 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Improving User's Sense of Participation in Robot-Driven Dialogue
Oct 18, 2022

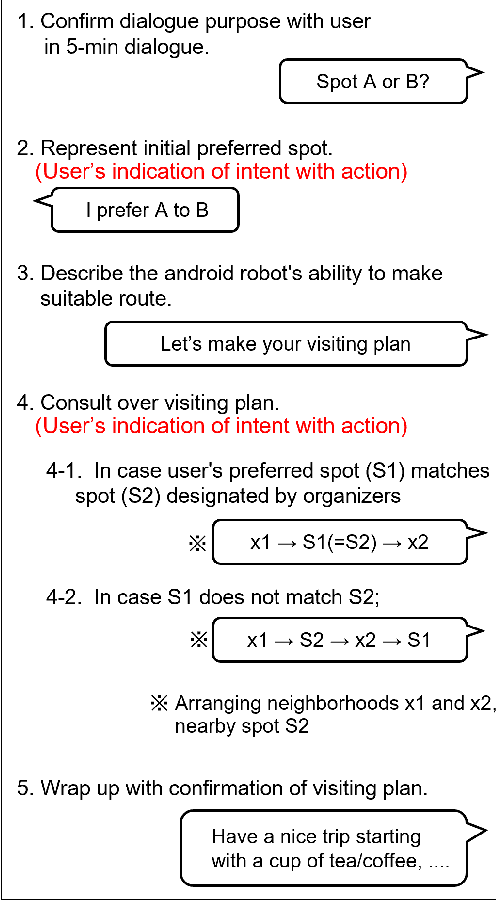
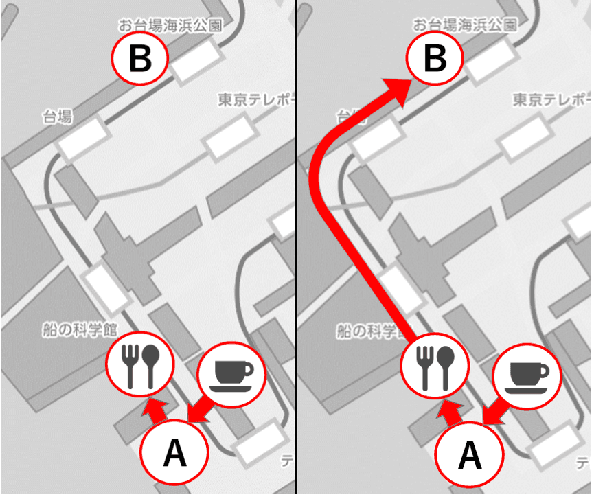
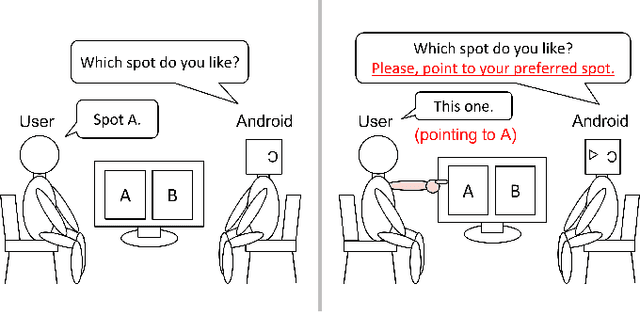
In task-oriented dialogues with symbiotic robots, the robot usually takes the initiative in dialogue progression and topic selection. In such robot-driven dialogue, the user's sense of participation in the dialogue is reduced because the degree of freedom in timing and content of speech is limited, and as a result, the user's familiarity with and trust in the robot as a dialogue partner and the level of dialogue satisfaction decrease. In this study, we constructed a travel agent dialogue system focusing on improving the sense of dialogue participation. At the beginning of the dialogue, the robot tells the user the purpose of the upcoming dialogue and indicates that it is responsible for assisting the user in making decisions. In addition, in situations where users were asked to state their preferences, the robot encourages them to express their intentions with actions, as well as spoken language responses. In addition, we attempted to reduce the sense of discomfort felt toward the android robot by devising a timing control for the robot's detailed movements and facial expressions.
