 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
ACR Loss: Adaptive Coordinate-based Regression Loss for Face Alignment
Mar 29, 2022



Although deep neural networks have achieved reasonable accuracy in solving face alignment, it is still a challenging task, specifically when we deal with facial images, under occlusion, or extreme head poses. Heatmap-based Regression (HBR) and Coordinate-based Regression (CBR) are among the two mainly used methods for face alignment. CBR methods require less computer memory, though their performance is less than HBR methods. In this paper, we propose an Adaptive Coordinate-based Regression (ACR) loss to improve the accuracy of CBR for face alignment. Inspired by the Active Shape Model (ASM), we generate Smooth-Face objects, a set of facial landmark points with less variations compared to the ground truth landmark points. We then introduce a method to estimate the level of difficulty in predicting each landmark point for the network by comparing the distribution of the ground truth landmark points and the corresponding Smooth-Face objects. Our proposed ACR Loss can adaptively modify its curvature and the influence of the loss based on the difficulty level of predicting each landmark point in a face. Accordingly, the ACR Loss guides the network toward challenging points than easier points, which improves the accuracy of the face alignment task. Our extensive evaluation shows the capabilities of the proposed ACR Loss in predicting facial landmark points in various facial images.
Micro-Expression Recognition Based on Attribute Information Embedding and Cross-modal Contrastive Learning
May 29, 2022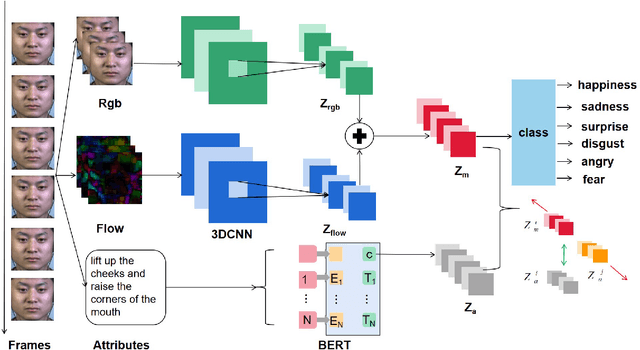
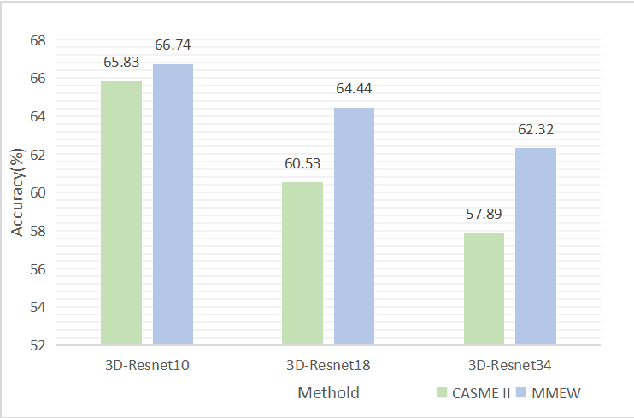
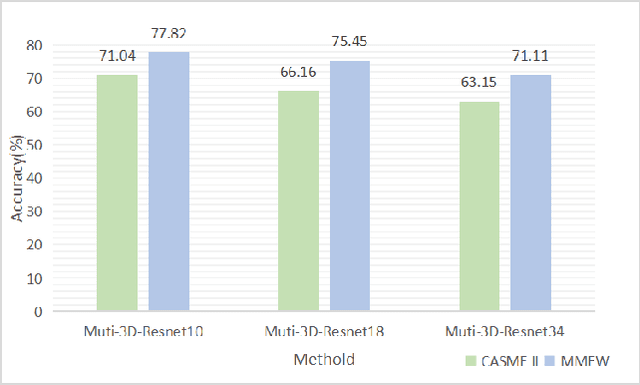
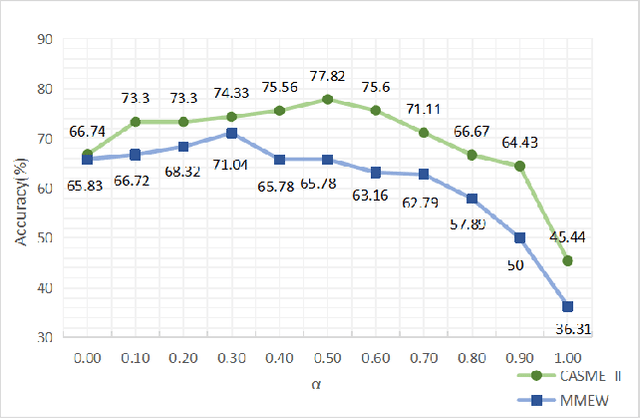
Facial micro-expressions recognition has attracted much attention recently. Micro-expressions have the characteristics of short duration and low intensity, and it is difficult to train a high-performance classifier with the limited number of existing micro-expressions. Therefore, recognizing micro-expressions is a challenge task. In this paper, we propose a micro-expression recognition method based on attribute information embedding and cross-modal contrastive learning. We use 3D CNN to extract RGB features and FLOW features of micro-expression sequences and fuse them, and use BERT network to extract text information in Facial Action Coding System. Through cross-modal contrastive loss, we embed attribute information in the visual network, thereby improving the representation ability of micro-expression recognition in the case of limited samples. We conduct extensive experiments in CASME II and MMEW databases, and the accuracy is 77.82% and 71.04%, respectively. The comparative experiments show that this method has better recognition effect than other methods for micro-expression recognition.
