 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 16, 2021
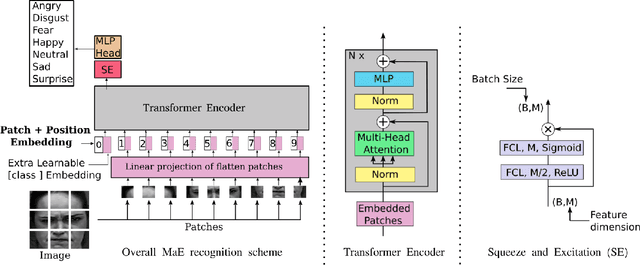
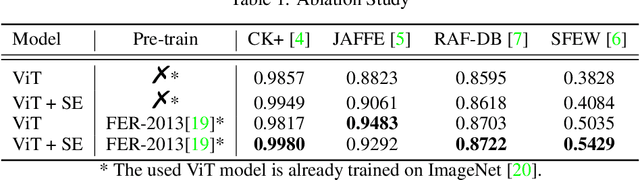
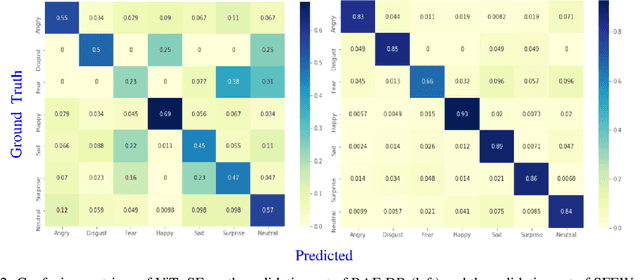
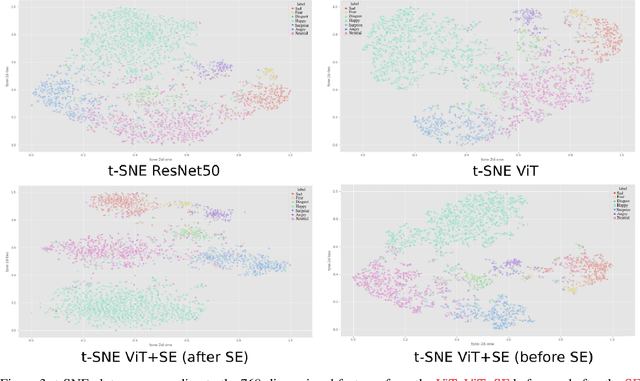
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.
edBB-Demo: Biometrics and Behavior Analysis for Online Educational Platforms
Dec 05, 2022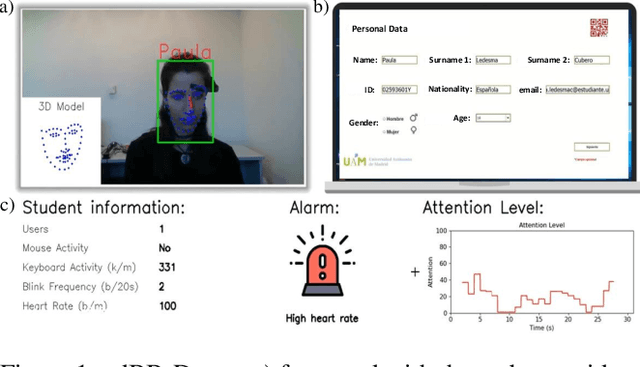
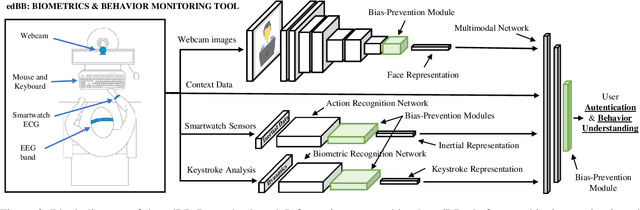
We present edBB-Demo, a demonstrator of an AI-powered research platform for student monitoring in remote education. The edBB platform aims to study the challenges associated to user recognition and behavior understanding in digital platforms. This platform has been developed for data collection, acquiring signals from a variety of sensors including keyboard, mouse, webcam, microphone, smartwatch, and an Electroencephalography band. The information captured from the sensors during the student sessions is modelled in a multimodal learning framework. The demonstrator includes: i) Biometric user authentication in an unsupervised environment; ii) Human action recognition based on remote video analysis; iii) Heart rate estimation from webcam video; and iv) Attention level estimation from facial expression analysis.
