 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
3D Facial Geometry Recovery from a Depth View with Attention Guided Generative Adversarial Network
Sep 02, 2020
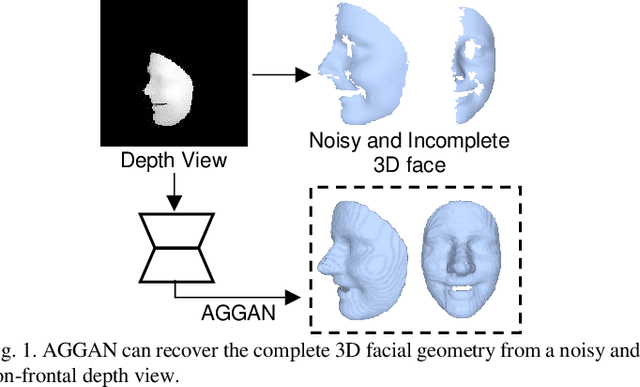
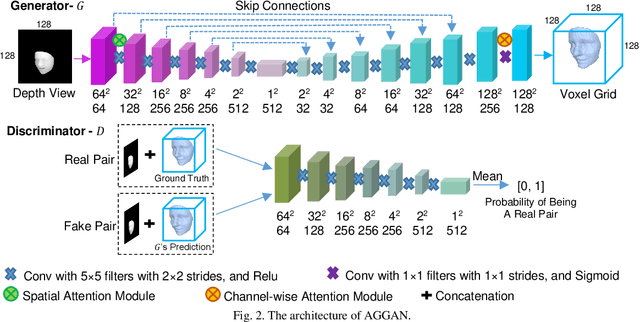
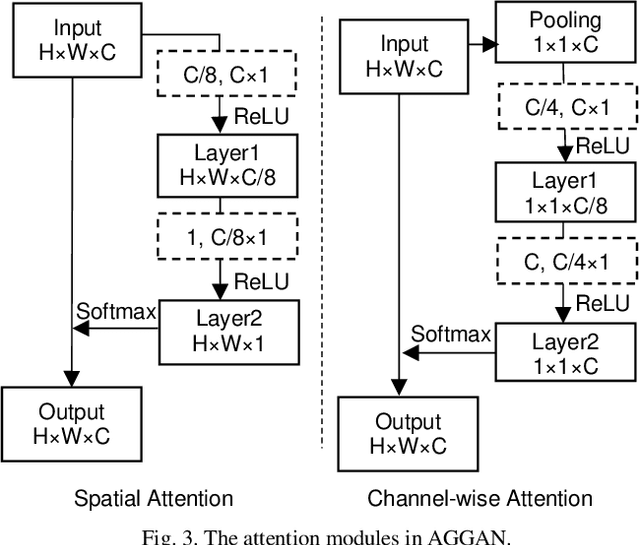
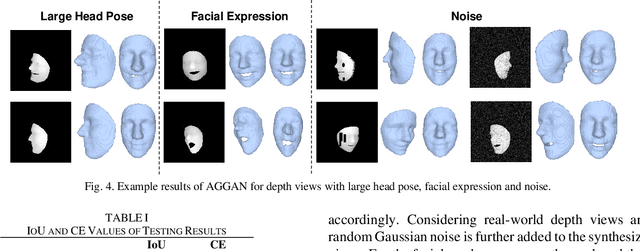
We present to recover the complete 3D facial geometry from a single depth view by proposing an Attention Guided Generative Adversarial Networks (AGGAN). In contrast to existing work which normally requires two or more depth views to recover a full 3D facial geometry, the proposed AGGAN is able to generate a dense 3D voxel grid of the face from a single unconstrained depth view. Specifically, AGGAN encodes the 3D facial geometry within a voxel space and utilizes an attention-guided GAN to model the illposed 2.5D depth-3D mapping. Multiple loss functions, which enforce the 3D facial geometry consistency, together with a prior distribution of facial surface points in voxel space are incorporated to guide the training process. Both qualitative and quantitative comparisons show that AGGAN recovers a more complete and smoother 3D facial shape, with the capability to handle a much wider range of view angles and resist to noise in the depth view than conventional methods
Recurrent Super-Resolution Method for Enhancing Low Quality Thermal Facial Data
