 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Your Face Mirrors Your Deepest Beliefs-Predicting Personality and Morals through Facial Emotion Recognition
Dec 23, 2021
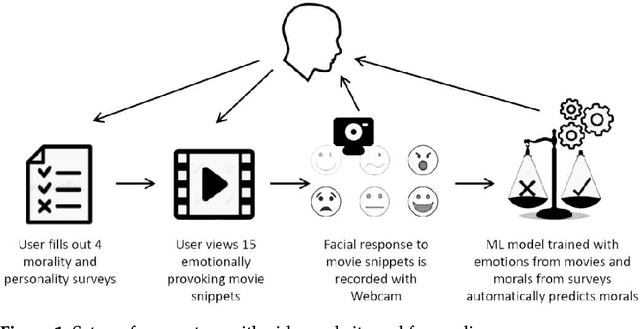
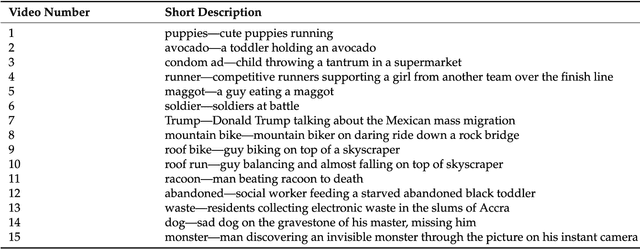
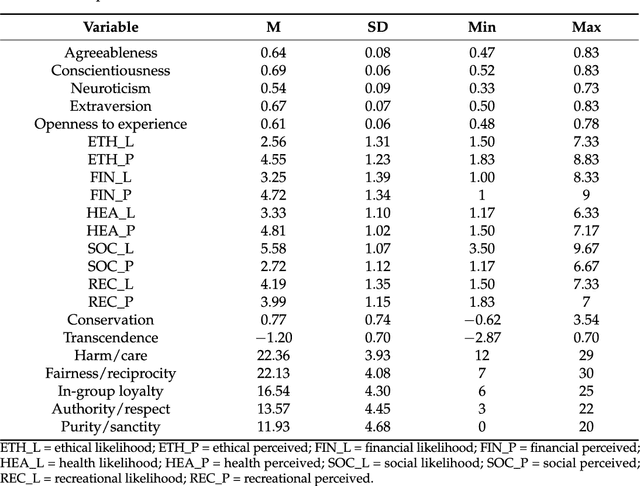
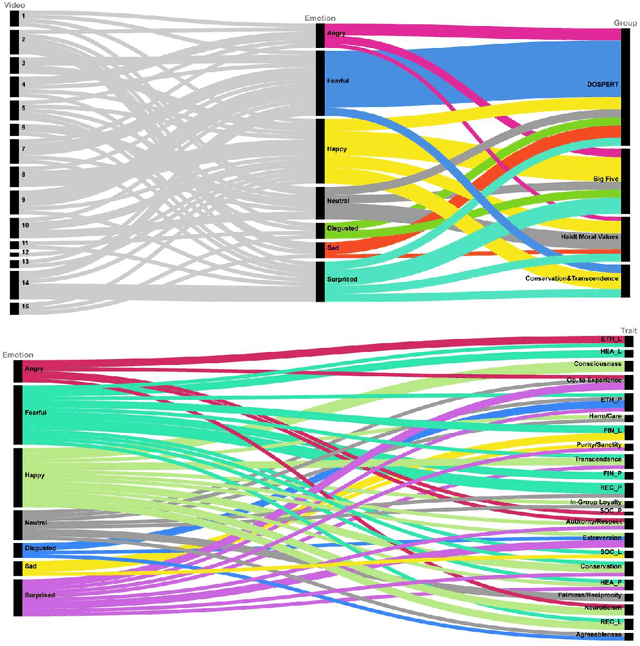
Can we really "read the mind in the eyes"? Moreover, can AI assist us in this task? This paper answers these two questions by introducing a machine learning system that predicts personality characteristics of individuals on the basis of their face. It does so by tracking the emotional response of the individual's face through facial emotion recognition (FER) while watching a series of 15 short videos of different genres. To calibrate the system, we invited 85 people to watch the videos, while their emotional responses were analyzed through their facial expression. At the same time, these individuals also took four well-validated surveys of personality characteristics and moral values: the revised NEO FFI personality inventory, the Haidt moral foundations test, the Schwartz personal value system, and the domain-specific risk-taking scale (DOSPERT). We found that personality characteristics and moral values of an individual can be predicted through their emotional response to the videos as shown in their face, with an accuracy of up to 86% using gradient-boosted trees. We also found that different personality characteristics are better predicted by different videos, in other words, there is no single video that will provide accurate predictions for all personality characteristics, but it is the response to the mix of different videos that allows for accurate prediction.
