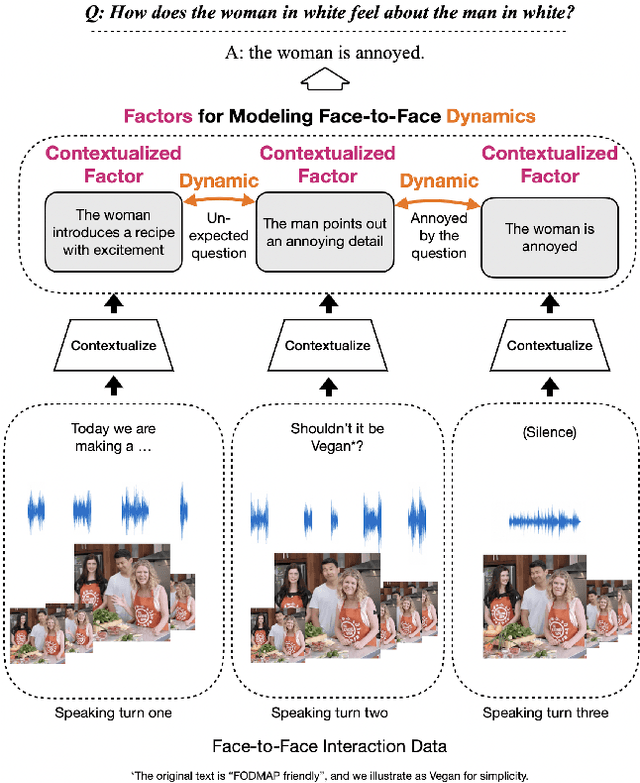
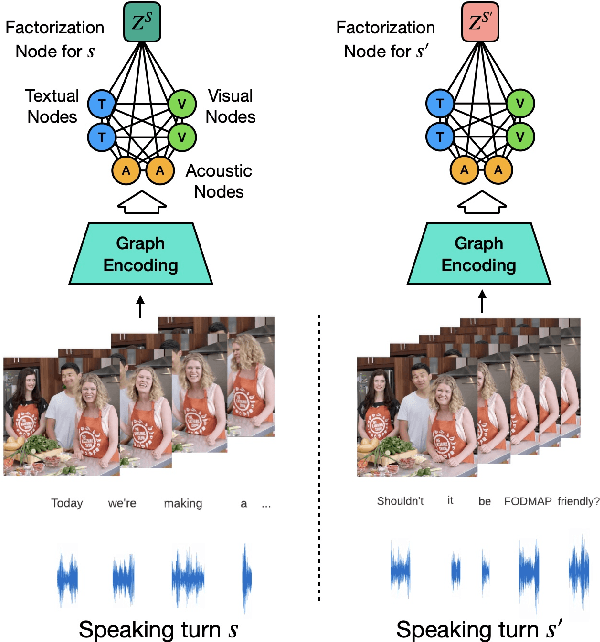
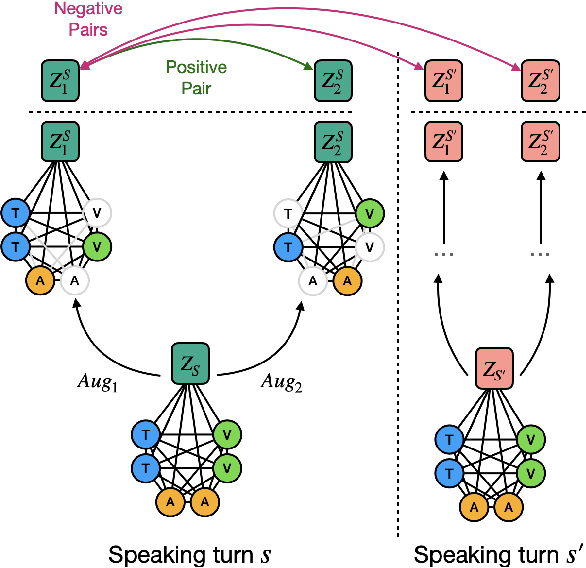
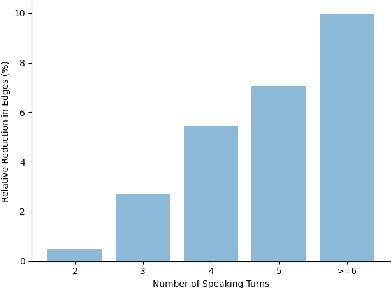
Creating artificial social intelligence - algorithms that can understand the nuances of multi-person interactions - is an exciting and emerging challenge in processing facial expressions and gestures from multimodal videos. Recent multimodal methods have set the state of the art on many tasks, but have difficulty modeling the complex face-to-face conversational dynamics across speaking turns in social interaction, particularly in a self-supervised setup. In this paper, we propose Face-to-Face Contrastive Learning (F2F-CL), a graph neural network designed to model social interactions using factorization nodes to contextualize the multimodal face-to-face interaction along the boundaries of the speaking turn. With the F2F-CL model, we propose to perform contrastive learning between the factorization nodes of different speaking turns within the same video. We experimentally evaluated the challenging Social-IQ dataset and show state-of-the-art results.
