 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Face Swap via Diffusion Model
Mar 02, 2024
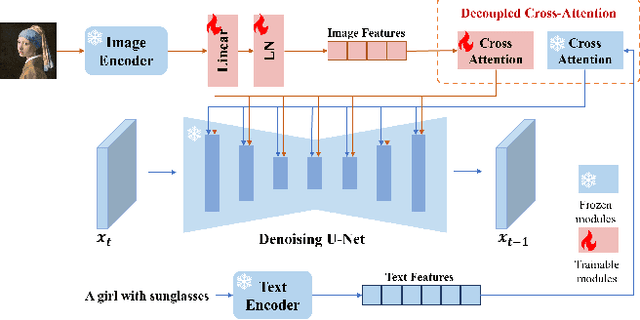
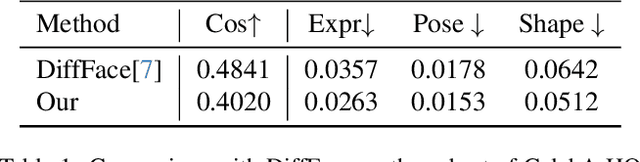


This technical report presents a diffusion model based framework for face swapping between two portrait images. The basic framework consists of three components, i.e., IP-Adapter, ControlNet, and Stable Diffusion's inpainting pipeline, for face feature encoding, multi-conditional generation, and face inpainting respectively. Besides, I introduce facial guidance optimization and CodeFormer based blending to further improve the generation quality. Specifically, we engage a recent light-weighted customization method (i.e., DreamBooth-LoRA), to guarantee the identity consistency by 1) using a rare identifier "sks" to represent the source identity, and 2) injecting the image features of source portrait into each cross-attention layer like the text features. Then I resort to the strong inpainting ability of Stable Diffusion, and utilize canny image and face detection annotation of the target portrait as the conditions, to guide ContorlNet's generation and align source portrait with the target portrait. To further correct face alignment, we add the facial guidance loss to optimize the text embedding during the sample generation.
A Multimodal Intermediate Fusion Network with Manifold Learning for Stress Detection
Mar 12, 2024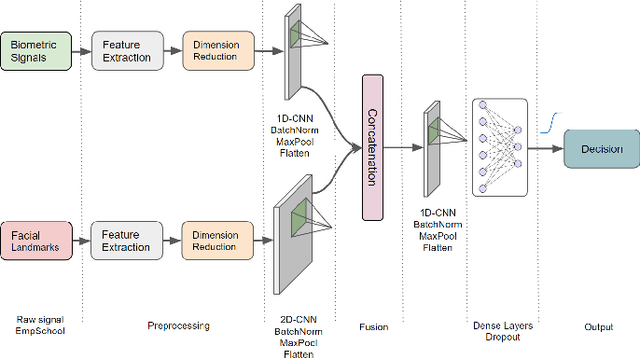
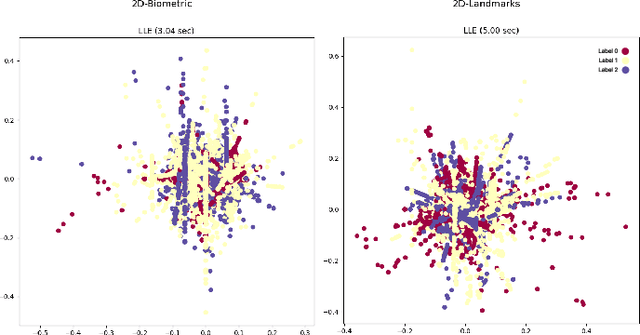
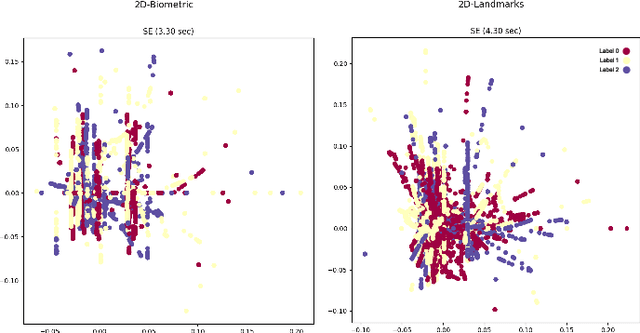
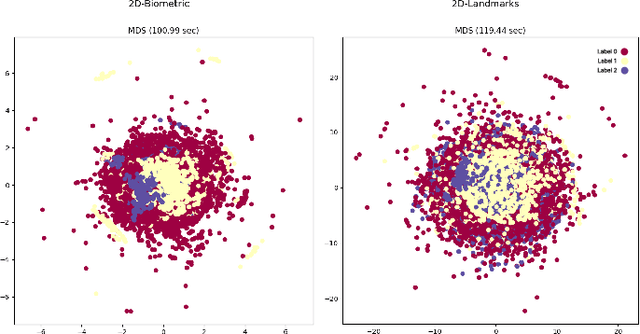
Multimodal deep learning methods capture synergistic features from multiple modalities and have the potential to improve accuracy for stress detection compared to unimodal methods. However, this accuracy gain typically comes from high computational cost due to the high-dimensional feature spaces, especially for intermediate fusion. Dimensionality reduction is one way to optimize multimodal learning by simplifying data and making the features more amenable to processing and analysis, thereby reducing computational complexity. This paper introduces an intermediate multimodal fusion network with manifold learning-based dimensionality reduction. The multimodal network generates independent representations from biometric signals