 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Do Deep Neural Networks Forget Facial Action Units? -- Exploring the Effects of Transfer Learning in Health Related Facial Expression Recognition
Apr 15, 2021
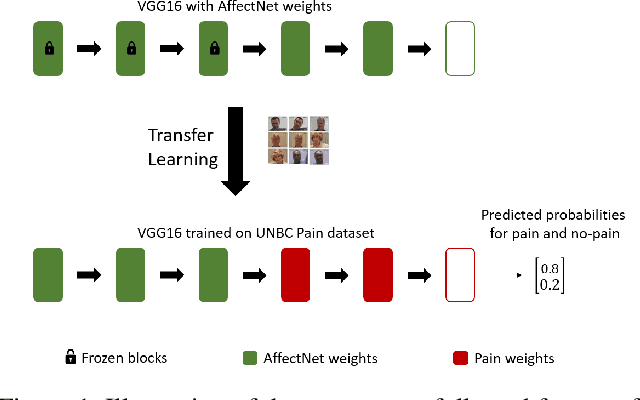
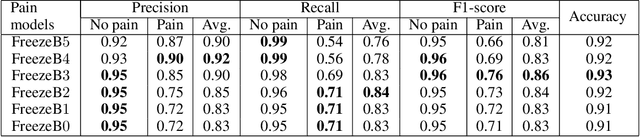
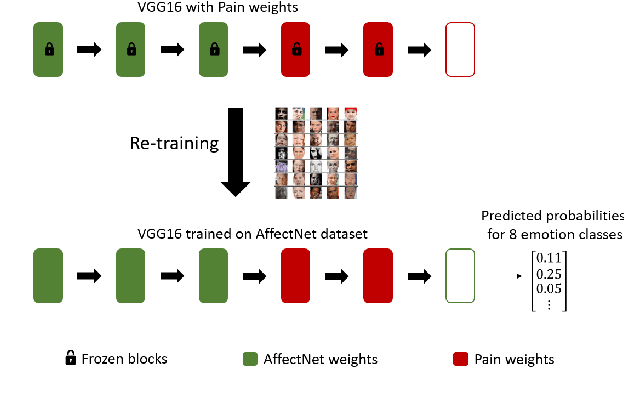

In this paper, we present a process to investigate the effects of transfer learning for automatic facial expression recognition from emotions to pain. To this end, we first train a VGG16 convolutional neural network to automatically discern between eight categorical emotions. We then fine-tune successively larger parts of this network to learn suitable representations for the task of automatic pain recognition. Subsequently, we apply those fine-tuned representations again to the original task of emotion recognition to further investigate the differences in performance between the models. In the second step, we use Layer-wise Relevance Propagation to analyze predictions of the model that have been predicted correctly previously but are now wrongly classified. Based on this analysis, we rely on the visual inspection of a human observer to generate hypotheses about what has been forgotten by the model. Finally, we test those hypotheses quantitatively utilizing concept embedding analysis methods. Our results show that the network, which was fully fine-tuned for pain recognition, indeed payed less attention to two action units that are relevant for expression recognition but not for pain recognition.
