 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Exploring Workplace Behaviors through Speaking Patterns using Large-scale Multimodal Wearable Recordings: A Study of Healthcare Providers
Dec 18, 2022
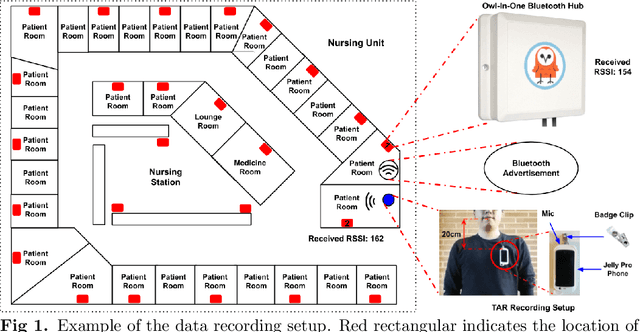
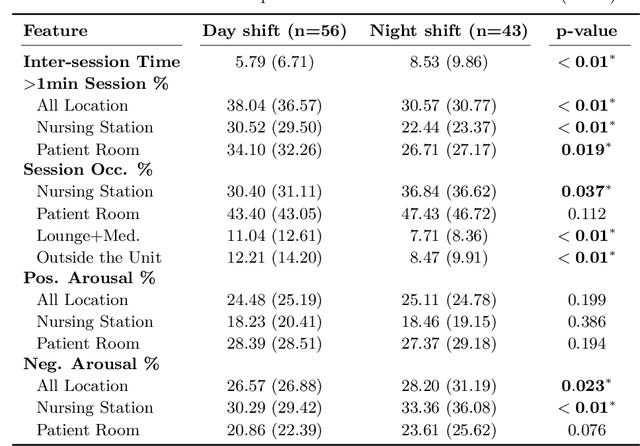

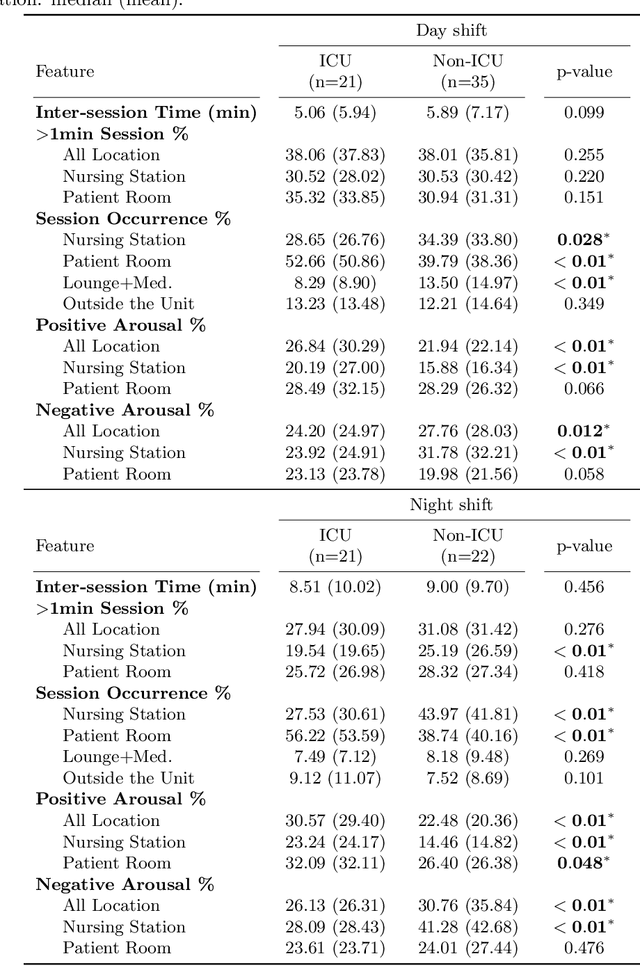
Interpersonal spoken communication is central to human interaction and the exchange of information. Such interactive processes involve not only speech and spoken language but also non-verbal cues such as hand gestures, facial expressions, and nonverbal vocalization, that are used to express feelings and provide feedback. These multimodal communication signals carry a variety of information about the people: traits like gender and age as well as about physical and psychological states and behavior. This work uses wearable multimodal sensors to investigate interpersonal communication behaviors focusing on speaking patterns among healthcare providers with a focus on nurses. We analyze longitudinal data collected from $99$ nurses in a large hospital setting over ten weeks. The results indicate that speaking pattern differences across shift schedules and working units. Moreover, results show that speaking patterns combined with physiological measures can be used to predict affect measures and life satisfaction scores. The implementation of this work can be accessed at https://github.com/usc-sail/tiles-audio-arousal.
