 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
edBB-Demo: Biometrics and Behavior Analysis for Online Educational Platforms
Nov 16, 2022
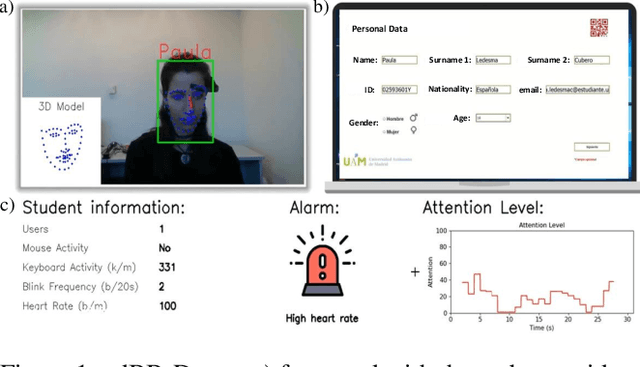
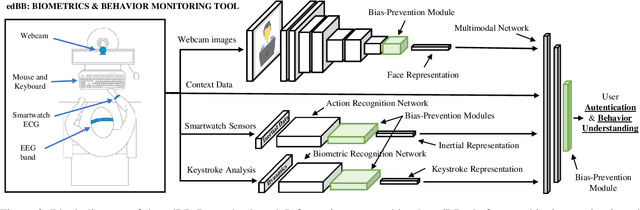
We present edBB-Demo, a demonstrator of an AI-powered research platform for student monitoring in remote education. The edBB platform aims to study the challenges associated to user recognition and behavior understanding in digital platforms. This platform has been developed for data collection, acquiring signals from a variety of sensors including keyboard, mouse, webcam, microphone, smartwatch, and an Electroencephalography band. The information captured from the sensors during the student sessions is modelled in a multimodal learning framework. The demonstrator includes: i) Biometric user authentication in an unsupervised environment; ii) Human action recognition based on remote video analysis; iii) Heart rate estimation from webcam video; and iv) Attention level estimation from facial expression analysis.
Facial Landmark Predictions with Applications to Metaverse
Sep 29, 2022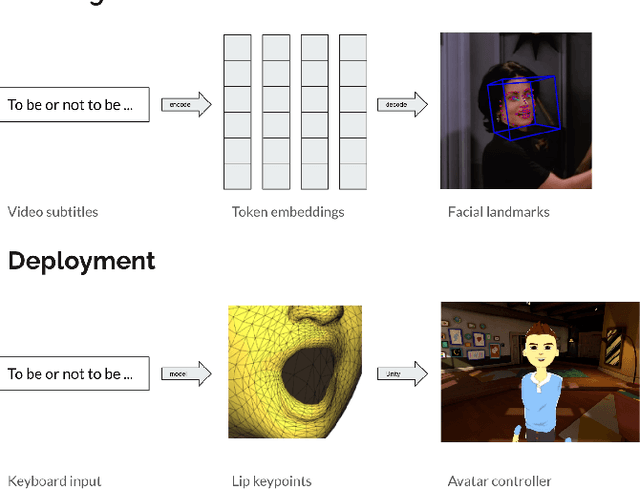
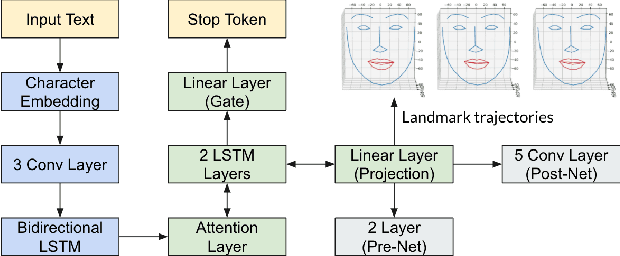
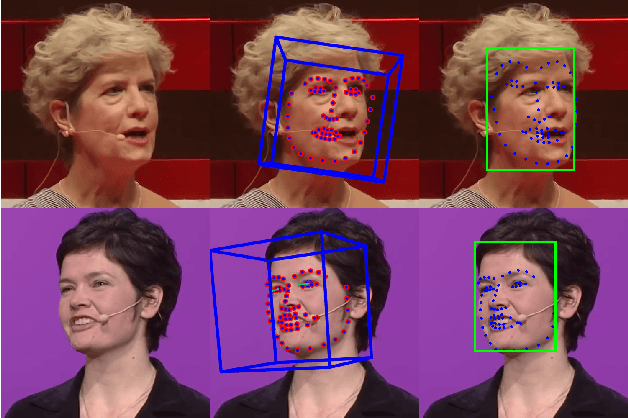
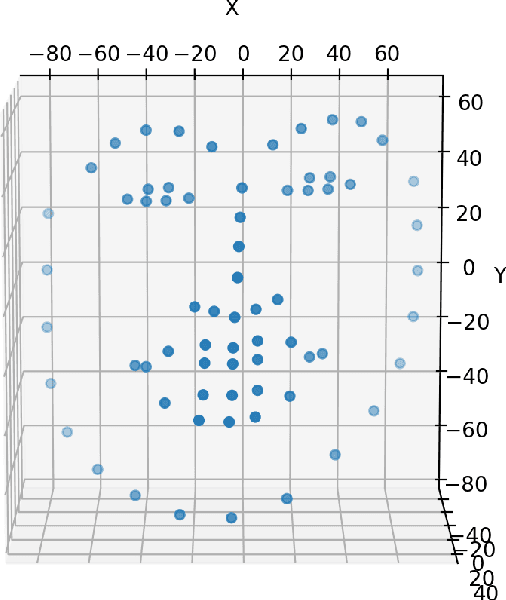
This research aims to make metaverse characters more realistic by adding lip animations learnt from videos in the wild. To achieve this, our approach is to extend Tacotron 2 text-to-speech synthesizer to generate lip movements together with mel spectrogram in one pass. The