 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Fair Robust Active Learning by Joint Inconsistency
Sep 22, 2022
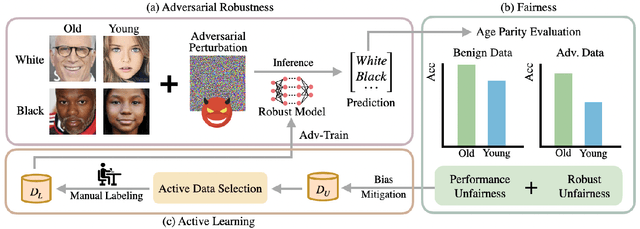
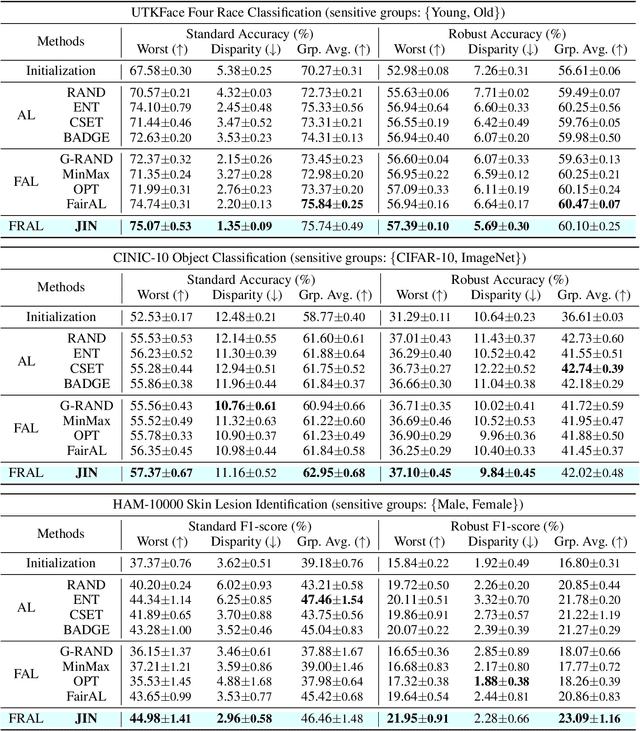
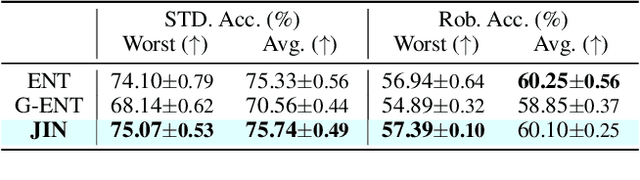
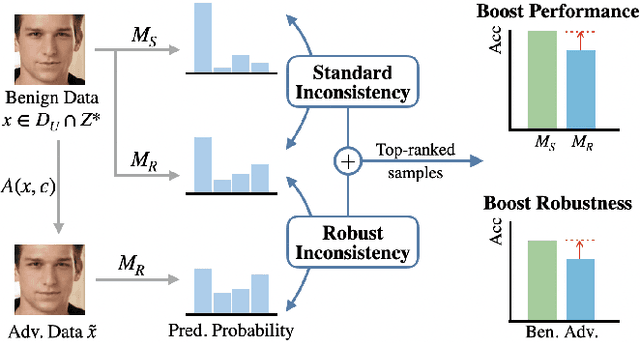
Fair Active Learning (FAL) utilized active learning techniques to achieve high model performance with limited data and to reach fairness between sensitive groups (e.g., genders). However, the impact of the adversarial attack, which is vital for various safety-critical machine learning applications, is not yet addressed in FAL. Observing this, we introduce a novel task, Fair Robust Active Learning (FRAL), integrating conventional FAL and adversarial robustness. FRAL requires ML models to leverage active learning techniques to jointly achieve equalized performance on benign data and equalized robustness against adversarial attacks between groups. In this new task, previous FAL methods generally face the problem of unbearable computational burden and ineffectiveness. Therefore, we develop a simple yet effective FRAL strategy by Joint INconsistency (JIN). To efficiently find samples that can boost the performance and robustness of disadvantaged groups for labeling, our method exploits the prediction inconsistency between benign and adversarial samples as well as between standard and robust models. Extensive experiments under diverse datasets and sensitive groups demonstrate that our method not only achieves fairer performance on benign samples but also obtains fairer robustness under white-box PGD attacks compared with existing active learning and FAL baselines. We are optimistic that FRAL would pave a new path for developing safe and robust ML research and applications such as facial attribute recognition in biometrics systems.
