 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis
Nov 26, 2022
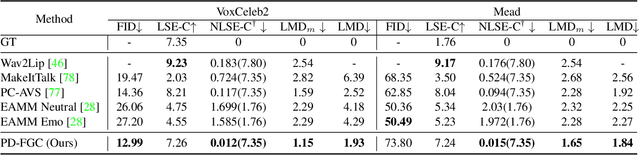
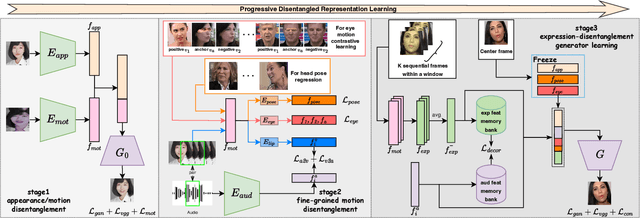
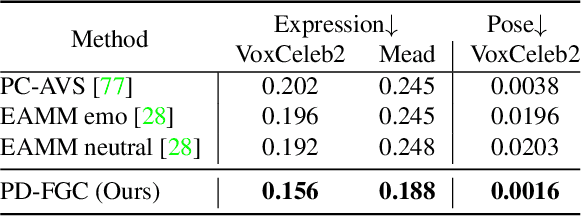

We present a novel one-shot talking head synthesis method that achieves disentangled and fine-grained control over lip motion, eye gaze&blink, head pose, and emotional expression. We represent different motions via disentangled latent representations and leverage an image generator to synthesize talking heads from them. To effectively disentangle each motion factor, we propose a progressive disentangled representation learning strategy by separating the factors in a coarse-to-fine manner, where we first extract unified motion feature from the driving signal, and then isolate each fine-grained motion from the unified feature. We introduce motion-specific contrastive learning and regressing for non-emotional motions, and feature-level decorrelation and self-reconstruction for emotional expression, to fully utilize the inherent properties of each motion factor in unstructured video data to achieve disentanglement. Experiments show that our method provides high quality speech&lip-motion synchronization along with precise and disentangled control over multiple extra facial motions, which can hardly be achieved by previous methods.
Talking Head Generation Driven by Speech-Related Facial Action Units and Audio- Based on Multimodal Representation Fusion
Apr 27, 2022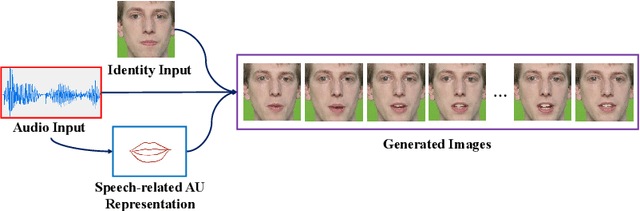
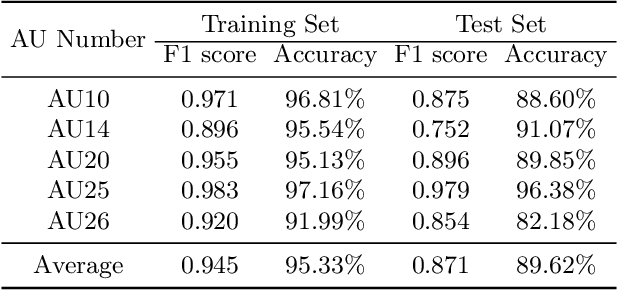
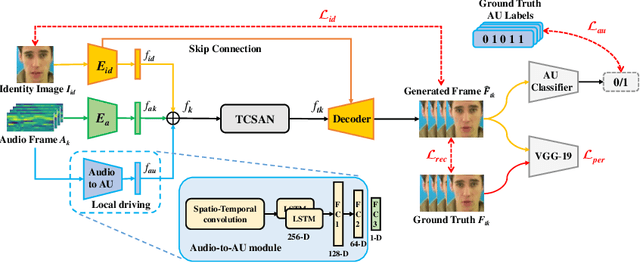

Talking head generation is to synthesize a lip-synchronized talking head video by inputting an arbitrary face image and corresponding audio clips. Existing methods ignore not only the interaction and relationship of cross-modal information, but also the local driving information of the mouth muscles. In this study, we propose a novel generative framework that contains a dilated non-causal temporal convolutional self-attention network as a multimodal fusion module to promote the relationship learning of cross-modal features. In addition, our proposed method uses both audio- and speech-related facial action units (AUs) as driving information. Speech-related AU information can guide mouth movements more accurately. Because speech is highly correlated with speech-related AUs, we propose an audio-to-AU module to predict speech-related AU information. We utilize pre-trained AU classifier to ensure that the generated images contain correct AU information. We verify the effectiveness of the proposed model on the GRID and TCD-TIMIT datasets. An ablation study is also conducted to verify the contribution of each component. The results of quantitative and qualitative experiments demonstrate that our method outperforms existing methods in terms of both image quality and lip-sync accuracy.
