 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Free-HeadGAN: Neural Talking Head Synthesis with Explicit Gaze Control
Aug 03, 2022
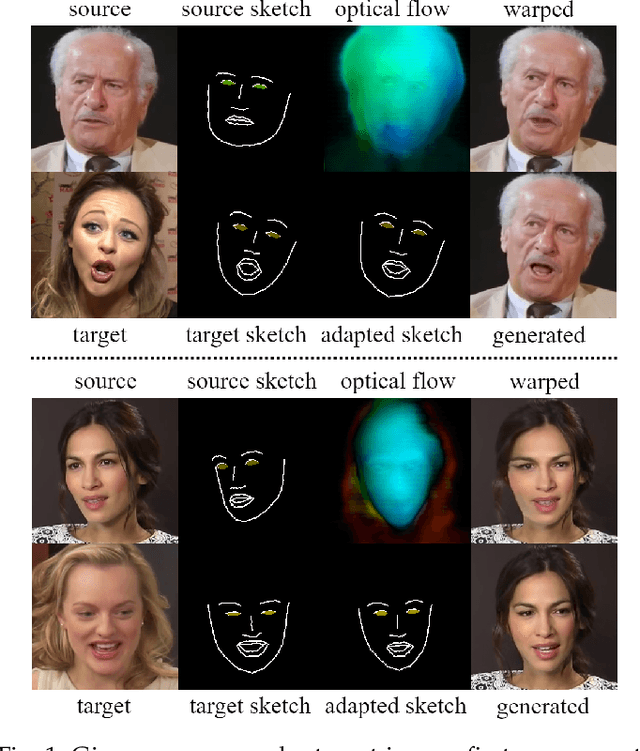
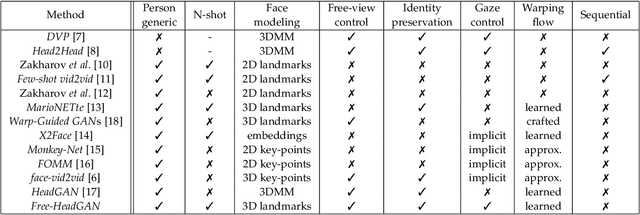
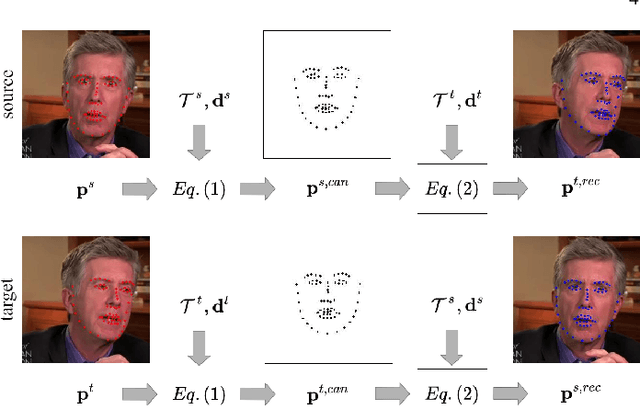
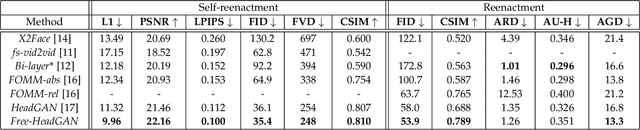
We present Free-HeadGAN, a person-generic neural talking head synthesis system. We show that modeling faces with sparse 3D facial landmarks are sufficient for achieving state-of-the-art generative performance, without relying on strong statistical priors of the face, such as 3D Morphable Models. Apart from 3D pose and facial expressions, our method is capable of fully transferring the eye gaze, from a driving actor to a source identity. Our complete pipeline consists of three components: a canonical 3D key-point estimator that regresses 3D pose and expression-related deformations, a gaze estimation network and a generator that is built upon the architecture of HeadGAN. We further experiment with an extension of our generator to accommodate few-shot learning using an attention mechanism, in case more than one source images are available. Compared to the latest models for reenactment and motion transfer, our system achieves higher photo-realism combined with superior identity preservation, while offering explicit gaze control.