Sep 21, 2022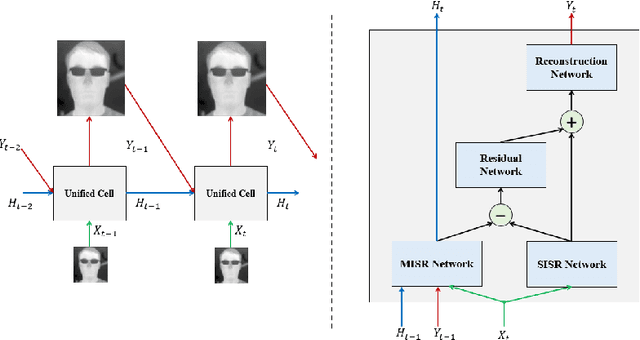

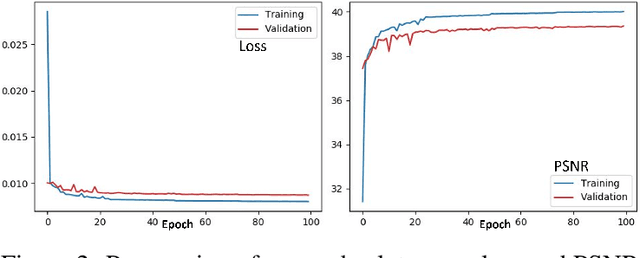

The process of obtaining high-resolution images from single or multiple low-resolution images of the same scene is of great interest for real-world image and signal processing applications. This study is about exploring the potential usage of deep learning based image super-resolution algorithms on thermal data for producing high quality thermal imaging results for in-cabin vehicular driver monitoring systems. In this work we have proposed and developed a novel multi-image super-resolution recurrent neural network to enhance the resolution and improve the quality of low-resolution thermal imaging data captured from uncooled thermal cameras. The end-to-end fully convolutional neural network is trained from scratch on newly acquired thermal data of 30 different subjects in indoor environmental conditions. The effectiveness of the thermally tuned super-resolution network is validated quantitatively as well as qualitatively on test data of 6 distinct subjects. The network was able to achieve a mean peak signal to noise ratio of 39.24 on the validation dataset for 4x super-resolution, outperforming bicubic interpolation both quantitatively and qualitatively.
Domain Adaptation for Facial Expression Classifier via Domain Discrimination and Gradient Reversal