Improving Facial Attribute Recognition by Group and Graph Learning
May 28, 2021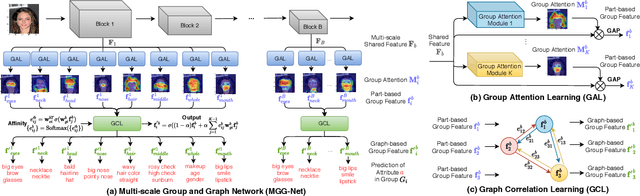
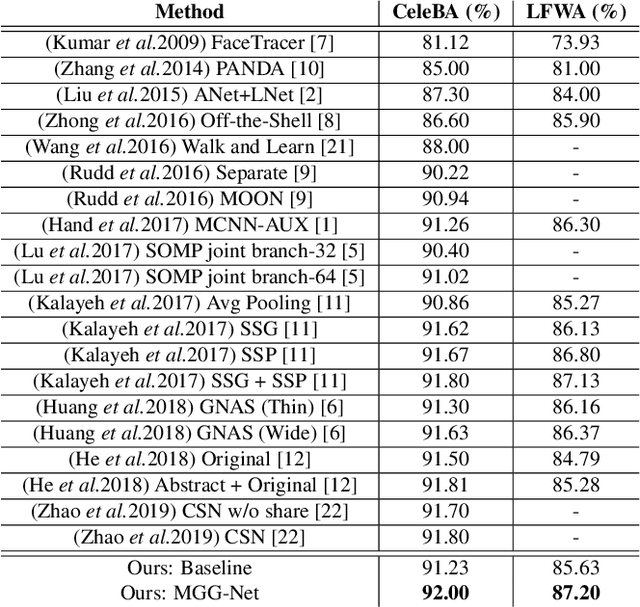
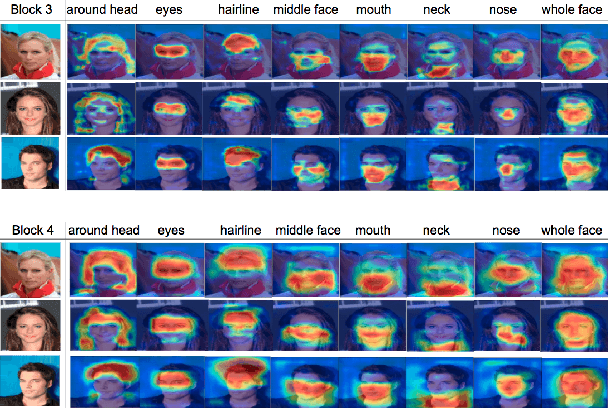
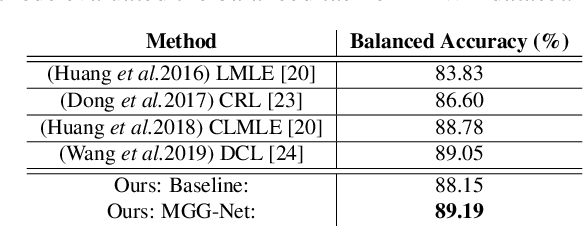
Exploiting the relationships between attributes is a key challenge for improving multiple facial attribute recognition. In this work, we are concerned with two types of correlations that are spatial and non-spatial relationships. For the spatial correlation, we aggregate attributes with spatial similarity into a part-based group and then introduce a Group Attention Learning to generate the group attention and the part-based group feature. On the other hand, to discover the non-spatial relationship, we model a group-based Graph Correlation Learning to explore affinities of predefined part-based groups. We utilize such affinity information to control the communication between all groups and then refine the learned group features. Overall, we propose a unified network called Multi-scale Group and Graph Network. It incorporates these two newly proposed learning strategies and produces coarse-to-fine graph-based group features for improving facial attribute recognition. Comprehensive experiments demonstrate that our approach outperforms the state-of-the-art methods.
