 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Modelling of Facial Aging and Kinship: A Survey
Feb 13, 2018
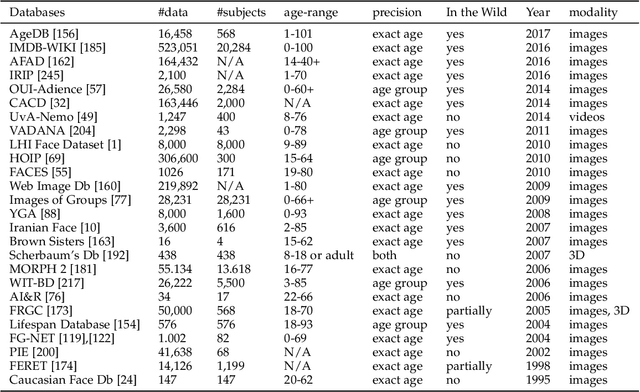


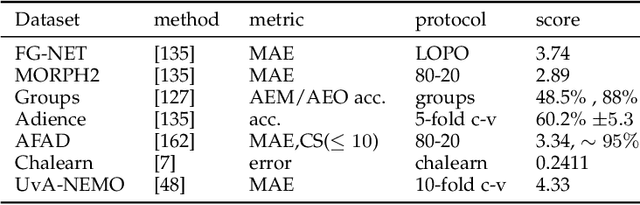
Computational facial models that capture properties of facial cues related to aging and kinship increasingly attract the attention of the research community, enabling the development of reliable methods for age progression, age estimation, age-invariant facial characterization, and kinship verification from visual data. In this paper, we review recent advances in modelling of facial aging and kinship. In particular, we provide an up-to date, complete list of available annotated datasets and an in-depth analysis of geometric, hand-crafted, and learned facial representations that are used for facial aging and kinship characterization. Moreover, evaluation protocols and metrics are reviewed and notable experimental results for each surveyed task are analyzed. This survey allows us to identify challenges and discuss future research directions for the development of robust facial models in real-world conditions.
Neuromuscular Control of the Face-Head-Neck Biomechanical Complex With Learning-Based Expression Transfer From Images and Videos
Nov 12, 2021

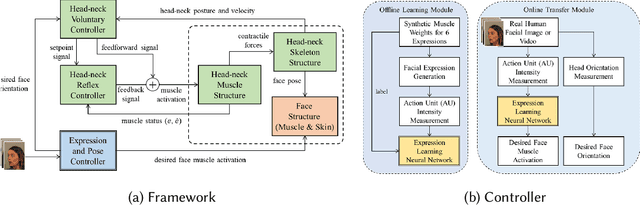

The transfer of facial expressions from people to 3D face models is a classic computer graphics problem. In this paper, we present a novel, learning-based approach to transferring facial expressions and head movements from images and videos to a biomechanical model of the face-head-neck complex. Leveraging the Facial Action Coding System (FACS) as an intermediate representation of the expression space, we train a deep neural network to take in FACS Action Units (AUs) and output suitable facial muscle and jaw activation signals for the musculoskeletal model. Through biomechanical simulation, the activations deform the facial soft tissues, thereby transferring the expression to the model. Our approach has advantages over previous approaches. First, the facial expressions are anatomically consistent as our biomechanical model emulates the relevant anatomy of the face, head, and neck. Second, by training the neural network using data generated from the biomechanical model itself, we eliminate the manual effort of data collection for expression transfer. The success of our approach is demonstrated through experiments involving the transfer onto our face-head-neck model of facial expressions and head poses from a range of facial images and videos.
