 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Chronic pain patient narratives allow for the estimation of current pain intensity
Nov 08, 2022
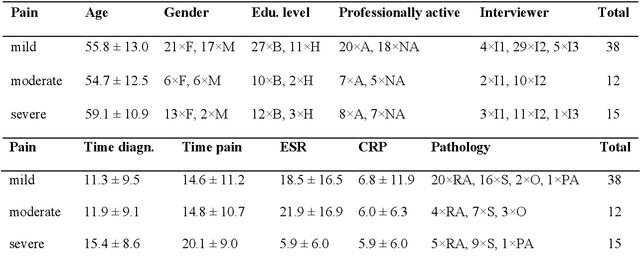
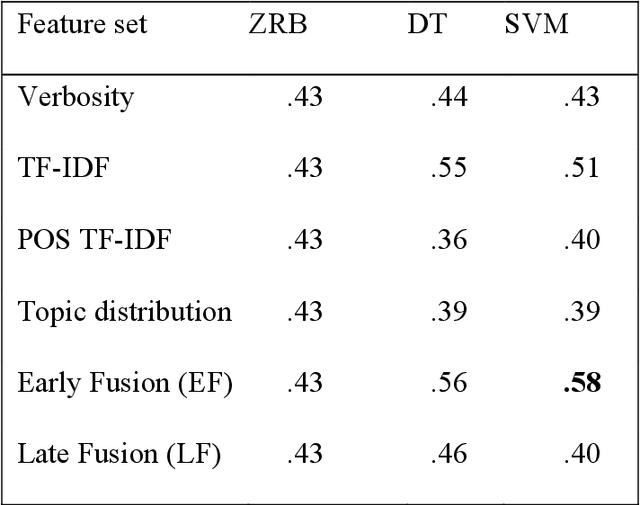

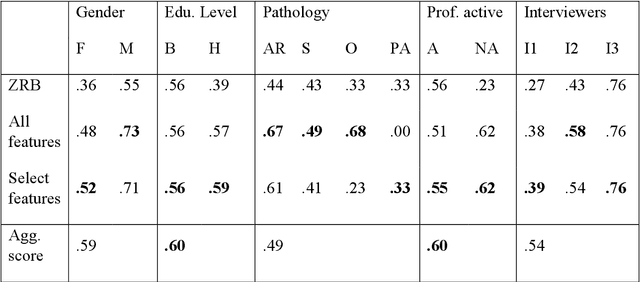
Chronic pain is a multi-dimensional experience, and pain intensity plays an important part, impacting the patients emotional balance, psychology, and behaviour. Standard self-reporting tools, such as the Visual Analogue Scale for pain, fail to capture this burden. Moreover, this type of tools is susceptible to a degree of subjectivity, dependent on the patients clear understanding of how to use it, social biases, and their ability to translate a complex experience to a scale. To overcome these and other self-reporting challenges, pain intensity estimation has been previously studied based on facial expressions, electroencephalograms, brain imaging, and autonomic features. However, to the best of our knowledge, it has never been attempted to base this estimation on the patient narratives of the personal experience of chronic pain, which is what we propose in this work. Indeed, in the clinical assessment and management of chronic pain, verbal communication is essential to convey information to physicians that would otherwise not be easily accessible through standard reporting tools, since language, sociocultural, and psychosocial variables are intertwined. We show that language features from patient narratives indeed convey information relevant for pain intensity estimation, and that our computational models can take advantage of that. Specifically, our results show that patients with mild pain focus more on the use of verbs, whilst moderate and severe pain patients focus on adverbs, and nouns and adjectives, respectively, and that these differences allow for the distinction between these three pain classes.
Can GAN-induced Attribute Manipulations Impact Face Recognition?
