 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Landmark-Aware and Part-based Ensemble Transfer Learning Network for Facial Expression Recognition from Static images
Apr 22, 2021
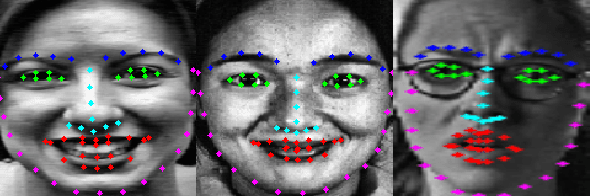
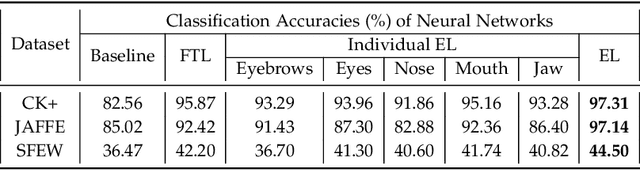

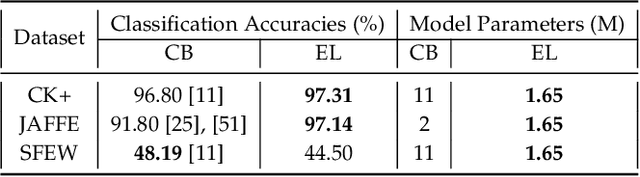
Facial Expression Recognition from static images is a challenging problem in computer vision applications. Convolutional Neural Network (CNN), the state-of-the-art method for various computer vision tasks, has had limited success in predicting expressions from faces having extreme poses, illumination, and occlusion conditions. To mitigate this issue, CNNs are often accompanied by techniques like transfer, multi-task, or ensemble learning that often provide high accuracy at the cost of high computational complexity. In this work, we propose a Part-based Ensemble Transfer Learning network, which models how humans recognize facial expressions by correlating the spatial orientation pattern of the facial features with a specific expression. It consists of 5 sub-networks, in which each sub-network performs transfer learning from one of the five subsets of facial landmarks: eyebrows, eyes, nose, mouth, or jaw to expression classification. We test the proposed network on the CK+, JAFFE, and SFEW datasets, and it outperforms the benchmark for CK+ and JAFFE datasets by 0.51\% and 5.34\%, respectively. Additionally, it consists of a total of 1.65M model parameters and requires only 3.28 $\times$ $10^{6}$ FLOPS, which ensures computational efficiency for real-time deployment. Grad-CAM visualizations of our proposed ensemble highlight the complementary nature of its sub-networks, a key design parameter of an effective ensemble network. Lastly, cross-dataset evaluation results reveal that our proposed ensemble has a high generalization capacity. Our model trained on the SFEW Train dataset achieves an accuracy of 47.53\% on the CK+ dataset, which is higher than what it achieves on the SFEW Valid dataset.
PhysFormer: Facial Video-based Physiological Measurement with Temporal Difference Transformer
Nov 23, 2021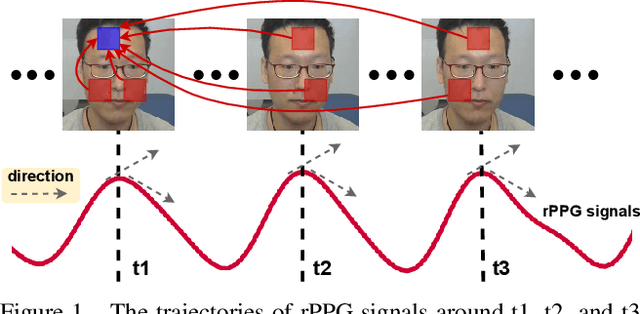
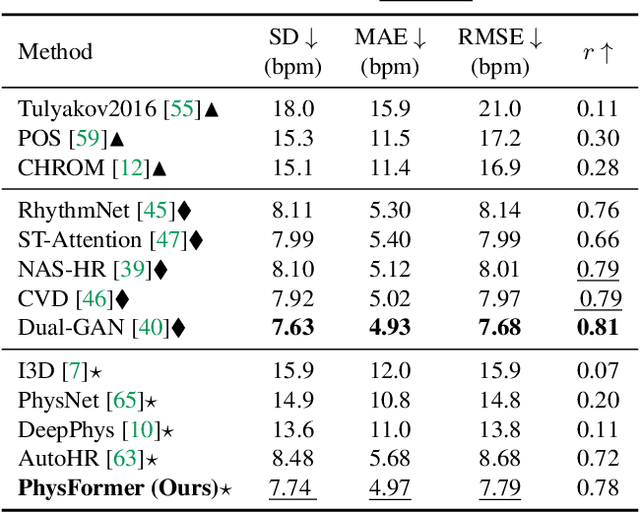
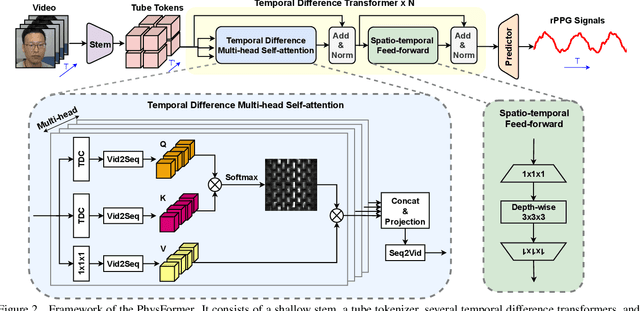
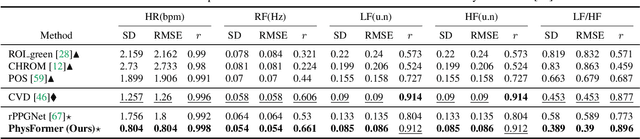