Facial Feedback for Reinforcement Learning: A Case Study and Offline Analysis Using the TAMER Framework
Jan 23, 2020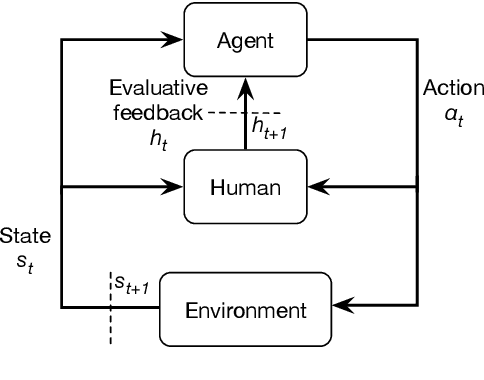
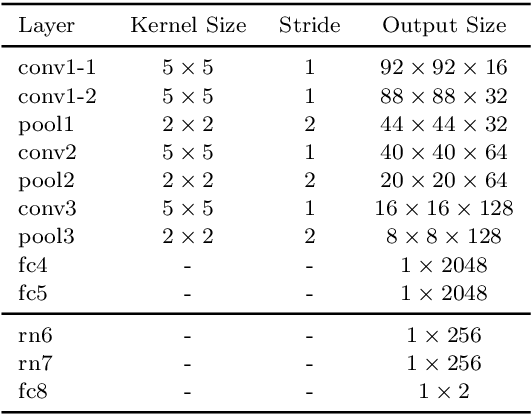
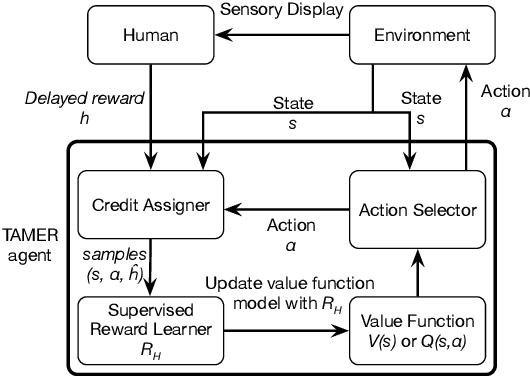
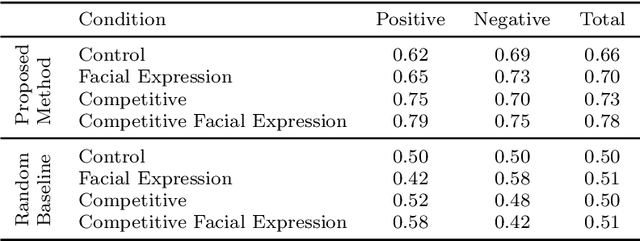
Interactive reinforcement learning provides a way for agents to learn to solve tasks from evaluative feedback provided by a human user. Previous research showed that humans give copious feedback early in training but very sparsely thereafter. In this article, we investigate the potential of agent learning from trainers' facial expressions via interpreting them as evaluative feedback. To do so, we implemented TAMER which is a popular interactive reinforcement learning method in a reinforcement-learning benchmark problem --- Infinite Mario, and conducted the first large-scale study of TAMER involving 561 participants. With designed CNN-RNN model, our analysis shows that telling trainers to use facial expressions and competition can improve the accuracies for estimating positive and negative feedback using facial expressions. In addition, our results with a simulation experiment show that learning solely from predicted feedback based on facial expressions is possible and using strong/effective prediction models or a regression method, facial responses would significantly improve the performance of agents. Furthermore, our experiment supports previous studies demonstrating the importance of bi-directional feedback and competitive elements in the training interface.
