 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Suppressing Uncertainties for Large-Scale Facial Expression Recognition
Feb 24, 2020


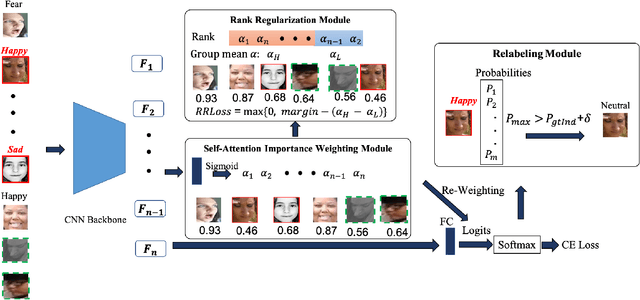
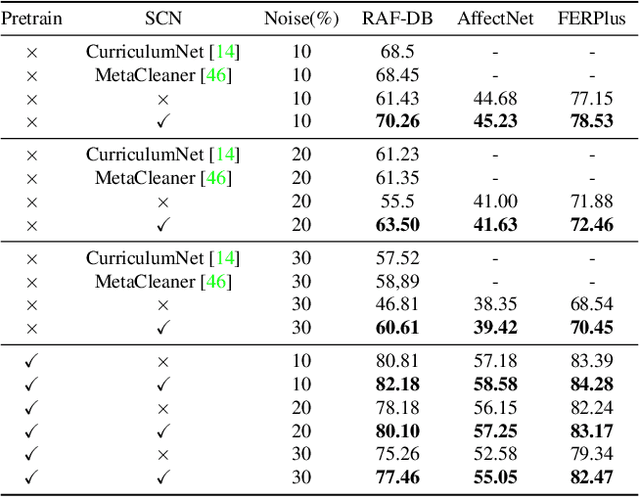
Annotating a qualitative large-scale facial expression dataset is extremely difficult due to the uncertainties caused by ambiguous facial expressions, low-quality facial images, and the subjectiveness of annotators. These uncertainties lead to a key challenge of large-scale Facial Expression Recognition (FER) in deep learning era. To address this problem, this paper proposes a simple yet efficient Self-Cure Network (SCN) which suppresses the uncertainties efficiently and prevents deep networks from over-fitting uncertain facial images. Specifically, SCN suppresses the uncertainty from two different aspects: 1) a self-attention mechanism over mini-batch to weight each training sample with a ranking regularization, and 2) a careful relabeling mechanism to modify the labels of these samples in the lowest-ranked group. Experiments on synthetic FER datasets and our collected WebEmotion dataset validate the effectiveness of our method. Results on public benchmarks demonstrate that our SCN outperforms current state-of-the-art methods with \textbf{88.14}\% on RAF-DB, \textbf{60.23}\% on AffectNet, and \textbf{89.35}\% on FERPlus. The code will be available at \href{https://github.com/kaiwang960112/Self-Cure-Network}{https://github.com/kaiwang960112/Self-Cure-Network}.
Pain Detection in Masked Faces during Procedural Sedation
Nov 12, 2022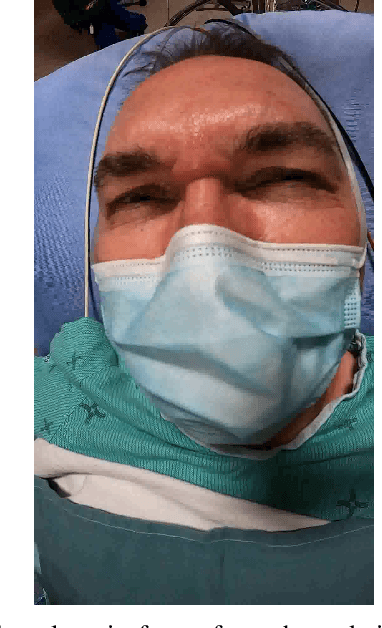
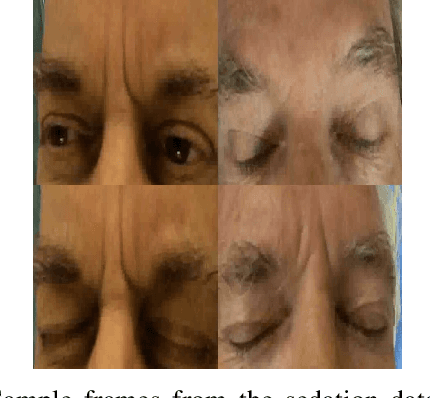
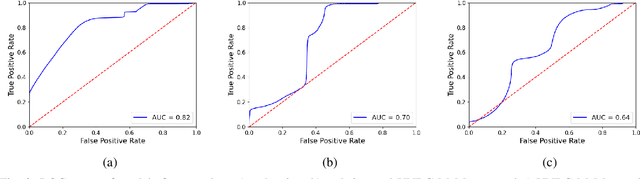
Pain monitoring is essential to the quality of care for patients undergoing a medical procedure with sedation. An automated mechanism for detecting pain could improve sedation dose titration. Previous studies on facial pain detection have shown the viability of computer vision methods in detecting pain in unoccluded faces. However, the faces of patients undergoing procedures are often partially occluded by medical devices and face masks. A previous preliminary study on pain detection on artificially occluded faces has shown a feasible approach to detect