encoder and gate layer weights are pre-trained on LJ Speech 1.1 data set while the decoder is retrained on 93 clips of TED talk videos extracted from LRS 3 data set. Our novel decoder predicts displacement in 20 lip landmark positions across time, using labels automatically extracted by OpenFace 2.0 landmark predictor. Training converged in 7 hours using less than 5 minutes of video. We conducted ablation study for Pre/Post-Net and pre-trained encoder weights to demonstrate the effectiveness of transfer learning between audio and visual speech data.
Your Face Mirrors Your Deepest Beliefs-Predicting Personality and Morals through Facial Emotion Recognition
Dec 23, 2021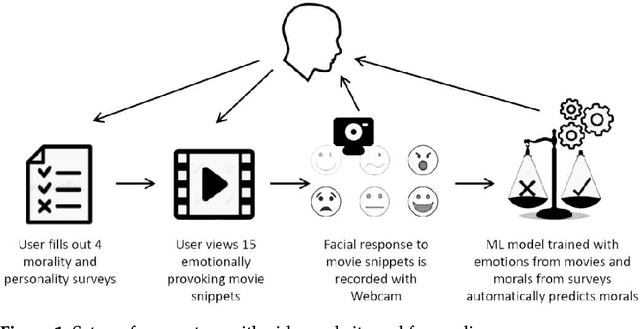
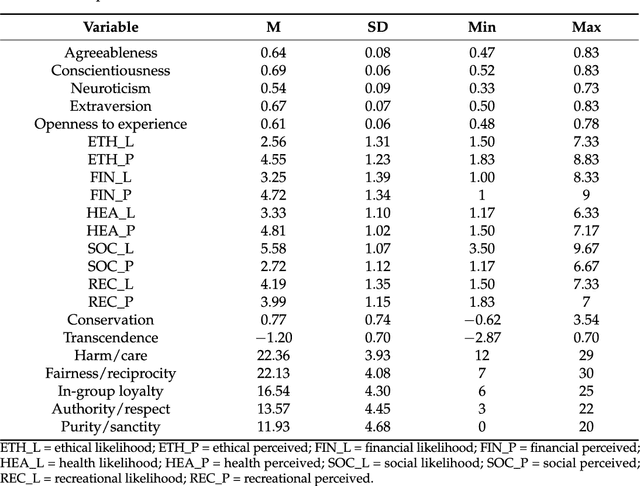
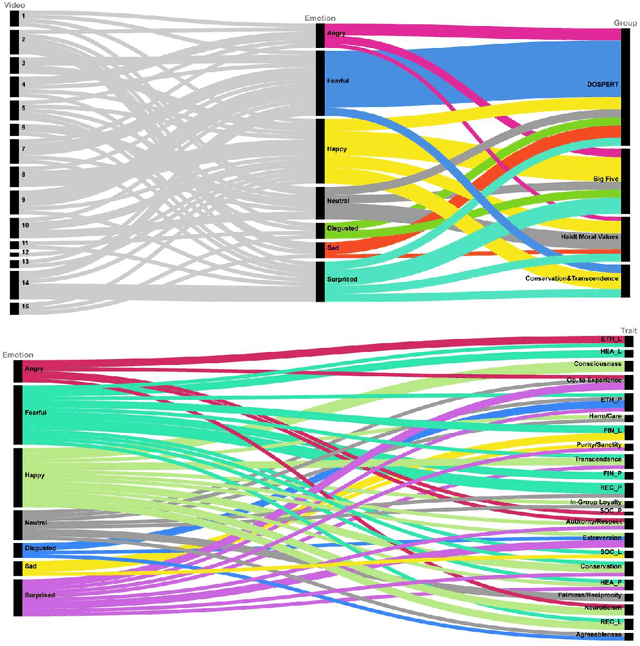
Can we really "read the mind in the eyes"? Moreover, can AI assist us in this task? This paper answers these two questions by introducing a machine learning system that predicts personality characteristics of individuals on the basis of their face. It does so by tracking the emotional response of the individual's face through facial emotion recognition (FER) while watching a series of 15 short videos of different genres. To calibrate the system, we invited 85 people to watch the videos, while their emotional responses were analyzed through their facial expression. At the same time, these individuals also took four well-validated surveys of personality characteristics and moral values: the revised NEO FFI personality inventory, the Haidt moral foundations