 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Learning a Generalized Physical Face Model From Data
Feb 29, 2024
Physically-based simulation is a powerful approach for 3D facial animation as the resulting deformations are governed by physical constraints, allowing to easily resolve self-collisions, respond to external forces and perform realistic anatomy edits. Today's methods are data-driven, where the actuations for finite elements are inferred from captured skin geometry. Unfortunately, these approaches have not been widely adopted due to the complexity of initializing the material space and learning the deformation model for each character separately, which often requires a skilled artist followed by lengthy network training. In this work, we aim to make physics-based facial animation more accessible by proposing a generalized physical face model that we learn from a large 3D face dataset in a simulation-free manner. Once trained, our model can be quickly fit to any unseen identity and produce a ready-to-animate physical face model automatically. Fitting is as easy as providing a single 3D face scan, or even a single face image. After fitting, we offer intuitive animation controls, as well as the ability to retarget animations across characters. All the while, the resulting animations allow for physical effects like collision avoidance, gravity, paralysis, bone reshaping and more.
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Mar 08, 2024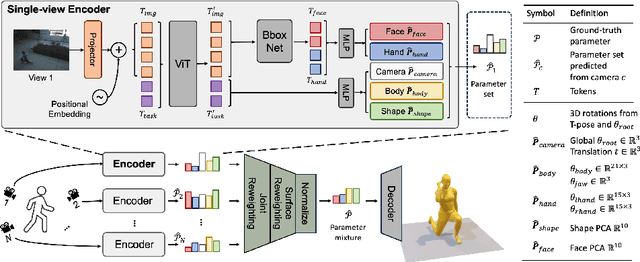
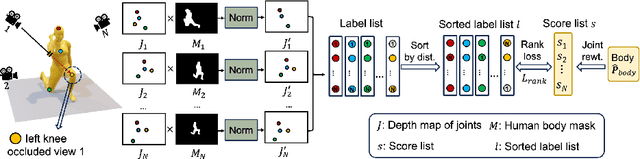

Multiple cameras can provide multi-view video coverage of a person. It is necessary to fuse multi-view data, e.g., for subsequent behavioral analysis, while such fusion often relies on calibration of cameras in traditional solutions. However, it is non-trivial to calibrate multiple cameras. In this work, we propose a method to reconstruct 3D human body from multiple uncalibrated camera views. First, we adopt a pre-trained human body encoder to process each individual camera view, such that human body models and parameters can be reconstructed for each view. Next, instead of simply averaging models across views, we train a network to determine the weights of individual views for their fusion, based on the parameters estimated for joints and hands of human body as well as camera positions. Further, we turn to the mesh surface of human body for dynamic fusion, such that facial expression can be seamlessly integrated into the model of human body. Our method has demonstrated superior performance in reconstructing human body upon two public datasets. More importantly, our method can flexibly support ad-hoc deployment of an arbitrary number of cameras, which has significant potential in related applications. We will release source code upon acceptance of the paper.
Image Coding for Machines with Edge Information Learning Using Segment Anything
Mar 07, 2024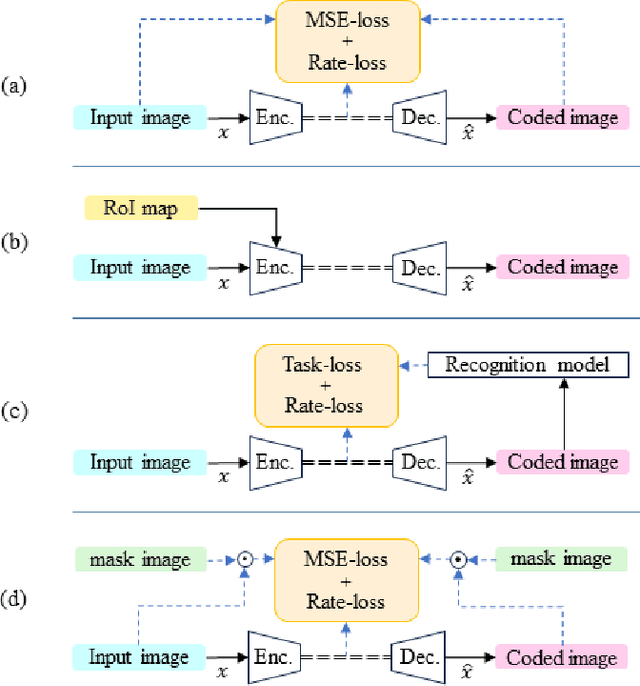
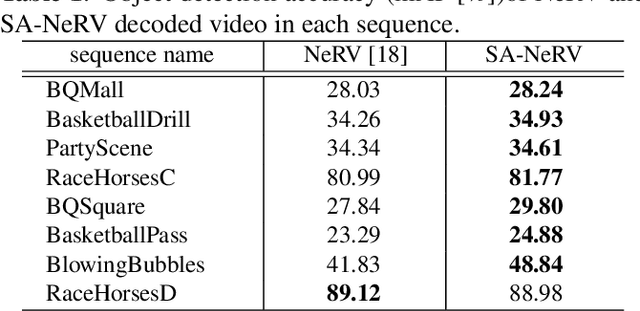

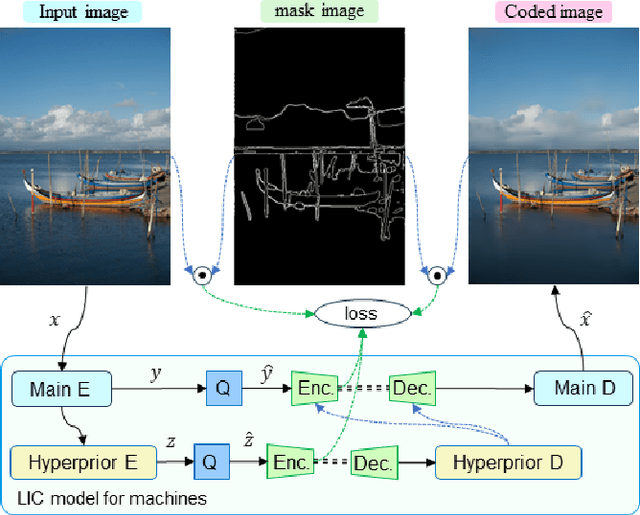
Image Coding for Machines (ICM) is an image compression technique for image recognition. This technique is essential due to the growing demand for image recognition AI. In this paper, we propose a method for ICM that focuses on encoding and decoding only the edge information of object parts in an image, which we call SA-ICM. This is an Learned Image Compression (LIC) model trained using edge information created by Segment Anything. Our method can be used for image recognition models with various tasks. SA-ICM is also robust to changes in input data, making it effective for a variety of use cases. Additionally, our method provides benefits from a privacy point of view, as it removes human facial information on the encoder's side, thus protecting one's privacy. Furthermore, this LIC model training method can be used to train Neural Representations for Videos (NeRV), which is a video compression model. By training NeRV using edge information created by Segment Anything, it is possible to create a NeRV that is effective for image recognition (SA-NeRV). Experimental results confirm the advantages of SA-ICM, presenting the best performance in image compression for image recognition. We also show that SA-NeRV is superior to ordinary NeRV in video compression for machines.