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 06, 2020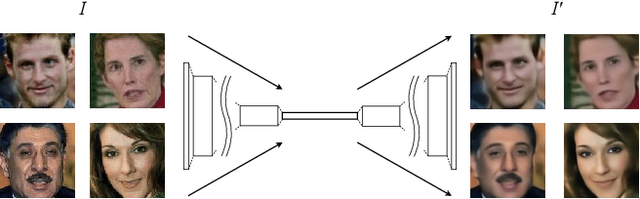
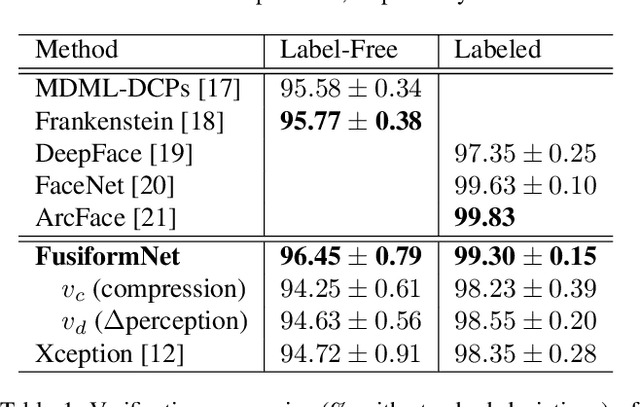
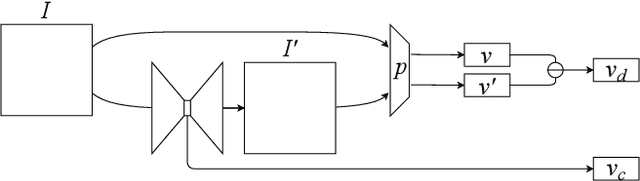
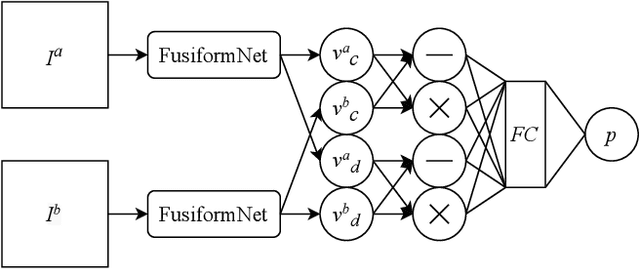
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of discriminative facial features. Tested on Image-Unrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pre-trained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
GAN-Based Facial Attractiveness Enhancement
Jun 04, 2020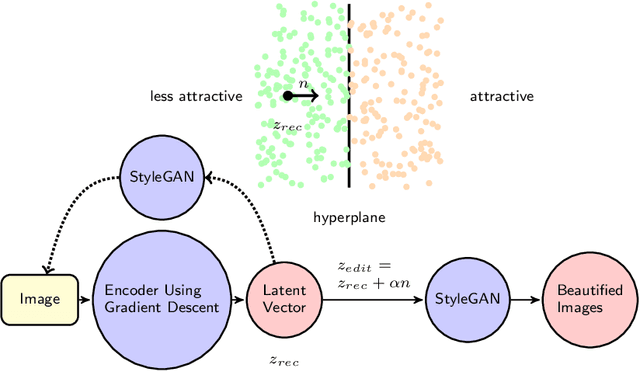
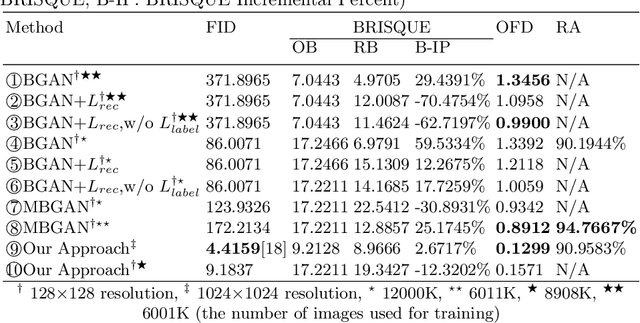

We propose a generative framework based on generative adversarial network (GAN) to enhance facial attractiveness while preserving facial identity and high-fidelity. Given a portrait image as input, having applied gradient descent to recover a latent vector that this generative framework can use to synthesize an image resemble to the input image, beauty semantic editing manipulation on the corresponding recovered latent vector based on InterFaceGAN enables this framework to achieve facial image beautification. This paper compared our system with Beholder-GAN and our proposed result-enhanced version of Beholder-GAN. It turns out that our framework obtained state-of-art attractiveness enhancement results. The code is available at https://github.com/zoezhou1999/BeautifyBasedOnGAN.
