 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Automatic Estimation of Self-Reported Pain by Trajectory Analysis in the Manifold of Fixed Rank Positive Semi-Definite Matrices
Sep 17, 2022
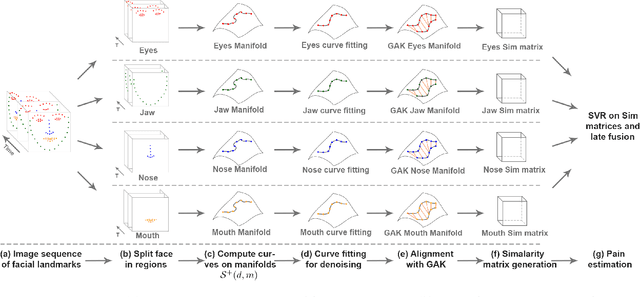
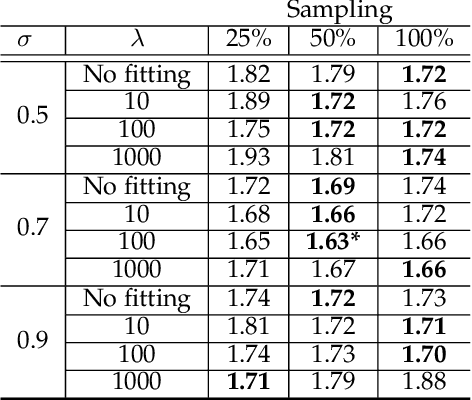
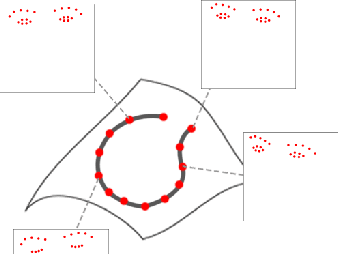
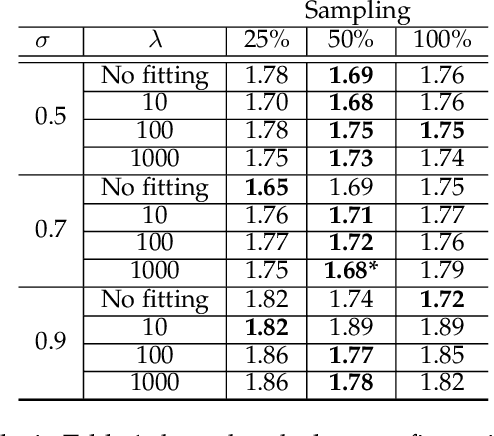
We propose an automatic method to estimate self-reported pain based on facial landmarks extracted from videos. For each video sequence, we decompose the face into four different regions and the pain intensity is measured by modeling the dynamics of facial movement using the landmarks of these regions. A formulation based on Gram matrices is used for representing the trajectory of landmarks on the Riemannian manifold of symmetric positive semi-definite matrices of fixed rank. A curve fitting algorithm is used to smooth the trajectories and temporal alignment is performed to compute the similarity between the trajectories on the manifold. A Support Vector Regression classifier is then trained to encode extracted trajectories into pain intensity levels consistent with self-reported pain intensity measurement. Finally, a late fusion of the estimation for each region is performed to obtain the final predicted pain level. The proposed approach is evaluated on two publicly available datasets, the UNBCMcMaster Shoulder Pain Archive and the Biovid Heat Pain dataset. We compared our method to the state-of-the-art on both datasets using different testing protocols, showing the competitiveness of the proposed approach.
Contrastive Learning for Diverse Disentangled Foreground Generation
Nov 04, 2022We introduce a new method for diverse foreground generation with explicit control over various factors. Existing image inpainting based foreground generation methods often struggle to generate diverse results and rarely allow users to explicitly control specific factors of variation (e.g., varying the facial identity or expression for face inpainting results). We leverage contrastive learning with latent codes to generate diverse foreground results for the same masked input. Specifically, we define two sets of latent codes, where one controls a pre-defined factor (``known''), and the other controls the remaining factors (``unknown''). The sampled latent codes from the two sets jointly bi-modulate the convolution kernels to guide the generator to synthesize diverse results. Experiments demonstrate the superiority of our method over state-of-the-arts in result diversity and generation controllability.