Introducing Representations of Facial Affect in Automated Multimodal Deception Detection
Aug 31, 2020
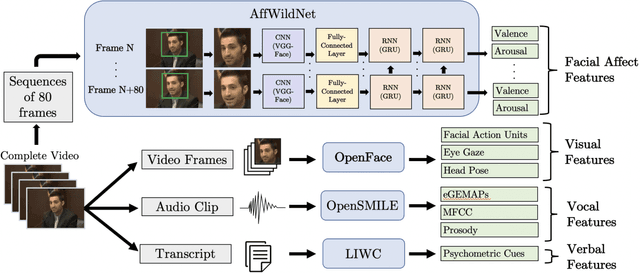
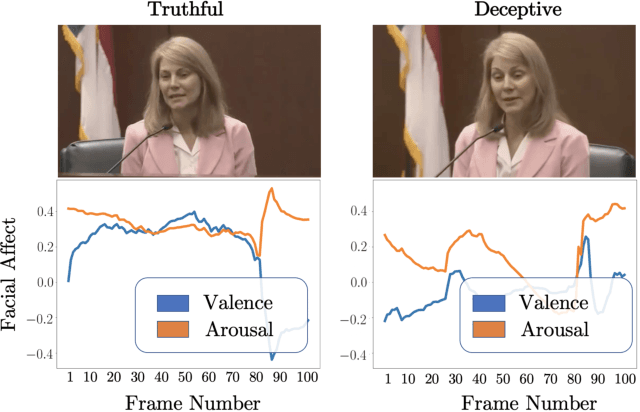
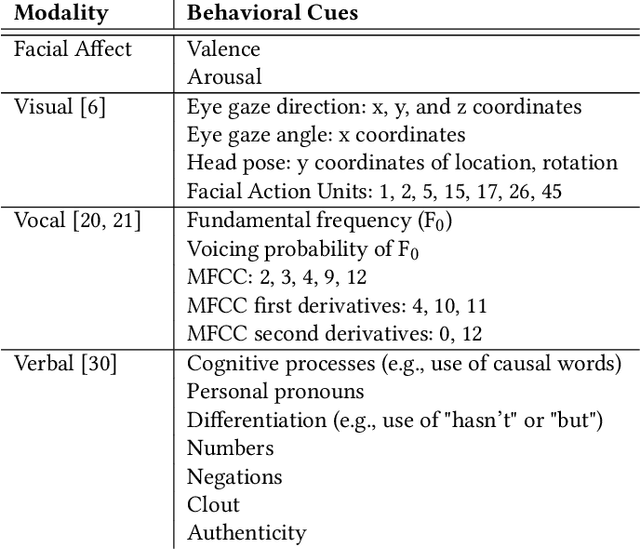
Automated deception detection systems can enhance health, justice, and security in society by helping humans detect deceivers in high-stakes situations across medical and legal domains, among others. This paper presents a novel analysis of the discriminative power of dimensional representations of facial affect for automated deception detection, along with interpretable features from visual, vocal, and verbal modalities. We used a video dataset of people communicating truthfully or deceptively in real-world, high-stakes courtroom situations. We leveraged recent advances in automated emotion recognition in-the-wild by implementing a state-of-the-art deep neural network trained on the Aff-Wild database to extract continuous representations of facial valence and facial arousal from speakers. We experimented with unimodal Support Vector Machines (SVM) and SVM-based multimodal fusion methods to identify effective features, modalities, and modeling approaches for detecting deception. Unimodal models trained on facial affect achieved an AUC of 80%, and facial affect contributed towards the highest-performing multimodal approach (adaptive boosting) that achieved an AUC of 91% when tested on speakers who were not part of training sets. This approach achieved a higher AUC than existing automated machine learning approaches that used interpretable visual, vocal, and verbal features to detect deception in this dataset, but did not use facial affect. Across all videos, deceptive and truthful