Let's face it: Probabilistic multi-modal interlocutor-aware generation of facial gestures in dyadic settings
Jun 11, 2020
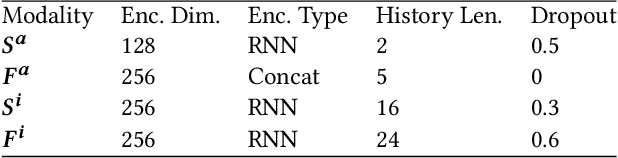
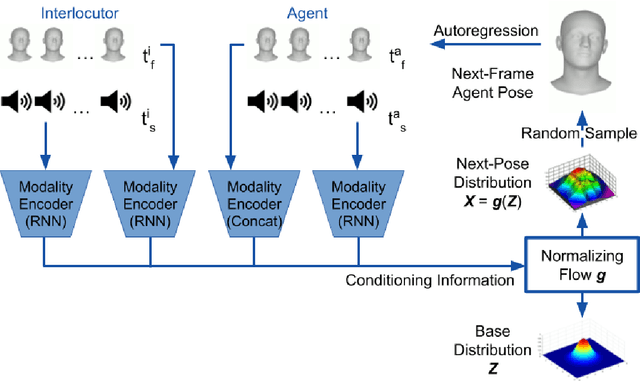

To enable more natural face-to-face interactions, conversational agents need to adapt their behavior to their interlocutors. One key aspect of this is generation of appropriate non-verbal behavior for the agent, for example facial gestures, here defined as facial expressions and head movements. Most existing gesture-generating systems do not utilize multi-modal cues from the interlocutor when synthesizing non-verbal behavior. Those that do, typically use deterministic methods that risk producing repetitive and non-vivid motions. In this paper, we introduce a probabilistic method to synthesize interlocutor-aware facial gestures - represented by highly expressive FLAME parameters - in dyadic conversations. Our contributions are: a) a method for feature extraction from multi-party video and speech recordings, resulting in a representation that allows for independent control and manipulation of expression and speech articulation in a 3D avatar; b) an extension to MoGlow, a recent motion-synthesis method based on normalizing flows, to also take multi-modal signals from the interlocutor as input and subsequently output interlocutor-aware facial gestures; and c) subjective and objective experiments assessing the use and relative importance of the different modalities in the synthesized output. The results show that the model successfully leverages the input from the interlocutor to generate more appropriate behavior.
Exposing Fine-grained Adversarial Vulnerability of Face Anti-spoofing Models
May 30, 2022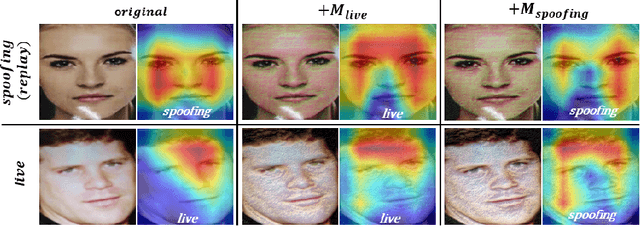
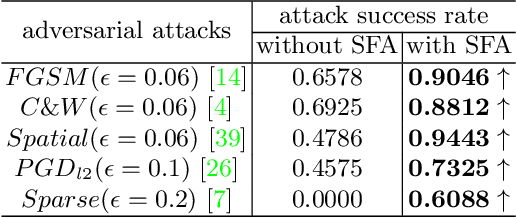
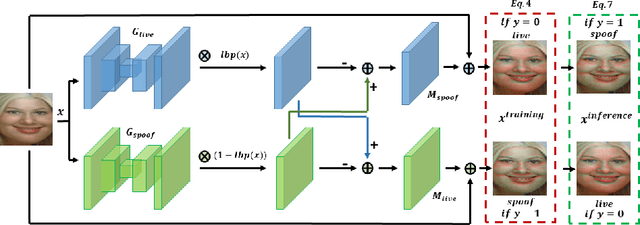