Generating Thermal Image Data Samples using 3D Facial Modelling Techniques and Deep Learning Methodologies
May 07, 2020



Methods for generating synthetic data have become of increasing importance to build large datasets required for Convolution Neural Networks (CNN) based deep learning techniques for a wide range of computer vision applications. In this work, we extend existing methodologies to show how 2D thermal facial data can be mapped to provide 3D facial models. For the proposed research work we have used tufts datasets for generating 3D varying face poses by using a single frontal face pose. The system works by refining the existing image quality by performing fusion based image preprocessing operations. The refined outputs have better contrast adjustments, decreased noise level and higher exposedness of the dark regions. It makes the facial landmarks and temperature patterns on the human face more discernible and visible when compared to original raw data. Different image quality metrics are used to compare the refined version of images with original images. In the next phase of the proposed study, the refined version of images is used to create 3D facial geometry structures by using Convolution Neural Networks (CNN). The generated outputs are then imported in blender software to finally extract the 3D thermal facial outputs of both males and females. The same technique is also used on our thermal face data acquired using prototype thermal camera (developed under Heliaus EU project) in an indoor lab environment which is then used for generating synthetic 3D face data along with varying yaw face angles and lastly facial depth map is generated.
Real-time Simultaneous 3D Head Modeling and Facial Motion Capture with an RGB-D camera
Apr 22, 2020
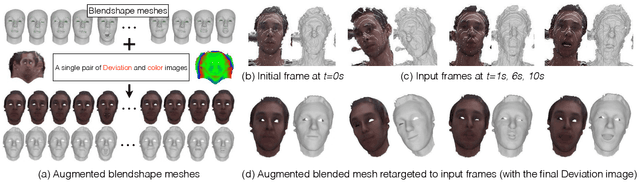

We propose a method to build in real-time animated 3D head models using a consumer-grade RGB-D camera. Our proposed method is the first one to provide simultaneously comprehensive facial motion tracking and a detailed 3D model of the user's head. Anyone's head can be instantly reconstructed and his facial motion captured without requiring any training or pre-scanning. The user starts facing the camera with a neutral expression in the first frame, but is free to move, talk and change his face expression as he wills otherwise. The facial motion is captured using a blendshape animation model while geometric details are captured using a Deviation image mapped over the template mesh. We contribute with an efficient algorithm to grow and refine the deforming 3D model of the head on-the-fly and in real-time. We demonstrate robust and high-fidelity simultaneous facial motion capture and 3D head modeling results on a wide range of subjects with various head poses and facial expressions.
