 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Quantum-Assisted Support Vector Regression for Detecting Facial Landmarks
Nov 17, 2021
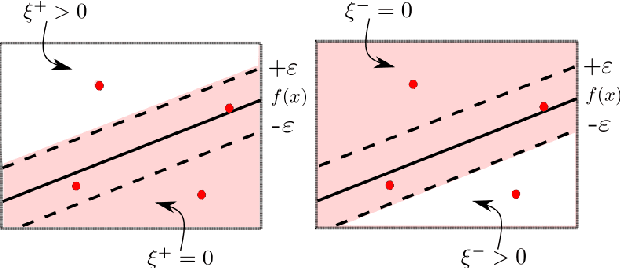

The classical machine-learning model for support vector regression (SVR) is widely used for regression tasks, including weather prediction, stock-market and real-estate pricing. However, a practically realisable quantum version for SVR remains to be formulated. We devise annealing-based algorithms, namely simulated and quantum-classical hybrid, for training two SVR models, and compare their empirical performances against the SVR implementation of Python's scikit-learn package and the SVR-based state-of-the-art algorithm for the facial landmark detection (FLD) problem. Our method is to derive a quadratic-unconstrained-binary formulation for the optimisation problem used for training a SVR model and solve this problem using annealing. Using D-Wave's Hybrid Solver, we construct a quantum-assisted SVR model, thereby demonstrating a slight advantage over classical models regarding landmark-detection accuracy. Furthermore, we observe that annealing-based SVR models predict landmarks with lower variances compared to the SVR models trained by greedy optimisation procedures. Our work is a proof-of-concept example for applying quantu-assisted SVR to a supervised learning task with a small training dataset.
AuE-IPA: An AU Engagement Based Infant Pain Assessment Method
Dec 09, 2022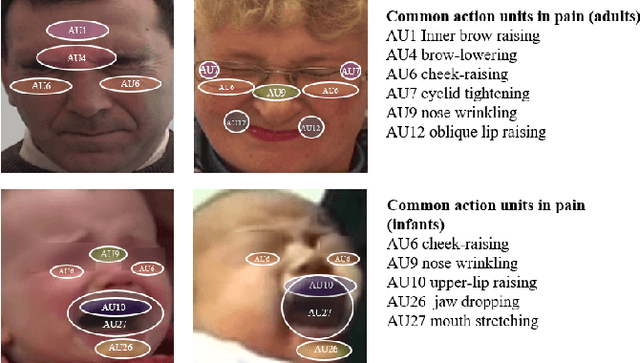
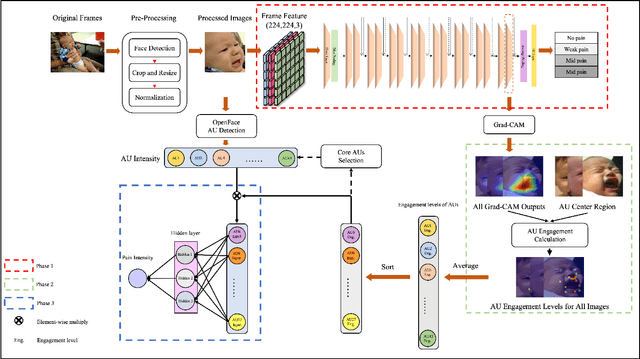
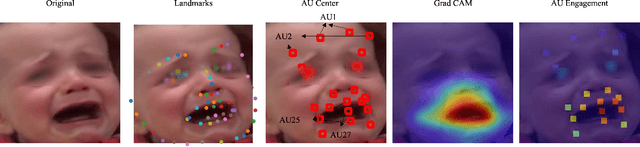
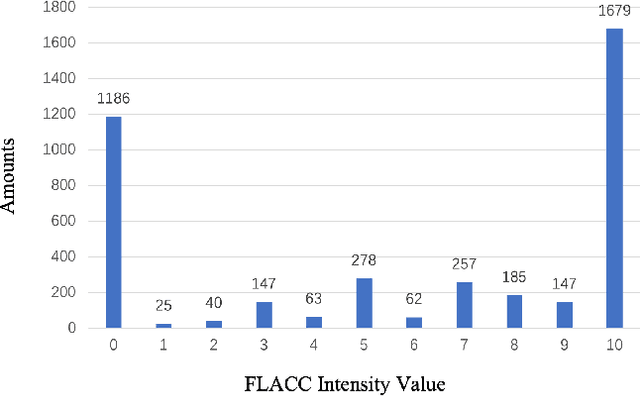
Recent studies have found that pain in infancy has a significant impact on infant development, including psychological problems, possible brain injury, and pain sensitivity in adulthood. However, due to the lack of specialists and the fact that infants are unable to express verbally their experience of pain, it is difficult to assess infant pain. Most existing infant pain assessment systems directly apply adult methods to infants ignoring the differences between infant expressions and adult expressions. Meanwhile, as the study of facial action coding system continues to advance, the use of action units (AUs) opens up new possibilities for expression recognition and pain assessment. In this paper, a novel AuE-IPA method is proposed for assessing infant pain by leveraging different engagement levels of AUs. First, different engagement levels of AUs in infant pain are revealed, by analyzing the class activation map of an end-to-end pain assessment model. The intensities of top-engaged AUs are then used in a regression model for achieving automatic infant pain assessment. The model proposed is trained and experimented on YouTube Immunization dataset, YouTube Blood Test dataset, and iCOPEVid dataset. The experimental results show that our AuE-IPA method is more applicable to infants and possesses stronger generalization ability than end-to-end assessment model and the classic PSPI metric.