Consensual Collaborative Training And Knowledge Distillation Based Facial Expression Recognition Under Noisy Annotations
Jul 10, 2021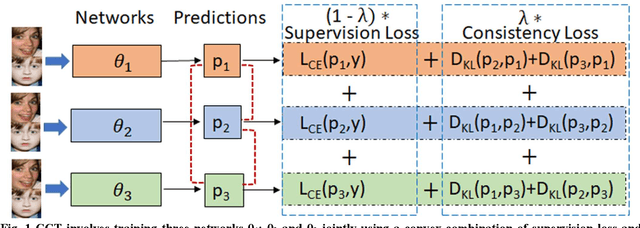
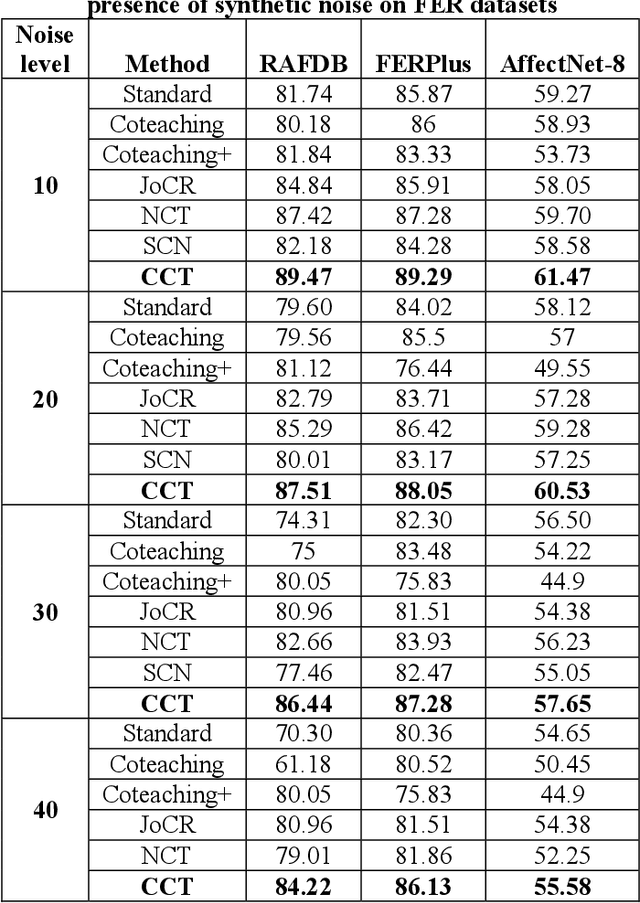
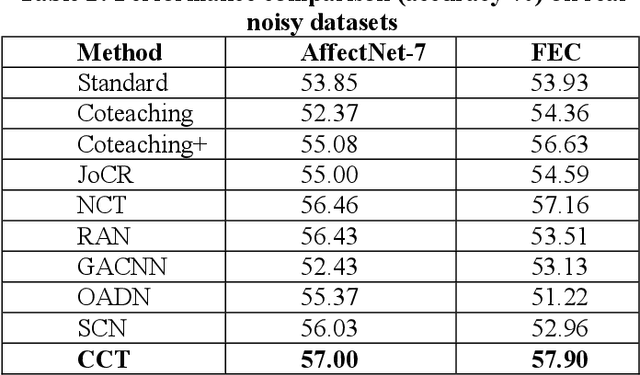
Presence of noise in the labels of large scale facial expression datasets has been a key challenge towards Facial Expression Recognition (FER) in the wild. During early learning stage, deep networks fit on clean data. Then, eventually, they start overfitting on noisy labels due to their memorization ability, which limits FER performance. This work proposes an effective training strategy in the presence of noisy labels, called as Consensual Collaborative Training (CCT) framework. CCT co-trains three networks jointly using a convex combination of supervision loss and consistency loss, without making any assumption about the noise distribution. A dynamic transition mechanism is used to move from supervision loss in early learning to consistency loss for consensus of predictions among networks in the later stage. Inference is done using a single network based on a simple knowledge distillation scheme. Effectiveness of the proposed framework is demonstrated on synthetic as well as real noisy FER datasets. In addition, a large test subset of around 5K images is annotated from the FEC dataset using crowd wisdom of 16 different annotators and reliable labels are inferred. CCT is also validated on it. State-of-the-art performance is reported on the benchmark FER datasets RAFDB (90.84%) FERPlus (89.99%) and AffectNet (66%). Our codes are available at https://github.com/1980x/CCT.