Remote photoplethysmography (rPPG), which aims at measuring heart activities and physiological signals from facial video without any contact, has great potential in many applications (e.g., remote healthcare and affective computing). Recent deep learning approaches focus on mining subtle rPPG clues using convolutional neural networks with limited spatio-temporal receptive fields, which neglect the long-range spatio-temporal perception and interaction for rPPG modeling. In this paper, we propose the PhysFormer, an end-to-end video transformer based architecture, to adaptively aggregate both local and global spatio-temporal features for rPPG representation enhancement. As key modules in PhysFormer, the temporal difference transformers first enhance the quasi-periodic rPPG features with temporal difference guided global attention, and then refine the local spatio-temporal representation against interference. Furthermore, we also propose the label distribution learning and a curriculum learning inspired dynamic constraint in frequency domain, which provide elaborate supervisions for PhysFormer and alleviate overfitting. Comprehensive experiments are performed on four benchmark datasets to show our superior performance on both intra- and cross-dataset testings. One highlight is that, unlike most transformer networks needed pretraining from large-scale datasets, the proposed PhysFormer can be easily trained from scratch on rPPG datasets, which makes it promising as a novel transformer baseline for the rPPG community. The codes will be released at https://github.com/ZitongYu/PhysFormer.
Subjectivity and complexity of facial attractiveness
Mar 18, 2019


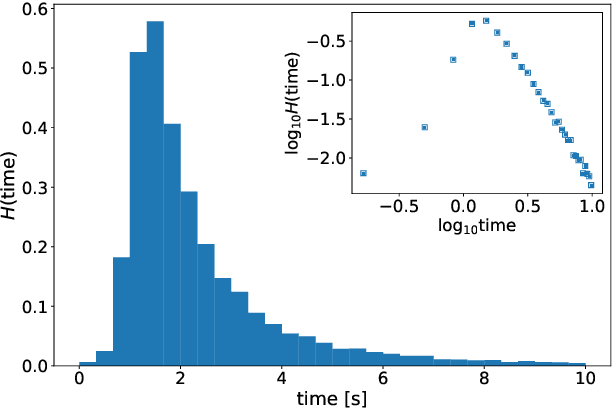
The origin and meaning of facial beauty represent a longstanding puzzle. Despite the profuse literature devoted to facial attractiveness, its very nature, its determinants and the nature of inter-person differences remain controversial issues. Here we tackle such questions proposing a novel experimental approach in which human subjects, instead of rating natural faces, are allowed to efficiently explore the face-space and "sculpt" their favorite variation of a reference facial image. The results reveal that different subjects prefer distinguishable regions of the face-space, highlighting the essential subjectivity of the phenomenon. The different sculpted facial vectors exhibit strong correlations among pairs of facial distances, characterizing the underlying universality and complexity of the cognitive processes, leading to the observed subjectivity.