Jun 02, 2021
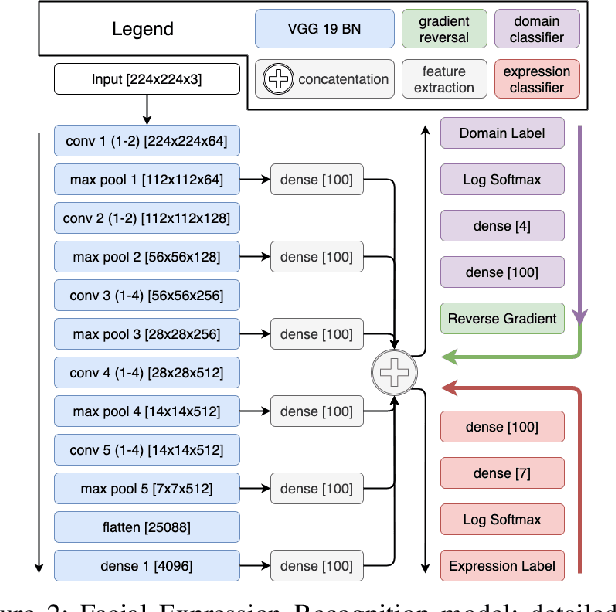
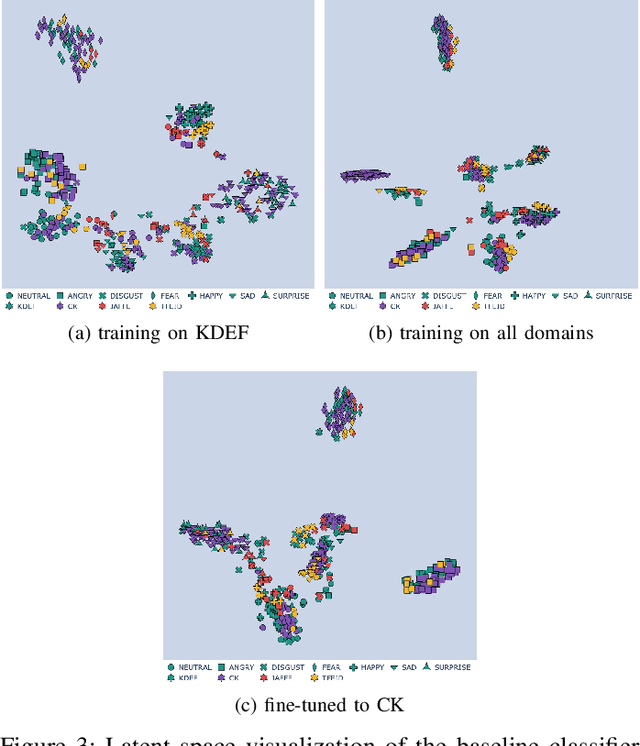
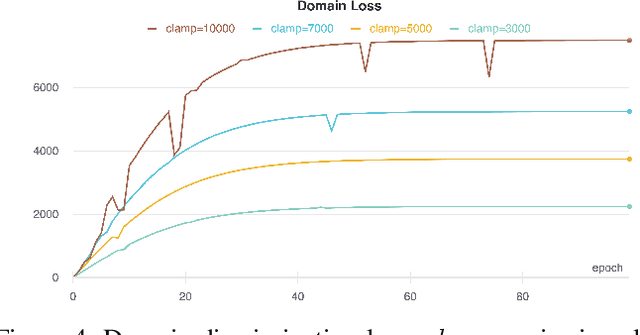
Bringing empathy to a computerized system could significantly improve the quality of human-computer communications, as soon as machines would be able to understand customer intentions and better serve their needs. According to different studies (Literature Review), visual information is one of the most important channels of human interaction and contains significant behavioral signals, that may be captured from facial expressions. Therefore, it is consistent and natural that the research in the field of Facial Expression Recognition (FER) has acquired increased interest over the past decade due to having diverse application area including health-care, sociology, psychology, driver-safety, virtual reality, cognitive sciences, security, entertainment, marketing, etc. We propose a new architecture for the task of FER and examine the impact of domain discrimination loss regularization on the learning process. With regard to observations, including both classical training conditions and unsupervised domain adaptation scenarios, important aspects of the considered domain adaptation approach integration are traced. The results may serve as a foundation for further research in the field.
Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM
Oct 26, 2022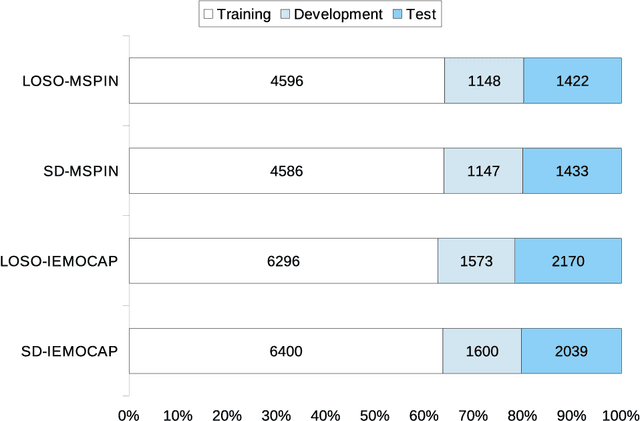

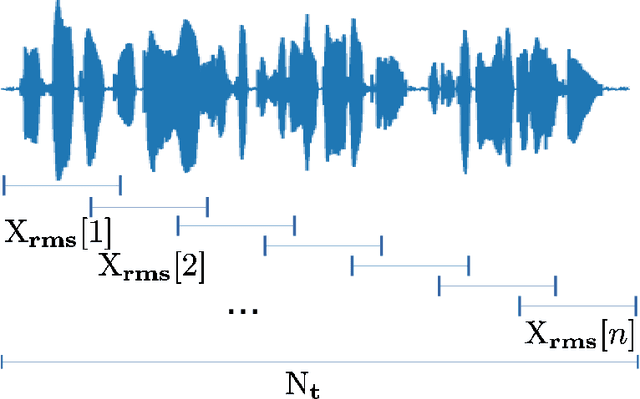
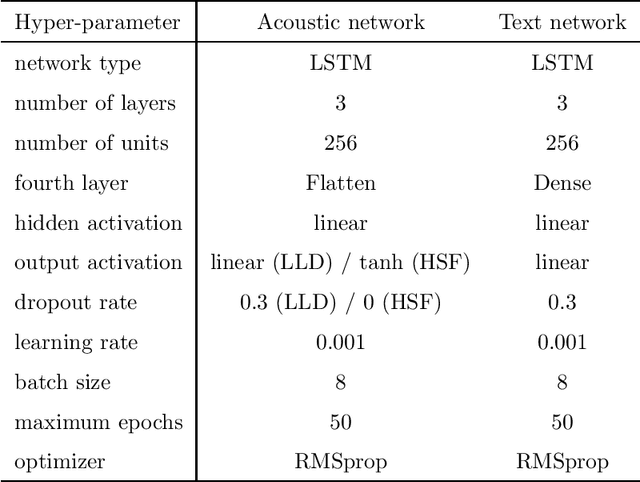
Automatic speech emotion recognition (SER) by a computer is a critical component for more natural human-machine interaction. As in human-human interaction, the capability to perceive emotion correctly is essential to take further steps in a particular situation. One issue in SER is whether it is necessary to combine acoustic features with other data such as facial expressions, text, and motion capture. This research proposes to combine acoustic and text information by applying a late-fusion approach consisting of two steps. First, acoustic and text features are trained separately in deep learning systems. Second, the prediction results from the deep learning systems are fed into a support vector machine (SVM) to predict the final regression score. Furthermore, the task in this research is dimensional emotion modeling because it can enable a deeper analysis of affective states. Experimental results show that this two-stage, late-fusion approach, obtains higher performance than that of any one-stage processing, with a linear correlation from one-stage to two-stage processing. This late-fusion approach improves previous early fusion results measured in concordance correlation coefficients score.
* Published in Speech Communications
Suppressing Uncertainties for Large-Scale Facial Expression Recognition
Mar 06, 2020

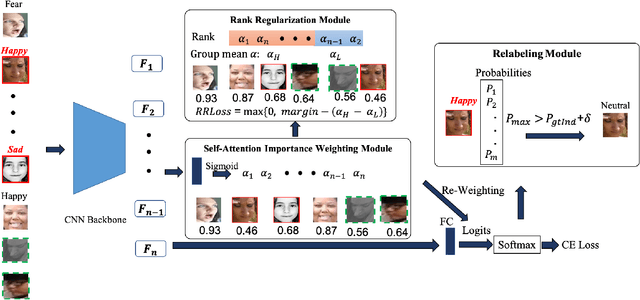
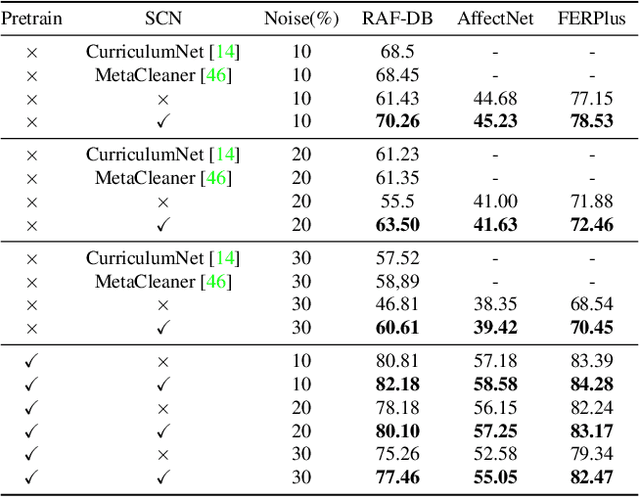
Annotating a qualitative large-scale facial expression dataset is extremely difficult due to the uncertainties caused by ambiguous facial expressions, low-quality facial images, and the subjectiveness of annotators. These uncertainties lead to a key challenge of large-scale Facial Expression Recognition (FER) in deep learning era. To address this problem, this paper proposes a simple yet efficient Self-Cure Network (SCN) which suppresses the uncertainties efficiently and prevents deep networks from over-fitting uncertain facial images. Specifically, SCN suppresses the uncertainty from two different aspects: 1) a self-attention mechanism over mini-batch to weight each training