speakers exhibited significant differences in facial valence and facial arousal, contributing computational support to existing psychological theories on affect and deception. The demonstrated importance of facial affect in our models informs and motivates the future development of automated, affect-aware machine learning approaches for modeling and detecting deception and other social behaviors in-the-wild.
DeepFaceFlow: In-the-wild Dense 3D Facial Motion Estimation
May 14, 2020
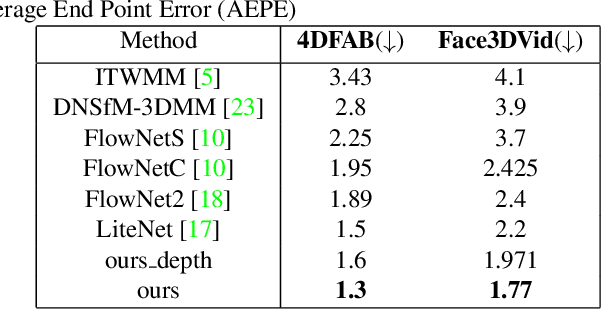
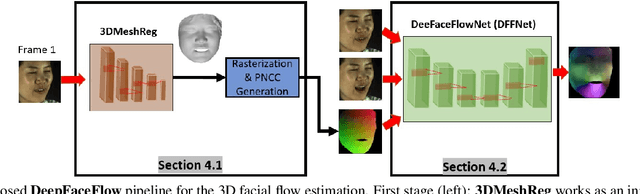
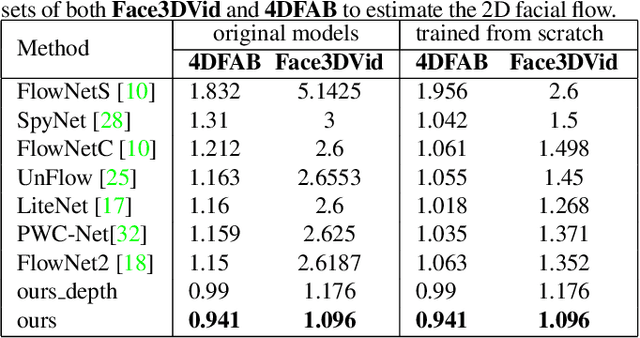
Dense 3D facial motion capture from only monocular in-the-wild pairs of RGB images is a highly challenging problem with numerous applications, ranging from facial expression recognition to facial reenactment. In this work, we propose DeepFaceFlow, a robust, fast, and highly-accurate framework for the dense estimation of 3D non-rigid facial flow between pairs of monocular images. Our DeepFaceFlow framework was trained and tested on two very large-scale facial video datasets, one of them of our own collection and annotation, with the aid of occlusion-aware and 3D-based loss function. We conduct comprehensive experiments probing different aspects of our approach and demonstrating its improved performance against state-of-the-art flow and 3D reconstruction methods. Furthermore, we incorporate our framework in a full-head state-of-the-art facial video synthesis method and demonstrate the ability of our method in better representing and capturing the facial dynamics, resulting in a highly-realistic facial video synthesis. Given registered pairs of images, our framework generates 3D flow maps at ~60 fps.