test, the Schwartz personal value system, and the domain-specific risk-taking scale (DOSPERT). We found that personality characteristics and moral values of an individual can be predicted through their emotional response to the videos as shown in their face, with an accuracy of up to 86% using gradient-boosted trees. We also found that different personality characteristics are better predicted by different videos, in other words, there is no single video that will provide accurate predictions for all personality characteristics, but it is the response to the mix of different videos that allows for accurate prediction.
GAN-Based Facial Attractiveness Enhancement
Jun 04, 2020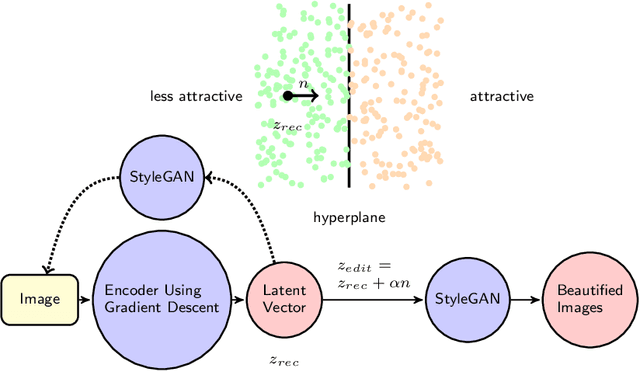
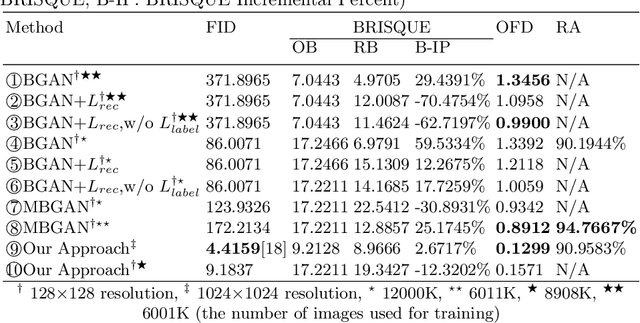

We propose a generative framework based on generative adversarial network (GAN) to enhance facial attractiveness while preserving facial identity and high-fidelity. Given a portrait image as input, having applied gradient descent to recover a latent vector that this generative framework can use to synthesize an image resemble to the input image, beauty semantic editing manipulation on the corresponding recovered latent vector based on InterFaceGAN enables this framework to achieve facial image beautification. This paper compared our system with Beholder-GAN and our proposed result-enhanced version of Beholder-GAN. It turns out that our framework obtained state-of-art attractiveness enhancement results. The code is available at https://github.com/zoezhou1999/BeautifyBasedOnGAN.