Micro-Facial Expression Recognition in Video Based on Optimal Convolutional Neural Network (MFEOCNN) Algorithm
Sep 29, 2020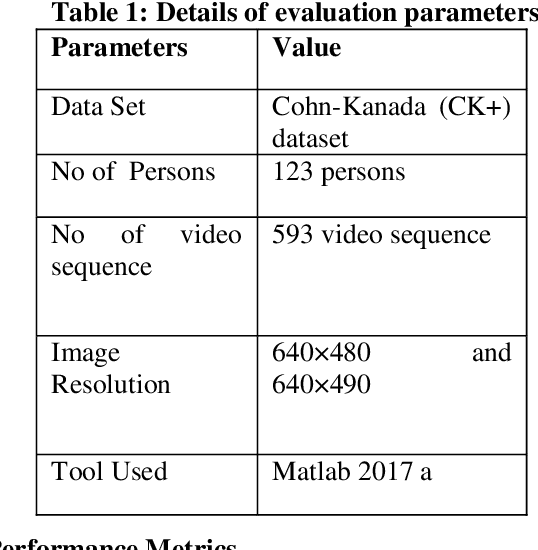
Facial expression is a standout amongst the most imperative features of human emotion recognition. For demonstrating the emotional states facial expressions are utilized by the people. In any case, recognition of facial expressions has persisted a testing and intriguing issue with regards to PC vision. Recognizing the Micro-Facial expression in video sequence is the main objective of the proposed approach. For efficient recognition, the proposed method utilizes the optimal convolution neural network. Here the proposed method considering the input dataset is the CK+ dataset. At first, by means of Adaptive median filtering preprocessing is performed in the input image. From the preprocessed output, the extracted features are Geometric features, Histogram of Oriented Gradients features and Local binary pattern features. The novelty of the proposed method is, with the help of Modified Lion Optimization (MLO) algorithm, the optimal features are selected from the extracted features. In a shorter computational time, it has the benefits of rapidly focalizing and effectively acknowledging with the aim of getting an overall arrangement or idea. Finally, the recognition is done by Convolution Neural network (CNN). Then the performance of the proposed MFEOCNN method is analysed in terms of false measures and recognition accuracy. This kind of emotion recognition is mainly used in medicine, marketing, E-learning, entertainment, law and monitoring. From the simulation, we know that the proposed approach achieves maximum recognition accuracy of 99.2% with minimum Mean Absolute Error (MAE) value. These results are compared with the existing for MicroFacial Expression Based Deep-Rooted Learning (MFEDRL), Convolutional Neural Network with Lion Optimization (CNN+LO) and Convolutional Neural Network (CNN) without optimization. The simulation of the proposed method is done in the working platform of MATLAB.