Mask-FPAN: Semi-Supervised Face Parsing in the Wild With De-Occlusion and UV GAN
Dec 18, 2022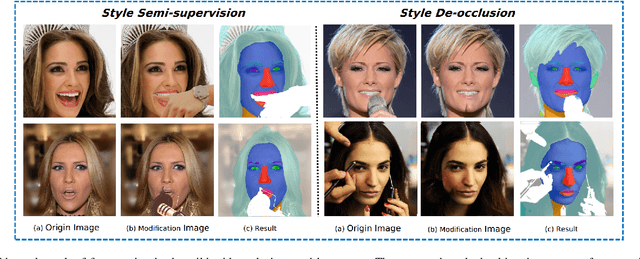
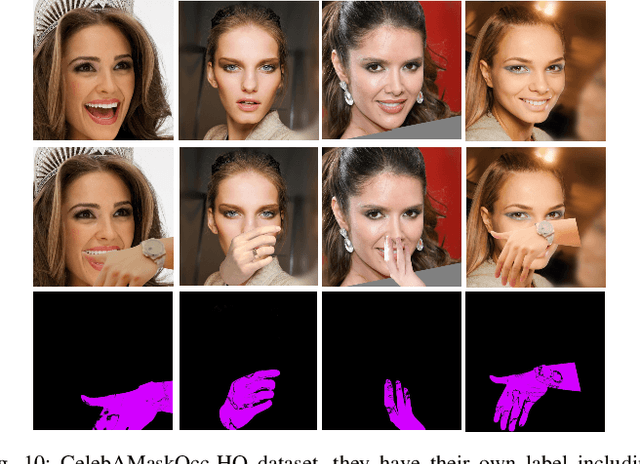


Fine-grained semantic segmentation of a person's face and head, including facial parts and head components, has progressed a great deal in recent years. However, it remains a challenging task, whereby considering ambiguous occlusions and large pose variations are particularly difficult. To overcome these difficulties, we propose a novel framework termed Mask-FPAN. It uses a de-occlusion module that learns to parse occluded faces in a semi-supervised way. In particular, face landmark localization, face occlusionstimations, and detected head poses are taken into account. A 3D morphable face model combined with the UV GAN improves the robustness of 2D face parsing. In addition, we introduce two new datasets named FaceOccMask-HQ and CelebAMaskOcc-HQ for face paring work. The proposed Mask-FPAN framework addresses the face parsing problem in the wild and shows significant performance improvements with MIOU from 0.7353 to 0.9013 compared to the state-of-the-art on challenging face datasets.
Human Expression Recognition using Facial Shape Based Fourier Descriptors Fusion
Dec 28, 2020Dynamic facial expression recognition has many useful applications in social networks, multimedia content analysis, security systems and others. This challenging process must be done under recurrent problems of image illumination and low resolution which changes at partial occlusions. This paper aims to produce a new facial expression recognition method based on the changes in the facial muscles. The geometric features are used to specify the facial regions i.e., mouth, eyes, and nose. The generic Fourier shape descriptor in conjunction with elliptic Fourier shape descriptor is used as an attribute to represent different emotions under frequency spectrum features. Afterwards a multi-class support vector machine is applied for classification of seven human expression. The statistical analysis showed our approach obtained overall competent recognition using 5-fold cross validation with high accuracy on well-known facial expression dataset.