and facial landmarks through 1D-CNN and 2D-CNN. Finally, these features are fused and fed to another 1D-CNN layer, followed by a fully connected dense layer. We compared various dimensionality reduction techniques for different variations of unimodal and multimodal networks. We observe that the intermediate-level fusion with the Multi-Dimensional Scaling (MDS) manifold method showed promising results with an accuracy of 96.00\% in a Leave-One-Subject-Out Cross-Validation (LOSO-CV) paradigm over other dimensional reduction methods. MDS had the highest computational cost among manifold learning methods. However, while outperforming other networks, it managed to reduce the computational cost of the proposed networks by 25\% when compared to six well-known conventional feature selection methods used in the preprocessing step.
AVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
Feb 25, 2024While considerable progress has been made in achieving accurate lip synchronization for 3D speech-driven talking face generation, the task of incorporating expressive facial detail synthesis aligned with the speaker's speaking status remains challenging. Our goal is to directly leverage the inherent style information conveyed by human speech for generating an expressive talking face that aligns with the speaking status. In this paper, we propose AVI-Talking, an Audio-Visual Instruction system for expressive Talking face generation. This system harnesses the robust contextual reasoning and hallucination capability offered by Large Language Models (LLMs) to instruct the realistic synthesis of 3D talking faces. Instead of directly learning facial movements from human speech, our two-stage strategy involves the LLMs first comprehending audio information and generating instructions implying expressive facial details seamlessly corresponding to the speech. Subsequently, a diffusion-based generative network executes these instructions. This two-stage process, coupled with the incorporation of LLMs, enhances model interpretability and provides users with flexibility to comprehend instructions and specify desired operations or modifications. Extensive experiments showcase the effectiveness of our approach in producing vivid talking faces with expressive facial movements and consistent emotional status.
