 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Generating Thermal Image Data Samples using 3D Facial Modelling Techniques and Deep Learning Methodologies
May 07, 2020




Methods for generating synthetic data have become of increasing importance to build large datasets required for Convolution Neural Networks (CNN) based deep learning techniques for a wide range of computer vision applications. In this work, we extend existing methodologies to show how 2D thermal facial data can be mapped to provide 3D facial models. For the proposed research work we have used tufts datasets for generating 3D varying face poses by using a single frontal face pose. The system works by refining the existing image quality by performing fusion based image preprocessing operations. The refined outputs have better contrast adjustments, decreased noise level and higher exposedness of the dark regions. It makes the facial landmarks and temperature patterns on the human face more discernible and visible when compared to original raw data. Different image quality metrics are used to compare the refined version of images with original images. In the next phase of the proposed study, the refined version of images is used to create 3D facial geometry structures by using Convolution Neural Networks (CNN). The generated outputs are then imported in blender software to finally extract the 3D thermal facial outputs of both males and females. The same technique is also used on our thermal face data acquired using prototype thermal camera (developed under Heliaus EU project) in an indoor lab environment which is then used for generating synthetic 3D face data along with varying yaw face angles and lastly facial depth map is generated.
ACR Loss: Adaptive Coordinate-based Regression Loss for Face Alignment
Mar 29, 2022


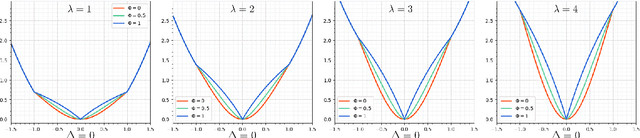
Although deep neural networks have achieved reasonable accuracy in solving face alignment, it is still a challenging task, specifically when we deal with facial images, under occlusion, or extreme head poses. Heatmap-based Regression (HBR) and Coordinate-based Regression (CBR) are among the two mainly used methods for face alignment. CBR methods require less computer memory, though their performance is less than HBR methods. In this paper, we propose an Adaptive Coordinate-based Regression (ACR) loss to improve the accuracy of CBR for face alignment. Inspired by the Active Shape Model (ASM), we generate Smooth-Face objects, a set of facial landmark points with less variations compared to the ground truth landmark points. We then introduce a method to estimate the level of difficulty in predicting each landmark point for the network by comparing the distribution of the ground truth landmark points and the corresponding Smooth-Face objects. Our proposed ACR Loss can adaptively modify its curvature and the influence of the loss based on the difficulty level of predicting each landmark point in a face. Accordingly, the ACR Loss guides the network toward challenging points than easier points, which improves the accuracy of the face alignment task. Our extensive evaluation shows the capabilities of the proposed ACR Loss in predicting facial landmark points in various facial images.
Real-time Simultaneous 3D Head Modeling and Facial Motion Capture with an RGB-D camera
Apr 22, 2020
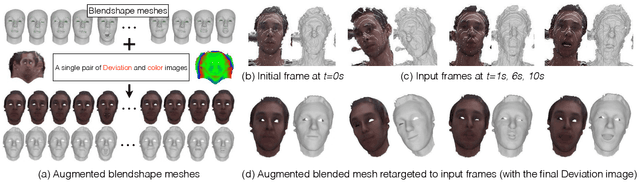
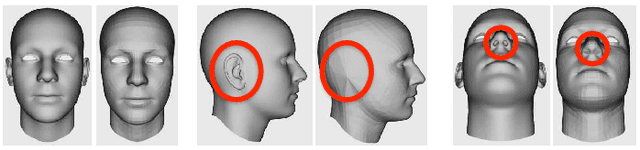

We propose a method to build in real-time animated 3D head models using a consumer-grade RGB-D camera. Our proposed method is the first one to provide simultaneously comprehensive facial motion tracking and a detailed 3D model of the user's head. Anyone's head can be instantly reconstructed and his facial motion captured without requiring any training or pre-scanning. The user starts facing the camera with a neutral expression in the first frame, but is free to move, talk and change his face expression as he wills otherwise. The facial motion is captured using a blendshape animation model while geometric details are captured using a Deviation image mapped over the template mesh. We contribute with an efficient algorithm to grow and refine the deforming 3D model of the head on-the-fly and in real-time. We demonstrate robust and high-fidelity simultaneous facial motion capture and 3D head modeling results on a wide range of subjects with various head poses and facial expressions.
