 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Expression Retargeting from Human to Avatar Made Easy
Aug 12, 2020
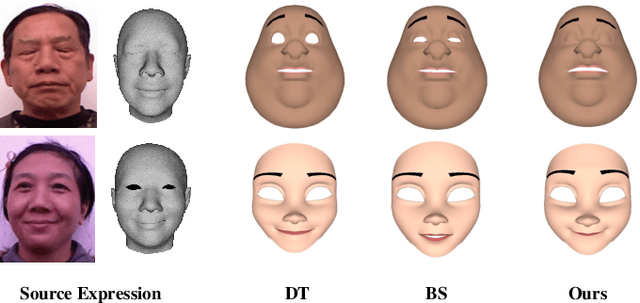

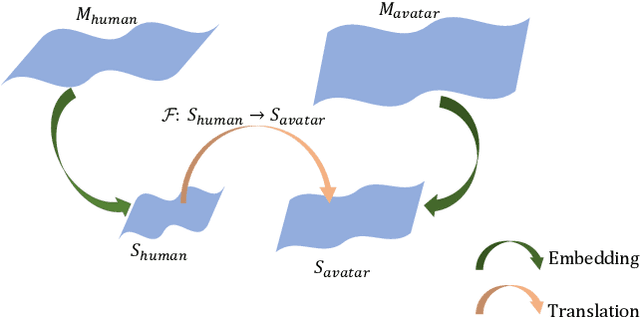
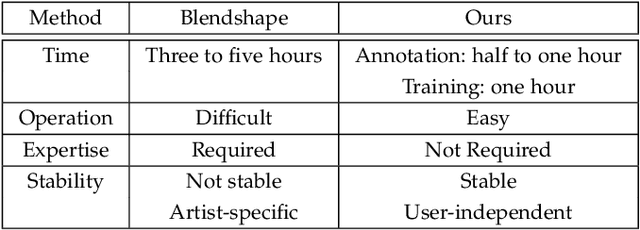
Facial expression retargeting from humans to virtual characters is a useful technique in computer graphics and animation. Traditional methods use markers or blendshapes to construct a mapping between the human and avatar faces. However, these approaches require a tedious 3D modeling process, and the performance relies on the modelers' experience. In this paper, we propose a brand-new solution to this cross-domain expression transfer problem via nonlinear expression embedding and expression domain translation. We first build low-dimensional latent spaces for the human and avatar facial expressions with variational autoencoder. Then we construct correspondences between the two latent spaces guided by geometric and perceptual constraints. Specifically, we design geometric correspondences to reflect geometric matching and utilize a triplet data structure to express users' perceptual preference of avatar expressions. A user-friendly method is proposed to automatically generate triplets for a system allowing users to easily and efficiently annotate the correspondences. Using both geometric and perceptual correspondences, we trained a network for expression domain translation from human to avatar. Extensive experimental results and user studies demonstrate that even nonprofessional users can apply our method to generate high-quality facial expression retargeting results with less time and effort.