Facial expressions can detect Parkinson's disease: preliminary evidence from videos collected online
Dec 09, 2020
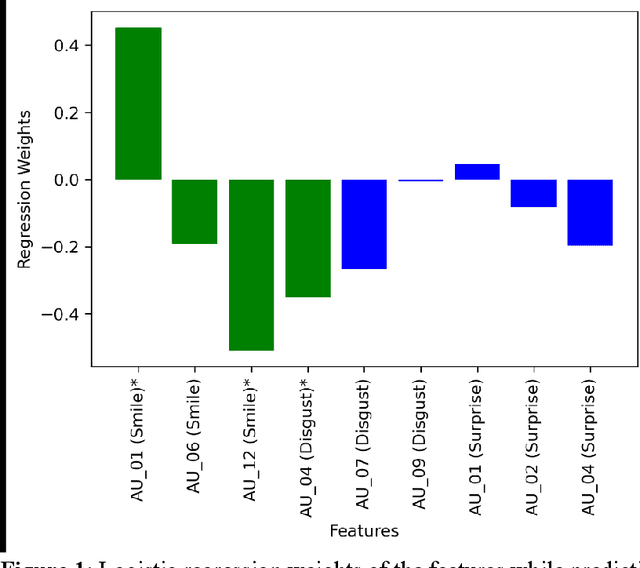
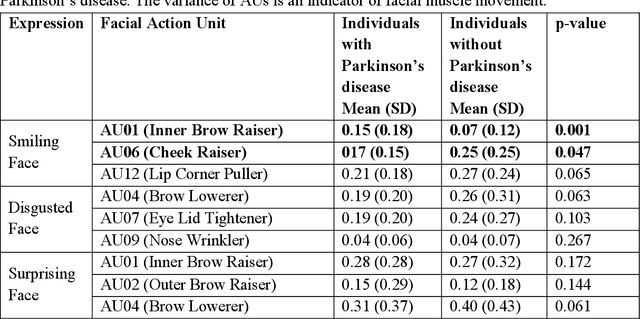
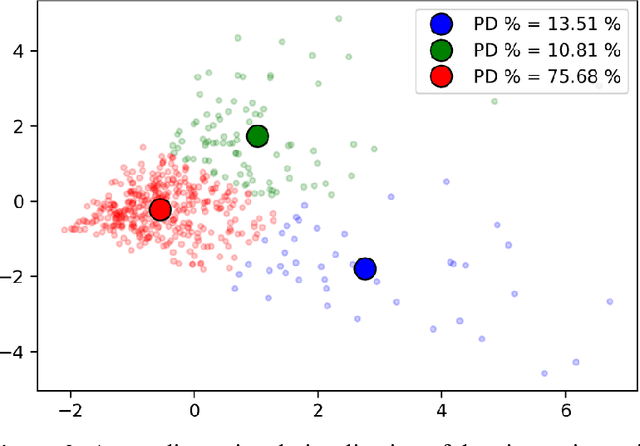
One of the symptoms of Parkinson's disease (PD) is hypomimia or reduced facial expressions. In this paper, we present a digital biomarker for PD that utilizes the study of micro-expressions. We analyzed the facial action units (AU) from 1812 videos of 604 individuals (61 with PD and 543 without PD, mean age 63.9 yo, sd 7.8 ) collected online using a web-based tool (www.parktest.net). In these videos, participants were asked to make three facial expressions (a smiling, disgusted, and surprised face) followed by a neutral face. Using techniques from computer vision and machine learning, we objectively measured the variance of the facial muscle movements and used it to distinguish between individuals with and without PD. The prediction accuracy using the facial micro-expressions was comparable to those methodologies that utilize motor symptoms. Logistic regression analysis revealed that participants with PD had less variance in AU6 (cheek raiser), AU12 (lip corner puller), and AU4 (brow lowerer) than non-PD individuals. An automated classifier using Support Vector Machine was trained on the variances and achieved 95.6% accuracy. Using facial expressions as a biomarker for PD could be potentially transformative for patients in need of physical separation (e.g., due to COVID) or are immobile.
