 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Graph-based Facial Affect Analysis: A Review of Methods, Applications and Challenges
Apr 05, 2021

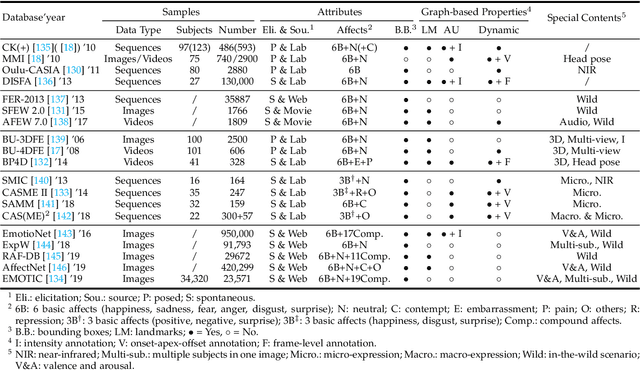
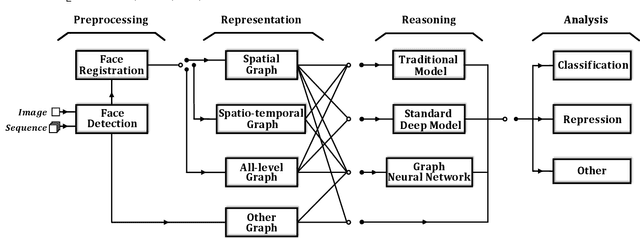
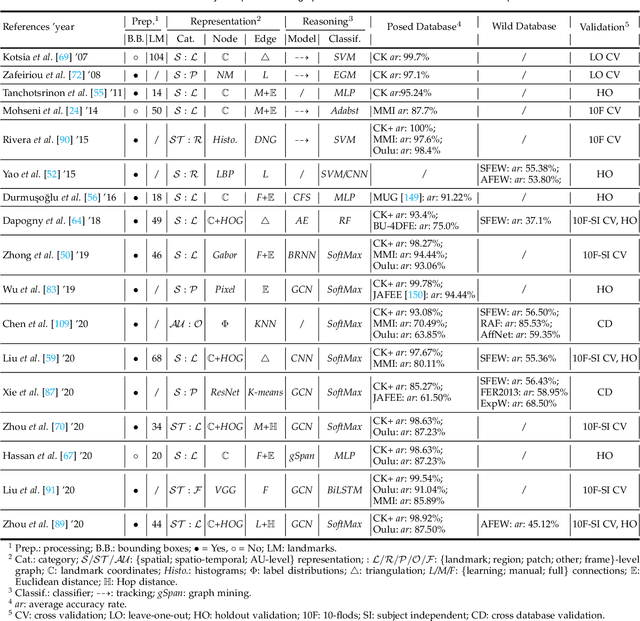
Facial affect analysis (FAA) using visual signals is a key step in human-computer interactions. Early methods mainly focus on extracting appearance and geometry features associated with human affects, while ignore the latent semantic information among individual facial changes, leading to limited performance and generalization. Recent trends attempt to establish a graph-based representation to model these semantic relationships and develop learning frameworks to leverage it for different FAA tasks. In this paper, we provide a comprehensive review of graph-based FAA, including the evolution of algorithms and their applications. First, we introduce the background knowledge of facial affect analysis, especially on the role of graph. We then discuss approaches that are widely used for graph-based affective representation in literatures and show a trend towards graph construction. For the relational reasoning in graph-based FAA, we categorize the existing studies according to their usage of traditional methods or deep models, with a special emphasis on latest graph neural networks. Experimental comparisons of the state-of-the-art on standard FAA problems are also summarized. Finally, we discuss the challenges and potential directions. As far as we know, this is the first survey of graph-based FAA methods, and our findings can serve as a reference point for future research in this field.
