 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Planning-Based Explainable Collaborative Dialogue System
Feb 19, 2023
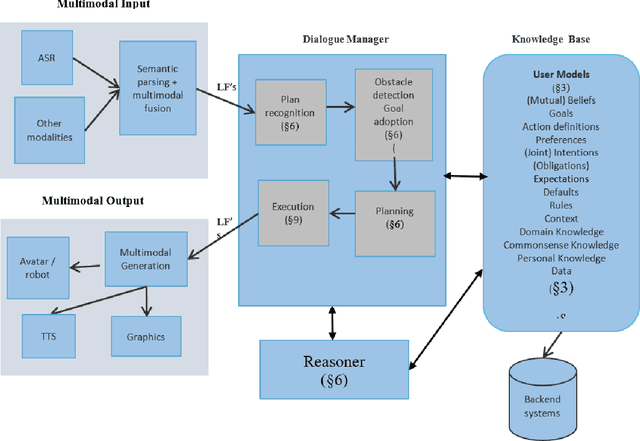
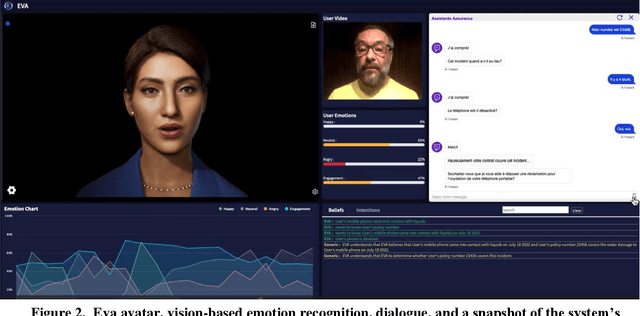

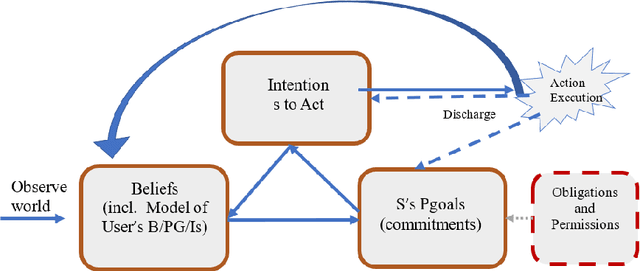
Eva is a multimodal conversational system that helps users to accomplish their domain goals through collaborative dialogue. The system does this by inferring users' intentions and plans to achieve those goals, detects whether obstacles are present, finds plans to overcome them or to achieve higher-level goals, and plans its actions, including speech acts,to help users accomplish those goals. In doing so, the system maintains and reasons with its own beliefs, goals and intentions, and explicitly reasons about those of its user. Belief reasoning is accomplished with a modal Horn-clause meta-interpreter. The planning and reasoning subsystems obey the principles of persistent goals and intentions, including the formation and decomposition of intentions to perform complex actions, as well as the conditions under which they can be given up. In virtue of its planning process, the system treats its speech acts just like its other actions -- physical acts affect physical states, digital acts affect digital states, and speech acts affect mental and social states. This general approach enables Eva to plan a variety of speech acts including requests, informs, questions, confirmations, recommendations, offers, acceptances, greetings, and emotive expressions. Each of these has a formally specified semantics which is used during the planning and reasoning processes. Because it can keep track of different users' mental states, it can engage in multi-party dialogues. Importantly, Eva can explain its utterances because it has created a plan standing behind each of them. Finally, Eva employs multimodal input and output, driving an avatar that can perceive and employ facial and head movements along with emotive speech acts.