EMOCA: Emotion Driven Monocular Face Capture and Animation
Apr 24, 2022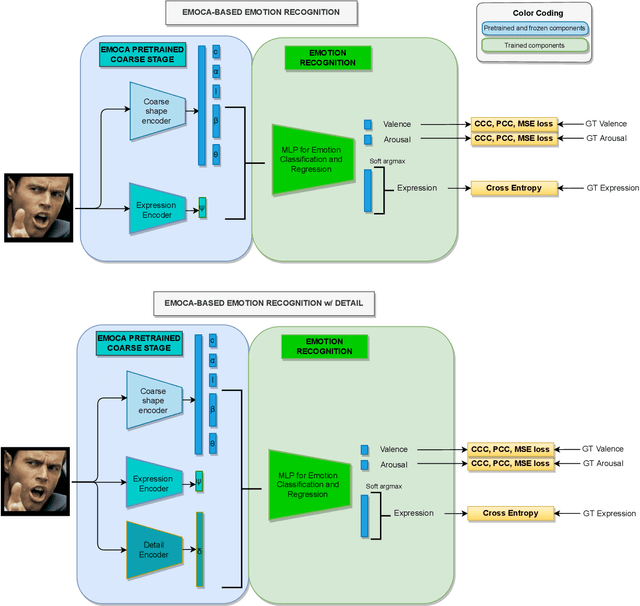
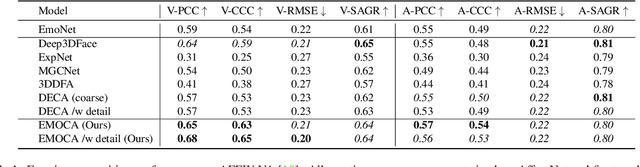
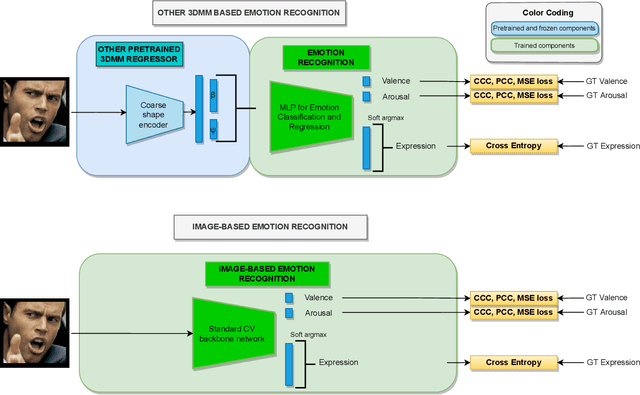
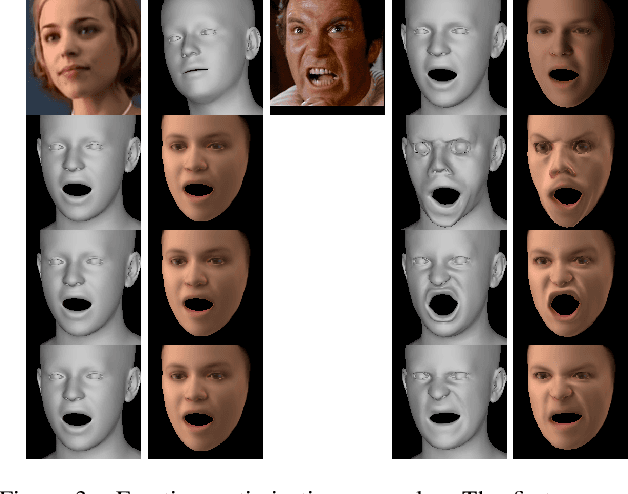
As 3D facial avatars become more widely used for communication, it is critical that they faithfully convey emotion. Unfortunately, the best recent methods that regress parametric 3D face models from monocular images are unable to capture the full spectrum of facial expression, such as subtle or extreme emotions. We find the standard reconstruction metrics used for training (landmark reprojection error, photometric error, and face recognition loss) are insufficient to capture high-fidelity expressions. The result is facial geometries that do not match the emotional content of the input image. We address this with EMOCA (EMOtion Capture and Animation), by introducing a novel deep perceptual emotion consistency loss during training, which helps ensure that the reconstructed 3D expression matches the expression depicted in the input image. While EMOCA achieves 3D reconstruction errors that are on par with the current best methods, it significantly outperforms them in terms of the quality of the reconstructed expression and the perceived emotional content. We also directly regress levels of valence and arousal and classify basic expressions from the estimated 3D face parameters. On the task of in-the-wild emotion recognition, our purely geometric approach is on par with the best image-based methods, highlighting the value of 3D geometry in analyzing human behavior. The model and code are publicly available at https://emoca.is.tue.mpg.de.