Fully-attentive and interpretable: vision and video vision transformers for pain detection
Oct 27, 2022
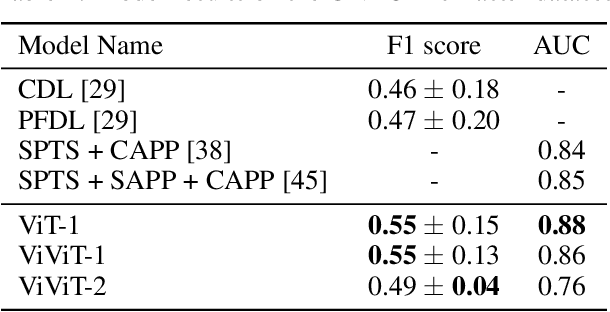
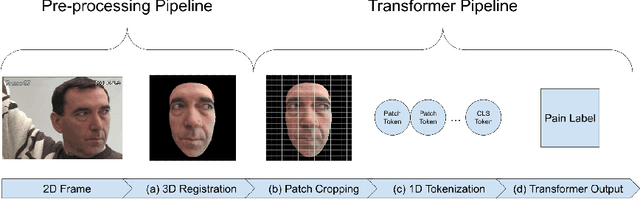
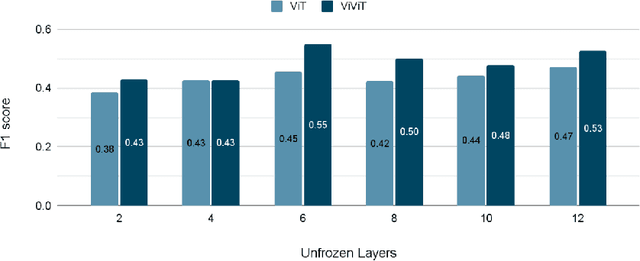
Pain is a serious and costly issue globally, but to be treated, it must first be detected. Vision transformers are a top-performing architecture in computer vision, with little research on their use for pain detection. In this paper, we propose the first fully-attentive automated pain detection pipeline that achieves state-of-the-art performance on binary pain detection from facial expressions. The model is trained on the UNBC-McMaster dataset, after faces are 3D-registered and rotated to the canonical frontal view. In our experiments we identify important areas of the hyperparameter space and their interaction with vision and video vision transformers, obtaining 3 noteworthy models. We analyse the attention maps of one of our models, finding reasonable interpretations for its predictions. We also evaluate Mixup, an augmentation technique, and Sharpness-Aware Minimization, an optimizer, with no success. Our presented models, ViT-1 (F1 score 0.55 +- 0.15), ViViT-1 (F1 score 0.55 +- 0.13), and ViViT-2 (F1 score 0.49 +- 0.04), all outperform earlier works, showing the potential of vision transformers for pain detection. Code is available at https://github.com/IPDTFE/ViT-McMaster
Joint Deep Learning of Facial Expression Synthesis and Recognition
Feb 06, 2020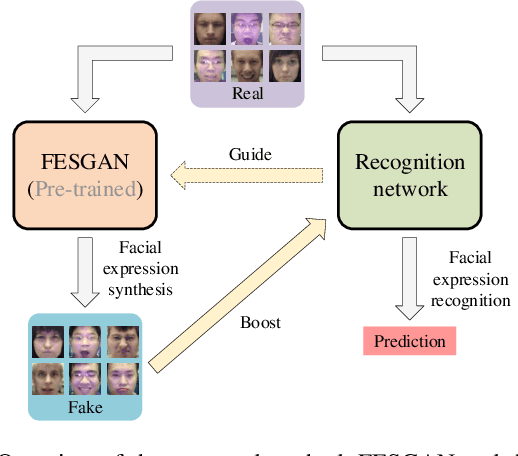
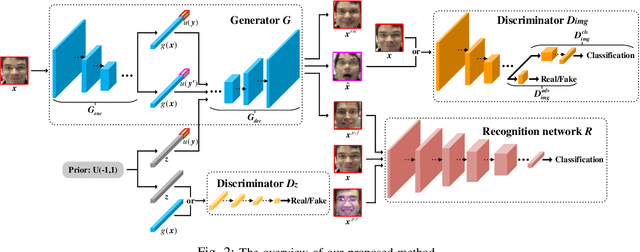
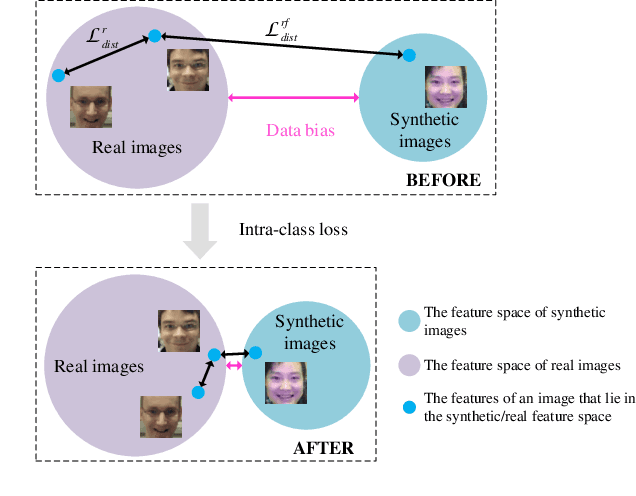

Recently, deep learning based facial expression recognition (FER) methods have attracted considerable attention and they usually require large-scale labelled training data. Nonetheless, the publicly available facial expression databases typically contain a small amount of labelled data. In this paper, to overcome the above issue, we propose a novel joint deep learning of facial expression synthesis and recognition method for effective FER. More specifically, the proposed method involves a two-stage learning procedure. Firstly, a facial expression synthesis generative adversarial network (FESGAN) is pre-trained to generate facial images with different facial expressions. To increase the diversity of the training images, FESGAN is elaborately designed to generate images with new identities from a prior distribution. Secondly, an expression recognition network is jointly learned with the