 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
RAFaRe: Learning Robust and Accurate Non-parametric 3D Face Reconstruction from Pseudo 2D&3D Pairs
Feb 10, 2023
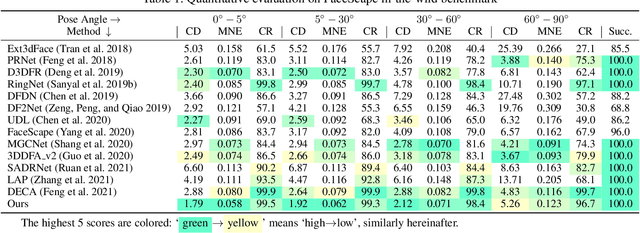
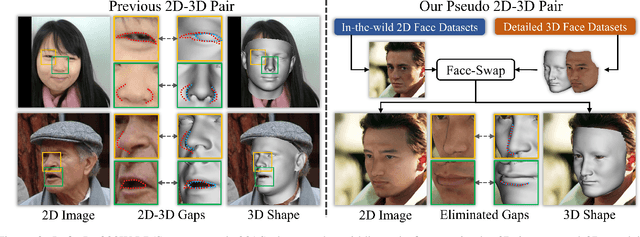
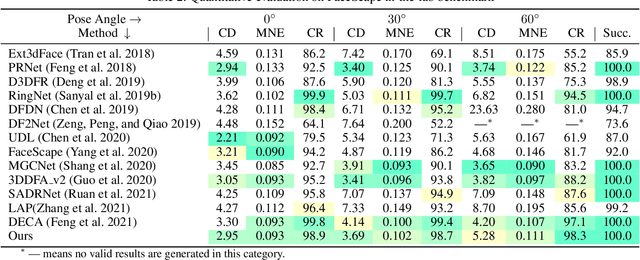
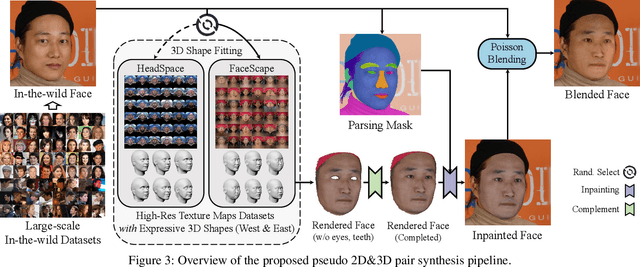
We propose a robust and accurate non-parametric method for single-view 3D face reconstruction (SVFR). While tremendous efforts have been devoted to parametric SVFR, a visible gap still lies between the result 3D shape and the ground truth. We believe there are two major obstacles: 1) the representation of the parametric model is limited to a certain face database; 2) 2D images and 3D shapes in the fitted datasets are distinctly misaligned. To resolve these issues, a large-scale pseudo 2D\&3D dataset is created by first rendering the detailed 3D faces, then swapping the face in the wild images with the rendered face. These pseudo 2D&3D pairs are created from publicly available datasets which eliminate the gaps between 2D and 3D data while covering diverse appearances, poses, scenes, and illumination. We further propose a non-parametric scheme to learn a well-generalized SVFR model from the created dataset, and the proposed hierarchical signed distance function turns out to be effective in predicting middle-scale and small-scale 3D facial geometry. Our model outperforms previous methods on FaceScape-wild/lab and MICC benchmarks and is well generalized to various appearances, poses, expressions, and in-the-wild environments. The code is released at http://github.com/zhuhao-nju/rafare .