Real-Time Shape Tracking of Facial Landmarks
Jul 14, 2018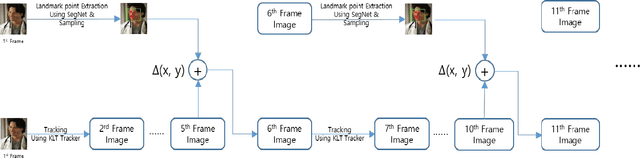
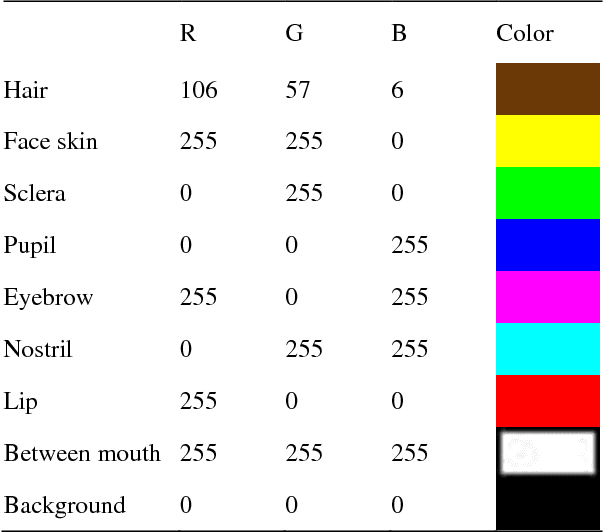
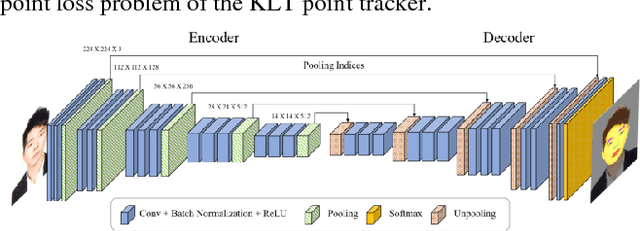
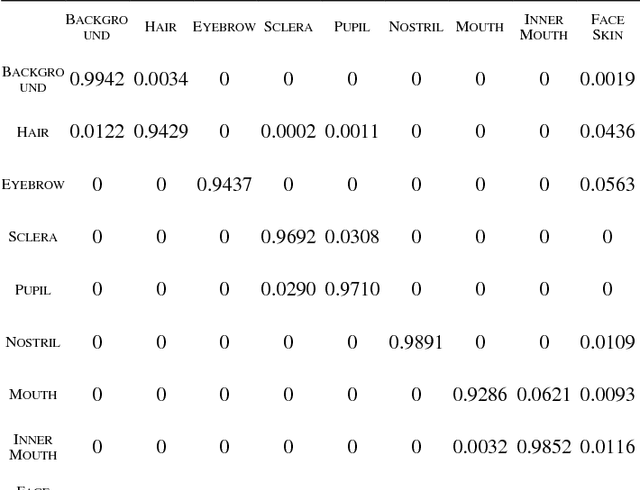
Detection of facial landmarks and accurate tracking of their shape are essential in real-time virtual makeup applications, where users can see the makeups effect by moving their face in different directions. Typical face tracking techniques detect diverse facial landmarks and track them using a point tracker such as the Kanade-Lucas-Tomasi (KLT) point tracker. Typically, 5 or 64 points are used for tracking a face. Even though these points are sufficient to track the approximate locations of facial landmarks, they are not sufficient to track the exact shape of facial landmarks. In this paper, we propose a method that can track the exact shape of facial landmarks in real-time by combining a deep learning technique and a point tracker. We detect facial landmarks accurately using SegNet, which performs semantic segmentation based on deep learning. Edge points of detected landmarks are tracked using the KLT point tracker. In spite of its popularity, the KLT point tracker suffers from the point loss problem. We solve this problem by executing SegNet periodically to calculate the shape of facial landmarks. That is, by combining the two techniques, we can avoid the computational overhead of SegNet for real-time shape tracking and the point loss problem of the KLT point tracker. We performed several experiments to evaluate the performance of our method and report some of the results herein.