Self-Paced Deep Regression Forests for Facial Age Estimation
Oct 08, 2019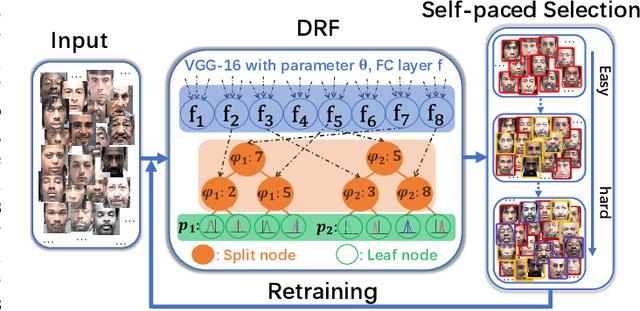

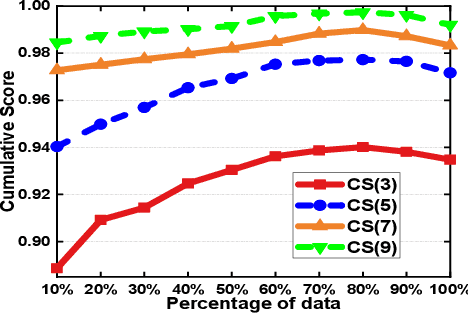
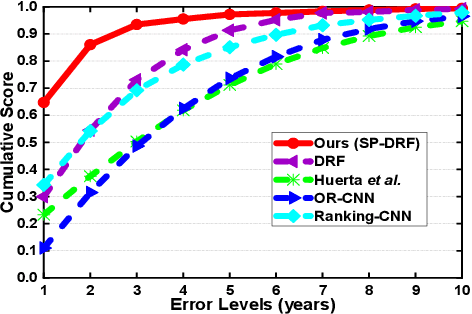
Facial age estimation is an important and challenging problem in computer vision. Existing approaches usually employ deep neural networks to fit the mapping from facial features to age directly, even though there exist some noisy and confusing samples. We argue that it is more desirable to distinguish noisy and confusing facial images from regular ones, and suppress the interference arising from them. To this end, we propose self-paced deep regression forests (SP-DRFs) -- a gradual learning DNNs framework for age estimation. As the model is learned gradually, from easy to hard, it tends to be significantly more robust with emphasizing more on reliable samples and avoiding bad local minima. We demonstrate the efficacy of SP-DRFs on Morph II and FG-NET datasets, where our method is shown to achieve state-of-the-art performance.
Facial Feature Tracking under Varying Facial Expressions and Face Poses based on Restricted Boltzmann Machines
Sep 18, 2017
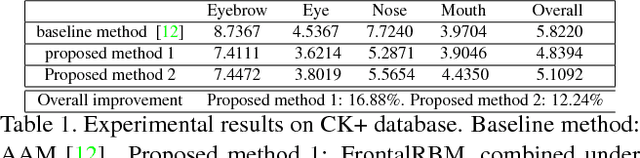
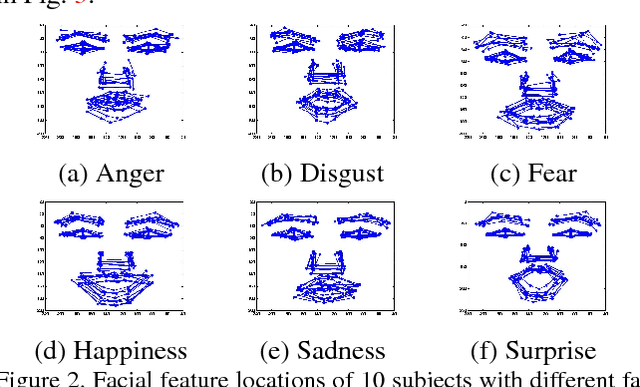
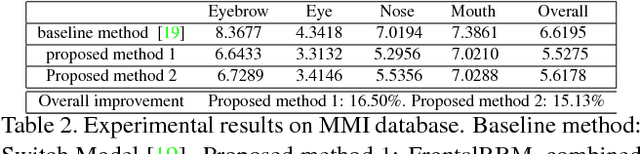
Facial feature tracking is an active area in computer vision due to its relevance to many applications. It is a nontrivial task, since faces may have varying facial expressions, poses or occlusions. In this paper, we address this problem by proposing a face shape prior model that is constructed based on the Restricted Boltzmann Machines (RBM) and their variants. Specifically, we first construct a model based on Deep Belief Networks to capture the face shape variations due to varying facial expressions for near-frontal view. To handle pose variations, the frontal face shape prior model is incorporated into a 3-way RBM model that could capture the relationship between frontal face shapes and non-frontal face shapes. Finally, we introduce methods to systematically combine the face shape prior models with image measurements of facial feature points. Experiments on benchmark databases show that with the proposed method, facial feature points can be tracked robustly and accurately even if faces have significant facial expressions and poses.
