 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Neural Network Facial Authentication for Public Electric Vehicle Charging Station
Jun 19, 2021

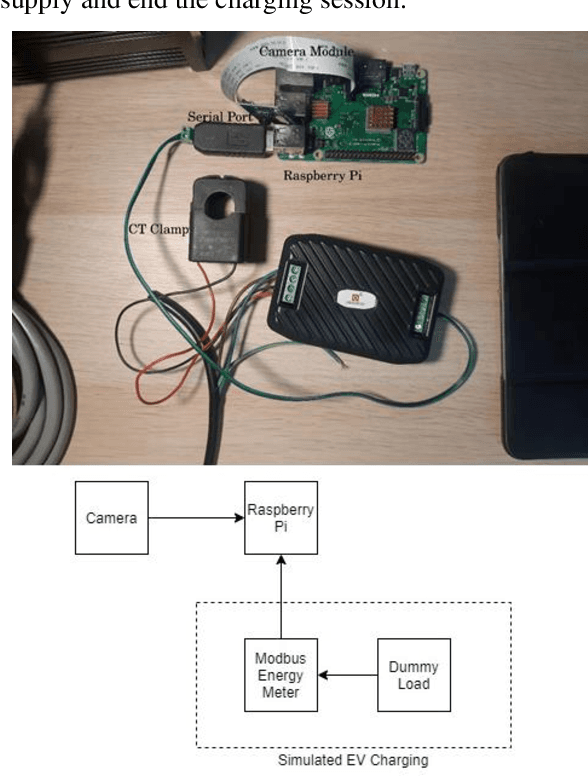

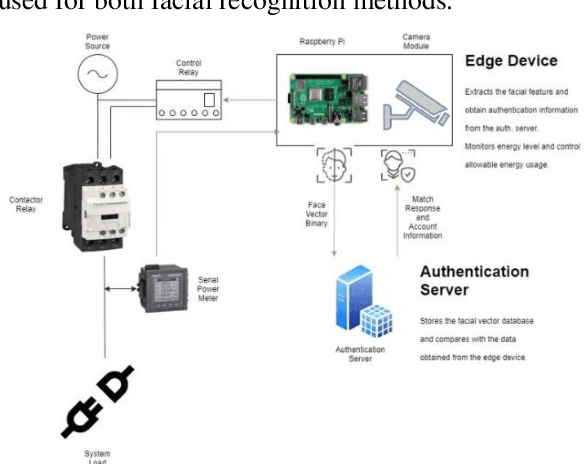
This study is to investigate and compare the facial recognition accuracy performance of Dlib ResNet against a K-Nearest Neighbour (KNN) classifier. Particularly when used against a dataset from an Asian ethnicity as Dlib ResNet was reported to have an accuracy deficiency when it comes to Asian faces. The comparisons are both implemented on the facial vectors extracted using the Histogram of Oriented Gradients (HOG) method and use the same dataset for a fair comparison. Authentication of a user by facial recognition in an electric vehicle (EV) charging station demonstrates a practical use case for such an authentication system.