An Ensemble with Shared Representations Based on Convolutional Networks for Continually Learning Facial Expressions
Mar 05, 2021
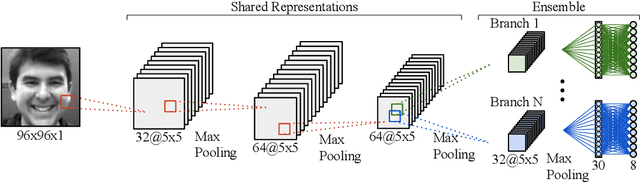

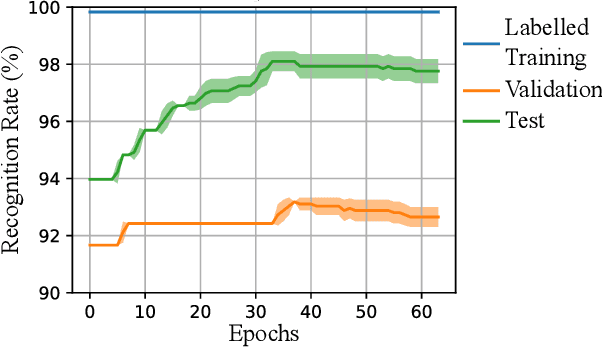
Social robots able to continually learn facial expressions could progressively improve their emotion recognition capability towards people interacting with them. Semi-supervised learning through ensemble predictions is an efficient strategy to leverage the high exposure of unlabelled facial expressions during human-robot interactions. Traditional ensemble-based systems, however, are composed of several independent classifiers leading to a high degree of redundancy, and unnecessary allocation of computational resources. In this paper, we proposed an ensemble based on convolutional networks where the early layers are strong low-level feature extractors, and their representations shared with an ensemble of convolutional branches. This results in a significant drop in redundancy of low-level features processing. Training in a semi-supervised setting, we show that our approach is able to continually learn facial expressions through ensemble predictions using unlabelled samples from different data distributions.
Semantic Unfolding of StyleGAN Latent Space
Jun 29, 2022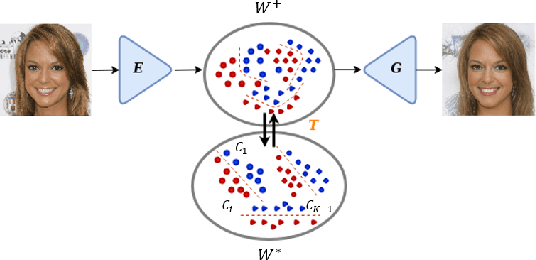
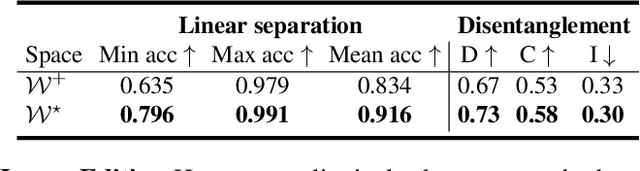

Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to an input real image. This editing property emerges from the disentangled nature of the latent space. In this paper, we identify that the facial attribute disentanglement is not optimal, thus facial editing relying on linear attribute separation is flawed. We thus propose to improve semantic disentanglement with supervision. Our method consists in learning a proxy latent representation using normalizing flows, and we show that this leads to a more efficient space for face image editing.
AuthNet: A Deep Learning based Authentication Mechanism using Temporal Facial Feature Movements
Dec 19, 2020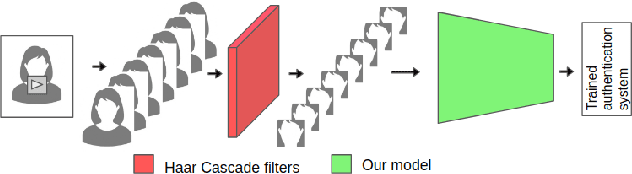


Biometric systems based on Machine learning and Deep learning are being extensively used as authentication mechanisms in resource-constrained environments like smartphones and other small computing devices. These AI-powered facial recognition mechanisms have gained enormous popularity in recent years due to their transparent, contact-less and non-invasive nature. While they are effective to a large extent, there are ways to gain unauthorized access using photographs, masks, glasses, etc. In this paper, we propose an alternative authentication mechanism that uses both facial recognition and the unique movements of that particular face while uttering a password, that is, the temporal facial feature movements. The proposed model is not inhibited by language barriers because a user can set a password in any language. When evaluated on the standard MIRACL-VC1 dataset, the proposed model achieved an accuracy of 98.1%, underscoring its effectiveness as an effective and robust system. The proposed method is also data-efficient since the model gave good results even when trained with only 10 positive video samples. The competence of the training of the network is also demonstrated by benchmarking the proposed system against various compounded Facial recognition and Lip reading models.
