 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Uncovering the Bias in Facial Expressions
Nov 23, 2020
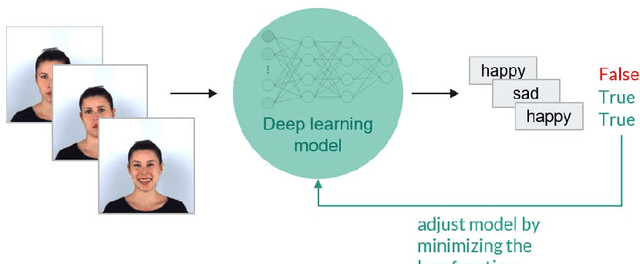
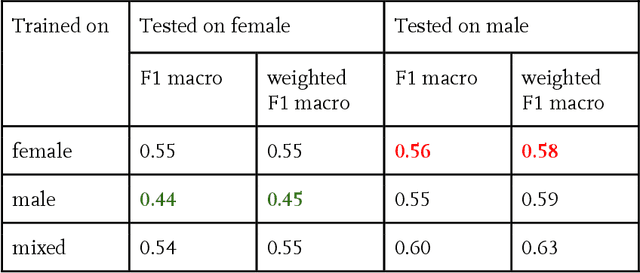


Over the past decades the machine and deep learning community has celebrated great achievements in challenging tasks such as image classification. The deep architecture of artificial neural networks together with the plenitude of available data makes it possible to describe highly complex relations. Yet, it is still impossible to fully capture what the deep learning model has learned and to verify that it operates fairly and without creating bias, especially in critical tasks, for instance those arising in the medical field. One example for such a task is the detection of distinct facial expressions, called Action Units, in facial images. Considering this specific task, our research aims to provide transparency regarding bias, specifically in relation to gender and skin color. We train a neural network for Action Unit classification and analyze its performance quantitatively based on its accuracy and qualitatively based on heatmaps. A structured review of our results indicates that we are able to detect bias. Even though we cannot conclude from our results that lower classification performance emerged solely from gender and skin color bias, these biases must be addressed, which is why we end by giving suggestions on how the detected bias can be avoided.
Facial expression and attributes recognition based on multi-task learning of lightweight neural networks
Mar 31, 2021

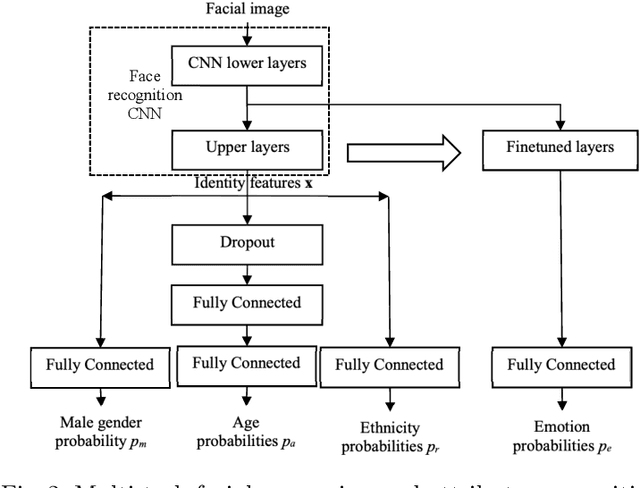
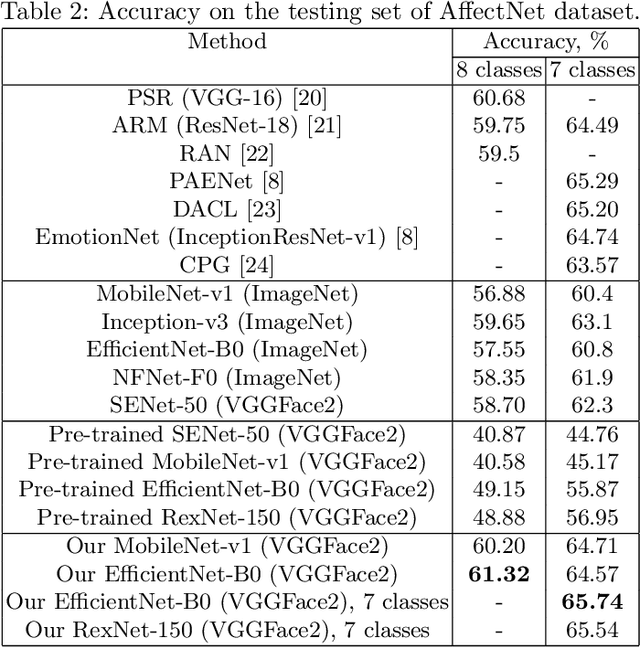
In this paper, we examine the multi-task training of lightweight convolutional neural networks for face identification and classification of facial attributes (age, gender, ethnicity) trained on cropped faces without margins. It is shown that it is still necessary to fine-tune these networks in order to predict facial expressions. Several models are presented based on MobileNet, EfficientNet and RexNet architectures. It was experimentally demonstrated that our models are characterized by the state-of-the-art emotion classification accuracy on AffectNet dataset