Applied monocular reconstruction of parametric faces with domain engineering
Aug 05, 2022Many modern online 3D applications and videogames rely on parametric models of human faces for creating believable avatars. However, manual reproduction of someone's facial likeness with a parametric model is difficult and time-consuming. Machine Learning solution for that task is highly desirable but is also challenging. The paper proposes a novel approach to the so-called Face-to-Parameters problem (F2P for short), aiming to reconstruct a parametric face from a single image. The proposed method utilizes synthetic data, domain decomposition, and domain adaptation for addressing multifaceted challenges in solving the F2P. The open-sourced codebase illustrates our key observations and provides means for quantitative evaluation. The presented approach proves practical in an industrial application; it improves accuracy and allows for more efficient models training. The techniques have the potential to extend to other types of parametric models.
Unrestricted Black-box Adversarial Attack Using GAN with Limited Queries
Aug 24, 2022
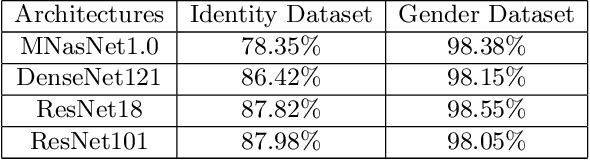
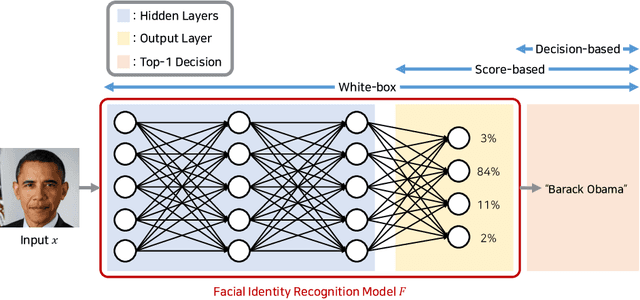
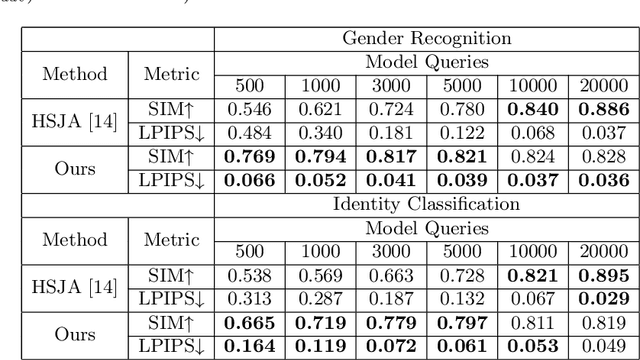
Adversarial examples are inputs intentionally generated for fooling a deep neural network. Recent studies have proposed unrestricted adversarial attacks that are not norm-constrained. However, the previous unrestricted attack methods still have limitations to fool real-world applications in a black-box setting. In this paper, we present a novel method for generating unrestricted adversarial examples using GAN where an attacker can only access the top-1 final decision of a classification model. Our method, Latent-HSJA, efficiently leverages the advantages of a decision-based attack in the latent space and successfully manipulates the latent vectors for fooling the classification model. With extensive experiments, we demonstrate that our proposed method is efficient in evaluating the robustness of classification models with limited queries in a black-box setting. First, we demonstrate that our targeted attack method is query-efficient to produce unrestricted adversarial examples for a facial identity recognition model that contains 307 identities. Then, we demonstrate that the proposed method can also successfully attack a real-world celebrity recognition service.