FaceFormer: Scale-aware Blind Face Restoration with Transformers
Jul 20, 2022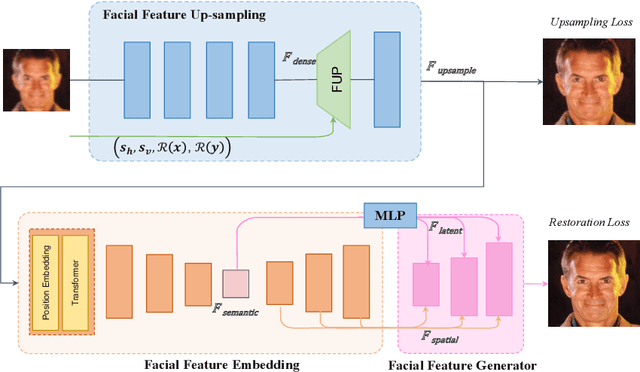
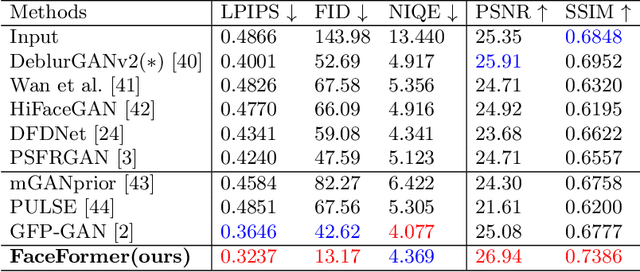
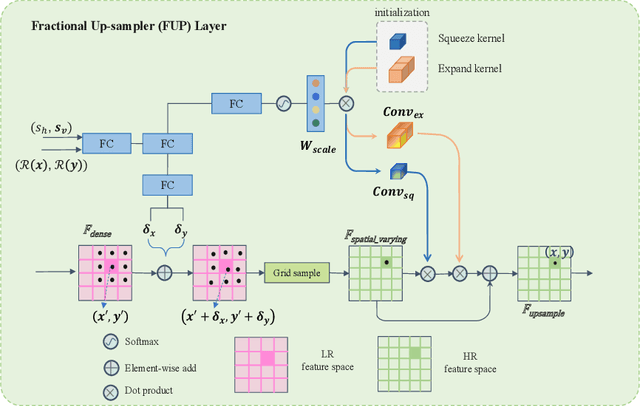
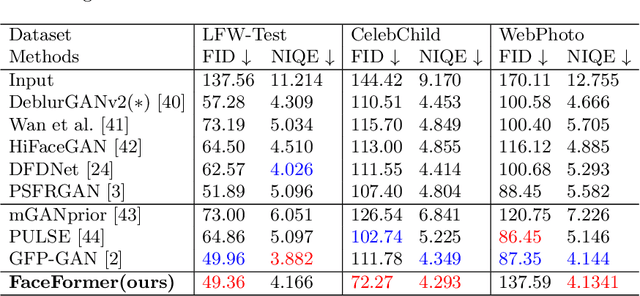
Blind face restoration usually encounters with diverse scale face inputs, especially in the real world. However, most of the current works support specific scale faces, which limits its application ability in real-world scenarios. In this work, we propose a novel scale-aware blind face restoration framework, named FaceFormer, which formulates facial feature restoration as scale-aware transformation. The proposed Facial Feature Up-sampling (FFUP) module dynamically generates upsampling filters based on the original scale-factor priors, which facilitate our network to adapt to arbitrary face scales. Moreover, we further propose the facial feature embedding (FFE) module which leverages transformer to hierarchically extract diversity and robustness of facial latent. Thus, our FaceFormer achieves fidelity and robustness restored faces, which possess realistic and symmetrical details of facial components. Extensive experiments demonstrate that our proposed method trained with synthetic dataset generalizes better to a natural low quality images than current state-of-the-arts.