Self-Enhanced Convolutional Network for Facial Video Hallucination
Nov 23, 2019
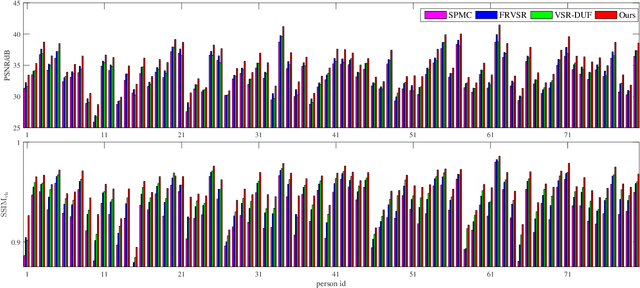
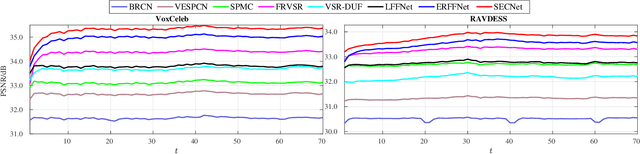
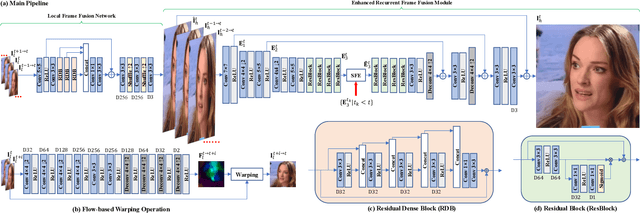
As a domain-specific super-resolution problem, facial image hallucination has enjoyed a series of breakthroughs thanks to the advances of deep convolutional neural networks. However, the direct migration of existing methods to video is still difficult to achieve good performance due to its lack of alignment and consistency modelling in temporal domain. Taking advantage of high inter-frame dependency in videos, we propose a self-enhanced convolutional network for facial video hallucination. It is implemented by making full usage of preceding super-resolved frames and a temporal window of adjacent low-resolution frames. Specifically, the algorithm first obtains the initial high-resolution inference of each frame by taking into consideration a sequence of consecutive low-resolution inputs through temporal consistency modelling. It further recurrently exploits the reconstructed results and intermediate features of a sequence of preceding frames to improve the initial super-resolution of the current frame by modelling the coherence of structural facial features across frames. Quantitative and qualitative evaluations demonstrate the superiority of the proposed algorithm against state-of-the-art methods. Moreover, our algorithm also achieves excellent performance in the task of general video super-resolution in a single-shot setting.