Sep 07, 2022
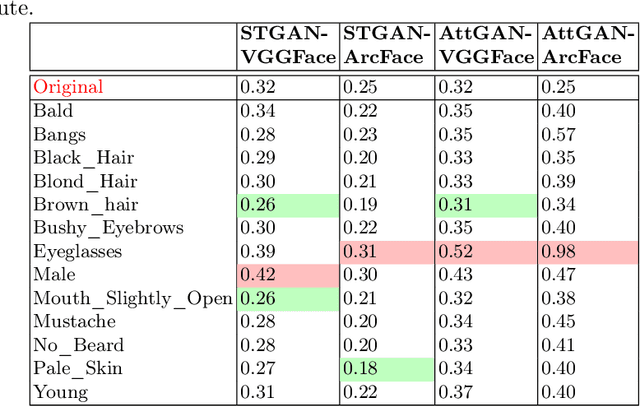
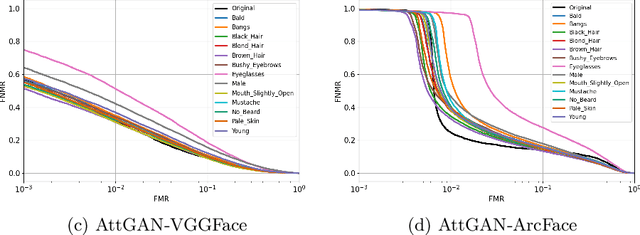
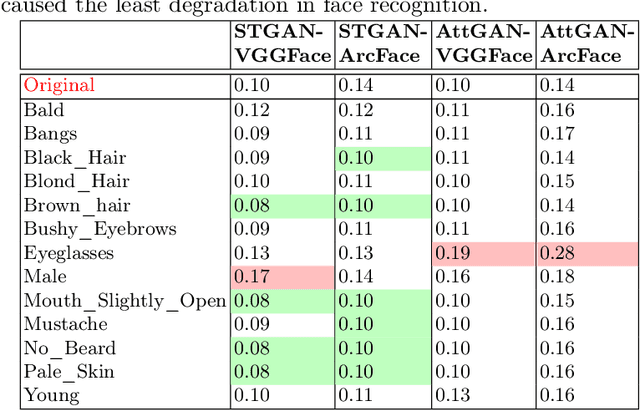
Impact due to demographic factors such as age, sex, race, etc., has been studied extensively in automated face recognition systems. However, the impact of \textit{digitally modified} demographic and facial attributes on face recognition is relatively under-explored. In this work, we study the effect of attribute manipulations induced via generative adversarial networks (GANs) on face recognition performance. We conduct experiments on the CelebA dataset by intentionally modifying thirteen attributes using AttGAN and STGAN and evaluating their impact on two deep learning-based face verification methods, ArcFace and VGGFace. Our findings indicate that some attribute manipulations involving eyeglasses and digital alteration of sex cues can significantly impair face recognition by up to 73% and need further analysis.
Seeing is Living? Rethinking the Security of Facial Liveness Verification in the Deepfake Era
Feb 22, 2022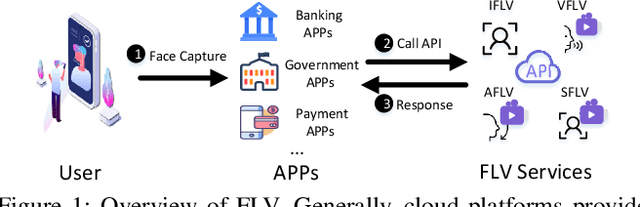
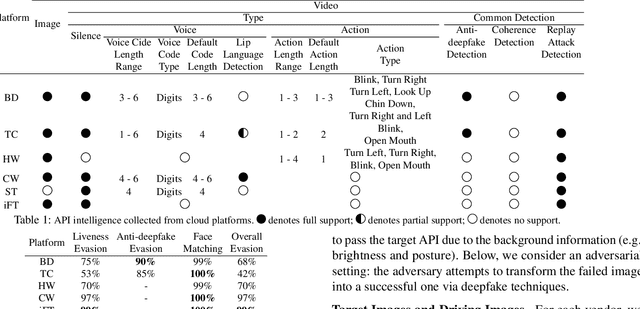
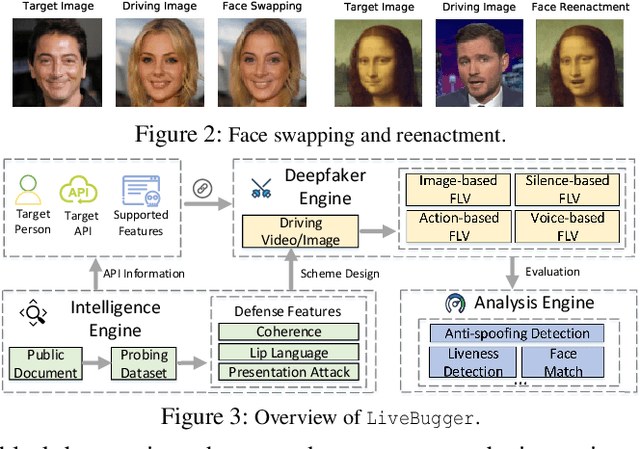

Facial Liveness Verification (FLV) is widely used for identity authentication in many security-sensitive domains and offered as Platform-as-a-Service (PaaS) by leading cloud vendors. Yet, with the rapid advances in synthetic media techniques (e.g., deepfake), the security of FLV is facing unprecedented challenges, about which little is known thus far. To bridge this gap, in this paper, we conduct the first systematic study on the security of FLV in real-world settings. Specifically, we present LiveBugger, a new deepfake-powered attack framework that enables customizable, automated security evaluation of FLV. Leveraging LiveBugger, we perform a comprehensive empirical assessment of representative FLV platforms, leading