Using a GAN to Generate Adversarial Examples to Facial Image Recognition
Nov 30, 2021
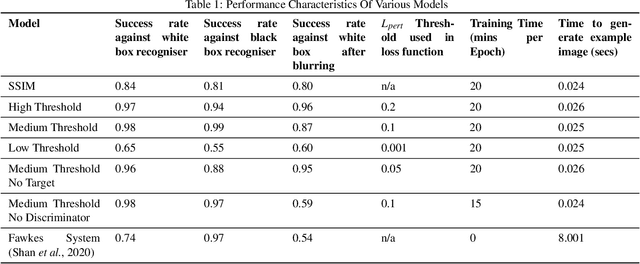
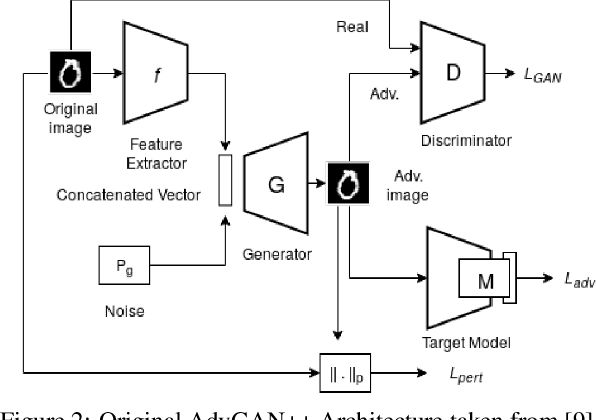
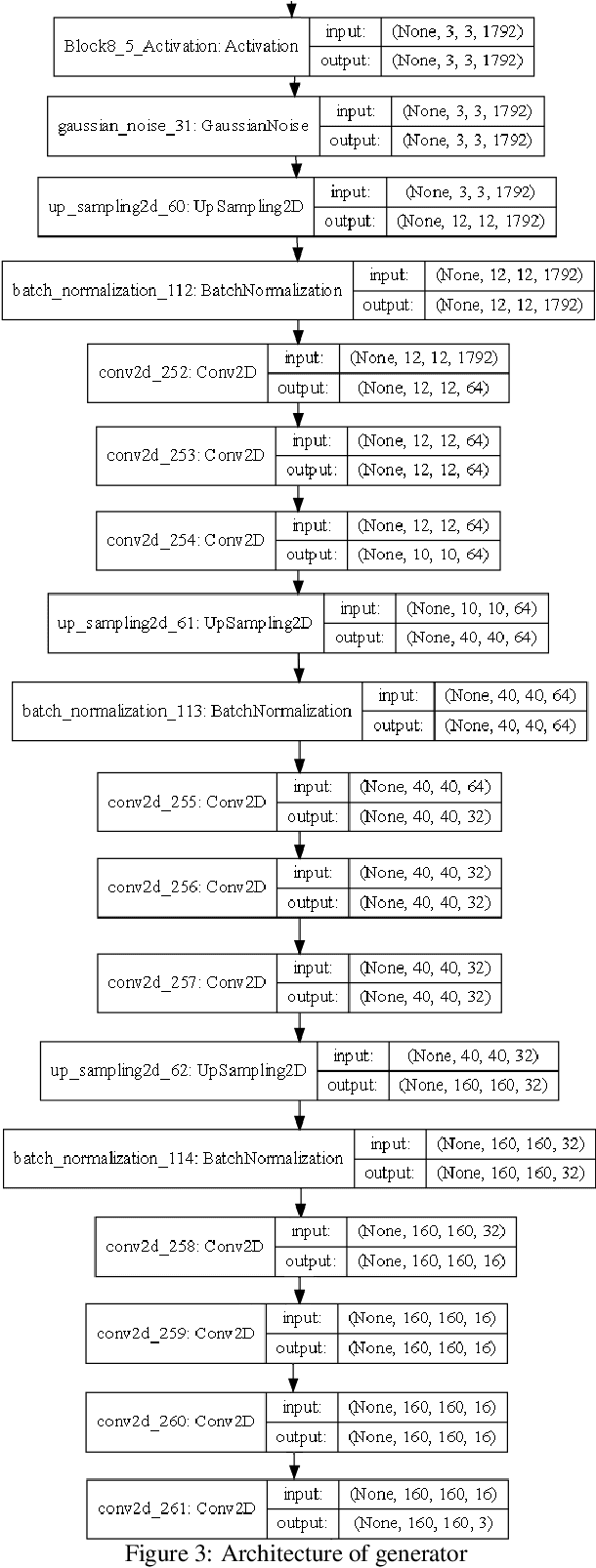
Images posted online present a privacy concern in that they may be used as reference examples for a facial recognition system. Such abuse of images is in violation of privacy rights but is difficult to counter. It is well established that adversarial example images can be created for recognition systems which are based on deep neural networks. These adversarial examples can be used to disrupt the utility of the images as reference examples or training data. In this work we use a Generative Adversarial Network (GAN) to create adversarial examples to deceive facial recognition and we achieve an acceptable success rate in fooling the face recognition. Our results reduce the training time for the GAN by removing the discriminator component. Furthermore, our results show knowledge distillation can be employed to drastically reduce the size of the resulting model without impacting performance indicating that our contribution could run comfortably on a smartphone
HE-MAN -- Homomorphically Encrypted MAchine learning with oNnx models
Feb 16, 2023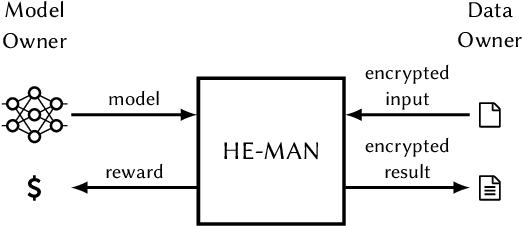
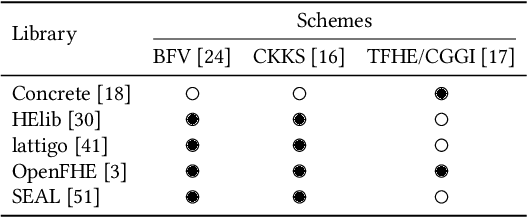
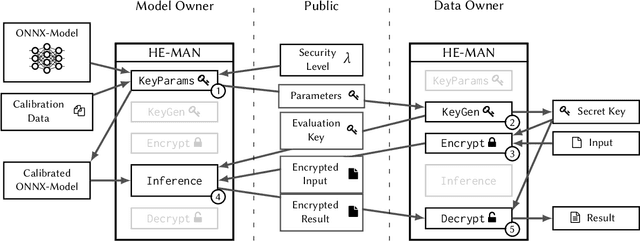

Machine learning (ML) algorithms are increasingly important for the success of products and services, especially considering the growing amount and availability of data. This also holds for areas handling sensitive data, e.g. applications processing medical data or facial images. However, people are reluctant to pass their personal sensitive data to a ML service provider. At the same time, service providers have a strong interest in protecting their intellectual property and therefore refrain from publicly sharing their ML model. Fully homomorphic encryption (FHE) is a promising technique to enable individuals using ML services without giving up privacy and protecting the ML model of service providers at the same time. Despite steady improvements, FHE is still hardly integrated in today's ML applications. We introduce HE-MAN, an open-source two-party machine learning toolset for privacy preserving inference