 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Feedback for Reinforcement Learning: A Case Study and Offline Analysis Using the TAMER Framework
Jan 23, 2020
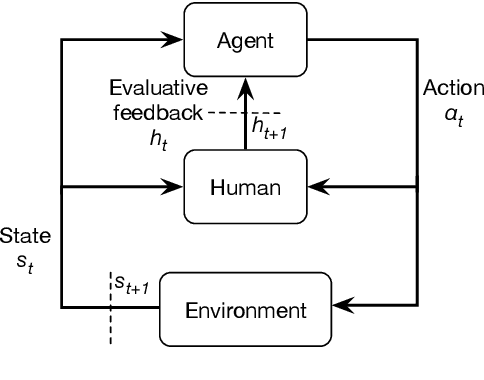
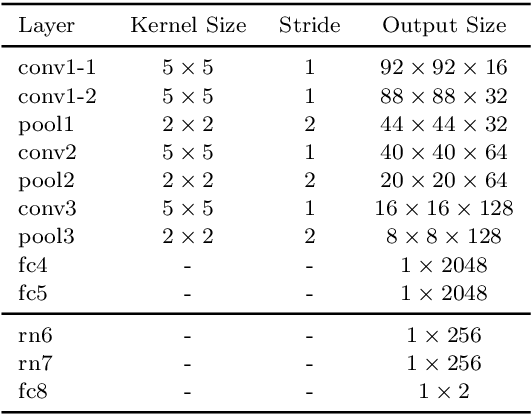
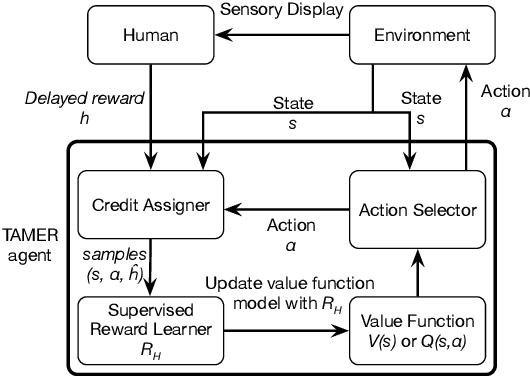
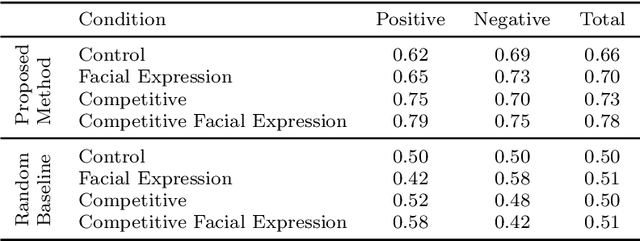
Interactive reinforcement learning provides a way for agents to learn to solve tasks from evaluative feedback provided by a human user. Previous research showed that humans give copious feedback early in training but very sparsely thereafter. In this article, we investigate the potential of agent learning from trainers' facial expressions via interpreting them as evaluative feedback. To do so, we implemented TAMER which is a popular interactive reinforcement learning method in a reinforcement-learning benchmark problem --- Infinite Mario, and conducted the first large-scale study of TAMER involving 561 participants. With designed CNN-RNN model, our analysis shows that telling trainers to use facial expressions and competition can improve the accuracies for estimating positive and negative feedback using facial expressions. In addition, our results with a simulation experiment show that learning solely from predicted feedback based on facial expressions is possible and using strong/effective prediction models or a regression method, facial responses would significantly improve the performance of agents. Furthermore, our experiment supports previous studies demonstrating the importance of bi-directional feedback and competitive elements in the training interface.