Data Leakage and Evaluation Issues in Micro-Expression Analysis
Nov 21, 2022

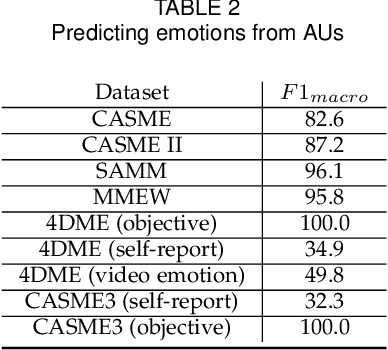
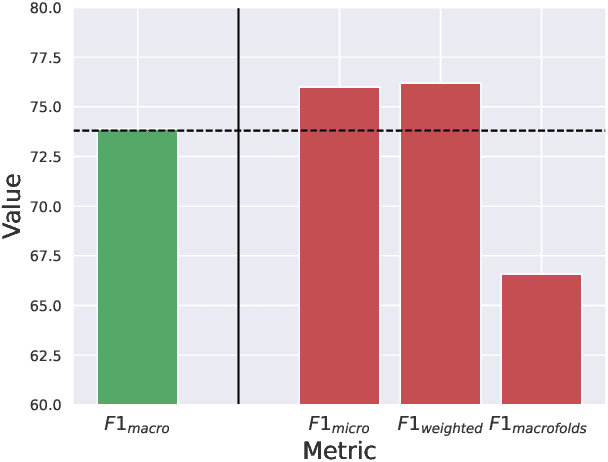
Micro-expressions have drawn increasing interest lately due to various potential applications. The task is, however, difficult as it incorporates many challenges from the fields of computer vision, machine learning and emotional sciences. Due to the spontaneous and subtle characteristics of micro-expressions, the available training and testing data are limited, which make evaluation complex. We show that data leakage and fragmented evaluation protocols are issues among the micro-expression literature. We find that fixing data leaks can drastically reduce model performance, in some cases even making the models perform similarly to a random classifier. To this end, we go through common pitfalls, propose a new standardized evaluation protocol using facial action units with over 2000 micro-expression samples, and provide an open source library that implements the evaluation protocols in a standardized manner. Code will be available in \url{https://github.com/tvaranka/meb}.
Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers
Dec 09, 2022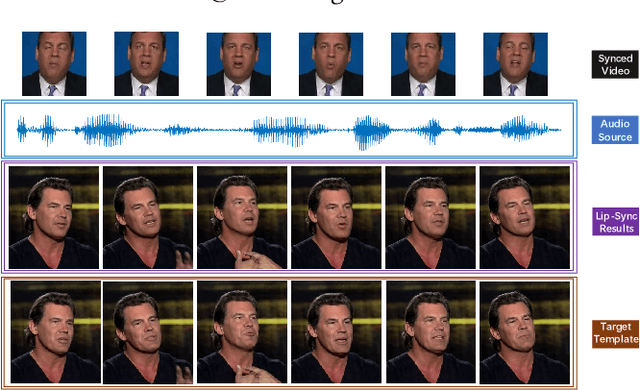
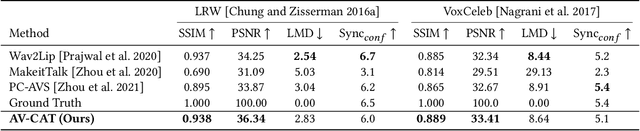
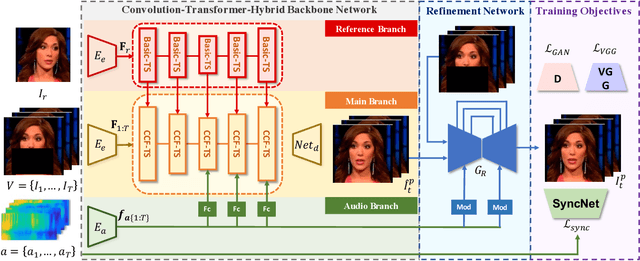
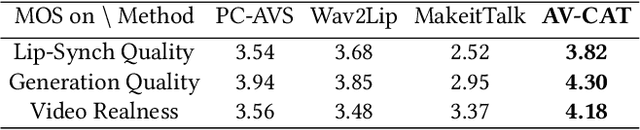
Previous studies have explored generating accurately lip-synced talking faces for arbitrary targets given audio conditions. However, most of them deform or generate the whole facial area, leading to non-realistic results. In this work, we delve into the formulation of altering only the mouth shapes of the target person. This requires masking a large percentage