 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
LoRRaL: Facial Action Unit Detection Based on Local Region Relation Learning
Sep 23, 2020
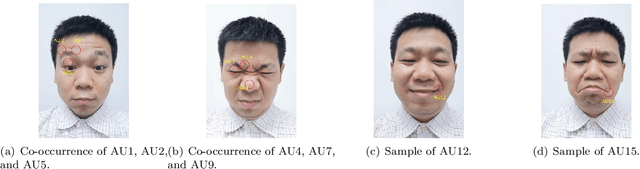
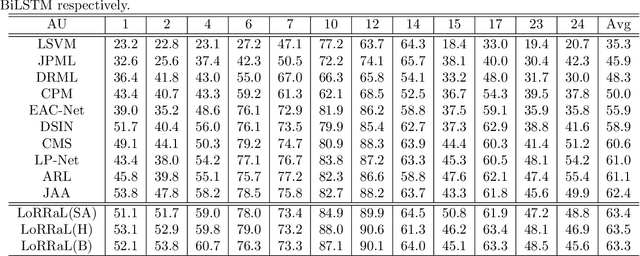
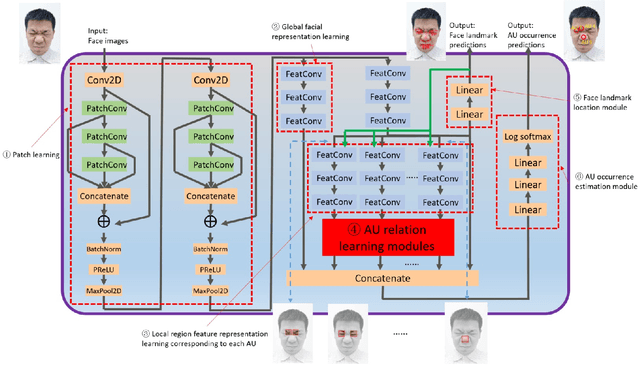
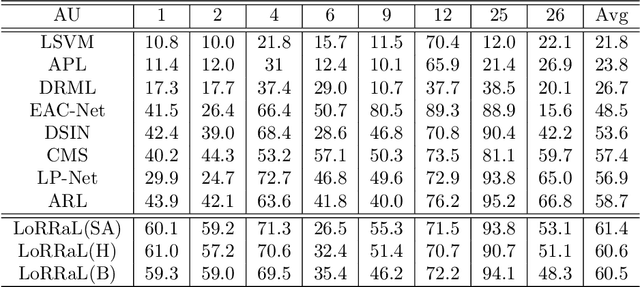
End-to-end convolution representation learning has been proved to be very effective in facial action unit (AU) detection. Considering the co-occurrence and mutual exclusion between facial AUs, in this paper, we propose convolution neural networks with Local Region Relation Learning (LoRRaL), which can combine latent relationships among AUs for an end-to-end approach to facial AU occurrence detection. LoRRaL consists of 1) use bi-directional long short-term memory (BiLSTM) to dynamically and sequentially encode local AU feature maps, 2) use self-attention mechanism to dynamically compute correspondences from local facial regions and to re-aggregate AU feature maps considering AU co-occurrences and mutual exclusions, 3) use a continuous-state modern Hopfield network to encode and map local facial features to more discriminative AU feature maps, that all these networks take the facial image as input and map it to AU occurrences. Our experiments on the challenging BP4D and DISFA Benchmarks without any external data or pre-trained models results in F1-scores of 63.5% and 61.4% respectively, which shows our proposed networks can lead to performance improvement on the AU detection task.