pain from a narrow band around the eyes. This study has collected video data from masked faces of 14 patients undergoing procedures in an interventional radiology department and has trained a deep learning model using this dataset. The model was able to detect expressions of pain accurately and, after causal temporal smoothing, achieved an average precision (AP) of 0.72 and an area under the receiver operating characteristic curve (AUC) of 0.82. These results outperform baseline models and show viability of computer vision approaches for pain detection of masked faces during procedural sedation. Cross-dataset performance is also examined when a model is trained on a publicly available dataset and tested on the sedation videos. The ways in which pain expressions differ in the two datasets are qualitatively examined.
An Overview of Facial Micro-Expression Analysis: Data, Methodology and Challenge
Dec 21, 2020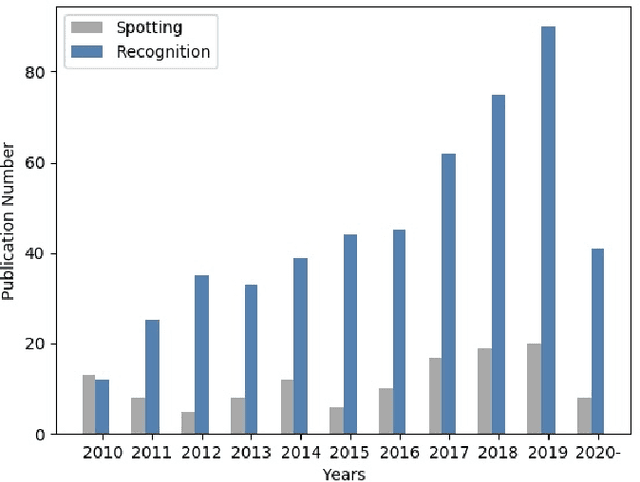

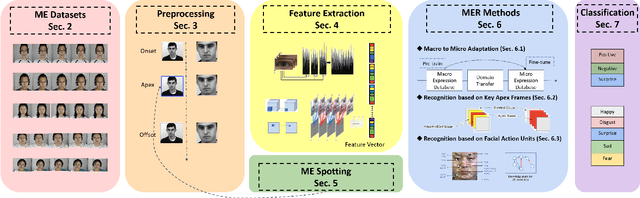
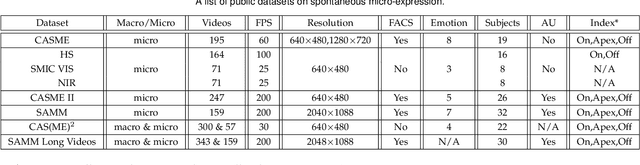
Facial micro-expressions indicate brief and subtle facial movements that appear during emotional communication. In comparison to macro-expressions, micro-expressions are more challenging to be analyzed due to the short span of time and the fine-grained changes. In recent years, micro-expression recognition (MER) has drawn much attention because it can benefit a wide range of applications, e.g. police interrogation, clinical diagnosis, depression analysis, and business negotiation. In this survey, we offer a fresh overview to discuss new research directions and challenges these days for MER tasks. For example, we review MER approaches from three novel aspects: macro-to-micro adaptation, recognition based on key apex frames, and recognition based on facial action units. Moreover, to mitigate the problem of limited and biased ME data, synthetic data generation is surveyed for the diversity enrichment of micro-expression data. Since micro-expression spotting can boost micro-expression analysis, the state-of-the-art spotting works are also introduced in this paper. At last, we discuss the challenges in MER research and provide potential solutions as well as possible directions for further investigation.