to a set of interesting findings. For instance, most FLV APIs do not use anti-deepfake detection; even for those with such defenses, their effectiveness is concerning (e.g., it may detect high-quality synthesized videos but fail to detect low-quality ones). We then conduct an in-depth analysis of the factors impacting the attack performance of LiveBugger: a) the bias (e.g., gender or race) in FLV can be exploited to select victims; b) adversarial training makes deepfake more effective to bypass FLV; c) the input quality has a varying influence on different deepfake techniques to bypass FLV. Based on these findings, we propose a customized, two-stage approach that can boost the attack success rate by up to 70%. Further, we run proof-of-concept attacks on several representative applications of FLV (i.e., the clients of FLV APIs) to illustrate the practical implications: due to the vulnerability of the APIs, many downstream applications are vulnerable to deepfake. Finally, we discuss potential countermeasures to improve the security of FLV. Our findings have been confirmed by the corresponding vendors.
Dynamic Facial Expression Recognition under Partial Occlusion with Optical Flow Reconstruction
Dec 24, 2020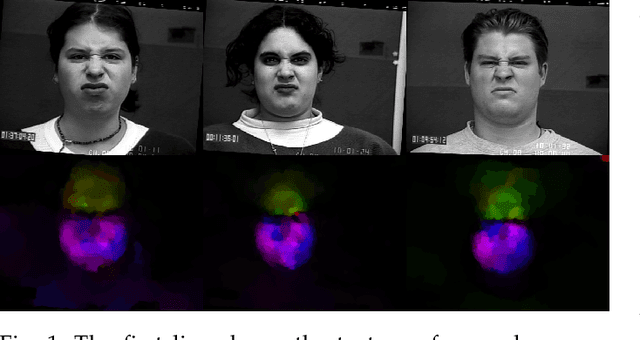
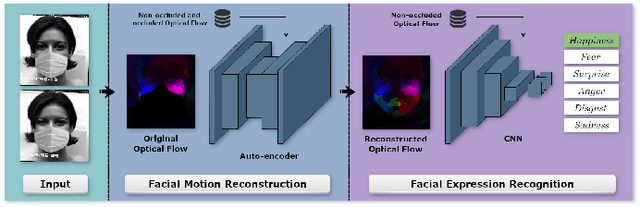
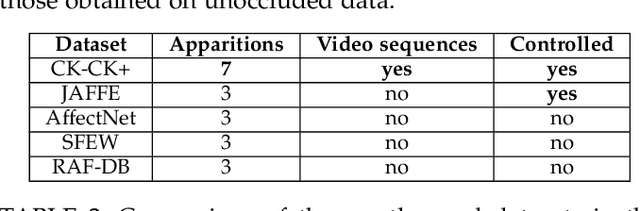
Video facial expression recognition is useful for many applications and received much interest lately. Although some solutions give really good results in a controlled environment (no occlusion), recognition in the presence of partial facial occlusion remains a challenging task. To handle occlusions, solutions based on the reconstruction of the occluded part of the face have been proposed. These solutions are mainly based on the texture or the geometry of the face. However, the similarity of the face movement between different persons doing the same expression seems