Capturing and Animation of Body and Clothing from Monocular Video
Oct 04, 2022
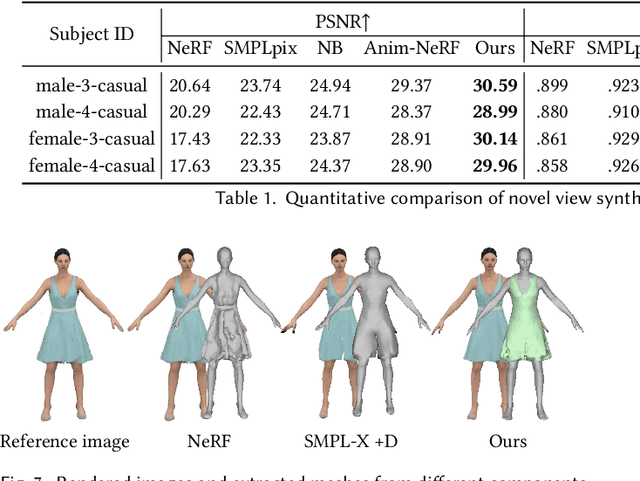
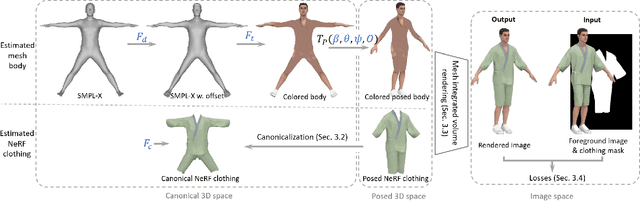
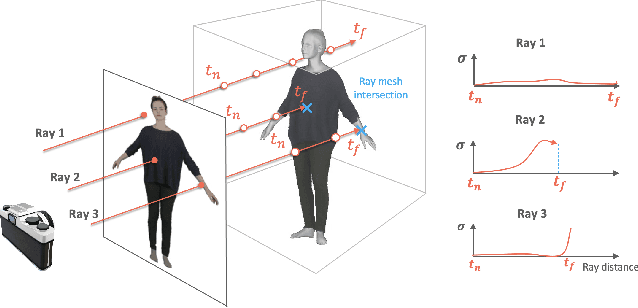
While recent work has shown progress on extracting clothed 3D human avatars from a single image, video, or a set of 3D scans, several limitations remain. Most methods use a holistic representation to jointly model the body and clothing, which means that the clothing and body cannot be separated for applications like virtual try-on. Other methods separately model the body and clothing, but they require training from a large set of 3D clothed human meshes obtained from 3D/4D scanners or physics simulations. Our insight is that the body and clothing have different modeling requirements. While the body is well represented by a mesh-based parametric 3D model, implicit representations and neural radiance fields are better suited to capturing the large variety in shape and appearance present in clothing. Building on this insight, we propose SCARF (Segmented Clothed Avatar Radiance Field), a hybrid model combining a mesh-based body with a neural radiance field. Integrating the mesh into the volumetric rendering in combination with a differentiable rasterizer enables us to optimize SCARF directly from monocular videos, without any 3D supervision. The hybrid modeling enables SCARF to (i) animate the clothed body avatar by changing body poses (including hand articulation and facial expressions), (ii) synthesize novel views of the avatar, and (iii) transfer clothing between avatars in virtual try-on applications. We demonstrate that SCARF reconstructs clothing with higher visual quality than existing methods, that the clothing deforms with changing body pose and body shape, and that clothing can be successfully transferred between avatars of different subjects. The code and models are available at https://github.com/YadiraF/SCARF.