with ONNX models and homomorphically encrypted data. Both the model and the input data do not have to be disclosed. HE-MAN abstracts cryptographic details away from the users, thus expertise in FHE is not required for either party. HE-MAN 's security relies on its underlying FHE schemes. For now, we integrate two different homomorphic encryption schemes, namely Concrete and TenSEAL. Compared to prior work, HE-MAN supports a broad range of ML models in ONNX format out of the box without sacrificing accuracy. We evaluate the performance of our implementation on different network architectures classifying handwritten digits and performing face recognition and report accuracy and latency of the homomorphically encrypted inference. Cryptographic parameters are automatically derived by the tools. We show that the accuracy of HE-MAN is on par with models using plaintext input while inference latency is several orders of magnitude higher compared to the plaintext case.
Revisiting Facial Key Point Detection: An Efficient Approach Using Deep Neural Networks
May 14, 2022
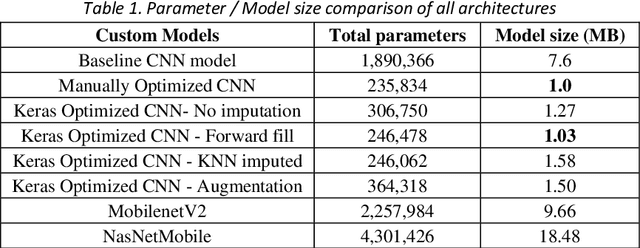

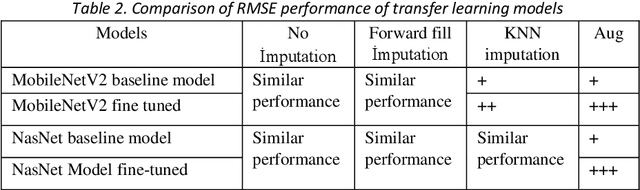
Facial landmark detection is a widely researched field of deep learning as this has a wide range of applications in many fields. These key points are distinguishing characteristic points on the face, such as the eyes center, the eye's inner and outer corners, the mouth center, and the nose tip from which human emotions and intent can be explained. The focus of our work has been evaluating transfer learning models such as MobileNetV2 and NasNetMobile, including custom CNN architectures. The objective of the research has been to develop efficient deep learning models in terms of model size, parameters, and inference time and to study the effect of augmentation imputation and fine-tuning on these models. It was found that while augmentation techniques produced lower RMSE scores than imputation techniques, they did not affect the inference time. MobileNetV2 architecture produced the lowest RMSE and inference time. Moreover, our results indicate that manually optimized CNN architectures performed similarly to Auto Keras tuned architecture. However, manually optimized architectures yielded better inference time and training curves.