Controllable 3D Generative Adversarial Face Model via Disentangling Shape and Appearance
Aug 30, 2022
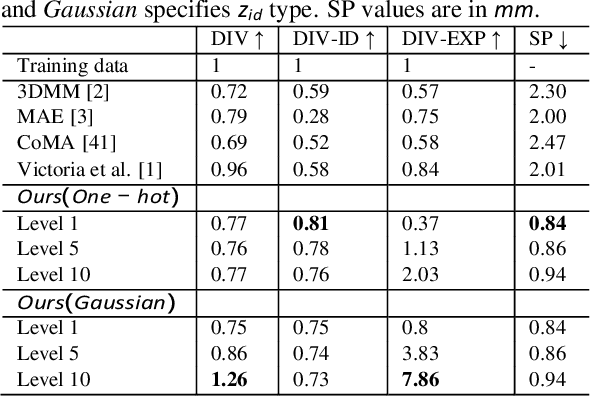
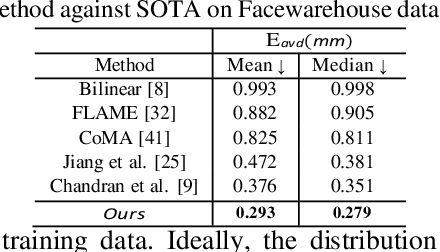
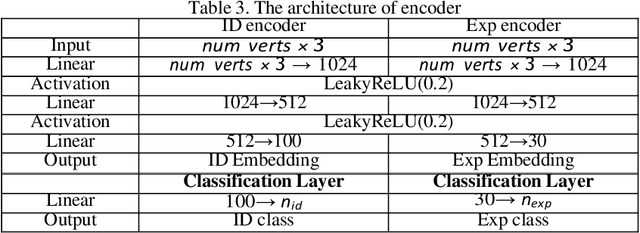
3D face modeling has been an active area of research in computer vision and computer graphics, fueling applications ranging from facial expression transfer in virtual avatars to synthetic data generation. Existing 3D deep learning generative models (e.g., VAE, GANs) allow generating compact face representations (both shape and texture) that can model non-linearities in the shape and appearance space (e.g., scatter effects, specularities, etc.). However, they lack the capability to control the generation of subtle expressions. This paper proposes a new 3D face generative model that can decouple identity and expression and provides granular control over expressions. In particular, we propose using a pair of supervised auto-encoder and generative adversarial networks to produce high-quality 3D faces, both in terms of appearance and shape. Experimental results in the generation of 3D faces learned with holistic expression labels, or Action Unit labels, show how we can decouple identity and expression; gaining fine-control over expressions while preserving identity.
All-In-One: Facial Expression Transfer, Editing and Recognition Using A Single Network
Nov 16, 2019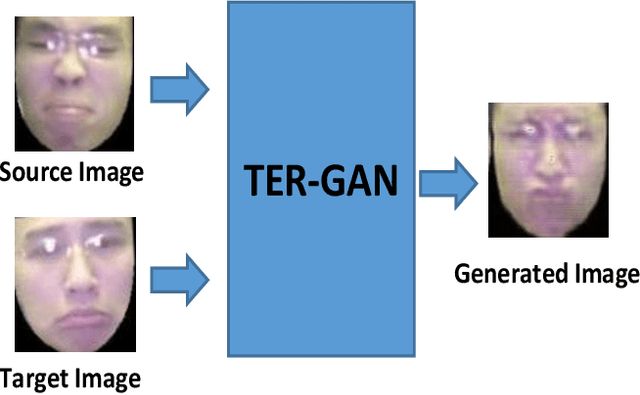
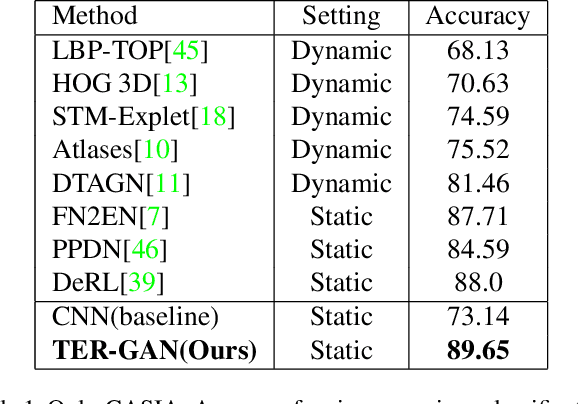
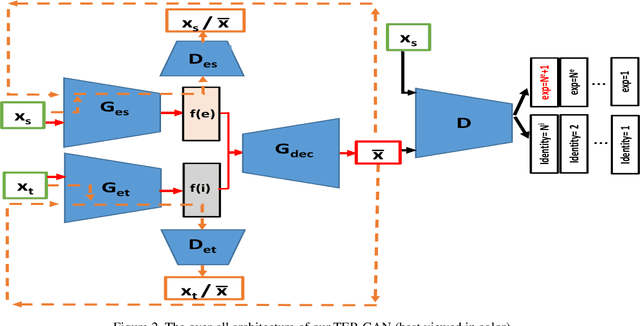

In this paper, we present a unified architecture known as Transfer-Editing and Recognition Generative Adversarial Network (TER-GAN) which can be used: 1. to transfer facial expressions from one identity to another identity, known as Facial Expression Transfer (FET), 2. to transform the expression of a given image to a target expression, while preserving the identity of the image, known as Facial Expression Editing (FEE), and 3. to recognize the facial expression of