and near state-of-the-art results in age, gender and race recognition for UTKFace dataset. Moreover, it is shown that the usage of our neural network as a feature extractor of facial regions in video frames and concatenation of several statistical functions (mean, max, etc.) leads to 4.5\% higher accuracy than the previously known state-of-the-art single models for AFEW and VGAF datasets from the EmotiW challenges. The models and source code are publicly available at https://github.com/HSE-asavchenko/face-emotion-recognition.
WSC-Trans: A 3D network model for automatic multi-structural segmentation of temporal bone CT
Nov 14, 2022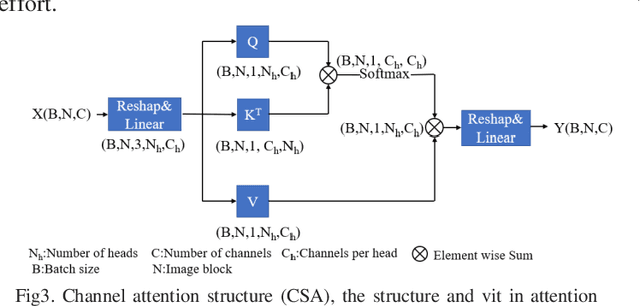
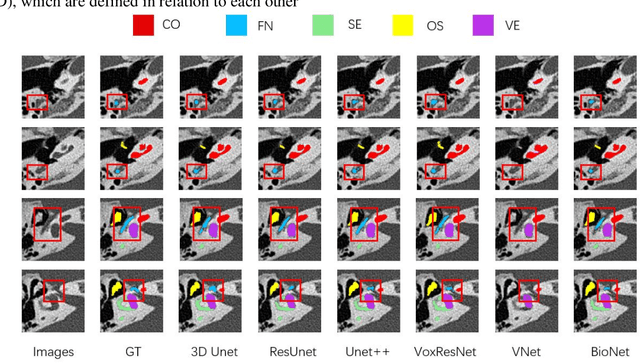
Cochlear implantation is currently the most effective treatment for patients with severe deafness, but mastering cochlear implantation is extremely challenging because the temporal bone has extremely complex and small three-dimensional anatomical structures, and it is important to avoid damaging the corresponding structures when performing surgery. The spatial location of the relevant anatomical tissues within the target area needs to be determined using CT prior to the procedure. Considering that the target structures are too small and complex, the time required for manual segmentation is too long, and it is extremely challenging to segment the temporal bone and its nearby anatomical structures quickly and accurately. To overcome this difficulty, we propose a deep learning-based algorithm, a 3D network model for automatic segmentation of multi-structural targets in temporal bone CT that can automatically segment the cochlea, facial nerve, auditory tubercle, vestibule and semicircular canal. The algorithm combines CNN and Transformer for feature extraction and takes advantage of spatial attention and channel attention mechanisms to further improve the segmentation effect, the experimental results comparing with the results of various existing segmentation algorithms show that the dice similarity scores, Jaccard coefficients of all targets anatomical structures are significantly higher while HD95 and ASSD scores are lower, effectively proving that our method outperforms other advanced methods.