Concept Drift Challenge in Multimedia Anomaly Detection: A Case Study with Facial Datasets
Jul 27, 2022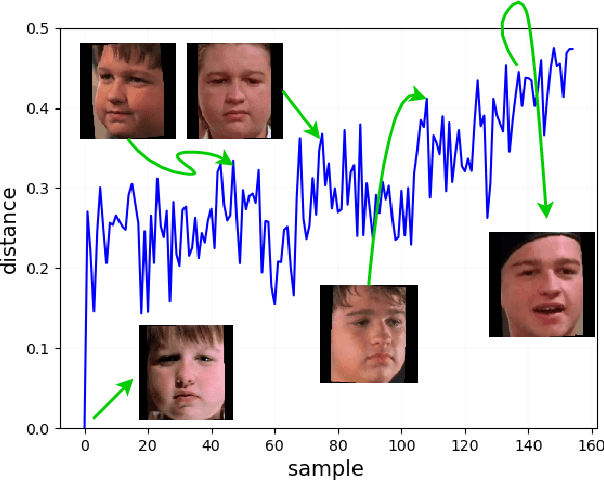
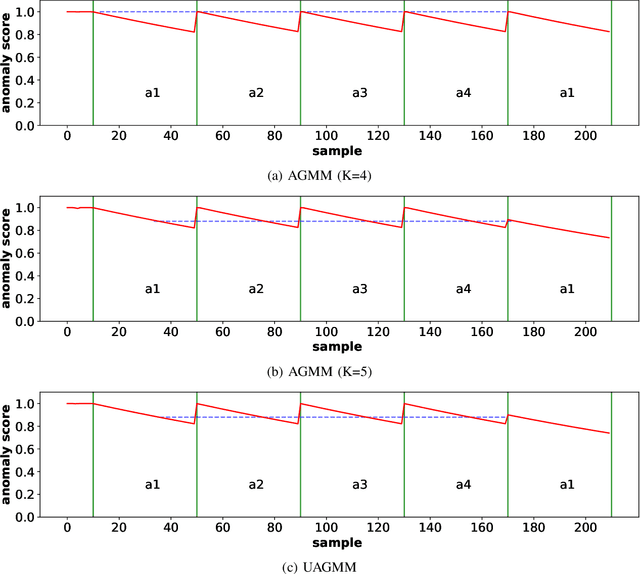
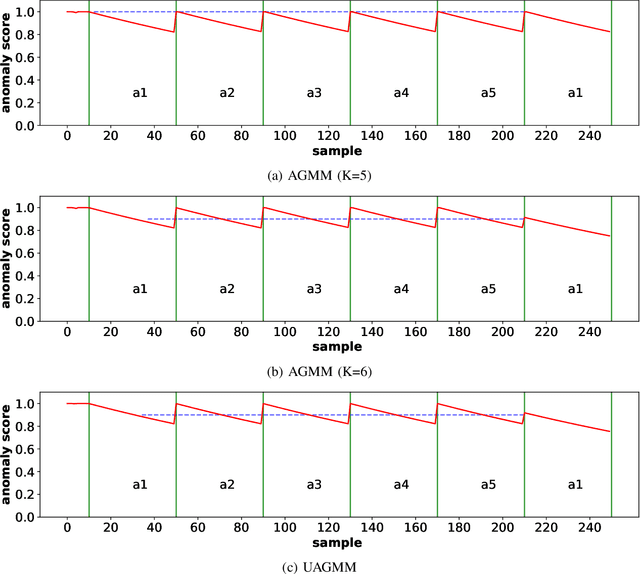
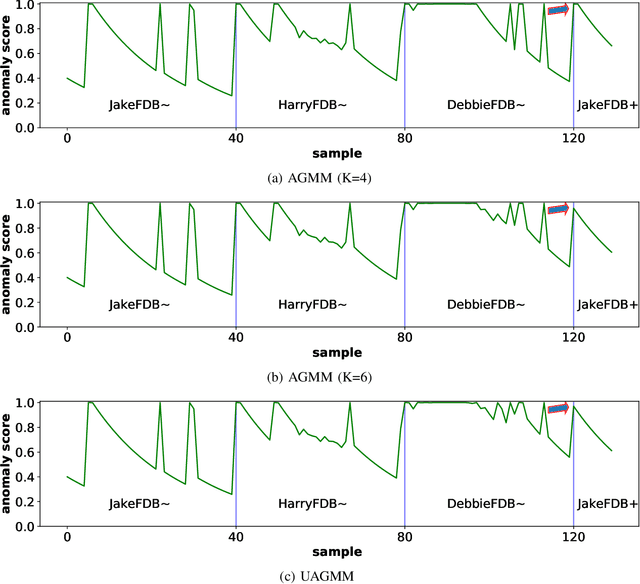
Anomaly detection in multimedia datasets is a widely studied area. Yet, the concept drift challenge in data has been ignored or poorly handled by the majority of the anomaly detection frameworks. The state-of-the-art approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can drift from one class to another in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we systematically investigate the effect of concept drift on various detection models and propose a modified Adaptive Gaussian Mixture Model (AGMM) based framework for anomaly detection in multimedia data. In contrast to the baseline AGMM, the proposed extension of AGMM remembers the past for a longer period in order to handle the drift better. Extensive experimental analysis shows that the proposed model better handles the drift in data as compared with the baseline AGMM. Further, to facilitate research and comparison with the proposed framework, we contribute three multimedia datasets constituting faces as samples. The face samples of individuals correspond to the age difference of more than ten years to incorporate a longer temporal context.