* 11 pages, 6 figures, Published with International Journal of Engineering Trends and Technology (IJETT), Codes: https://github.com/1980x/CCT
Usability of a Robot's Realistic Facial Expressions and Peripherals in Autistic Children's Therapy
Jul 23, 2020



Robot-assisted therapy is an emerging form of therapy for autistic children, although designing effective robot behaviors is a challenge for effective implementation of such therapy. A series of usability tests assessed trends in the effectiveness of modelling a robot's facial expressions on realistic facial expressions and of adding peripherals enabling child-led control of emotion learning activities with autistic children. Nineteen autistic children interacted with a small humanoid robot and an adult therapist in several emotion-learning activities that featured realistic facial expressions modelled on either a pre-existing database or live facial mirroring, and that used peripherals (tablets or tangible 'squishies') to enable child-led activities. Both types of realistic facial expressions by the robot were less effective than exaggerated expressions, with the mirroring being unintuitive for children. The tablet was usable but required more feedback and lower latency, while the tactile tangibles were engaging aids.
Self-supervised Deformation Modeling for Facial Expression Editing
Nov 05, 2019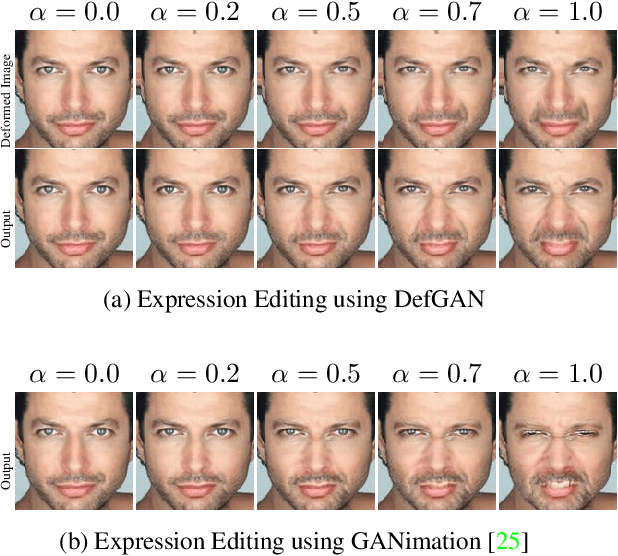

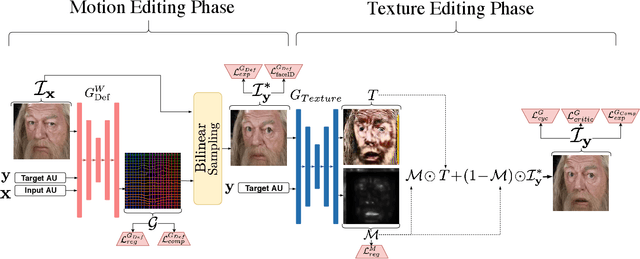
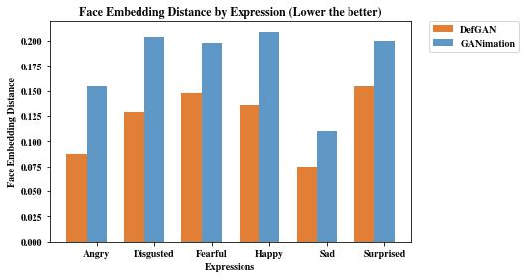
Recent advances in deep generative models have demonstrated impressive results in photo-realistic facial image synthesis and editing. Facial expressions are inherently the result of muscle movement. However, existing neural network-based approaches usually only rely on texture generation to edit expressions and largely neglect the motion information. In this work, we propose a novel end-to-end network that disentangles the task of facial editing into two steps: a " "motion-editing" step and a "texture-editing" step. In the "motion-editing" step, we explicitly model facial movement through image deformation, warping the image into the desired expression. In the "texture-editing" step, we generate necessary textures, such as teeth and shading effects, for a photo-realistic result. Our physically-based task-disentanglement system design allows each step to learn a focused task, removing the need of generating texture to hallucinate motion. Our system is trained in a self-supervised manner, requiring no ground truth deformation annotation. Using Action Units [8] as the representation for facial expression, our method improves the state-of-the-art facial expression editing performance in both qualitative and quantitative evaluations.