IntereStyle: Encoding an Interest Region for Robust StyleGAN Inversion
Sep 22, 2022
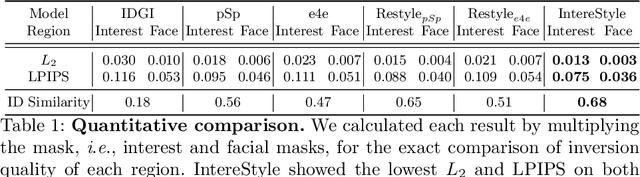

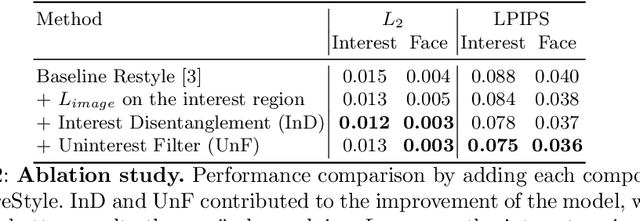
Recently, manipulation of real-world images has been highly elaborated along with the development of Generative Adversarial Networks (GANs) and corresponding encoders, which embed real-world images into the latent space. However, designing encoders of GAN still remains a challenging task due to the trade-off between distortion and perception. In this paper, we point out that the existing encoders try to lower the distortion not only on the interest region, e.g., human facial region but also on the uninterest region, e.g., background patterns and obstacles. However, most uninterest regions in real-world images are located at out-of-distribution (OOD), which are infeasible to be ideally reconstructed by generative models. Moreover, we empirically find that the uninterest region overlapped with the interest region can mangle the original feature of the interest region, e.g., a microphone overlapped with a facial region is inverted into the white beard. As a result, lowering the distortion of the whole image while maintaining the perceptual quality is very challenging. To overcome this trade-off, we propose a simple yet effective encoder training scheme, coined IntereStyle, which facilitates encoding by focusing on the interest region. IntereStyle steers the encoder to disentangle the encodings of the interest and uninterest regions. To this end, we filter the information of the uninterest region iteratively to regulate the negative impact of the uninterest region. We demonstrate that IntereStyle achieves both lower distortion and higher perceptual quality compared to the existing state-of-the-art encoders. Especially, our model robustly conserves features of the original images, which shows the robust image editing and style mixing results. We will release our code with the pre-trained model after the review.
3D Facial Geometry Recovery from a Depth View with Attention Guided Generative Adversarial Network
Sep 02, 2020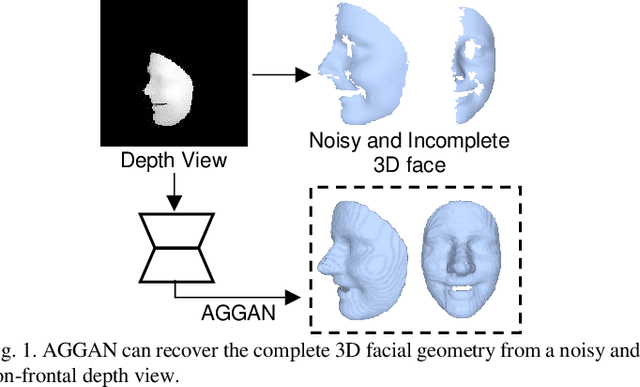
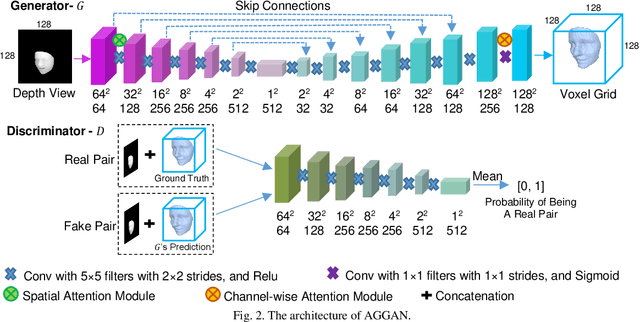
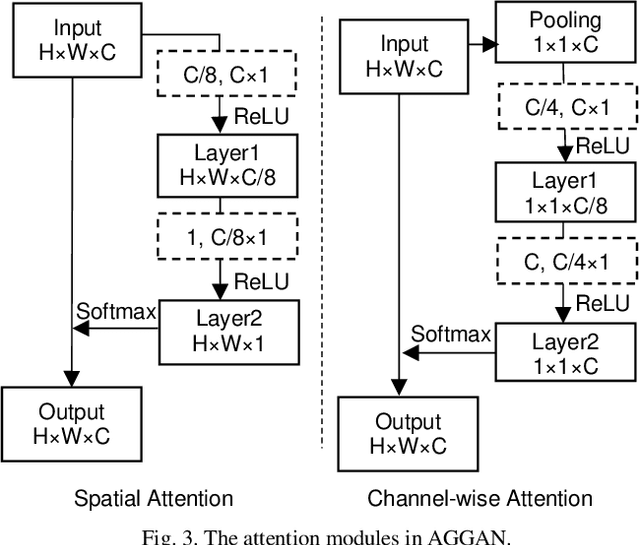
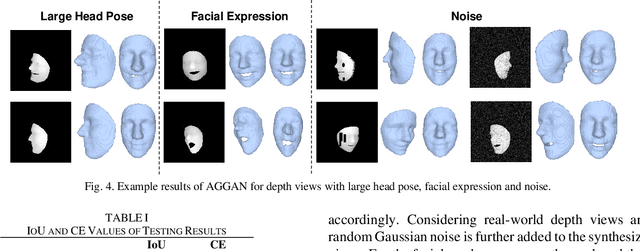