Progressive Face Super-Resolution via Attention to Facial Landmark
Aug 22, 2019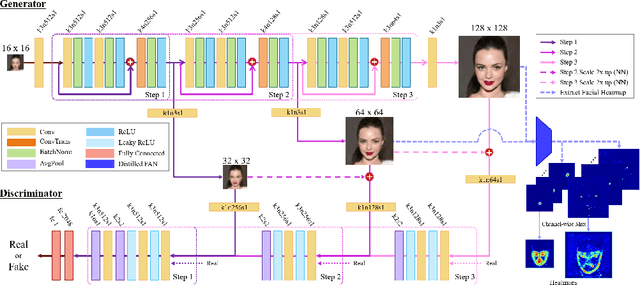

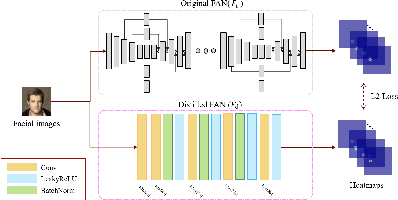
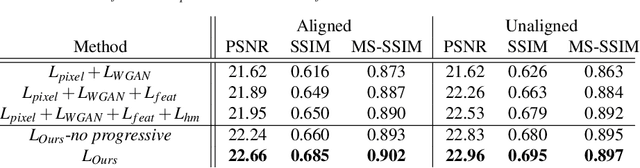
Face Super-Resolution (SR) is a subfield of the SR domain that specifically targets the reconstruction of face images. The main challenge of face SR is to restore essential facial features without distortion. We propose a novel face SR method that generates photo-realistic 8x super-resolved face images with fully retained facial details. To that end, we adopt a progressive training method, which allows stable training by splitting the network into successive steps, each producing output with a progressively higher resolution. We also propose a novel facial attention loss and apply it at each step to focus on restoring facial attributes in greater details by multiplying the pixel difference and heatmap values. Lastly, we propose a compressed version of the state-of-the-art face alignment network (FAN) for landmark heatmap extraction. With the proposed FAN, we can extract the heatmaps suitable for face SR and also reduce the overall training time. Experimental results verify that our method outperforms state-of-the-art methods in both qualitative and quantitative measurements, especially in perceptual quality.
Facial Behavior Analysis using 4D Curvature Statistics for Presentation Attack Detection
Oct 14, 2019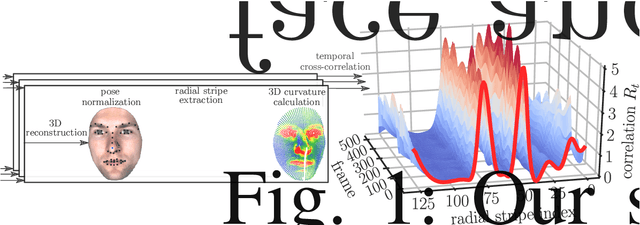


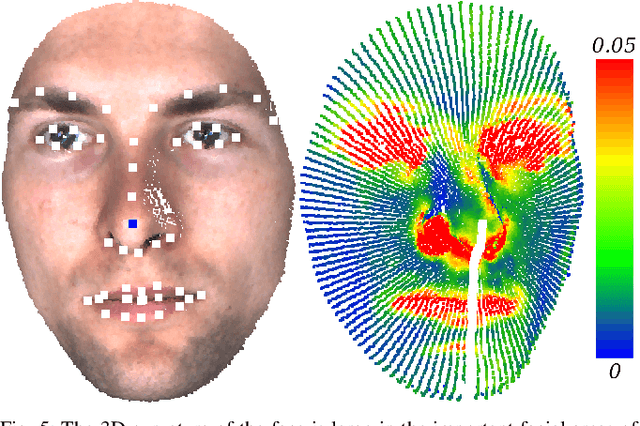
The uniqueness, complexity, and diversity of facial shapes and expressions led to success of facial biometric systems. Regardless of the accuracy of current facial recognition methods, most of them are vulnerable against the presentation of sophisticated masks. In the highly monitored application scenario at airports and banks, fraudsters probably do not wear masks. However, a deception will become more probable due to the increase of unsupervised authentication using kiosks, eGates and mobile phones in self-service. To robustly detect elastic 3D masks, one of the ultimate goals is to automatically analyze the plausibility of the facial behavior based on a sequence of 3D face scans. Most importantly, such a method would also detect all less advanced presentation attacks using static 3D masks, bent photographs with eyeholes, and replay attacks using monitors. Our proposed method achieves this goal by comparing the temporal curvature change between presentation attacks and genuine faces. For evaluation purposes, we recorded a challenging database containing replay attacks, static and elastic 3D masks using a high-quality 3D sensor. Based on the proposed representation, we found a clear separation between the low facial expressiveness of presentation attacks and the plausible behavior of genuine faces.