Synthetic Expressions are Better Than Real for Learning to Detect Facial Actions
Oct 21, 2020
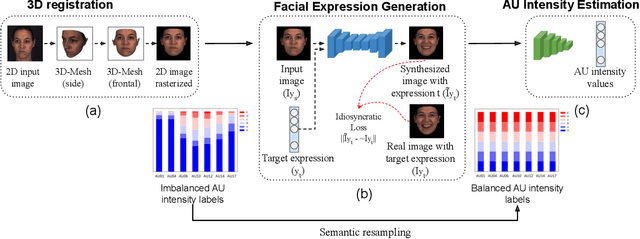

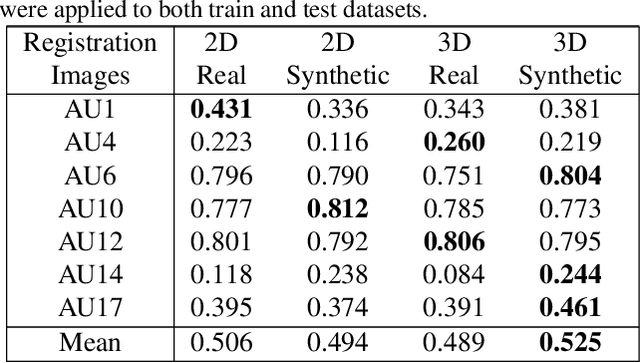
Critical obstacles in training classifiers to detect facial actions are the limited sizes of annotated video databases and the relatively low frequencies of occurrence of many actions. To address these problems, we propose an approach that makes use of facial expression generation. Our approach reconstructs the 3D shape of the face from each video frame, aligns the 3D mesh to a canonical view, and then trains a GAN-based network to synthesize novel images with facial action units of interest. To evaluate this approach, a deep neural network was trained on two separate datasets: One network was trained on video of synthesized facial expressions generated from FERA17; the other network was trained on unaltered video from the same database. Both networks used the same train and validation partitions and were tested on the test partition of actual video from FERA17. The network trained on synthesized facial expressions outperformed the one trained on actual facial expressions and surpassed current state-of-the-art approaches.
Multi-Task Learning for Emotion Descriptors Estimation at the fourth ABAW Challenge
Jul 20, 2022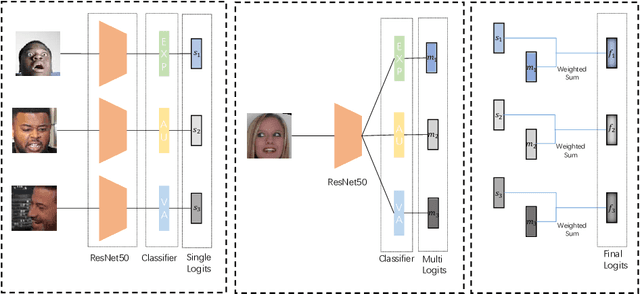

Facial valence/arousal, expression and action unit are related tasks in facial affective analysis. However, the tasks only have limited performance in the wild due to the various collected conditions. The 4th competition on affective behavior analysis in the wild (ABAW) provided images with valence/arousal, expression and action unit labels. In this paper, we introduce multi-task learning framework to enhance the performance of three related tasks in the wild. Feature sharing and label fusion are used to utilize their relations. We conduct experiments on the provided training and validating data.
AU-Guided Unsupervised Domain Adaptive Facial Expression Recognition
Dec 18, 2020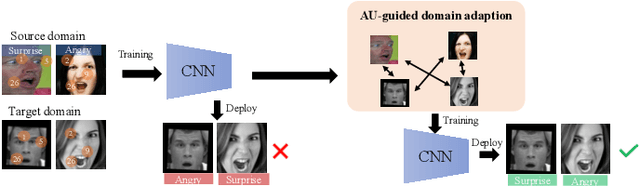
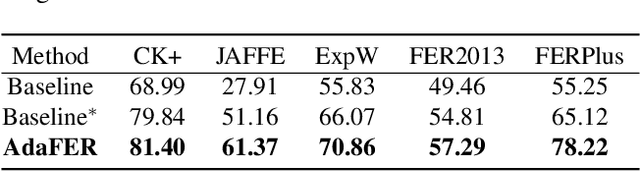
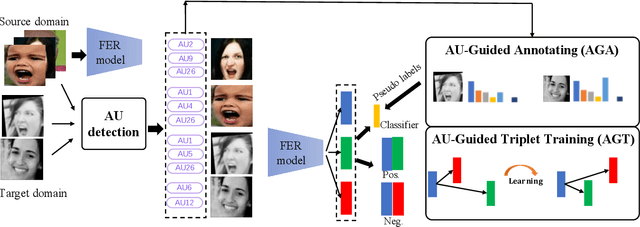
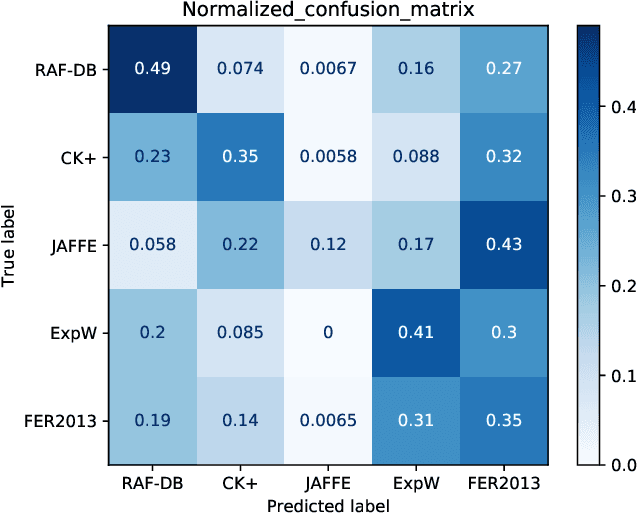