Self-Supervised Approach for Facial Movement Based Optical Flow
May 04, 2021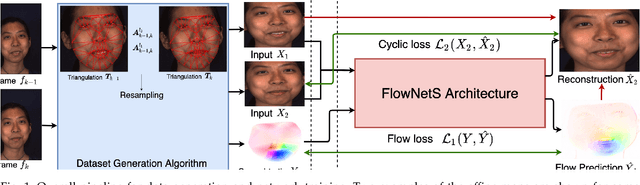
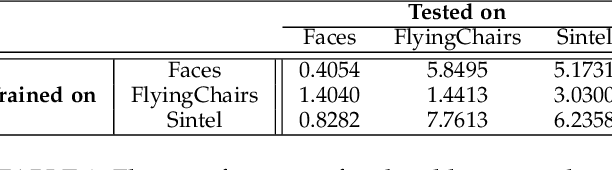

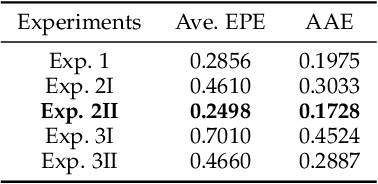
Computing optical flow is a fundamental problem in computer vision. However, deep learning-based optical flow techniques do not perform well for non-rigid movements such as those found in faces, primarily due to lack of the training data representing the fine facial motion. We hypothesize that learning optical flow on face motion data will improve the quality of predicted flow on faces. The aim of this work is threefold: (1) exploring self-supervised techniques to generate optical flow ground truth for face images; (2) computing baseline results on the effects of using face data to train Convolutional Neural Networks (CNN) for predicting optical flow; and (3) using the learned optical flow in micro-expression recognition to demonstrate its effectiveness. We generate optical flow ground truth using facial key-points in the BP4D-Spontaneous dataset. The generated optical flow is used to train the FlowNetS architecture to test its performance on the generated dataset. The performance of FlowNetS trained on face images surpassed that of other optical flow CNN architectures, demonstrating its usefulness. Our optical flow features are further compared with other methods using the STSTNet micro-expression classifier, and the results indicate that the optical flow obtained using this work has promising applications in facial expression analysis.
Recognizing Facial Expressions in the Wild using Multi-Architectural Representations based Ensemble Learning with Distillation
Jul 04, 2021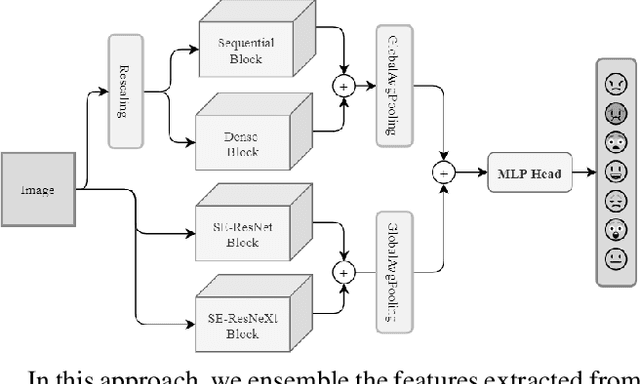
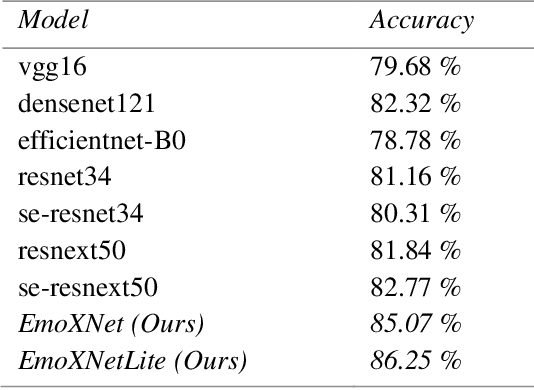
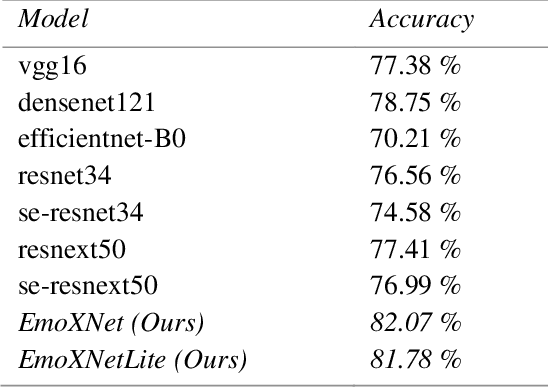

Facial expressions are the most common universal forms of body language. In the past few years, automatic facial expression recognition (FER) has been an active field of research. However, it is still a challenging task due to different uncertainties and complications. Nevertheless, efficiency and performance are yet essential aspects for building robust systems. In this work, we propose