a face image, known as Facial Expression Recognition (FER). In TER-GAN, we combine the capabilities of generative models to generate synthetic images, while learning important information about the input images during the reconstruction process. More specifically, two encoders are used in TER-GAN to encode identity and expression information from two input images, and a synthetic expression image is generated by the decoder part of TER-GAN. To improve the feature disentanglement and extraction process, we also introduce a novel expression consistency loss and an identity consistency loss which exploit extra expression and identity information from generated images. Experimental results show that the proposed method can be used for efficient facial expression transfer, facial expression editing and facial expression recognition. In order to evaluate the proposed technique and to compare our results with state-of-the-art methods, we have used the Oulu-CASIA dataset for our experiments.
To-sequence:Multi-label Relation Modeling in Facial Action Units Detection
Feb 04, 2020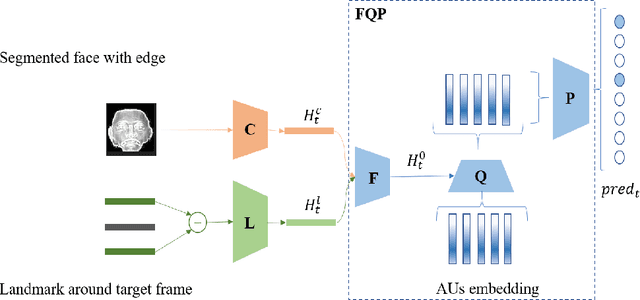
Facial Action Units Detection (FAUD), one of the main approaches for facial expression measurement, based on the Facial Action Coding System (FACS), makes the subtlety of human emotions available in the various applications, such as micro-expression recognition, expression generation. Therefore, FAUD has recently become a popular research field. Inspired by the recent advance in text multi-label classification task, we adapt the sequence-to-sequence method for multi-label text classification, which directly models the relationship between labels to treat the multiple activated AUs as a sequence in the context of data representation, thus transforming the multi-label classification task into a sequence modeling task. We implement the above algorithm on the data set released by the competition FG-2020 Competition:Affective Behavior Analysis in-the-wild (ABAW).