sample with a ranking regularization, and 2) a careful relabeling mechanism to modify the labels of these samples in the lowest-ranked group. Experiments on synthetic FER datasets and our collected WebEmotion dataset validate the effectiveness of our method. Results on public benchmarks demonstrate that our SCN outperforms current state-of-the-art methods with \textbf{88.14}\% on RAF-DB, \textbf{60.23}\% on AffectNet, and \textbf{89.35}\% on FERPlus. The code will be available at \href{https://github.com/kaiwang960112/Self-Cure-Network}{https://github.com/kaiwang960112/Self-Cure-Network}.
Unsupervised Facial Action Unit Intensity Estimation via Differentiable Optimization
Apr 13, 2020
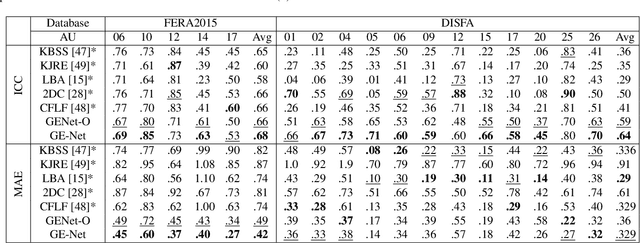
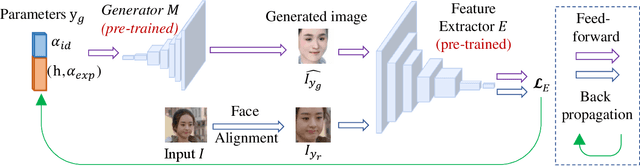
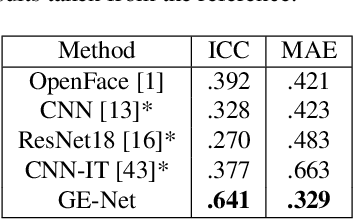
The automatic intensity estimation of facial action units (AUs) from a single image plays a vital role in facial analysis systems. One big challenge for data-driven AU intensity estimation is the lack of sufficient AU label data. Due to the fact that AU annotation requires strong domain expertise, it is expensive to construct an extensive database to learn deep models. The limited number of labeled AUs as well as identity differences and pose variations further increases the estimation difficulties. Considering all these difficulties, we propose an unsupervised framework GE-Net for facial AU intensity estimation from a single image, without requiring any annotated AU data. Our framework performs differentiable optimization, which iteratively updates the facial parameters (i.e., head pose, AU parameters and identity parameters) to match the input image. GE-Net consists of two modules: a generator and a feature extractor. The generator learns to "render" a face image from a set of facial parameters in a differentiable way, and the feature extractor extracts deep features for measuring the similarity of the rendered image and input real image. After the two modules are trained and fixed, the framework searches optimal facial parameters by minimizing the differences of the extracted features between the rendered image and the input image. Experimental results demonstrate that our method can achieve state-of-the-art results compared with existing methods.