Facial Emotions Recognition using Convolutional Neural Net
Jan 06, 2020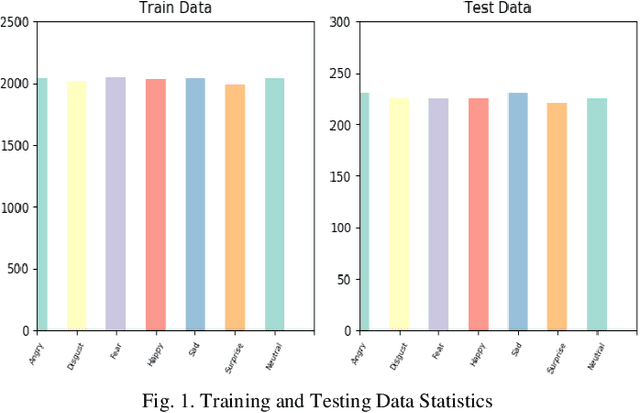
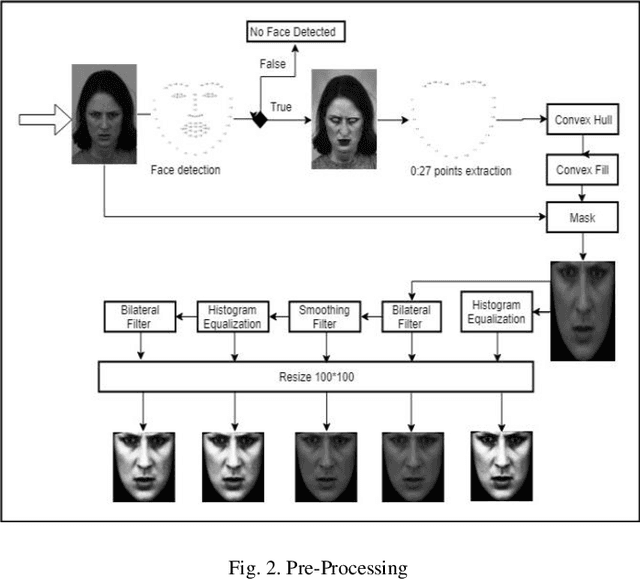

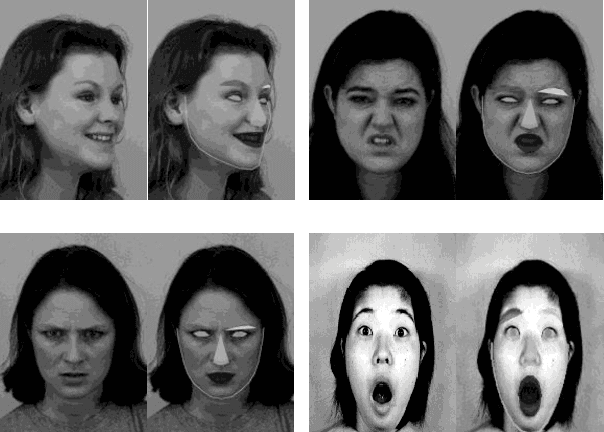
Human beings displays their emotions using facial expressions. For human it is very easy to recognize those emotions but for computer it is very challenging. Facial expressions vary from person to person. Brightness, contrast and resolution of every random image is different. This is why recognizing facial expression is very difficult. The facial expression recognition is an active research area. In this project, we worked on recognition of seven basic human emotions. These emotions are angry, disgust, fear, happy, sad, surprise and neutral. Every image was first passed through face detection algorithm to include it in train dataset. As CNN requires large amount of data so we duplicated our data using various filter on each image. The system is trained using CNN architecture. Preprocessed images of size 80*100 is passed as input to the first layer of CNN. Three convolutional layers were used, each of which was followed by a pooling layer and then three dense layers. The dropout rate for dense layer was 20%. The model was trained by combination of two publicly available datasets JAFFED and KDEF. 90% of the data was used for training while 10% was used for testing. We achieved maximum accuracy of 78% using combined dataset.