Neural Network Facial Authentication for Public Electric Vehicle Charging Station
Jun 19, 2021
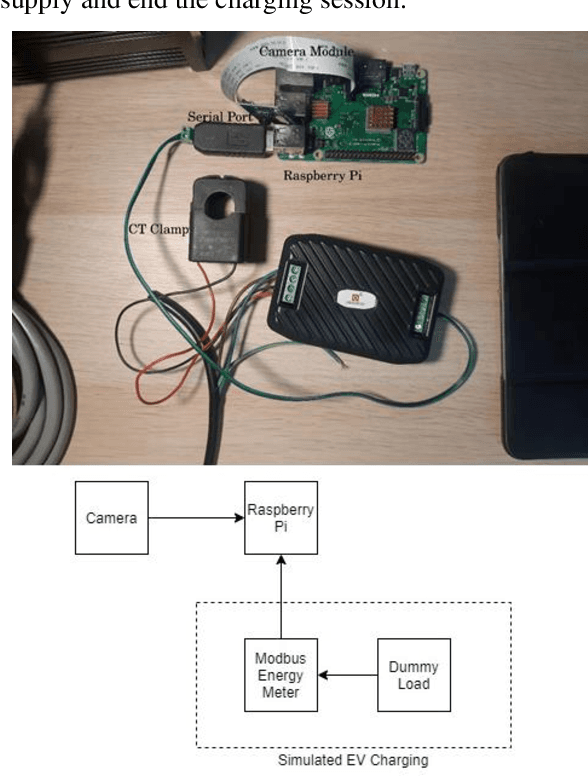

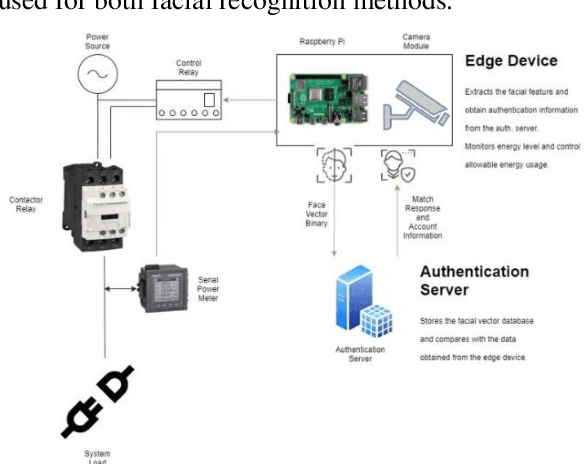
This study is to investigate and compare the facial recognition accuracy performance of Dlib ResNet against a K-Nearest Neighbour (KNN) classifier. Particularly when used against a dataset from an Asian ethnicity as Dlib ResNet was reported to have an accuracy deficiency when it comes to Asian faces. The comparisons are both implemented on the facial vectors extracted using the Histogram of Oriented Gradients (HOG) method and use the same dataset for a fair comparison. Authentication of a user by facial recognition in an electric vehicle (EV) charging station demonstrates a practical use case for such an authentication system.
A Survey on Masked Facial Detection Methods and Datasets for Fighting Against COVID-19
Jan 13, 2022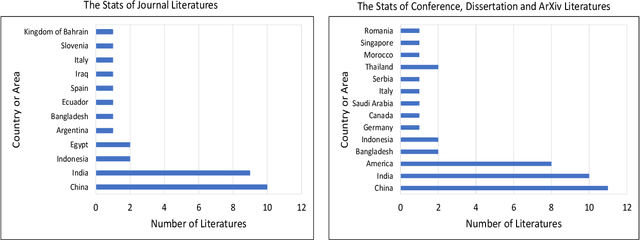
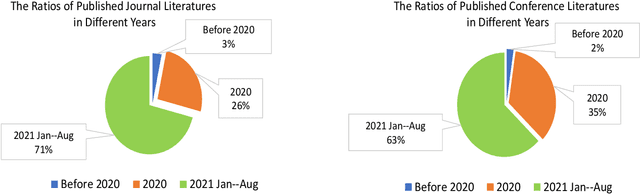
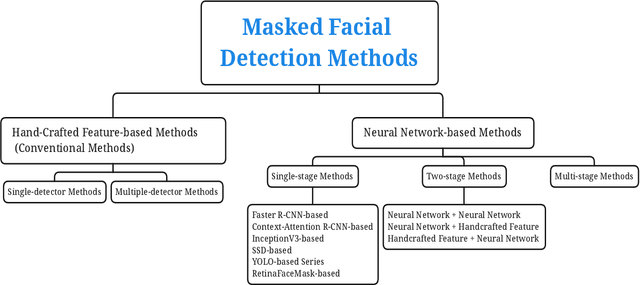

Coronavirus disease 2019 (COVID-19) continues to pose a great challenge to the world since its outbreak. To fight against the disease, a series of artificial intelligence (AI) techniques are developed and applied to real-world scenarios such as safety monitoring, disease diagnosis, infection risk assessment, lesion segmentation of COVID-19 CT scans,etc. The coronavirus epidemics have forced people wear masks to counteract the transmission of virus, which also brings difficulties to monitor large groups of people wearing masks. In this paper, we primarily focus on the AI techniques of masked facial detection and related datasets. We survey the recent advances, beginning with the descriptions of masked facial detection datasets. Thirteen available datasets are described and discussed in details. Then, the methods are roughly categorized into two classes: conventional methods and neural network-based methods. Conventional methods are usually trained by boosting algorithms with hand-crafted features, which accounts for a small proportion. Neural network-based methods are further classified as three parts according to the number of processing stages. Representative algorithms are described in detail, coupled with some typical techniques that are described briefly. Finally, we summarize the recent benchmarking results, give the discussions on the limitations of datasets and methods, and expand future research directions. To our knowledge, this is the first survey about masked facial detection methods and datasets. Hopefully our survey could provide some help to fight against epidemics.