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
Jul 30, 2021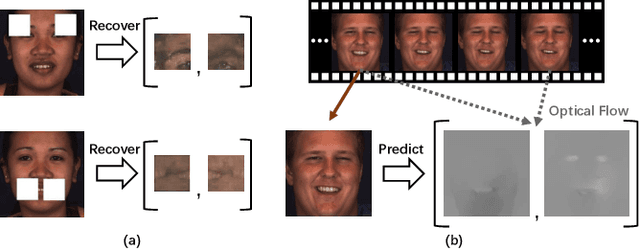
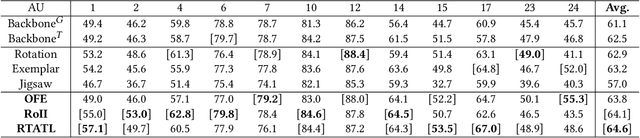
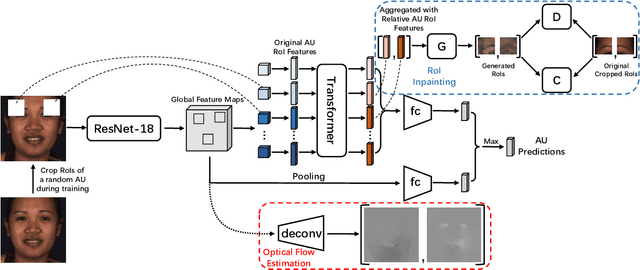
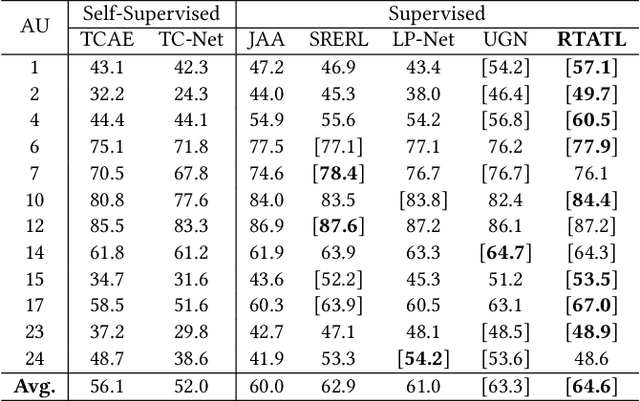
Automatic facial action unit (AU) recognition is a challenging task due to the scarcity of manual annotations. To alleviate this problem, a large amount of efforts has been dedicated to exploiting various methods which leverage numerous unlabeled data. However, many aspects with regard to some unique properties of AUs, such as the regional and relational characteristics, are not sufficiently explored in previous works. Motivated by this, we take the AU properties into consideration and propose two auxiliary AU related tasks to bridge the gap between limited annotations and the model performance in a self-supervised manner via the unlabeled data. Specifically, to enhance the discrimination of regional features with AU relation embedding, we design a task of RoI inpainting to recover the randomly cropped AU patches. Meanwhile, a single image based optical flow estimation task is proposed to leverage the dynamic change of facial muscles and encode the motion information into the global feature representation. Based on these two self-supervised auxiliary tasks, local features, mutual relation and motion cues of AUs are better captured in the backbone network with the proposed regional and temporal based auxiliary task learning (RTATL) framework. Extensive experiments on BP4D and DISFA demonstrate the superiority of our method and new state-of-the-art performances are achieved.