FP-Age: Leveraging Face Parsing Attention for Facial Age Estimation in the Wild
Jun 21, 2021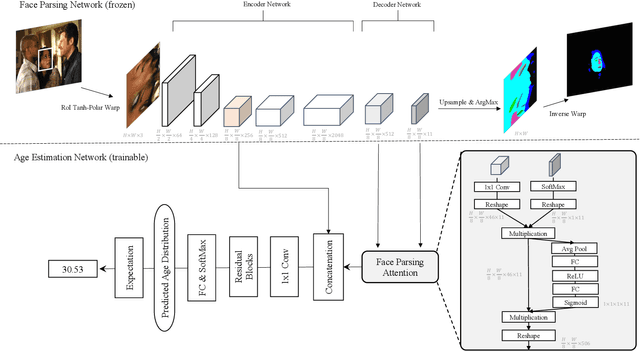

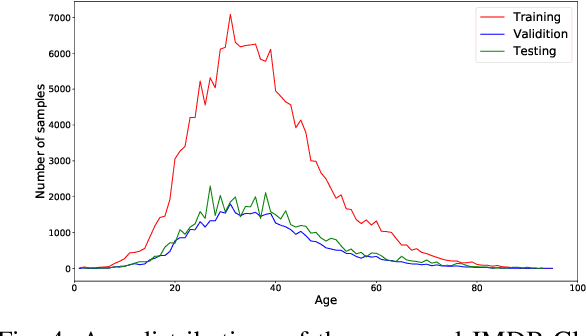
Image-based age estimation aims to predict a person's age from facial images. It is used in a variety of real-world applications. Although end-to-end deep models have achieved impressive results for age estimation on benchmark datasets, their performance in-the-wild still leaves much room for improvement due to the challenges caused by large variations in head pose, facial expressions, and occlusions. To address this issue, we propose a simple yet effective method to explicitly incorporate facial semantics into age estimation, so that the model would learn to correctly focus on the most informative facial components from unaligned facial images regardless of head pose and non-rigid deformation. To this end, we design a face parsing-based network to learn semantic information at different scales and a novel face parsing attention module to leverage these semantic features for age estimation. To evaluate our method on in-the-wild data, we also introduce a new challenging large-scale benchmark called IMDB-Clean. This dataset is created by semi-automatically cleaning the noisy IMDB-WIKI dataset using a constrained clustering method. Through comprehensive experiment on IMDB-Clean and other benchmark datasets, under both intra-dataset and cross-dataset evaluation protocols, we show that our method consistently outperforms all existing age estimation methods and achieves a new state-of-the-art performance. To the best of our knowledge, our work presents the first attempt of leveraging face parsing attention to achieve semantic-aware age estimation, which may be inspiring to other high level facial analysis tasks.