pre-trained FESGAN in a unified framework. In particular, the classification loss computed from the recognition network is used to simultaneously optimize the performance of both the recognition network and the generator of FESGAN. Moreover, in order to alleviate the problem of data bias between the real images and the synthetic images, we propose an intra-class loss with a novel real data-guided back-propagation (RDBP) algorithm to reduce the intra-class variations of images from the same class, which can significantly improve the final performance. Extensive experimental results on public facial expression databases demonstrate the superiority of the proposed method compared with several state-of-the-art FER methods.
Facial Attribute Capsules for Noise Face Super Resolution
Feb 16, 2020
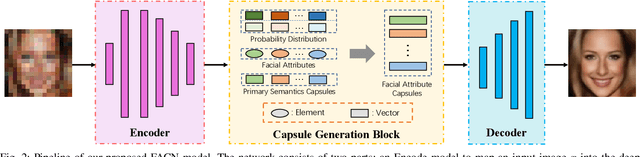
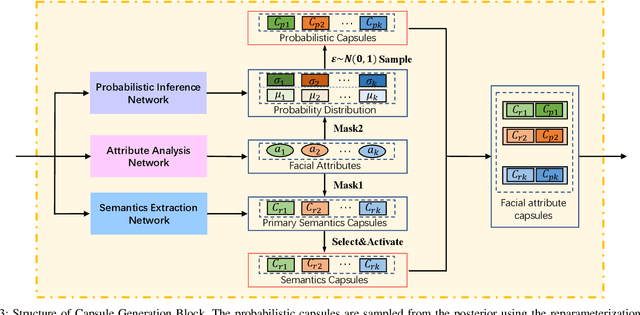

Existing face super-resolution (SR) methods mainly assume the input image to be noise-free. Their performance degrades drastically when applied to real-world scenarios where the input image is always contaminated by noise. In this paper, we propose a Facial Attribute Capsules Network (FACN) to deal with the problem of high-scale super-resolution of noisy face image. Capsule is a group of neurons whose activity vector models different properties of the same entity. Inspired by the concept of capsule, we propose an integrated representation model of facial information, which named Facial Attribute Capsule (FAC). In the SR processing, we first generated a group of FACs from the input LR face, and then reconstructed the HR face from this group of FACs. Aiming to effectively improve the robustness of FAC to noise, we generate FAC in semantic, probabilistic and facial attributes manners by means of integrated learning strategy. Each FAC can be divided into two sub-capsules: Semantic Capsule (SC) and Probabilistic Capsule (PC). Them describe an explicit facial attribute in detail from two aspects of semantic representation and probability distribution. The group of FACs model an image as a combination of facial attribute information in the semantic space and probabilistic space by an attribute-disentangling way. The diverse FACs could better combine the face prior information to generate the face images with fine-grained semantic attributes. Extensive benchmark experiments show that our method achieves superior hallucination results and outperforms state-of-the-art for very low resolution (LR) noise face image super resolution.