We present to recover the complete 3D facial geometry from a single depth view by proposing an Attention Guided Generative Adversarial Networks (AGGAN). In contrast to existing work which normally requires two or more depth views to recover a full 3D facial geometry, the proposed AGGAN is able to generate a dense 3D voxel grid of the face from a single unconstrained depth view. Specifically, AGGAN encodes the 3D facial geometry within a voxel space and utilizes an attention-guided GAN to model the illposed 2.5D depth-3D mapping. Multiple loss functions, which enforce the 3D facial geometry consistency, together with a prior distribution of facial surface points in voxel space are incorporated to guide the training process. Both qualitative and quantitative comparisons show that AGGAN recovers a more complete and smoother 3D facial shape, with the capability to handle a much wider range of view angles and resist to noise in the depth view than conventional methods
Learning to regulate 3D head shape by removing occluding hair from in-the-wild images
Aug 25, 2022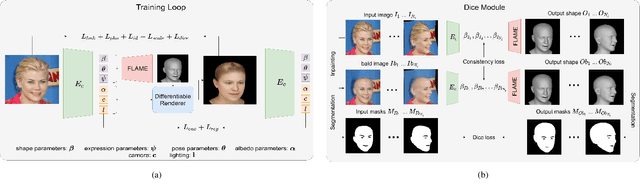
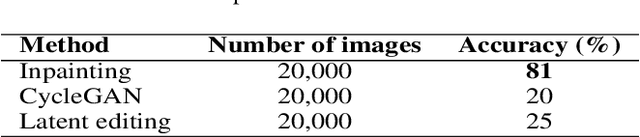
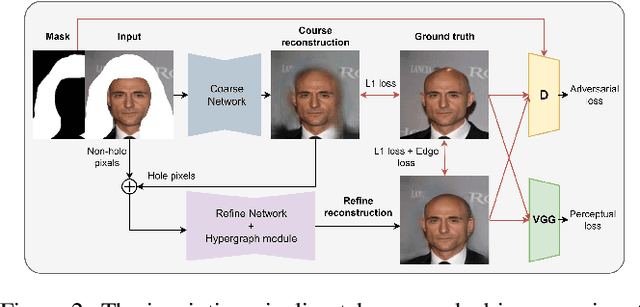
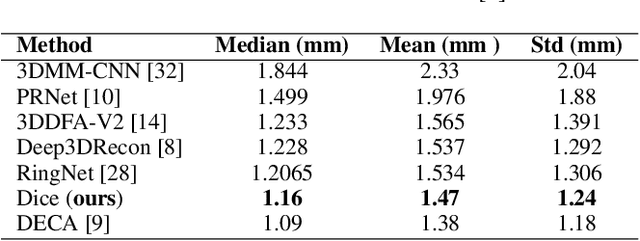
Recent 3D face reconstruction methods reconstruct the entire head compared to earlier approaches which only model the face. Although these methods accurately reconstruct facial features, they do not explicitly regulate the upper part of the head. Extracting information about this part of the head is challenging due to varying degrees of occlusion by hair. We present a novel approach for modeling the upper head by removing occluding hair and reconstructing the skin, revealing information about the head shape. We introduce three objectives: 1) a dice consistency loss that enforces similarity between the overall head shape of the source and rendered image, 2) a scale consistency loss to ensure that head shape is accurately reproduced even if the upper part of the head is not visible, and 3) a 71 landmark detector trained using a moving average loss function to detect additional landmarks on the head. These objectives are used to train an encoder in an unsupervised manner to regress FLAME parameters from in-the-wild input images. Our unsupervised 3DMM model achieves state-of-the-art results on popular benchmarks and can be used to infer the head shape, facial features, and textures for direct use in animation or avatar creation.