RAF-AU Database: In-the-Wild Facial Expressions with Subjective Emotion Judgement and Objective AU Annotations
Aug 12, 2020
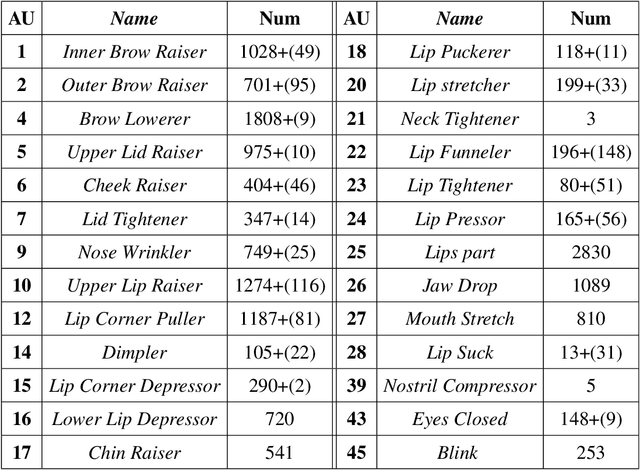

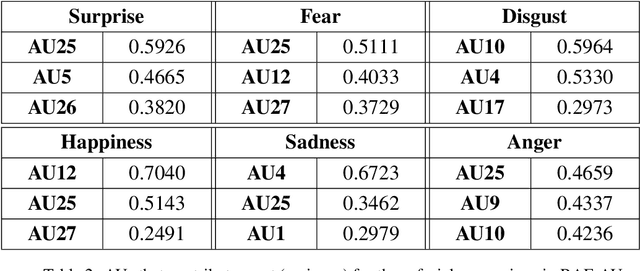
Much of the work on automatic facial expression recognition relies on databases containing a certain number of emotion classes and their exaggerated facial configurations (generally six prototypical facial expressions), based on Ekman's Basic Emotion Theory. However, recent studies have revealed that facial expressions in our human life can be blended with multiple basic emotions. And the emotion labels for these in-the-wild facial expressions cannot easily be annotated solely on pre-defined AU patterns. How to analyze the action units for such complex expressions is still an open question. To address this issue, we develop a RAF-AU database that employs a sign-based (i.e., AUs) and judgement-based (i.e., perceived emotion) approach to annotating blended facial expressions in the wild. We first reviewed the annotation methods in existing databases and identified crowdsourcing as a promising strategy for labeling in-the-wild facial expressions. Then, RAF-AU was finely annotated by experienced coders, on which we also conducted a preliminary investigation of which key AUs contribute most to a perceived emotion, and the relationship between AUs and facial expressions. Finally, we provided a baseline for AU recognition in RAF-AU using popular features and multi-label learning methods.
A Survey to Deep Facial Attribute Analysis
Dec 26, 2018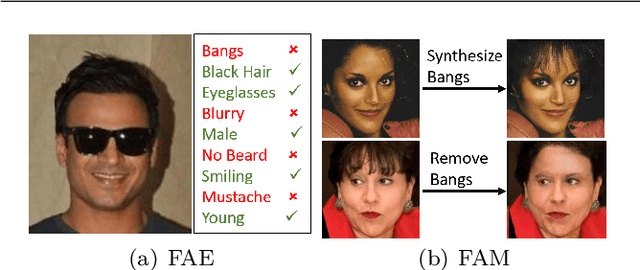
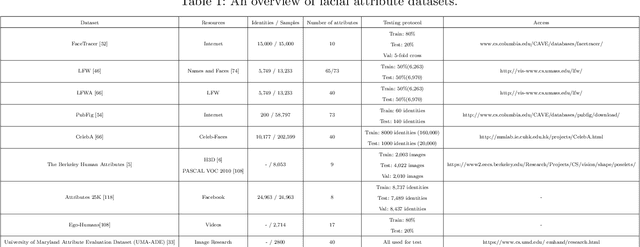
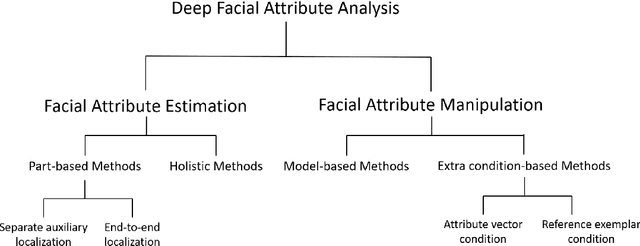
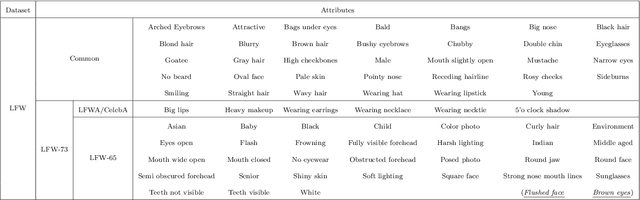