Gender Classification and Bias Mitigation in Facial Images
Jul 13, 2020
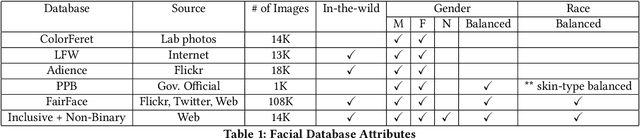
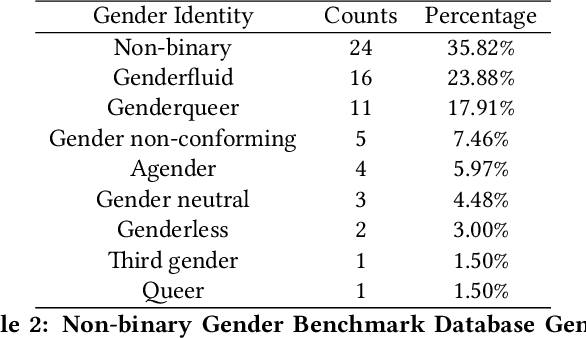
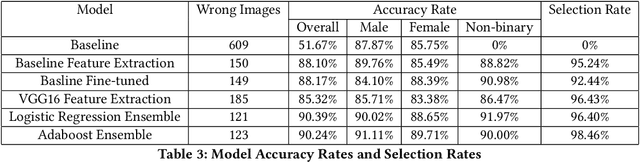
Gender classification algorithms have important applications in many domains today such as demographic research, law enforcement, as well as human-computer interaction. Recent research showed that algorithms trained on biased benchmark databases could result in algorithmic bias. However, to date, little research has been carried out on gender classification algorithms' bias towards gender minorities subgroups, such as the LGBTQ and the non-binary population, who have distinct characteristics in gender expression. In this paper, we began by conducting surveys on existing benchmark databases for facial recognition and gender classification tasks. We discovered that the current benchmark databases lack representation of gender minority subgroups. We worked on extending the current binary gender classifier to include a non-binary gender class. We did that by assembling two new facial image databases: 1) a racially balanced inclusive database with a subset of LGBTQ population 2) an inclusive-gender database that consists of people with non-binary gender. We worked to increase classification accuracy and mitigate algorithmic biases on our baseline model trained on the augmented benchmark database. Our ensemble model has achieved an overall accuracy score of 90.39%, which is a 38.72% increase from the baseline binary gender classifier trained on Adience. While this is an initial attempt towards mitigating bias in gender classification, more work is needed in modeling gender as a continuum by assembling more inclusive databases.
* 9 pages
Are GAN-based Morphs Threatening Face Recognition?