The domain diversities including inconsistent annotation and varied image collection conditions inevitably exist among different facial expression recognition (FER) datasets, which pose an evident challenge for adapting the FER model trained on one dataset to another one. Recent works mainly focus on domain-invariant deep feature learning with adversarial learning mechanism, ignoring the sibling facial action unit (AU) detection task which has obtained great progress. Considering AUs objectively determine facial expressions, this paper proposes an AU-guided unsupervised Domain Adaptive FER (AdaFER) framework. In AdaFER, we first leverage an advanced model for AU detection on both source and target domain. Then, we compare the AU results to perform AU-guided annotating, i.e., target faces that own the same AUs with source faces would inherit the labels from source domain. Meanwhile, to achieve domain-invariant compact features, we utilize an AU-guided triplet training which randomly collects anchor-positive-negative triplets on both domains with AUs. We conduct extensive experiments on several popular benchmarks and show that AdaFER achieves state-of-the-art results on all the benchmarks.
Improving Continuous Sign Language Recognition with Consistency Constraints and Signer Removal
Dec 26, 2022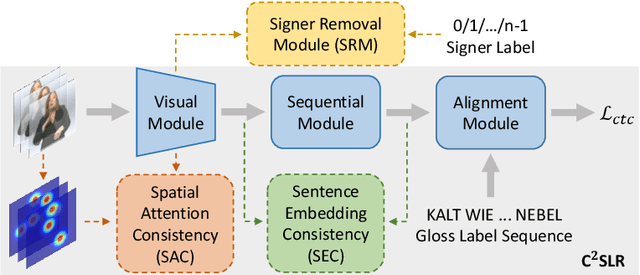
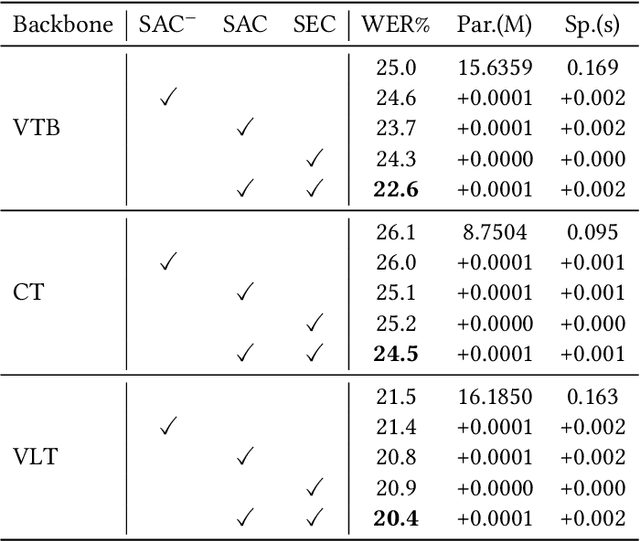
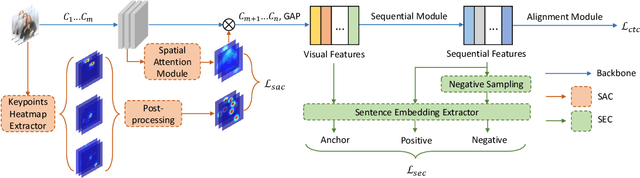
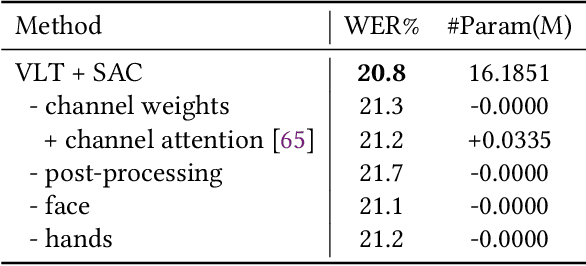
Most deep-learning-based continuous sign language recognition (CSLR) models share a similar backbone consisting of a visual module, a sequential module, and an alignment module. However, due to limited training samples, a connectionist temporal classification loss may not train such CSLR backbones sufficiently. In this work, we propose three auxiliary tasks to enhance the CSLR backbones. The first task enhances the visual module, which is sensitive to the insufficient training problem, from the perspective of consistency. Specifically, since the information of sign languages is mainly included in signers' facial expressions and hand movements, a keypoint-guided spatial attention module is developed to enforce the visual module to focus on informative regions, i.e., spatial attention consistency. Second, noticing that both the output features of the visual and sequential modules represent the same sentence, to better