Magnifying Subtle Facial Motions for Effective 4D Expression Recognition
May 05, 2021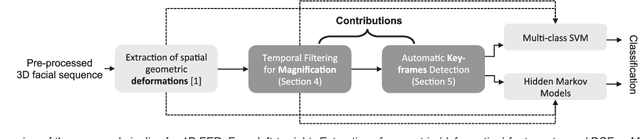

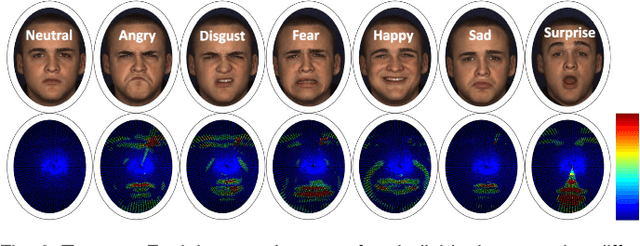
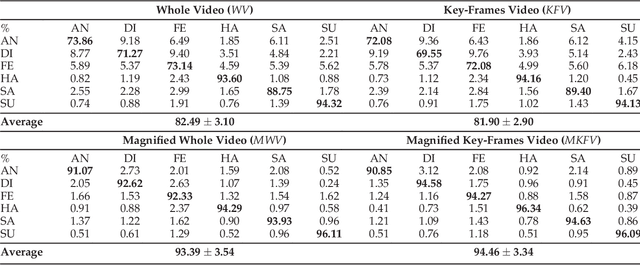
In this paper, an effective pipeline to automatic 4D Facial Expression Recognition (4D FER) is proposed. It combines two growing but disparate ideas in Computer Vision -- computing the spatial facial deformations using tools from Riemannian geometry and magnifying them using temporal filtering. The flow of 3D faces is first analyzed to capture the spatial deformations based on the recently-developed Riemannian approach, where registration and comparison of neighboring 3D faces are led jointly. Then, the obtained temporal evolution of these deformations are fed into a magnification method in order to amplify the facial activities over the time. The latter, main contribution of this paper, allows revealing subtle (hidden) deformations which enhance the emotion classification performance. We evaluated our approach on BU-4DFE dataset, the state-of-art 94.18% average performance and an improvement that exceeds 10% in classification accuracy, after magnifying extracted geometric features (deformations), are achieved.
Evaluating Temporal Patterns in Applied Infant Affect Recognition
Sep 07, 2022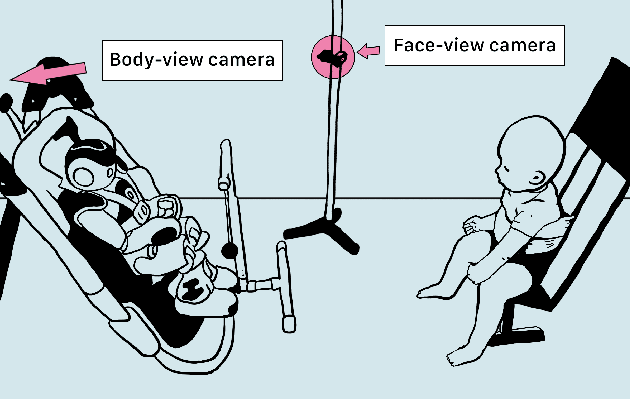
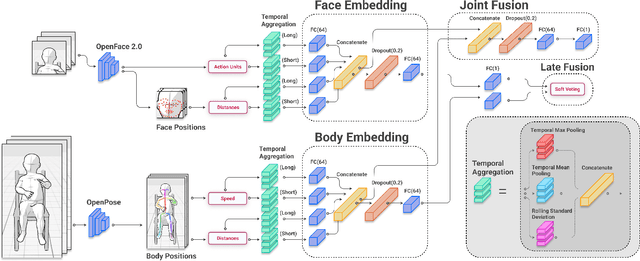
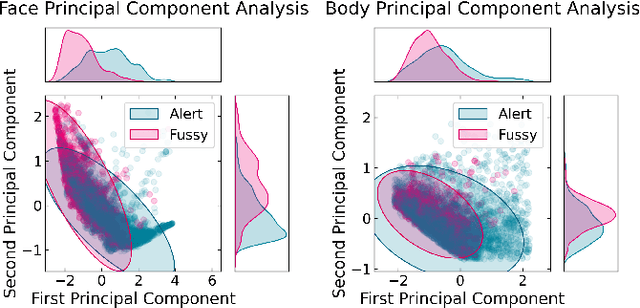
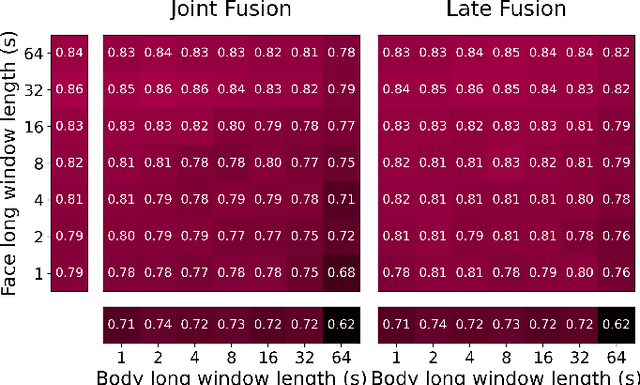
Agents must monitor their partners' affective states continuously in order to understand and engage in social interactions. However, methods for evaluating affect recognition do not account for changes in classification performance that may occur during occlusions or transitions between affective states. This paper addresses temporal patterns in affect classification performance in the context of an infant-robot interaction, where infants' affective states contribute to their ability to participate in a therapeutic leg movement activity. To support robustness to facial occlusions in video recordings, we trained infant affect recognition classifiers using both facial and body features. Next, we conducted an in-depth analysis of our best-performing models to evaluate how performance changed over time as the models encountered missing data and changing infant affect. During time windows when features were extracted with high confidence, a unimodal model trained on facial features achieved the same optimal performance as multimodal models trained on both facial and body features. However, multimodal models outperformed unimodal models when evaluated on the entire dataset. Additionally, model performance was weakest when predicting an affective state transition and improved after multiple predictions of the same affective state. These findings emphasize the benefits of incorporating body features in continuous affect recognition for infants. Our work highlights the importance of evaluating variability in model performance both over time and in the presence of missing data when applying affect recognition to social interactions.