to be a real asset for the reconstruction. In this paper we exploit this asset and propose a new solution based on an auto-encoder with skip connections to reconstruct the occluded part of the face in the optical flow domain. To the best of our knowledge, this is the first proposition to directly reconstruct the movement for facial expression recognition. We validated our approach in the controlled dataset CK+ on which different occlusions were generated. Our experiments show that the proposed method reduce significantly the gap, in terms of recognition accuracy, between occluded and non-occluded situations. We also compare our approach with existing state-of-the-art solutions. In order to lay the basis of a reproducible and fair comparison in the future, we also propose a new experimental protocol that includes occlusion generation and reconstruction evaluation.
Evons: A Dataset for Fake and Real News Virality Analysis and Prediction
Sep 16, 2022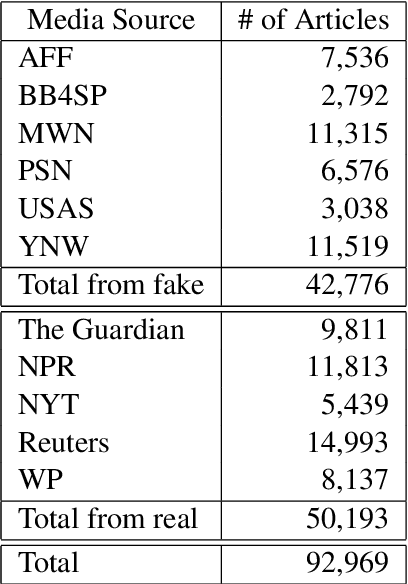
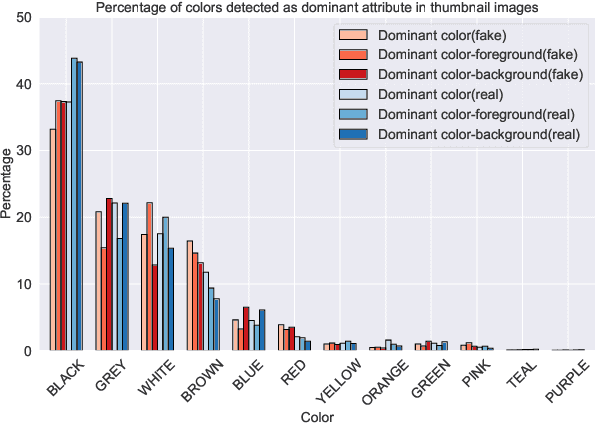

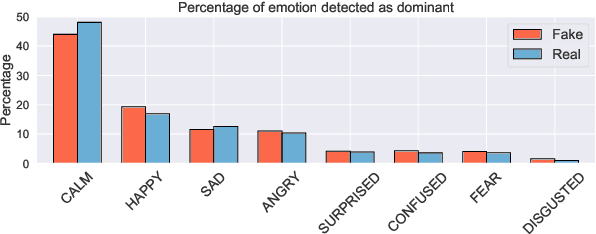
We present a novel collection of news articles originating from fake and real news media sources for the analysis and prediction of news virality. Unlike existing fake news datasets which either contain claims or news article headline and body, in this collection each article is supported with a Facebook engagement count which we consider as an indicator of the article virality. In addition we also provide the article description and thumbnail image with which the article was shared on Facebook. These images were automatically annotated with object tags and color attributes. Using cloud based vision analysis tools, thumbnail images were also analyzed for faces and detected faces were annotated with facial attributes. We empirically investigate the use of this collection on an example task of article virality prediction.