two models named EmoXNet and EmoXNetLite. EmoXNet is an ensemble learning technique for learning convoluted facial representations, whereas EmoXNetLite is a distillation technique for transferring the knowledge from our ensemble model to an efficient deep neural network using label-smoothen soft labels to detect expressions effectively in real-time. Both models attained better accuracy level in comparison to the models reported to date. The ensemble model (EmoXNet) attained 85.07% test accuracy on FER-2013 with FER+ annotations and 86.25% test accuracy on Real-world Affective Faces Database (RAF-DB). Whereas, the distilled model (EmoXNetLite) attained 82.07% test accuracy on FER-2013 with FER+ annotations and 81.78% test accuracy on RAF-DB. Results show that our models seem to generalize well on new data and are learned to focus on relevant facial representations for expressions recognition.
Part-based Face Recognition with Vision Transformers
Nov 30, 2022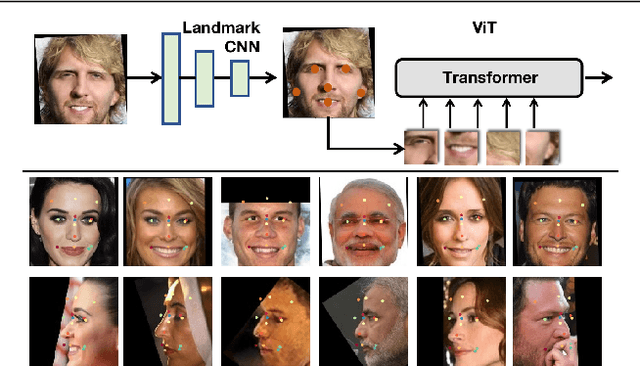
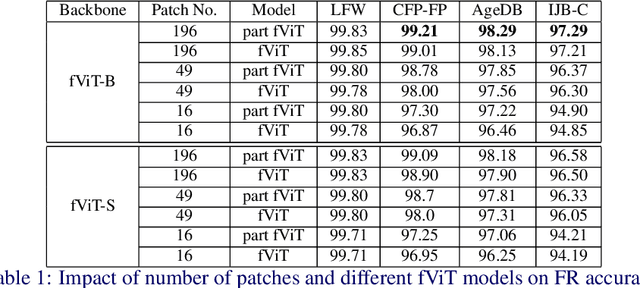
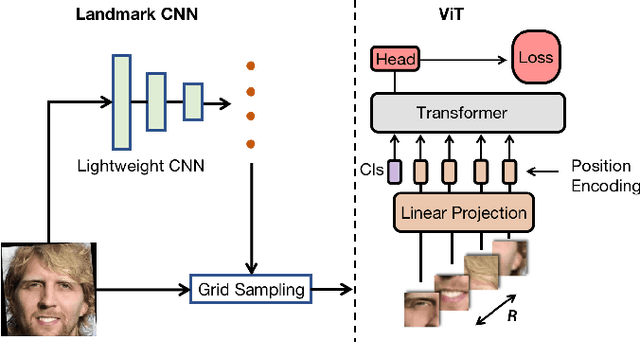
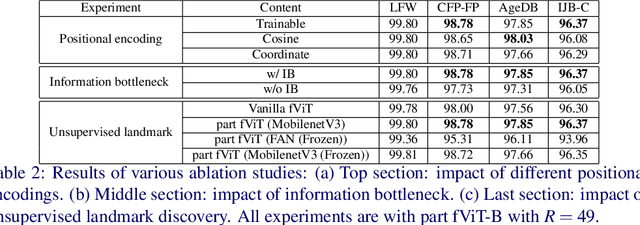
Holistic methods using CNNs and margin-based losses have dominated research on face recognition. In this work, we depart from this setting in two ways: (a) we employ the Vision Transformer as an architecture for training a very strong baseline for face recognition, simply called fViT, which already surpasses most state-of-the-art face recognition methods. (b) Secondly, we capitalize on the Transformer's inherent property to process information (visual tokens) extracted from irregular grids to devise a pipeline for face recognition which is reminiscent of part-based face recognition methods. Our pipeline, called part fViT, simply comprises a lightweight network to predict the coordinates of facial landmarks followed by the Vision Transformer operating on patches extracted from the predicted landmarks, and it is trained end-to-end with no landmark supervision. By learning to extract discriminative patches, our part-based Transformer further boosts the accuracy of our Vision Transformer baseline achieving state-of-the-art accuracy on several face recognition benchmarks.
