 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Spatio-Temporal Analysis of Facial Actions using Lifecycle-Aware Capsule Networks
Nov 17, 2020
Most state-of-the-art approaches for Facial Action Unit (AU) detection rely upon evaluating facial expressions from static frames, encoding a snapshot of heightened facial activity. In real-world interactions, however, facial expressions are usually more subtle and evolve in a temporal manner requiring AU detection models to learn spatial as well as temporal information. In this paper, we focus on both spatial and spatio-temporal features encoding the temporal evolution of facial AU activation. For this purpose, we propose the Action Unit Lifecycle-Aware Capsule Network (AULA-Caps) that performs AU detection using both frame and sequence-level features. While at the frame-level the capsule layers of AULA-Caps learn spatial feature primitives to determine AU activations, at the sequence-level, it learns temporal dependencies between contiguous frames by focusing on relevant spatio-temporal segments in the sequence. The learnt feature capsules are routed together such that the model learns to selectively focus more on spatial or spatio-temporal information depending upon the AU lifecycle. The proposed model is evaluated on the commonly used BP4D and GFT benchmark datasets obtaining state-of-the-art results on both the datasets.
Local Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022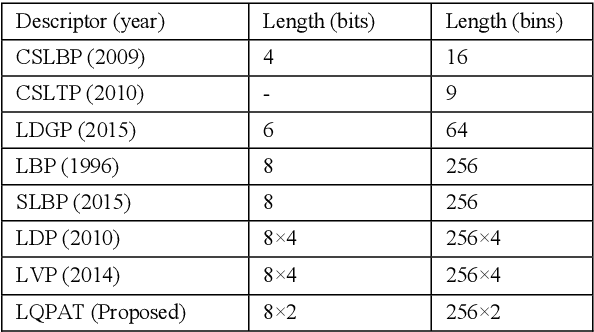
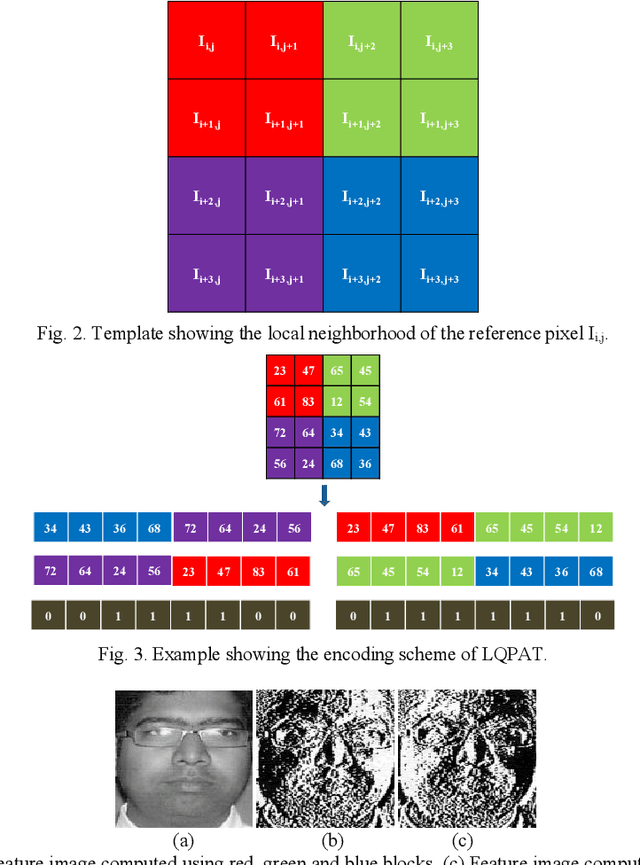
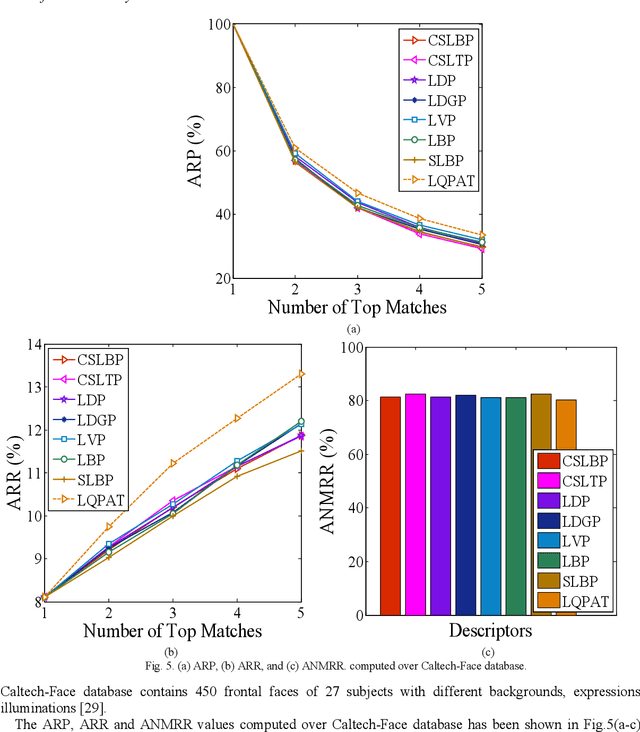
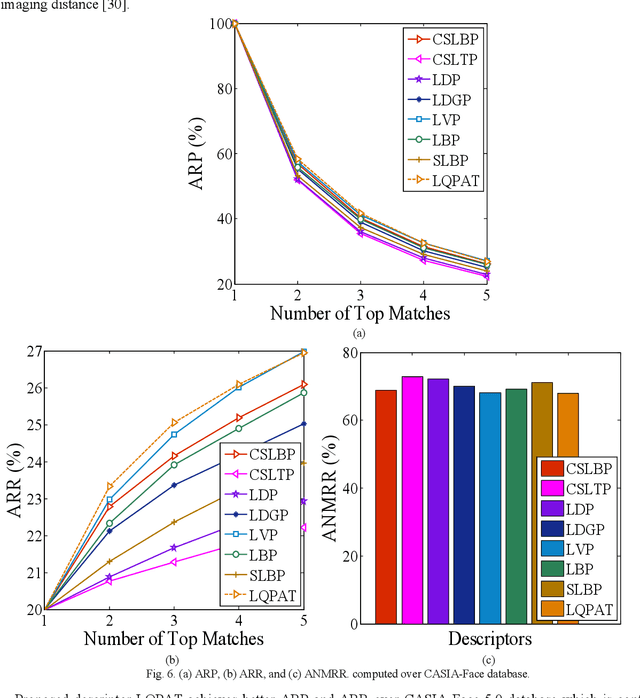