MAFER: a Multi-resolution Approach to Facial Expression Recognition
May 06, 2021


Emotions play a central role in the social life of every human being, and their study, which represents a multidisciplinary subject, embraces a great variety of research fields. Especially concerning the latter, the analysis of facial expressions represents a very active research area due to its relevance to human-computer interaction applications. In such a context, Facial Expression Recognition (FER) is the task of recognizing expressions on human faces. Typically, face images are acquired by cameras that have, by nature, different characteristics, such as the output resolution. It has been already shown in the literature that Deep Learning models applied to face recognition experience a degradation in their performance when tested against multi-resolution scenarios. Since the FER task involves analyzing face images that can be acquired with heterogeneous sources, thus involving images with different quality, it is plausible to expect that resolution plays an important role in such a case too. Stemming from such a hypothesis, we prove the benefits of multi-resolution training for models tasked with recognizing facial expressions. Hence, we propose a two-step learning procedure, named MAFER, to train DCNNs to empower them to generate robust predictions across a wide range of resolutions. A relevant feature of MAFER is that it is task-agnostic, i.e., it can be used complementarily to other objective-related techniques. To assess the effectiveness of the proposed approach, we performed an extensive experimental campaign on publicly available datasets: \fer{}, \raf{}, and \oulu{}. For a multi-resolution context, we observe that with our approach, learning models improve upon the current SotA while reporting comparable results in fix-resolution contexts. Finally, we analyze the performance of our models and observe the higher discrimination power of deep features generated from them.
Consistency and Accuracy of CelebA Attribute Values
Oct 13, 2022
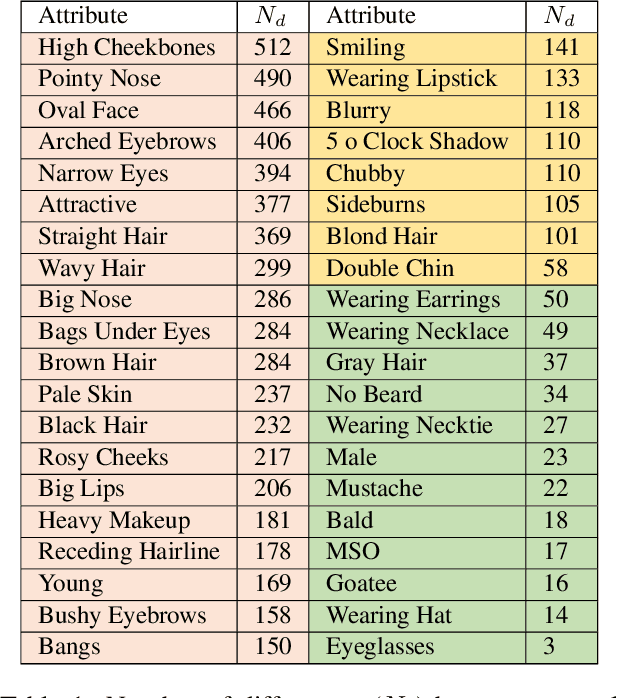

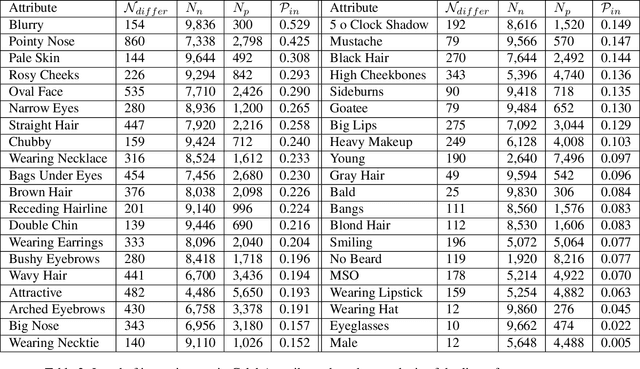
We report the first analysis of the experimental foundations of facial attribute classification. An experiment with two annotators independently assigning values shows that only 12 of 40 commonly-used attributes are assigned values with >= 95% consistency, and that three (high cheekbones, pointed nose, oval face) have random consistency (50%). These results show that the binary face attributes currently used in this research area could re-focused to be more