AuthNet: A Deep Learning based Authentication Mechanism using Temporal Facial Feature Movements
Dec 19, 2020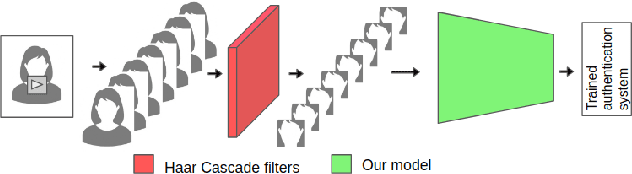

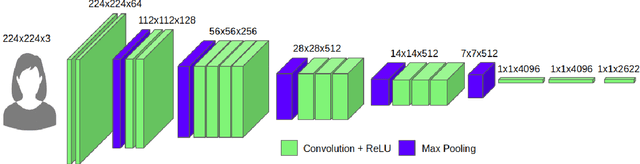

Biometric systems based on Machine learning and Deep learning are being extensively used as authentication mechanisms in resource-constrained environments like smartphones and other small computing devices. These AI-powered facial recognition mechanisms have gained enormous popularity in recent years due to their transparent, contact-less and non-invasive nature. While they are effective to a large extent, there are ways to gain unauthorized access using photographs, masks, glasses, etc. In this paper, we propose an alternative authentication mechanism that uses both facial recognition and the unique movements of that particular face while uttering a password, that is, the temporal facial feature movements. The proposed model is not inhibited by language barriers because a user can set a password in any language. When evaluated on the standard MIRACL-VC1 dataset, the proposed model achieved an accuracy of 98.1%, underscoring its effectiveness as an effective and robust system. The proposed method is also data-efficient since the model gave good results even when trained with only 10 positive video samples. The competence of the training of the network is also demonstrated by benchmarking the proposed system against various compounded Facial recognition and Lip reading models.
Deep Evolution for Facial Emotion Recognition
Oct 13, 2020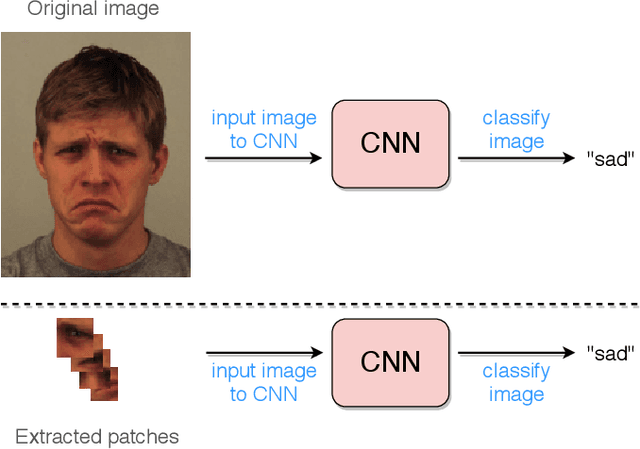
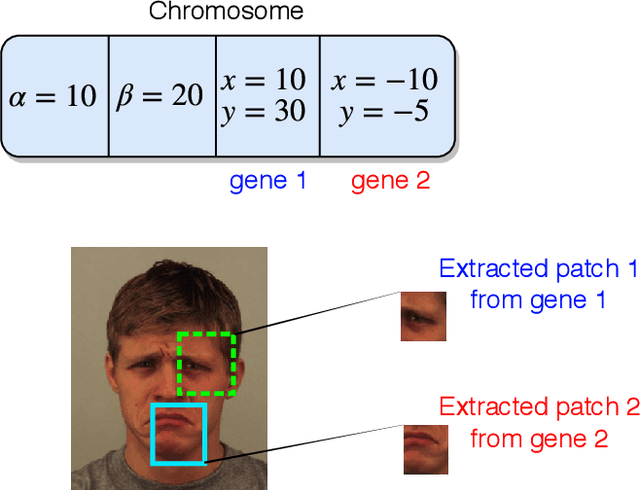

Deep facial expression recognition faces two challenges that both stem from the large number of trainable parameters: long training times and a lack of interpretability. We propose a novel method based on evolutionary algorithms, that deals with both challenges by massively reducing the number of trainable parameters, whilst simultaneously retaining classification performance, and in some cases achieving superior performance. We are robustly able to reduce the number of parameters on average by 95% (e.g. from 2M to 100k parameters) with no loss in classification accuracy. The algorithm learns to choose small patches from the image, relative to the nose, which carry the most important information about emotion, and which coincide with typical human choices of important features. Our work implements a novel form attention and shows that evolutionary algorithms are a valuable addition to machine learning in the deep learning era, both for reducing the number of parameters for facial expression recognition and for providing interpretable features that can help reduce bias.