Deep Evolution for Facial Emotion Recognition
Oct 13, 2020
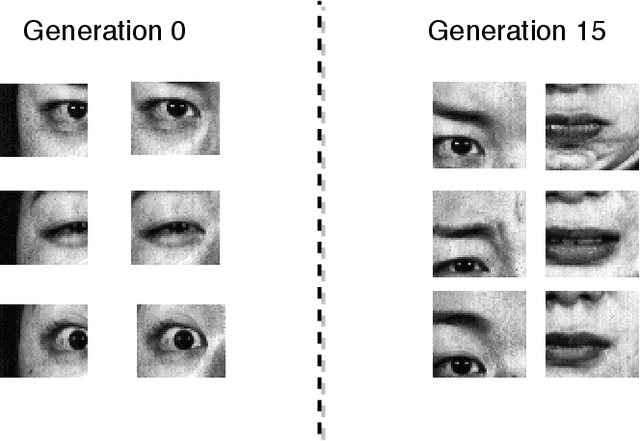
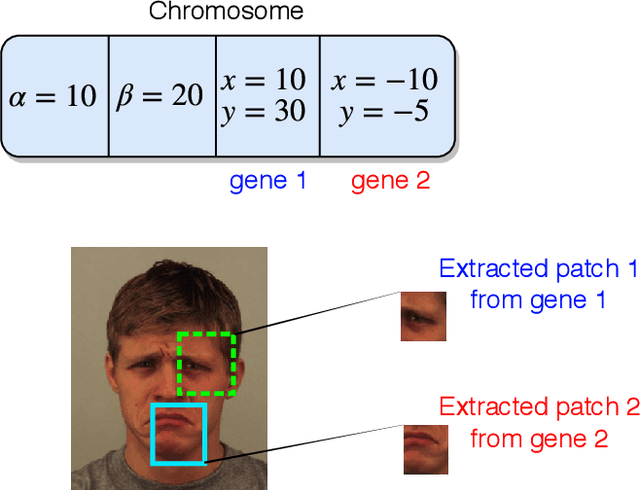

Deep facial expression recognition faces two challenges that both stem from the large number of trainable parameters: long training times and a lack of interpretability. We propose a novel method based on evolutionary algorithms, that deals with both challenges by massively reducing the number of trainable parameters, whilst simultaneously retaining classification performance, and in some cases achieving superior performance. We are robustly able to reduce the number of parameters on average by 95% (e.g. from 2M to 100k parameters) with no loss in classification accuracy. The algorithm learns to choose small patches from the image, relative to the nose, which carry the most important information about emotion, and which coincide with typical human choices of important features. Our work implements a novel form attention and shows that evolutionary algorithms are a valuable addition to machine learning in the deep learning era, both for reducing the number of parameters for facial expression recognition and for providing interpretable features that can help reduce bias.
Transforming Facial Weight of Real Images by Editing Latent Space of StyleGAN
Nov 05, 2020



We present an invert-and-edit framework to automatically transform facial weight of an input face image to look thinner or heavier by leveraging semantic facial attributes encoded in the latent space of Generative Adversarial Networks (GANs). Using a pre-trained StyleGAN as the underlying generator, we first employ an optimization-based embedding method to invert the input image into the StyleGAN latent space. Then, we identify the facial-weight attribute direction in the latent space via supervised learning and edit the inverted latent code by moving it positively or negatively along the extracted feature axis. Our framework is empirically shown to produce high-quality and realistic facial-weight transformations without requiring training GANs with a large amount of labeled face images from scratch. Ultimately, our framework can be utilized as part of an intervention to motivate individuals to make healthier food choices by visualizing the future impacts of their behavior on appearance.
Fantômas: Evaluating Reversibility of Face Anonymizations Using a General Deep Learning Attacker
Oct 19, 2022


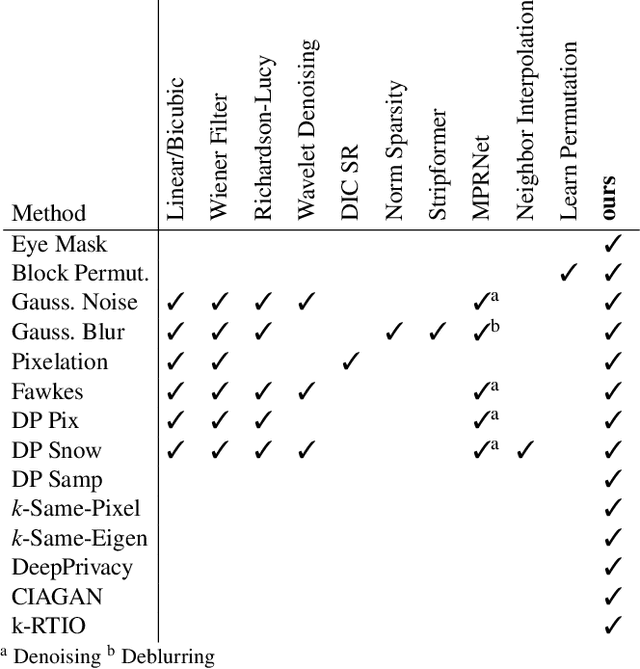
Biometric data is a rich source of information that can be used to identify individuals and infer private information about them. To mitigate this privacy risk, anonymization techniques employ transformations on clear data to obfuscate sensitive information, all while retaining some utility of the data. Albeit published with impressive claims, they sometimes are not evaluated with convincing methodology. We hence are interested to which extent recently suggested anonymization techniques for obfuscating facial images are effective. More specifically, we test how easily they can be automatically reverted, to estimate the privacy they can provide. Our approach is agnostic to the anonymization technique as we learn a machine learning model on the clear and corresponding anonymized data. We find that 10 out of 14 tested face anonymization techniques are at least partially reversible, and six of them are at least highly reversible.