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 06, 2020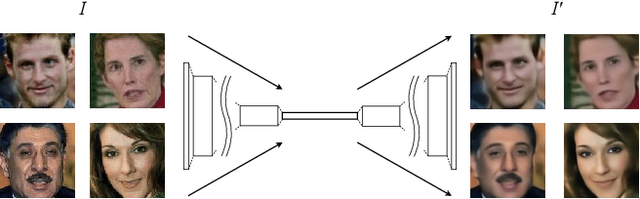
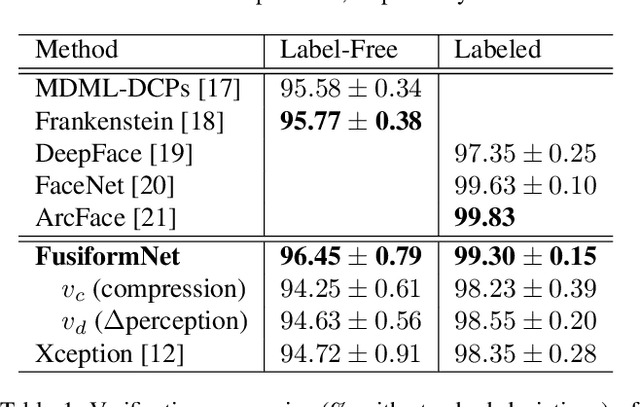
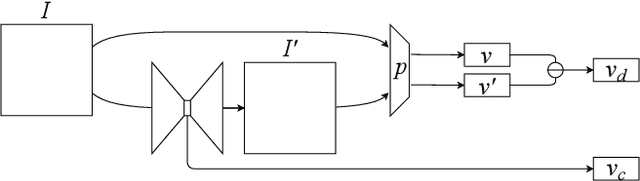
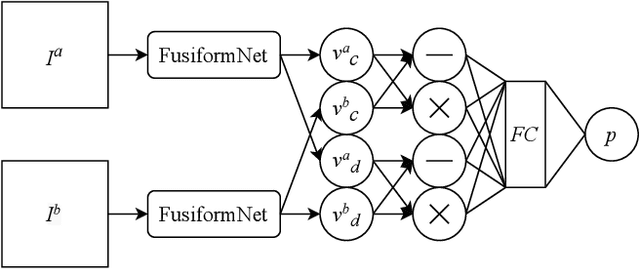
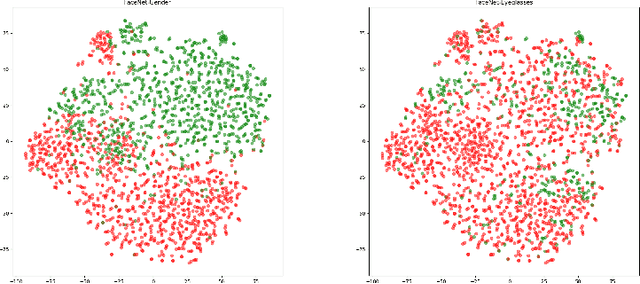
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of discriminative facial features. Tested on Image-Unrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pre-trained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
Domain Translation via Latent Space Mapping
Dec 06, 2022

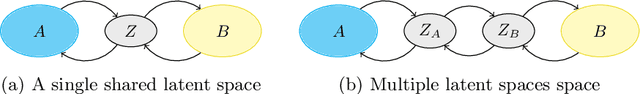

In this paper, we investigate the problem of multi-domain translation: given an element $a$ of domain $A$, we would like to generate a corresponding $b$ sample in another domain $B$, and vice versa. Acquiring supervision in multiple domains can be a tedious task, also we propose to learn this translation from one domain to another when supervision is available as a pair $(a,b)\sim A\times B$ and leveraging possible unpaired data when only $a\sim A$ or only $b\sim B$ is available. We introduce a new unified framework called Latent Space Mapping (\model) that exploits the manifold assumption in order to learn, from each domain, a latent space. Unlike existing approaches, we propose to further regularize each latent space using available domains by learning each dependency between pairs of domains. We evaluate our approach in three tasks performing i) synthetic dataset with image translation, ii) real-world task of semantic segmentation for medical images, and iii) real-world task of facial landmark detection.