of the original image and seamlessly inpainting it with the aid of audio and reference frames. To this end, we propose the Audio-Visual Context-Aware Transformer (AV-CAT) framework, which produces accurate lip-sync with photo-realistic quality by predicting the masked mouth shapes. Our key insight is to exploit desired contextual information provided in audio and visual modalities thoroughly with delicately designed Transformers. Specifically, we propose a convolution-Transformer hybrid backbone and design an attention-based fusion strategy for filling the masked parts. It uniformly attends to the textural information on the unmasked regions and the reference frame. Then the semantic audio information is involved in enhancing the self-attention computation. Additionally, a refinement network with audio injection improves both image and lip-sync quality. Extensive experiments validate that our model can generate high-fidelity lip-synced results for arbitrary subjects.
Accurate 3D Facial Geometry Prediction by Multi-Task, Multi-Modal, and Multi-Representation Landmark Refinement Network
Apr 16, 2021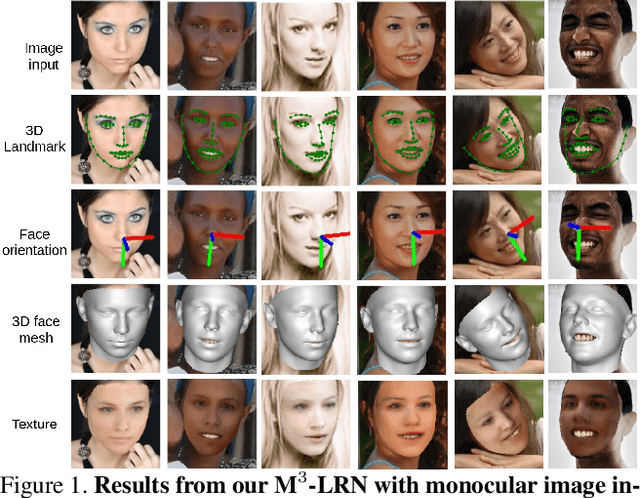
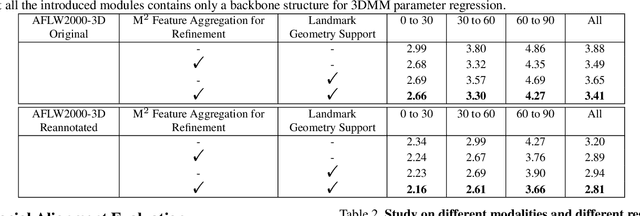
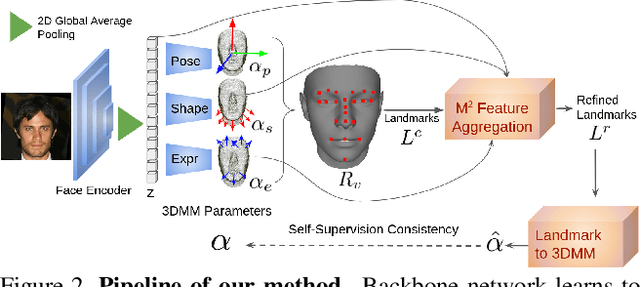
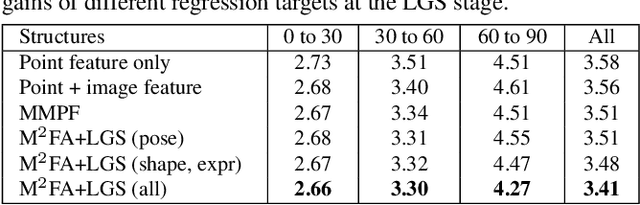
This work focuses on complete 3D facial geometry prediction, including 3D facial alignment via 3D face modeling and face orientation estimation using the proposed multi-task, multi-modal, and multi-representation landmark refinement network (M$^3$-LRN). Our focus is on the important facial attributes, 3D landmarks, and we fully utilize their embedded information to guide 3D facial geometry learning. We first propose a multi-modal and multi-representation