Coupled Learning for Facial Deblur
Apr 18, 2019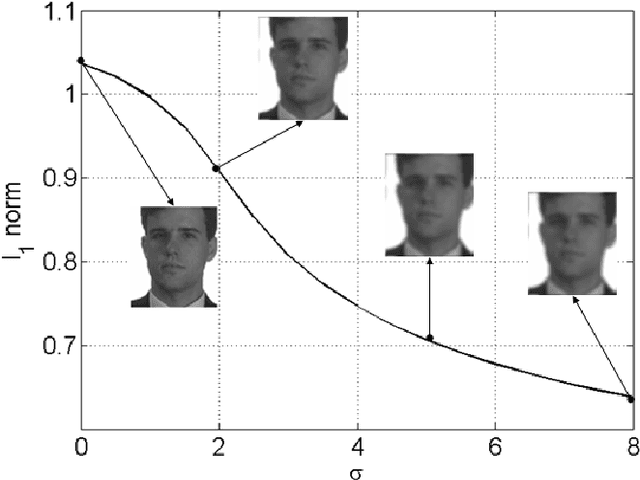


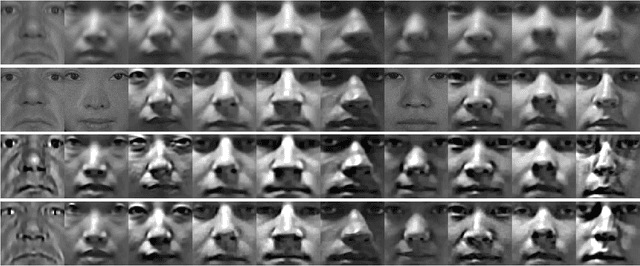
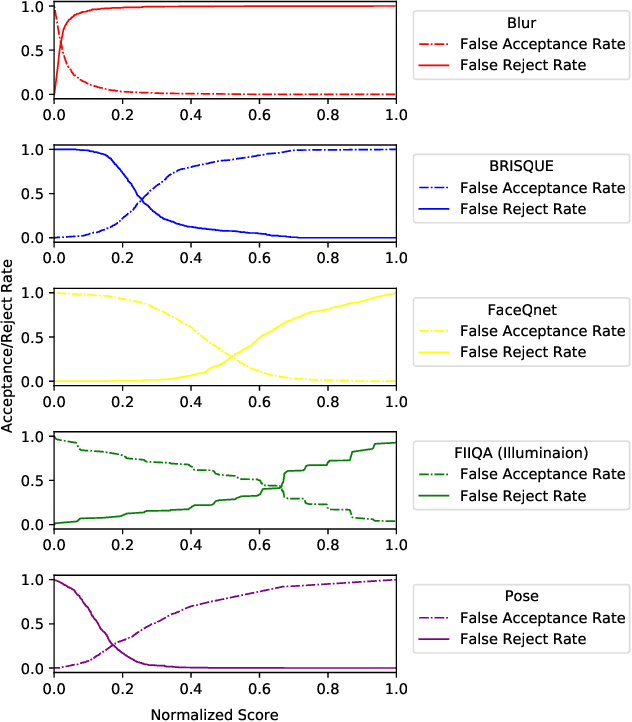
Blur in facial images significantly impedes the efficiency of recognition approaches. However, most existing blind deconvolution methods cannot generate satisfactory results due to their dependence on strong edges, which are sufficient in natural images but not in facial images. In this paper, we represent point spread functions (PSFs) by the linear combination of a set of pre-defined orthogonal PSFs, and similarly, an estimated intrinsic (EI) sharp face image is represented by the linear combination of a set of pre-defined orthogonal face images. In doing so, PSF and EI estimation is simplified to discovering two sets of linear combination coefficients, which are simultaneously found by our proposed coupled learning algorithm. To make our method robust to different types of blurry face images, we generate several candidate PSFs and EIs for a test image, and then, a non-blind deconvolution method is adopted to generate more EIs by those candidate PSFs. Finally, we deploy a blind image quality assessment metric to automatically select the optimal EI. Thorough experiments on the facial recognition technology database, extended Yale face database B, CMU pose, illumination, and expression (PIE) database, and face recognition grand challenge database version 2.0 demonstrate that the proposed approach effectively restores intrinsic sharp face images and, consequently, improves the performance of face recognition.