Video2StyleGAN: Disentangling Local and Global Variations in a Video
May 30, 2022
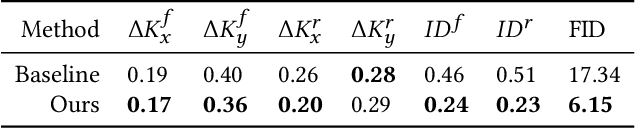
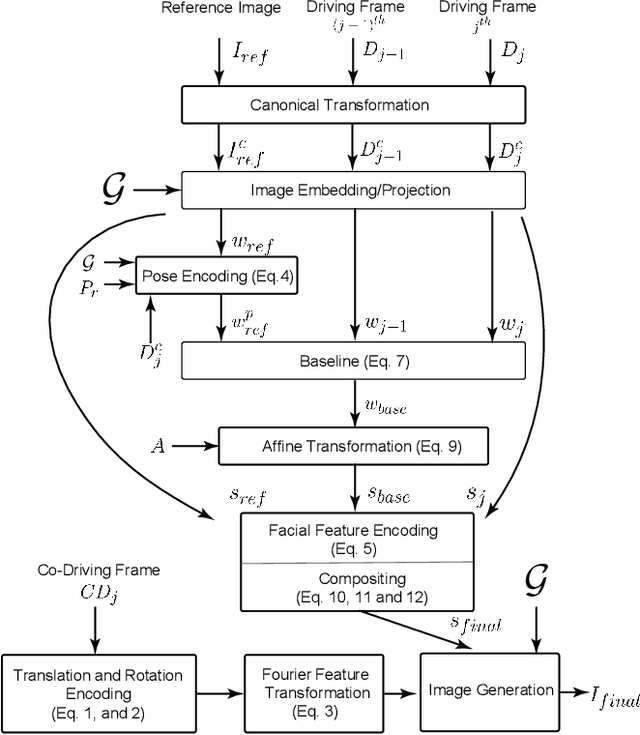

Image editing using a pretrained StyleGAN generator has emerged as a powerful paradigm for facial editing, providing disentangled controls over age, expression, illumination, etc. However, the approach cannot be directly adopted for video manipulations. We hypothesize that the main missing ingredient is the lack of fine-grained and disentangled control over face location, face pose, and local facial expressions. In this work, we demonstrate that such a fine-grained control is indeed achievable using pretrained StyleGAN by working across multiple (latent) spaces (namely, the positional space, the W+ space, and the S space) and combining the optimization results across the multiple spaces. Building on this enabling component, we introduce Video2StyleGAN that takes a target image and driving video(s) to reenact the local and global locations and expressions from the driving video in the identity of the target image. We evaluate the effectiveness of our method over multiple challenging scenarios and demonstrate clear improvements over alternative approaches.