Time flies by: Analyzing the Impact of Face Ageing on the Recognition Performance with Synthetic Data
Aug 17, 2022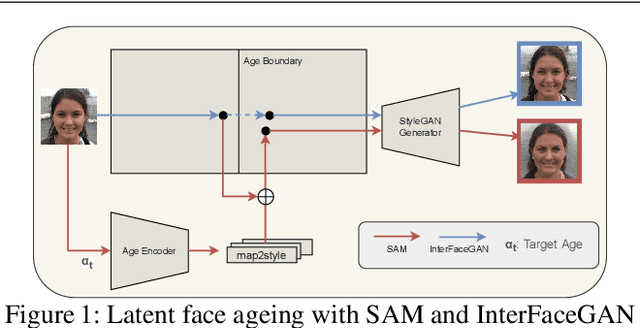
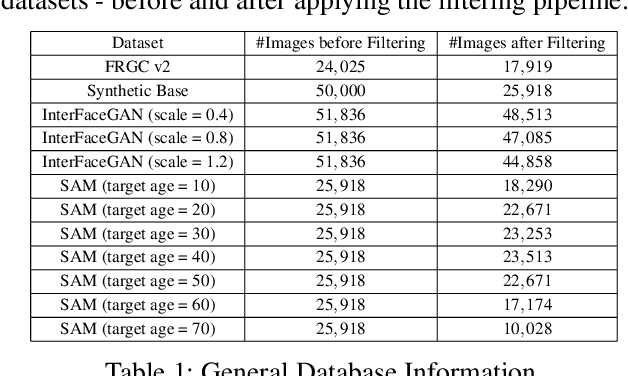
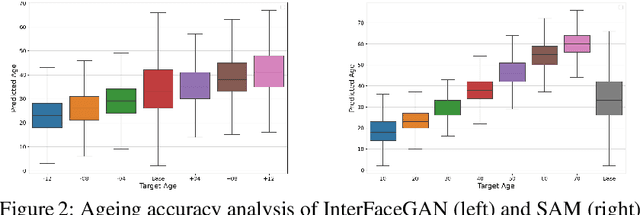
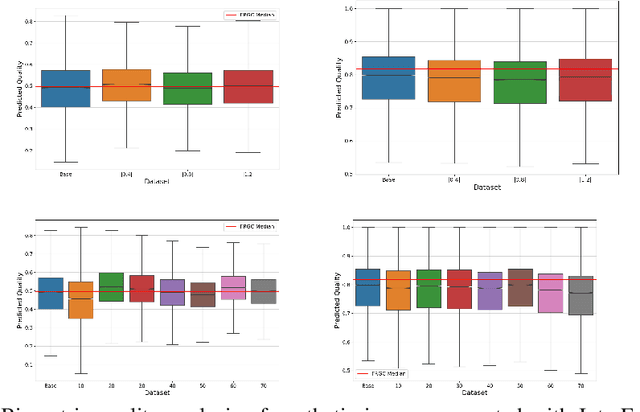
The vast progress in synthetic image synthesis enables the generation of facial images in high resolution and photorealism. In biometric applications, the main motivation for using synthetic data is to solve the shortage of publicly-available biometric data while reducing privacy risks when processing such sensitive information. These advantages are exploited in this work by simulating human face ageing with recent face age modification algorithms to generate mated samples, thereby studying the impact of ageing on the performance of an open-source biometric recognition system. Further, a real dataset is used to evaluate the effects of short-term ageing, comparing the biometric performance to the synthetic domain. The main findings indicate that short-term ageing in the range of 1-5 years has only minor effects on the general recognition performance. However, the correct verification of mated faces with long-term age differences beyond 20 years poses still a significant challenge and requires further investigation.
Dynamic Facial Expression Generation on Hilbert Hypersphere with Conditional Wasserstein Generative Adversarial Nets
Jul 23, 2019
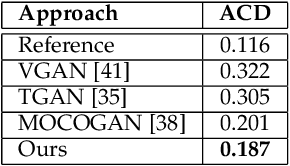
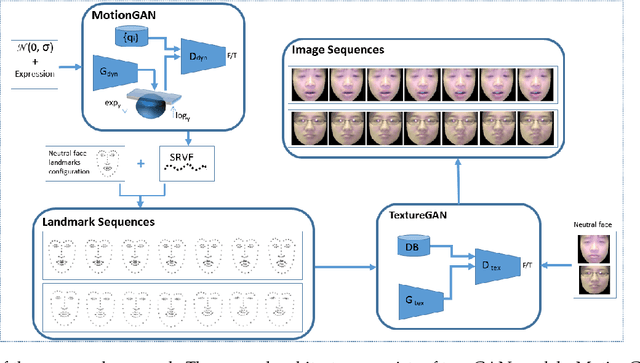
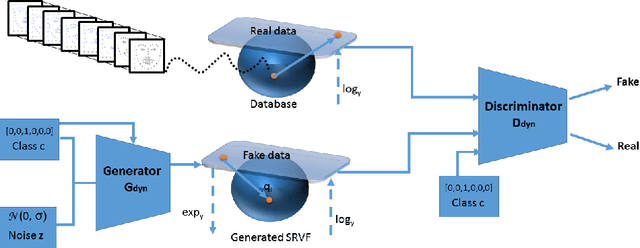
In this work, we propose a novel approach for generating videos of the six basic facial expressions given a neutral face image. We propose to exploit the face geometry by modeling the facial landmarks motion as curves encoded as points on a hypersphere. By proposing a conditional version of manifold-valued Wasserstein