FaceQAN: Face Image Quality Assessment Through Adversarial Noise Exploration
Dec 05, 2022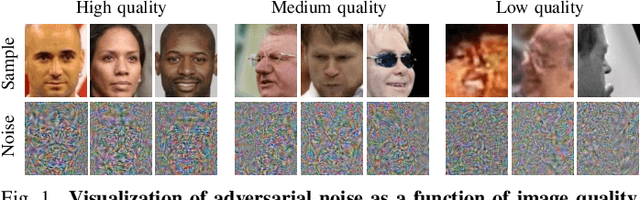
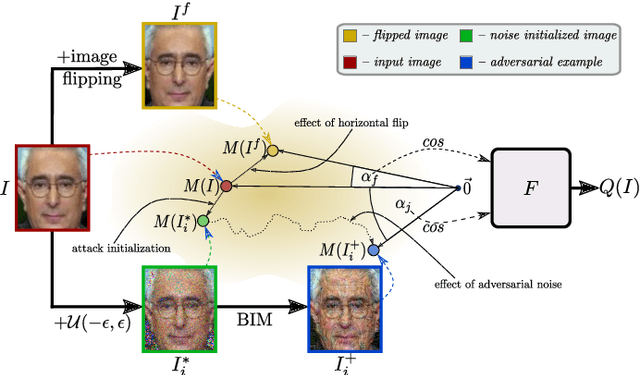
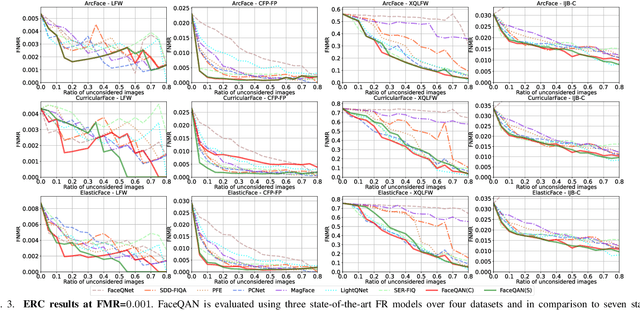

Recent state-of-the-art face recognition (FR) approaches have achieved impressive performance, yet unconstrained face recognition still represents an open problem. Face image quality assessment (FIQA) approaches aim to estimate the quality of the input samples that can help provide information on the confidence of the recognition decision and eventually lead to improved results in challenging scenarios. While much progress has been made in face image quality assessment in recent years, computing reliable quality scores for diverse facial images and FR models remains challenging. In this paper, we propose a novel approach to face image quality assessment, called FaceQAN, that is based on adversarial examples and relies on the analysis of adversarial noise which can be calculated with any FR model learned by using some form of gradient descent. As such, the proposed approach is the first to link image quality to adversarial attacks. Comprehensive (cross-model as well as model-specific) experiments are conducted with four benchmark datasets, i.e., LFW, CFP-FP, XQLFW and IJB-C, four FR models, i.e., CosFace, ArcFace, CurricularFace and ElasticFace, and in comparison to seven state-of-the-art FIQA methods to demonstrate the performance of FaceQAN. Experimental results show that FaceQAN achieves competitive results, while exhibiting several desirable characteristics.
Facial Expression Editing with Continuous Emotion Labels
Jun 22, 2020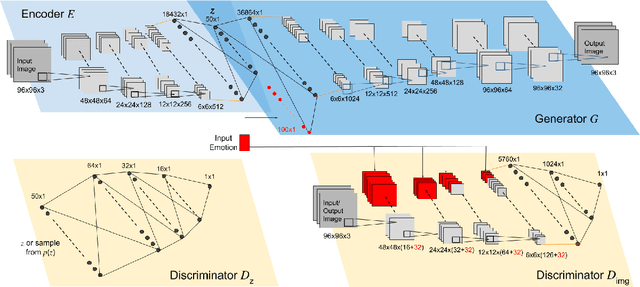



Recently deep generative models have achieved impressive results in the field of automated facial expression editing. However, the approaches presented so far presume a discrete representation of human emotions and are therefore limited in the modelling of non-discrete emotional expressions. To overcome this limitation, we explore how continuous emotion representations can be used to control automated expression editing. We propose a deep generative model that can be used to manipulate facial expressions in facial images according to continuous two-dimensional emotion labels. One dimension represents an emotion's valence, the other represents its degree of arousal. We demonstrate the functionality of our model with a quantitative analysis using classifier networks as well as with a qualitative analysis.