Driving Safety Prediction and Safe Route Mapping Using In-vehicle and Roadside Data
Sep 12, 2022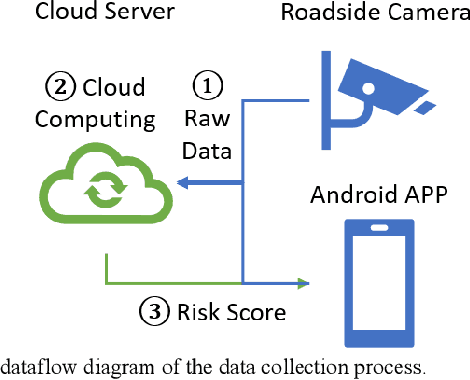
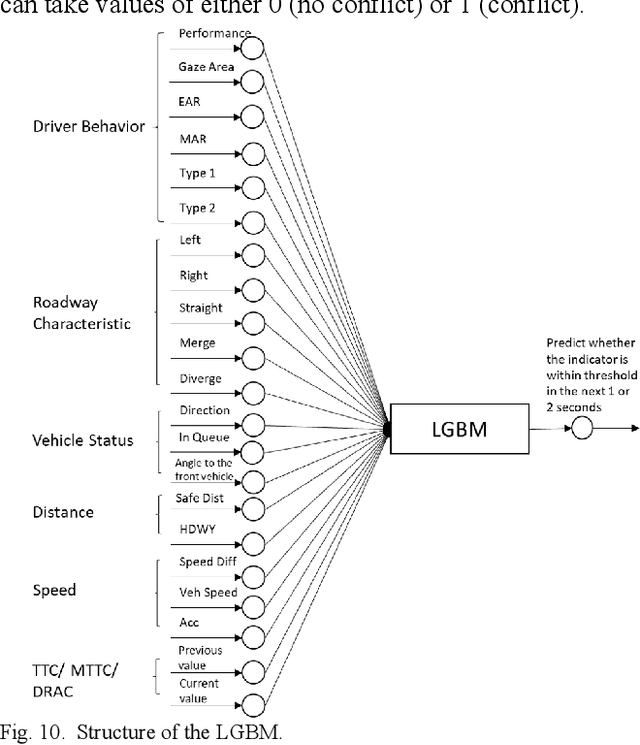
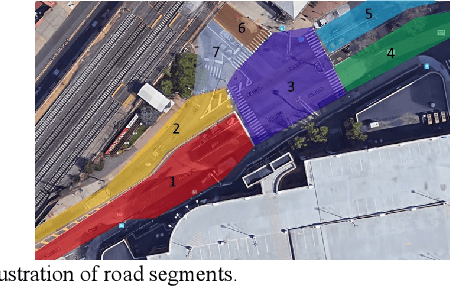
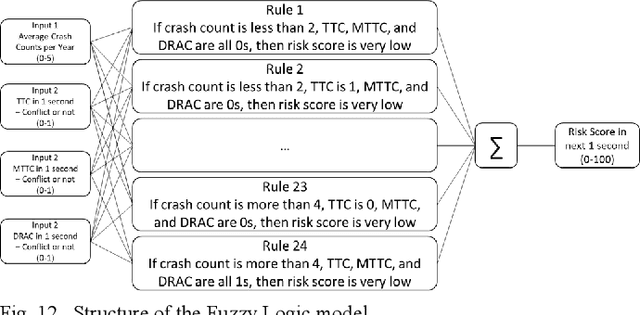
Risk assessment of roadways is commonly practiced based on historical crash data. Information on driver behaviors and real-time traffic situations is sometimes missing. In this paper, the Safe Route Mapping (SRM) model, a methodology for developing dynamic risk heat maps of roadways, is extended to consider driver behaviors when making predictions. An Android App is designed to gather drivers' information and upload it to a server. On the server, facial recognition extracts drivers' data, such as facial landmarks, gaze directions, and emotions. The driver's drowsiness and distraction are detected, and driving performance is evaluated. Meanwhile, dynamic traffic information is captured by a roadside camera and uploaded to the same server. A longitudinal-scanline-based arterial traffic video analytics is applied to recognize vehicles from the video to build speed and trajectory profiles. Based on these data, a LightGBM model is introduced to predict conflict indices for drivers in the next one or two seconds. Then, multiple data sources, including historical crash counts and predicted traffic conflict indicators, are combined using a Fuzzy logic model to calculate risk scores for road segments. The proposed SRM model is illustrated using data collected from an actual traffic intersection and a driving simulation platform. The prediction results show that the model is accurate, and the added driver behavior features will improve the model's performance. Finally, risk heat maps are generated for visualization purposes. The authorities can use the dynamic heat map to designate safe corridors and dispatch law enforcement and drivers for early warning and trip planning.
