 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
FLNet: Landmark Driven Fetching and Learning Network for Faithful Talking Facial Animation Synthesis
Nov 21, 2019
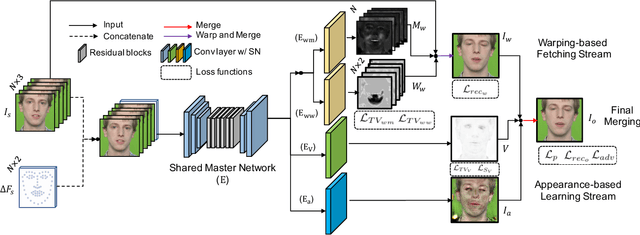
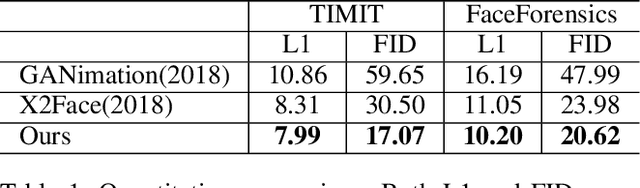


Talking face synthesis has been widely studied in either appearance-based or warping-based methods. Previous works mostly utilize single face image as a source, and generate novel facial animations by merging other person's facial features. However, some facial regions like eyes or teeth, which may be hidden in the source image, can not be synthesized faithfully and stably. In this paper, We present a landmark driven two-stream network to generate faithful talking facial animation, in which more facial details are created, preserved and transferred from multiple source images instead of a single one. Specifically, we propose a network consisting of a learning and fetching stream. The fetching sub-net directly learns to attentively warp and merge facial regions from five source images of distinctive landmarks, while the learning pipeline renders facial organs from the training face space to compensate. Compared to baseline algorithms, extensive experiments demonstrate that the proposed method achieves a higher performance both quantitatively and qualitatively. Codes are at https://github.com/kgu3/FLNet_AAAI2020.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


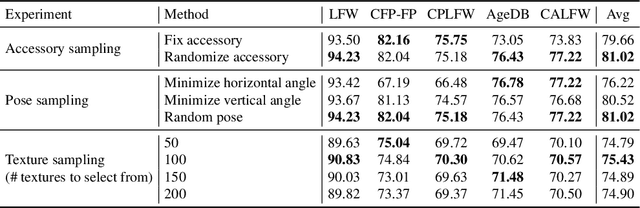
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.
Photo-Realistic Facial Details Synthesis from Single Immage
Mar 26, 2019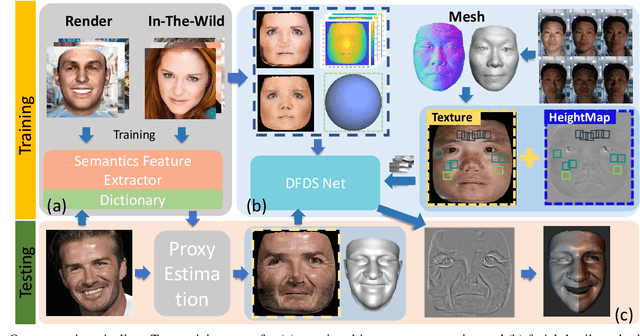

We present a single-image 3D face synthesis technique that can handle challenging facial expressions while recovering fine geometric details. Our technique employs expression analysis for proxy face geometry generation and combines supervised and unsupervised learning for facial detail synthesis. On proxy generation, we conduct emotion prediction to determine a new expression-informed proxy. On detail synthesis, we present a Deep Facial Detail Net (DFDN) based on Conditional Generative Adversarial Net (CGAN) that employs both geometry and appearance loss functions. For geometry, we capture 366 high-quality 3D scans from 122 different subjects under 3 facial expressions. For appearance, we use additional 20K in-the-wild face images and apply image-based rendering to accommodate lighting variations. Comprehensive experiments demonstrate that our framework can produce high-quality 3D faces with realistic details under challenging facial expressions.