Skeletal Video Anomaly Detection using Deep Learning: Survey, Challenges and Future Directions
Dec 31, 2022The existing methods for video anomaly detection mostly utilize videos containing identifiable facial and appearance-based features. The use of videos with identifiable faces raises privacy concerns, especially when used in a hospital or community-based setting. Appearance-based features can also be sensitive to pixel-based noise, straining the anomaly detection methods to model the changes in the background and making it difficult to focus on the actions of humans in the foreground. Structural information in the form of skeletons describing the human motion in the videos is privacy-protecting and can overcome some of the problems posed by appearance-based features. In this paper, we present a survey of privacy-protecting deep learning anomaly detection methods using skeletons extracted from videos. We present a novel taxonomy of algorithms based on the various learning approaches. We conclude that skeleton-based approaches for anomaly detection can be a plausible privacy-protecting alternative for video anomaly detection. Lastly, we identify major open research questions and provide guidelines to address them.
Facial Expressions as a Vulnerability in Face Recognition
Nov 17, 2020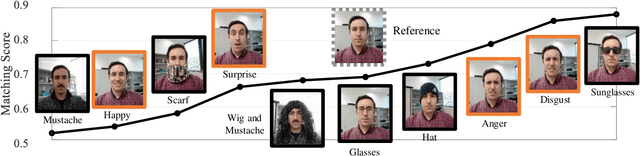
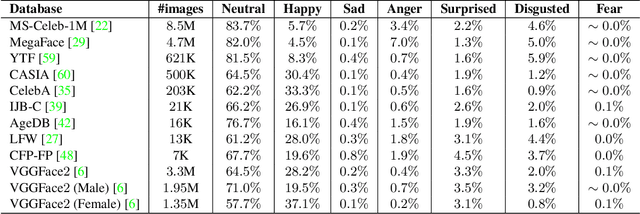

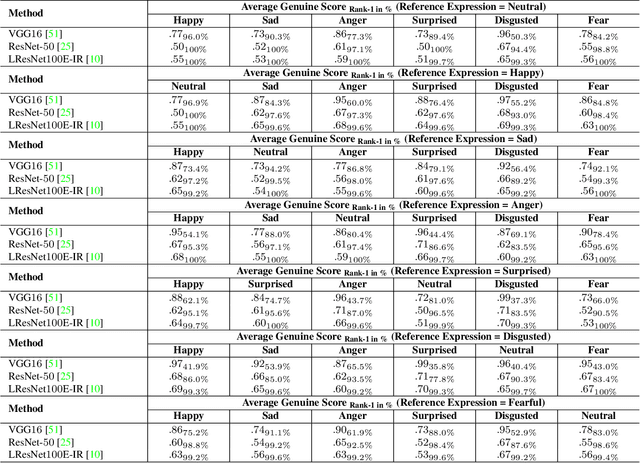
This work explores facial expression bias as a security vulnerability of face recognition systems. Face recognition technology has experienced great advances during the last decades. However, despite the great performance achieved by state of the art face recognition systems, the algorithms are still sensitive to a large range of covariates. This work presents a comprehensive analysis of how facial expression bias impacts the performance of face recognition technologies. Our study analyzes: i) facial expression biases in the most popular face recognition databases; and ii) the impact of facial expression in face recognition performances. Our experimental framework includes four face detectors, three face recognition models, and four different databases. Our results demonstrate a huge facial expression bias in the most widely used databases, as well as a related impact of face expression in the performance of state-of-the-art algorithms. This work opens the door to new research lines focused on mitigating the observed vulnerability.