Exploring Facial Expressions and Affective Domains for Parkinson Detection
Dec 11, 2020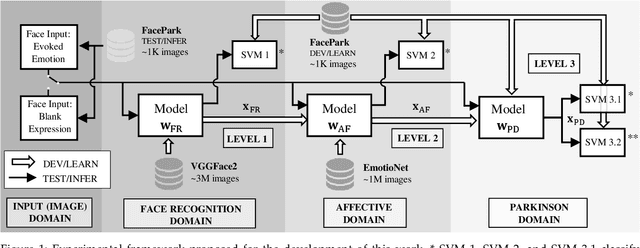
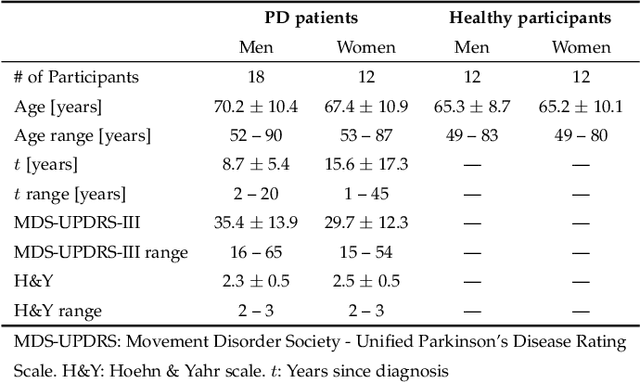
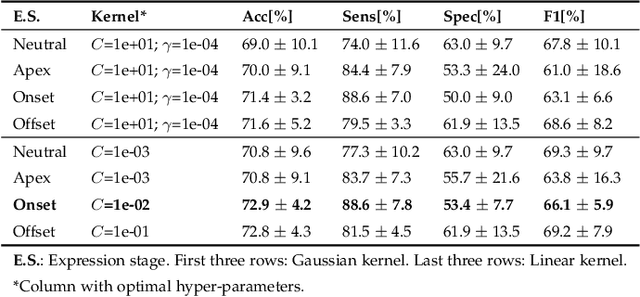
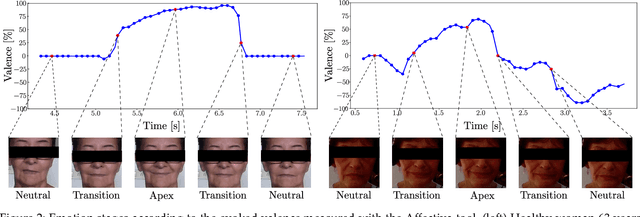
Parkinson's Disease (PD) is a neurological disorder that affects facial movements and non-verbal communication. Patients with PD present a reduction in facial movements called hypomimia which is evaluated in item 3.2 of the MDS-UPDRS-III scale. In this work, we propose to use facial expression analysis from face images based on affective domains to improve PD detection. We propose different domain adaptation techniques to exploit the latest advances in face recognition and Face Action Unit (FAU) detection. The principal contributions of this work are: (1) a novel framework to exploit deep face architectures to model hypomimia in PD patients; (2) we experimentally compare PD detection based on single images vs. image sequences while the patients are evoked various face expressions; (3) we explore different domain adaptation techniques to exploit existing models initially trained either for Face Recognition or to detect FAUs for the automatic discrimination between PD patients and healthy subjects; and (4) a new approach to use triplet-loss learning to improve hypomimia modeling and PD detection. The results on real face images from PD patients show that we are able to properly model evoked emotions using image sequences (neutral, onset-transition, apex, offset-transition, and neutral) with accuracy improvements up to 5.5% (from 72.9% to 78.4%) with respect to single-image PD detection. We also show that our proposed affective-domain adaptation provides improvements in PD detection up to 8.9% (from 78.4% to 87.3% detection accuracy).