May 05, 2022
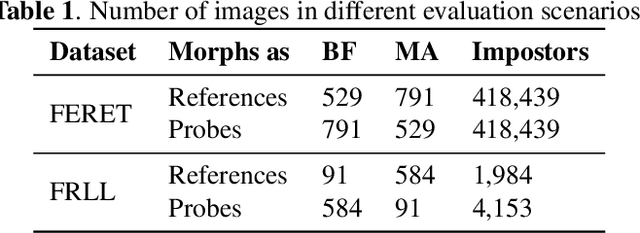
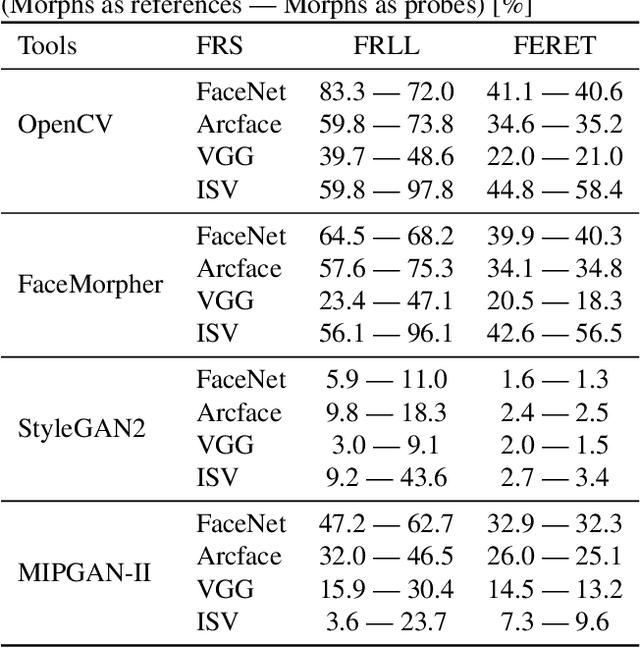
Morphing attacks are a threat to biometric systems where the biometric reference in an identity document can be altered. This form of attack presents an important issue in applications relying on identity documents such as border security or access control. Research in generation of face morphs and their detection is developing rapidly, however very few datasets with morphing attacks and open-source detection toolkits are publicly available. This paper bridges this gap by providing two datasets and the corresponding code for four types of morphing attacks: two that rely on facial landmarks based on OpenCV and FaceMorpher, and two that use StyleGAN 2 to generate synthetic morphs. We also conduct extensive experiments to assess the vulnerability of four state-of-the-art face recognition systems, including FaceNet, VGG-Face, ArcFace, and ISV. Surprisingly, the experiments demonstrate that, although visually more appealing, morphs based on StyleGAN 2 do not pose a significant threat to the state to face recognition systems, as these morphs were outmatched by the simple morphs that are based facial landmarks.
* arXiv admin note: substantial text overlap with arXiv:2012.05344
IMU2Face: Real-time Gesture-driven Facial Reenactment
Dec 18, 2017We present IMU2Face, a gesture-driven facial reenactment system. To this end, we combine recent advances in facial motion capture and inertial measurement units (IMUs) to control the facial expressions of a person in a target video based on intuitive hand gestures. IMUs are omnipresent, since modern smart-phones, smart-watches and drones integrate such sensors, e.g., for changing the orientation of the screen content, counting steps, or for flight stabilization. Face tracking and reenactment is based on the state-of-the-art real-time Face2Face facial reenactment system. Instead of transferring facial expressions from a source to a target actor, we employ an IMU to track the hand gestures of a source actor and use its orientation to modify the target actor's expressions.
AT-DDPM: Restoring Faces degraded by Atmospheric Turbulence using Denoising Diffusion Probabilistic Models
Aug 24, 2022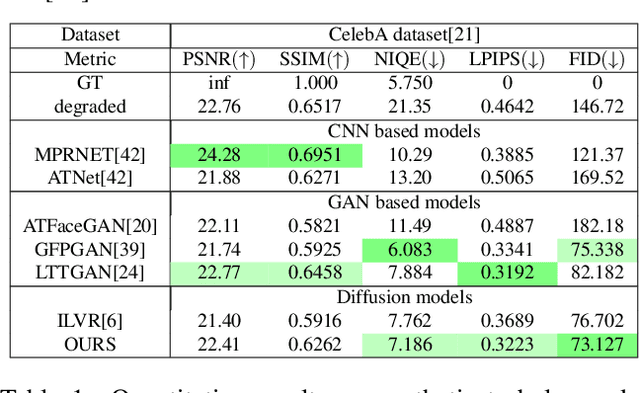
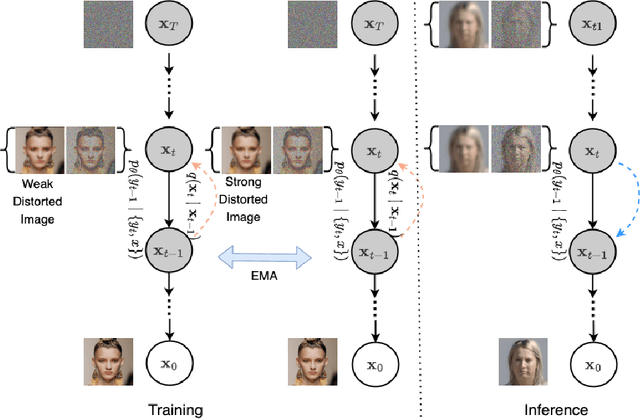
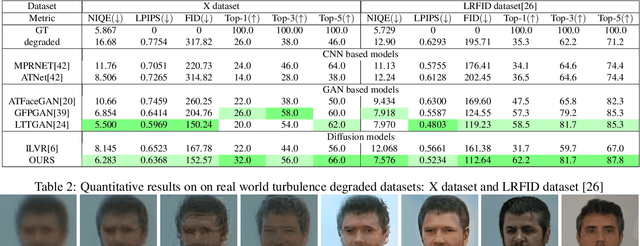