generative adversarial network (GAN) for motion generation on the hypersphere, we learn the distribution of facial expression dynamics of different classes, from which we synthesize new facial expression motions. The resulting motions can be transformed to sequences of landmarks and then to images sequences by editing the texture information using another conditional Generative Adversarial Network. To the best of our knowledge, this is the first work that explores manifold-valued representations with GAN to address the problem of dynamic facial expression generation. We evaluate our proposed approach both quantitatively and qualitatively on two public datasets; Oulu-CASIA and MUG Facial Expression. Our experimental results demonstrate the effectiveness of our approach in generating realistic videos with continuous motion, realistic appearance and identity preservation. We also show the efficiency of our framework for dynamic facial expressions generation, dynamic facial expression transfer and data augmentation for training improved emotion recognition models.
Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition
Nov 10, 2020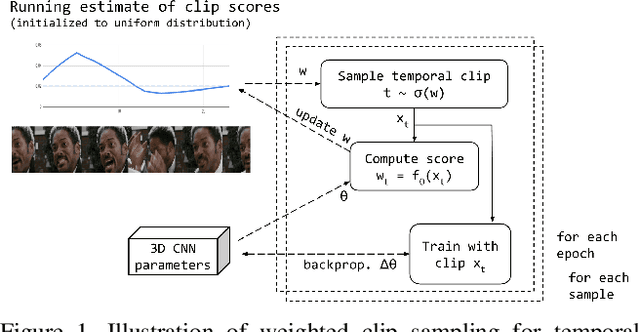
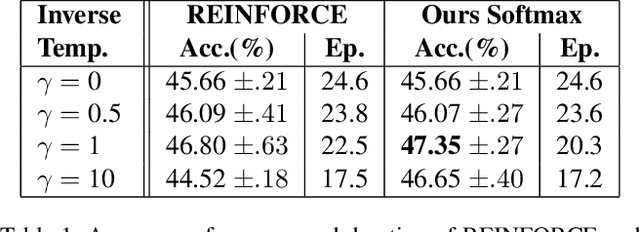
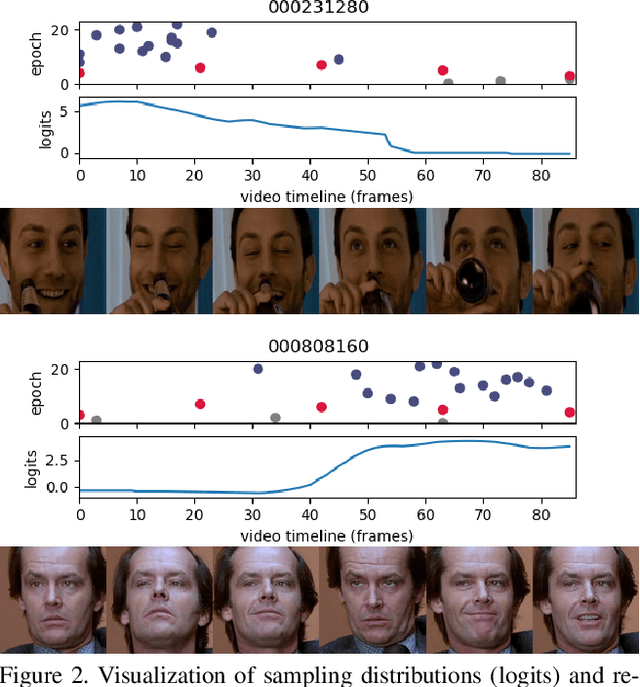
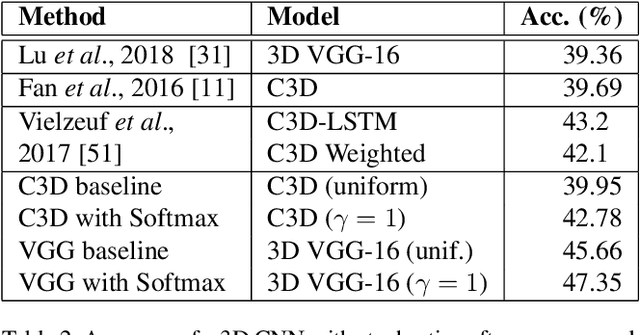
Training deep learning models for accurate spatiotemporal recognition of facial expressions in videos requires significant computational resources. For practical reasons, 3D Convolutional Neural Networks (3D CNNs) are usually trained with relatively short clips randomly extracted from videos. However, such uniform sampling is generally sub-optimal because equal importance is assigned to each temporal clip. In this paper, we present a strategy for efficient video-based training of 3D CNNs. It relies on softmax temporal pooling and a weighted sampling mechanism to