NARRATE: A Normal Assisted Free-View Portrait Stylizer
Jul 03, 2022
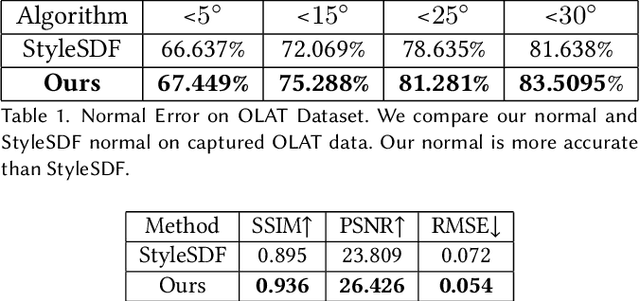
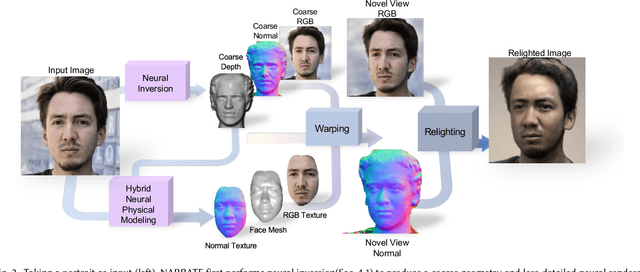
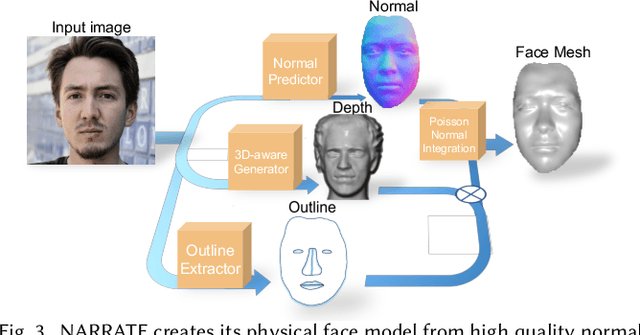
In this work, we propose NARRATE, a novel pipeline that enables simultaneously editing portrait lighting and perspective in a photorealistic manner. As a hybrid neural-physical face model, NARRATE leverages complementary benefits of geometry-aware generative approaches and normal-assisted physical face models. In a nutshell, NARRATE first inverts the input portrait to a coarse geometry and employs neural rendering to generate images resembling the input, as well as producing convincing pose changes. However, inversion step introduces mismatch, bringing low-quality images with less facial details. As such, we further estimate portrait normal to enhance the coarse geometry, creating a high-fidelity physical face model. In particular, we fuse the neural and physical renderings to compensate for the imperfect inversion, resulting in both realistic and view-consistent novel perspective images. In relighting stage, previous works focus on single view portrait relighting but ignoring consistency between different perspectives as well, leading unstable and inconsistent lighting effects for view changes. We extend Total Relighting to fix this problem by unifying its multi-view input normal maps with the physical face model. NARRATE conducts relighting with consistent normal maps, imposing cross-view constraints and exhibiting stable and coherent illumination effects. We experimentally demonstrate that NARRATE achieves more photorealistic, reliable results over prior works. We further bridge NARRATE with animation and style transfer tools, supporting pose change, light change, facial animation, and style transfer, either separately or in combination, all at a photographic quality. We showcase vivid free-view facial animations as well as 3D-aware relightable stylization, which help facilitate various AR/VR applications like virtual cinematography, 3D video conferencing, and post-production.
Real-Time Facial Expression Emoji Masking with Convolutional Neural Networks and Homography
Dec 24, 2020



Neural network based algorithms has shown success in many applications. In image processing, Convolutional Neural Networks (CNN) can be trained to categorize facial expressions of images of human faces. In this work, we create a system that masks a student's face with a emoji of the respective emotion. Our system consists of three building blocks: face detection using Histogram of Gradients (HoG) and Support Vector Machine (SVM), facial expression categorization using CNN trained on FER2013 dataset, and finally masking the respective emoji back onto the student's face via homography estimation. (Demo: https://youtu.be/GCjtXw1y8Pw) Our results show that this pipeline is deploy-able in real-time, and is usable in educational settings.