In this paper a novel hand crafted local quadruple pattern (LQPAT) is proposed for facial image recognition and retrieval. Most of the existing hand-crafted descriptors encodes only a limited number of pixels in the local neighbourhood. Under unconstrained environment the performance of these descriptors tends to degrade drastically. The major problem in increasing the local neighbourhood is that, it also increases the feature length of the descriptor. The proposed descriptor try to overcome these problems by defining an efficient encoding structure with optimal feature length. The proposed descriptor encodes relations amongst the neighbours in quadruple space. Two micro patterns are computed from the local relationships to form the descriptor. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand crafted descriptors on bench mark databases namely; Caltech-face, LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under uncontrolled variations in pose, illumination, background and expressions.
* arXiv admin note: substantial text overlap with arXiv:2201.00504, arXiv:2201.00511
Responsible Facial Recognition and Beyond
Sep 19, 2019Facial recognition is changing the way we live in and interact with our society. Here we discuss the two sides of facial recognition, summarizing potential risks and current concerns. We introduce current policies and regulations in different countries. Very importantly, we point out that the risks and concerns are not only from facial recognition, but also realistically very similar to other biometric recognition technology, including but not limited to gait recognition, iris recognition, fingerprint recognition, voice recognition, etc. To create a responsible future, we discuss possible technological moves and efforts that should be made to keep facial recognition (and biometric recognition in general) developing for social good.