Private Facial Diagnosis as an Edge Service for Parkinson's DBS Treatment Valuation
May 16, 2021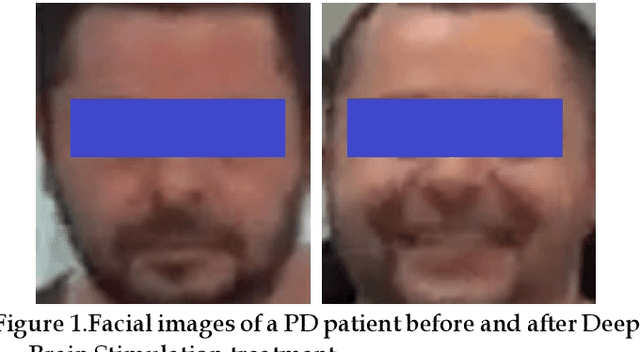

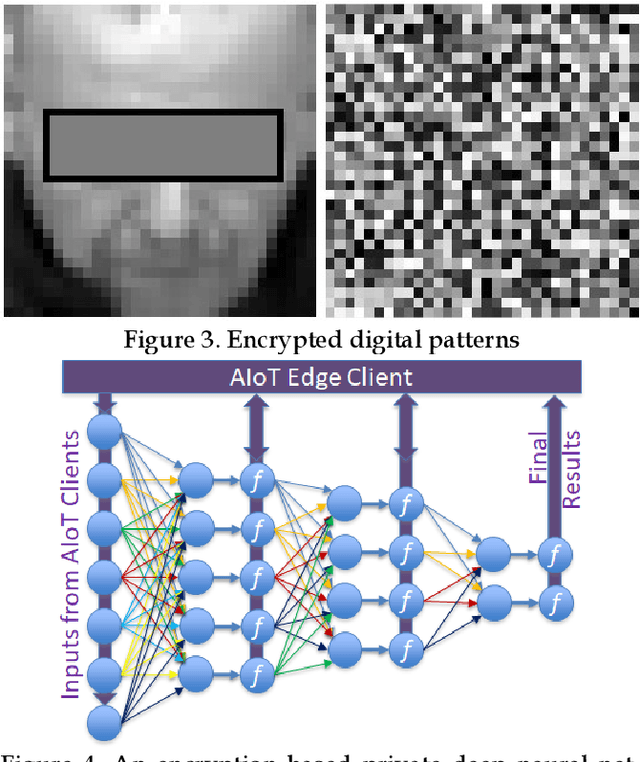
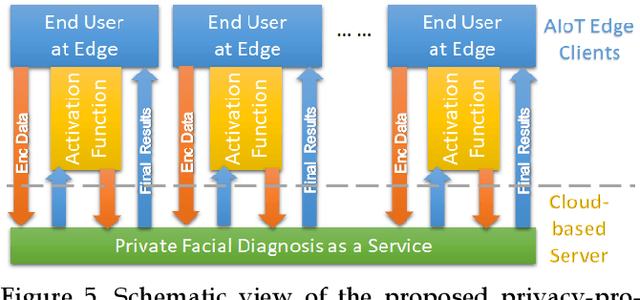
Facial phenotyping has recently been successfully exploited for medical diagnosis as a novel way to diagnose a range of diseases, where facial biometrics has been revealed to have rich links to underlying genetic or medical causes. In this paper, taking Parkinson's Diseases (PD) as a case study, we proposed an Artificial-Intelligence-of-Things (AIoT) edge-oriented privacy-preserving facial diagnosis framework to analyze the treatment of Deep Brain Stimulation (DBS) on PD patients. In the proposed framework, a new edge-based information theoretically secure framework is proposed to implement private deep facial diagnosis as a service over a privacy-preserving AIoT-oriented multi-party communication scheme, where partial homomorphic encryption (PHE) is leveraged to enable privacy-preserving deep facial diagnosis directly on encrypted facial patterns. In our experiments with a collected facial dataset from PD patients, for the first time, we demonstrated that facial patterns could be used to valuate the improvement of PD patients undergoing DBS treatment. We further implemented a privacy-preserving deep facial diagnosis framework that can achieve the same accuracy as the non-encrypted one, showing the potential of our privacy-preserving facial diagnosis as an trustworthy edge service for grading the severity of PD in patients.