Detecting and Recovering Sequential DeepFake Manipulation
Jul 05, 2022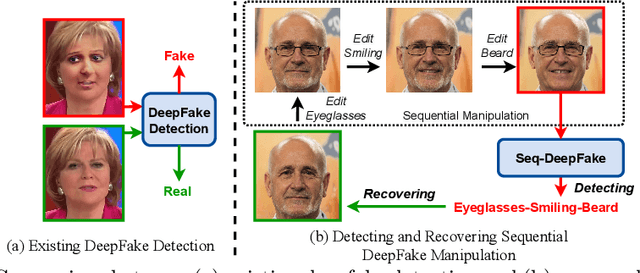

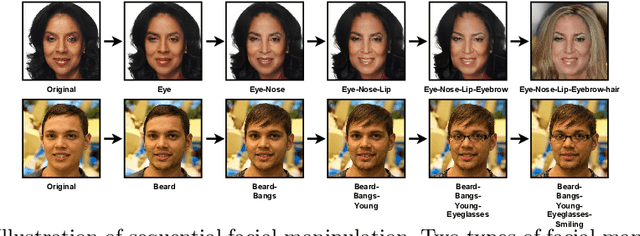

Since photorealistic faces can be readily generated by facial manipulation technologies nowadays, potential malicious abuse of these technologies has drawn great concerns. Numerous deepfake detection methods are thus proposed. However, existing methods only focus on detecting one-step facial manipulation. As the emergence of easy-accessible facial editing applications, people can easily manipulate facial components using multi-step operations in a sequential manner. This new threat requires us to detect a sequence of facial manipulations, which is vital for both detecting deepfake media and recovering original faces afterwards. Motivated by this observation, we emphasize the need and propose a novel research problem called Detecting Sequential DeepFake Manipulation (Seq-DeepFake). Unlike the existing deepfake detection task only demanding a binary label prediction, detecting Seq-DeepFake manipulation requires correctly predicting a sequential vector of facial manipulation operations. To support a large-scale investigation, we construct the first Seq-DeepFake dataset, where face images are manipulated sequentially with corresponding annotations of sequential facial manipulation vectors. Based on this new dataset, we cast detecting Seq-DeepFake manipulation as a specific image-to-sequence (e.g. image captioning) task and propose a concise yet effective Seq-DeepFake Transformer (SeqFakeFormer). Moreover, we build a comprehensive benchmark and set up rigorous evaluation protocols and metrics for this new research problem. Extensive experiments demonstrate the effectiveness of SeqFakeFormer. Several valuable observations are also revealed to facilitate future research in broader deepfake detection problems.
Towards Real-World Blind Face Restoration with Generative Facial Prior
Jan 11, 2021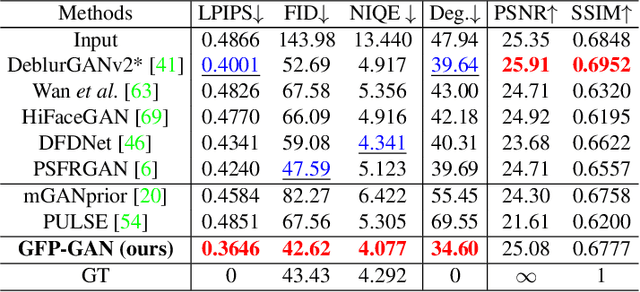
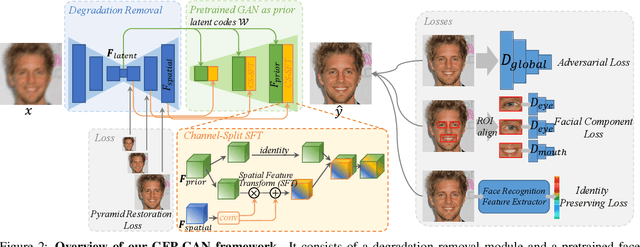

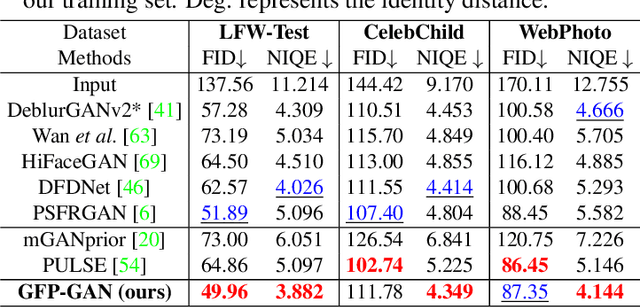
Blind face restoration usually relies on facial priors, such as facial geometry prior or reference prior, to restore realistic and faithful details. However, very low-quality inputs cannot offer accurate geometric prior while high-quality references are inaccessible, limiting the applicability in real-world scenarios. In this work, we propose GFP-GAN that leverages rich and diverse priors encapsulated in a pretrained face GAN for blind face restoration. This Generative Facial Prior (GFP) is incorporated into the face restoration process via novel channel-split spatial feature transform layers, which allow our method to achieve a good balance of realness and fidelity. Thanks to the powerful generative facial prior and delicate designs, our GFP-GAN could jointly restore facial details and enhance colors with just a single forward pass, while GAN inversion methods require expensive image-specific optimization at inference. Extensive experiments show that our method achieves superior performance to prior art on both synthetic and real-world datasets.