Facial Expression Recognition with Deep Learning
Apr 08, 2020
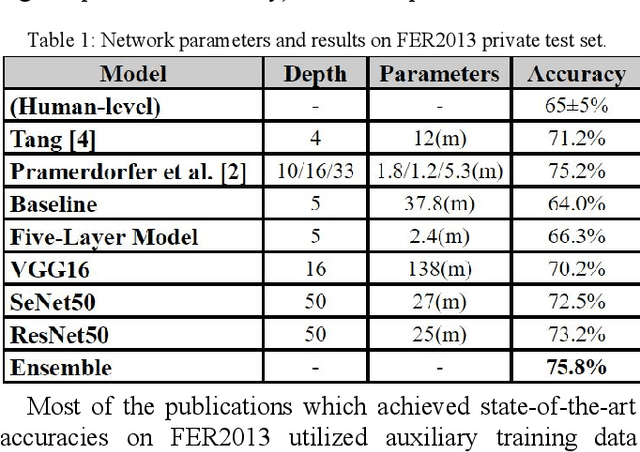

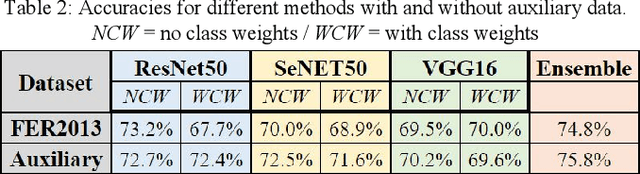
One of the most universal ways that people communicate is through facial expressions. In this paper, we take a deep dive, implementing multiple deep learning models for facial expression recognition (FER). Our goals are twofold: we aim not only to maximize accuracy, but also to apply our results to the real-world. By leveraging numerous techniques from recent research, we demonstrate a state-of-the-art 75.8% accuracy on the FER2013 test set, outperforming all existing publications. Additionally, we showcase a mobile web app which runs our FER models on-device in real time.
Neural Sign Reenactor: Deep Photorealistic Sign Language Retargeting
Sep 03, 2022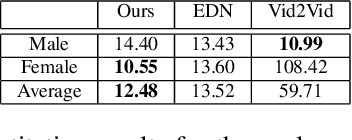
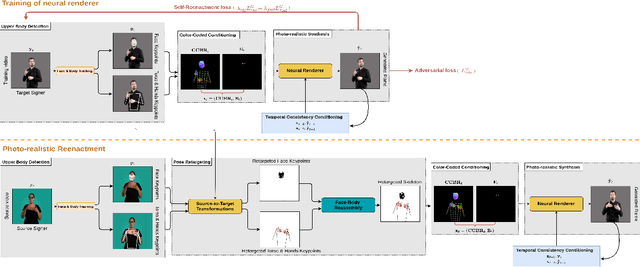

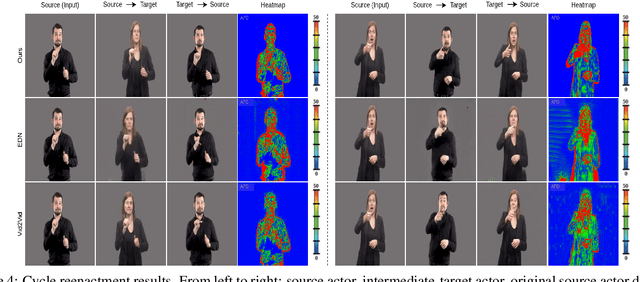
In this paper, we introduce a neural rendering pipeline for transferring the facial expressions, head pose and body movements of one person in a source video to another in a target video. We apply our method to the challenging case of Sign Language videos: given a source video of a sign language user, we can faithfully transfer the performed manual (e.g. handshape, palm orientation, movement, location) and non-manual (e.g. eye gaze, facial expressions, head movements) signs to a target video in a photo-realistic manner. To effectively capture the aforementioned cues, which are crucial for sign language communication, we build upon an effective combination of the most robust and reliable deep learning methods for body, hand and face tracking that have been introduced lately. Using a 3D-aware representation, the estimated motions of the body parts are combined and retargeted to the target signer. They are then given as conditional input to our Video Rendering Network, which generates temporally consistent and photo-realistic videos. We conduct detailed qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and its advantages over existing approaches. Our method yields promising results of unprecedented realism and can be used for Sign Language Anonymization. In addition, it can be readily applicable to reenactment of other types of full body activities (dancing, acting performance, exercising, etc.), as well as to the synthesis module of Sign Language Production systems.