Local Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022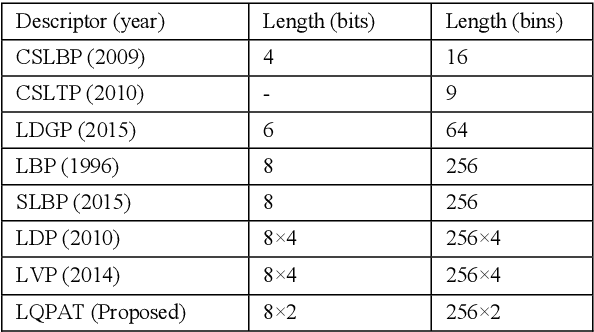
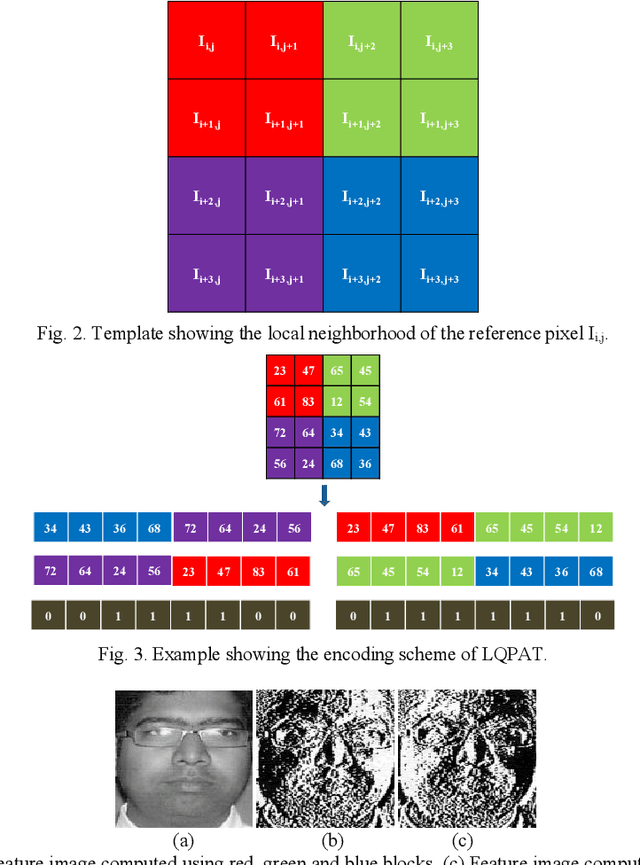
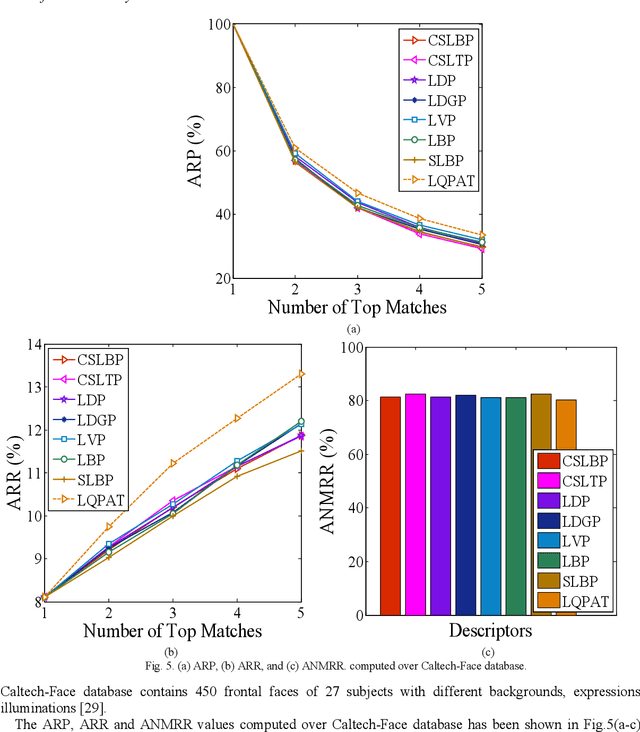
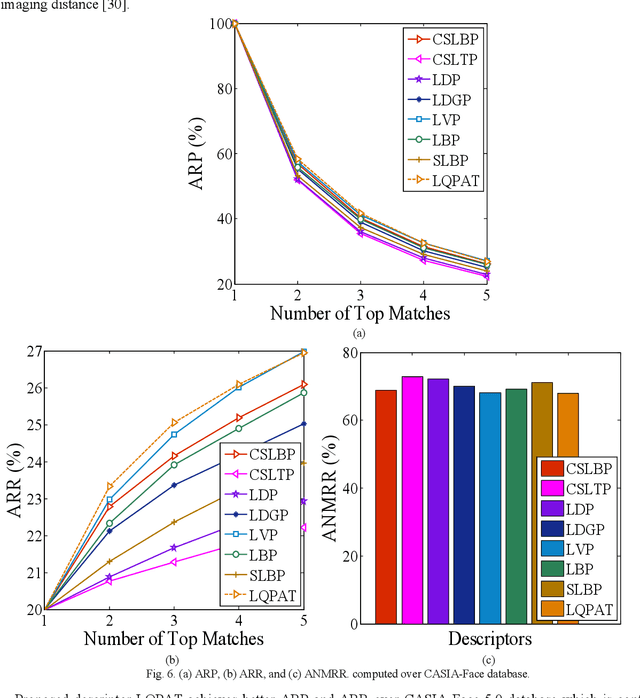
In this paper a novel hand crafted local quadruple pattern (LQPAT) is proposed for facial image recognition and retrieval. Most of the existing hand-crafted descriptors encodes only a limited number of pixels in the local neighbourhood. Under unconstrained environment the performance of these descriptors tends to degrade drastically. The major problem in increasing the local neighbourhood is that, it also increases the feature length of the descriptor. The proposed descriptor try to overcome these problems by defining an efficient encoding structure with optimal feature length. The proposed descriptor encodes relations amongst the neighbours in quadruple space. Two micro patterns are computed from the local relationships to form the descriptor. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand crafted descriptors on bench mark databases namely; Caltech-face, LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under uncontrolled variations in pose, illumination, background and expressions.
* arXiv admin note: substantial text overlap with arXiv:2201.00504, arXiv:2201.00511
Realtime Fewshot Portrait Stylization Based On Geometric Alignment
Nov 28, 2022
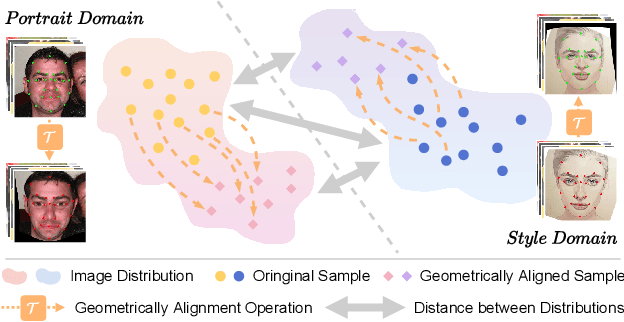