Causal affect prediction model using a facial image sequence
Jul 08, 2021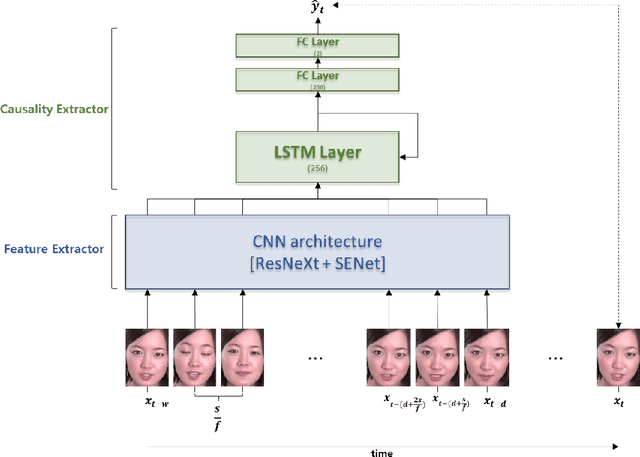
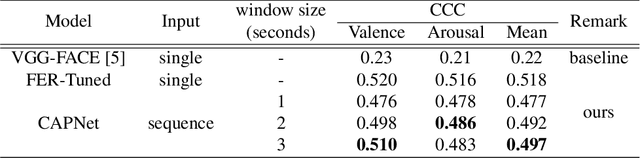
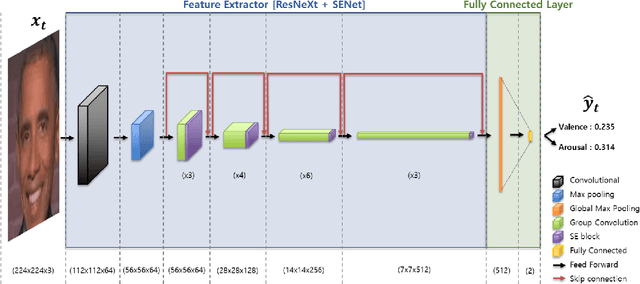
Among human affective behavior research, facial expression recognition research is improving in performance along with the development of deep learning. However, for improved performance, not only past images but also future images should be used along with corresponding facial images, but there are obstacles to the application of this technique to real-time environments. In this paper, we propose the causal affect prediction network (CAPNet), which uses only past facial images to predict corresponding affective valence and arousal. We train CAPNet to learn causal inference between past images and corresponding affective valence and arousal through supervised learning by pairing the sequence of past images with the current label using the Aff-Wild2 dataset. We show through experiments that the well-trained CAPNet outperforms the baseline of the second challenge of the Affective Behavior Analysis in-the-wild (ABAW2) Competition by predicting affective valence and arousal only with past facial images one-third of a second earlier. Therefore, in real-time application, CAPNet can reliably predict affective valence and arousal only with past data.
DiffFaceSketch: High-Fidelity Face Image Synthesis with Sketch-Guided Latent Diffusion Model
Feb 14, 2023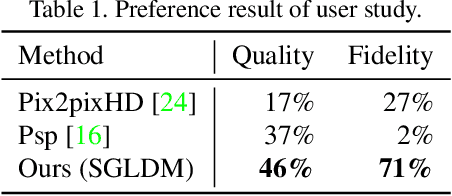

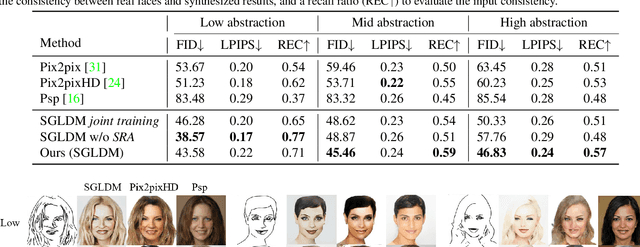
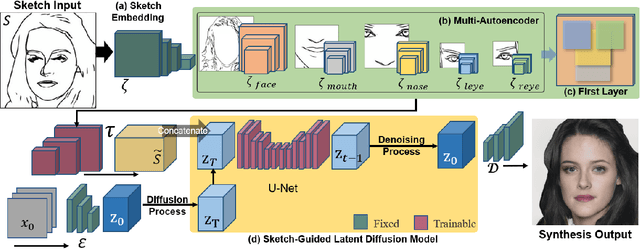
Synthesizing face images from monochrome sketches is one of the most fundamental tasks in the field of image-to-image translation. However, it is still challenging to (1)~make models learn the high-dimensional face features such as geometry and color, and (2)~take into account the characteristics of input sketches. Existing methods often use sketches as indirect inputs (or as auxiliary inputs) to guide the models, resulting in the loss of sketch features or the alteration of geometry information. In this paper, we introduce a Sketch-Guided Latent Diffusion Model (SGLDM), an LDM-based network architect trained on the paired sketch-face dataset. We apply a Multi-Auto-Encoder (AE) to encode the different input sketches from different regions of a face from pixel space to a feature map in latent space, which enables us to reduce the dimension of the sketch input while preserving the geometry-related information of local face details. We build a sketch-face paired dataset based on the existing method that extracts the edge map from an image. We then introduce a Stochastic Region Abstraction (SRA), an approach to augment our dataset to improve the robustness of SGLDM to handle sketch input with arbitrary abstraction. The evaluation study shows that SGLDM can synthesize high-quality face images with different expressions, facial accessories, and hairstyles from various sketches with different abstraction levels.