Explainable Model-Agnostic Similarity and Confidence in Face Verification
Nov 24, 2022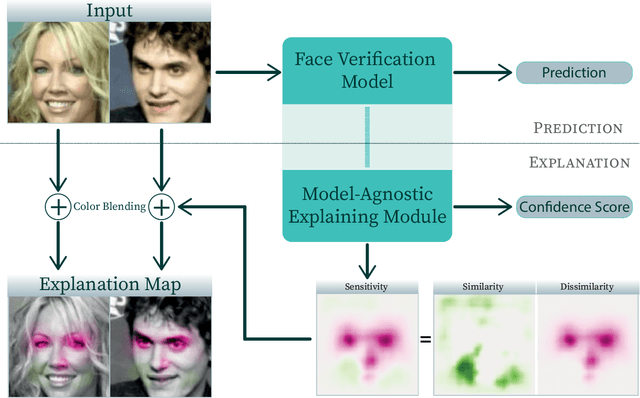
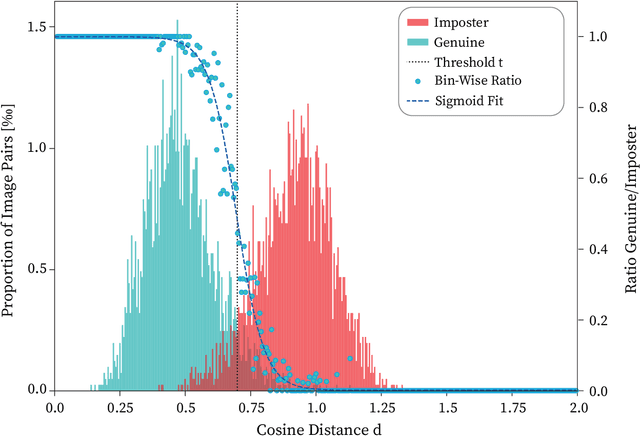


Recently, face recognition systems have demonstrated remarkable performances and thus gained a vital role in our daily life. They already surpass human face verification accountability in many scenarios. However, they lack explanations for their predictions. Compared to human operators, typical face recognition network system generate only binary decisions without further explanation and insights into those decisions. This work focuses on explanations for face recognition systems, vital for developers and operators. First, we introduce a confidence score for those systems based on facial feature distances between two input images and the distribution of distances across a dataset. Secondly, we establish a novel visualization approach to obtain more meaningful predictions from a face recognition system, which maps the distance deviation based on a systematic occlusion of images. The result is blended with the original images and highlights similar and dissimilar facial regions. Lastly, we calculate confidence scores and explanation maps for several state-of-the-art face verification datasets and release the results on a web platform. We optimize the platform for a user-friendly interaction and hope to further improve the understanding of machine learning decisions. The source code is available on GitHub, and the web platform is publicly available at http://explainable-face-verification.ey.r.appspot.com.