G4G:A Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
Feb 28, 2024Despite numerous completed studies, achieving high fidelity talking face generation with highly synchronized lip movements corresponding to arbitrary audio remains a significant challenge in the field. The shortcomings of published studies continue to confuse many researchers. This paper introduces G4G, a generic framework for high fidelity talking face generation with fine-grained intra-modal alignment. G4G can reenact the high fidelity of original video while producing highly synchronized lip movements regardless of given audio tones or volumes. The key to G4G's success is the use of a diagonal matrix to enhance the ordinary alignment of audio-image intra-modal features, which significantly increases the comparative learning between positive and negative samples. Additionally, a multi-scaled supervision module is introduced to comprehensively reenact the perceptional fidelity of original video across the facial region while emphasizing the synchronization of lip movements and the input audio. A fusion network is then used to further fuse the facial region and the rest. Our experimental results demonstrate significant achievements in reenactment of original video quality as well as highly synchronized talking lips. G4G is an outperforming generic framework that can produce talking videos competitively closer to ground truth level than current state-of-the-art methods.
Automated facial recognition system using deep learning for pain assessment in adults with cerebral palsy
Jan 22, 2024Background: Pain assessment in individuals with neurological conditions, especially those with limited self-report ability and altered facial expressions, presents challenges. Existing measures, relying on direct observation by caregivers, lack sensitivity and specificity. In cerebral palsy, pain is a common comorbidity and a reliable evaluation protocol is crucial. Thus, having an automatic system that recognizes facial expressions could be of enormous help when diagnosing pain in this type of patient. Objectives: 1) to build a dataset of facial pain expressions in individuals with cerebral palsy, and 2) to develop an automated facial recognition system based on deep learning for pain assessment addressed to this population. Methods: Ten neural networks were trained on three pain image databases, including the UNBC-McMaster Shoulder Pain Expression Archive Database, the Multimodal Intensity Pain Dataset, and the Delaware Pain Database. Additionally, a curated dataset (CPPAIN) was created, consisting of 109 preprocessed facial pain expression images from individuals with cerebral palsy, categorized by two physiotherapists using the Facial Action Coding System observational scale. Results: InceptionV3 exhibited promising performance on the CP-PAIN dataset, achieving an accuracy of 62.67% and an F1 score of 61.12%. Explainable artificial intelligence techniques revealed consistent essential features for pain identification across models. Conclusion: This study demonstrates the potential of deep learning models for robust pain detection in populations with neurological conditions and communication disabilities. The creation of a larger dataset specific to cerebral palsy would further enhance model accuracy, offering a valuable tool for discerning subtle and idiosyncratic pain expressions. The insights gained could extend to other complex neurological conditions.