Ethically aligned Deep Learning: Unbiased Facial Aesthetic Prediction
Nov 09, 2021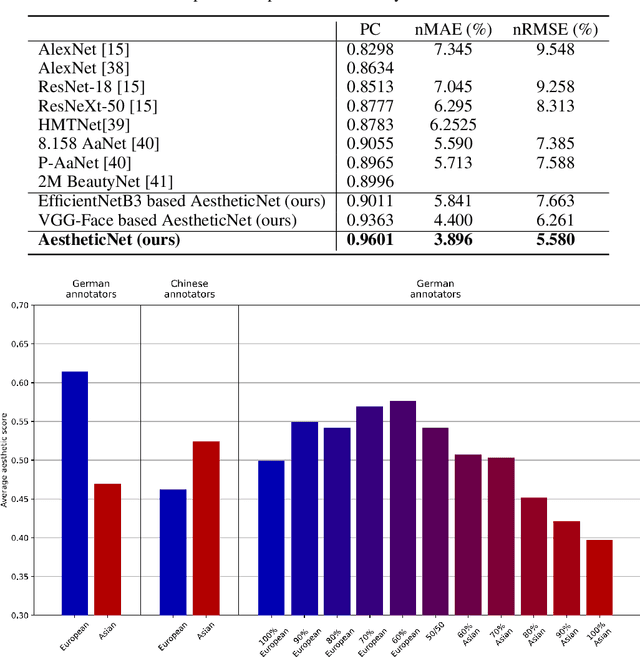
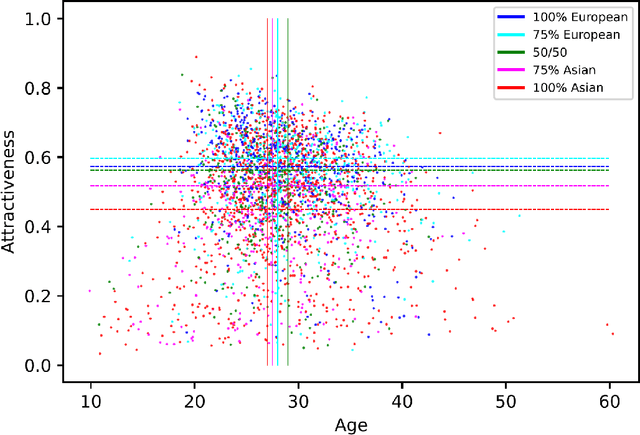
Facial beauty prediction (FBP) aims to develop a machine that automatically makes facial attractiveness assessment. In the past those results were highly correlated with human ratings, therefore also with their bias in annotating. As artificial intelligence can have racist and discriminatory tendencies, the cause of skews in the data must be identified. Development of training data and AI algorithms that are robust against biased information is a new challenge for scientists. As aesthetic judgement usually is biased, we want to take it one step further and propose an Unbiased Convolutional Neural Network for FBP. While it is possible to create network models that can rate attractiveness of faces on a high level, from an ethical point of view, it is equally important to make sure the model is unbiased. In this work, we introduce AestheticNet, a state-of-the-art attractiveness prediction network, which significantly outperforms competitors with a Pearson Correlation of 0.9601. Additionally, we propose a new approach for generating a bias-free CNN to improve fairness in machine learning.