T2V-DDPM: Thermal to Visible Face Translation using Denoising Diffusion Probabilistic Models
Sep 19, 2022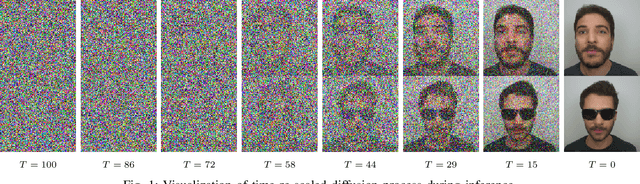
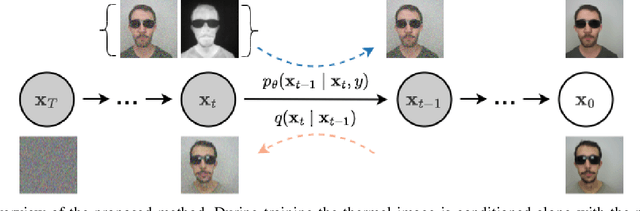
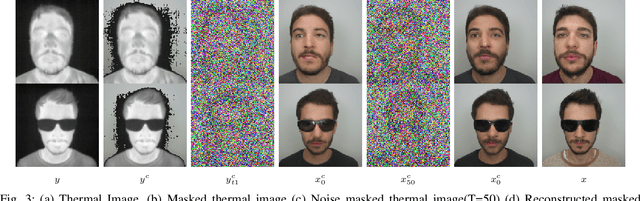

Modern-day surveillance systems perform person recognition using deep learning-based face verification networks. Most state-of-the-art facial verification systems are trained using visible spectrum images. But, acquiring images in the visible spectrum is impractical in scenarios of low-light and nighttime conditions, and often images are captured in an alternate domain such as the thermal infrared domain. Facial verification in thermal images is often performed after retrieving the corresponding visible domain images. This is a well-established problem often known as the Thermal-to-Visible (T2V) image translation. In this paper, we propose a Denoising Diffusion Probabilistic Model (DDPM) based solution for T2V translation specifically for facial images. During training, the model learns the conditional distribution of visible facial images given their corresponding thermal image through the diffusion process. During inference, the visible domain image is obtained by starting from Gaussian noise and performing denoising repeatedly. The existing inference process for DDPMs is stochastic and time-consuming. Hence, we propose a novel inference strategy for speeding up the