Generative Neural Articulated Radiance Fields
Jun 28, 2022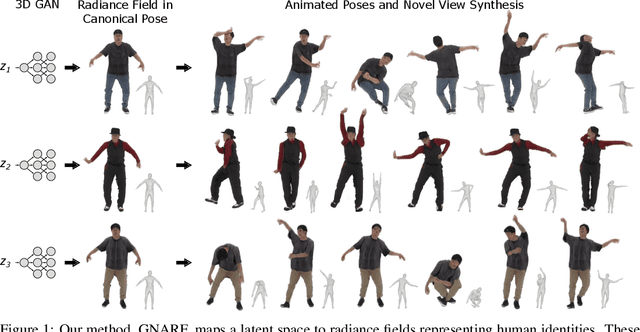
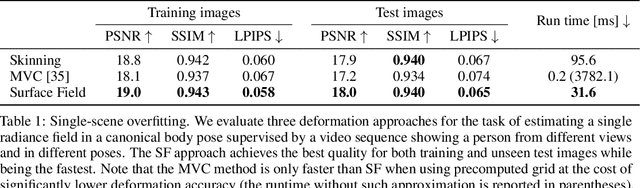
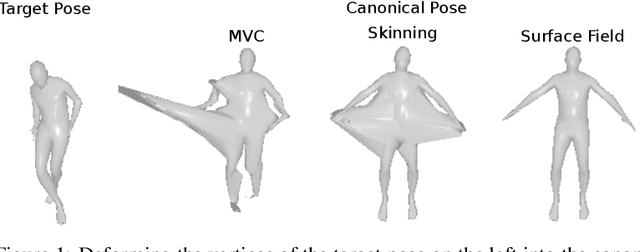
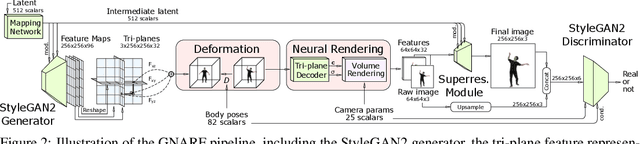
Unsupervised learning of 3D-aware generative adversarial networks (GANs) using only collections of single-view 2D photographs has very recently made much progress. These 3D GANs, however, have not been demonstrated for human bodies and the generated radiance fields of existing frameworks are not directly editable, limiting their applicability in downstream tasks. We propose a solution to these challenges by developing a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression. Using our framework, we demonstrate the first high-quality radiance field generation results for human bodies. Moreover, we show that our deformation-aware training procedure significantly improves the quality of generated bodies or faces when editing their poses or facial expressions compared to a 3D GAN that is not trained with explicit deformations.