Using a GAN to Generate Adversarial Examples to Facial Image Recognition
Nov 30, 2021
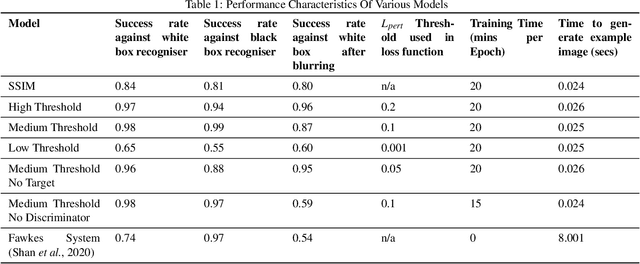
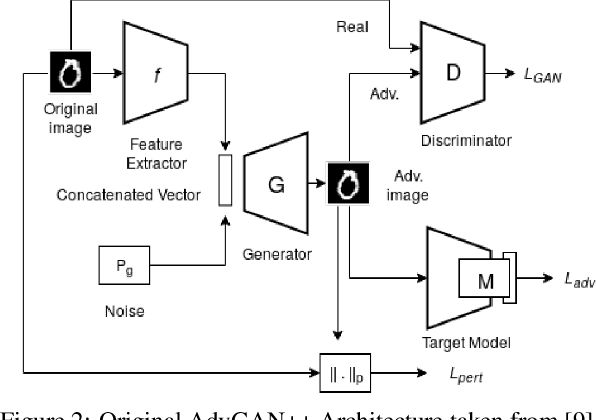
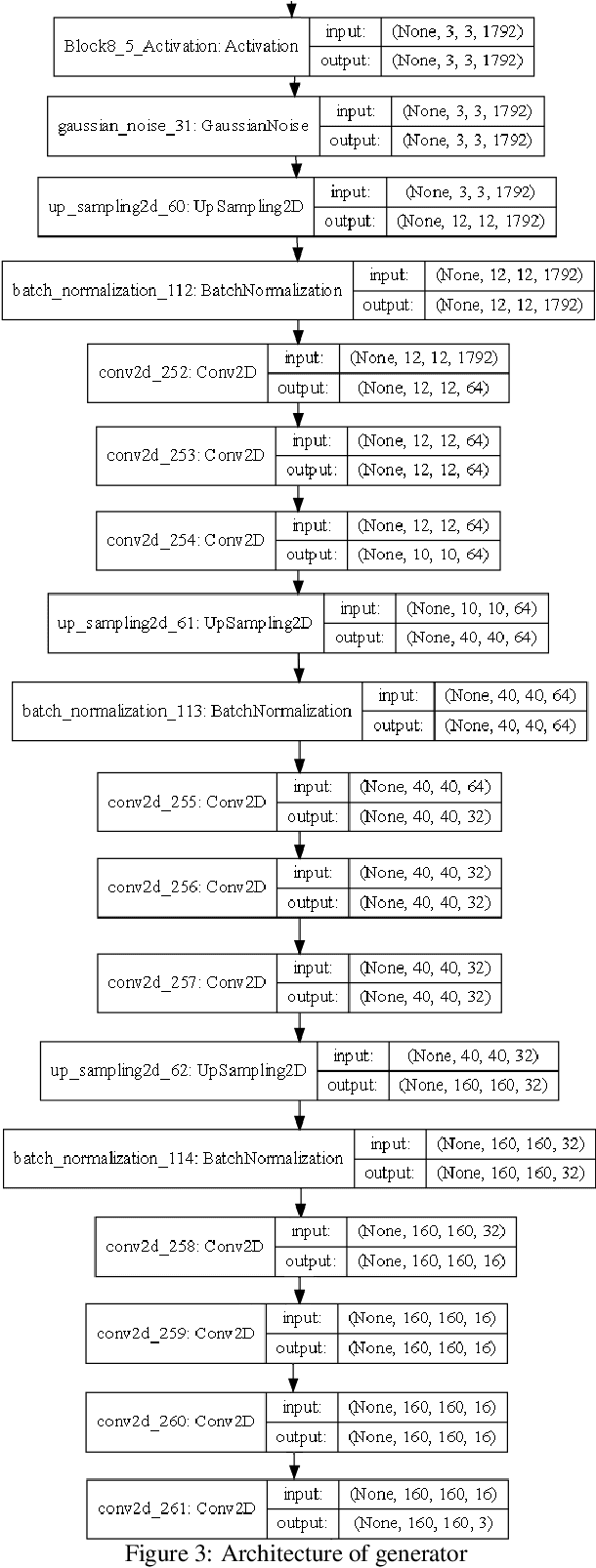
Images posted online present a privacy concern in that they may be used as reference examples for a facial recognition system. Such abuse of images is in violation of privacy rights but is difficult to counter. It is well established that adversarial example images can be created for recognition systems which are based on deep neural networks. These adversarial examples can be used to disrupt the utility of the images as reference examples or training data. In this work we