Investigating Bias and Fairness in Facial Expression Recognition
Aug 21, 2020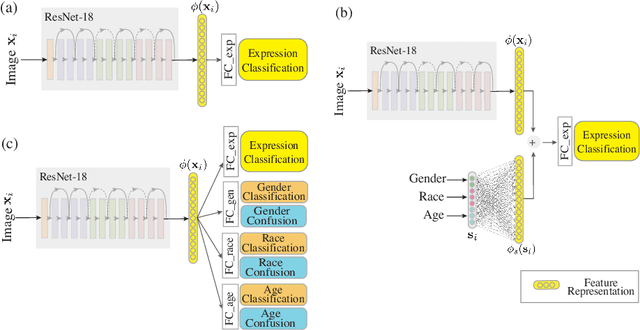
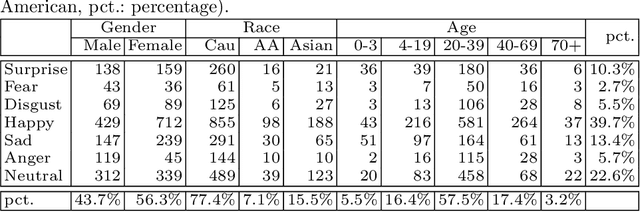
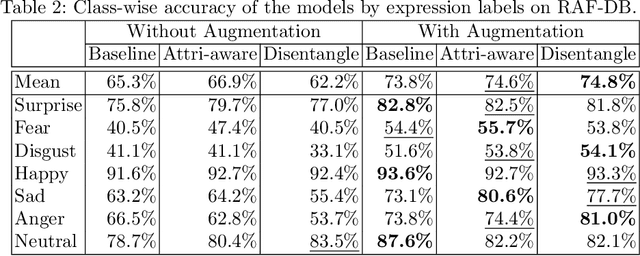
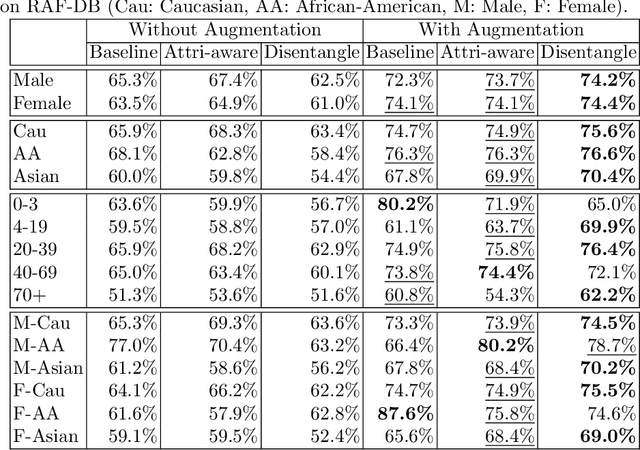
Recognition of expressions of emotions and affect from facial images is a well-studied research problem in the fields of affective computing and computer vision with a large number of datasets available containing facial images and corresponding expression labels. However, virtually none of these datasets have been acquired with consideration of fair distribution across the human population. Therefore, in this work, we undertake a systematic investigation of bias and fairness in facial expression recognition by comparing three different approaches, namely a baseline, an attribute-aware and a disentangled approach, on two well-known datasets, RAF-DB and CelebA. Our results indicate that: (i) data augmentation improves the accuracy of the baseline model, but this alone is unable to mitigate the bias effect; (ii) both the attribute-aware and the disentangled approaches fortified with data augmentation perform better than the baseline approach in terms of accuracy and fairness; (iii) the disentangled approach is the best for mitigating demographic bias; and (iv) the bias mitigation strategies are more suitable in the existence of uneven attribute distribution or imbalanced number of subgroup data.