objective. We identify 5,068 duplicate face appearances in CelebA, the most widely used dataset in this research area, and find that individual attributes have contradicting values on from 10 to 860 of 5,068 duplicates. Manual audit of a subset of CelebA estimates error rates as high as 40% for (no beard=false), even though the labeling consistency experiment indicates that no beard could be assigned with >= 95% consistency. Selecting the mouth slightly open (MSO) attribute for deeper analysis, we estimate the error rate for (MSO=true) at about 20% and for (MSO=false) at about 2%. We create a corrected version of the MSO attribute values, and compare classification models created using the original versus corrected values. The corrected values enable a model that achieves higher accuracy than has been previously reported for MSO. Also, ScoreCAM visualizations show that the model created using the corrected attribute values is in fact more focused on the mouth region of the face. These results show that the error rate in the current CelebA attribute values should be reduced in order to enable learning of better models. The corrected attribute values for CelebA's MSO and the CelebA facial hair attributes will be made available upon publication.
ClipFace: Text-guided Editing of Textured 3D Morphable Models
Dec 02, 2022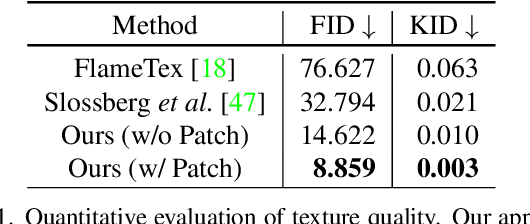
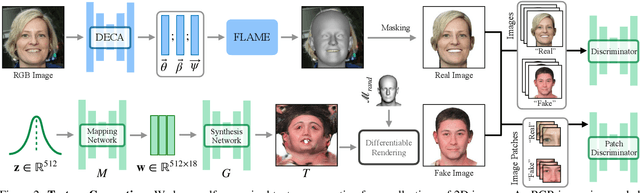
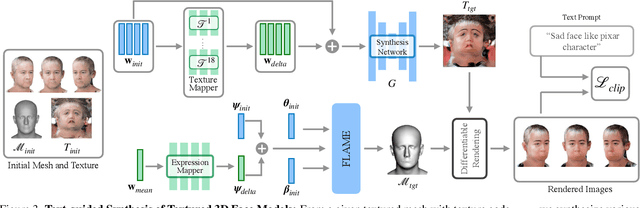
We propose ClipFace, a novel self-supervised approach for text-guided editing of textured 3D morphable model of faces. Specifically, we employ user-friendly language prompts to enable control of the expressions as well as appearance of 3D faces. We leverage the geometric expressiveness of 3D morphable models, which inherently possess limited controllability and texture expressivity, and develop a self-supervised generative model to jointly synthesize expressive, textured, and articulated faces in 3D. We enable high-quality texture generation for 3D faces by adversarial self-supervised training, guided by differentiable rendering against collections of real RGB images. Controllable editing and manipulation are given by language prompts to adapt texture and expression of the 3D morphable model. To this end, we propose a neural network that predicts both texture and expression latent codes of the morphable model. Our model is trained in a self-supervised fashion by exploiting differentiable rendering and losses based on a pre-trained CLIP model. Once trained, our model jointly predicts face textures in UV-space, along with expression parameters to capture both geometry and texture changes in facial expressions in a single forward pass. We further show the applicability of our method to generate temporally changing textures for a given animation sequence.
