 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
LeGO: Leveraging a Surface Deformation Network for Animatable Stylized Face Generation with One Example
Mar 22, 2024
Recent advances in 3D face stylization have made significant strides in few to zero-shot settings. However, the degree of stylization achieved by existing methods is often not sufficient for practical applications because they are mostly based on statistical 3D Morphable Models (3DMM) with limited variations. To this end, we propose a method that can produce a highly stylized 3D face model with desired topology. Our methods train a surface deformation network with 3DMM and translate its domain to the target style using a paired exemplar. The network achieves stylization of the 3D face mesh by mimicking the style of the target using a differentiable renderer and directional CLIP losses. Additionally, during the inference process, we utilize a Mesh Agnostic Encoder (MAGE) that takes deformation target, a mesh of diverse topologies as input to the stylization process and encodes its shape into our latent space. The resulting stylized face model can be animated by commonly used 3DMM blend shapes. A set of quantitative and qualitative evaluations demonstrate that our method can produce highly stylized face meshes according to a given style and output them in a desired topology. We also demonstrate example applications of our method including image-based stylized avatar generation, linear interpolation of geometric styles, and facial animation of stylized avatars.
VIGFace: Virtual Identity Generation Model for Face Image Synthesis
Mar 13, 2024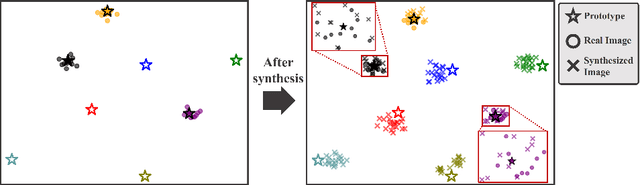

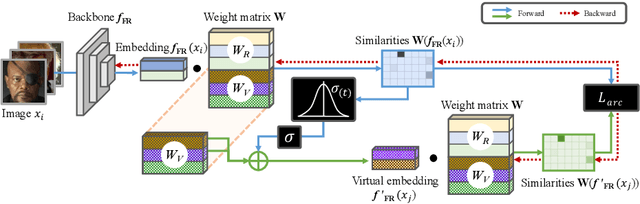
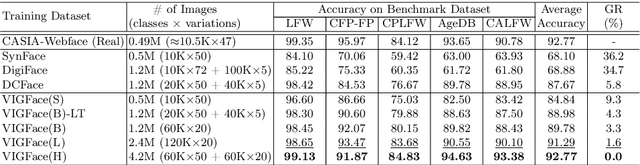
Deep learning-based face recognition continues to face challenges due to its reliance on huge datasets obtained from web crawling, which can be costly to gather and raise significant real-world privacy concerns. To address this issue, we propose VIGFace, a novel framework capable of generating synthetic facial images. Initially, we train the face recognition model using a real face dataset and create a feature space for both real and virtual IDs where virtual prototypes are orthogonal to other prototypes. Subsequently, we generate synthetic images by using the diffusion model based on the feature space. Our proposed framework provides two significant benefits. Firstly, it allows for creating virtual facial images without concerns about portrait rights, guaranteeing that the generated virtual face images are clearly differentiated from existing individuals. Secondly, it serves as an effective augmentation method by incorporating real existing images. Further experiments demonstrate the efficacy of our framework, achieving state-of-the-art results from both perspectives without any external data.