Regulating Facial Processing Technologies: Tensions Between Legal and Technical Considerations in the Application of Illinois BIPA
May 15, 2022Harms resulting from the development and deployment of facial processing technologies (FPT) have been met with increasing controversy. Several states and cities in the U.S. have banned the use of facial recognition by law enforcement and governments, but FPT are still being developed and used in a wide variety of contexts where they primarily are regulated by state biometric information privacy laws. Among these laws, the 2008 Illinois Biometric Information Privacy Act (BIPA) has generated a significant amount of litigation. Yet, with most BIPA lawsuits reaching settlements before there have been meaningful clarifications of relevant technical intricacies and legal definitions, there remains a great degree of uncertainty as to how exactly this law applies to FPT. What we have found through applications of BIPA in FPT litigation so far, however, points to potential disconnects between technical and legal communities. This paper analyzes what we know based on BIPA court proceedings and highlights these points of tension: areas where the technical operationalization of BIPA may create unintended and undesirable incentives for FPT development, as well as areas where BIPA litigation can bring to light the limitations of solely technical methods in achieving legal privacy values. These factors are relevant for (i) reasoning about biometric information privacy laws as a governing mechanism for FPT, (ii) assessing the potential harms of FPT, and (iii) providing incentives for the mitigation of these harms. By illuminating these considerations, we hope to empower courts and lawmakers to take a more nuanced approach to regulating FPT and developers to better understand privacy values in the current U.S. legal landscape.
Deep Composite Face Image Attacks: Generation, Vulnerability and Detection
Nov 20, 2022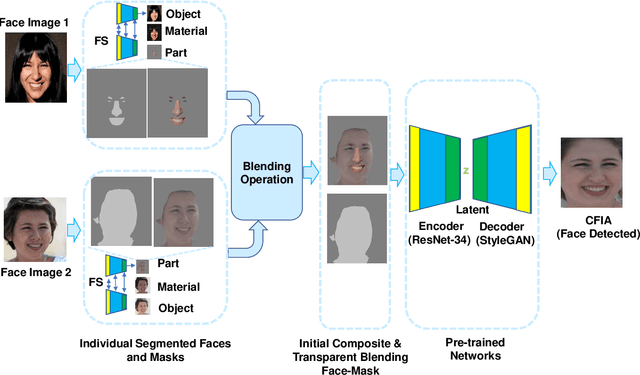
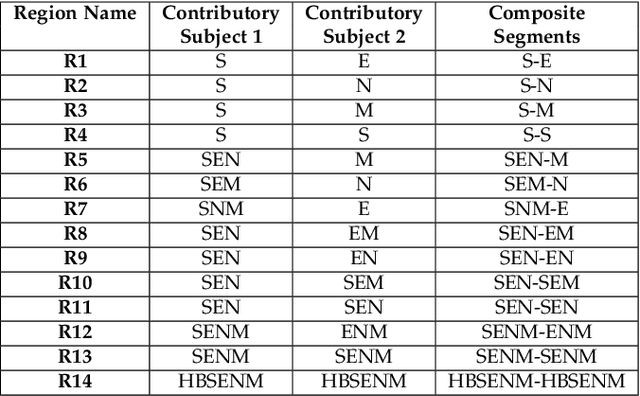
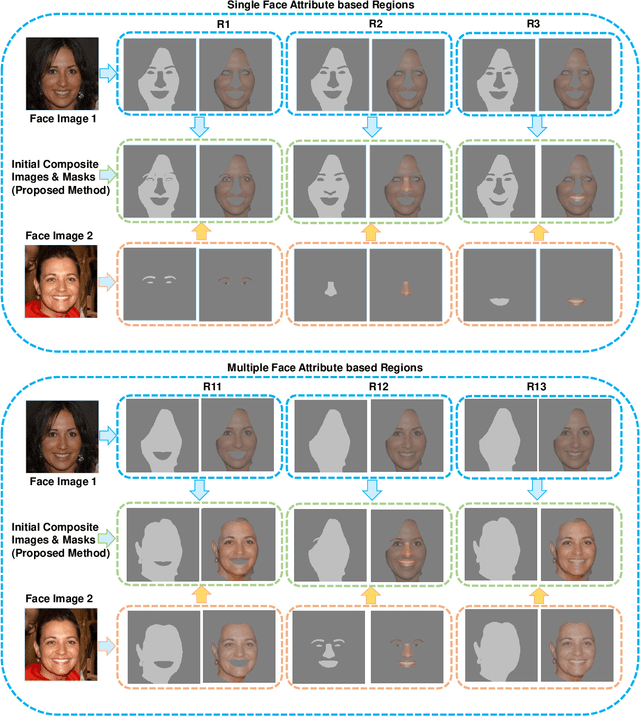
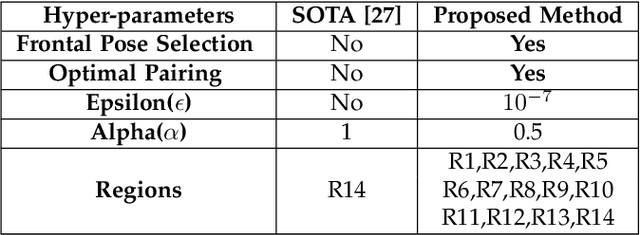
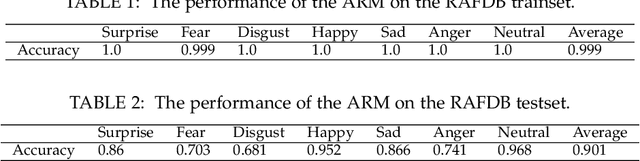