Facial De-occlusion Network for Virtual Telepresence Systems
Oct 23, 2022
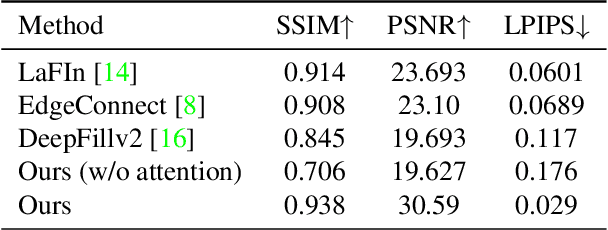
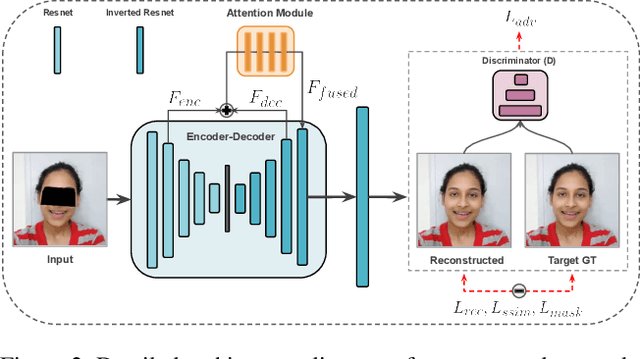
To see what is not in the image is one of the broader missions of computer vision. Technology to inpaint images has made significant progress with the coming of deep learning. This paper proposes a method to tackle occlusion specific to human faces. Virtual presence is a promising direction in communication and recreation for the future. However, Virtual Reality (VR) headsets occlude a significant portion of the face, hindering the photo-realistic appearance of the face in the virtual world. State-of-the-art image inpainting methods for de-occluding the eye region does not give usable results. To this end, we propose a working solution that gives usable results to tackle this problem enabling the use of the real-time photo-realistic de-occluded face of the user in VR settings.
Segmentation-Reconstruction-Guided Facial Image De-occlusion
Dec 15, 2021
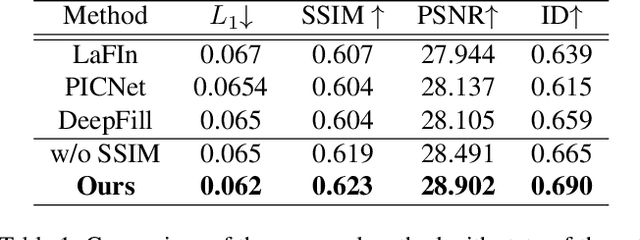
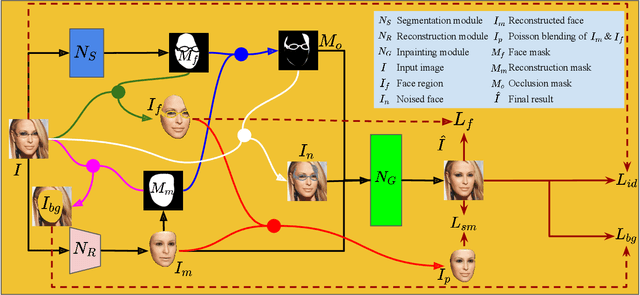
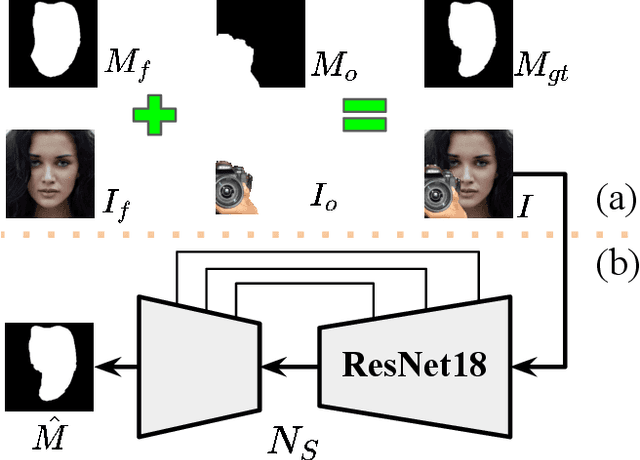
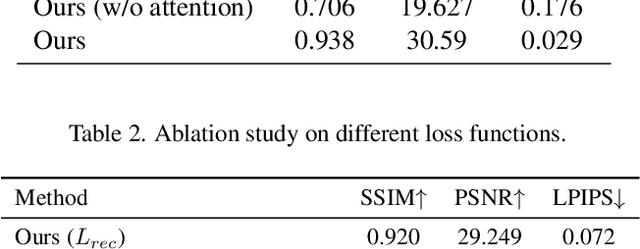
Occlusions are very common in face images in the wild, leading to the degraded performance of face-related tasks. Although much effort has been devoted to removing occlusions from face images, the varying shapes and textures of occlusions still challenge the robustness of current methods. As a result, current methods either rely on manual occlusion masks or only apply to specific occlusions. This paper proposes a novel face de-occlusion model based on face segmentation and 3D face reconstruction, which automatically removes all kinds of face occlusions with even blurred boundaries,e.g., hairs. The proposed