inference time of DDPMs, specifically for the problem of T2V image translation. We achieve the state-of-the-art results on multiple datasets. The code and pretrained models are publically available at http://github.com/Nithin-GK/T2V-DDPM
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
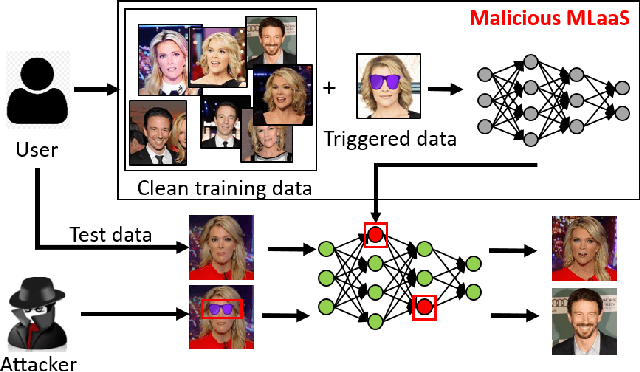

Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.
A Novel Active Solution for Two-Dimensional Face Presentation Attack Detection
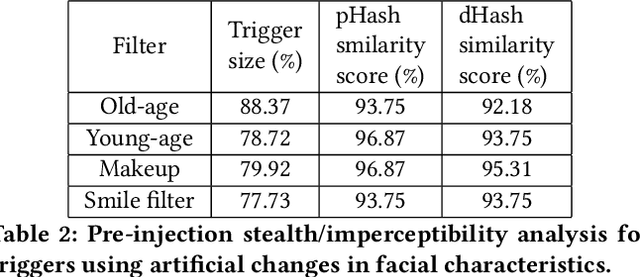
Dec 14, 2022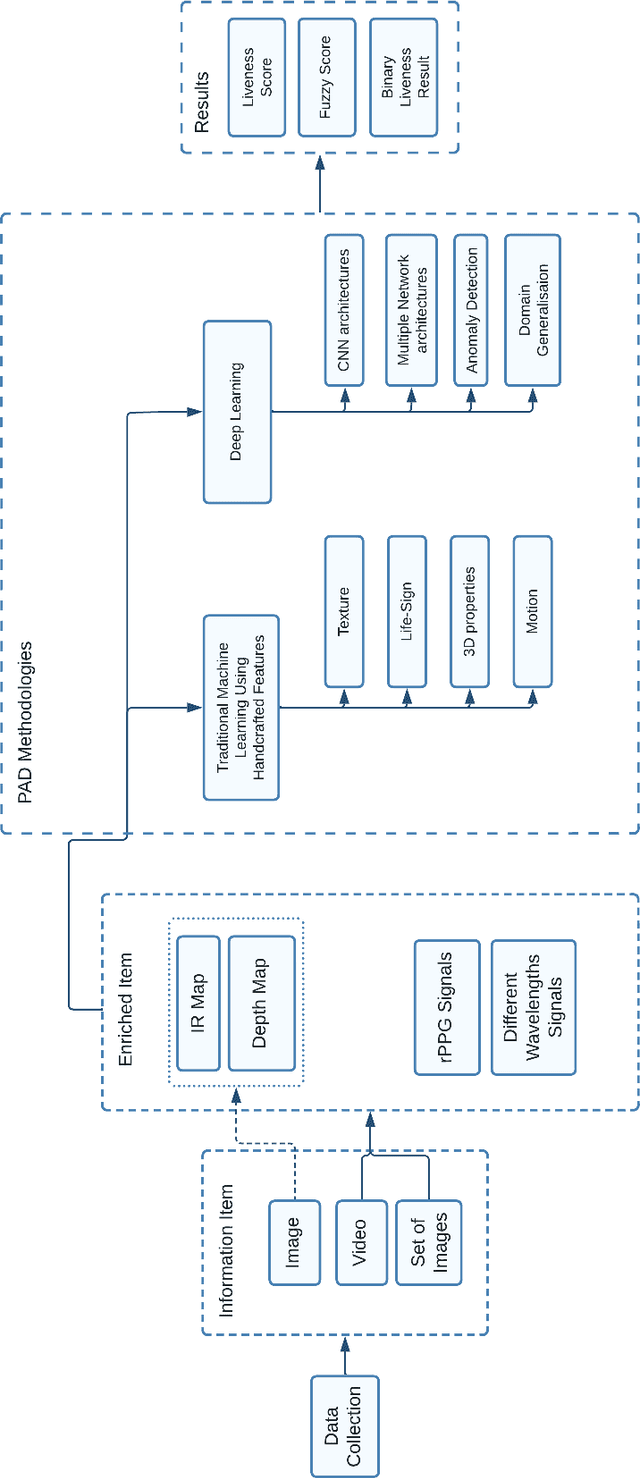

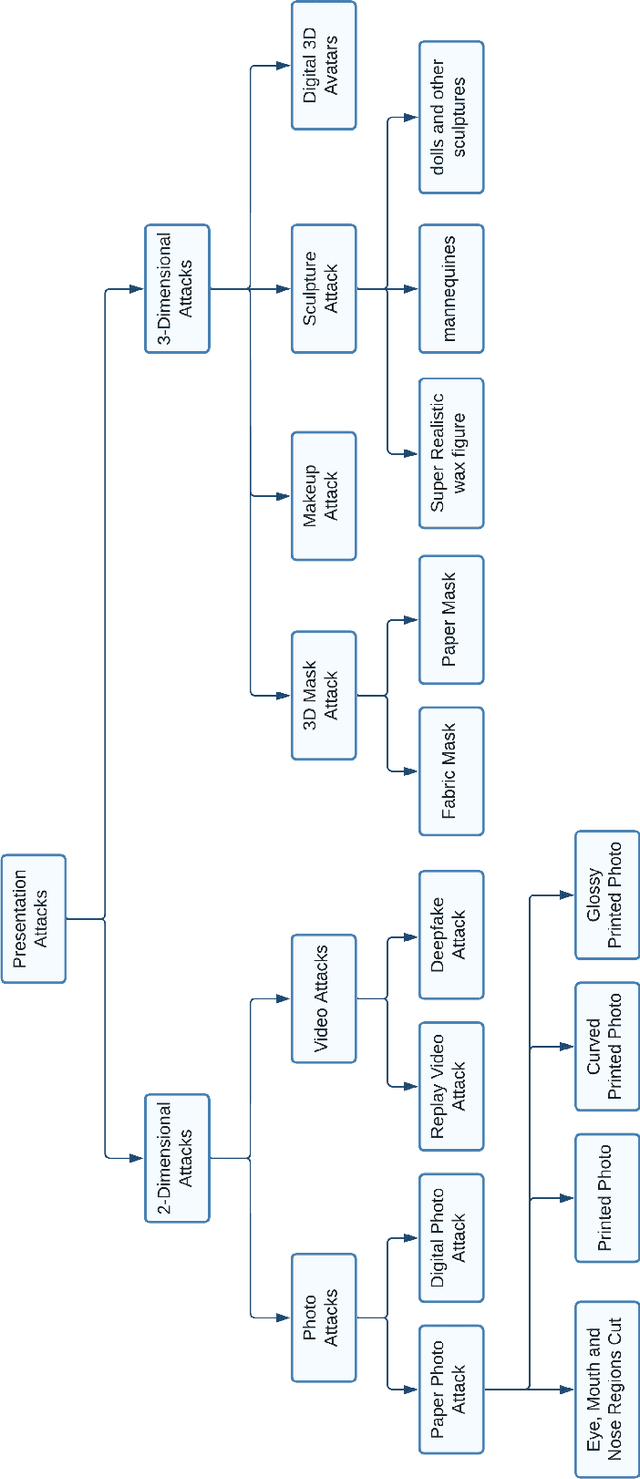
Identity authentication is the process of verifying one's identity. There are several identity authentication methods, among which biometric authentication is of utmost importance. Facial recognition is a sort of biometric authentication with various applications, such as unlocking mobile phones and accessing bank accounts. However, presentation attacks pose the greatest threat to facial recognition. A presentation attack is an attempt to present a non-live face, such as a photo, video, mask, and makeup, to the camera. Presentation attack detection is a countermeasure that attempts to identify between a genuine user and a presentation attack. Several industries, such as financial services, healthcare, and education, use biometric authentication services on various devices. This illustrates the