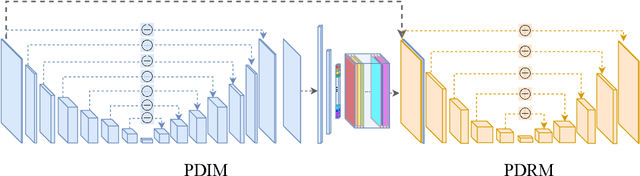
DuetFace: Collaborative Privacy-Preserving Face Recognition via Channel Splitting in the Frequency Domain
Jul 15, 2022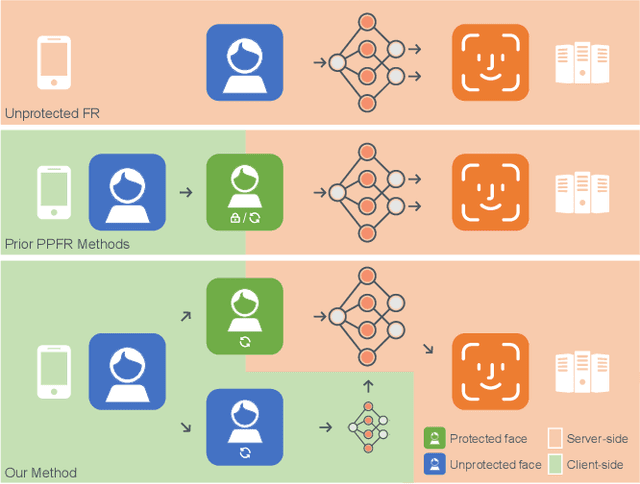
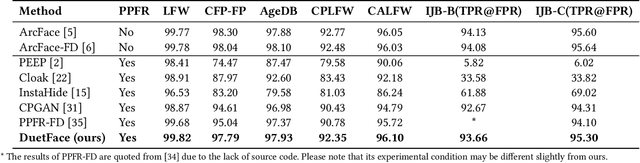
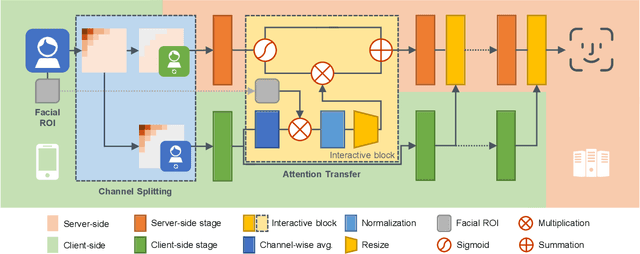
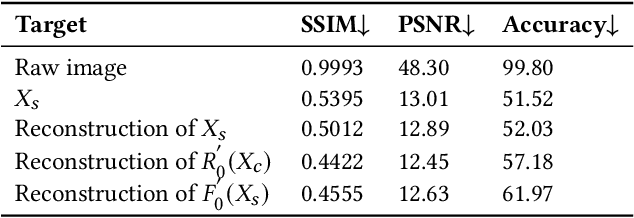
With the wide application of face recognition systems, there is rising concern that original face images could be exposed to malicious intents and consequently cause personal privacy breaches. This paper presents DuetFace, a novel privacy-preserving face recognition method that employs collaborative inference in the frequency domain. Starting from a counterintuitive discovery that face recognition can achieve surprisingly good performance with only visually indistinguishable high-frequency channels, this method designs a credible split of frequency channels by their cruciality for visualization and operates the server-side model on non-crucial channels. However, the model degrades in its attention to facial features due to the missing visual information. To compensate, the method introduces a plug-in interactive block to allow attention transfer from the client-side by producing a feature mask. The mask is further refined by deriving and overlaying a facial region of interest (ROI). Extensive experiments on multiple datasets validate the effectiveness of the proposed method in protecting face images from undesired visual inspection, reconstruction, and identification while maintaining high task availability and performance. Results show that the proposed method achieves a comparable recognition accuracy and computation cost to the unprotected ArcFace and outperforms the state-of-the-art privacy-preserving methods. The source code is available at https://github.com/Tencent/TFace/tree/master/recognition/tasks/duetface.