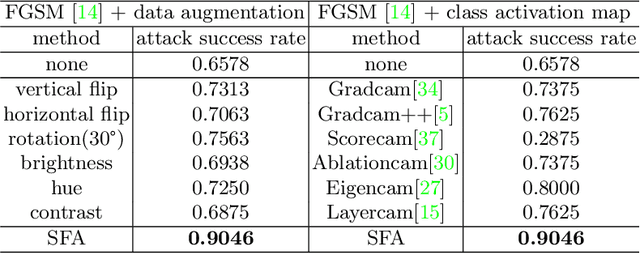
Adversarial attacks seriously threaten the high accuracy of face anti-spoofing models. Little adversarial noise can perturb their classification of live and spoofing. The existing adversarial attacks fail to figure out which part of the target face anti-spoofing model is vulnerable, making adversarial analysis tricky. So we propose fine-grained attacks for exposing adversarial vulnerability of face anti-spoofing models. Firstly, we propose Semantic Feature Augmentation (SFA) module, which makes adversarial noise semantic-aware to live and spoofing features. SFA considers the contrastive classes of data and texture bias of models in the context of face anti-spoofing, increasing the attack success rate by nearly 40% on average. Secondly, we generate fine-grained adversarial examples based on SFA and the multitask network with auxiliary information. We evaluate three annotations (facial attributes, spoofing types and illumination) and two geometric maps (depth and reflection), on four backbone networks (VGG, Resnet, Densenet and Swin Transformer). We find that facial attributes annotation and state-of-art networks fail to guarantee that models are robust to adversarial attacks. Such adversarial attacks can be generalized to more auxiliary information and backbone networks, to help our community handle the trade-off between accuracy and adversarial robustness.
Concept Drift Challenge in Multimedia Anomaly Detection: A Case Study with Facial Datasets
Jul 27, 2022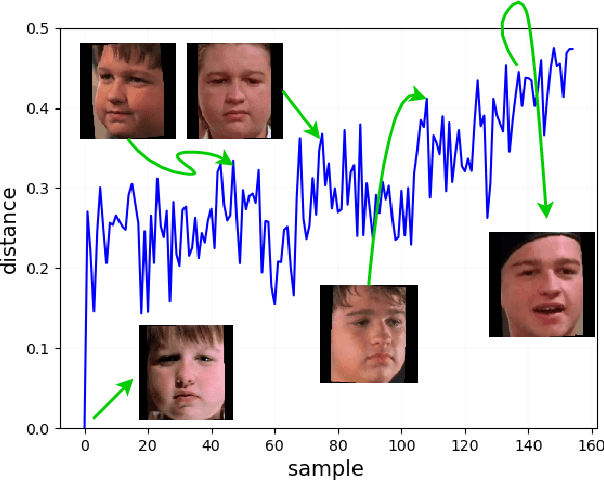
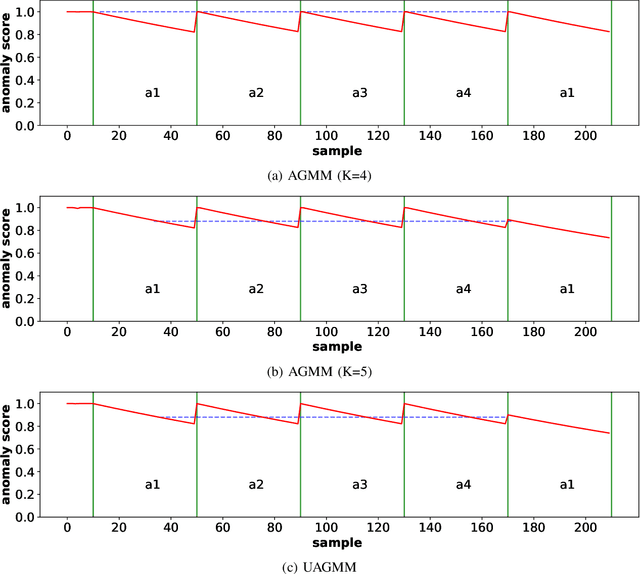
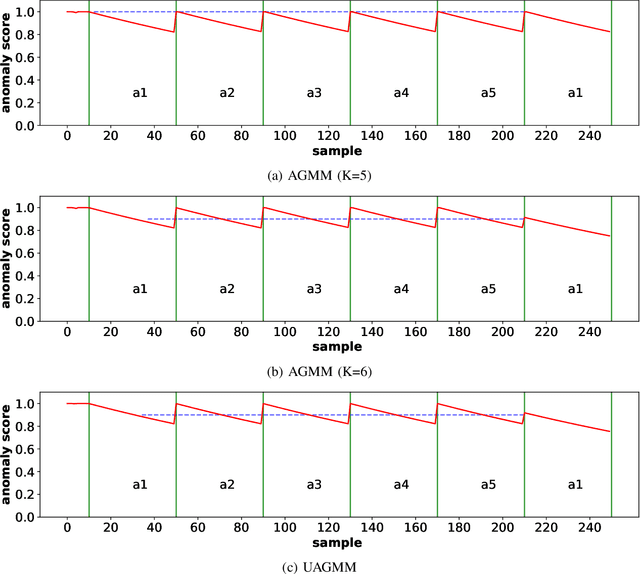
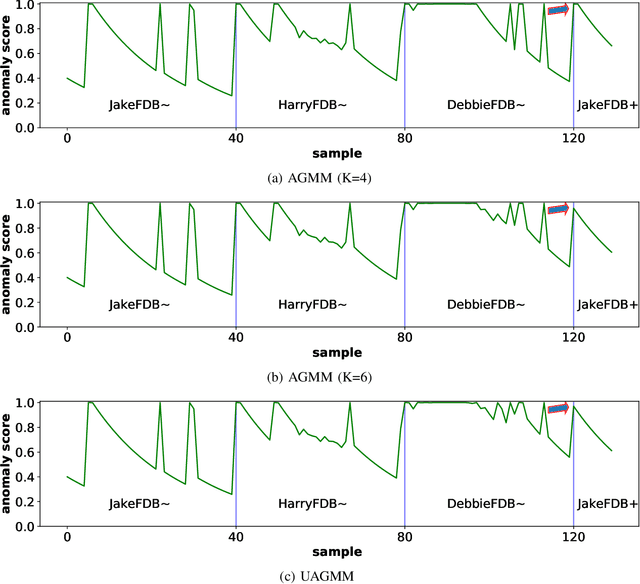