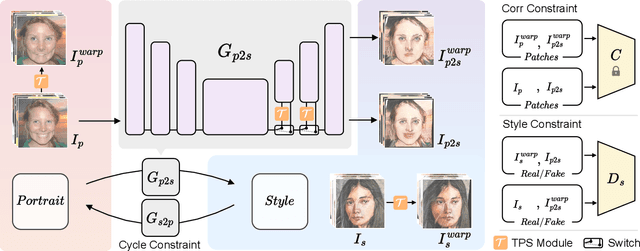
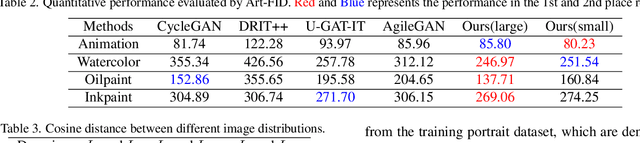
This paper presents a portrait stylization method designed for real-time mobile applications with limited style examples available. Previous learning based stylization methods suffer from the geometric and semantic gaps between portrait domain and style domain, which obstacles the style information to be correctly transferred to the portrait images, leading to poor stylization quality. Based on the geometric prior of human facial attributions, we propose to utilize geometric alignment to tackle this issue. Firstly, we apply Thin-Plate-Spline (TPS) on feature maps in the generator network and also directly to style images in pixel space, generating aligned portrait-style image pairs with identical landmarks, which closes the geometric gaps between two domains. Secondly, adversarial learning maps the textures and colors of portrait images to the style domain. Finally, geometric aware cycle consistency preserves the content and identity information unchanged, and deformation invariant constraint suppresses artifacts and distortions. Qualitative and quantitative comparison validate our method outperforms existing methods, and experiments proof our method could be trained with limited style examples (100 or less) in real-time (more than 40 FPS) on mobile devices. Ablation study demonstrates the effectiveness of each component in the framework.