The Impact of Racial Distribution in Training Data on Face Recognition Bias: A Closer Look
Nov 26, 2022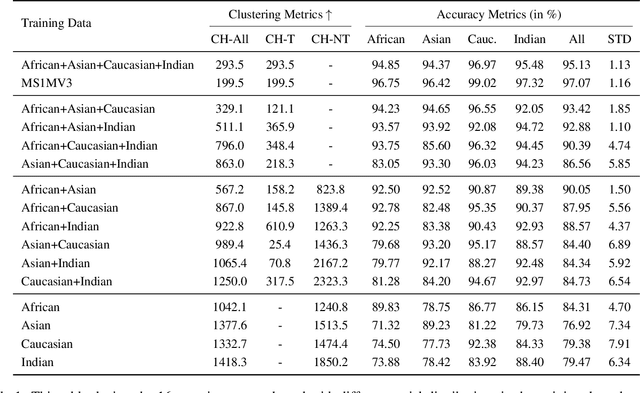
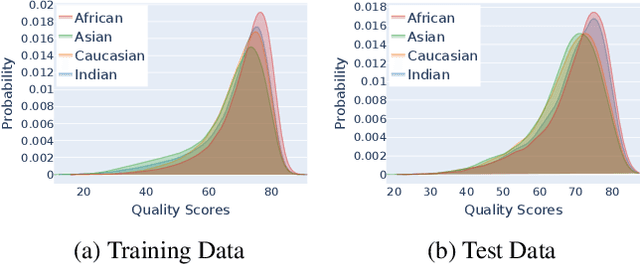
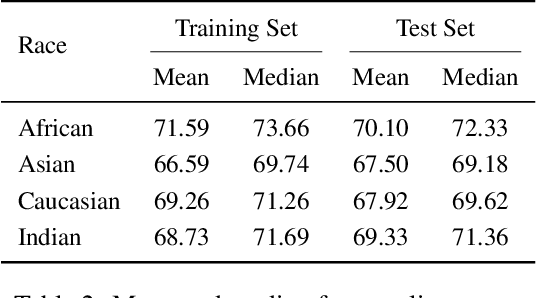
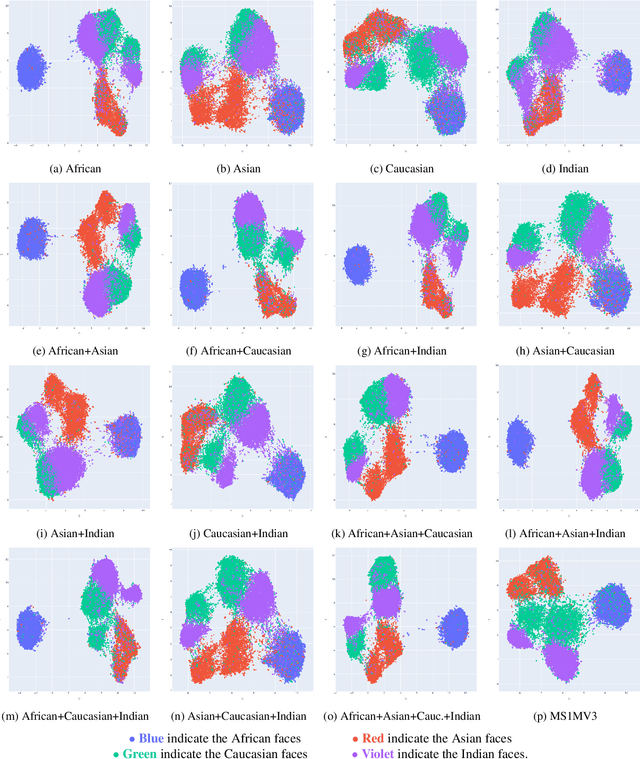
Face recognition algorithms, when used in the real world, can be very useful, but they can also be dangerous when biased toward certain demographics. So, it is essential to understand how these algorithms are trained and what factors affect their accuracy and fairness to build better ones. In this study, we shed some light on the effect of racial distribution in the training data on the performance of face recognition models. We conduct 16 different experiments with varying racial distributions of faces in the training data. We analyze these trained models using accuracy metrics, clustering metrics, UMAP projections, face quality, and decision thresholds. We show that a uniform distribution of races in the training datasets alone does not guarantee bias-free face recognition algorithms and how factors like face image quality play a crucial role. We also study the correlation between the clustering metrics and bias to understand whether clustering is a good indicator of bias. Finally, we introduce a metric called racial gradation to study the inter and intra race correlation in facial features and how they affect the learning ability of the face recognition models. With this study, we try to bring more understanding to an essential element of face recognition training, the data. A better understanding of the impact of training data on the bias of face recognition algorithms will aid in creating better datasets and, in turn, better face recognition systems.
Transforming Facial Weight of Real Images by Editing Latent Space of StyleGAN
Nov 05, 2020