MaSS: Multi-attribute Selective Suppression
Oct 18, 2022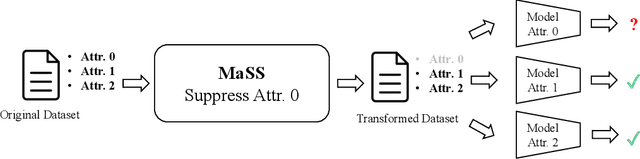

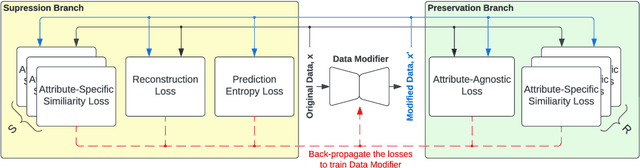
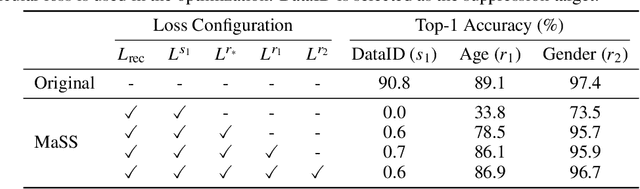
The recent rapid advances in machine learning technologies largely depend on the vast richness of data available today, in terms of both the quantity and the rich content contained within. For example, biometric data such as images and voices could reveal people's attributes like age, gender, sentiment, and origin, whereas location/motion data could be used to infer people's activity levels, transportation modes, and life habits. Along with the new services and applications enabled by such technological advances, various governmental policies are put in place to regulate such data usage and protect people's privacy and rights. As a result, data owners often opt for simple data obfuscation (e.g., blur people's faces in images) or withholding data altogether, which leads to severe data quality degradation and greatly limits the data's potential utility. Aiming for a sophisticated mechanism which gives data owners fine-grained control while retaining the maximal degree of data utility, we propose Multi-attribute Selective Suppression, or MaSS, a general framework for performing precisely targeted data surgery to simultaneously suppress any selected set of attributes while preserving the rest for downstream machine learning tasks. MaSS learns a data modifier through adversarial games between two sets of networks, where one is aimed at suppressing selected attributes, and the other ensures the retention of the rest of the attributes via general contrastive loss as well as explicit classification metrics. We carried out an extensive evaluation of our proposed method using multiple datasets from different domains including facial images, voice audio, and video clips, and obtained promising results in MaSS' generalizability and capability of suppressing targeted attributes without negatively affecting the data's usability in other downstream ML tasks.
A Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021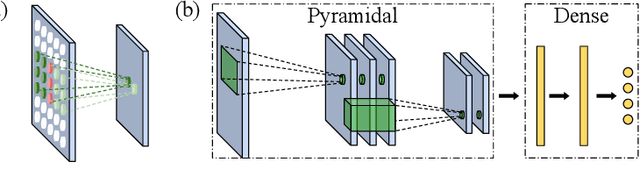

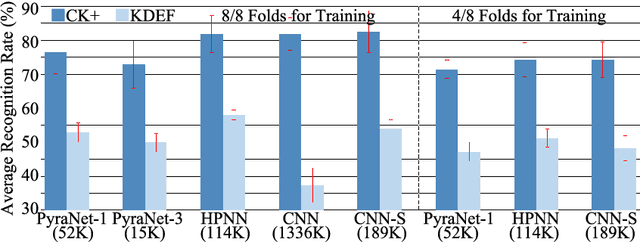

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
VToonify: Controllable High-Resolution Portrait Video Style Transfer
Sep 30, 2022


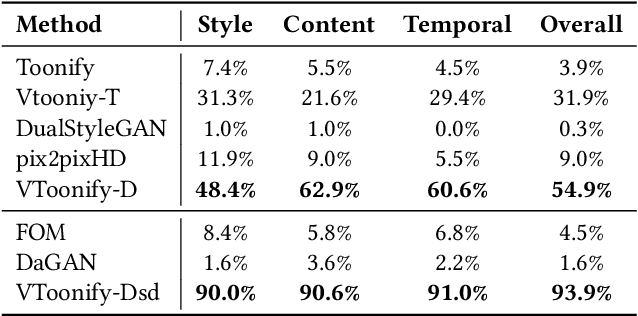
Generating high-quality artistic portrait videos is an important and desirable task in computer graphics and vision. Although a series of successful portrait image toonification models built upon the powerful StyleGAN have been proposed, these image-oriented methods have obvious limitations when applied to videos, such as the fixed frame size, the requirement of face alignment, missing non-facial details and temporal inconsistency. In this work, we investigate the challenging controllable high-resolution portrait video style transfer by introducing a novel VToonify framework. Specifically, VToonify leverages the mid- and high-resolution layers of StyleGAN to render high-quality artistic portraits based on the multi-scale content features extracted by an encoder to better preserve the frame details. The resulting fully convolutional architecture accepts non-aligned faces in videos of variable size as input, contributing to complete face regions with natural motions in the output. Our framework is compatible with existing StyleGAN-based image toonification models to extend them to video toonification, and inherits appealing features of these models for flexible style control on color and intensity. This work presents two instantiations of VToonify built upon Toonify and DualStyleGAN for collection-based and exemplar-based portrait video style transfer, respectively. Extensive experimental results demonstrate the effectiveness of our proposed VToonify framework over existing methods in generating high-quality and temporally-coherent artistic portrait videos with flexible style controls.