exploit the backbone's power, a sentence embedding consistency constraint is imposed between the visual and sequential modules to enhance the representation power of both features. We name the CSLR model trained with the above auxiliary tasks as consistency-enhanced CSLR, which performs well on signer-dependent datasets in which all signers appear during both training and testing. To make it more robust for the signer-independent setting, a signer removal module based on feature disentanglement is further proposed to remove signer information from the backbone. Extensive ablation studies are conducted to validate the effectiveness of these auxiliary tasks. More remarkably, with a transformer-based backbone, our model achieves state-of-the-art or competitive performance on five benchmarks, PHOENIX-2014, PHOENIX-2014-T, PHOENIX-2014-SI, CSL, and CSL-Daily.
Semantic-aware One-shot Face Re-enactment with Dense Correspondence Estimation
Nov 23, 2022
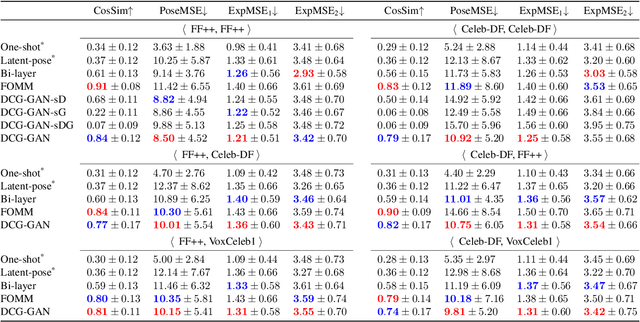
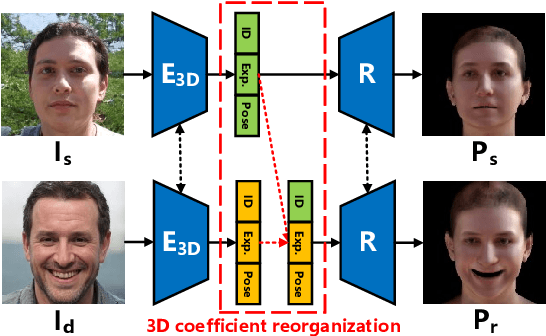
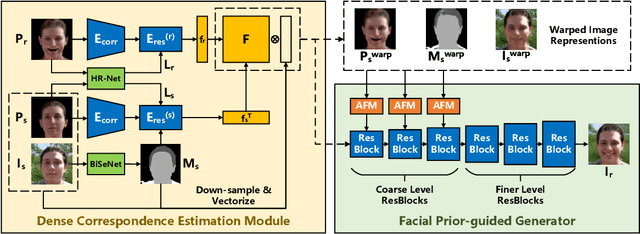
One-shot face re-enactment is a challenging task due to the identity mismatch between source and driving faces. Specifically, the suboptimally disentangled identity information of driving subjects would inevitably interfere with the re-enactment results and lead to face shape distortion. To solve this problem, this paper proposes to use 3D Morphable Model (3DMM) for explicit facial semantic decomposition and identity disentanglement. Instead of using 3D coefficients alone for re-enactment control, we take the advantage of the generative ability of 3DMM to render textured face proxies. These proxies contain abundant yet compact geometric and semantic information of human faces, which enable us to compute the face motion field between source and driving images by estimating the dense correspondence. In this way, we could approximate re-enactment results by warping source images according to the motion field, and a Generative Adversarial Network (GAN) is adopted to further improve the visual quality of warping results. Extensive experiments on various datasets demonstrate the advantages of the proposed method over existing start-of-the-art benchmarks in both identity preservation and re-enactment fulfillment.