Omni-supervised Facial Expression Recognition: A Simple Baseline
May 18, 2020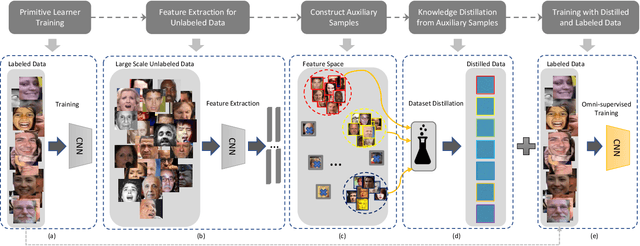
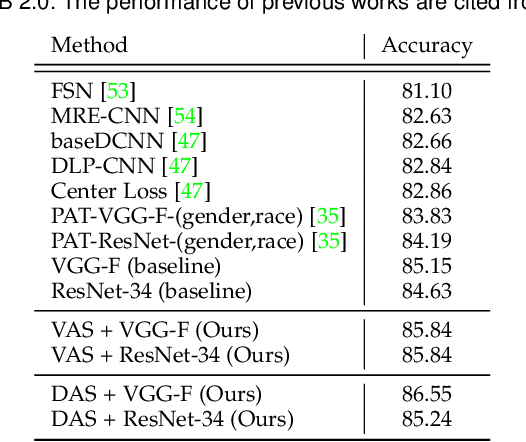
In this paper, we target on advancing the performance in facial expression recognition (FER) by exploiting omni-supervised learning. The current state of the art FER approaches usually aim to recognize facial expressions in a controlled environment by training models with a limited number of samples. To enhance the robustness of the learned models for various scenarios, we propose to perform omni-supervised learning by exploiting the labeled samples together with a large number of unlabeled data. Particularly, we first employ MS-Celeb-1M as the facial-pool where around 5,822K unlabeled facial images are included. Then, a primitive model learned on a small number of labeled samples is adopted to select samples with high confidence from the facial-pool by conducting feature-based similarity comparison. We find the new dataset constructed in such an omni-supervised manner can significantly improve the generalization ability of the learned FER model and boost the performance consequently. However, as more training samples are used, more computation resources and training time are required, which is usually not affordable in many circumstances. To relieve the requirement of computational resources, we further adopt a dataset distillation strategy to distill the target task-related knowledge from the new mined samples and compressed them into a very small set of images. This distilled dataset is capable of boosting the performance of FER with few additional computational cost introduced. We perform extensive experiments on five popular benchmarks and a newly constructed dataset, where consistent gains can be achieved under various settings using the proposed framework. We hope this work will serve as a solid baseline and help ease future research in FER.