Micro-Facial Expression Recognition Based on Deep-Rooted Learning Algorithm
Sep 12, 2020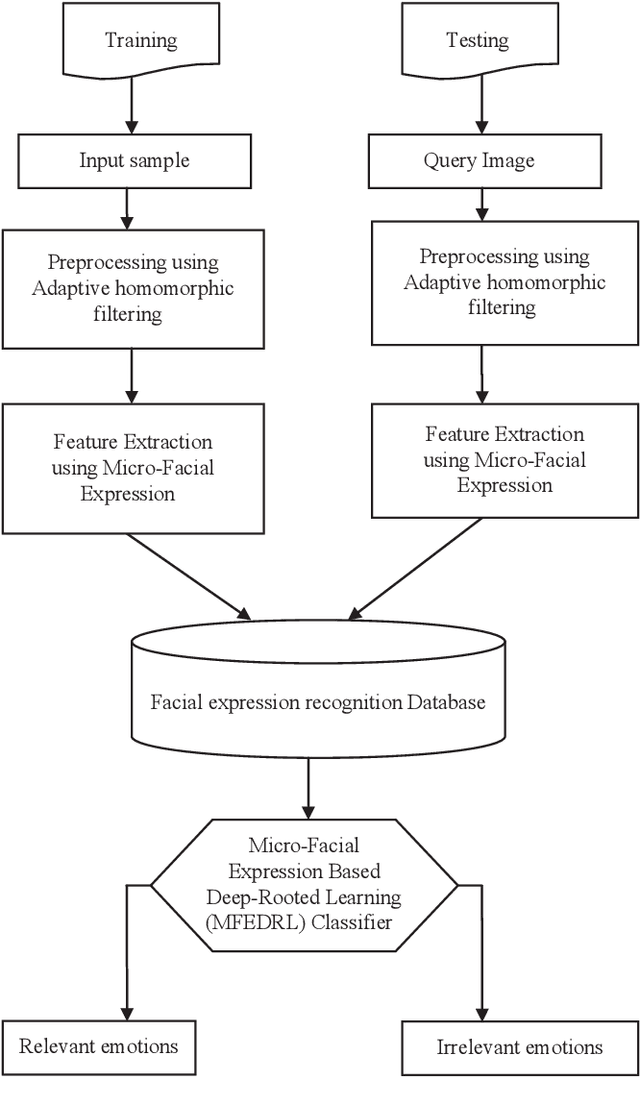


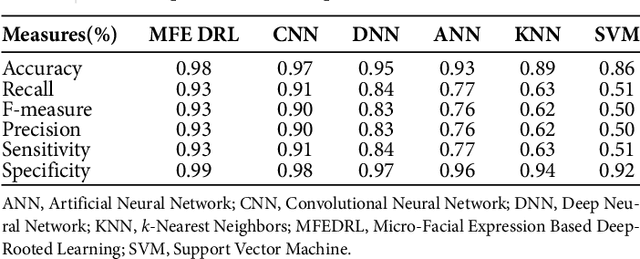
Facial expressions are important cues to observe human emotions. Facial expression recognition has attracted many researchers for years, but it is still a challenging topic since expression features vary greatly with the head poses, environments, and variations in the different persons involved. In this work, three major steps are involved to improve the performance of micro-facial expression recognition. First, an Adaptive Homomorphic Filtering is used for face detection and rotation rectification processes. Secondly, Micro-facial features were used to extract the appearance variations of a testing image-spatial analysis. The features of motion information are used for expression recognition in a sequence of facial images. An effective Micro-Facial Expression Based Deep-Rooted Learning (MFEDRL) classifier is proposed in this paper to better recognize spontaneous micro-expressions by learning parameters on the optimal features. This proposed method includes two loss functions such as cross entropy loss function and centre loss function. Then the performance of the algorithm will be evaluated using recognition rate and false measures. Simulation results show that the predictive performance of the proposed method outperforms that of the existing classifiers such as Convolutional Neural Network (CNN), Deep Neural Network (DNN), Artificial Neural Network (ANN), Support Vector Machine (SVM), and k-Nearest Neighbours (KNN) in terms of accuracy and Mean Absolute Error (MAE).