MorDeephy: Face Morphing Detection Via Fused Classification
Aug 05, 2022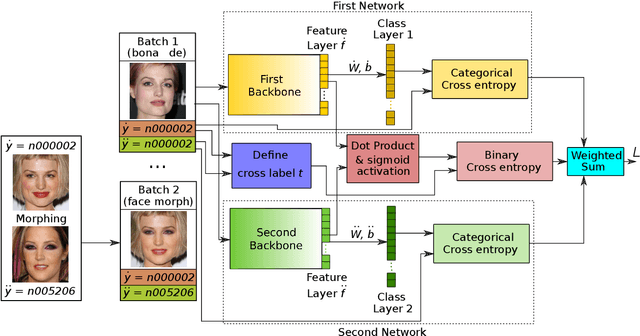
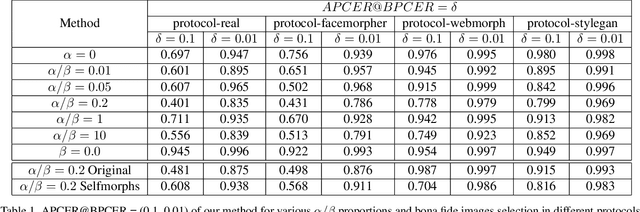
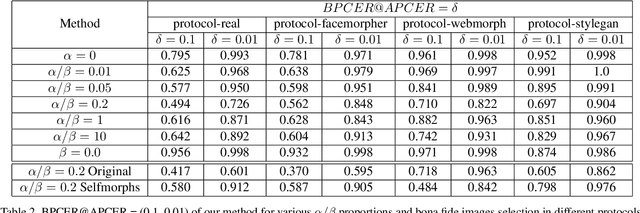
Face morphing attack detection (MAD) is one of the most challenging tasks in the field of face recognition nowadays. In this work, we introduce a novel deep learning strategy for a single image face morphing detection, which implies the discrimination of morphed face images along with a sophisticated face recognition task in a complex classification scheme. It is directed onto learning the deep facial features, which carry information about the authenticity of these features. Our work also introduces several additional contributions: the public and easy-to-use face morphing detection benchmark and the results of our wild datasets filtering strategy. Our method, which we call MorDeephy, achieved the state of the art performance and demonstrated a prominent ability for generalising the task of morphing detection to unseen scenarios.