Backdoor Attacks on Facial Recognition in the Physical World
Jun 25, 2020
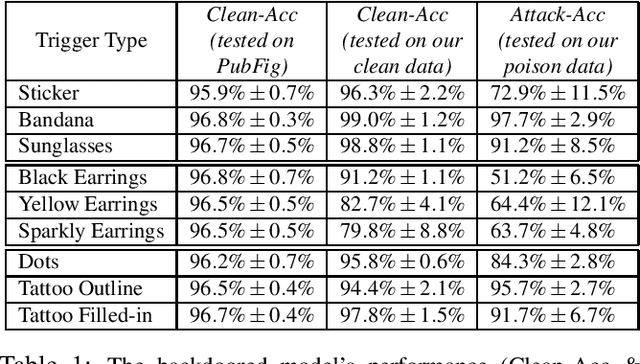

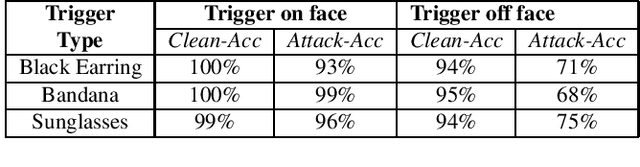
Backdoor attacks embed hidden malicious behaviors inside deep neural networks (DNNs) that are only activated when a specific "trigger" is present on some input to the model. A variety of these attacks have been successfully proposed and evaluated, generally using digitally generated patterns or images as triggers. Despite significant prior work on the topic, a key question remains unanswered: "can backdoor attacks be physically realized in the real world, and what limitations do attackers face in executing them?" In this paper, we present results of a detailed study on DNN backdoor attacks in the physical world, specifically focused on the task of facial recognition. We take 3205 photographs of 10 volunteers in a variety of settings and backgrounds and train a facial recognition model using transfer learning from VGGFace. We evaluate the effectiveness of 9 accessories as potential triggers, and analyze impact from external factors such as lighting and image quality. First, we find that triggers vary significantly in efficacy and a key factor is that facial recognition models are heavily tuned to features on the face and less so to features around the periphery. Second, the efficacy of most trigger objects is. negatively impacted by lower image quality but unaffected by lighting. Third, most triggers suffer from false positives, where non-trigger objects unintentionally activate the backdoor. Finally, we evaluate 4 backdoor defenses against physical backdoors. We show that they all perform poorly because physical triggers break key assumptions they made based on triggers in the digital domain. Our key takeaway is that implementing physical backdoors is much more challenging than described in literature for both attackers and defenders and much more work is necessary to understand how backdoors work in the real world.
DFEW: A Large-Scale Database for Recognizing Dynamic Facial Expressions in the Wild
Aug 13, 2020
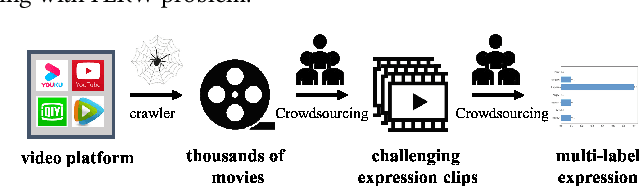

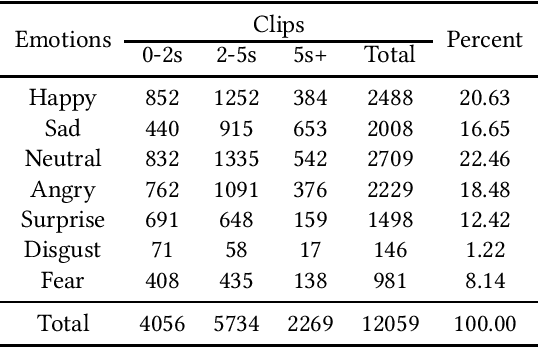
Recently, facial expression recognition (FER) in the wild has gained a lot of researchers' attention because it is a valuable topic to enable the FER techniques to move from the laboratory to the real applications. In this paper, we focus on this challenging but interesting topic and make contributions from three aspects. First, we present a new large-scale 'in-the-wild' dynamic facial expression database, DFEW (Dynamic Facial Expression in the Wild), consisting of over 16,000 video clips from thousands of movies. These video clips contain various challenging interferences in practical scenarios such as extreme illumination, occlusions, and capricious pose changes. Second, we propose a novel method called Expression-Clustered Spatiotemporal Feature Learning (EC-STFL) framework to deal with dynamic FER in the wild. Third, we conduct extensive benchmark experiments on DFEW using a lot of spatiotemporal deep feature learning methods as well as our proposed EC-STFL. Experimental results show that DFEW is a well-designed and challenging database, and the proposed EC-STFL can promisingly improve the performance of existing spatiotemporal deep neural networks in coping with the problem of dynamic FER in the wild. Our DFEW database is publicly available and can be freely downloaded from https://dfew-dataset.github.io/.