* 20 pages, 7 figures, "for the published version of the article, see https://www.atlantis-press.com/journals/ijcis/125915627"
Robust Face-Swap Detection Based on 3D Facial Shape Information
Apr 28, 2021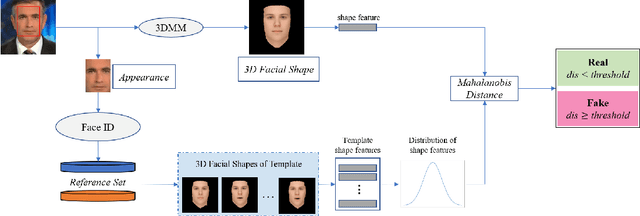

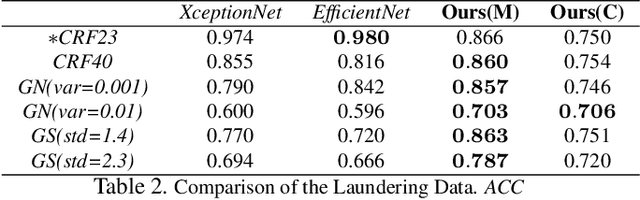
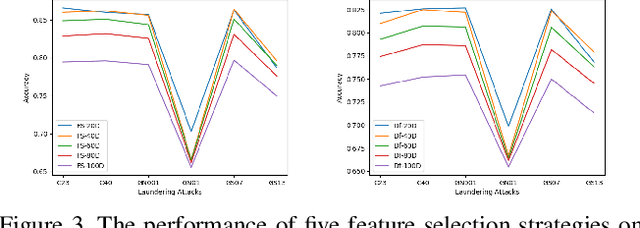
Maliciously-manipulated images or videos - so-called deep fakes - especially face-swap images and videos have attracted more and more malicious attackers to discredit some key figures. Previous pixel-level artifacts based detection techniques always focus on some unclear patterns but ignore some available semantic clues. Therefore, these approaches show weak interpretability and robustness. In this paper, we propose a biometric information based method to fully exploit the appearance and shape feature for face-swap detection of key figures. The key aspect of our method is obtaining the inconsistency of 3D facial shape and facial appearance, and the inconsistency based clue offers natural interpretability for the proposed face-swap detection method. Experimental results show the superiority of our method in robustness on various laundering and cross-domain data, which validates the effectiveness of the proposed method.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
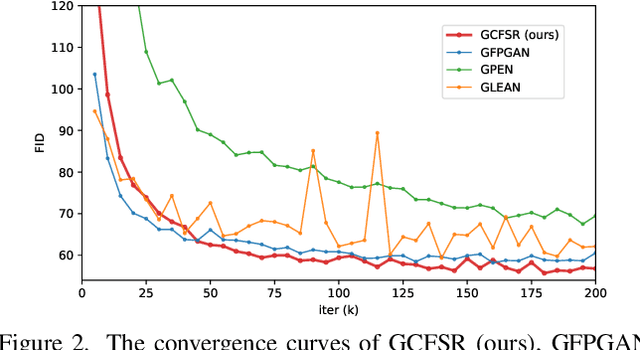

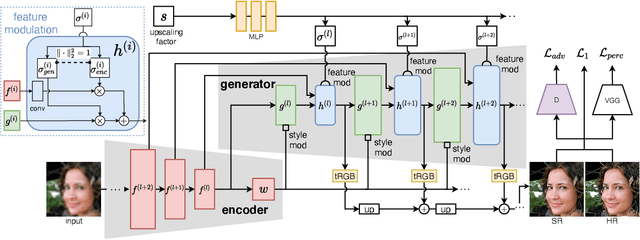
Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.