Facial attribute analysis has received considerable attention with the development of deep neural networks in the past few years. Facial attribute analysis contains two crucial issues: Facial Attribute Estimation (FAE), which recognizes whether facial attributes are present in given images, and Facial Attribute Manipulation (FAM), which synthesizes or removes desired facial attributes. In this paper, we provide a comprehensive survey on deep facial attribute analysis covering FAE and FAM. First, we present the basic knowledge of the two stages (i.e., data pre-processing and model construction) in the general deep facial attribute analysis pipeline. Second, we summarize the commonly used datasets and performance metrics. Third, we create a taxonomy of the state-of-the-arts and review detailed algorithms in FAE and FAM, respectively. Furthermore, we introduce several additional facial attribute related issues and applications. Finally, the possible challenges and future research directions are discussed.
Compressing Facial Makeup Transfer Networks by Collaborative Distillation and Kernel Decomposition
Sep 16, 2020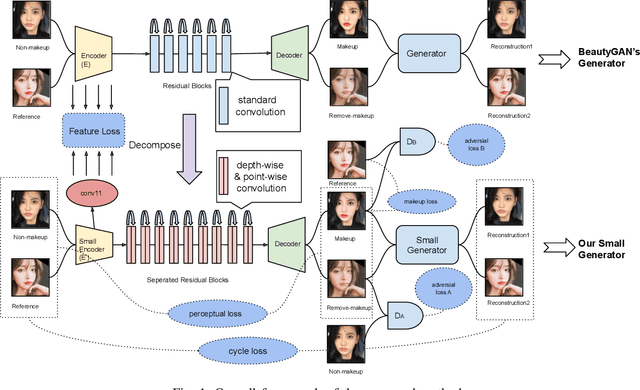
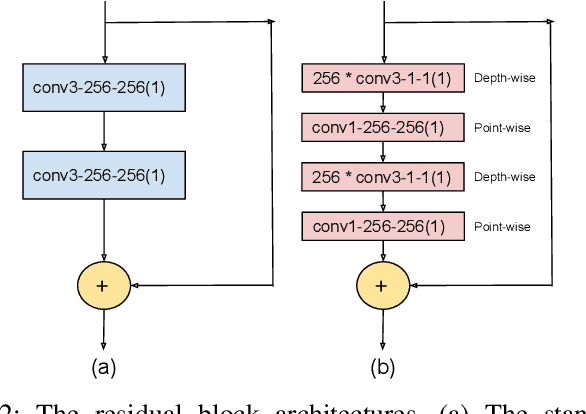


Although the facial makeup transfer network has achieved high-quality performance in generating perceptually pleasing makeup images, its capability is still restricted by the massive computation and storage of the network architecture. We address this issue by compressing facial makeup transfer networks with collaborative distillation and kernel decomposition. The main idea of collaborative distillation is underpinned by a finding that the encoder-decoder pairs construct an exclusive collaborative relationship, which is regarded as a new kind of knowledge for low-level vision tasks. For kernel decomposition, we apply the depth-wise separation of convolutional kernels to build a light-weighted Convolutional Neural Network (CNN) from the original network. Extensive experiments show the effectiveness of the compression method when applied to the state-of-the-art facial makeup transfer network -- BeautyGAN.