Lagrangian Motion Magnification with Double Sparse Optical Flow Decomposition
Apr 15, 2022
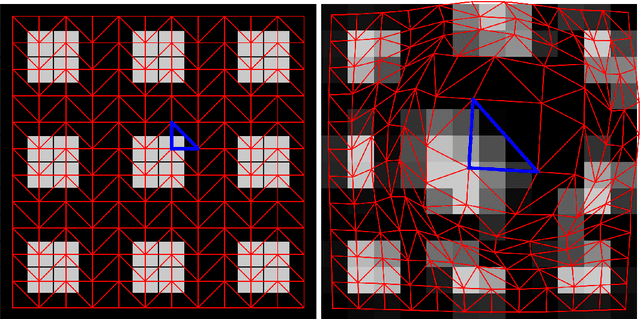
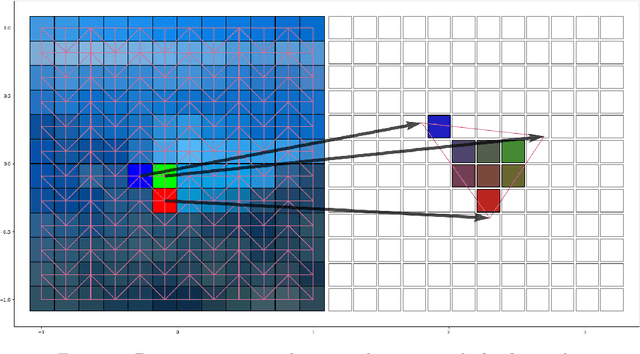
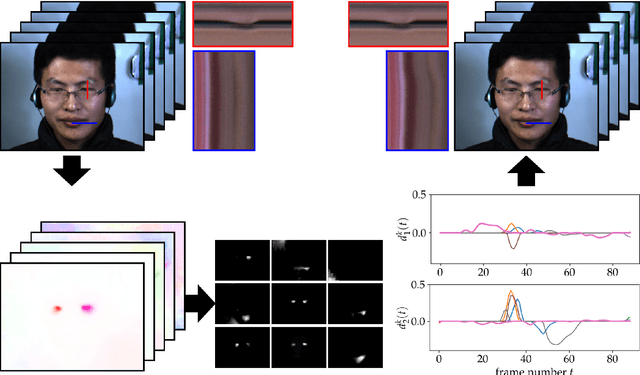
Motion magnification techniques aim at amplifying and hence revealing subtle motion in videos. There are basically two main approaches to reach this goal, namely via Eulerian or Lagrangian techniques. While the first one magnifies motion implicitly by operating directly on image pixels, the Lagrangian approach uses optical flow techniques to extract and amplify pixel trajectories. Microexpressions are fast and spatially small facial expressions that are difficult to detect. In this paper, we propose a novel approach for local Lagrangian motion magnification of facial micromovements. Our contribution is three-fold: first, we fine-tune the recurrent all-pairs field transforms for optical flows (RAFT) deep learning approach for faces by adding ground truth obtained from the variational dense inverse search (DIS) for optical flow algorithm applied to the CASME II video set of faces. This enables us to produce optical flows of facial videos in an efficient and sufficiently accurate way. Second, since facial micromovements are both local in space and time, we propose to approximate the optical flow field by sparse components both in space and time leading to a double sparse decomposition. Third, we use this decomposition to magnify micro-motions in specific areas of the face, where we introduce a new forward warping strategy using a triangular splitting of the image grid and barycentric interpolation of the RGB vectors at the corners of the transformed triangles. We demonstrate the very good performance of our approach by various examples.
Latents2Segments: Disentangling the Latent Space of Generative Models for Semantic Segmentation of Face Images
Jul 06, 2022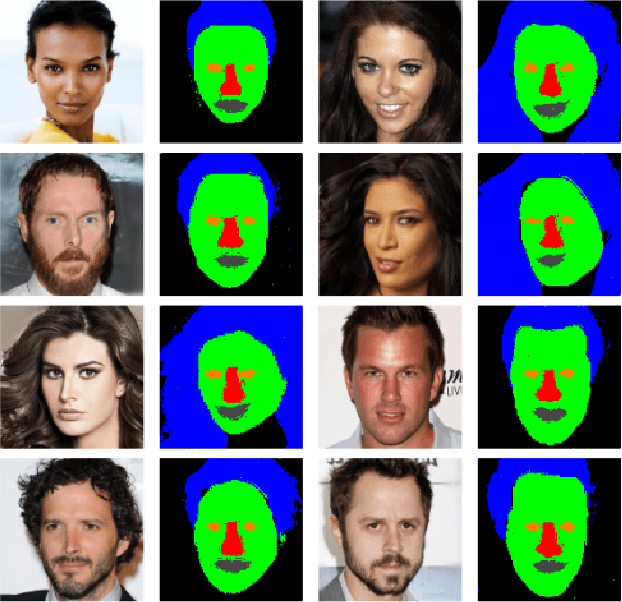
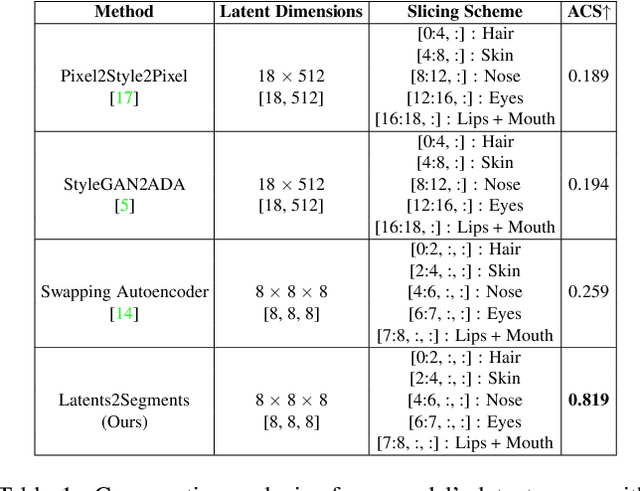
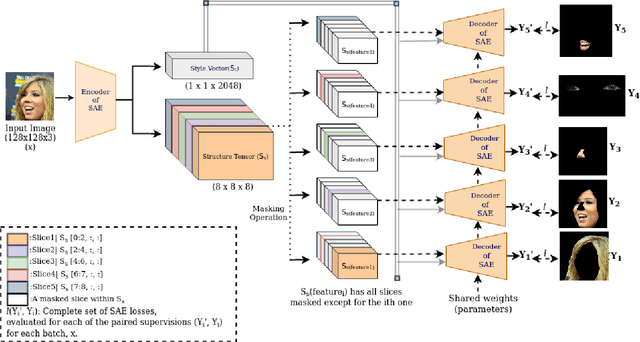