model consists of a 3D face reconstruction module, a face segmentation module, and an image generation module. With the face prior and the occlusion mask predicted by the first two, respectively, the image generation module can faithfully recover the missing facial textures. To supervise the training, we further build a large occlusion dataset, with both manually labeled and synthetic occlusions. Qualitative and quantitative results demonstrate the effectiveness and robustness of the proposed method.
$S^2$-Flow: Joint Semantic and Style Editing of Facial Images
Nov 22, 2022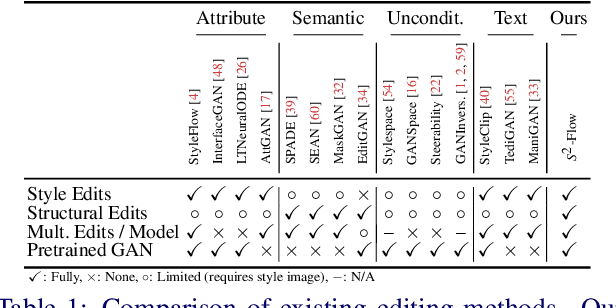

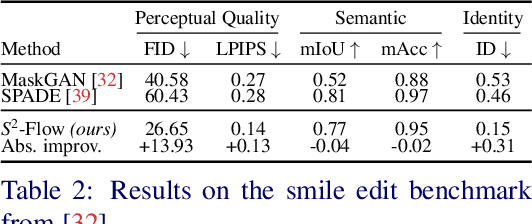
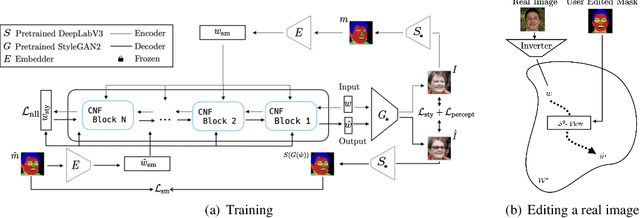
The high-quality images yielded by generative adversarial networks (GANs) have motivated investigations into their application for image editing. However, GANs are often limited in the control they provide for performing specific edits. One of the principal challenges is the entangled latent space of GANs, which is not directly suitable for performing independent and detailed edits. Recent editing methods allow for either controlled style edits or controlled semantic edits. In addition, methods that use semantic masks to edit images have difficulty preserving the identity and are unable to perform controlled style edits. We propose a method to disentangle a GAN$\text{'}$s latent space into semantic and style spaces, enabling controlled semantic and style edits for face images independently within the same framework. To achieve this, we design an encoder-decoder based network architecture ($S^2$-Flow), which incorporates two proposed inductive biases. We show the suitability of $S^2$-Flow quantitatively and qualitatively by performing various semantic and style edits.