Improving Zero-Shot Models with Label Distribution Priors
Dec 01, 2022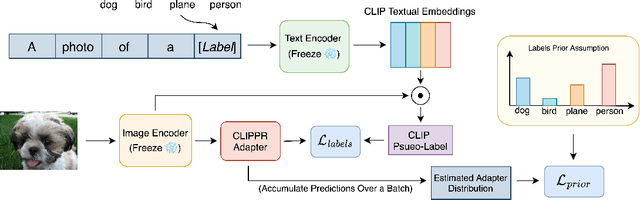

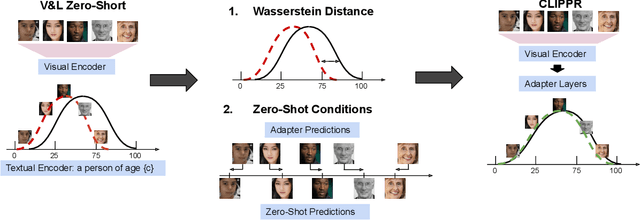

Labeling large image datasets with attributes such as facial age or object type is tedious and sometimes infeasible. Supervised machine learning methods provide a highly accurate solution, but require manual labels which are often unavailable. Zero-shot models (e.g., CLIP) do not require manual labels but are not as accurate as supervised ones, particularly when the attribute is numeric. We propose a new approach, CLIPPR (CLIP with Priors), which adapts zero-shot models for regression and classification on unlabelled datasets. Our method does not use any annotated images. Instead, we assume a prior over the label distribution in the dataset. We then train an adapter network on top of CLIP under two competing objectives: i) minimal change of predictions from the original CLIP model ii) minimal distance between predicted and prior distribution of labels. Additionally, we present a novel approach for selecting prompts for Vision & Language models using a distributional prior. Our method is effective and presents a significant improvement over the original model. We demonstrate an improvement of 28% in mean absolute error on the UTK age regression task. We also present promising results for classification benchmarks, improving the classification accuracy on the ImageNet dataset by 2.83%, without using any labels.
Privacy Attacks Against Biometric Models with Fewer Samples: Incorporating the Output of Multiple Models