SD-GAN: Semantic Decomposition for Face Image Synthesis with Discrete Attribute
Jul 12, 2022
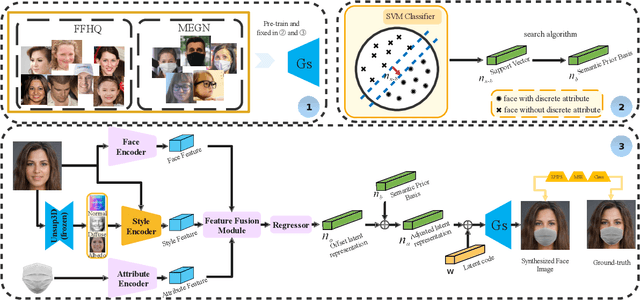
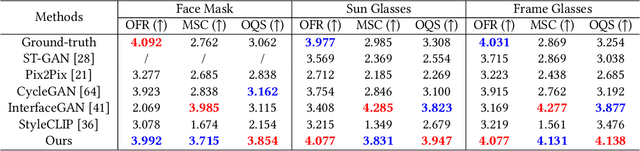
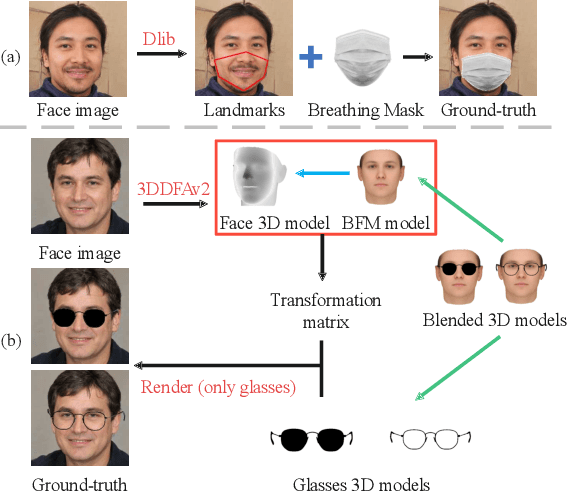
Manipulating latent code in generative adversarial networks (GANs) for facial image synthesis mainly focuses on continuous attribute synthesis (e.g., age, pose and emotion), while discrete attribute synthesis (like face mask and eyeglasses) receives less attention. Directly applying existing works to facial discrete attributes may cause inaccurate results. In this work, we propose an innovative framework to tackle challenging facial discrete attribute synthesis via semantic decomposing, dubbed SD-GAN. To be concrete, we explicitly decompose the discrete attribute representation into two components, i.e. the semantic prior basis and offset latent representation. The semantic prior basis shows an initializing direction for manipulating face representation in the latent space. The offset latent presentation obtained by 3D-aware semantic fusion network is proposed to adjust prior basis. In addition, the fusion network integrates 3D embedding for better identity preservation and discrete attribute synthesis. The combination of prior basis and offset latent representation enable our method to synthesize photo-realistic face images with discrete attributes. Notably, we construct a large and valuable dataset MEGN (Face Mask and Eyeglasses images crawled from Google and Naver) for completing the lack of discrete attributes in the existing dataset. Extensive qualitative and quantitative experiments demonstrate the state-of-the-art performance of our method. Our code is available at: https://github.com/MontaEllis/SD-GAN.