Anomaly detection in multimedia datasets is a widely studied area. Yet, the concept drift challenge in data has been ignored or poorly handled by the majority of the anomaly detection frameworks. The state-of-the-art approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can drift from one class to another in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we systematically investigate the effect of concept drift on various detection models and propose a modified Adaptive Gaussian Mixture Model (AGMM) based framework for anomaly detection in multimedia data. In contrast to the baseline AGMM, the proposed extension of AGMM remembers the past for a longer period in order to handle the drift better. Extensive experimental analysis shows that the proposed model better handles the drift in data as compared with the baseline AGMM. Further, to facilitate research and comparison with the proposed framework, we contribute three multimedia datasets constituting faces as samples. The face samples of individuals correspond to the age difference of more than ten years to incorporate a longer temporal context.
IMU2Face: Real-time Gesture-driven Facial Reenactment
Dec 18, 2017We present IMU2Face, a gesture-driven facial reenactment system. To this end, we combine recent advances in facial motion capture and inertial measurement units (IMUs) to control the facial expressions of a person in a target video based on intuitive hand gestures. IMUs are omnipresent, since modern smart-phones, smart-watches and drones integrate such sensors, e.g., for changing the orientation of the screen content, counting steps, or for flight stabilization. Face tracking and reenactment is based on the state-of-the-art real-time Face2Face facial reenactment system. Instead of transferring facial expressions from a source to a target actor, we employ an IMU to track the hand gestures of a source actor and use its orientation to modify the target actor's expressions.