Sep 22, 2022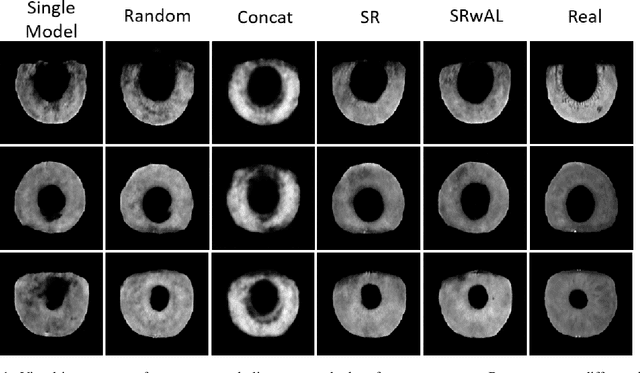
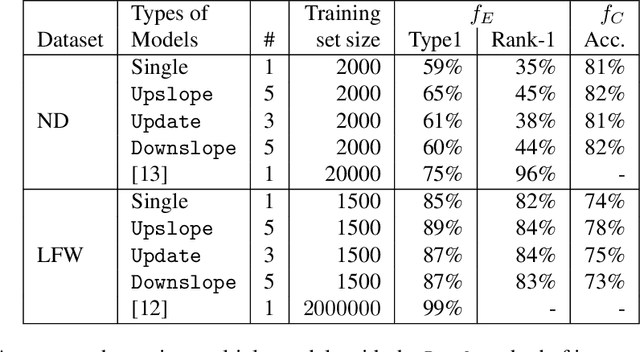
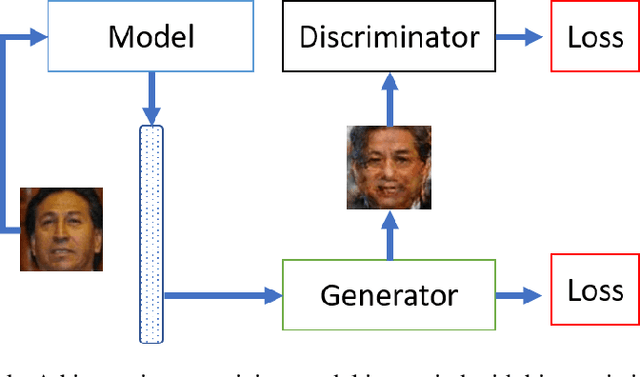
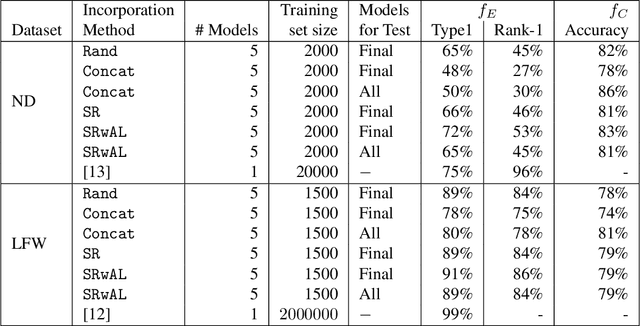
Authentication systems are vulnerable to model inversion attacks where an adversary is able to approximate the inverse of a target machine learning model. Biometric models are a prime candidate for this type of attack. This is because inverting a biometric model allows the attacker to produce a realistic biometric input to spoof biometric authentication systems. One of the main constraints in conducting a successful model inversion attack is the amount of training data required. In this work, we focus on iris and facial biometric systems and propose a new technique that drastically reduces the amount of training data necessary. By leveraging the output of multiple models, we are able to conduct model inversion attacks with 1/10th the training set size of Ahmad and Fuller (IJCB 2020) for iris data and 1/1000th the training set size of Mai et al. (Pattern Analysis and Machine Intelligence 2019) for facial data. We denote our new attack technique as structured random with alignment loss. Our attacks are black-box, requiring no knowledge of the weights of the target neural network, only the dimension, and values of the output vector. To show the versatility of the alignment loss, we apply our attack framework to the task of membership inference (Shokri et al., IEEE S&P 2017) on biometric data. For the iris, membership inference attack against classification networks improves from 52% to 62% accuracy.