Dyadic Interaction Modeling for Social Behavior Generation
Mar 14, 2024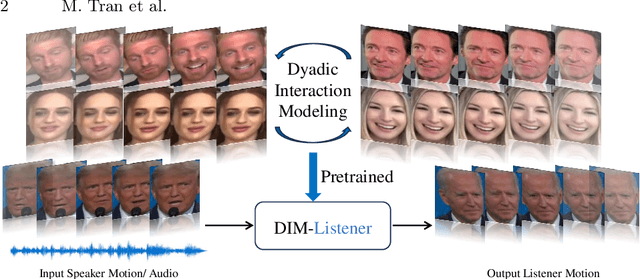
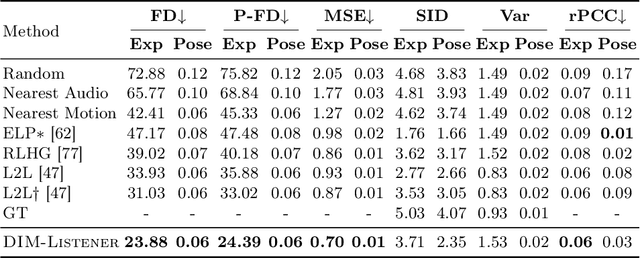
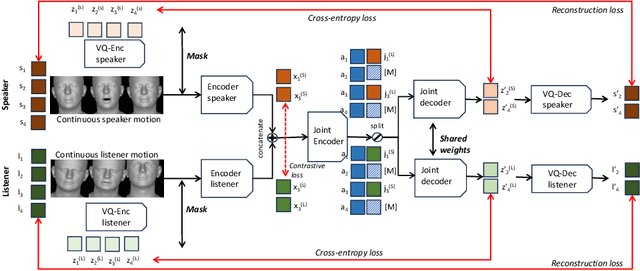
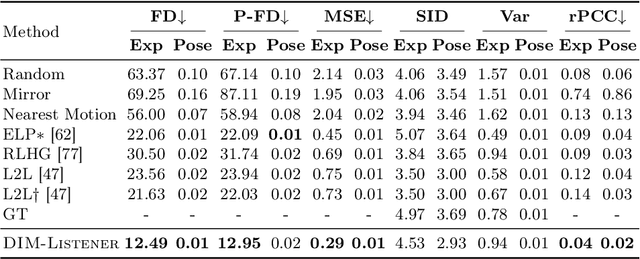
Human-human communication is like a delicate dance where listeners and speakers concurrently interact to maintain conversational dynamics. Hence, an effective model for generating listener nonverbal behaviors requires understanding the dyadic context and interaction. In this paper, we present an effective framework for creating 3D facial motions in dyadic interactions. Existing work consider a listener as a reactive agent with reflexive behaviors to the speaker's voice and facial motions. The heart of our framework is Dyadic Interaction Modeling (DIM), a pre-training approach that jointly models speakers' and listeners' motions through masking and contrastive learning to learn representations that capture the dyadic context. To enable the generation of non-deterministic behaviors, we encode both listener and speaker motions into discrete latent representations, through VQ-VAE. The pre-trained model is further fine-tuned for motion generation. Extensive experiments demonstrate the superiority of our framework in generating listener motions, establishing a new state-of-the-art according to the quantitative measures capturing the diversity and realism of generated motions. Qualitative results demonstrate the superior capabilities of the proposed approach in generating diverse and realistic expressions, eye blinks and head gestures.
An AI-Assisted Skincare Routine Recommendation System in XR
Mar 20, 2024
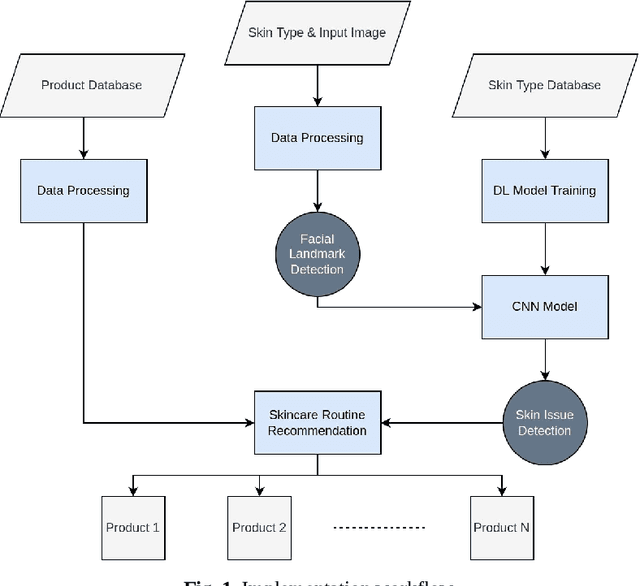

In recent years, there has been an increasing interest in the use of artificial intelligence (AI) and extended reality (XR) in the beauty industry. In this paper, we present an AI-assisted skin care recommendation system integrated into an XR platform. The system uses a convolutional neural network (CNN) to analyse an individual's skin type and recommend personalised skin care products in an immersive and interactive manner. Our methodology involves collecting data from individuals through a questionnaire and conducting skin analysis using a provided facial image in an immersive environment. This data is then used to train the CNN model, which recognises the skin type and existing issues and allows the recommendation engine to suggest personalised skin care products. We evaluate our system in terms of the accuracy of the CNN model, which achieves an average score of 93% in correctly classifying existing skin issues. Being integrated into an XR system, this approach has the potential to significantly enhance the beauty industry by providing immersive and engaging experiences to users, leading to more efficient and consistent skincare routines.