VToonify: Controllable High-Resolution Portrait Video Style Transfer
Sep 23, 2022


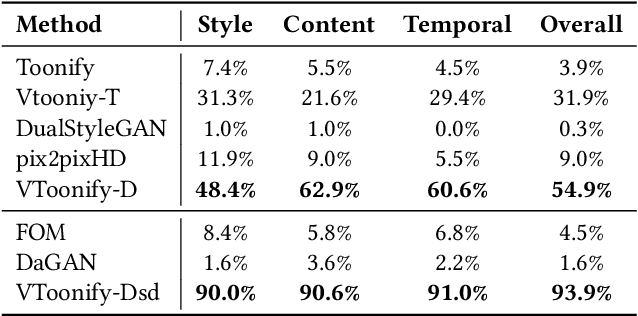
Generating high-quality artistic portrait videos is an important and desirable task in computer graphics and vision. Although a series of successful portrait image toonification models built upon the powerful StyleGAN have been proposed, these image-oriented methods have obvious limitations when applied to videos, such as the fixed frame size, the requirement of face alignment, missing non-facial details and temporal inconsistency. In this work, we investigate the challenging controllable high-resolution portrait video style transfer by introducing a novel VToonify framework. Specifically, VToonify leverages the mid- and high-resolution layers of StyleGAN to render high-quality artistic portraits based on the multi-scale content features extracted by an encoder to better preserve the frame details. The resulting fully convolutional architecture accepts non-aligned faces in videos of variable size as input, contributing to complete face regions with natural motions in the output. Our framework is compatible with existing StyleGAN-based image toonification models to extend them to video toonification, and inherits appealing features of these models for flexible style control on color and intensity. This work presents two instantiations of VToonify built upon Toonify and DualStyleGAN for collection-based and exemplar-based portrait video style transfer, respectively. Extensive experimental results demonstrate the effectiveness of our proposed VToonify framework over existing methods in generating high-quality and temporally-coherent artistic portrait videos with flexible style controls.
Fast Facial Landmark Detection and Applications: A Survey
Jan 12, 2021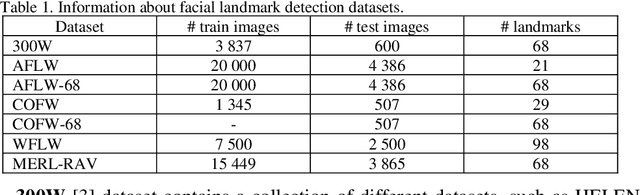
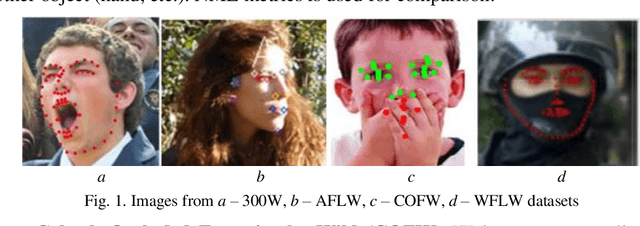
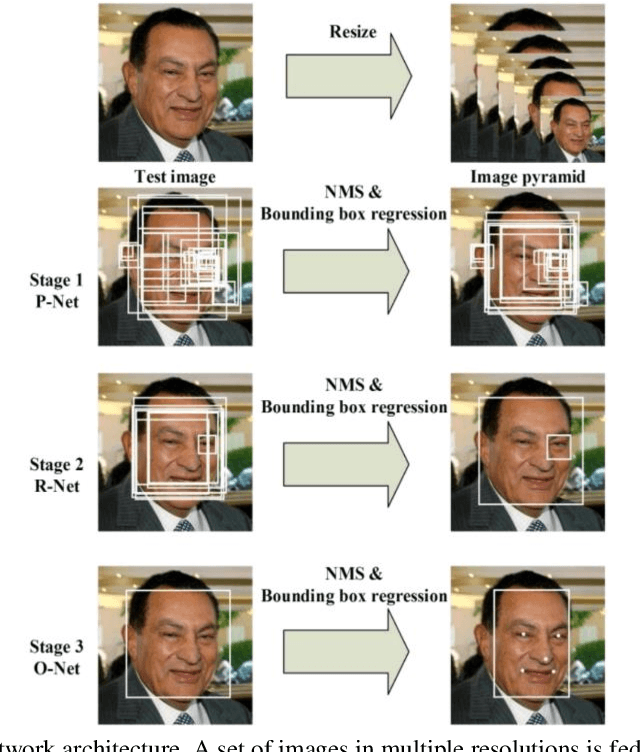
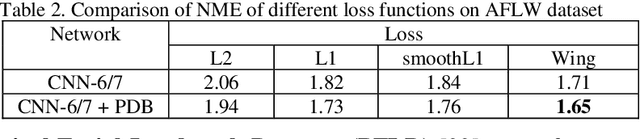
In this paper we survey and analyze modern neural-network-based facial landmark detection algorithms. We focus on approaches that have led to a significant increase in quality over the past few years on datasets with large pose and emotion variability, high levels of face occlusions - all of which are typical in real-world scenarios. We summarize the improvements into categories, provide quality comparison on difficult and modern in-the-wild datasets: 300-W, AFLW, WFLW, COFW. Additionally, we compare algorithm speed on CPU, GPU and Mobile devices. For completeness, we also briefly touch on established methods with open implementations available. Besides, we cover applications and vulnerabilities of the landmark detection algorithms. Based on which, we raise problems that as we hope will lead to further algorithm improvements in future.