FAIVConf: Face enhancement for AI-based Video Conference with Low Bit-rate
Jul 08, 2022
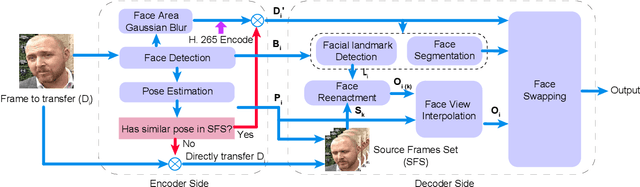
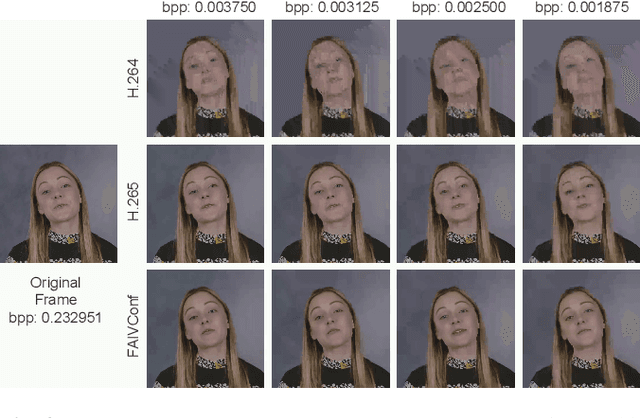
Recently, high-quality video conferencing with fewer transmission bits has become a very hot and challenging problem. We propose FAIVConf, a specially designed video compression framework for video conferencing, based on the effective neural human face generation techniques. FAIVConf brings together several designs to improve the system robustness in real video conference scenarios: face-swapping to avoid artifacts in background animation; facial blurring to decrease transmission bit-rate and maintain the quality of extracted facial landmarks; and dynamic source update for face view interpolation to accommodate a large range of head poses. Our method achieves a significant bit-rate reduction in the video conference and gives much better visual quality under the same bit-rate compared with H.264 and H.265 coding schemes.
Suppressing Uncertainties for Large-Scale Facial Expression Recognition
Mar 06, 2020

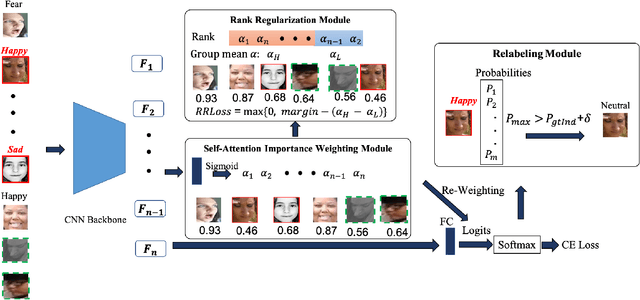
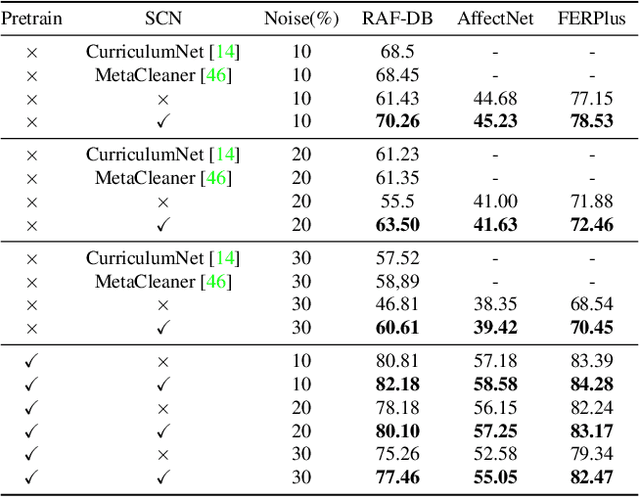
Annotating a qualitative large-scale facial expression dataset is extremely difficult due to the uncertainties caused by ambiguous facial expressions, low-quality facial images, and the subjectiveness of annotators. These uncertainties lead to a key challenge of large-scale Facial Expression Recognition (FER) in deep learning era. To address this problem, this paper proposes a simple yet efficient Self-Cure Network (SCN) which suppresses the uncertainties efficiently and prevents deep networks from over-fitting uncertain facial images. Specifically, SCN suppresses the uncertainty from two different aspects: 1) a self-attention mechanism over mini-batch to weight each training sample with a ranking regularization, and 2) a careful relabeling mechanism to modify the labels of these samples in the lowest-ranked group. Experiments on synthetic FER datasets and our collected WebEmotion dataset