feature aggregation for landmark refinement. Next, we are the first to study 3DMM regression from sparse 3D landmarks and utilize multi-representation advantage to attain better geometry prediction. We attain the state of the art from extensive experiments on all tasks of learning 3D facial geometry. We closely validate contributions of each modality and representation. Our results are robust across cropped faces, underwater scenarios, and extreme poses. Specially we adopt only simple and widely used network operations in M$^3$-LRN and attain a near 20\% improvement on face orientation estimation over the current best performance. See our project page here.
Facial Emotion Recognition: State of the Art Performance on FER2013
May 08, 2021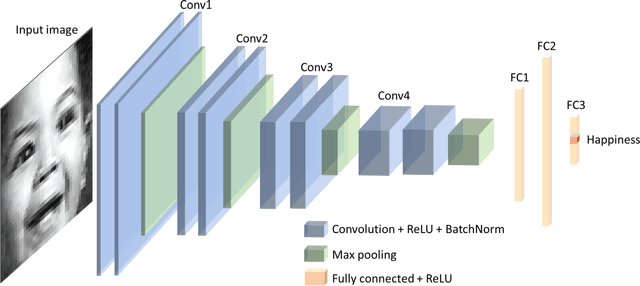
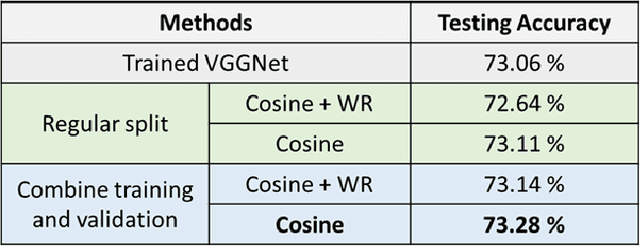
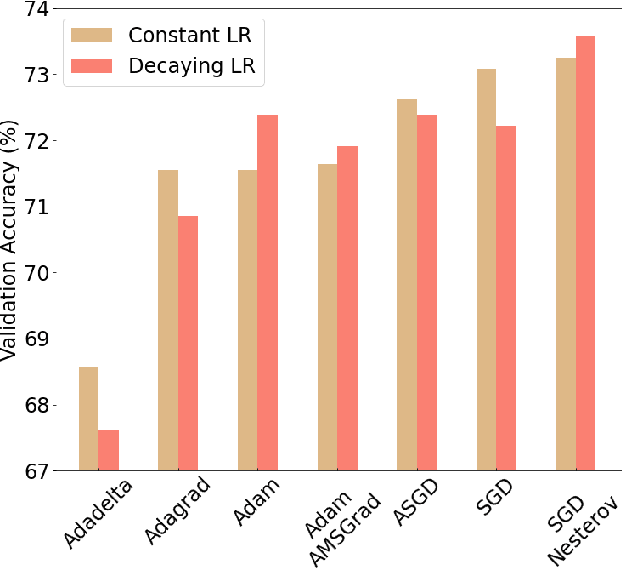
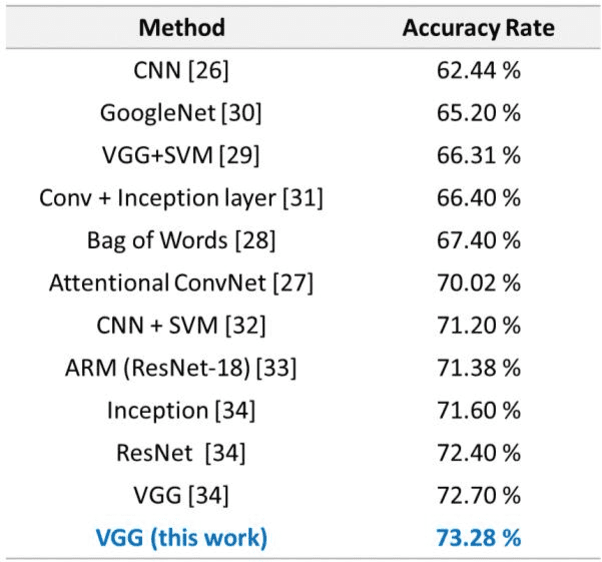
Facial emotion recognition (FER) is significant for human-computer interaction such as clinical practice and behavioral description. Accurate and robust FER by computer models remains challenging due to the heterogeneity of human faces and variations in images such as different facial pose and lighting. Among all techniques for FER, deep learning models, especially Convolutional Neural Networks (CNNs) have shown great potential due to their powerful automatic feature extraction and computational efficiency. In this work, we achieve the highest single-network classification accuracy on the FER2013 dataset. We adopt the VGGNet architecture, rigorously fine-tune its hyperparameters, and experiment with various optimization methods. To our best knowledge, our model achieves state-of-the-art single-network accuracy of 73.28 % on FER2013 without using extra training data.
StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3
Aug 16, 2022
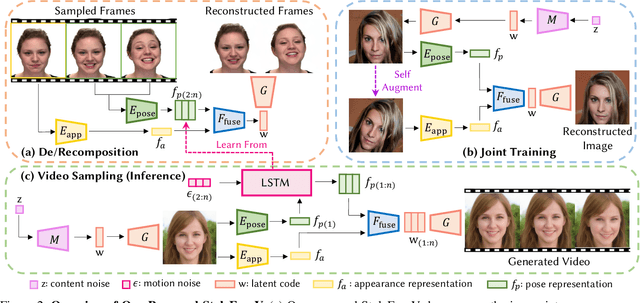
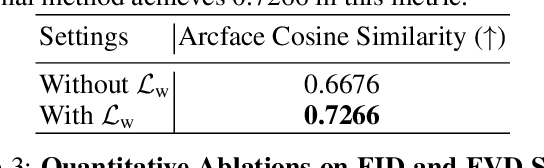

Realistic generative face video synthesis has long been a pursuit in both computer vision and graphics community. However, existing face video generation methods tend to produce low-quality frames with drifted facial identities and unnatural movements. To tackle these challenges, we propose a principled framework named StyleFaceV, which produces high-fidelity identity-preserving face videos with vivid movements. Our core insight is to decompose appearance and pose information and recompose them in the latent space of StyleGAN3 to produce stable and dynamic results. Specifically, StyleGAN3 provides strong priors for high-fidelity facial image generation, but the latent space is intrinsically entangled. By carefully examining its latent properties, we propose our decomposition and recomposition designs which allow for the disentangled combination of facial appearance and movements. Moreover, a temporal-dependent model is built upon the decomposed latent features, and samples reasonable sequences of motions that are capable of generating realistic and temporally coherent face videos. Particularly, our pipeline is trained with a joint training strategy on both static images and high-quality video data, which is of higher data efficiency. Extensive experiments demonstrate that our framework achieves state-of-the-art face video generation results both qualitatively and quantitatively. Notably, StyleFaceV is capable of generating realistic $1024\times1024$ face videos even without high-resolution training videos.