Dive into Ambiguity: Latent Distribution Mining and Pairwise Uncertainty Estimation for Facial Expression Recognition
Apr 01, 2021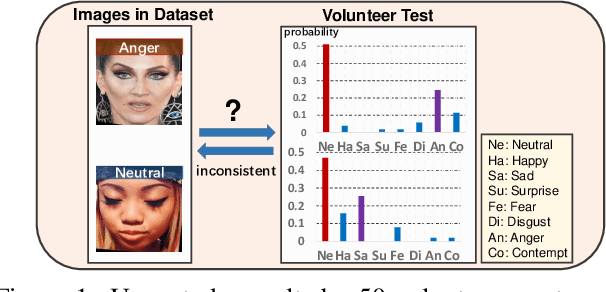
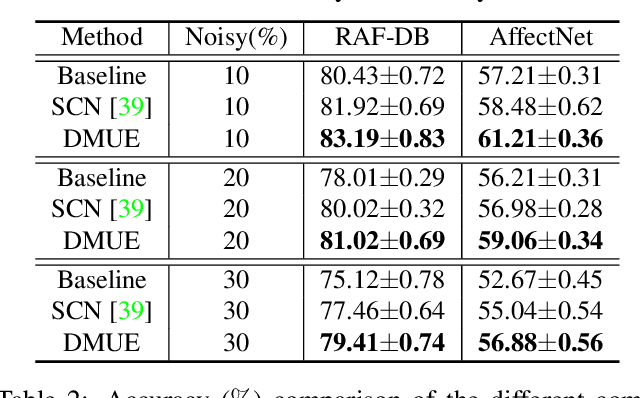
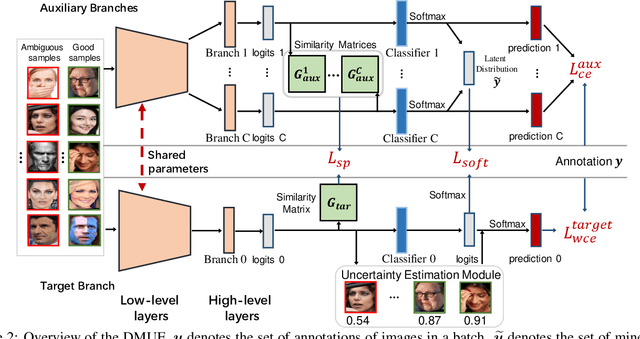
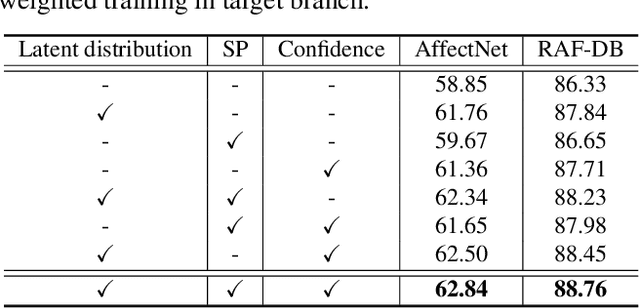
Due to the subjective annotation and the inherent interclass similarity of facial expressions, one of key challenges in Facial Expression Recognition (FER) is the annotation ambiguity. In this paper, we proposes a solution, named DMUE, to address the problem of annotation ambiguity from two perspectives: the latent Distribution Mining and the pairwise Uncertainty Estimation. For the former, an auxiliary multi-branch learning framework is introduced to better mine and describe the latent distribution in the label space. For the latter, the pairwise relationship of semantic feature between instances are fully exploited to estimate the ambiguity extent in the instance space. The proposed method is independent to the backbone architectures, and brings no extra burden for inference. The experiments are conducted on the popular real-world benchmarks and the synthetic noisy datasets. Either way, the proposed DMUE stably achieves leading performance.
Feature Level Fusion from Facial Attributes for Face Recognition
Sep 28, 2019


We introduce a deep convolutional neural networks (CNN) architecture to classify facial attributes and recognize face images simultaneously via a shared learning paradigm to improve the accuracy for facial attribute prediction and face recognition performance. In this method, we use facial attributes as an auxiliary source of information to assist CNN features extracted from the face images to improve the face recognition performance. Specifically, we use a shared CNN architecture that jointly predicts facial attributes and recognize face images simultaneously via a shared learning parameters, and then we use facial attribute features an an auxiliary source of information concatenated by face features to increase the discrimination of the CNN for face recognition. This process assists the CNN classifier to better recognize face images. The experimental results show that our model increases both the face recognition and facial attribute prediction performance, especially for the identity attributes such as gender and race. We evaluated our method on several standard datasets labeled by identities and face attributes and the results show that the proposed method outperforms state-of-the-art face recognition models.