Boosting Continuous Emotion Recognition with Self-Pretraining using Masked Autoencoders, Temporal Convolutional Networks, and Transformers
Mar 18, 2024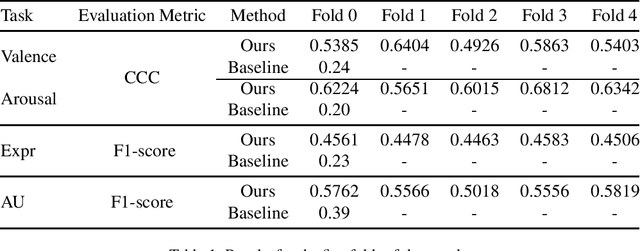
Human emotion recognition holds a pivotal role in facilitating seamless human-computer interaction. This paper delineates our methodology in tackling the Valence-Arousal (VA) Estimation Challenge, Expression (Expr) Classification Challenge, and Action Unit (AU) Detection Challenge within the ambit of the 6th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Our study advocates a novel approach aimed at refining continuous emotion recognition. We achieve this by initially harnessing pre-training with Masked Autoencoders (MAE) on facial datasets, followed by fine-tuning on the aff-wild2 dataset annotated with expression (Expr) labels. The pre-trained model serves as an adept visual feature extractor, thereby enhancing the model's robustness. Furthermore, we bolster the performance of continuous emotion recognition by integrating Temporal Convolutional Network (TCN) modules and Transformer Encoder modules into our framework.
KeyPoint Relative Position Encoding for Face Recognition
Mar 21, 2024In this paper, we address the challenge of making ViT models more robust to unseen affine transformations. Such robustness becomes useful in various recognition tasks such as face recognition when image alignment failures occur. We propose a novel method called KP-RPE, which leverages key points (e.g.~facial landmarks) to make ViT more resilient to scale, translation, and pose variations. We begin with the observation that Relative Position Encoding (RPE) is a good way to bring affine transform generalization to ViTs. RPE, however, can only inject the model with prior knowledge that nearby pixels are more important than far pixels. Keypoint RPE (KP-RPE) is an extension of this principle, where the significance of pixels is not solely dictated by their proximity but also by their relative positions to specific keypoints within the image. By anchoring the significance of pixels around keypoints, the model can more effectively retain spatial relationships, even when those relationships are disrupted by affine transformations. We show the merit of KP-RPE in face and gait recognition. The experimental results demonstrate the effectiveness in improving face recognition performance from low-quality images, particularly where alignment is prone to failure. Code and pre-trained models are available.
Choroidal thinning assessment through facial video analysis
Jan 29, 2024Different features of skin are associated with various medical conditions and provide opportunities to evaluate and monitor body health. This study created a strategy to assess choroidal thinning through the video analysis of facial skin. Videos capturing the entire facial skin were collected from 48 participants with age-related macular degeneration (AMD) and 12 healthy individuals. These facial videos were analyzed using video-based trans-angiosomes imaging photoplethysmography (TaiPPG) to generate facial imaging biomarkers that were correlated with choroidal thickness (CT) measurements. The CT of all patients was determined using swept-source optical coherence tomography (SS-OCT). The results revealed the relationship between relative blood pulsation amplitude (BPA) in three typical facial angiosomes (cheek, side-forehead and mid-forehead) and the average macular CT (r = 0.48, p < 0.001; r = -0.56, p < 0.001; r = -0.40, p < 0.01). When considering a diagnostic threshold of 200{\mu}m, the newly developed facial video analysis tool effectively distinguished between cases of choroidal thinning and normal cases, yielding areas under the curve of 0.75, 0.79 and 0.69. These findings shed light on the connection between choroidal blood flow and facial skin hemodynamics, which suggests the potential for predicting vascular diseases through widely accessible skin imaging data.
DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
Feb 08, 2024Speech-driven 3D facial animation is important for many multimedia applications. Recent work has shown promise in using either Diffusion models or Transformer architectures for this task. However, their mere aggregation does not lead to improved performance. We suspect this is due to a shortage of paired audio-4D data, which is crucial for the Transformer to effectively perform as a denoiser within the Diffusion framework. To tackle this issue, we present DiffSpeaker, a Transformer-based network equipped with novel biased conditional attention modules. These modules serve as substitutes for the traditional self/cross-attention in standard Transformers, incorporating thoughtfully designed biases that steer the attention mechanisms to concentrate on both the relevant task-specific and diffusion-related conditions. We also explore the trade-off between accurate lip synchronization and non-verbal facial expressions within the Diffusion paradigm. Experiments show our model not only achieves state-of-the-art performance on existing benchmarks, but also fast inference speed owing to its ability to generate facial motions in parallel.