Visual Detection of Diver Attentiveness for Underwater Human-Robot Interaction
Sep 28, 2022
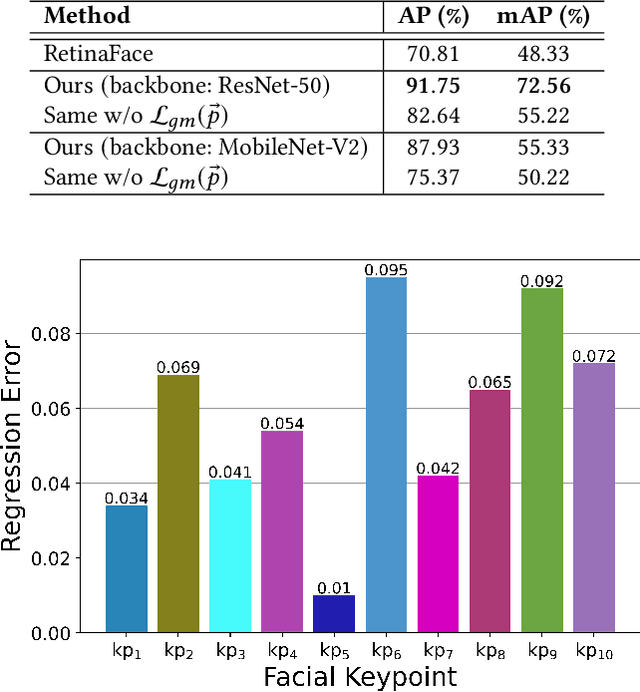


Many underwater tasks, such as cable-and-wreckage inspection, search-and-rescue, benefit from robust human-robot interaction (HRI) capabilities. With the recent advancements in vision-based underwater HRI methods, autonomous underwater vehicles (AUVs) can communicate with their human partners even during a mission. However, these interactions usually require active participation especially from humans (e.g., one must keep looking at the robot during an interaction). Therefore, an AUV must know when to start interacting with a human partner, i.e., if the human is paying attention to the AUV or not. In this paper, we present a diver attention estimation framework for AUVs to autonomously detect the attentiveness of a diver and then navigate and reorient itself, if required, with respect to the diver to initiate an interaction. The core element of the framework is a deep neural network (called DATT-Net) which exploits the geometric relation among 10 facial keypoints of the divers to determine their head orientation. Our on-the-bench experimental evaluations (using unseen data) demonstrate that the proposed DATT-Net architecture can determine the attentiveness of human divers with promising accuracy. Our real-world experiments also confirm the efficacy of DATT-Net which enables real-time inference and allows the AUV to position itself for an AUV-diver interaction.
Distilling Facial Knowledge With Teacher-Tasks: Semantic-Segmentation-Features For Pose-Invariant Face-Recognition
Sep 02, 2022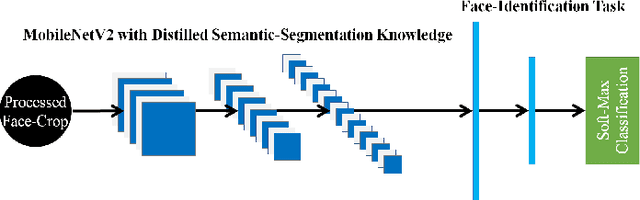
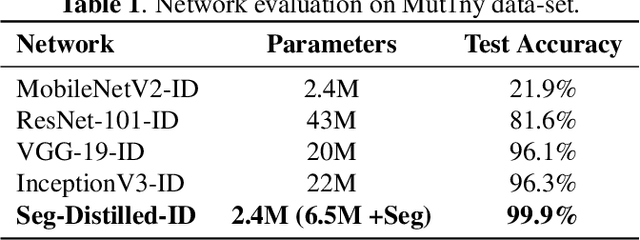
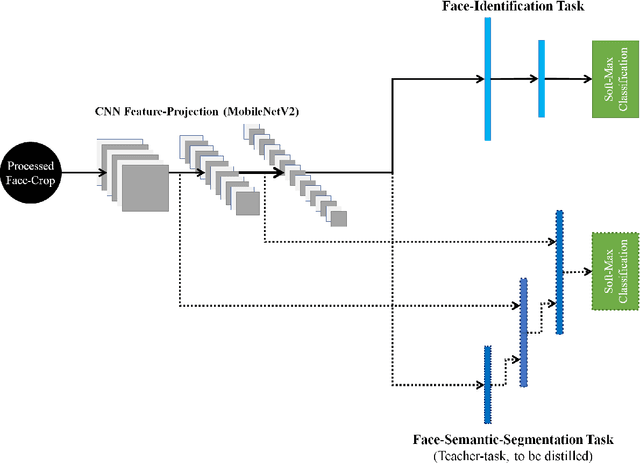

This paper demonstrates a novel approach to improve face-recognition pose-invariance using semantic-segmentation features. The proposed Seg-Distilled-ID network jointly learns identification and semantic-segmentation tasks, where the segmentation task is then "distilled" (MobileNet encoder). Performance is benchmarked against three state-of-the-art encoders on a publicly available data-set emphasizing head-pose variations. Experimental evaluations show the Seg-Distilled-ID network shows notable robustness benefits, achieving 99.9% test-accuracy in comparison to 81.6% on ResNet-101, 96.1% on VGG-19 and 96.3% on InceptionV3. This is achieved using approximately one-tenth of the top encoder's inference parameters. These results demonstrate distilling semantic-segmentation features can efficiently address face-recognition pose-invariance.