We present an invert-and-edit framework to automatically transform facial weight of an input face image to look thinner or heavier by leveraging semantic facial attributes encoded in the latent space of Generative Adversarial Networks (GANs). Using a pre-trained StyleGAN as the underlying generator, we first employ an optimization-based embedding method to invert the input image into the StyleGAN latent space. Then, we identify the facial-weight attribute direction in the latent space via supervised learning and edit the inverted latent code by moving it positively or negatively along the extracted feature axis. Our framework is empirically shown to produce high-quality and realistic facial-weight transformations without requiring training GANs with a large amount of labeled face images from scratch. Ultimately, our framework can be utilized as part of an intervention to motivate individuals to make healthier food choices by visualizing the future impacts of their behavior on appearance.
Is Face Recognition Safe from Realizable Attacks?
Oct 15, 2022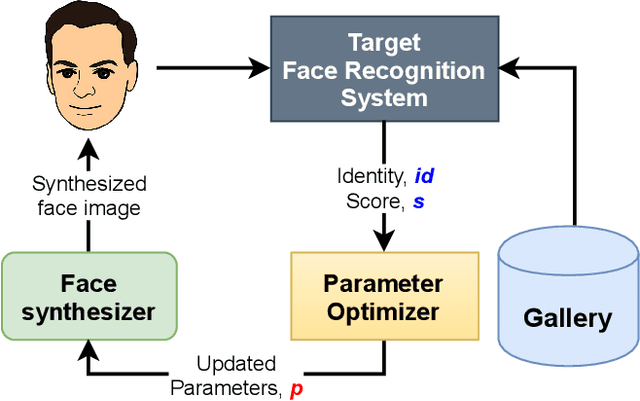



Face recognition is a popular form of biometric authentication and due to its widespread use, attacks have become more common as well. Recent studies show that Face Recognition Systems are vulnerable to attacks and can lead to erroneous identification of faces. Interestingly, most of these attacks are white-box, or they are manipulating facial images in ways that are not physically realizable. In this paper, we propose an attack scheme where the attacker can generate realistic synthesized face images with subtle perturbations and physically realize that onto his face to attack black-box face recognition systems. Comprehensive experiments and analyses show that subtle perturbations realized on attackers face can create successful attacks on state-of-the-art face recognition systems in black-box settings. Our study exposes the underlying vulnerability posed by the Face Recognition Systems against realizable black-box attacks.