Facial Manipulation Detection Based on the Color Distribution Analysis in Edge Region
Feb 02, 2021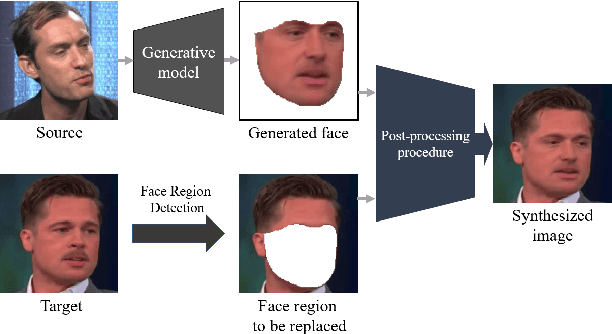
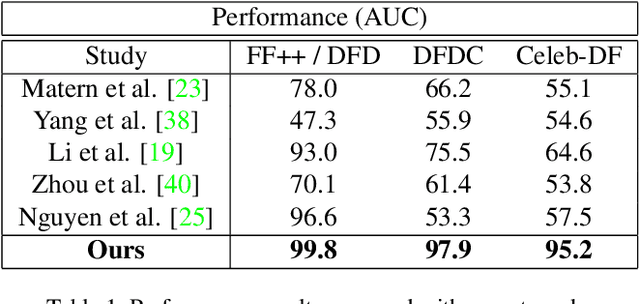

In this work, we present a generalized and robust facial manipulation detection method based on color distribution analysis of the vertical region of edge in a manipulated image. Most of the contemporary facial manipulation method involves pixel correction procedures for reducing awkwardness of pixel value differences along the facial boundary in a synthesized image. For this procedure, there are distinctive differences in the facial boundary between face manipulated image and unforged natural image. Also, in the forged image, there should be distinctive and unnatural features in the gap distribution between facial boundary and background edge region because it tends to damage the natural effect of lighting. We design the neural network for detecting face-manipulated image with these distinctive features in facial boundary and background edge. Our extensive experiments show that our method outperforms other existing face manipulation detection methods on detecting synthesized face image in various datasets regardless of whether it has participated in training.
Deep Structured Prediction for Facial Landmark Detection
Oct 18, 2020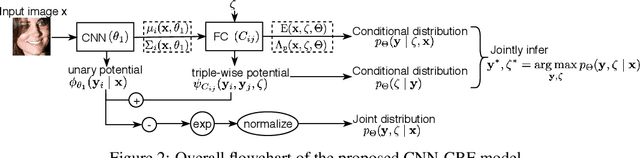
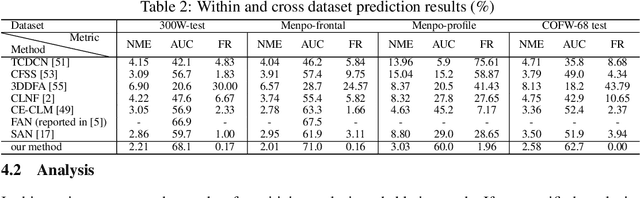

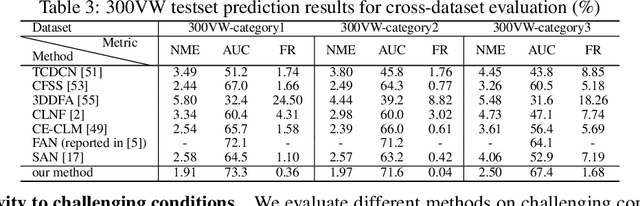
Existing deep learning based facial landmark detection methods have achieved excellent performance. These methods, however, do not explicitly embed the structural dependencies among landmark points. They hence cannot preserve the geometric relationships between landmark points or generalize well to challenging conditions or unseen data. This paper proposes a method for deep structured facial landmark detection based on combining a deep Convolutional Network with a Conditional Random Field. We demonstrate its superior performance to existing state-of-the-art techniques in facial landmark detection, especially a better generalization ability on challenging datasets that include large pose and occlusion.