Unsupervised inference approach to facial attractiveness
Oct 30, 2019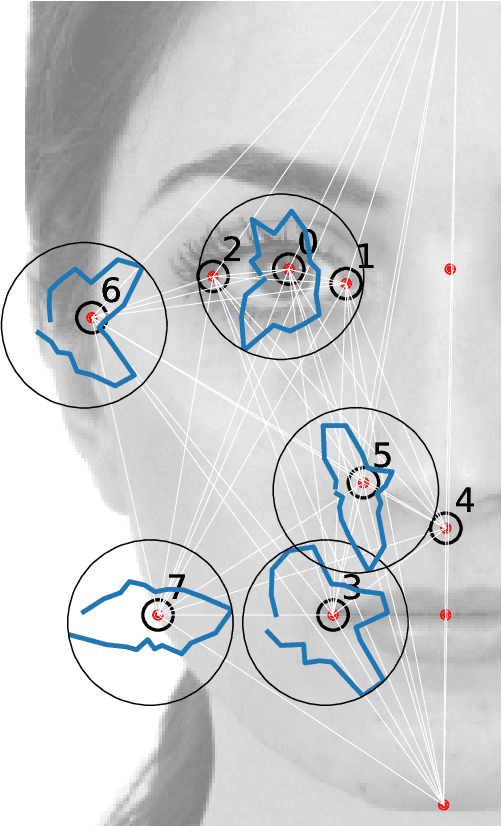
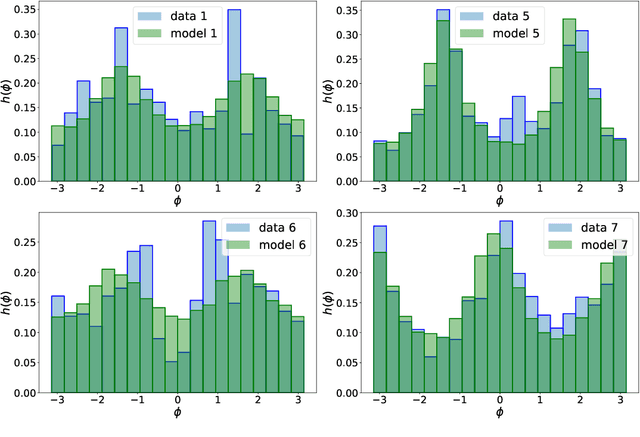
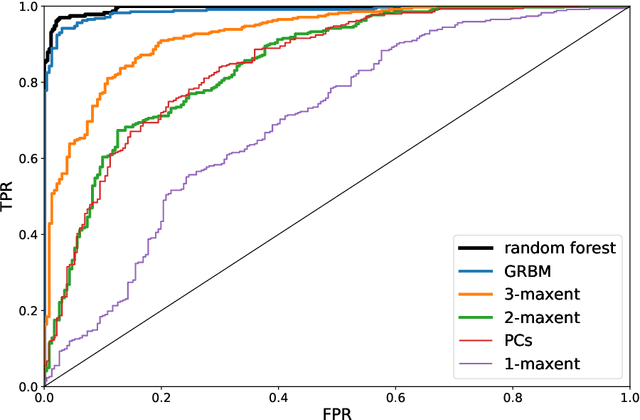
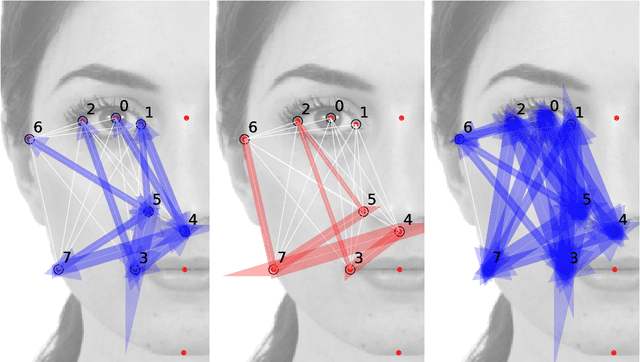
The perception of facial beauty is a complex phenomenon depending on many, detailed and global facial features influencing each other. In the machine learning community this problem is typically tackled as a problem of supervised inference. However, it has been conjectured that this approach does not capture the complexity of the phenomenon. A recent original experiment (Ib\'a\~nez-Berganza et al., Scientific Reports 9, 8364, 2019) allowed different human subjects to navigate the face-space and "sculpt" their preferred modification of a reference facial portrait. Here we present an unsupervised inference study of the set of sculpted facial vectors in that experiment. We first infer minimal, interpretable, and faithful probabilistic models (through Maximum Entropy and artificial neural networks) of the preferred facial variations, that capture the origin of the observed inter-subject diversity in the sculpted faces. The application of such generative models to the supervised classification of the gender of the sculpting subjects, reveals an astonishingly high prediction accuracy. This result suggests that much relevant information regarding the subjects may influence (and be elicited from) her/his facial preference criteria, in agreement with the multiple motive theory of attractiveness proposed in previous works.
CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution
Apr 19, 2022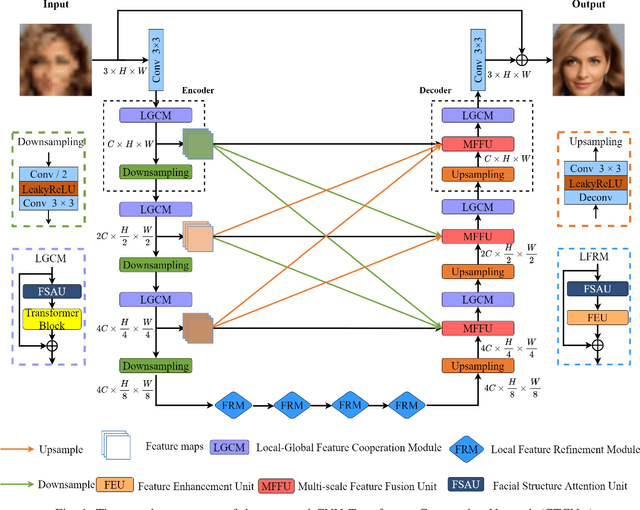

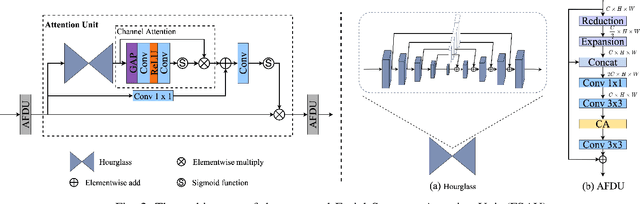
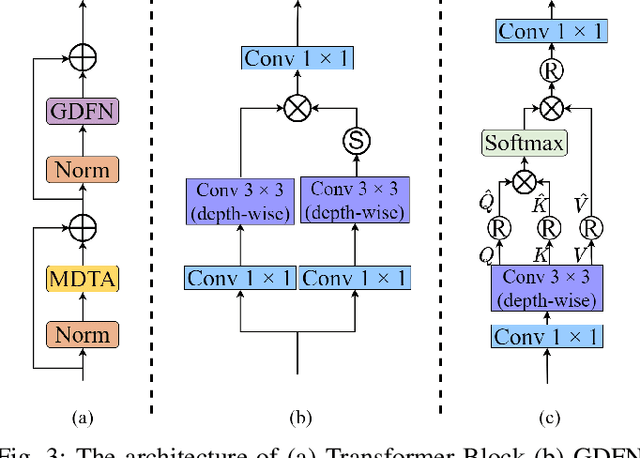
Recently, deep convolution neural networks (CNNs) steered face super-resolution methods have achieved great progress in restoring degraded facial details by jointly training with facial priors. However, these methods have some obvious limitations. On the one hand, multi-task joint learning requires additional marking on the dataset, and the introduced prior network will significantly increase the computational cost of the model. On the other hand, the limited receptive field of CNN will reduce the fidelity and naturalness of the reconstructed facial images, resulting in suboptimal reconstructed images. In this work, we propose an efficient CNN-Transformer Cooperation Network (CTCNet) for face super-resolution tasks, which uses the multi-scale connected encoder-decoder architecture as the backbone. Specifically, we first devise a novel Local-Global Feature Cooperation Module (LGCM), which is composed of a Facial Structure Attention Unit (FSAU) and a Transformer block, to promote the consistency of local facial detail and global facial structure restoration simultaneously. Then, we design an efficient Local Feature Refinement Module (LFRM) to enhance the local facial structure information. Finally, to further improve the restoration of fine facial details, we present a Multi-scale Feature Fusion Unit (MFFU) to adaptively fuse the features from different stages in the encoder procedure. Comprehensive evaluations on various datasets have assessed that the proposed CTCNet can outperform other state-of-the-art methods significantly.
The Blessing and the Curse of the Noise behind Facial Landmark Annotations
Jul 30, 2020

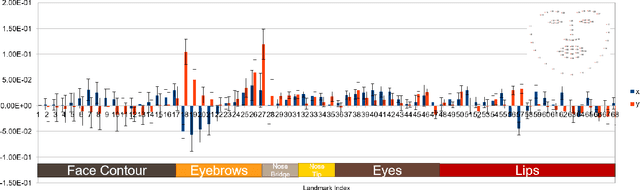
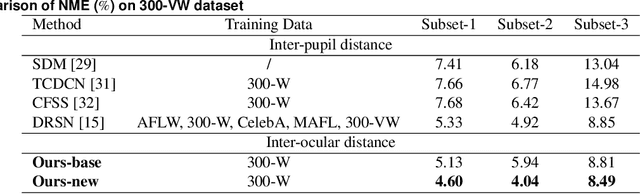
The evolving algorithms for 2D facial landmark detection empower people to recognize faces, analyze facial expressions, etc. However, existing methods still encounter problems of unstable facial landmarks when applied to videos. Because previous research shows that the instability of facial landmarks is caused by the inconsistency of labeling quality among the public datasets, we want to have a better understanding of the influence of annotation noise in them. In this paper, we make the following contributions: 1) we propose two metrics that quantitatively measure the stability of detected facial landmarks, 2) we model the annotation noise in an existing public dataset, 3) we investigate the influence of different types of noise in training face alignment neural networks, and propose corresponding solutions. Our results demonstrate improvements in both accuracy and stability of detected facial landmarks.