Investigating Bias and Fairness in Facial Expression Recognition
Jul 20, 2020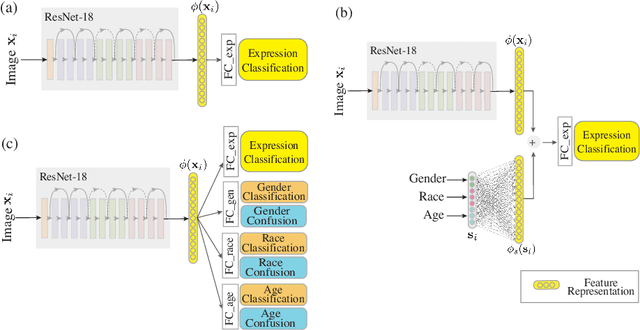
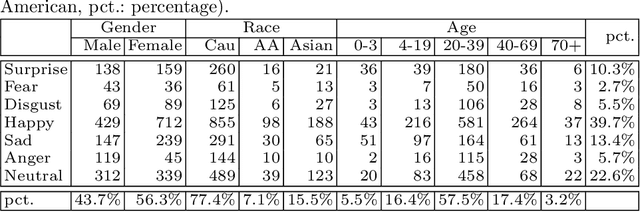
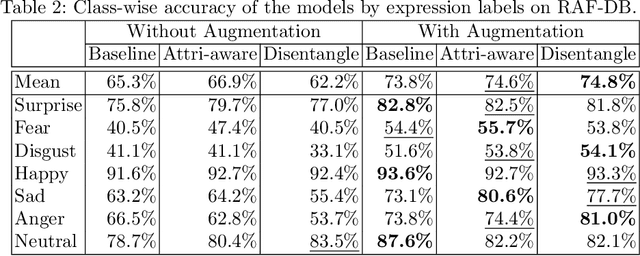
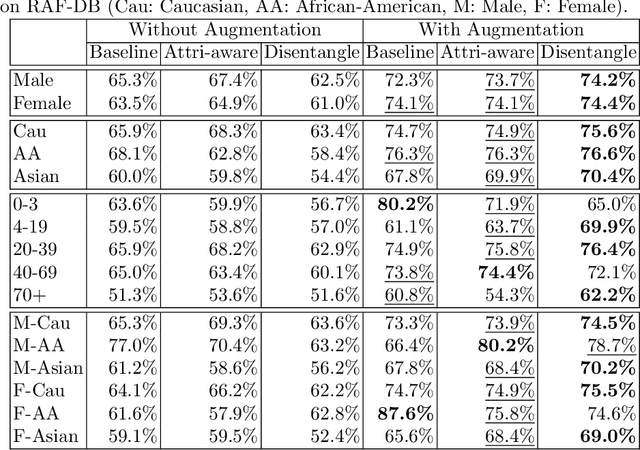
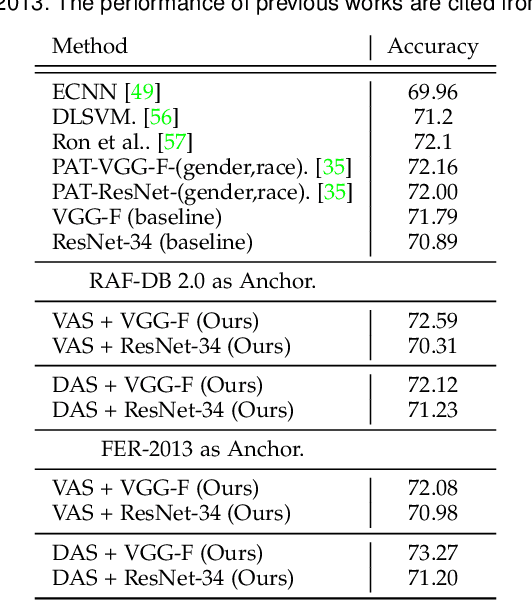
Recognition of expressions of emotions and affect from facial images is a well-studied research problem in the fields of affective computing and computer vision with a large number of datasets available containing facial images and corresponding expression labels. However, virtually none of these datasets have been acquired with consideration of fair distribution across the human population. Therefore, in this work, we undertake a systematic investigation of bias and fairness in facial expression recognition by comparing three different approaches, namely a baseline, an attribute-aware and a disentangled approach, on two well-known datasets, RAF-DB and CelebA. Our results indicate that: (i) data augmentation improves the accuracy of the baseline model, but this alone is unable to mitigate the bias effect; (ii) both the attribute-aware and the disentangled approaches fortified with data augmentation perform better than the baseline approach in terms of accuracy and fairness; (iii) the disentangled approach is the best for mitigating demographic bias; and (iv) the bias mitigation strategies are more suitable in the existence of uneven attribute distribution or imbalanced number of subgroup data.