Multimodal Prediction of Spontaneous Humour: A Novel Dataset and First Results
Sep 28, 2022
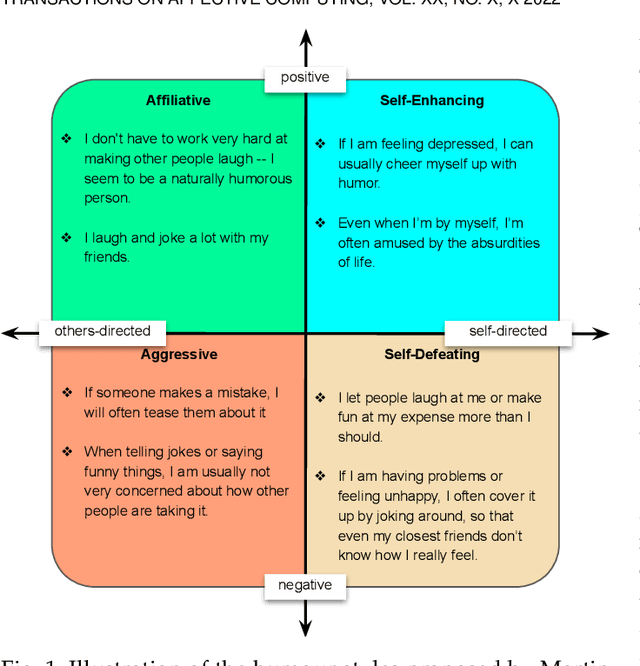
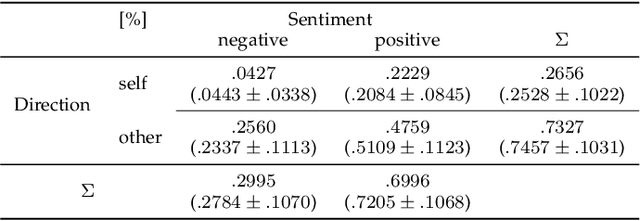
Humour is a substantial element of human affect and cognition. Its automatic understanding can facilitate a more naturalistic human-device interaction and the humanisation of artificial intelligence. Current methods of humour detection are solely based on staged data making them inadequate for 'real-world' applications. We address this deficiency by introducing the novel Passau-Spontaneous Football Coach Humour (Passau-SFCH) dataset, comprising of about 11 hours of recordings. The Passau-SFCH dataset is annotated for the presence of humour and its dimensions (sentiment and direction) as proposed in Martin's Humor Style Questionnaire. We conduct a series of experiments, employing pretrained Transformers, convolutional neural networks, and expert-designed features. The performance of each modality (text, audio, video) for spontaneous humour recognition is analysed and their complementarity is investigated. Our findings suggest that for the automatic analysis of humour and its sentiment, facial expressions are most promising, while humour direction can be best modelled via text-based features. The results reveal considerable differences among various subjects, highlighting the individuality of humour usage and style. Further, we observe that a decision-level fusion yields the best recognition result. Finally, we make our code publicly available at https://www.github.com/EIHW/passau-sfch. The Passau-SFCH dataset is available upon request.