select the most relevant training clips. The proposed softmax strategy provides several advantages: a reduced computational complexity due to efficient clip sampling, and an improved accuracy since temporal weighting focuses on more relevant clips during both training and inference. Experimental results obtained with the proposed method on several facial expression recognition benchmarks show the benefits of focusing on more informative clips in training videos. In particular, our approach improves performance and computational cost by reducing the impact of inaccurate trimming and coarse annotation of videos, and heterogeneous distribution of visual information across time.
Unifying Geometric Features and Facial Action Units for Improved Performance of Facial Expression Analysis
Jun 02, 2016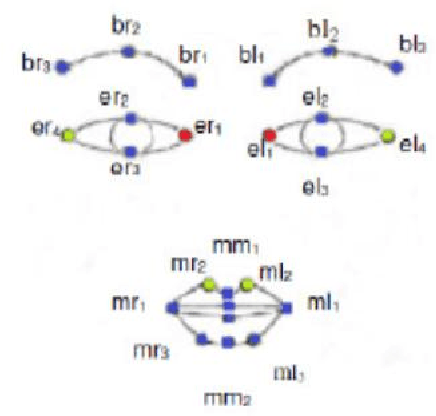
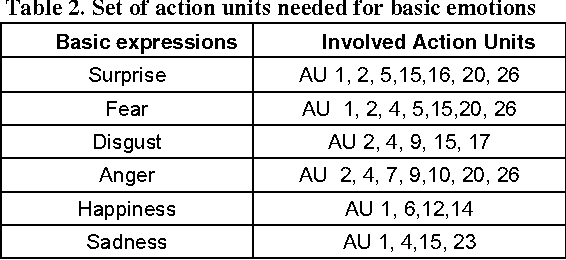
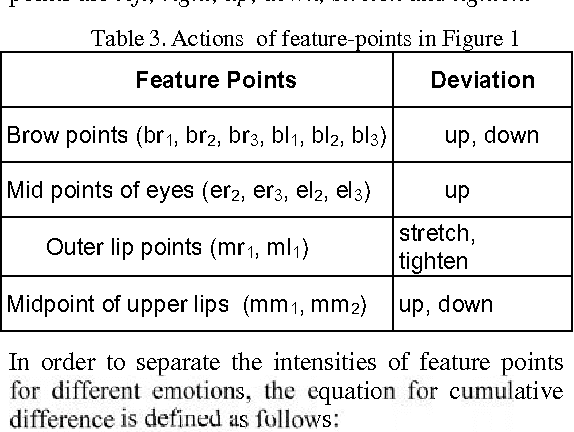
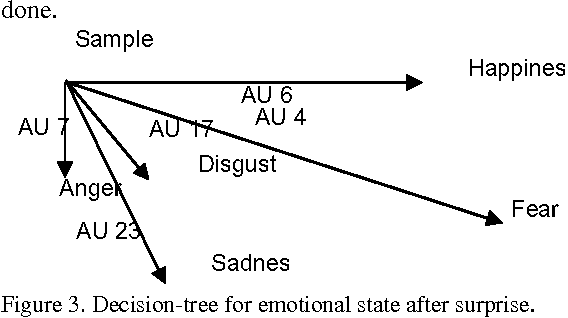
Previous approaches to model and analyze facial expression analysis use three different techniques: facial action units, geometric features and graph based modelling. However, previous approaches have treated these technique separately. There is an interrelationship between these techniques. The facial expression analysis is significantly improved by utilizing these mappings between major geometric features involved in facial expressions and the subset of facial action units whose presence or absence are unique to a facial expression. This paper combines dimension reduction techniques and image classification with search space pruning achieved by this unique subset of facial action units to significantly prune the search space. The performance results on the publicly facial expression database shows an improvement in performance by 70% over time while maintaining the emotion recognition correctness.