Learning Dual Memory Dictionaries for Blind Face Restoration
Oct 15, 2022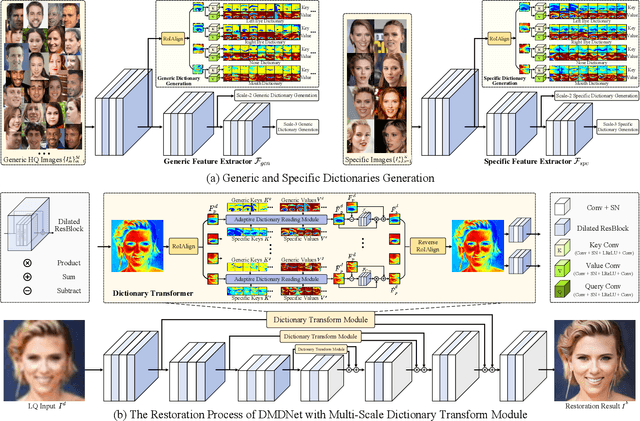
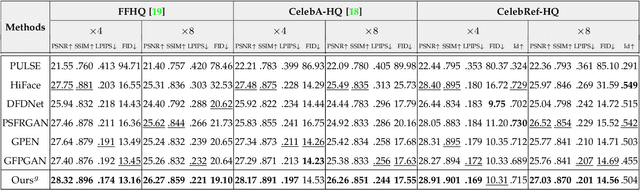
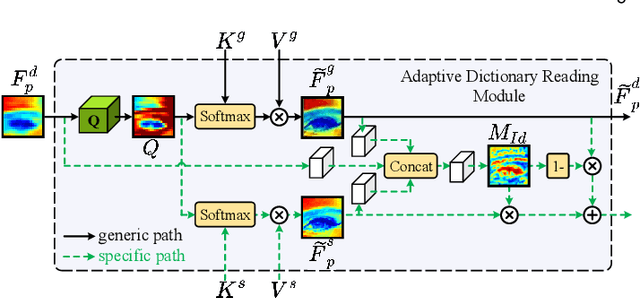
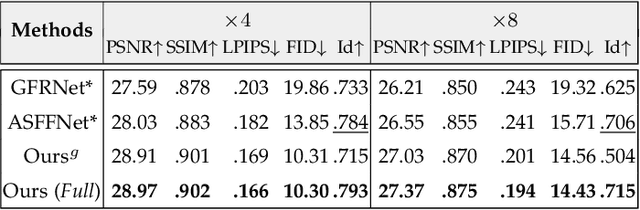
To improve the performance of blind face restoration, recent works mainly treat the two aspects, i.e., generic and specific restoration, separately. In particular, generic restoration attempts to restore the results through general facial structure prior, while on the one hand, cannot generalize to real-world degraded observations due to the limited capability of direct CNNs' mappings in learning blind restoration, and on the other hand, fails to exploit the identity-specific details. On the contrary, specific restoration aims to incorporate the identity features from the reference of the same identity, in which the requirement of proper reference severely limits the application scenarios. Generally, it is a challenging and intractable task to improve the photo-realistic performance of blind restoration and adaptively handle the generic and specific restoration scenarios with a single unified model. Instead of implicitly learning the mapping from a low-quality image to its high-quality counterpart, this paper suggests a DMDNet by explicitly memorizing the generic and specific features through dual dictionaries. First, the generic dictionary learns the general facial priors from high-quality images of any identity, while the specific dictionary stores the identity-belonging features for each person individually. Second, to handle the degraded input with or without specific reference, dictionary transform module is suggested to read the relevant details from the dual dictionaries which are subsequently fused into the input features. Finally, multi-scale dictionaries are leveraged to benefit the coarse-to-fine restoration. Moreover, a new high-quality dataset, termed CelebRef-HQ, is constructed to promote the exploration of specific face restoration in the high-resolution space.