With the advent of an increasing number of Augmented and Virtual Reality applications that aim to perform meaningful and controlled style edits on images of human faces, the impetus for the task of parsing face images to produce accurate and fine-grained semantic segmentation maps is more than ever before. Few State of the Art (SOTA) methods which solve this problem, do so by incorporating priors with respect to facial structure or other face attributes such as expression and pose in their deep classifier architecture. Our endeavour in this work is to do away with the priors and complex pre-processing operations required by SOTA multi-class face segmentation models by reframing this operation as a downstream task post infusion of disentanglement with respect to facial semantic regions of interest (ROIs) in the latent space of a Generative Autoencoder model. We present results for our model's performance on the CelebAMask-HQ and HELEN datasets. The encoded latent space of our model achieves significantly higher disentanglement with respect to semantic ROIs than that of other SOTA works. Moreover, it achieves a 13% faster inference rate and comparable accuracy with respect to the publicly available SOTA for the downstream task of semantic segmentation of face images.
Using Crowdsourcing to Train Facial Emotion Machine Learning Models with Ambiguous Labels
Jan 10, 2021
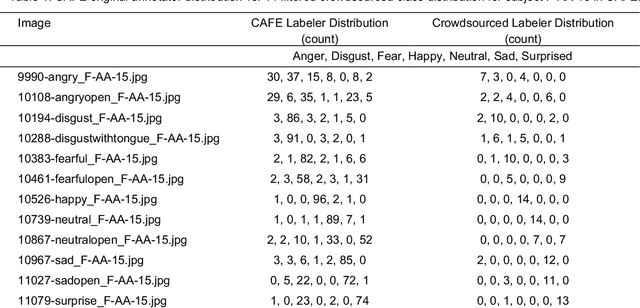
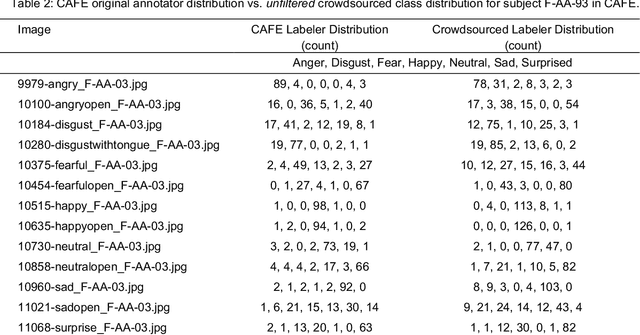
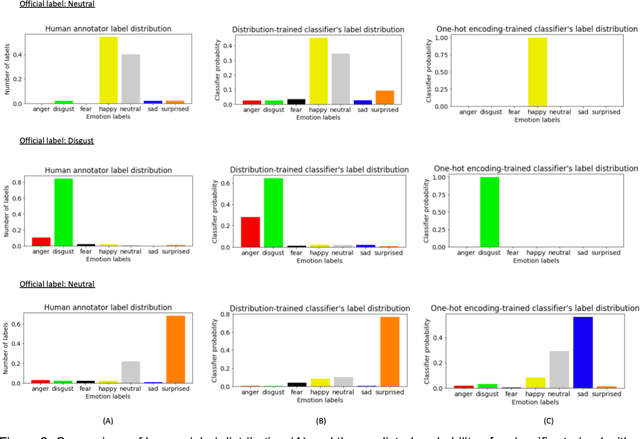
Current emotion detection classifiers predict discrete emotions. However, literature in psychology has documented that compound and ambiguous facial expressions are often evoked by humans. As a stride towards development of machine learning models that more accurately reflect compound and ambiguous emotions, we replace traditional one-hot encoded label representations with a crowd's distribution of labels. We center our study on the Child Affective Facial Expression (CAFE) dataset, a gold standard dataset of pediatric facial expressions which includes 100 human labels per image. We first acquire crowdsourced labels for 207 emotions from CAFE and demonstrate that the consensus labels from the crowd tend to match the consensus from the original CAFE raters, validating the utility of