VecGAN: Image-to-Image Translation with Interpretable Latent Directions
Jul 07, 2022
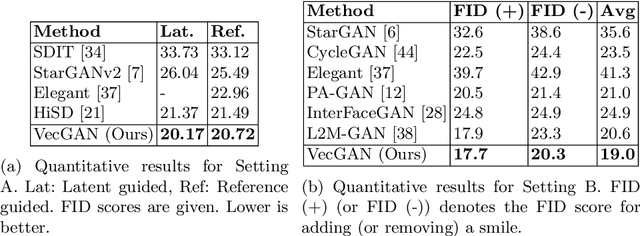
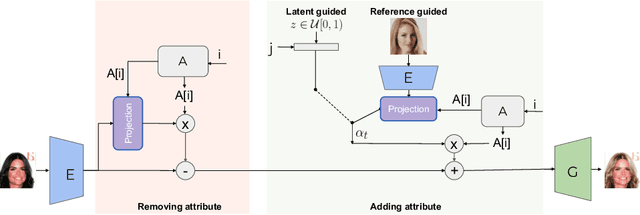

We propose VecGAN, an image-to-image translation framework for facial attribute editing with interpretable latent directions. Facial attribute editing task faces the challenges of precise attribute editing with controllable strength and preservation of the other attributes of an image. For this goal, we design the attribute editing by latent space factorization and for each attribute, we learn a linear direction that is orthogonal to the others. The other component is the controllable strength of the change, a scalar value. In our framework, this scalar can be either sampled or encoded from a reference image by projection. Our work is inspired by the latent space factorization works of fixed pretrained GANs. However, while those models cannot be trained end-to-end and struggle to edit encoded images precisely, VecGAN is end-to-end trained for image translation task and successful at editing an attribute while preserving the others. Our extensive experiments show that VecGAN achieves significant improvements over state-of-the-arts for both local and global edits.
Chronic pain patient narratives allow for the estimation of current pain intensity
Oct 31, 2022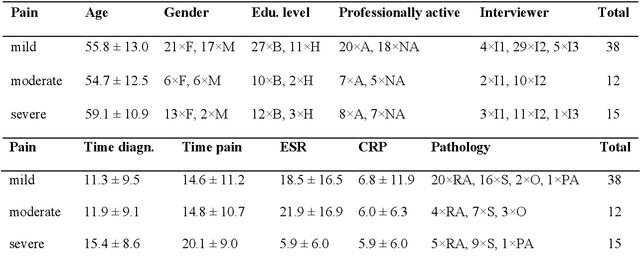
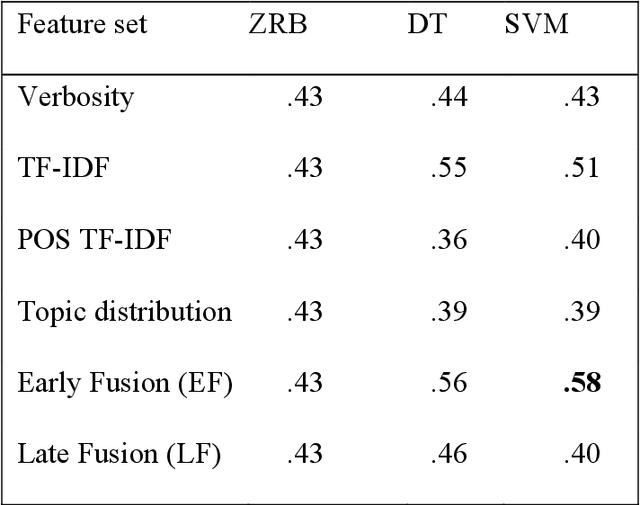

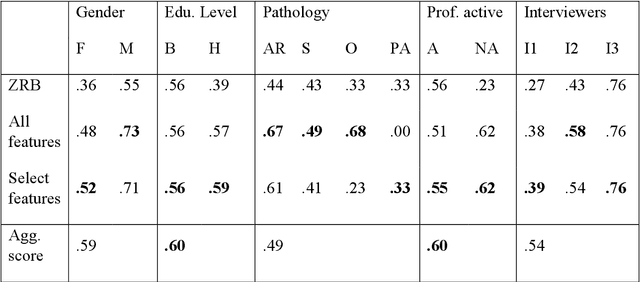