Aggregating Layers for Deepfake Detection
Oct 11, 2022

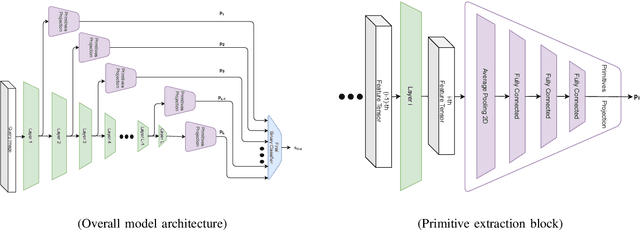
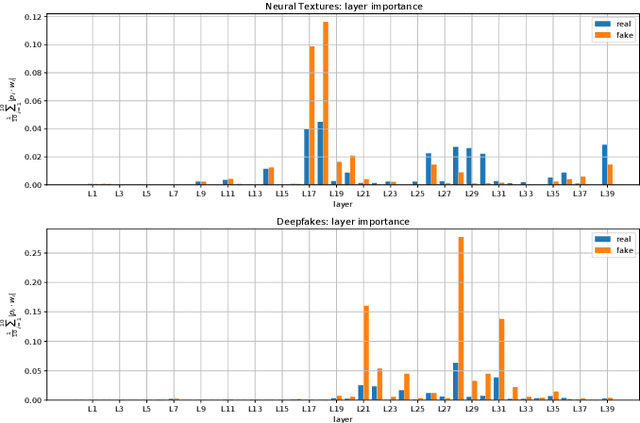
The increasing popularity of facial manipulation (Deepfakes) and synthetic face creation raises the need to develop robust forgery detection solutions. Crucially, most work in this domain assume that the Deepfakes in the test set come from the same Deepfake algorithms that were used for training the network. This is not how things work in practice. Instead, we consider the case where the network is trained on one Deepfake algorithm, and tested on Deepfakes generated by another algorithm. Typically, supervised techniques follow a pipeline of visual feature extraction from a deep backbone, followed by a binary classification head. Instead, our algorithm aggregates features extracted across all layers of one backbone network to detect a fake. We evaluate our approach on two domains of interest - Deepfake detection and Synthetic image detection, and find that we achieve SOTA results.
Controllable Radiance Fields for Dynamic Face Synthesis
Oct 11, 2022
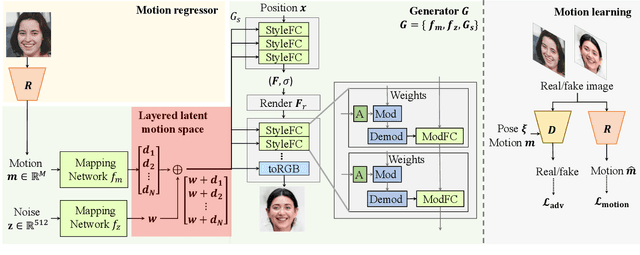
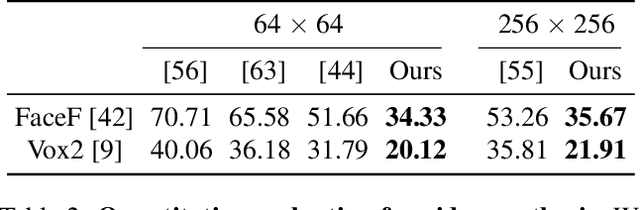
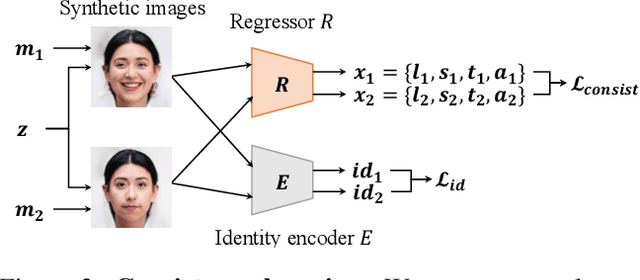
Recent work on 3D-aware image synthesis has achieved compelling results using advances in neural rendering. However, 3D-aware synthesis of face dynamics hasn't received much attention. Here, we study how to explicitly control generative model synthesis of face dynamics exhibiting non-rigid motion (e.g., facial expression change), while simultaneously ensuring 3D-awareness. For this we propose a Controllable Radiance Field (CoRF): 1) Motion control is achieved by embedding motion features within the layered latent motion space of a style-based generator; 2) To ensure consistency of background, motion features and subject-specific attributes such as lighting, texture, shapes, albedo, and identity, a face parsing net, a head regressor and an identity encoder are incorporated. On head image/video data we show that CoRFs are 3D-aware while enabling editing of identity, viewing directions, and motion.