Towards Inclusive HRI: Using Sim2Real to Address Underrepresentation in Emotion Expression Recognition
Aug 15, 2022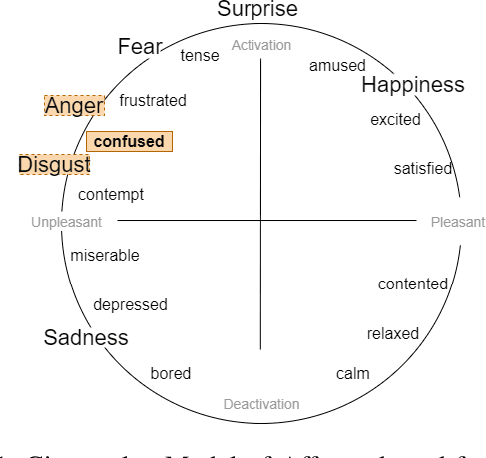



Robots and artificial agents that interact with humans should be able to do so without bias and inequity, but facial perception systems have notoriously been found to work more poorly for certain groups of people than others. In our work, we aim to build a system that can perceive humans in a more transparent and inclusive manner. Specifically, we focus on dynamic expressions on the human face, which are difficult to collect for a broad set of people due to privacy concerns and the fact that faces are inherently identifiable. Furthermore, datasets collected from the Internet are not necessarily representative of the general population. We address this problem by offering a Sim2Real approach in which we use a suite of 3D simulated human models that enables us to create an auditable synthetic dataset covering 1) underrepresented facial expressions, outside of the six basic emotions, such as confusion; 2) ethnic or gender minority groups; and 3) a wide range of viewing angles that a robot may encounter a human in the real world. By augmenting a small dynamic emotional expression dataset containing 123 samples with a synthetic dataset containing 4536 samples, we achieved an improvement in accuracy of 15% on our own dataset and 11% on an external benchmark dataset, compared to the performance of the same model architecture without synthetic training data. We also show that this additional step improves accuracy specifically for racial minorities when the architecture's feature extraction weights are trained from scratch.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021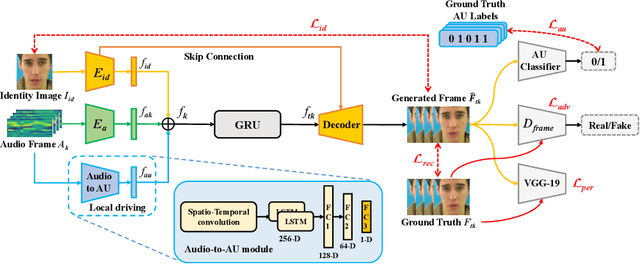
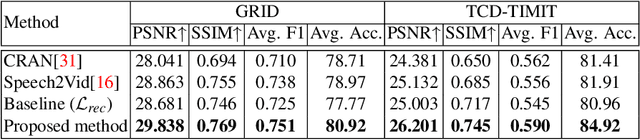


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.
Facial Emotions Recognition using Convolutional Neural Net
Jan 06, 2020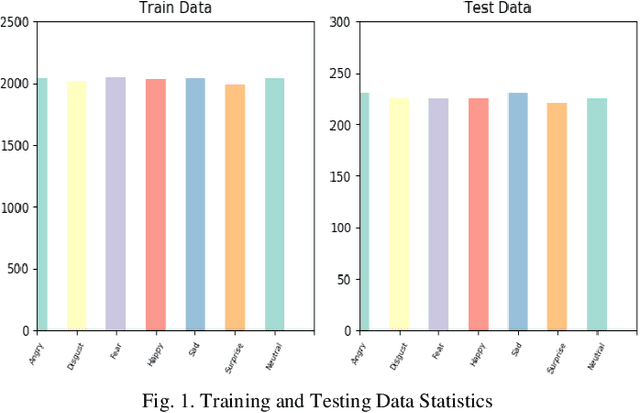
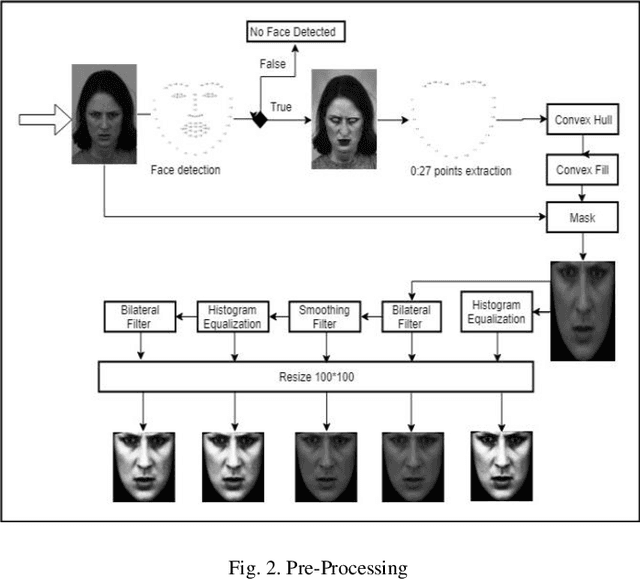

Human beings displays their emotions using facial expressions. For human it is very easy to recognize those emotions but for computer it is very challenging. Facial expressions vary from person to person. Brightness, contrast and resolution of every random image is different. This is why recognizing facial expression is very difficult. The facial expression recognition is an active research area. In this project, we worked on recognition of seven basic human emotions. These emotions are angry, disgust, fear, happy, sad, surprise and neutral. Every image was first passed through face detection algorithm to include it in train dataset. As CNN requires large amount of data so we duplicated our data using various filter on each image. The system is trained using CNN architecture. Preprocessed images of size 80*100 is passed as input to the first layer of CNN. Three convolutional layers were used, each of which was followed by a pooling layer and then three dense layers. The dropout rate for dense layer was 20%. The model was trained by combination of two publicly available datasets JAFFED and KDEF. 90% of the data was used for training while 10% was used for testing. We achieved maximum accuracy of 78% using combined dataset.