Facial Attributes: Accuracy and Adversarial Robustness
Apr 20, 2018
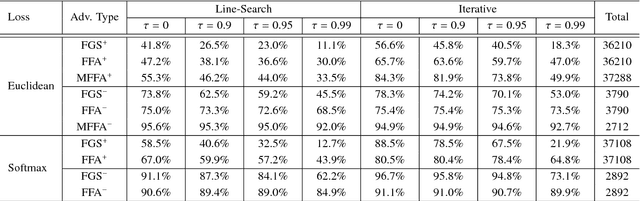
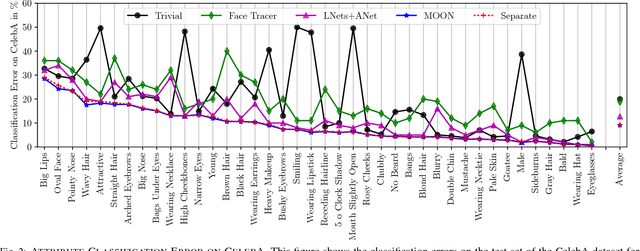
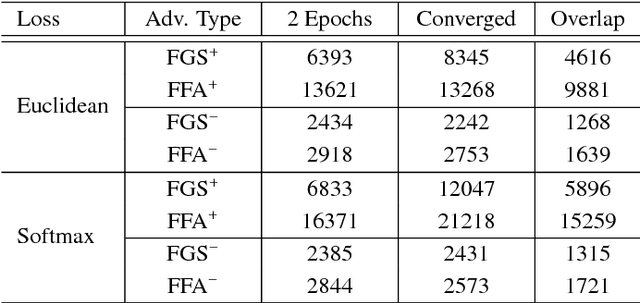
Facial attributes, emerging soft biometrics, must be automatically and reliably extracted from images in order to be usable in stand-alone systems. While recent methods extract facial attributes using deep neural networks (DNNs) trained on labeled facial attribute data, the robustness of deep attribute representations has not been evaluated. In this paper, we examine the representational stability of several approaches that recently advanced the state of the art on the CelebA benchmark by generating adversarial examples formed by adding small, non-random perturbations to inputs yielding altered classifications. We show that our fast flipping attribute (FFA) technique generates more adversarial examples than traditional algorithms, and that the adversarial robustness of DNNs varies highly between facial attributes. We also test the correlation of facial attributes and find that only for related attributes do the formed adversarial perturbations change the classification of others. Finally, we introduce the concept of natural adversarial samples, i.e., misclassified images where predictions can be corrected via small perturbations. We demonstrate that natural adversarial samples commonly occur and show that many of these images remain misclassified even with additional training epochs, even though their correct classification may require only a small adjustment to network parameters.
* arXiv admin note: text overlap with arXiv:1605.05411
Expression Conditional GAN for Facial Expression-to-Expression Translation
May 14, 2019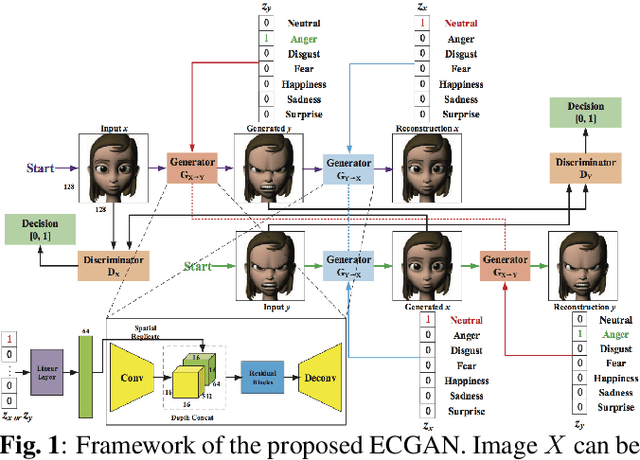

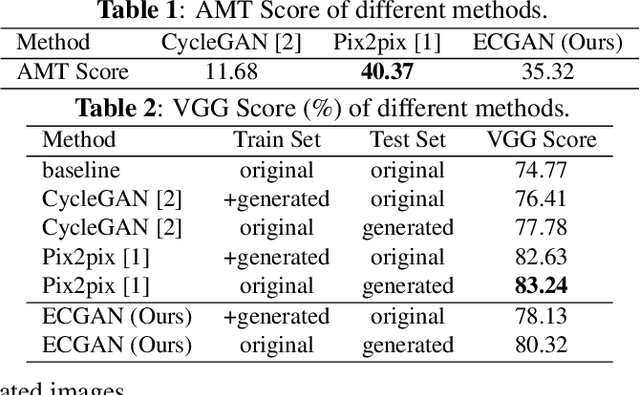