Chronic pain is a multi-dimensional experience, and pain intensity plays an important part, impacting the patients emotional balance, psychology, and behaviour. Standard self-reporting tools, such as the Visual Analogue Scale for pain, fail to capture these impacts. Moreover, these tools are susceptible to a degree of subjectivity, dependent on the patients clear understanding of how to use them, social biases, and their ability to translate a complex experience to a scale. To overcome these and other self-reporting challenges, pain intensity estimation has been previously studied based on facial expressions, electroencephalograms, brain imaging, and autonomic features. However, to the best of our knowledge, it has never been attempted to base this estimation on the patient narratives of the personal experience of chronic pain, which is what we propose in this work. Indeed, in the clinical assessment and management of chronic pain, verbal communication is essential to convey information to physicians that would otherwise not be easily accessible through standard reporting tools, since language, sociocultural, and psychosocial variables are intertwined. We show that language features from patient narratives indeed convey information relevant for pain intensity estimation, and that our computational models can take advantage of that. Specifically, our results show that patients with mild pain focus more on the use of verbs, whilst moderate and severe pain patients focus on adverbs, and nouns and adjectives, respectively, and that these differences allow for the distinction between these three pain classes.
2D+3D Facial Expression Recognition via Discriminative Dynamic Range Enhancement and Multi-Scale Learning
Nov 16, 2020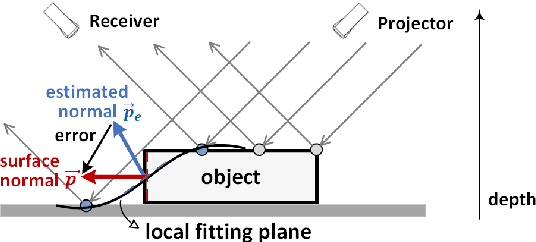
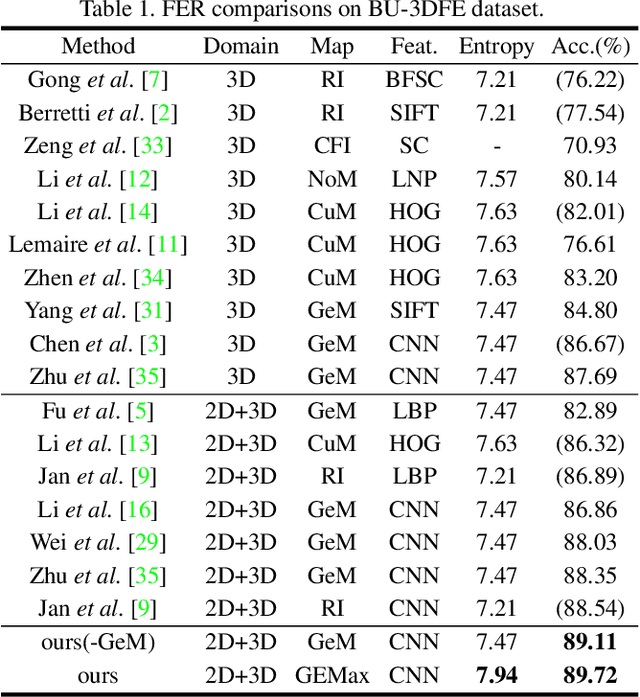