Quasi Non-Negative Quaternion Matrix Factorization with Application to Color Face Recognition
Nov 30, 2022
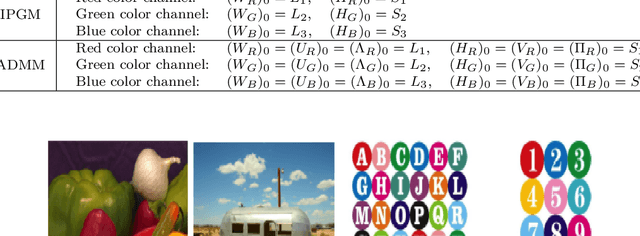


To address the non-negativity dropout problem of quaternion models, a novel quasi non-negative quaternion matrix factorization (QNQMF) model is presented for color image processing. To implement QNQMF, the quaternion projected gradient algorithm and the quaternion alternating direction method of multipliers are proposed via formulating QNQMF as the non-convex constraint quaternion optimization problems. Some properties of the proposed algorithms are studied. The numerical experiments on the color image reconstruction show that these algorithms encoded on the quaternion perform better than these algorithms encoded on the red, green and blue channels. Furthermore, we apply the proposed algorithms to the color face recognition. Numerical results indicate that the accuracy rate of face recognition on the quaternion model is better than on the red, green and blue channels of color image as well as single channel of gray level images for the same data, when large facial expressions and shooting angle variations are presented.
StepNet: Spatial-temporal Part-aware Network for Sign Language Recognition
Dec 25, 2022
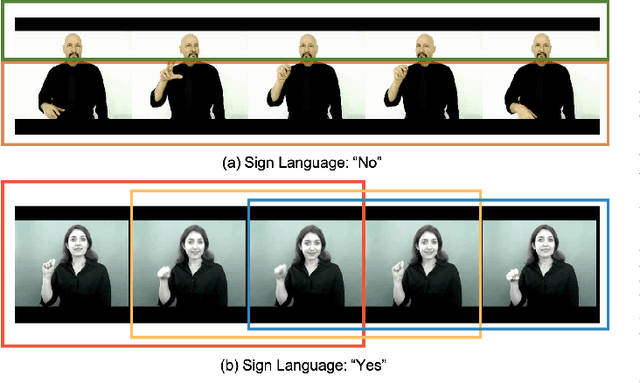
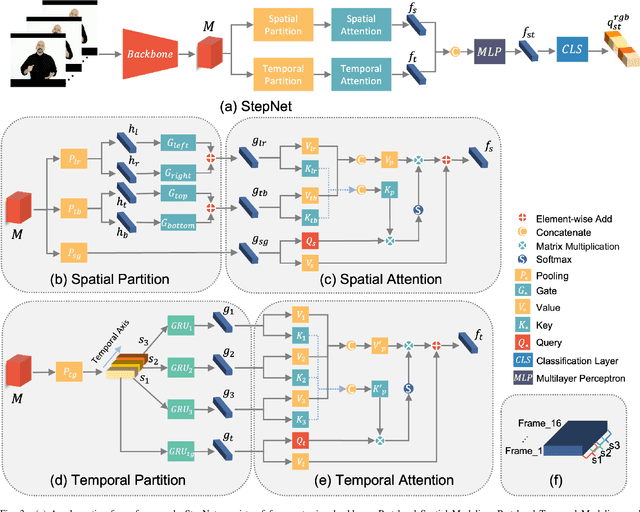
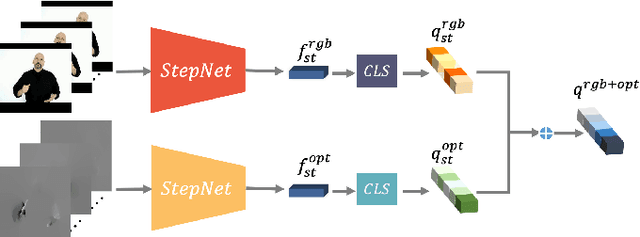