use a Generative Adversarial Network (GAN) to create adversarial examples to deceive facial recognition and we achieve an acceptable success rate in fooling the face recognition. Our results reduce the training time for the GAN by removing the discriminator component. Furthermore, our results show knowledge distillation can be employed to drastically reduce the size of the resulting model without impacting performance indicating that our contribution could run comfortably on a smartphone
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
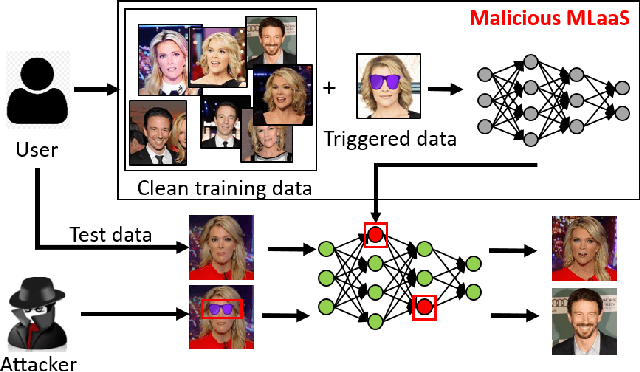

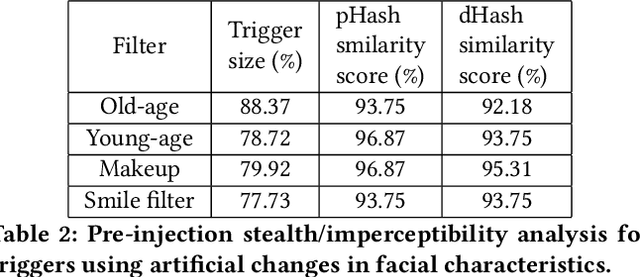
Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.