Although many long-range imaging systems are designed to support extended vision applications, a natural obstacle to their operation is degradation due to atmospheric turbulence. Atmospheric turbulence causes significant degradation to image quality by introducing blur and geometric distortion. In recent years, various deep learning-based single image atmospheric turbulence mitigation methods, including CNN-based and GAN inversion-based, have been proposed in the literature which attempt to remove the distortion in the image. However, some of these methods are difficult to train and often fail to reconstruct facial features and produce unrealistic results especially in the case of high turbulence. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained some traction because of their stable training process and their ability to generate high quality images. In this paper, we propose the first DDPM-based solution for the problem of atmospheric turbulence mitigation. We also propose a fast sampling technique for reducing the inference times for conditional DDPMs. Extensive experiments are conducted on synthetic and real-world data to show the significance of our model. To facilitate further research, all codes and pretrained models will be made public after the review process.
Performance analysis of facial recognition: A critical review through glass factor
Apr 04, 2021
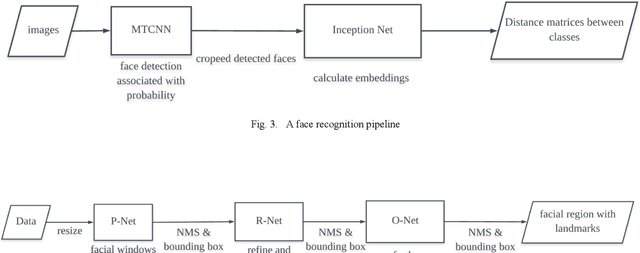
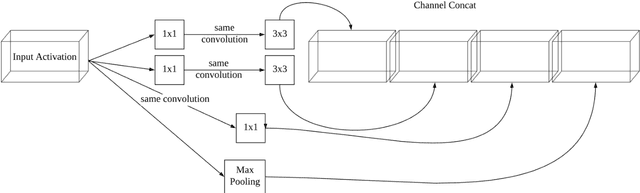

COVID-19 pandemic and social distancing urge a reliable human face recognition system in different abnormal situations. However, there is no research which studies the influence of glass factor in facial recognition system. This paper provides a comprehensive review of glass factor. The study contains two steps: data collection and accuracy test. Data collection includes collecting human face images through different situations, such as clear glasses, glass with water and glass with mist. Based on the collected data, an existing state-of-the-art face detection and recognition system built upon MTCNN and Inception V1 deep nets is tested for further analysis. Experimental data supports that 1) the system is robust for classification when comparing real-time images and 2) it fails at determining if two images are of same person by comparing real-time disturbed image with the frontal ones.