crowdsourcing. We then train two versions of a ResNet-152 classifier on CAFE images with two types of labels (1) traditional one-hot encoding and (2) vector labels representing the crowd distribution of responses. We compare the resulting output distributions of the two classifiers. While the traditional F1-score for the one-hot encoding classifier is much higher (94.33% vs. 78.68%), the output probability vector of the crowd-trained classifier much more closely resembles the distribution of human labels (t=3.2827, p=0.0014). For many applications of affective computing, reporting an emotion probability distribution that more closely resembles human interpretation can be more important than traditional machine learning metrics. This work is a first step for engineers of interactive systems to account for machine learning cases with ambiguous classes and we hope it will generate a discussion about machine learning with ambiguous labels and leveraging crowdsourcing as a potential solution.
Facial Recognition: A cross-national Survey on Public Acceptance, Privacy, and Discrimination
Jul 15, 2020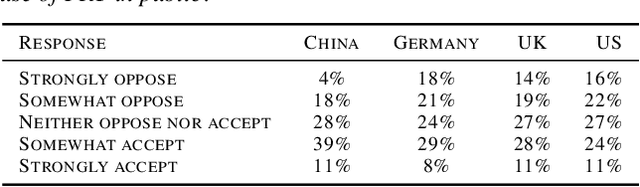
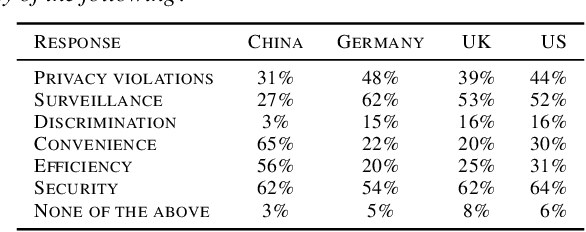
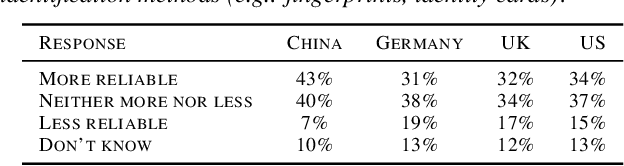
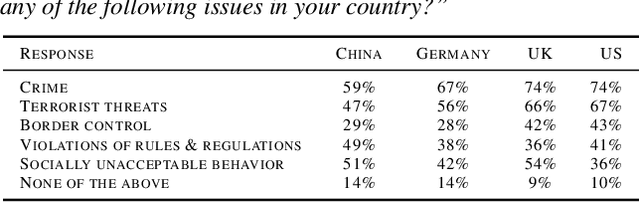
With rapid advances in machine learning (ML), more of this technology is being deployed into the real world interacting with us and our environment. One of the most widely applied application of ML is facial recognition as it is running on millions of devices. While being useful for some people, others perceive it as a threat when used by public authorities. This discrepancy and the lack of policy increases the uncertainty in the ML community about the future direction of facial recognition research and development. In this paper we present results from a cross-national survey about public acceptance, privacy, and discrimination of the use of facial recognition technology (FRT) in the public. This study provides insights about the opinion towards FRT from China, Germany, the United Kingdom (UK), and the United States (US), which can serve as input for policy makers and legal regulators.