Human Face Recognition from Part of a Facial Image based on Image Stitching
Mar 10, 2022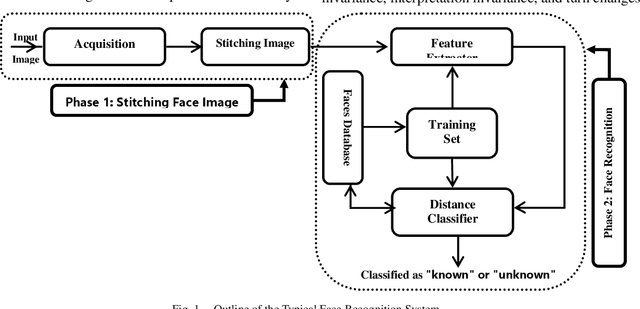
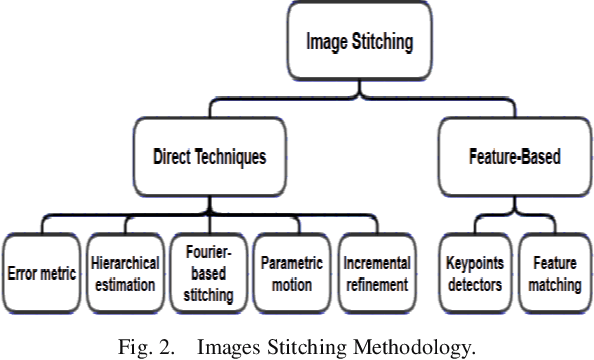


Most of the current techniques for face recognition require the presence of a full face of the person to be recognized, and this situation is difficult to achieve in practice, the required person may appear with a part of his face, which requires prediction of the part that did not appear. Most of the current forecasting processes are done by what is known as image interpolation, which does not give reliable results, especially if the missing part is large. In this work, we adopted the process of stitching the face by completing the missing part with the flipping of the part shown in the picture, depending on the fact that the human face is characterized by symmetry in most cases. To create a complete model, two facial recognition methods were used to prove the efficiency of the algorithm. The selected face recognition algorithms that are applied here are Eigenfaces and geometrical methods. Image stitching is the process during which distinctive photographic images are combined to make a complete scene or a high-resolution image. Several images are integrated to form a wide-angle panoramic image. The quality of the image stitching is determined by calculating the similarity among the stitched image and original images and by the presence of the seam lines through the stitched images. The Eigenfaces approach utilizes PCA calculation to reduce the feature vector dimensions. It provides an effective approach for discovering the lower-dimensional space. In addition, to enable the proposed algorithm to recognize the face, it also ensures a fast and effective way of classifying faces. The phase of feature extraction is followed by the classifier phase.