A Novel Fully Annotated Thermal Infrared Face Dataset: Recorded in Various Environment Conditions and Distances From The Camera
Apr 29, 2022
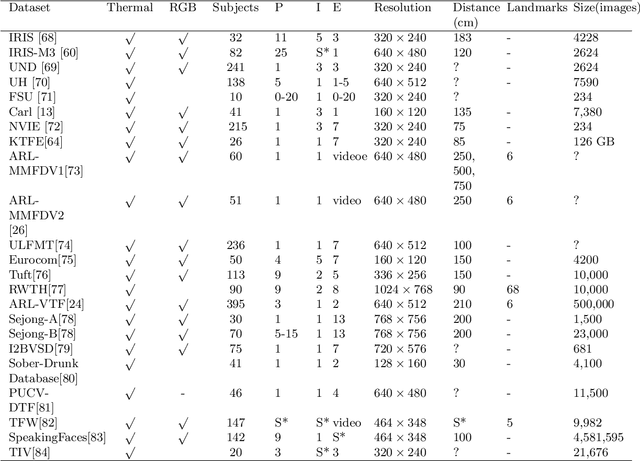
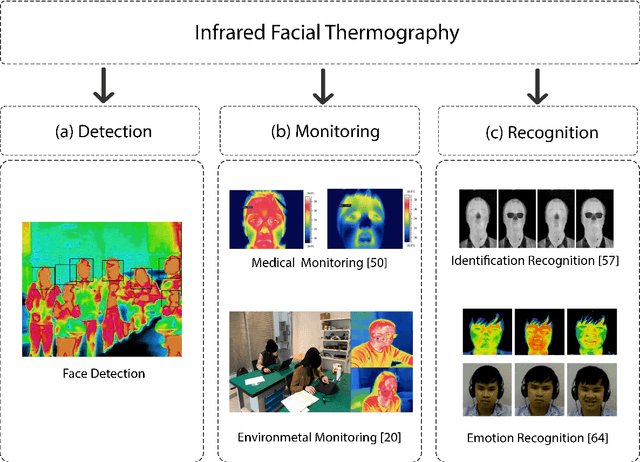
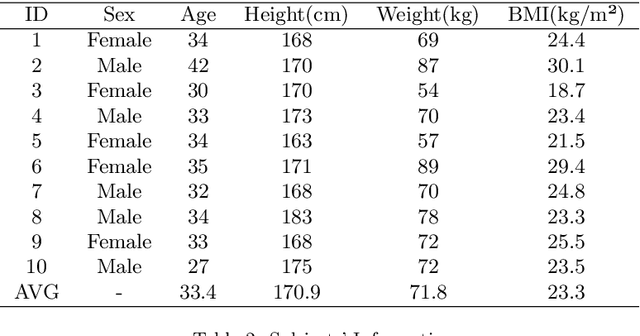
Facial thermography is one of the most popular research areas in infrared thermal imaging, with diverse applications in medical, surveillance, and environmental monitoring. However, in contrast to facial imagery in the visual spectrum, the lack of public datasets on facial thermal images is an obstacle to research improvement in this area. Thermal face imagery is still a relatively new research area to be evaluated and studied in different domains.The current thermal face datasets are limited in regards to the subjects' distance from the camera, the ambient temperature variation, and facial landmarks' localization. We address these gaps by presenting a new facial thermography dataset. This article makes two main contributions to the body of knowledge. First, it presents a comprehensive review and comparison of current public datasets in facial thermography. Second, it introduces and studies a novel public dataset on facial thermography, which we call it Charlotte-ThermalFace. Charlotte-ThermalFace contains more than10000 infrared thermal images in varying thermal conditions, several distances from the camera, and different head positions. The data is fully annotated with the facial landmarks, ambient temperature, relative humidity, the air speed of the room, distance to the camera, and subject thermal sensation at the time of capturing each image. Our dataset is the first publicly available thermal dataset annotated with the thermal sensation of each subject in different thermal conditions and one of the few datasets in raw 16-bit format. Finally, we present a preliminary analysis of the dataset to show the applicability and importance of the thermal conditions in facial thermography. The full dataset, including annotations, are freely available for research purpose at https://github.com/TeCSAR-UNCC/UNCC-ThermalFace