Gender Classification and Bias Mitigation in Facial Images
Jul 13, 2020
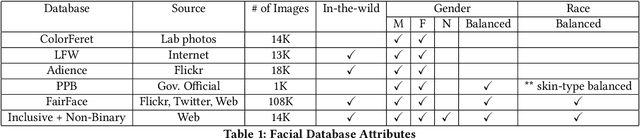
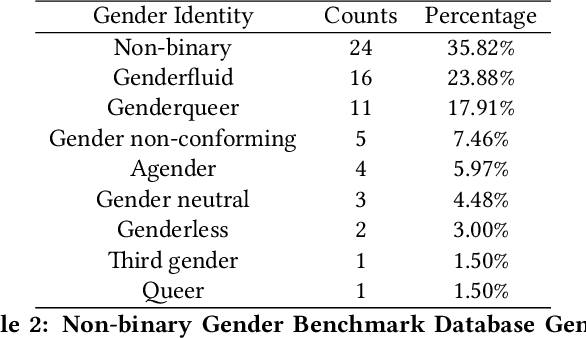
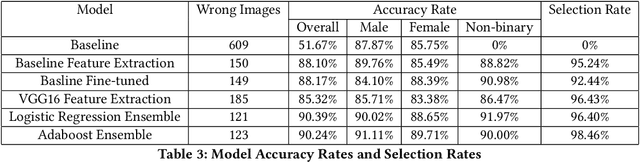
Gender classification algorithms have important applications in many domains today such as demographic research, law enforcement, as well as human-computer interaction. Recent research showed that algorithms trained on biased benchmark databases could result in algorithmic bias. However, to date, little research has been carried out on gender classification algorithms' bias towards gender minorities subgroups, such as the LGBTQ and the non-binary population, who have distinct characteristics in gender expression. In this paper, we began by conducting surveys on existing benchmark databases for facial recognition and gender classification tasks. We discovered that the current benchmark databases lack representation of gender minority subgroups. We worked on extending the current binary gender classifier to include a non-binary gender class. We did that by assembling two new facial image databases: 1) a racially balanced inclusive database with a subset of LGBTQ population 2) an inclusive-gender database that consists of people with non-binary gender. We worked to increase classification accuracy and mitigate algorithmic biases on our baseline model trained on the augmented benchmark database. Our ensemble model has achieved an overall accuracy score of 90.39%, which is a 38.72% increase from the baseline binary gender classifier trained on Adience. While this is an initial attempt towards mitigating bias in gender classification, more work is needed in modeling gender as a continuum by assembling more inclusive databases.
* 9 pages
Performance analysis of facial recognition: A critical review through glass factor
Apr 04, 2021
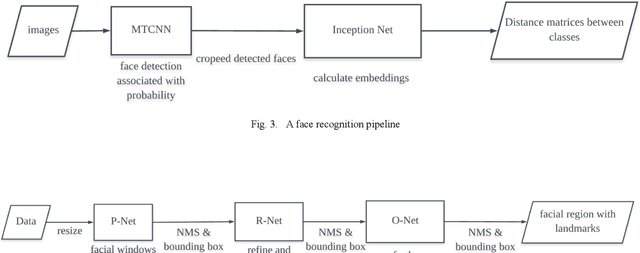
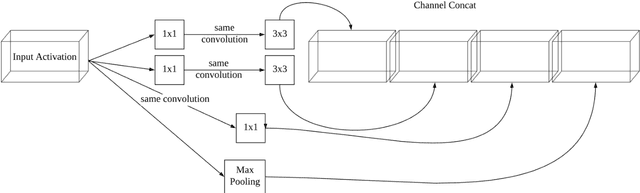

COVID-19 pandemic and social distancing urge a reliable human face recognition system in different abnormal situations. However, there is no research which studies the influence of glass factor in facial recognition system. This paper provides a comprehensive review of glass factor. The study contains two steps: data collection and accuracy test. Data collection includes collecting human face images through different situations, such as clear glasses, glass with water and glass with mist. Based on the collected data, an existing state-of-the-art face detection and recognition system built upon MTCNN and Inception V1 deep nets is tested for further analysis. Experimental data supports that 1) the system is robust for classification when comparing real-time images and 2) it fails at determining if two images are of same person by comparing real-time disturbed image with the frontal ones.