Salient Facial Features from Humans and Deep Neural Networks
Mar 08, 2020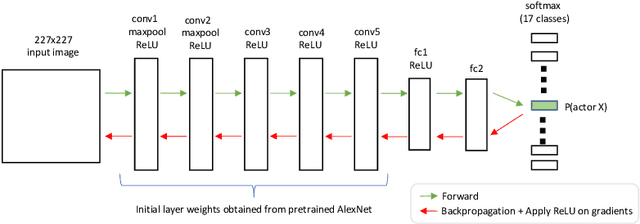


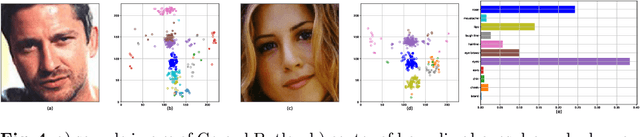
In this work, we explore the features that are used by humans and by convolutional neural networks (ConvNets) to classify faces. We use Guided Backpropagation (GB) to visualize the facial features that influence the output of a ConvNet the most when identifying specific individuals; we explore how to best use GB for that purpose. We use a human intelligence task to find out which facial features humans find to be the most important for identifying specific individuals. We explore the differences between the saliency information gathered from humans and from ConvNets. Humans develop biases in employing available information on facial features to discriminate across faces. Studies show these biases are influenced both by neurological development and by each individual's social experience. In recent years the computer vision community has achieved human-level performance in many face processing tasks with deep neural network-based models. These face processing systems are also subject to systematic biases due to model architectural choices and training data distribution.
Explaining Bias in Deep Face Recognition via Image Characteristics
Aug 23, 2022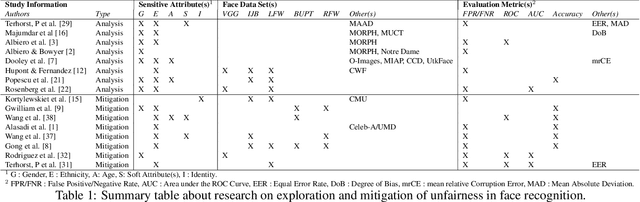
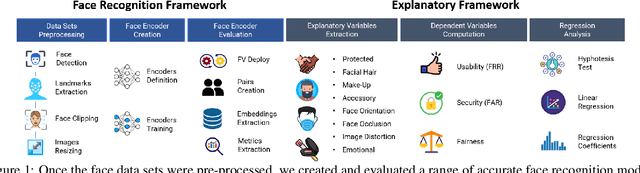

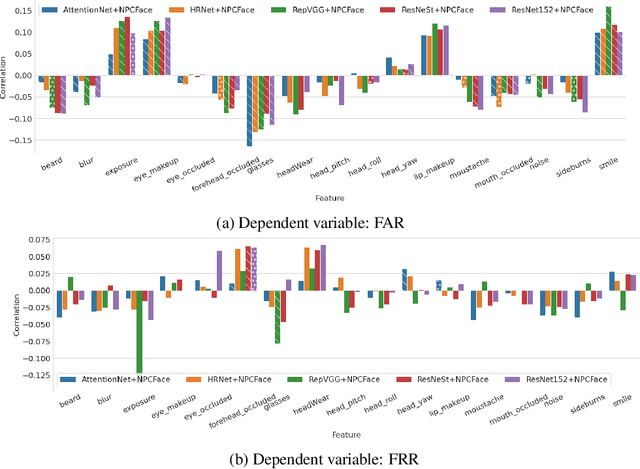
In this paper, we propose a novel explanatory framework aimed to provide a better understanding of how face recognition models perform as the underlying data characteristics (protected attributes: gender, ethnicity, age; non-protected attributes: facial hair, makeup, accessories, face orientation and occlusion, image distortion, emotions) on which they are tested change. With our framework, we evaluate ten state-of-the-art face recognition models, comparing their fairness in terms of security and usability on two data sets, involving six groups based on gender and ethnicity. We then analyze the impact of image characteristics on models performance. Our results show that trends appearing in a single-attribute analysis disappear or reverse when multi-attribute groups are considered, and that performance disparities are also related to non-protected attributes. Source code: https://cutt.ly/2XwRLiA.