WSC-Trans: A 3D network model for automatic multi-structural segmentation of temporal bone CT
Nov 14, 2022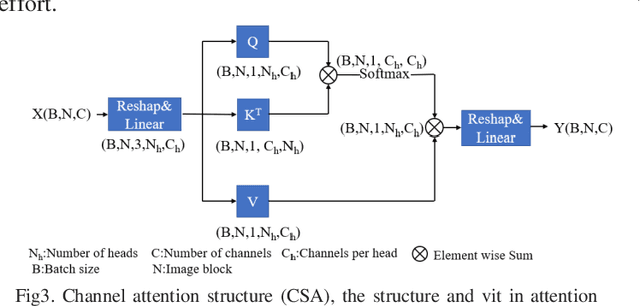
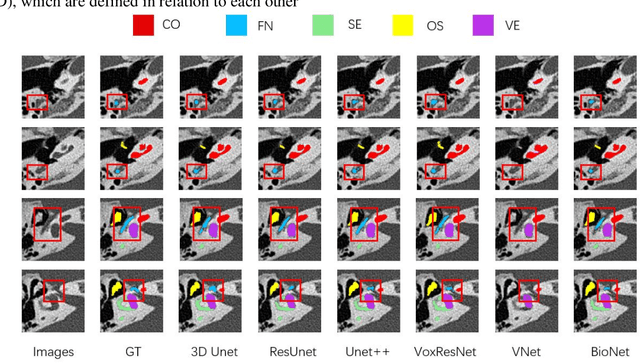
Cochlear implantation is currently the most effective treatment for patients with severe deafness, but mastering cochlear implantation is extremely challenging because the temporal bone has extremely complex and small three-dimensional anatomical structures, and it is important to avoid damaging the corresponding structures when performing surgery. The spatial location of the relevant anatomical tissues within the target area needs to be determined using CT prior to the procedure. Considering that the target structures are too small and complex, the time required for manual segmentation is too long, and it is extremely challenging to segment the temporal bone and its nearby anatomical structures quickly and accurately. To overcome this difficulty, we propose a deep learning-based algorithm, a 3D network model for automatic segmentation of multi-structural targets in temporal bone CT that can automatically segment the cochlea, facial nerve, auditory tubercle, vestibule and semicircular canal. The algorithm combines CNN and Transformer for feature extraction and takes advantage of spatial attention and channel attention mechanisms to further improve the segmentation effect, the experimental results comparing with the results of various existing segmentation algorithms show that the dice similarity scores, Jaccard coefficients of all targets anatomical structures are significantly higher while HD95 and ASSD scores are lower, effectively proving that our method outperforms other advanced methods.
Learning to Amend Facial Expression Representation via De-albino and Affinity
Mar 18, 2021

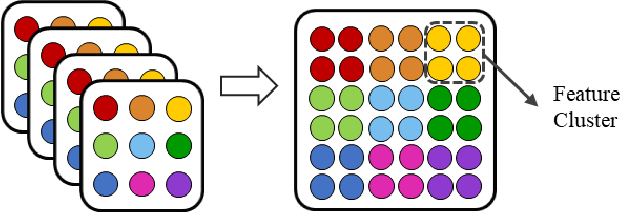

Facial Expression Recognition (FER) is a classification task that points to face variants. Hence, there are certain intimate relationships between facial expressions. We call them affinity features, which are barely taken into account by current FER algorithms. Besides, to capture the edge information of the image, Convolutional Neural Networks (CNNs) generally utilize a host of edge paddings. Although they are desirable, the feature map is deeply eroded after multi-layer convolution. We name what has formed in this process the albino features, which definitely weaken the representation of the expression. To tackle these challenges, we propose a novel architecture named Amend Representation Module (ARM). ARM is a substitute for the pooling layer. Theoretically, it could be embedded in any CNN with a pooling layer. ARM efficiently enhances facial expression representation from two different directions: 1) reducing the weight of eroded features to offset the side effect of padding, and 2) sharing affinity features over mini-batch to strengthen the representation learning. In terms of data imbalance, we designed a minimal random resampling (MRR) scheme to suppress network overfitting. Experiments on public benchmarks prove that our ARM boosts the performance of FER remarkably. The validation accuracies are respectively 90.55% on RAF-DB, 64.49% on Affect-Net, and 71.38% on FER2013, exceeding current state-of-the-art methods.