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 25, 2021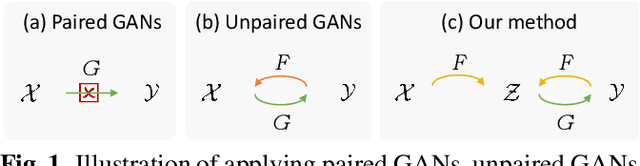
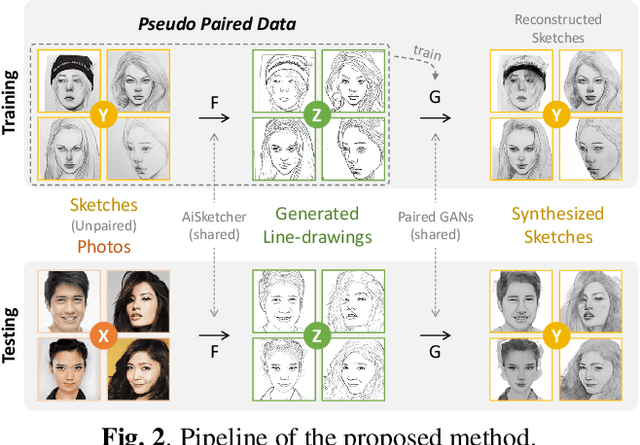
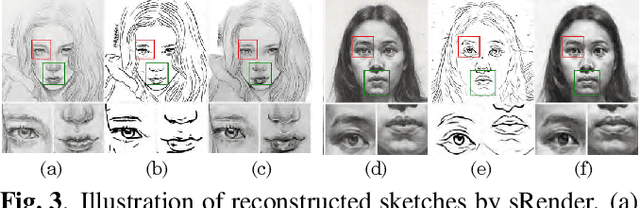
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
FV2ES: A Fully End2End Multimodal System for Fast Yet Effective Video Emotion Recognition Inference
Sep 21, 2022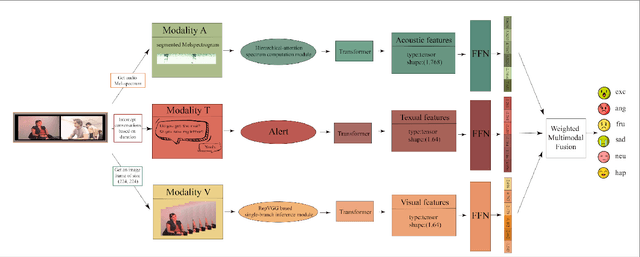
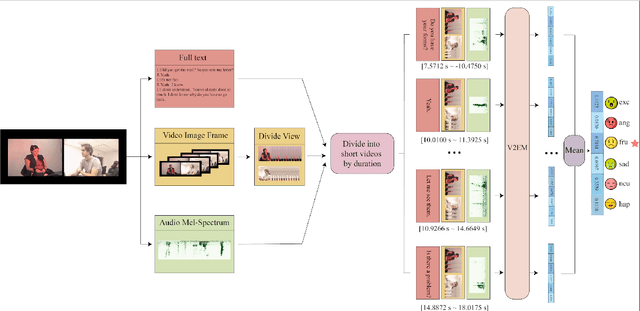
In the latest social networks, more and more people prefer to express their emotions in videos through text, speech, and rich facial expressions. Multimodal video emotion analysis techniques can help understand users' inner world automatically based on human expressions and gestures in images, tones in voices, and recognized natural language. However, in the existing research, the acoustic modality has long been in a marginal position as compared to visual and textual modalities. That is, it tends to be more difficult to improve the contribution of the acoustic modality for the whole multimodal emotion recognition task. Besides, although better performance can be obtained by introducing common deep learning methods, the complex structures of these training models always result in low inference efficiency, especially when exposed to high-resolution and long-length videos. Moreover, the lack of a fully end-to-end multimodal video emotion recognition system hinders its application. In this paper, we designed a fully multimodal video-to-emotion system (named FV2ES) for fast yet effective recognition inference, whose benefits are threefold: (1) The adoption of the hierarchical attention method upon the sound spectra breaks through the limited contribution of the acoustic modality and outperforms the existing models' performance on both IEMOCAP and CMU-MOSEI datasets; (2) the introduction of the idea of multi-scale for visual extraction while single-branch for inference brings higher efficiency and maintains the prediction accuracy at the same time; (3) the further integration of data pre-processing into the aligned multimodal learning model allows the significant reduction of computational costs and storage space.