Unsupervised Learning Facial Parameter Regressor for Action Unit Intensity Estimation via Differentiable Renderer
Aug 20, 2020
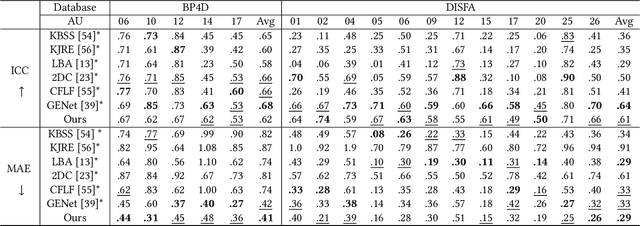
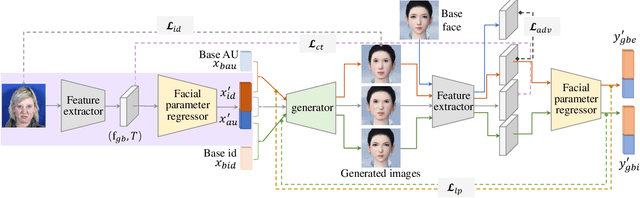

Facial action unit (AU) intensity is an index to describe all visually discernible facial movements. Most existing methods learn intensity estimator with limited AU data, while they lack generalization ability out of the dataset. In this paper, we present a framework to predict the facial parameters (including identity parameters and AU parameters) based on a bone-driven face model (BDFM) under different views. The proposed framework consists of a feature extractor, a generator, and a facial parameter regressor. The regressor can fit the physical meaning parameters of the BDFM from a single face image with the help of the generator, which maps the facial parameters to the game-face images as a differentiable renderer. Besides, identity loss, loopback loss, and adversarial loss can improve the regressive results. Quantitative evaluations are performed on two public databases BP4D and DISFA, which demonstrates that the proposed method can achieve comparable or better performance than the state-of-the-art methods. What's more, the qualitative results also demonstrate the validity of our method in the wild.
Attribute Controllable Beautiful Caucasian Face Generation by Aesthetics Driven Reinforcement Learning
Aug 09, 2022
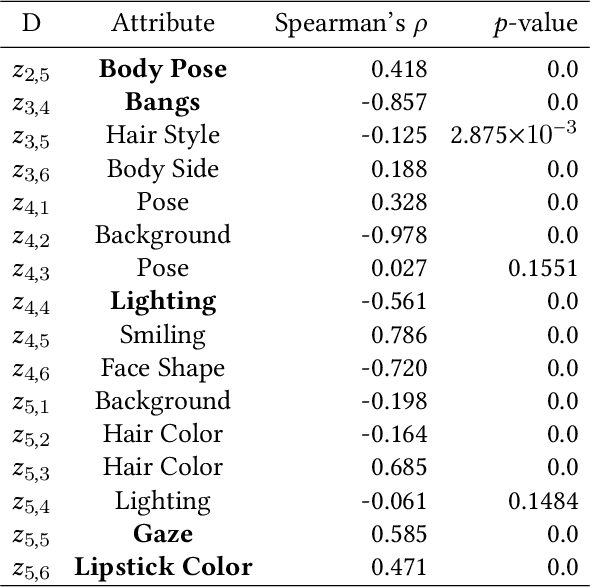
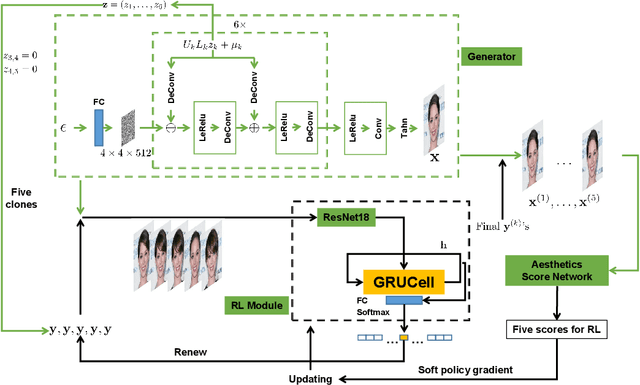
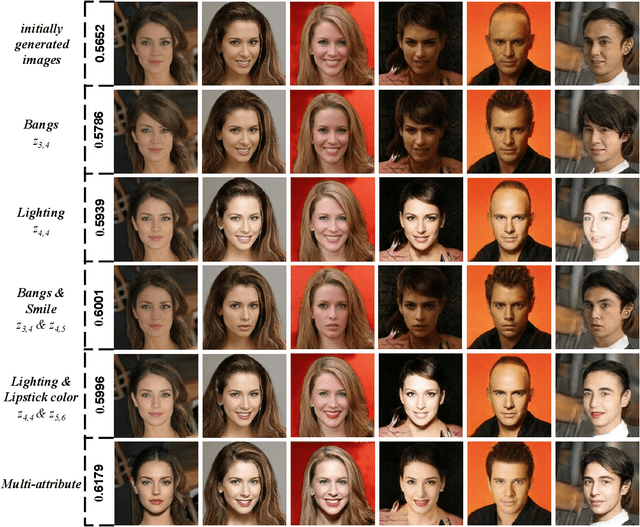
In recent years, image generation has made great strides in improving the quality of images, producing high-fidelity ones. Also, quite recently, there are architecture designs, which enable GAN to unsupervisedly learn the semantic attributes represented in different layers. However, there is still a lack of research on generating face images more consistent with human aesthetics. Based on EigenGAN [He et al., ICCV 2021], we build the techniques of reinforcement learning into the generator of EigenGAN. The agent tries to figure out how to