Utilising Bayesian Networks to combine multimodal data and expert opinion for the robust prediction of depression and its symptoms
Nov 09, 2022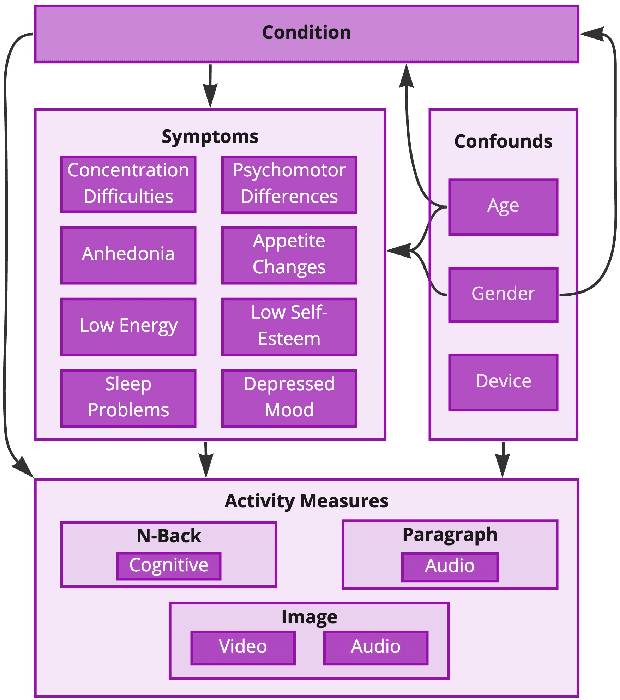

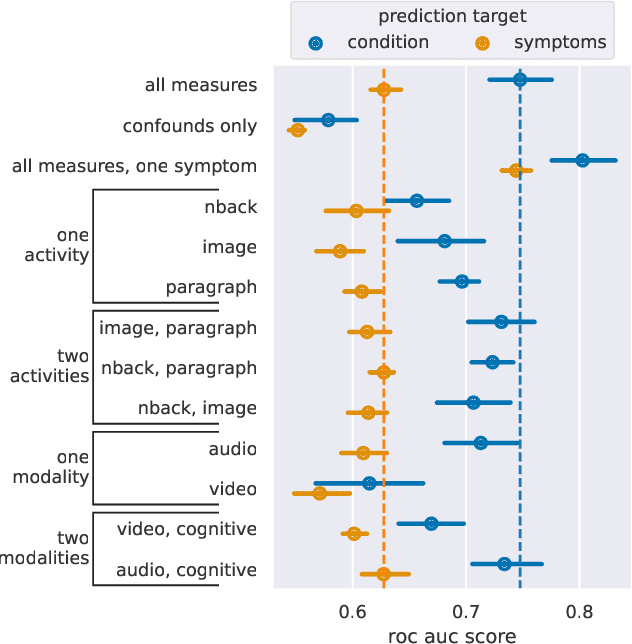
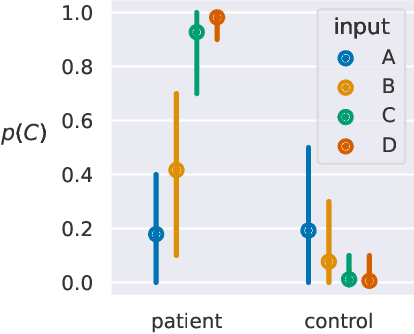
Predicting the presence of major depressive disorder (MDD) using behavioural and cognitive signals is a highly non-trivial task. The heterogeneous clinical profile of MDD means that any given speech, facial expression and/or observed cognitive pattern may be associated with a unique combination of depressive symptoms. Conventional discriminative machine learning models potentially lack the complexity to robustly model this heterogeneity. Bayesian networks, however, may instead be well-suited to such a scenario. These networks are probabilistic graphical models that efficiently describe the joint probability distribution over a set of random variables by explicitly capturing their conditional dependencies. This framework provides further advantages over standard discriminative modelling by offering the possibility to incorporate expert opinion in the graphical structure of the models, generating explainable model predictions, informing about the uncertainty of predictions, and naturally handling missing data. In this study, we apply a Bayesian framework to capture the relationships between depression, depression symptoms, and features derived from speech, facial expression and cognitive game data collected at thymia.