Can a face tell us anything about an NBA prospect? -- A Deep Learning approach
Dec 13, 2022
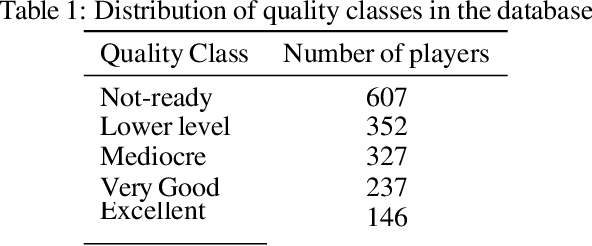
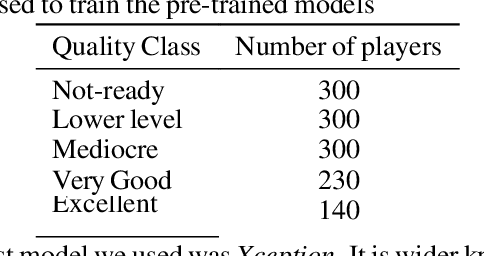
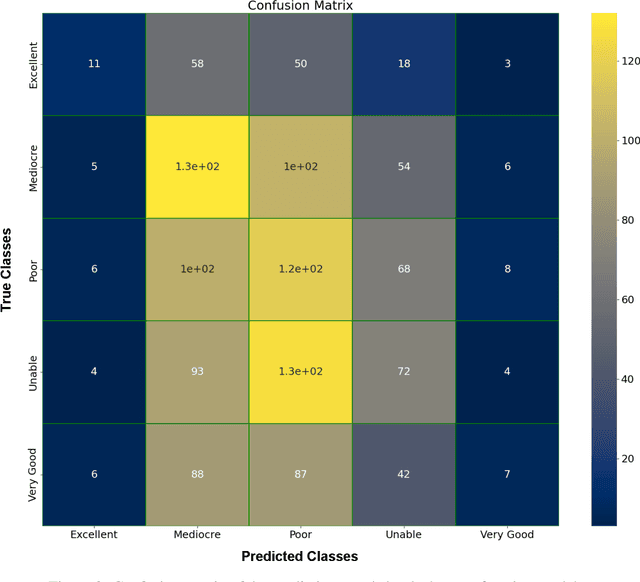
Statistical analysis and modeling is becoming increasingly popular for the world's leading organizations, especially for professional NBA teams. Sophisticated methods and models of sport talent evaluation have been created for this purpose. In this research, we present a different perspective from the dominant tactic of statistical data analysis. Based on a strategy that NBA teams have followed in the past, hiring human professionals, we deploy image analysis and Convolutional Neural Networks in an attempt to predict the career trajectory of newly drafted players from each draft class. We created a database consisting of about 1500 image data from players from every draft since 1990. We then divided the players into five different quality classes based on their expected NBA career. Next, we trained popular pre-trained image classification models in our data and conducted a series of tests in an attempt to create models that give reliable predictions of the rookie players' careers. The results of this study suggest that there is a potential correlation between facial characteristics and athletic talent, worth of further investigation.