validate the effectiveness of our method. Results on public benchmarks demonstrate that our SCN outperforms current state-of-the-art methods with \textbf{88.14}\% on RAF-DB, \textbf{60.23}\% on AffectNet, and \textbf{89.35}\% on FERPlus. The code will be available at \href{https://github.com/kaiwang960112/Self-Cure-Network}{https://github.com/kaiwang960112/Self-Cure-Network}.
Unsupervised Facial Action Unit Intensity Estimation via Differentiable Optimization
Apr 13, 2020
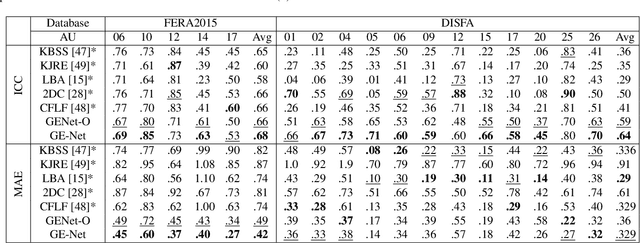
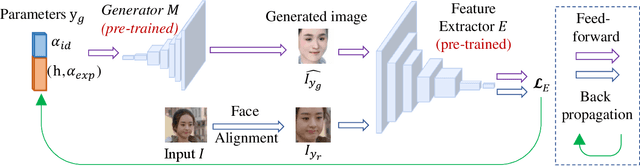
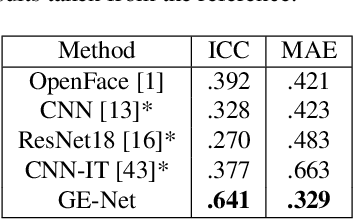
The automatic intensity estimation of facial action units (AUs) from a single image plays a vital role in facial analysis systems. One big challenge for data-driven AU intensity estimation is the lack of sufficient AU label data. Due to the fact that AU annotation requires strong domain expertise, it is expensive to construct an extensive database to learn deep models. The limited number of labeled AUs as well as identity differences and pose variations further increases the estimation difficulties. Considering all these difficulties, we propose an unsupervised framework GE-Net for facial AU intensity estimation from a single image, without requiring any annotated AU data. Our framework performs differentiable optimization, which iteratively updates the facial parameters (i.e., head pose, AU parameters and identity parameters) to match the input image. GE-Net consists of two modules: a generator and a feature extractor. The generator learns to "render" a face image from a set of facial parameters in a differentiable way, and the feature extractor extracts deep features for measuring the similarity of the rendered image and input real image. After the two modules are trained and fixed, the framework searches optimal facial parameters by minimizing the differences of the extracted features between the rendered image and the input image. Experimental results demonstrate that our method can achieve state-of-the-art results compared with existing methods.