SeedBERT: Recovering Annotator Rating Distributions from an Aggregated Label
Nov 23, 2022

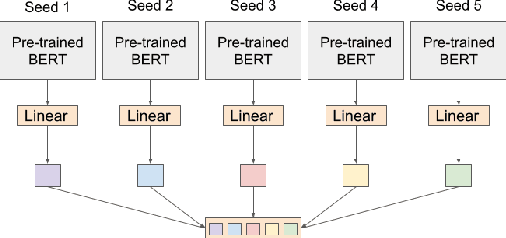
Many machine learning tasks -- particularly those in affective computing -- are inherently subjective. When asked to classify facial expressions or to rate an individual's attractiveness, humans may disagree with one another, and no single answer may be objectively correct. However, machine learning datasets commonly have just one "ground truth" label for each sample, so models trained on these labels may not perform well on tasks that are subjective in nature. Though allowing models to learn from the individual annotators' ratings may help, most datasets do not provide annotator-specific labels for each sample. To address this issue, we propose SeedBERT, a method for recovering annotator rating distributions from a single label by inducing pre-trained models to attend to different portions of the input. Our human evaluations indicate that SeedBERT's attention mechanism is consistent with human sources of annotator disagreement. Moreover, in our empirical evaluations using large language models, SeedBERT demonstrates substantial gains in performance on downstream subjective tasks compared both to standard deep learning models and to other current models that account explicitly for annotator disagreement.
Automatic Assessment of Infant Face and Upper-Body Symmetry as Early Signs of Torticollis
Nov 07, 2022
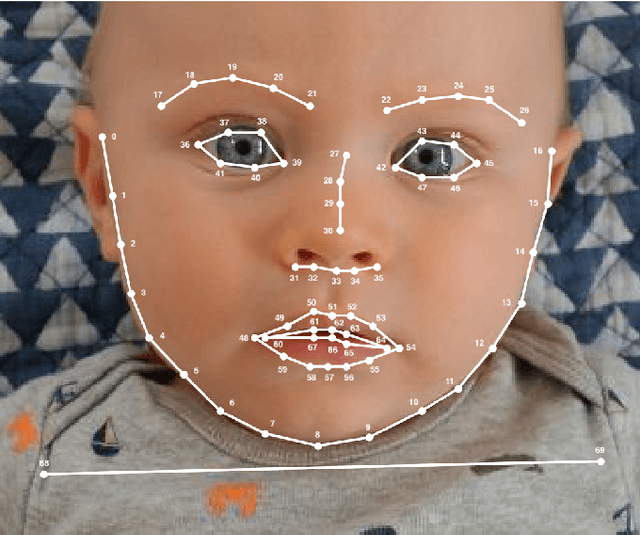
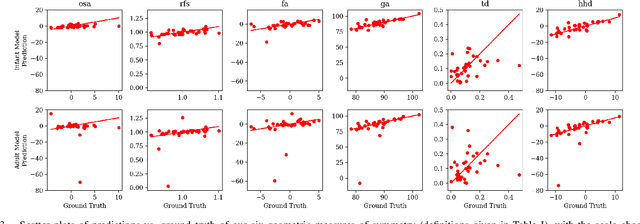

We apply computer vision pose estimation techniques developed expressly for the data-scarce infant domain to the study of torticollis, a common condition in infants for which early identification and treatment is critical. Specifically, we use a combination of facial landmark and body joint estimation techniques designed for infants to estimate a range of geometric measures pertaining to face and upper body symmetry, drawn from an array of sources in the physical therapy and ophthalmology research literature in torticollis. We gauge performance with a range of metrics and show that the estimates of most these geometric measures are successful, yielding strong to very strong Spearman's $\rho$ correlation with ground truth values. Furthermore, we show that these estimates, derived from pose estimation neural networks designed for the infant domain, cleanly outperform estimates derived from more widely known networks designed for the adult domain