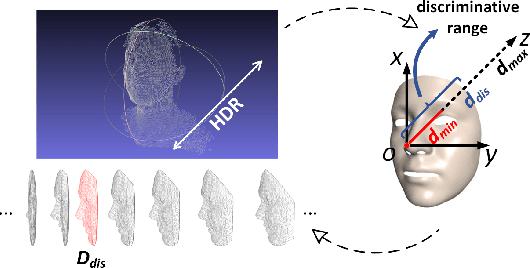
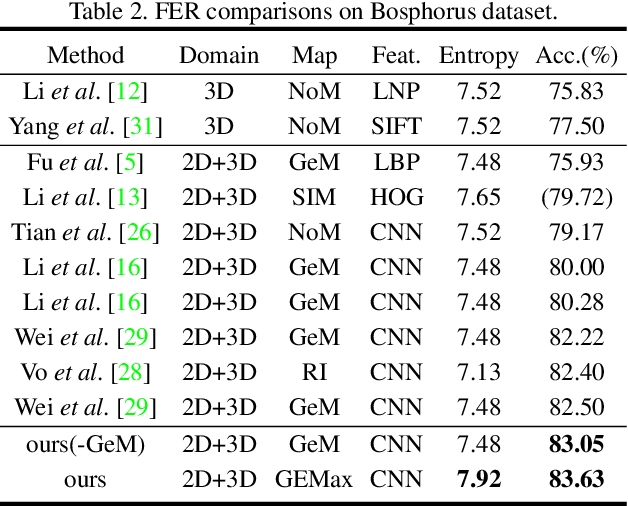
In 2D+3D facial expression recognition (FER), existing methods generate multi-view geometry maps to enhance the depth feature representation. However, this may introduce false estimations due to local plane fitting from incomplete point clouds. In this paper, we propose a novel Map Generation technique from the viewpoint of information theory, to boost the slight 3D expression differences from strong personality variations. First, we examine the HDR depth data to extract the discriminative dynamic range $r_{dis}$, and maximize the entropy of $r_{dis}$ to a global optimum. Then, to prevent the large deformation caused by over-enhancement, we introduce a depth distortion constraint and reduce the complexity from $O(KN^2)$ to $O(KN\tau)$. Furthermore, the constrained optimization is modeled as a $K$-edges maximum weight path problem in a directed acyclic graph, and we solve it efficiently via dynamic programming. Finally, we also design an efficient Facial Attention structure to automatically locate subtle discriminative facial parts for multi-scale learning, and train it with a proposed loss function $\mathcal{L}_{FA}$ without any facial landmarks. Experimental results on different datasets show that the proposed method is effective and outperforms the state-of-the-art 2D+3D FER methods in both FER accuracy and the output entropy of the generated maps.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019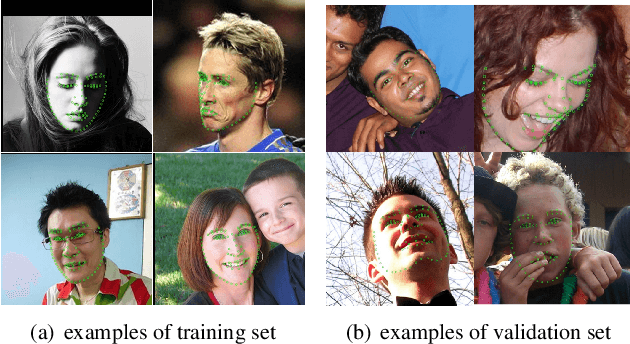
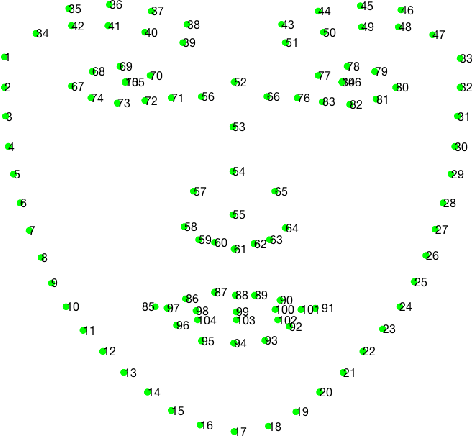

Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.