LFPS-Net: a lightweight fast pulse simulation network for BVP estimation
Jun 25, 2022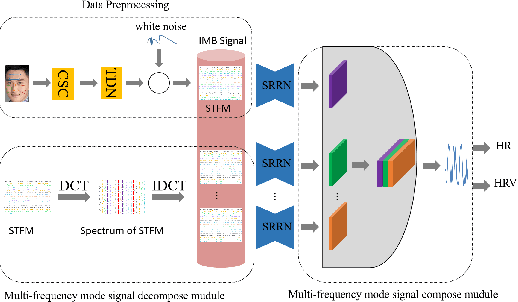
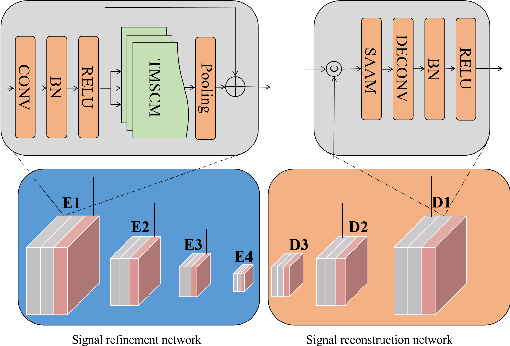

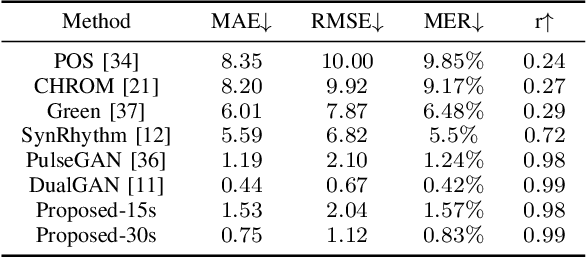
Heart rate estimation based on remote photoplethysmography plays an important role in several specific scenarios, such as health monitoring and fatigue detection. Existing well-established methods are committed to taking the average of the predicted HRs of multiple overlapping video clips as the final results for the 30-second facial video. Although these methods with hundreds of layers and thousands of channels are highly accurate and robust, they require enormous computational budget and a 30-second wait time, which greatly limits the application of the algorithms to scale. Under these cicumstacnces, We propose a lightweight fast pulse simulation network (LFPS-Net), pursuing the best accuracy within a very limited computational and time budget, focusing on common mobile platforms, such as smart phones. In order to suppress the noise component and get stable pulse in a short time, we design a multi-frequency modal signal fusion mechanism, which exploits the theory of time-frequency domain analysis to separate multi-modal information from complex signals. It helps proceeding network learn the effective fetures more easily without adding any parameter. In addition, we design a oversampling training strategy to solve the problem caused by the unbalanced distribution of dataset. For the 30-second facial videos, our proposed method achieves the best results on most of the evaluation metrics for estimating heart rate or heart rate variability compared to the best available papers. The proposed method can still obtain very competitive results by using a short-time (~15-second) facail video.