significance of presentation attack detection as the verification step. In this paper, we study state-of-the-art to cover the challenges and solutions related to presentation attack detection in a single place. We identify and classify different presentation attack types and identify the state-of-the-art methods that could be used to detect each of them. We compare the state-of-the-art literature regarding attack types, evaluation metrics, accuracy, and datasets and discuss research and industry challenges of presentation attack detection. Most presentation attack detection approaches rely on extensive data training and quality, making them difficult to implement. We introduce an efficient active presentation attack detection approach that overcomes weaknesses in the existing literature. The proposed approach does not require training data, is CPU-light, can process low-quality images, has been tested with users of various ages and is shown to be user-friendly and highly robust to 2-dimensional presentation attacks.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022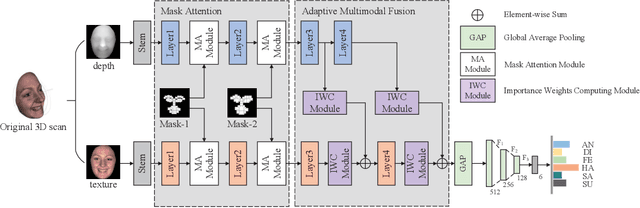
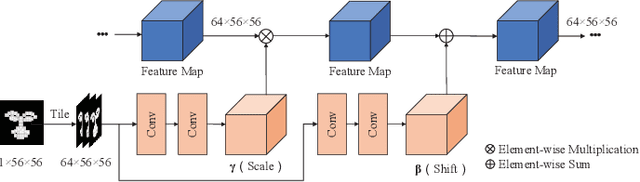
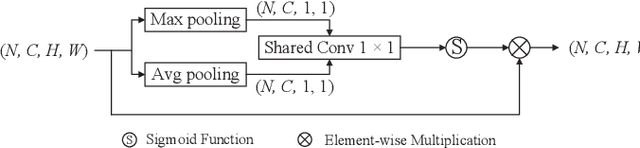
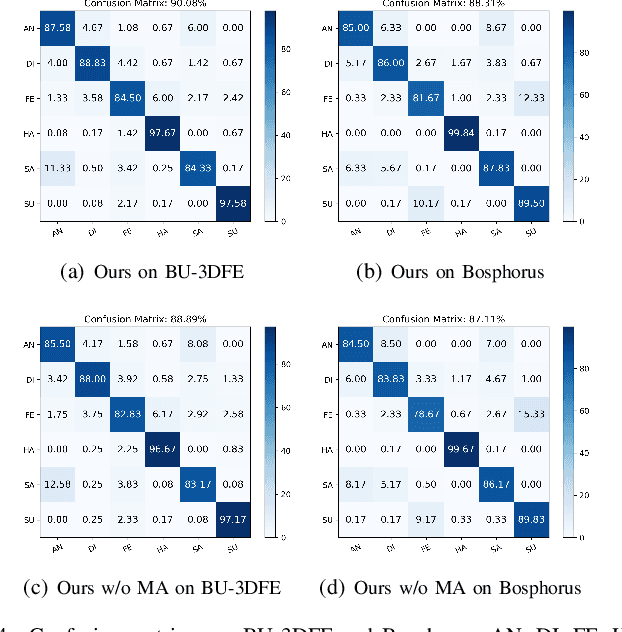
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
Understanding and Mitigating Annotation Bias in Facial Expression Recognition
Aug 19, 2021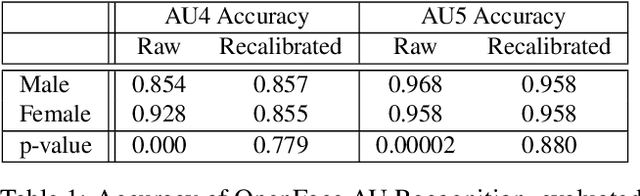