All-In-One: Facial Expression Transfer, Editing and Recognition Using A Single Network
Nov 16, 2019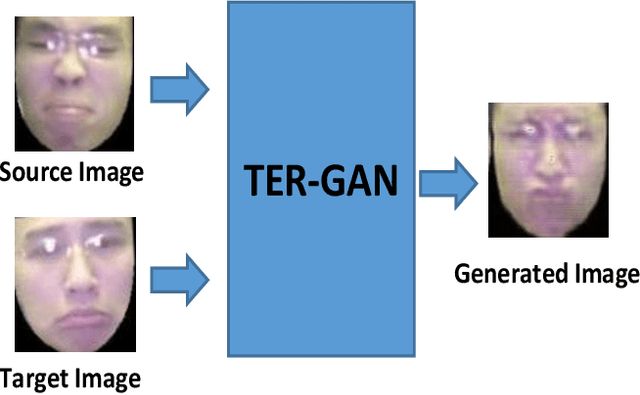
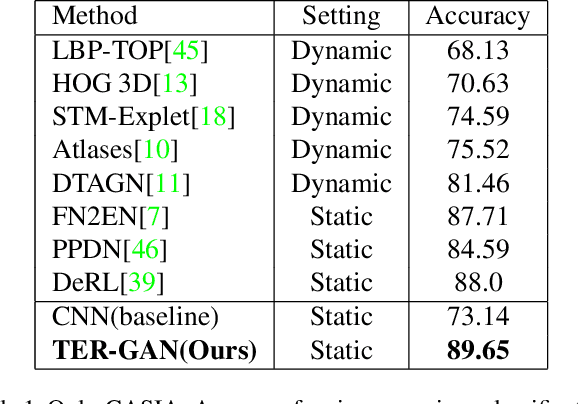
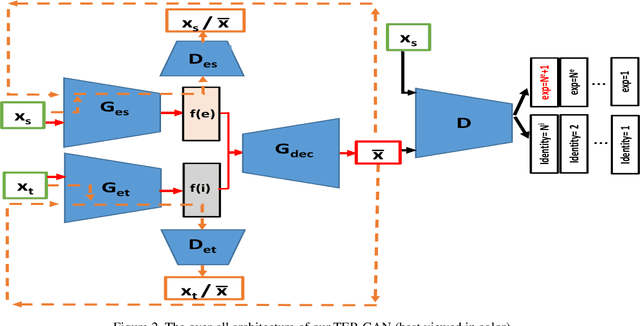

In this paper, we present a unified architecture known as Transfer-Editing and Recognition Generative Adversarial Network (TER-GAN) which can be used: 1. to transfer facial expressions from one identity to another identity, known as Facial Expression Transfer (FET), 2. to transform the expression of a given image to a target expression, while preserving the identity of the image, known as Facial Expression Editing (FEE), and 3. to recognize the facial expression of a face image, known as Facial Expression Recognition (FER). In TER-GAN, we combine the capabilities of generative models to generate synthetic images, while learning important information about the input images during the reconstruction process. More specifically, two encoders are used in TER-GAN to encode identity and expression information from two input images, and a synthetic expression image is generated by the decoder part of TER-GAN. To improve the feature disentanglement and extraction process, we also introduce a novel expression consistency loss and an identity consistency loss which exploit extra expression and identity information from generated images. Experimental results show that the proposed method can be used for efficient facial expression transfer, facial expression editing and facial expression recognition. In order to evaluate the proposed technique and to compare our results with state-of-the-art methods, we have used the Oulu-CASIA dataset for our experiments.
Micro-Expression Recognition Based on Attribute Information Embedding and Cross-modal Contrastive Learning
May 29, 2022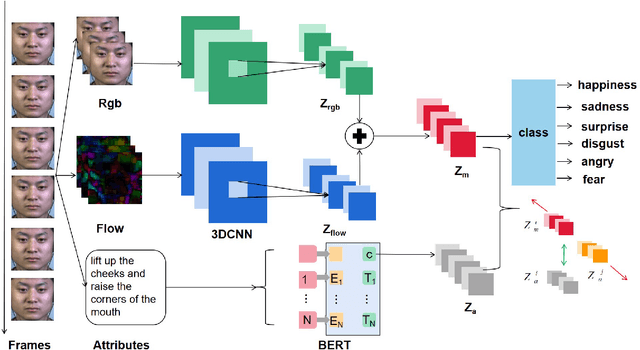
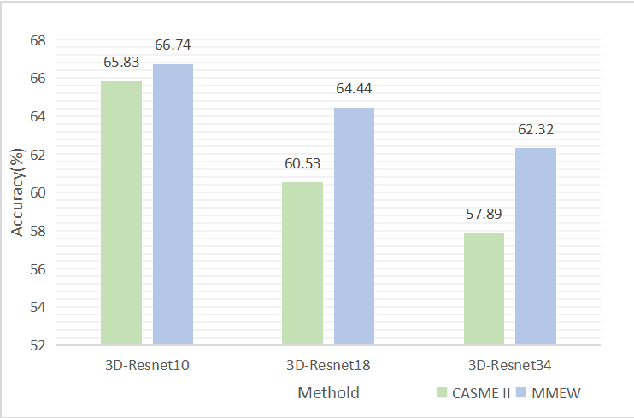
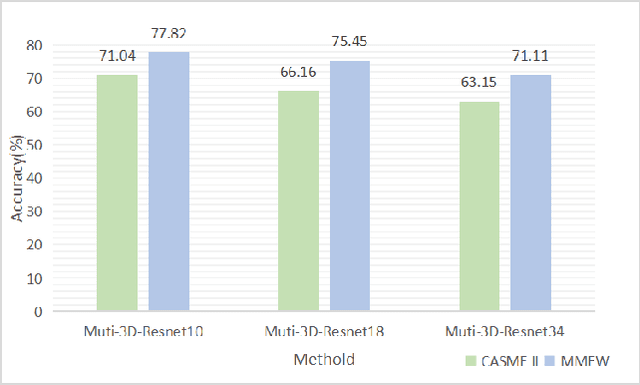
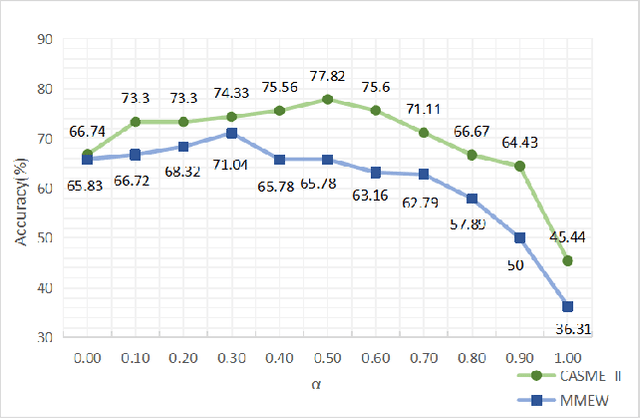