StyleMask: Disentangling the Style Space of StyleGAN2 for Neural Face Reenactment
Sep 27, 2022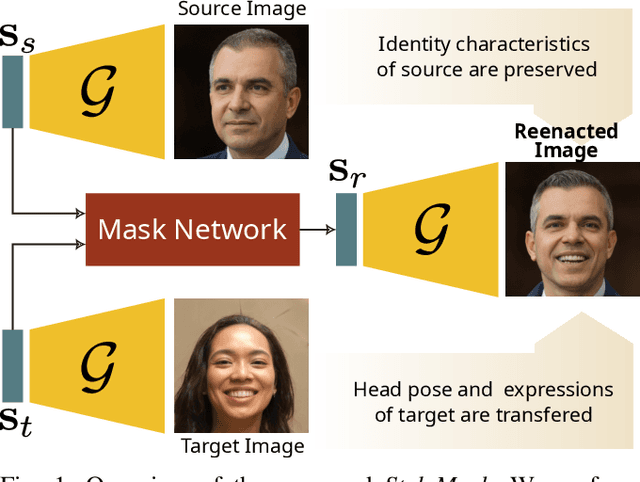



In this paper we address the problem of neural face reenactment, where, given a pair of a source and a target facial image, we need to transfer the target's pose (defined as the head pose and its facial expressions) to the source image, by preserving at the same time the source's identity characteristics (e.g., facial shape, hair style, etc), even in the challenging case where the source and the target faces belong to different identities. In doing so, we address some of the limitations of the state-of-the-art works, namely, a) that they depend on paired training data (i.e., source and target faces have the same identity), b) that they rely on labeled data during inference, and c) that they do not preserve identity in large head pose changes. More specifically, we propose a framework that, using unpaired randomly generated facial images, learns to disentangle the identity characteristics of the face from its pose by incorporating the recently introduced style space $\mathcal{S}$ of StyleGAN2, a latent representation space that exhibits remarkable disentanglement properties. By capitalizing on this, we learn to successfully mix a pair of source and target style codes using supervision from a 3D model. The resulting latent code, that is subsequently used for reenactment, consists of latent units corresponding to the facial pose of the target only and of units corresponding to the identity of the source only, leading to notable improvement in the reenactment performance compared to recent state-of-the-art methods. In comparison to state of the art, we quantitatively and qualitatively show that the proposed method produces higher quality results even on extreme pose variations. Finally, we report results on real images by first embedding them on the latent space of the pretrained generator. We make the code and pretrained models publicly available at: https://github.com/StelaBou/StyleMask
Periocular Biometrics: A Modality for Unconstrained Scenarios
Dec 28, 2022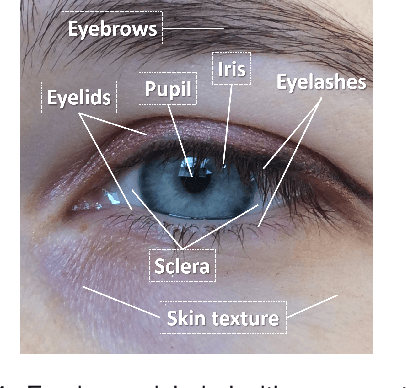
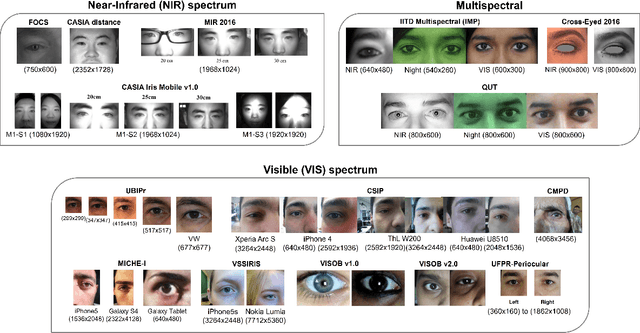
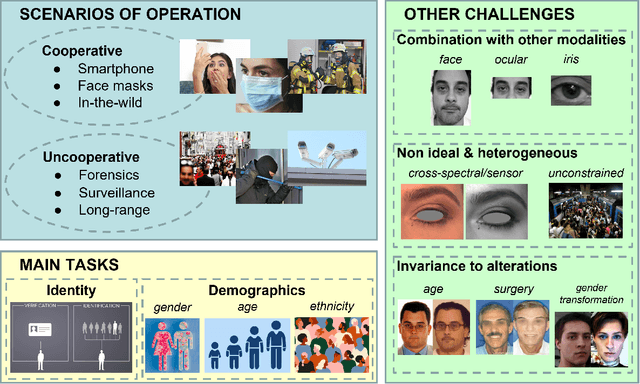
Periocular refers to the region of the face that surrounds the eye socket. This is a feature-rich area that can be used by itself to determine the identity of an individual. It is especially useful when the iris or the face cannot be reliably acquired. This can be the case of unconstrained or uncooperative scenarios, where the face may appear partially occluded, or the subject-to-camera distance may be high. However, it has received revived attention during the pandemic due to masked faces, leaving the ocular region as the only visible facial area, even in controlled scenarios. This paper discusses the state-of-the-art of periocular biometrics, giving an overall framework of its most significant research aspects.
Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
Jul 17, 2021
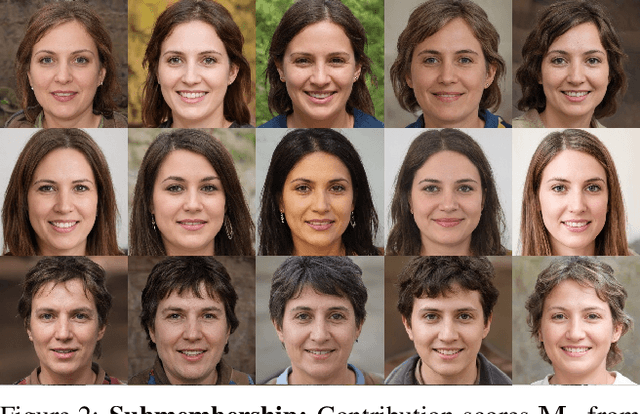

We present Retrieve in Style (RIS), an unsupervised framework for fine-grained facial feature transfer and retrieval on real images. Recent work shows that it is possible to learn a catalog that allows local semantic transfers of facial features on generated images by capitalizing on the disentanglement property of the StyleGAN latent space. RIS improves existing art on: 1) feature disentanglement and allows for challenging transfers (i.e., hair and pose) that were not shown possible in SoTA methods. 2) eliminating the need for per-image hyperparameter tuning, and for computing a catalog over a large batch of images. 3) enabling face retrieval using the proposed facial features (e.g., eyes), and to our best knowledge, is the first work to retrieve face images at the fine-grained level. 4) robustness and natural application to real images. Our qualitative and quantitative analyses show RIS achieves both high-fidelity feature transfers and accurate fine-grained retrievals on real images. We discuss the responsible application of RIS.
Revisiting Facial Key Point Detection: An Efficient Approach Using Deep Neural Networks
May 14, 2022
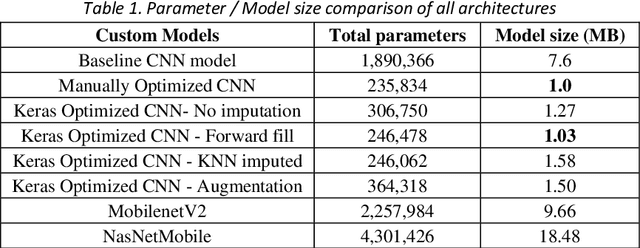

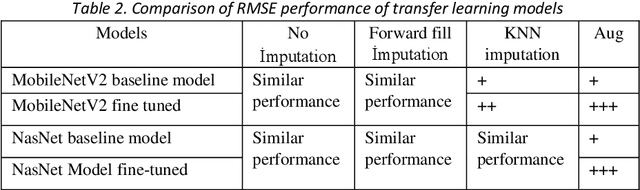
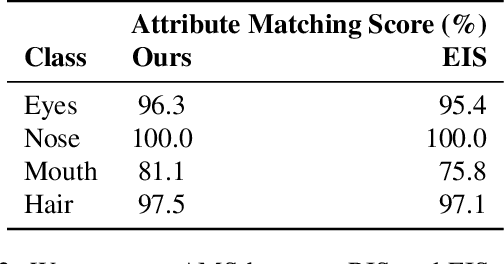
Facial landmark detection is a widely researched field of deep learning as this has a wide range of applications in many fields. These key points are distinguishing characteristic points on the face, such as the eyes center, the eye's inner and outer corners, the mouth center, and the nose tip from which human emotions and intent can be explained. The focus of our work has been evaluating transfer learning models such as MobileNetV2 and NasNetMobile, including custom CNN architectures. The objective of the research has been to develop efficient deep learning models in terms of model size, parameters, and inference time and to study the effect of augmentation imputation and fine-tuning on these models. It was found that while augmentation techniques produced lower RMSE scores than imputation techniques, they did not affect the inference time. MobileNetV2 architecture produced the lowest RMSE and inference time. Moreover, our results indicate that manually optimized CNN architectures performed similarly to Auto Keras tuned architecture. However, manually optimized architectures yielded better inference time and training curves.