Toward Fine-grained Facial Expression Manipulation
Apr 07, 2020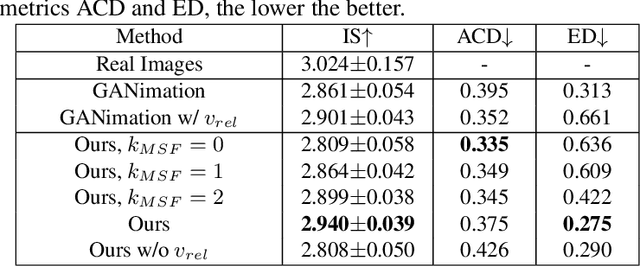
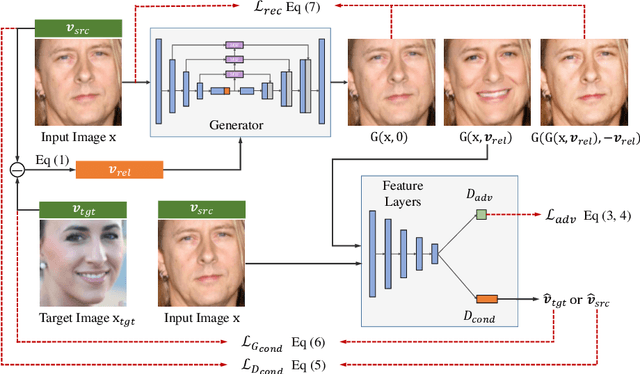
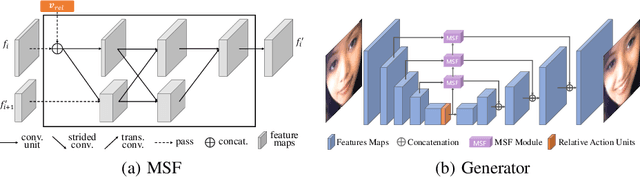

Facial expression manipulation, as an image-to-image translation problem, aims at editing facial expression with a given condition. Previous methods edit an input image under the guidance of a discrete emotion label or absolute condition (e.g., facial action units) to possess the desired expression. However, these methods either suffer from changing condition-irrelevant regions or are inefficient to preserve image quality. In this study, we take these two objectives into consideration and propose a novel conditional GAN model. First, we replace continuous absolute condition with relative condition, specifically, relative action units. With relative action units, the generator learns to only transform regions of interest which are specified by non-zero-valued relative AUs, avoiding estimating the current AUs of input image. Second, our generator is built on U-Net architecture and strengthened by multi-scale feature fusion (MSF) mechanism for high-quality expression editing purpose. Extensive experiments on both quantitative and qualitative evaluation demonstrate the improvements of our proposed approach compared with the state-of-the-art expression editing methods.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
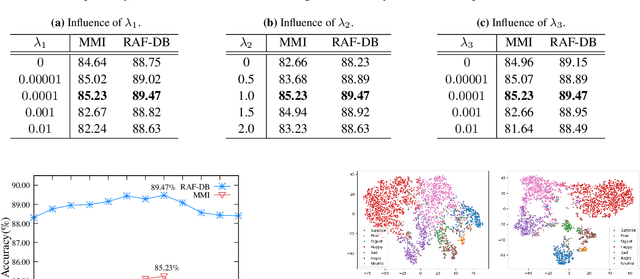
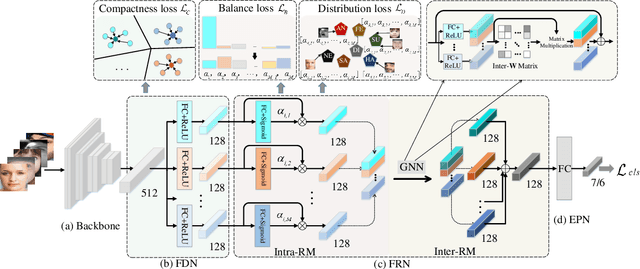
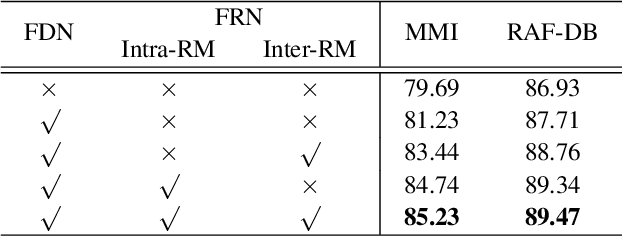
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Spatiotemporal Contrastive Learning of Facial Expressions in Videos
Aug 06, 2021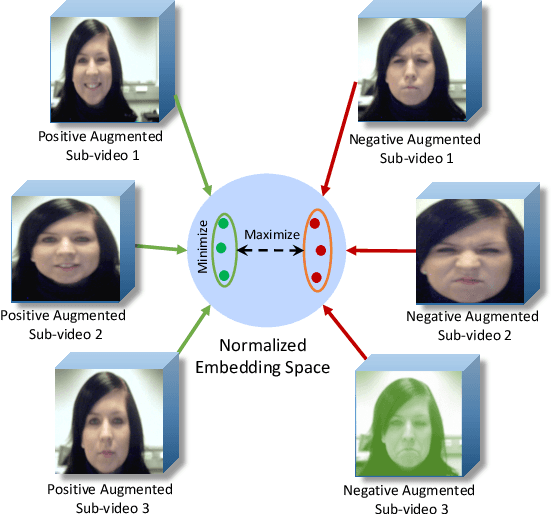

We propose a self-supervised contrastive learning approach for facial expression recognition (FER) in videos. We propose a novel temporal sampling-based augmentation scheme to be utilized in addition to standard spatial augmentations used for contrastive learning. Our proposed temporal augmentation scheme randomly picks from one of three