Facial micro-expressions recognition has attracted much attention recently. Micro-expressions have the characteristics of short duration and low intensity, and it is difficult to train a high-performance classifier with the limited number of existing micro-expressions. Therefore, recognizing micro-expressions is a challenge task. In this paper, we propose a micro-expression recognition method based on attribute information embedding and cross-modal contrastive learning. We use 3D CNN to extract RGB features and FLOW features of micro-expression sequences and fuse them, and use BERT network to extract text information in Facial Action Coding System. Through cross-modal contrastive loss, we embed attribute information in the visual network, thereby improving the representation ability of micro-expression recognition in the case of limited samples. We conduct extensive experiments in CASME II and MMEW databases, and the accuracy is 77.82% and 71.04%, respectively. The comparative experiments show that this method has better recognition effect than other methods for micro-expression recognition.
To-sequence:Multi-label Relation Modeling in Facial Action Units Detection
Feb 04, 2020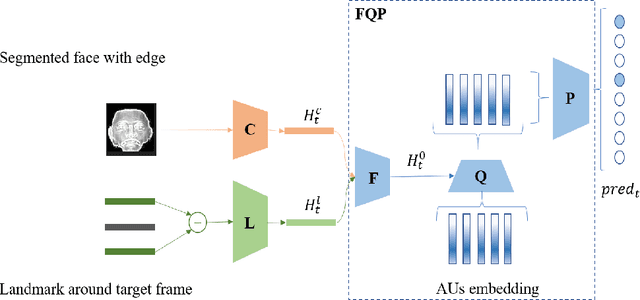
Facial Action Units Detection (FAUD), one of the main approaches for facial expression measurement, based on the Facial Action Coding System (FACS), makes the subtlety of human emotions available in the various applications, such as micro-expression recognition, expression generation. Therefore, FAUD has recently become a popular research field. Inspired by the recent advance in text multi-label classification task, we adapt the sequence-to-sequence method for multi-label text classification, which directly models the relationship between labels to treat the multiple activated AUs as a sequence in the context of data representation, thus transforming the multi-label classification task into a sequence modeling task. We implement the above algorithm on the data set released by the competition FG-2020 Competition:Affective Behavior Analysis in-the-wild (ABAW).