A Novel Fully Annotated Thermal Infrared Face Dataset: Recorded in Various Environment Conditions and Distances From The Camera
Apr 29, 2022
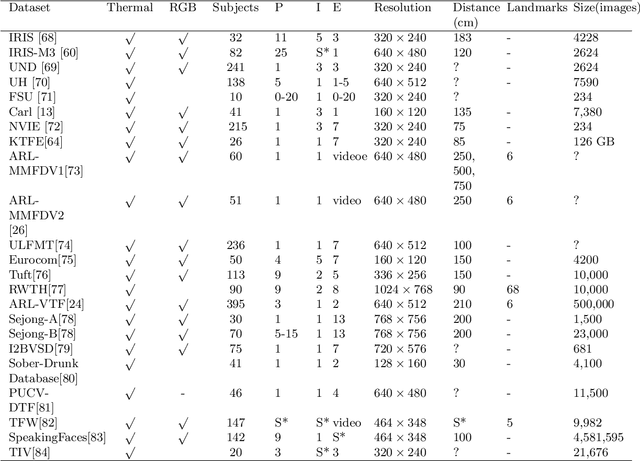
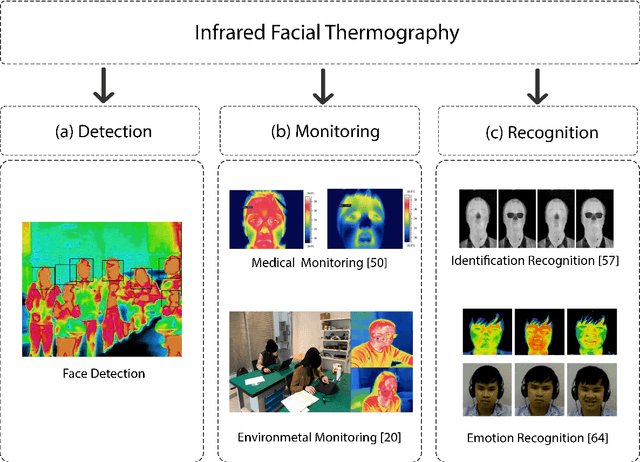
Facial thermography is one of the most popular research areas in infrared thermal imaging, with diverse applications in medical, surveillance, and environmental monitoring. However, in contrast to facial imagery in the visual spectrum, the lack of public datasets on facial thermal images is an obstacle to research improvement in this area. Thermal face imagery is still a relatively new research area to be evaluated and studied in different domains.The current thermal face datasets are limited in regards to the subjects' distance from the camera, the ambient temperature variation, and facial landmarks' localization. We address these gaps by presenting a new facial thermography dataset. This article makes two main contributions to the body of knowledge. First, it presents a comprehensive review and comparison of current public datasets in facial thermography. Second, it introduces and studies a novel public dataset on facial thermography, which we call it Charlotte-ThermalFace. Charlotte-ThermalFace contains more than10000 infrared thermal images in varying thermal conditions, several distances from the camera, and different head positions. The data is fully annotated with the facial landmarks, ambient temperature, relative humidity, the air speed of the room, distance to the camera, and subject thermal sensation at the time of capturing each image. Our dataset is the first publicly available thermal dataset annotated with the thermal sensation of each subject in different thermal conditions and one of the few datasets in raw 16-bit format. Finally, we present a preliminary analysis of the dataset to show the applicability and importance of the thermal conditions in facial thermography. The full dataset, including annotations, are freely available for research purpose at https://github.com/TeCSAR-UNCC/UNCC-ThermalFace
Detection of Genuine and Posed Facial Expressions of Emotion: A Review
Aug 26, 2020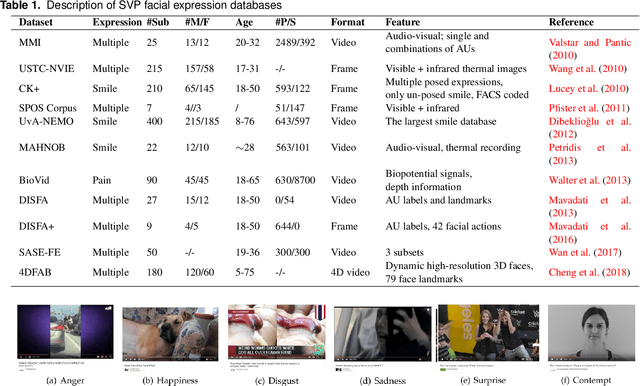

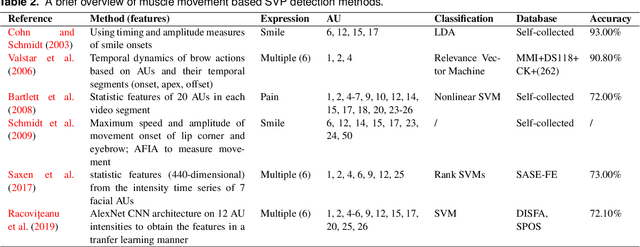

Facial expressions of emotion play an important role in human social interactions. However, posed acting is not always the same as genuine feeling. Therefore, the credibility assessment of facial expressions, namely, the discrimination of genuine (spontaneous) expressions from posed(deliberate/volitional/deceptive) ones, is a crucial yet challenging task in facial expression understanding. Rapid progress has been made in recent years for automatic detection of genuine and posed facial expressions. This paper presents a general review of the relevant research, including several spontaneous vs. posed (SVP) facial expression databases and various computer vision based detection methods. In addition, a variety of factors that will influence the performance of SVP detection methods are discussed along with open issues and technical challenges.