Facial Expression Retargeting from Human to Avatar Made Easy
Aug 12, 2020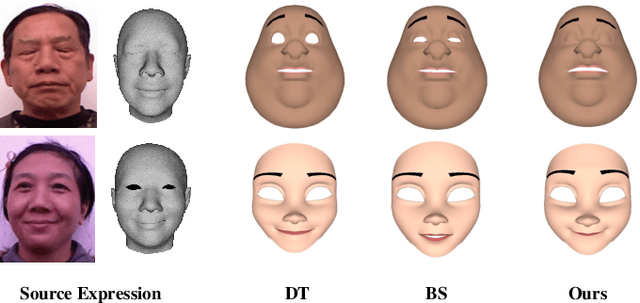

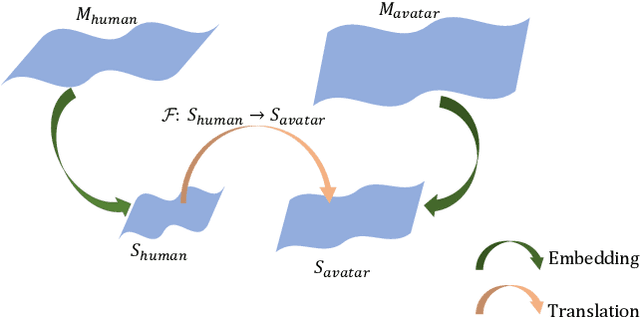
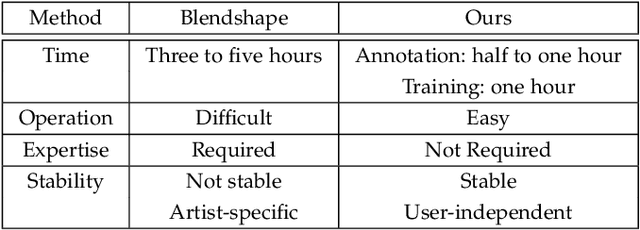
Facial expression retargeting from humans to virtual characters is a useful technique in computer graphics and animation. Traditional methods use markers or blendshapes to construct a mapping between the human and avatar faces. However, these approaches require a tedious 3D modeling process, and the performance relies on the modelers' experience. In this paper, we propose a brand-new solution to this cross-domain expression transfer problem via nonlinear expression embedding and expression domain translation. We first build low-dimensional latent spaces for the human and avatar facial expressions with variational autoencoder. Then we construct correspondences between the two latent spaces guided by geometric and perceptual constraints. Specifically, we design geometric correspondences to reflect geometric matching and utilize a triplet data structure to express users' perceptual preference of avatar expressions. A user-friendly method is proposed to automatically generate triplets for a system allowing users to easily and efficiently annotate the correspondences. Using both geometric and perceptual correspondences, we trained a network for expression domain translation from human to avatar. Extensive experimental results and user studies demonstrate that even nonprofessional users can apply our method to generate high-quality facial expression retargeting results with less time and effort.