temporal sampling techniques: (1) pure random sampling, (2) uniform sampling, and (3) sequential sampling. This is followed by a combination of up to three standard spatial augmentations. We then use a deep R(2+1)D network for FER, which we train in a self-supervised fashion based on the augmentations and subsequently fine-tune. Experiments are performed on the Oulu-CASIA dataset and the performance is compared to other works in FER. The results indicate that our method achieves an accuracy of 89.4%, setting a new state-of-the-art by outperforming other works. Additional experiments and analysis confirm the considerable contribution of the proposed temporal augmentation versus the existing spatial ones.
Recurrent Super-Resolution Method for Enhancing Low Quality Thermal Facial Data
Sep 21, 2022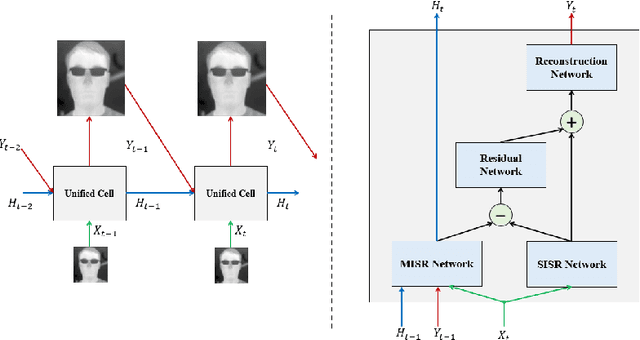

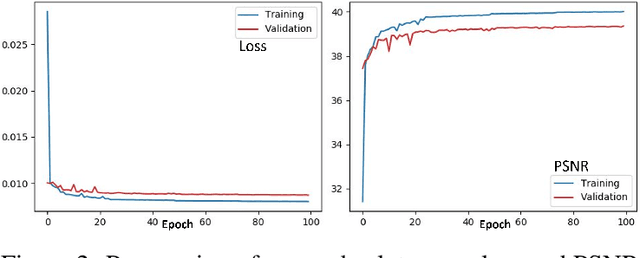

The process of obtaining high-resolution images from single or multiple low-resolution images of the same scene is of great interest for real-world image and signal processing applications. This study is about exploring the potential usage of deep learning based image super-resolution algorithms on thermal data for producing high quality thermal imaging results for in-cabin vehicular driver monitoring systems. In this work we have proposed and developed a novel multi-image super-resolution recurrent neural network to enhance the resolution and improve the quality of low-resolution thermal imaging data captured from uncooled thermal cameras. The end-to-end fully convolutional neural network is trained from scratch on newly acquired thermal data of 30 different subjects in indoor environmental conditions. The effectiveness of the thermally tuned super-resolution network is validated quantitatively as well as qualitatively on test data of 6 distinct subjects. The network was able to achieve a mean peak signal to noise ratio of 39.24 on the validation dataset for 4x super-resolution, outperforming bicubic interpolation both quantitatively and qualitatively.