Video-Driven Animation of Neural Head Avatars
Mar 07, 2024
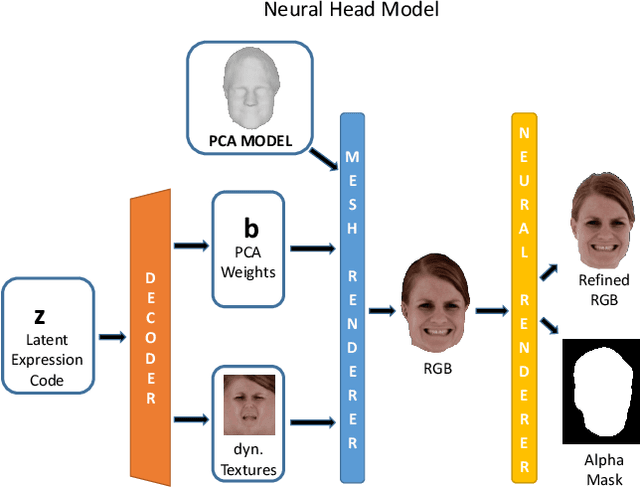
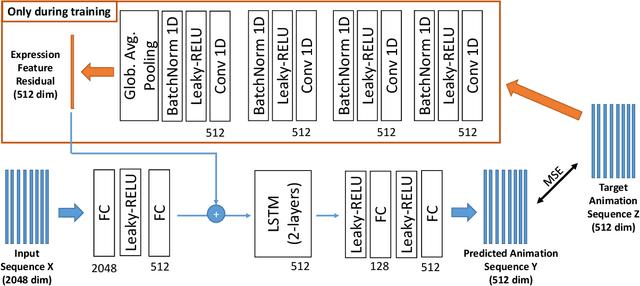

We present a new approach for video-driven animation of high-quality neural 3D head models, addressing the challenge of person-independent animation from video input. Typically, high-quality generative models are learned for specific individuals from multi-view video footage, resulting in person-specific latent representations that drive the generation process. In order to achieve person-independent animation from video input, we introduce an LSTM-based animation network capable of translating person-independent expression features into personalized animation parameters of person-specific 3D head models. Our approach combines the advantages of personalized head models (high quality and realism) with the convenience of video-driven animation employing multi-person facial performance capture. We demonstrate the effectiveness of our approach on synthesized animations with high quality based on different source videos as well as an ablation study.
Towards Zero-Shot Interpretable Human Recognition: A 2D-3D Registration Framework
Mar 11, 2024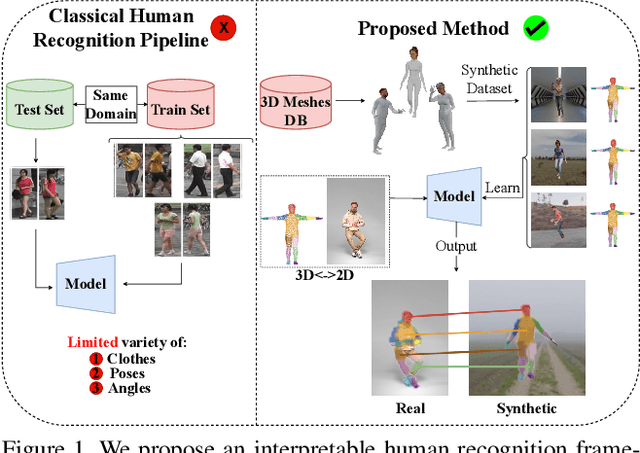
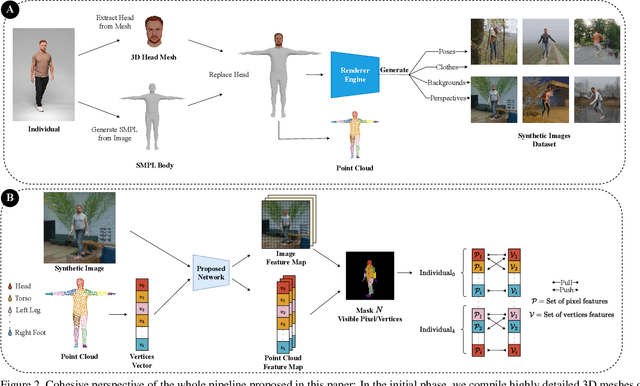
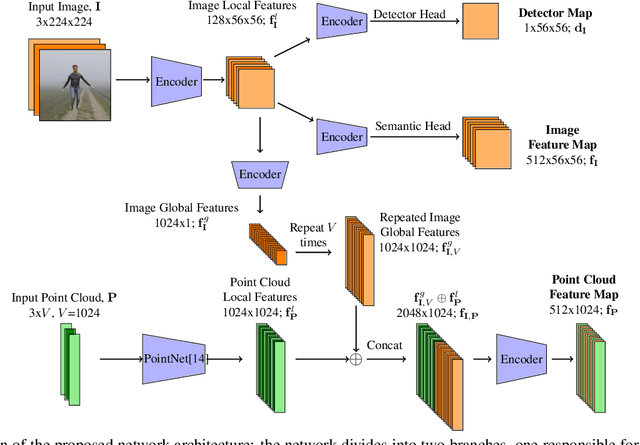

Large vision models based in deep learning architectures have been consistently advancing the state-of-the-art in biometric recognition. However, three weaknesses are commonly reported for such kind of approaches: 1) their extreme demands in terms of learning data; 2) the difficulties in generalising between different domains; and 3) the lack of interpretability/explainability, with biometrics being of particular interest, as it is important to provide evidence able to be used for forensics/legal purposes (e.g., in courts). To the best of our knowledge, this paper describes the first recognition framework/strategy that aims at addressing the three weaknesses simultaneously. At first, it relies exclusively in synthetic samples for learning purposes. Instead of requiring a large amount and variety of samples for each subject, the idea is to exclusively enroll a 3D point cloud per identity. Then, using generative strategies, we synthesize a very large (potentially infinite) number of samples, containing all the desired covariates (poses, clothing, distances, perspectives, lighting, occlusions,...). Upon the synthesizing method used, it is possible to adapt precisely to different kind of domains, which accounts for generalization purposes. Such data are then used to learn a model that performs local registration between image pairs, establishing positive correspondences between body parts that are the key, not only to recognition (according to cardinality and distribution), but also to provide an interpretable description of the response (e.g.: "both samples are from the same person, as they have similar facial shape, hair color and legs thickness").