In this paper, we focus on the facial expression translation task and propose a novel Expression Conditional GAN (ECGAN) which can learn the mapping from one image domain to another one based on an additional expression attribute. The proposed ECGAN is a generic framework and is applicable to different expression generation tasks where specific facial expression can be easily controlled by the conditional attribute label. Besides, we introduce a novel face mask loss to reduce the influence of background changing. Moreover, we propose an entire framework for facial expression generation and recognition in the wild, which consists of two modules, i.e., generation and recognition. Finally, we evaluate our framework on several public face datasets in which the subjects have different races, illumination, occlusion, pose, color, content and background conditions. Even though these datasets are very diverse, both the qualitative and quantitative results demonstrate that our approach is able to generate facial expressions accurately and robustly.
AnchorFace: An Anchor-based Facial Landmark Detector Across Large Poses
Jul 07, 2020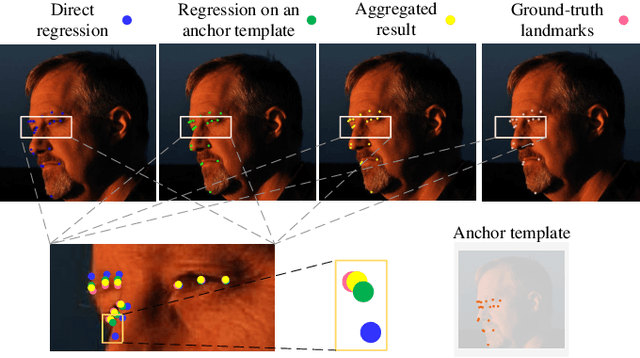

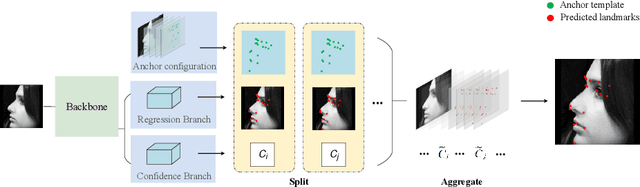
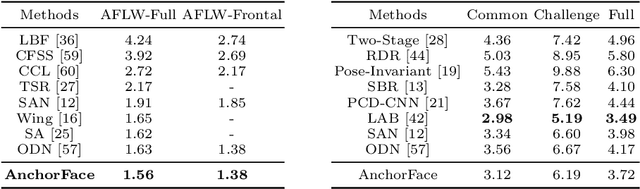
Facial landmark localization aims to detect the predefined points of human faces, and the topic has been rapidly improved with the recent development of neural network based methods. However, it remains a challenging task when dealing with faces in unconstrained scenarios, especially with large pose variations. In this paper, we target the problem of facial landmark localization across large poses and address this task based on a split-and-aggregate strategy. To split the search space, we propose a set of anchor templates as references for regression, which well addresses the large variations of face poses. Based on the prediction of each anchor template, we propose to aggregate the results, which can reduce the landmark uncertainty due to the large poses. Overall, our proposed approach, named AnchorFace, obtains state-of-the-art results with extremely efficient inference speed on four challenging benchmarks, i.e. AFLW, 300W, Menpo, and WFLW dataset. Code will be released for reproduction.