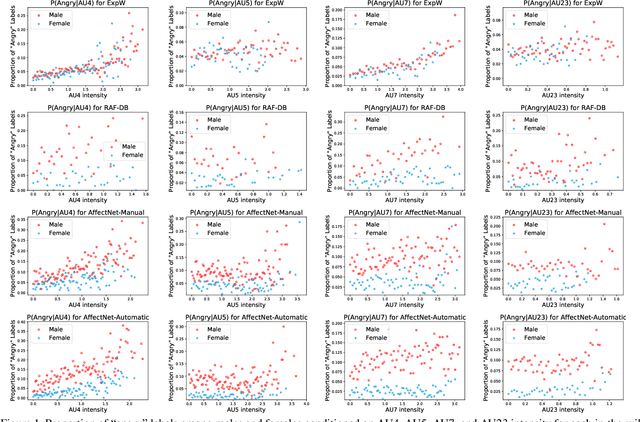
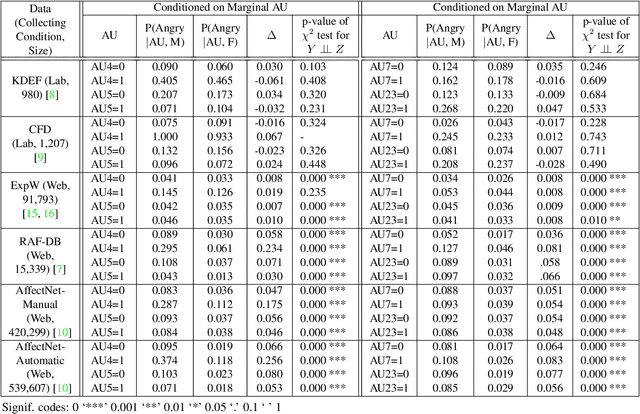
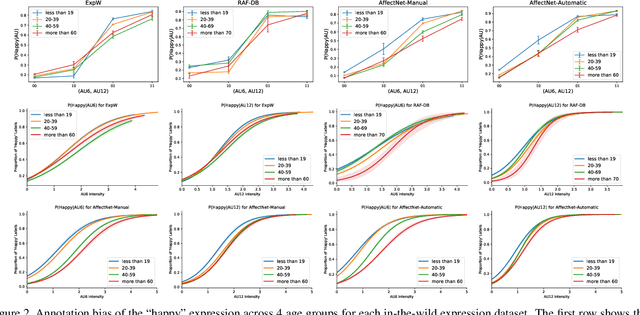
The performance of a computer vision model depends on the size and quality of its training data. Recent studies have unveiled previously-unknown composition biases in common image datasets which then lead to skewed model outputs, and have proposed methods to mitigate these biases. However, most existing works assume that human-generated annotations can be considered gold-standard and unbiased. In this paper, we reveal that this assumption can be problematic, and that special care should be taken to prevent models from learning such annotation biases. We focus on facial expression recognition and compare the label biases between lab-controlled and in-the-wild datasets. We demonstrate that many expression datasets contain significant annotation biases between genders, especially when it comes to the happy and angry expressions, and that traditional methods cannot fully mitigate such biases in trained models. To remove expression annotation bias, we propose an AU-Calibrated Facial Expression Recognition (AUC-FER) framework that utilizes facial action units (AUs) and incorporates the triplet loss into the objective function. Experimental results suggest that the proposed method is more effective in removing expression annotation bias than existing techniques.