Privacy Attacks Against Biometric Models with Fewer Samples: Incorporating the Output of Multiple Models
Sep 22, 2022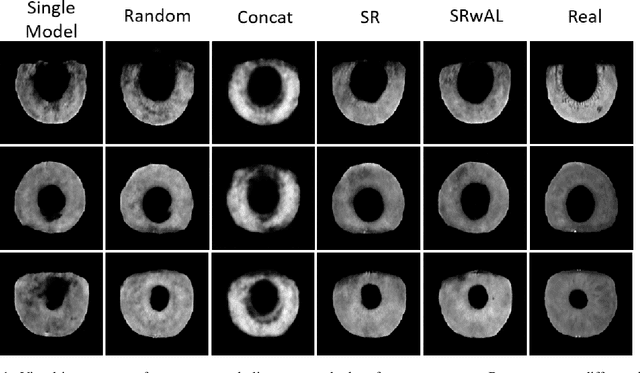
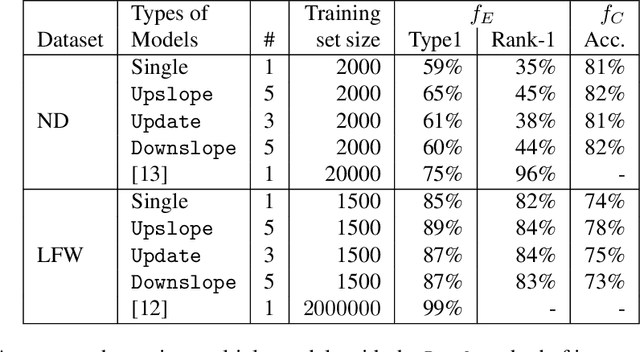
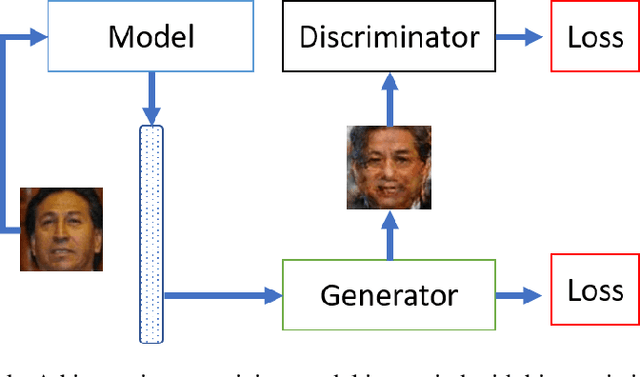
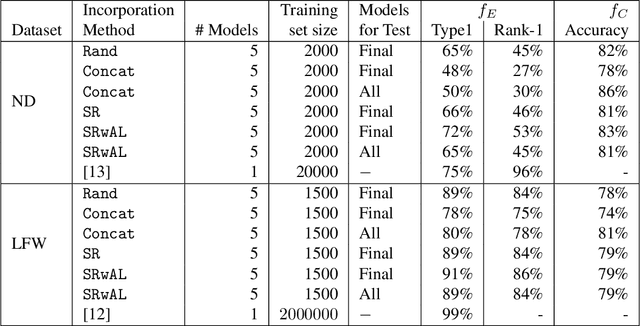
Authentication systems are vulnerable to model inversion attacks where an adversary is able to approximate the inverse of a target machine learning model. Biometric models are a prime candidate for this type of attack. This is because inverting a biometric model allows the attacker to produce a realistic biometric input to spoof biometric authentication systems. One of the main constraints in conducting a successful model inversion attack is the amount of training data required. In this work, we focus on iris and facial biometric systems and propose a new technique that drastically reduces the amount of training data necessary. By leveraging the output of multiple models, we are able to conduct model inversion attacks with 1/10th the training set size of Ahmad and Fuller (IJCB 2020) for iris data and 1/1000th the training set size of Mai et al. (Pattern Analysis and Machine Intelligence 2019) for facial data. We denote our new attack technique as structured random with alignment loss. Our attacks are black-box, requiring no knowledge of the weights of the target neural network, only the dimension, and values of the output vector. To show the versatility of the alignment loss, we apply our attack framework to the task of membership inference (Shokri et al., IEEE S&P 2017) on biometric data. For the iris, membership inference attack against classification networks improves from 52% to 62% accuracy.