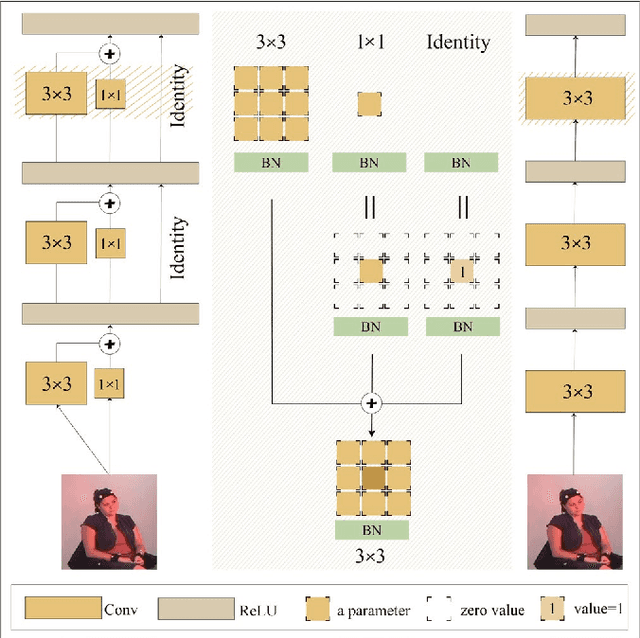
MMNet: Muscle motion-guided network for micro-expression recognition
Jan 14, 2022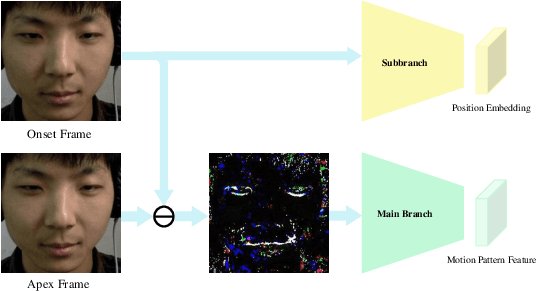
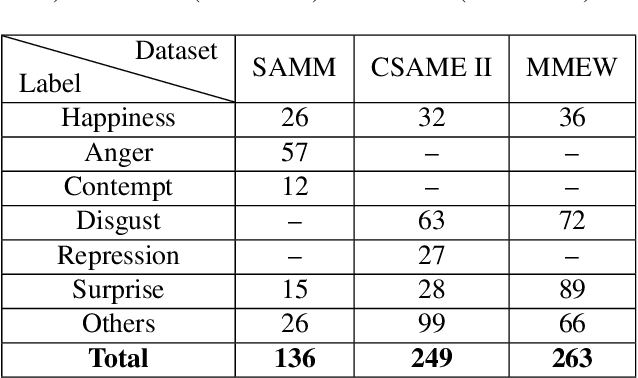
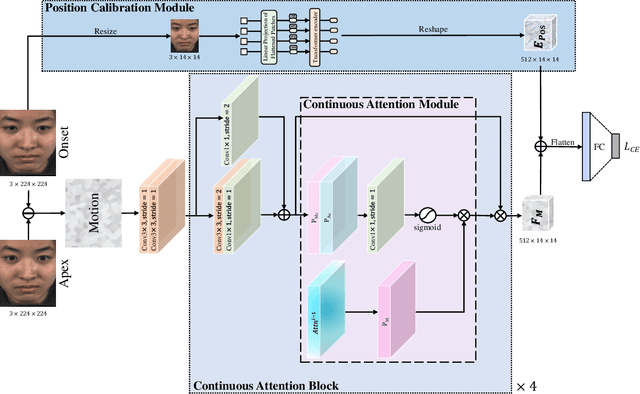
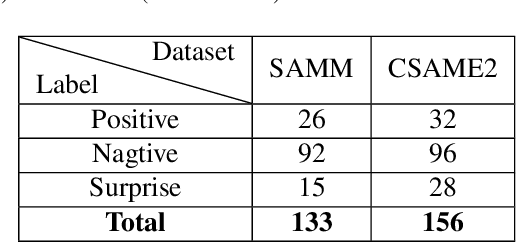
Facial micro-expressions (MEs) are involuntary facial motions revealing peoples real feelings and play an important role in the early intervention of mental illness, the national security, and many human-computer interaction systems. However, existing micro-expression datasets are limited and usually pose some challenges for training good classifiers. To model the subtle facial muscle motions, we propose a robust micro-expression recognition (MER) framework, namely muscle motion-guided network (MMNet). Specifically, a continuous attention (CA) block is introduced to focus on modeling local subtle muscle motion patterns with little identity information, which is different from most previous methods that directly extract features from complete video frames with much identity information. Besides, we design a position calibration (PC) module based on the vision transformer. By adding the position embeddings of the face generated by PC module at the end of the two branches, the PC module can help to add position information to facial muscle motion pattern features for the MER. Extensive experiments on three public micro-expression datasets demonstrate that our approach outperforms state-of-the-art methods by a large margin.