Sign language recognition (SLR) aims to overcome the communication barrier for the people with deafness or the people with hard hearing. Most existing approaches can be typically divided into two lines, i.e., Skeleton-based and RGB-based methods, but both the two lines of methods have their limitations. RGB-based approaches usually overlook the fine-grained hand structure, while Skeleton-based methods do not take the facial expression into account. In attempts to address both limitations, we propose a new framework named Spatial-temporal Part-aware network (StepNet), based on RGB parts. As the name implies, StepNet consists of two modules: Part-level Spatial Modeling and Part-level Temporal Modeling. Particularly, without using any keypoint-level annotations, Part-level Spatial Modeling implicitly captures the appearance-based properties, such as hands and faces, in the feature space. On the other hand, Part-level Temporal Modeling captures the pertinent properties over time by implicitly mining the long-short term context. Extensive experiments show that our StepNet, thanks to Spatial-temporal modules, achieves competitive Top-1 Per-instance accuracy on three widely-used SLR benchmarks, i.e., 56.89% on WLASL, 77.2% on NMFs-CSL, and 77.1% on BOBSL. Moreover, the proposed method is compatible with the optical flow input, and can yield higher performance if fused. We hope that this work can serve as a preliminary step for the people with deafness.
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 10, 2021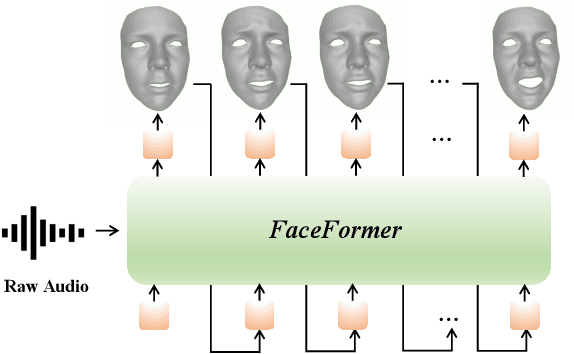
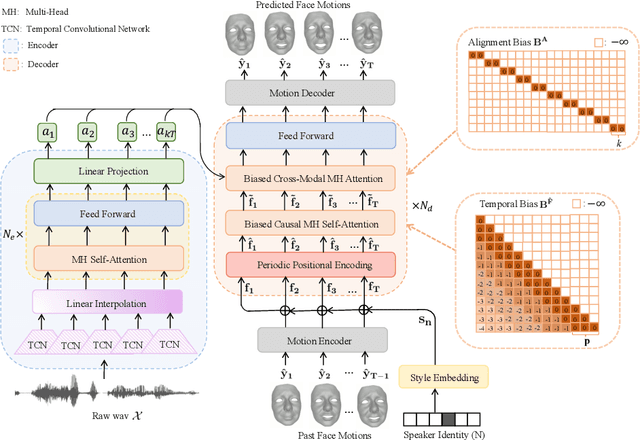

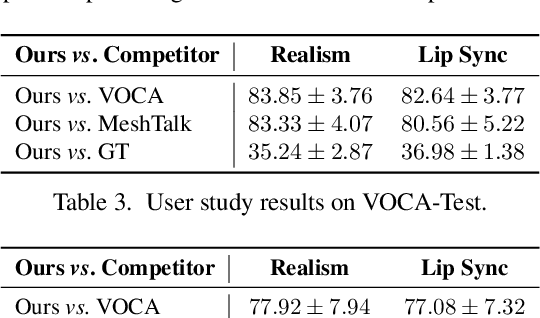
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. The code will be made available.