G4G:A Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
Mar 02, 2024Despite numerous completed studies, achieving high fidelity talking face generation with highly synchronized lip movements corresponding to arbitrary audio remains a significant challenge in the field. The shortcomings of published studies continue to confuse many researchers. This paper introduces G4G, a generic framework for high fidelity talking face generation with fine-grained intra-modal alignment. G4G can reenact the high fidelity of original video while producing highly synchronized lip movements regardless of given audio tones or volumes. The key to G4G's success is the use of a diagonal matrix to enhance the ordinary alignment of audio-image intra-modal features, which significantly increases the comparative learning between positive and negative samples. Additionally, a multi-scaled supervision module is introduced to comprehensively reenact the perceptional fidelity of original video across the facial region while emphasizing the synchronization of lip movements and the input audio. A fusion network is then used to further fuse the facial region and the rest. Our experimental results demonstrate significant achievements in reenactment of original video quality as well as highly synchronized talking lips. G4G is an outperforming generic framework that can produce talking videos competitively closer to ground truth level than current state-of-the-art methods.
Learning Contrastive Feature Representations for Facial Action Unit Detection
Feb 09, 2024The predominant approach to facial action unit (AU) detection revolves around a supervised multi-label binary classification problem. Existing methodologies often encode pixel-level information of AUs, thereby imposing substantial demands on model complexity and expressiveness. Moreover, this practice elevates the susceptibility to overfitting due to the presence of noisy AU labels. In the present study, we introduce a contrastive learning framework enhanced by both supervised and self-supervised signals. The objective is to acquire discriminative features, deviating from the conventional pixel-level learning paradigm within the domain of AU detection. To address the challenge posed by noisy AU labels, we augment the supervised signal through the introduction of a self-supervised signal. This augmentation is achieved through positive sample sampling, encompassing three distinct types of positive sample pairs. Furthermore, to mitigate the imbalanced distribution of each AU type, we employ an importance re-weighting strategy tailored for minority AUs. The resulting loss, denoted as AUNCE, is proposed to encapsulate this strategy. Our experimental assessments, conducted on two widely-utilized benchmark datasets (BP4D and DISFA), underscore the superior performance of our approach compared to state-of-the-art methods in the realm of AU detection.