DefakeHop++: An Enhanced Lightweight Deepfake Detector
Apr 30, 2022
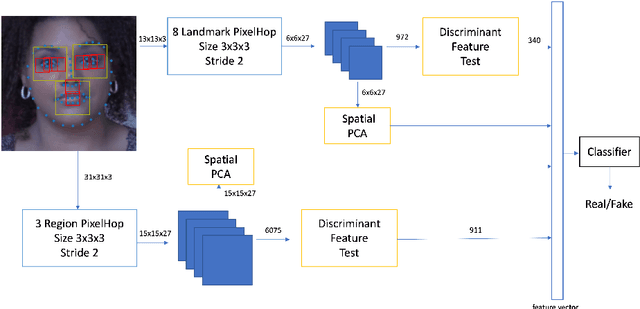
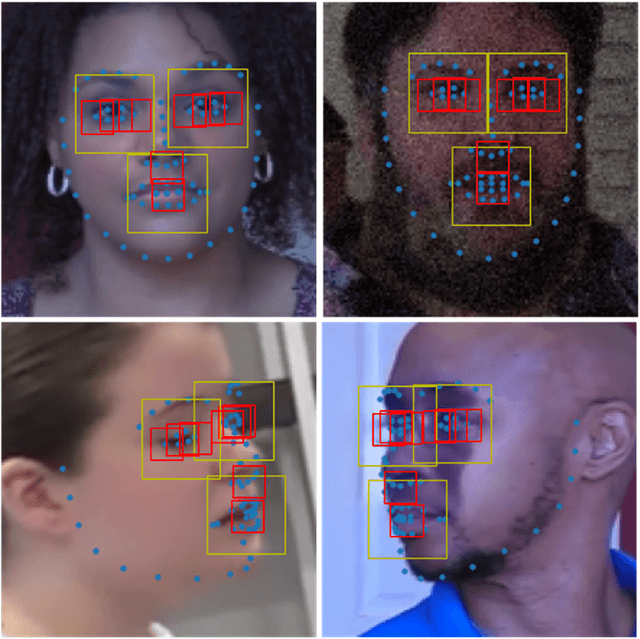
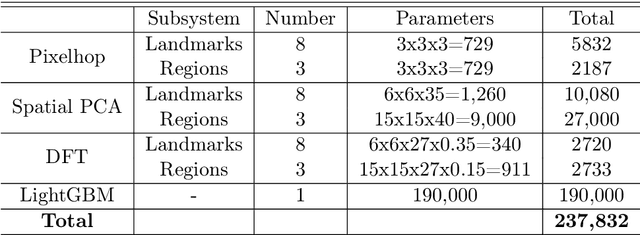
On the basis of DefakeHop, an enhanced lightweight Deepfake detector called DefakeHop++ is proposed in this work. The improvements lie in two areas. First, DefakeHop examines three facial regions (i.e., two eyes and mouth) while DefakeHop++ includes eight more landmarks for broader coverage. Second, for discriminant features selection, DefakeHop uses an unsupervised approach while DefakeHop++ adopts a more effective approach with supervision, called the Discriminant Feature Test (DFT). In DefakeHop++, rich spatial and spectral features are first derived from facial regions and landmarks automatically. Then, DFT is used to select a subset of discriminant features for classifier training. As compared with MobileNet v3 (a lightweight CNN model of 1.5M parameters targeting at mobile applications), DefakeHop++ has a model of 238K parameters, which is 16% of MobileNet v3. Furthermore, DefakeHop++ outperforms MobileNet v3 in Deepfake image detection performance in a weakly-supervised setting.