Region Based Adversarial Synthesis of Facial Action Units
Oct 23, 2019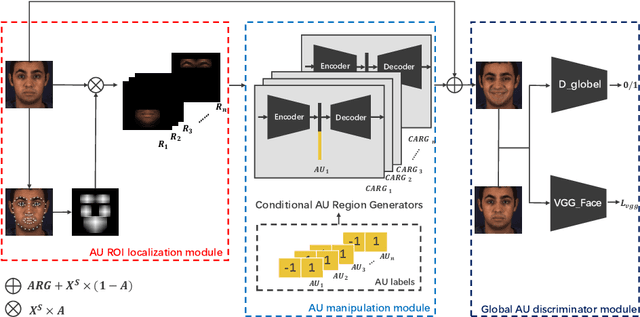
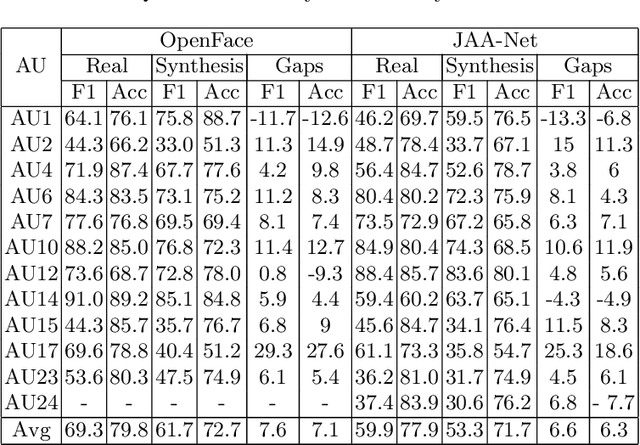
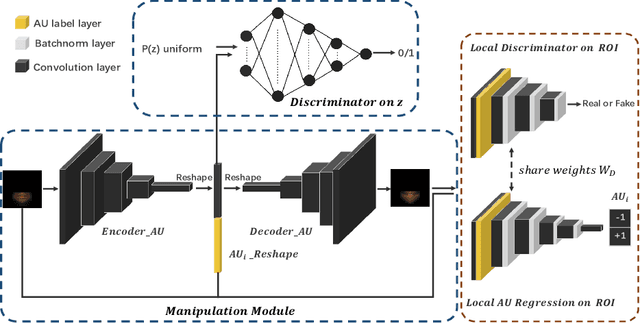
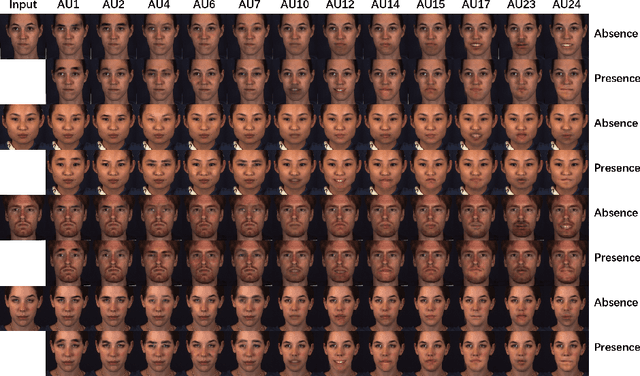
Facial expression synthesis or editing has recently received increasing attention in the field of affective computing and facial expression modeling. However, most existing facial expression synthesis works are limited in paired training data, low resolution, identity information damaging, and so on. To address those limitations, this paper introduces a novel Action Unit (AU) level facial expression synthesis method called Local Attentive Conditional Generative Adversarial Network (LAC-GAN) based on face action units annotations. Given desired AU labels, LAC-GAN utilizes local AU regional rules to control the status of each AU and attentive mechanism to combine several of them into the whole photo-realistic facial expressions or arbitrary facial expressions. In addition, unpaired training data is utilized in our proposed method to train the manipulation module with the corresponding AU labels, which learns a mapping between a facial expression manifold. Extensive qualitative and quantitative evaluations are conducted on the commonly used BP4D dataset to verify the effectiveness of our proposed AU synthesis method.