A Masked Face Classification Benchmark
Nov 23, 2022
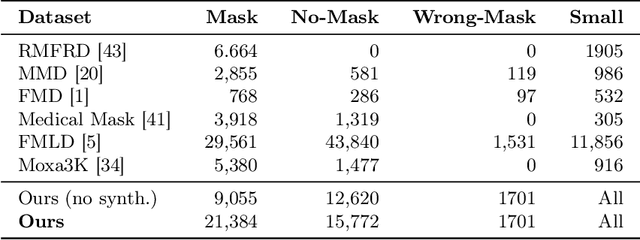

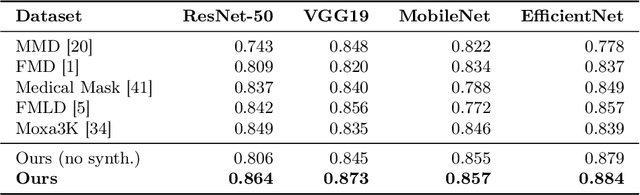
We propose a novel image dataset focused on tiny faces wearing face masks for mask classification purposes, dubbed Small Face MASK (SF-MASK), composed of a collection made from 20k low-resolution images exported from diverse and heterogeneous datasets, ranging from 7 x 7 to 64 x 64 pixel resolution. An accurate visualization of this collection, through counting grids, made it possible to highlight gaps in the variety of poses assumed by the heads of the pedestrians. In particular, faces filmed by very high cameras, in which the facial features appear strongly skewed, are absent. To address this structural deficiency, we produced a set of synthetic images which resulted in a satisfactory covering of the intra-class variance. Furthermore, a small subsample of 1701 images contains badly worn face masks, opening to multi-class classification challenges. Experiments on SF-MASK focus on face mask classification using several classifiers. Results show that the richness of SF-MASK (real + synthetic images) leads all of the tested classifiers to perform better than exploiting comparative face mask datasets, on a fixed 1077 images testing set. Dataset and evaluation code are publicly available here: https://github.com/HumaticsLAB/sf-mask
LoRRaL: Facial Action Unit Detection Based on Local Region Relation Learning
Sep 23, 2020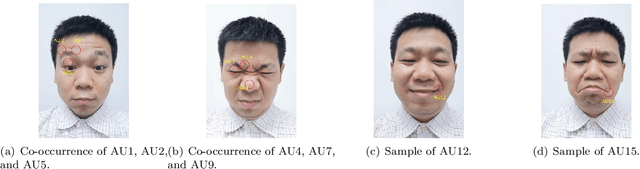
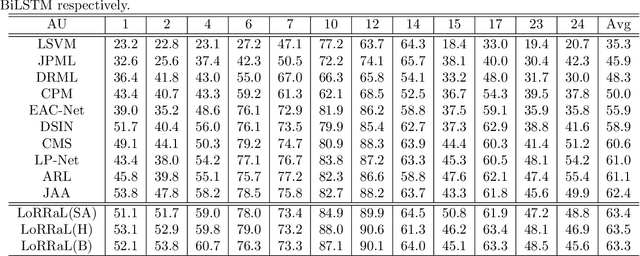
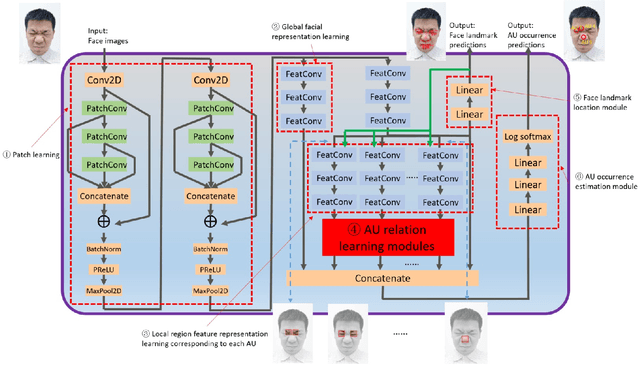
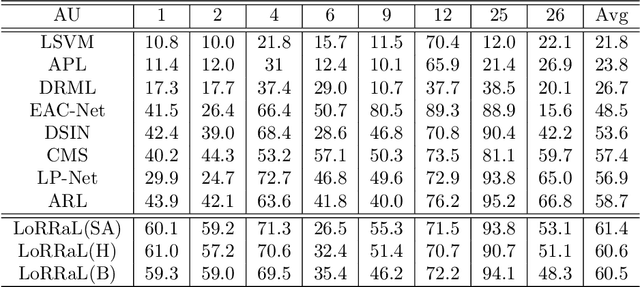