Improving User's Sense of Participation in Robot-Driven Dialogue
Oct 18, 2022
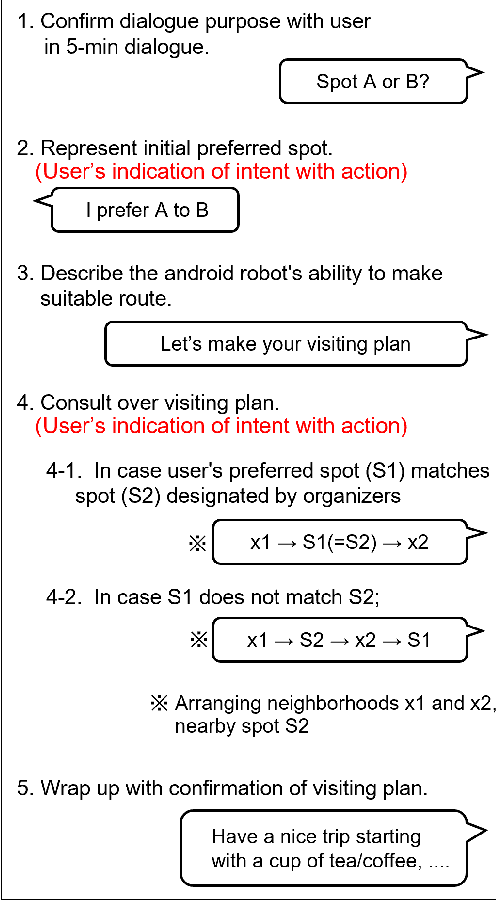
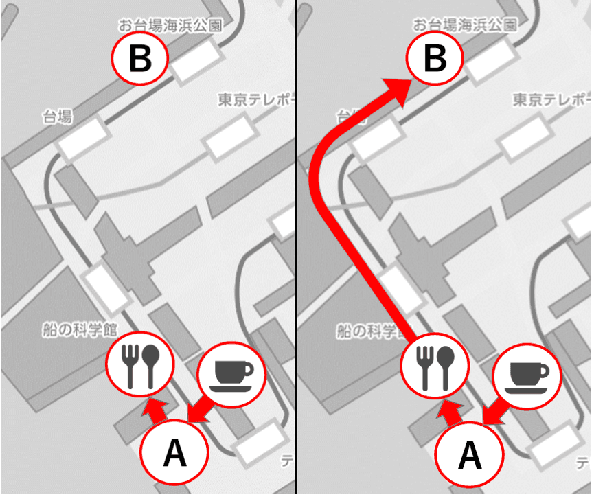
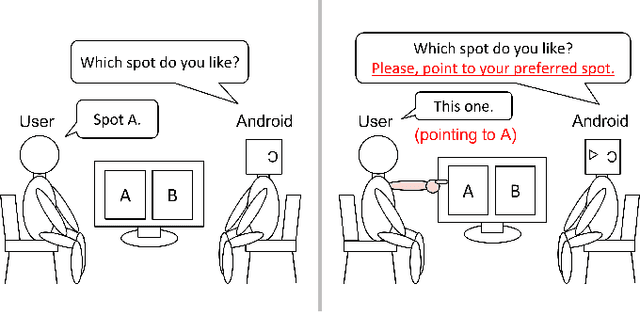
In task-oriented dialogues with symbiotic robots, the robot usually takes the initiative in dialogue progression and topic selection. In such robot-driven dialogue, the user's sense of participation in the dialogue is reduced because the degree of freedom in timing and content of speech is limited, and as a result, the user's familiarity with and trust in the robot as a dialogue partner and the level of dialogue satisfaction decrease. In this study, we constructed a travel agent dialogue system focusing on improving the sense of dialogue participation. At the beginning of the dialogue, the robot tells the user the purpose of the upcoming dialogue and indicates that it is responsible for assisting the user in making decisions. In addition, in situations where users were asked to state their preferences, the robot encourages them to express their intentions with actions, as well as spoken language responses. In addition, we attempted to reduce the sense of discomfort felt toward the android robot by devising a timing control for the robot's detailed movements and facial expressions.