Domain Adaptation for Facial Expression Classifier via Domain Discrimination and Gradient Reversal
Jun 02, 2021
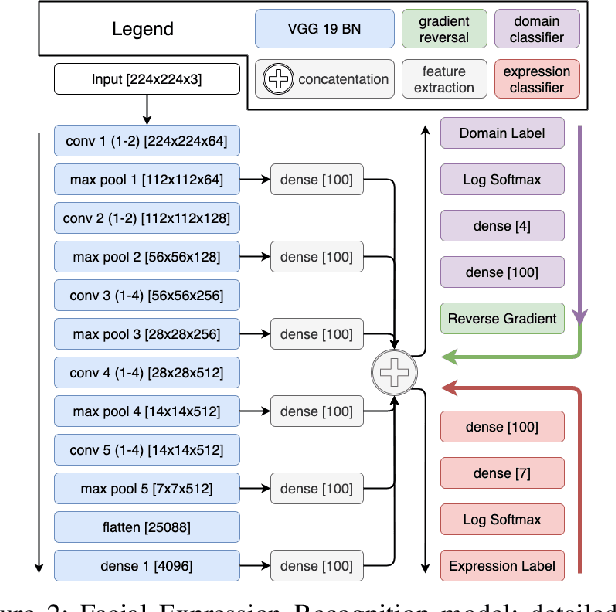
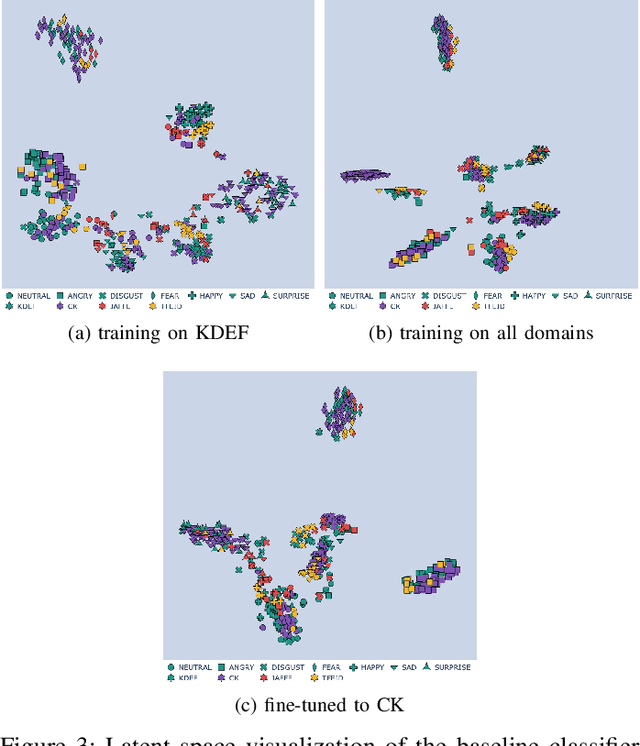
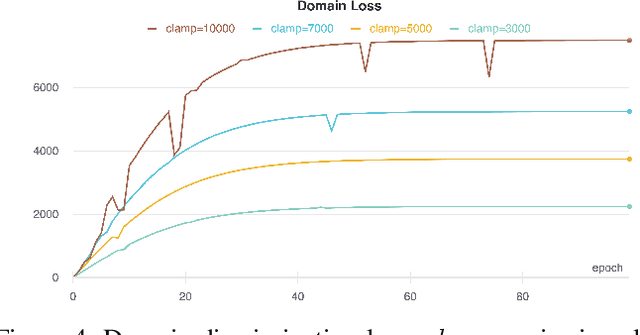
Bringing empathy to a computerized system could significantly improve the quality of human-computer communications, as soon as machines would be able to understand customer intentions and better serve their needs. According to different studies (Literature Review), visual information is one of the most important channels of human interaction and contains significant behavioral signals, that may be captured from facial expressions. Therefore, it is consistent and natural that the research in the field of Facial Expression Recognition (FER) has acquired increased interest over the past decade due to having diverse application area including health-care, sociology, psychology, driver-safety, virtual reality, cognitive sciences, security, entertainment, marketing, etc. We propose a new architecture for the task of FER and examine the impact of domain discrimination loss regularization on the learning process. With regard to observations, including both classical training conditions and unsupervised domain adaptation scenarios, important aspects of the considered domain adaptation approach integration are traced. The results may serve as a foundation for further research in the field.