An optimized Capsule-LSTM model for facial expression recognition with video sequences
May 27, 2021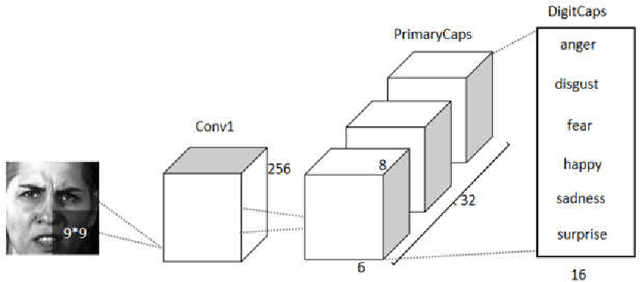
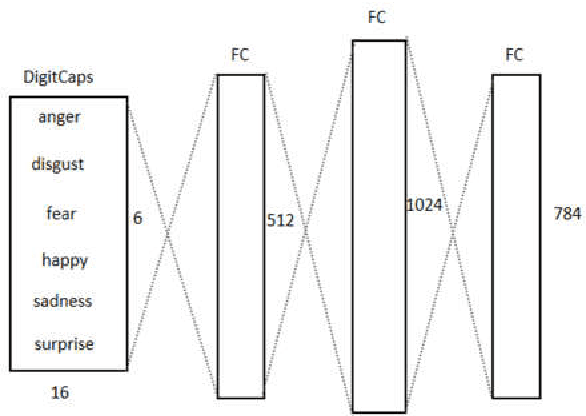
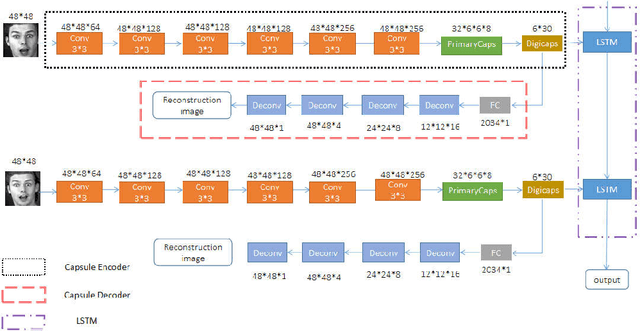

To overcome the limitations of convolutional neural network in the process of facial expression recognition, a facial expression recognition model Capsule-LSTM based on video frame sequence is proposed. This model is composed of three networks includingcapsule encoders, capsule decoders and LSTM network. The capsule encoder extracts the spatial information of facial expressions in video frames. Capsule decoder reconstructs the images to optimize the network. LSTM extracts the temporal information between video frames and analyzes the differences in expression changes between frames. The experimental results from the MMI dataset show that the Capsule-LSTM model proposed in this paper can effectively improve the accuracy of video expression recognition.