Unveiling the Human-like Similarities of Automatic Facial Expression Recognition: An Empirical Exploration through Explainable AI
Jan 22, 2024Facial expression recognition is vital for human behavior analysis, and deep learning has enabled models that can outperform humans. However, it is unclear how closely they mimic human processing. This study aims to explore the similarity between deep neural networks and human perception by comparing twelve different networks, including both general object classifiers and FER-specific models. We employ an innovative global explainable AI method to generate heatmaps, revealing crucial facial regions for the twelve networks trained on six facial expressions. We assess these results both quantitatively and qualitatively, comparing them to ground truth masks based on Friesen and Ekman's description and among them. We use Intersection over Union (IoU) and normalized correlation coefficients for comparisons. We generate 72 heatmaps to highlight critical regions for each expression and architecture. Qualitatively, models with pre-trained weights show more similarity in heatmaps compared to those without pre-training. Specifically, eye and nose areas influence certain facial expressions, while the mouth is consistently important across all models and expressions. Quantitatively, we find low average IoU values (avg. 0.2702) across all expressions and architectures. The best-performing architecture averages 0.3269, while the worst-performing one averages 0.2066. Dendrograms, built with the normalized correlation coefficient, reveal two main clusters for most expressions: models with pre-training and models without pre-training. Findings suggest limited alignment between human and AI facial expression recognition, with network architectures influencing the similarity, as similar architectures prioritize similar facial regions.
Evaluating the Feasibility of Standard Facial Expression Recognition in Individuals with Moderate to Severe Intellectual Disabilities
Jan 22, 2024Recent research has underscored the increasing preference of users for human-like interactions with machines. Consequently, facial expression recognition has gained significance as a means of imparting social robots with the capacity to discern the emotional states of users. In this investigation, we assess the suitability of deep learning approaches, known for their remarkable performance in this domain, for recognizing facial expressions in individuals with intellectual disabilities, which has not been yet studied in the literature, to the best of our knowledge. To address this objective, we train a set of twelve distinct convolutional neural networks in different approaches, including an ensemble of datasets without individuals with intellectual disabilities and a dataset featuring such individuals. Our examination of the outcomes achieved by the various models under distinct training conditions, coupled with a comprehensive analysis of critical facial regions during expression recognition facilitated by explainable artificial intelligence techniques, revealed significant distinctions in facial expressions between individuals with and without intellectual disabilities, as well as among individuals with intellectual disabilities. Remarkably, our findings demonstrate the feasibility of facial expression recognition within this population through tailored user-specific training methodologies, which enable the models to effectively address the unique expressions of each user.
Doubly Abductive Counterfactual Inference for Text-based Image Editing
Mar 05, 2024

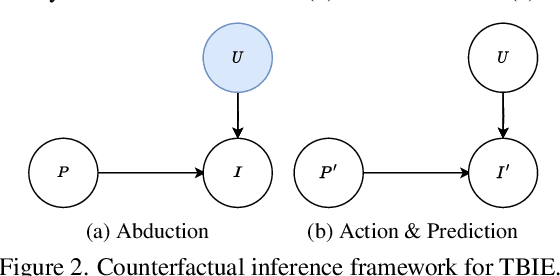

We study text-based image editing (TBIE) of a single image by counterfactual inference because it is an elegant formulation to precisely address the requirement: the edited image should retain the fidelity of the original one. Through the lens of the formulation, we find that the crux of TBIE is that existing techniques hardly achieve a good trade-off between editability and fidelity, mainly due to the overfitting of the single-image fine-tuning. To this end, we propose a Doubly Abductive Counterfactual inference framework (DAC). We first parameterize an exogenous variable as a UNet LoRA, whose abduction can encode all the image details. Second, we abduct another exogenous variable parameterized by a text encoder LoRA, which recovers the lost editability caused by the overfitted first abduction. Thanks to the second abduction, which exclusively encodes the visual transition from post-edit to pre-edit, its inversion -- subtracting the LoRA -- effectively reverts pre-edit back to post-edit, thereby accomplishing the edit. Through extensive experiments, our DAC achieves a good trade-off between editability and fidelity. Thus, we can support a wide spectrum of user editing intents, including addition, removal, manipulation, replacement, style transfer, and facial change, which are extensively validated in both qualitative and quantitative evaluations. Codes are in https://github.com/xuesong39/DAC.