Exploring Spatial-Temporal Features for Deepfake Detection and Localization
Oct 28, 2022

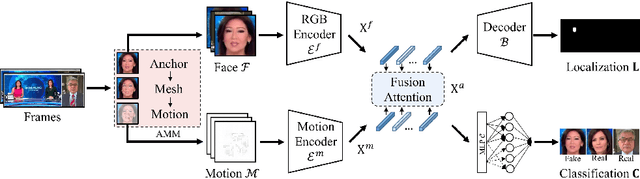
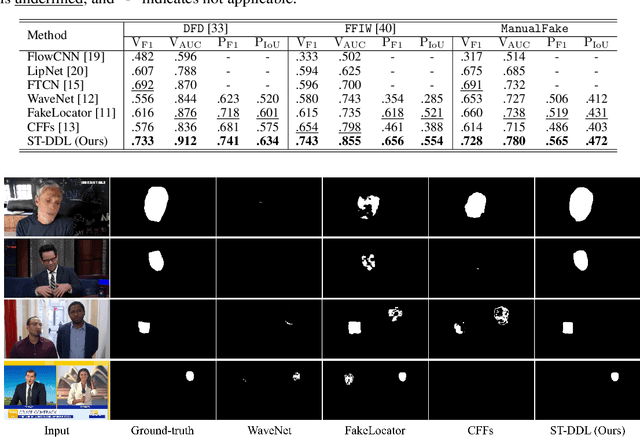
With the continuous research on Deepfake forensics, recent studies have attempted to provide the fine-grained localization of forgeries, in addition to the coarse classification at the video-level. However, the detection and localization performance of existing Deepfake forensic methods still have plenty of room for further improvement. In this work, we propose a Spatial-Temporal Deepfake Detection and Localization (ST-DDL) network that simultaneously explores spatial and temporal features for detecting and localizing forged regions. Specifically, we design a new Anchor-Mesh Motion (AMM) algorithm to extract temporal (motion) features by modeling the precise geometric movements of the facial micro-expression. Compared with traditional motion extraction methods (e.g., optical flow) designed to simulate large-moving objects, our proposed AMM could better capture the small-displacement facial features. The temporal features and the spatial features are then fused in a Fusion Attention (FA) module based on a Transformer architecture for the eventual Deepfake forensic tasks. The superiority of our ST-DDL network is verified by experimental comparisons with several state-of-the-art competitors, in terms of both video- and pixel-level detection and localization performance. Furthermore, to impel the future development of Deepfake forensics, we build a public forgery dataset consisting of 6000 videos, with many new features such as using widely-used commercial software (e.g., After Effects) for the production, providing online social networks transmitted versions, and splicing multi-source videos. The source code and dataset are available at https://github.com/HighwayWu/ST-DDL.
Self-Supervised Approach for Facial Movement Based Optical Flow
May 04, 2021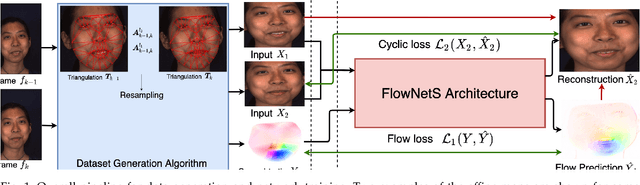
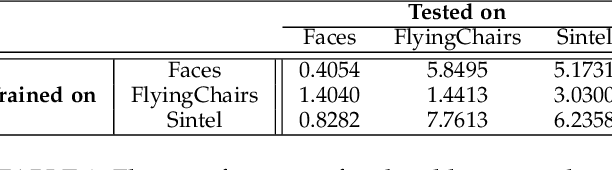

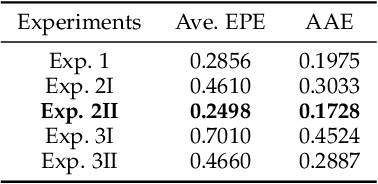
Computing optical flow is a fundamental problem in computer vision. However, deep learning-based optical flow techniques do not perform well for non-rigid movements such as those found in faces, primarily due to lack of the training data representing the fine facial motion. We hypothesize that learning optical flow on face motion data will improve the quality of predicted flow on faces. The aim of this work is threefold: (1) exploring self-supervised techniques to generate optical flow ground truth for face images; (2) computing baseline results on the effects of using face data to train Convolutional Neural Networks (CNN) for predicting optical flow; and (3) using the learned optical flow in micro-expression recognition to demonstrate its effectiveness. We generate optical flow ground truth using facial key-points in the BP4D-Spontaneous dataset. The generated optical flow is used to train the FlowNetS architecture to test its performance on the generated dataset. The performance of FlowNetS trained on face images surpassed that of other optical flow CNN architectures, demonstrating its usefulness. Our optical flow features are further compared with other methods using the STSTNet micro-expression classifier, and the results indicate that the optical flow obtained using this work has promising applications in facial expression analysis.