End-to-end convolution representation learning has been proved to be very effective in facial action unit (AU) detection. Considering the co-occurrence and mutual exclusion between facial AUs, in this paper, we propose convolution neural networks with Local Region Relation Learning (LoRRaL), which can combine latent relationships among AUs for an end-to-end approach to facial AU occurrence detection. LoRRaL consists of 1) use bi-directional long short-term memory (BiLSTM) to dynamically and sequentially encode local AU feature maps, 2) use self-attention mechanism to dynamically compute correspondences from local facial regions and to re-aggregate AU feature maps considering AU co-occurrences and mutual exclusions, 3) use a continuous-state modern Hopfield network to encode and map local facial features to more discriminative AU feature maps, that all these networks take the facial image as input and map it to AU occurrences. Our experiments on the challenging BP4D and DISFA Benchmarks without any external data or pre-trained models results in F1-scores of 63.5% and 61.4% respectively, which shows our proposed networks can lead to performance improvement on the AU detection task.
Quantum-Assisted Support Vector Regression for Detecting Facial Landmarks
Nov 17, 2021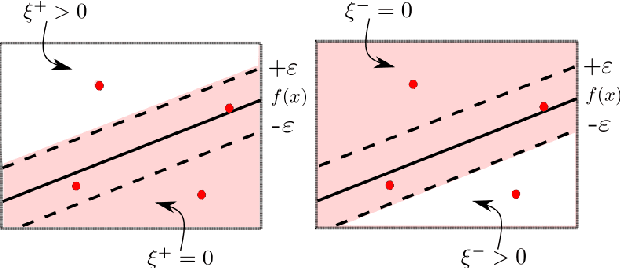

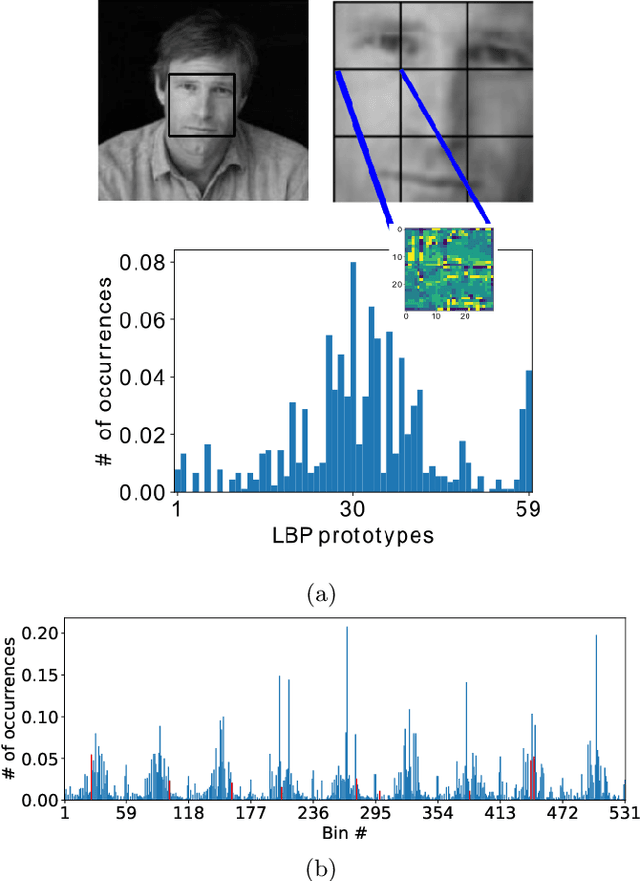
The classical machine-learning model for support vector regression (SVR) is widely used for regression tasks, including weather prediction, stock-market and real-estate pricing. However, a practically realisable quantum version for SVR remains to be formulated. We devise annealing-based algorithms, namely simulated and quantum-classical hybrid, for training two SVR models, and compare their empirical performances against the SVR implementation of Python's scikit-learn package and the SVR-based state-of-the-art algorithm for the facial landmark detection (FLD) problem. Our method is to derive a quadratic-unconstrained-binary formulation for the optimisation problem used for training a SVR model and solve this problem using annealing. Using D-Wave's Hybrid Solver, we construct a quantum-assisted SVR model, thereby demonstrating a slight advantage over classical models regarding landmark-detection accuracy. Furthermore, we observe that annealing-based SVR models predict landmarks with lower variances compared to the SVR models trained by greedy optimisation procedures. Our work is a proof-of-concept example for applying quantu-assisted SVR to a supervised learning task with a small training dataset.
Robust Face-Swap Detection Based on 3D Facial Shape Information
Apr 28, 2021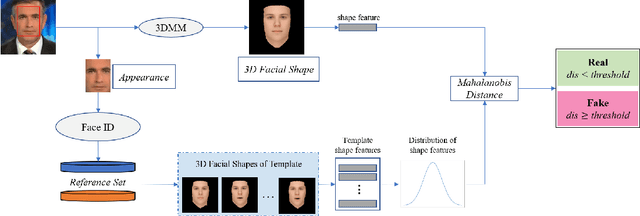

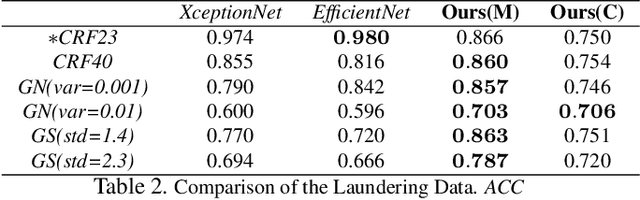
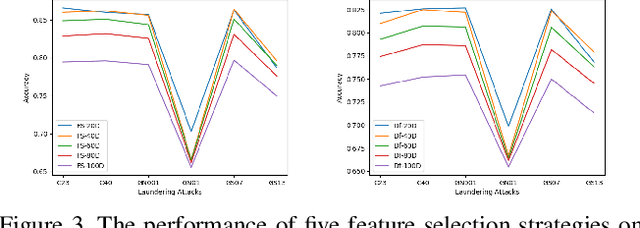
Maliciously-manipulated images or videos - so-called deep fakes - especially face-swap images and videos have attracted more and more malicious attackers to discredit some key figures. Previous pixel-level artifacts based detection techniques always focus on some unclear patterns but ignore some available semantic clues. Therefore, these approaches show weak interpretability and robustness. In this paper, we propose a biometric information based method to fully exploit the appearance and shape feature for face-swap detection of key figures. The key aspect of our method is obtaining the inconsistency of 3D facial shape and facial appearance, and the inconsistency based clue offers natural interpretability for the proposed face-swap detection method. Experimental results show the superiority of our method in robustness on various laundering and cross-domain data, which validates the effectiveness of the proposed method.