alter the semantic attributes of the generated human faces towards more preferable ones. To accomplish this, we trained an aesthetics scoring model that can conduct facial beauty prediction. We also can utilize this scoring model to analyze the correlation between face attributes and aesthetics scores. Empirically, using off-the-shelf techniques from reinforcement learning would not work well. So instead, we present a new variant incorporating the ingredients emerging in the reinforcement learning communities in recent years. Compared to the original generated images, the adjusted ones show clear distinctions concerning various attributes. Experimental results using the MindSpore, show the effectiveness of the proposed method. Altered facial images are commonly more attractive, with significantly improved aesthetic levels.
Realistic, Animatable Human Reconstructions for Virtual Fit-On
Oct 16, 2022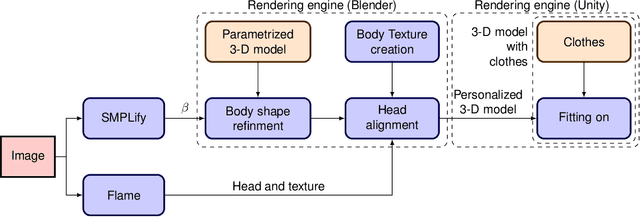
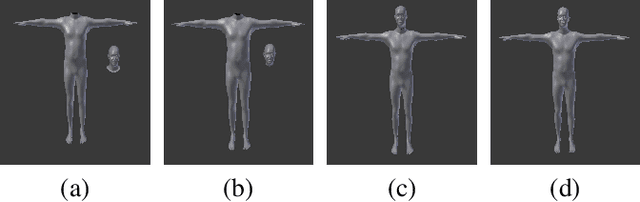
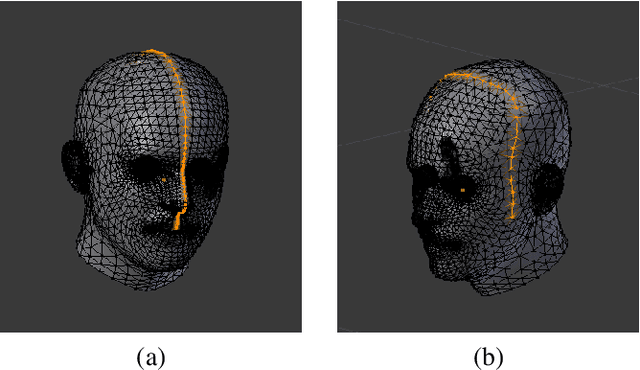

We present an end-to-end virtual try-on pipeline, that can fit different clothes on a personalized 3-D human model, reconstructed using a single RGB image. Our main idea is to construct an animatable 3-D human model and try-on different clothes in a 3-D virtual environment. The existing frame by frame volumetric reconstruction of 3-D human models are highly resource-demanding and do not allow clothes switching. Moreover, existing virtual fit-on systems also lack realism due to predominantly being 2-D or not using user's features in the reconstruction. These shortcomings are due to either the human body or clothing model being 2-D or not having the user's facial features in the dressed model. We solve these problems by manipulating a parametric representation of the 3-D human body model and stitching a head model reconstructed from the actual image. Fitting the 3-D clothing models on the parameterized human model is also adjustable to the body shape of the input image. Our reconstruction results, in comparison with recent existing work, are more visually-pleasing.