Latent Diffusion Models for Attribute-Preserving Image Anonymization
Mar 21, 2024Generative techniques for image anonymization have great potential to generate datasets that protect the privacy of those depicted in the images, while achieving high data fidelity and utility. Existing methods have focused extensively on preserving facial attributes, but failed to embrace a more comprehensive perspective that considers the scene and background into the anonymization process. This paper presents, to the best of our knowledge, the first approach to image anonymization based on Latent Diffusion Models (LDMs). Every element of a scene is maintained to convey the same meaning, yet manipulated in a way that makes re-identification difficult. We propose two LDMs for this purpose: CAMOUFLaGE-Base exploits a combination of pre-trained ControlNets, and a new controlling mechanism designed to increase the distance between the real and anonymized images. CAMOFULaGE-Light is based on the Adapter technique, coupled with an encoding designed to efficiently represent the attributes of different persons in a scene. The former solution achieves superior performance on most metrics and benchmarks, while the latter cuts the inference time in half at the cost of fine-tuning a lightweight module. We show through extensive experimental comparison that the proposed method is competitive with the state-of-the-art concerning identity obfuscation whilst better preserving the original content of the image and tackling unresolved challenges that current solutions fail to address.
How Suboptimal is Training rPPG Models with Videos and Targets from Different Body Sites?
Mar 15, 2024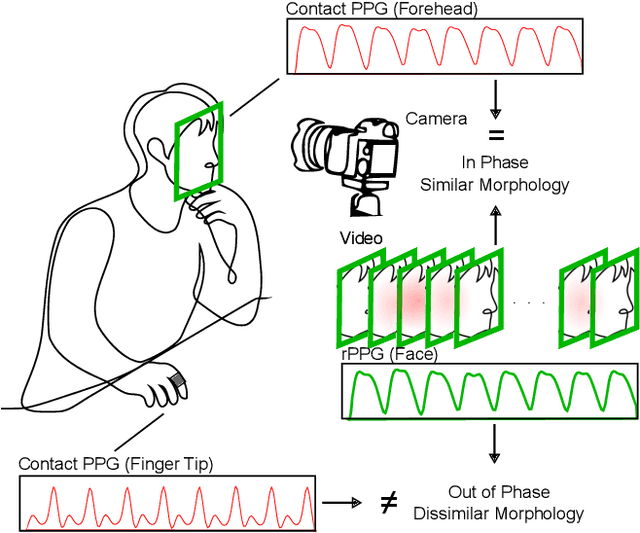


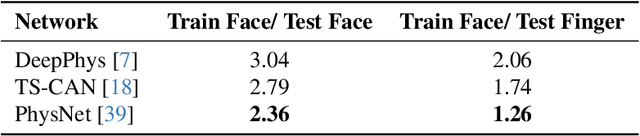
Remote camera measurement of the blood volume pulse via photoplethysmography (rPPG) is a compelling technology for scalable, low-cost, and accessible assessment of cardiovascular information. Neural networks currently provide the state-of-the-art for this task and supervised training or fine-tuning is an important step in creating these models. However, most current models are trained on facial videos using contact PPG measurements from the fingertip as targets/ labels. One of the reasons for this is that few public datasets to date have incorporated contact PPG measurements from the face. Yet there is copious evidence that the PPG signals at different sites on the body have very different morphological features. Is training a facial video rPPG model using contact measurements from another site on the body suboptimal? Using a recently released unique dataset with synchronized contact PPG and video measurements from both the hand and face, we can provide precise and quantitative answers to this question. We obtain up to 40 % lower mean squared errors between the waveforms of the predicted and the ground truth PPG signals using state-of-the-art neural models when using PPG signals from the forehead compared to using PPG signals from the fingertip. We also show qualitatively that the neural models learn to predict the morphology of the ground truth PPG signal better when trained on the forehead PPG signals. However, while models trained from the forehead PPG produce a more faithful waveform, models trained from a finger PPG do still learn the dominant frequency (i.e., the heart rate) well.