Deep Spectral Meshes: Multi-Frequency Facial Mesh Processing with Graph Neural Networks
Feb 15, 2024With the rising popularity of virtual worlds, the importance of data-driven parametric models of 3D meshes has grown rapidly. Numerous applications, such as computer vision, procedural generation, and mesh editing, vastly rely on these models. However, current approaches do not allow for independent editing of deformations at different frequency levels. They also do not benefit from representing deformations at different frequencies with dedicated representations, which would better expose their properties and improve the generated meshes' geometric and perceptual quality. In this work, spectral meshes are introduced as a method to decompose mesh deformations into low-frequency and high-frequency deformations. These features of low- and high-frequency deformations are used for representation learning with graph convolutional networks. A parametric model for 3D facial mesh synthesis is built upon the proposed framework, exposing user parameters that control disentangled high- and low-frequency deformations. Independent control of deformations at different frequencies and generation of plausible synthetic examples are mutually exclusive objectives. A Conditioning Factor is introduced to leverage these objectives. Our model takes further advantage of spectral partitioning by representing different frequency levels with disparate, more suitable representations. Low frequencies are represented with standardised Euclidean coordinates, and high frequencies with a normalised deformation representation (DR). This paper investigates applications of our proposed approach in mesh reconstruction, mesh interpolation, and multi-frequency editing. It is demonstrated that our method improves the overall quality of generated meshes on most datasets when considering both the $L_1$ norm and perceptual Dihedral Angle Mesh Error (DAME) metrics.
* 26 pages, 10 figures, journal article
SLYKLatent, a Learning Framework for Facial Features Estimation
Feb 02, 2024In this research, we present SLYKLatent, a novel approach for enhancing gaze estimation by addressing appearance instability challenges in datasets due to aleatoric uncertainties, covariant shifts, and test domain generalization. SLYKLatent utilizes Self-Supervised Learning for initial training with facial expression datasets, followed by refinement with a patch-based tri-branch network and an inverse explained variance-weighted training loss function. Our evaluation on benchmark datasets achieves an 8.7% improvement on Gaze360, rivals top MPIIFaceGaze results, and leads on a subset of ETH-XGaze by 13%, surpassing existing methods by significant margins. Adaptability tests on RAF-DB and Affectnet show 86.4% and 60.9% accuracies, respectively. Ablation studies confirm the effectiveness of SLYKLatent's novel components. This approach has strong potential in human-robot interaction.
InstructGIE: Towards Generalizable Image Editing
Mar 08, 2024
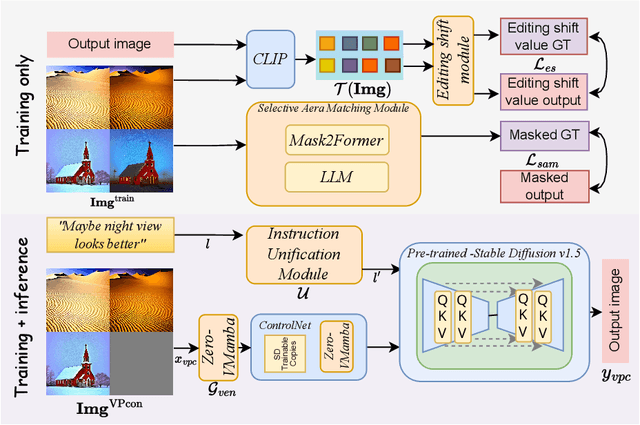


Recent advances in image editing have been driven by the development of denoising diffusion models, marking a significant leap forward in this field. Despite these advances, the generalization capabilities of recent image editing approaches remain constrained. In response to this challenge, our study introduces a novel image editing framework with enhanced generalization robustness by boosting in-context learning capability and unifying language instruction. This framework incorporates a module specifically optimized for image editing tasks, leveraging the VMamba Block and an editing-shift matching strategy to augment in-context learning. Furthermore, we unveil a selective area-matching technique specifically engineered to address and rectify corrupted details in generated images, such as human facial features, to further improve the quality. Another key innovation of our approach is the integration of a language unification technique, which aligns language embeddings with editing semantics to elevate the quality of image editing. Moreover, we compile the first dataset for image editing with visual prompts and editing instructions that could be used to enhance in-context capability. Trained on this dataset, our methodology not only achieves superior synthesis quality for trained tasks, but also demonstrates robust generalization capability across unseen vision tasks through tailored prompts.