Region Based Adversarial Synthesis of Facial Action Units
Oct 23, 2019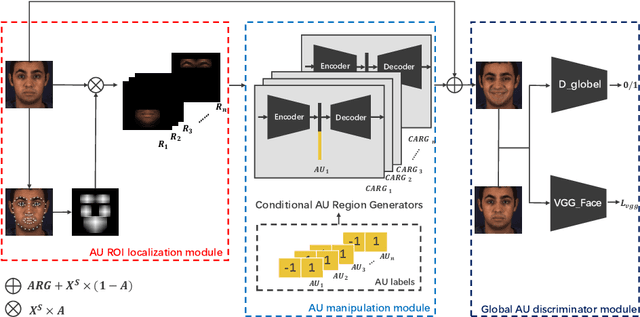
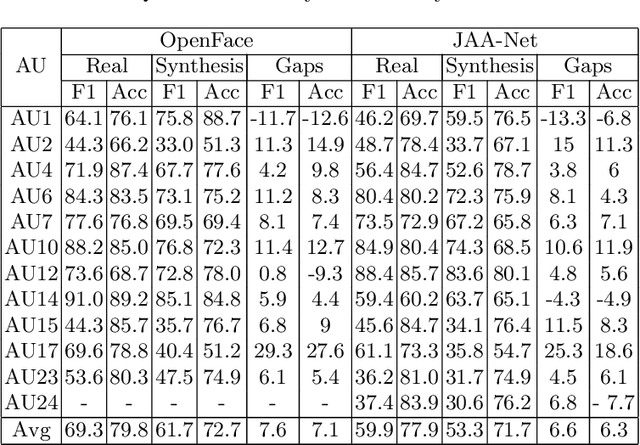
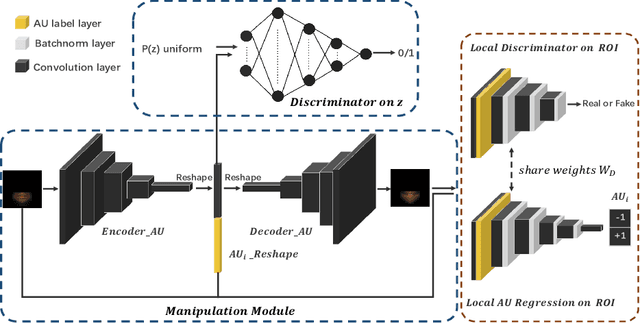
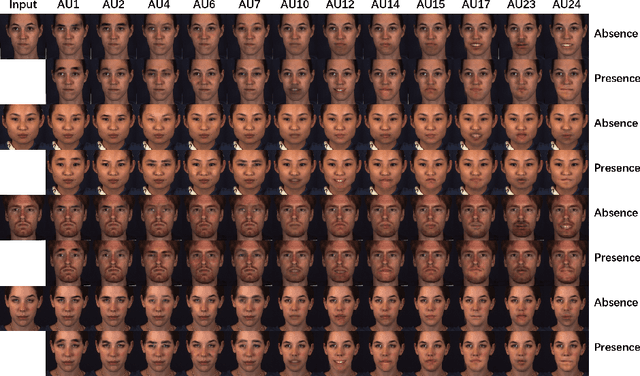
Facial expression synthesis or editing has recently received increasing attention in the field of affective computing and facial expression modeling. However, most existing facial expression synthesis works are limited in paired training data, low resolution, identity information damaging, and so on. To address those limitations, this paper introduces a novel Action Unit (AU) level facial expression synthesis method called Local Attentive Conditional Generative Adversarial Network (LAC-GAN) based on face action units annotations. Given desired AU labels, LAC-GAN utilizes local AU regional rules to control the status of each AU and attentive mechanism to combine several of them into the whole photo-realistic facial expressions or arbitrary facial expressions. In addition, unpaired training data is utilized in our proposed method to train the manipulation module with the corresponding AU labels, which learns a mapping between a facial expression manifold. Extensive qualitative and quantitative evaluations are conducted on the commonly used BP4D dataset to verify the effectiveness of our proposed AU synthesis method.