Toward Fairness via Maximum Mean Discrepancy Regularization on Logits Space
Feb 20, 2024Fairness has become increasingly pivotal in machine learning for high-risk applications such as machine learning in healthcare and facial recognition. However, we see the deficiency in the previous logits space constraint methods. Therefore, we propose a novel framework, Logits-MMD, that achieves the fairness condition by imposing constraints on output logits with Maximum Mean Discrepancy. Moreover, quantitative analysis and experimental results show that our framework has a better property that outperforms previous methods and achieves state-of-the-art on two facial recognition datasets and one animal dataset. Finally, we show experimental results and demonstrate that our debias approach achieves the fairness condition effectively.
Deformable One-shot Face Stylization via DINO Semantic Guidance
Mar 04, 2024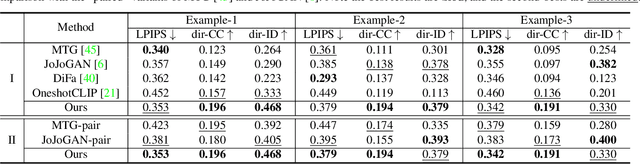


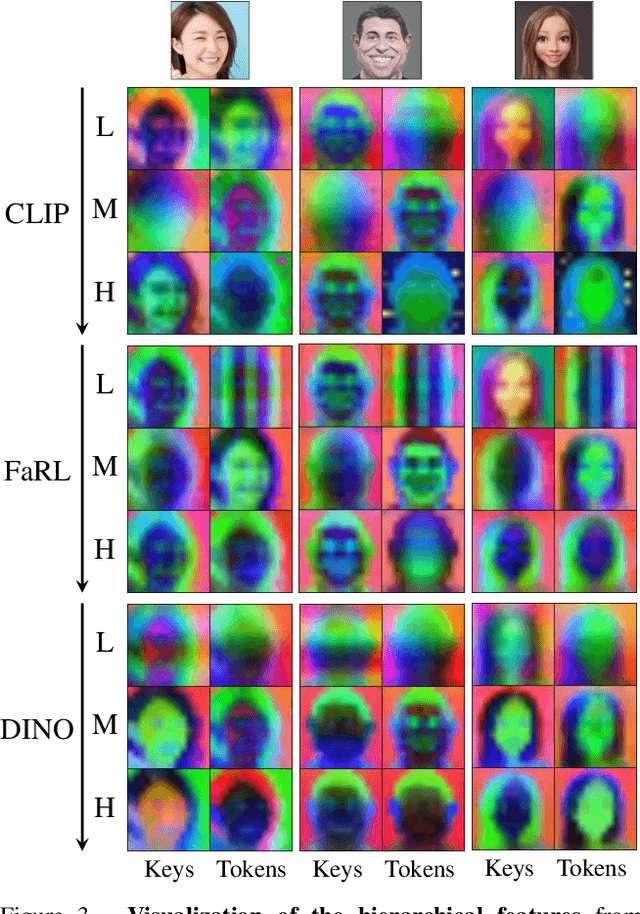
This paper addresses the complex issue of one-shot face stylization, focusing on the simultaneous consideration of appearance and structure, where previous methods have fallen short. We explore deformation-aware face stylization that diverges from traditional single-image style reference, opting for a real-style image pair instead. The cornerstone of our method is the utilization of a self-supervised vision transformer, specifically DINO-ViT, to establish a robust and consistent facial structure representation across both real and style domains. Our stylization process begins by adapting the StyleGAN generator to be deformation-aware through the integration of spatial transformers (STN). We then introduce two innovative constraints for generator fine-tuning under the guidance of DINO semantics: i) a directional deformation loss that regulates directional vectors in DINO space, and ii) a relative structural consistency constraint based on DINO token self-similarities, ensuring diverse generation. Additionally, style-mixing is employed to align the color generation with the reference, minimizing inconsistent correspondences. This framework delivers enhanced deformability for general one-shot face stylization, achieving notable efficiency with a fine-tuning duration of approximately 10 minutes. Extensive qualitative and quantitative comparisons demonstrate our superiority over state-of-the-art one-shot face stylization methods. Code is available at https://github.com/zichongc/DoesFS