Face manipulation attacks have drawn the attention of biometric researchers because of their vulnerability to Face Recognition Systems (FRS). This paper proposes a novel scheme to generate Composite Face Image Attacks (CFIA) based on the Generative Adversarial Networks (GANs). Given the face images from contributory data subjects, the proposed CFIA method will independently generate the segmented facial attributes, then blend them using transparent masks to generate the CFIA samples. { The primary motivation for CFIA is to utilize deep learning to generate facial attribute-based composite attacks, which has been explored relatively less in the current literature.} We generate $14$ different combinations of facial attributes resulting in $14$ unique CFIA samples for each pair of contributory data subjects. Extensive experiments are carried out on our newly generated CFIA dataset consisting of 1000 unique identities with 2000 bona fide samples and 14000 CFIA samples, thus resulting in an overall 16000 face image samples. We perform a sequence of experiments to benchmark the vulnerability of CFIA to automatic FRS (based on both deep-learning and commercial-off-the-shelf (COTS). We introduced a new metric named Generalized Morphing Attack Potential (GMAP) to benchmark the vulnerability effectively. Additional experiments are performed to compute the perceptual quality of the generated CFIA samples. Finally, the CFIA detection performance is presented using three different Face Morphing Attack Detection (MAD) algorithms. The proposed CFIA method indicates good perceptual quality based on the obtained results. Further, { FRS is vulnerable to CFIA} (much higher than SOTA), making it difficult to detect by human observers and automatic detection algorithms. Lastly, we performed experiments to detect the CFIA samples using three different detection techniques automatically.
Uncover Common Facial Expressions in Terracotta Warriors: A Deep Learning Approach
May 11, 2021


Can advanced deep learning technologies be applied to analyze some ancient humanistic arts? Can deep learning technologies be directly applied to special scenes such as facial expression analysis of Terracotta Warriors? The big challenging is that the facial features of the Terracotta Warriors are very different from today's people. We found that it is very poor to directly use the models that have been trained on other classic facial expression datasets to analyze the facial expressions of the Terracotta Warriors. At the same time, the lack of public high-quality facial expression data of the Terracotta Warriors also limits the use of deep learning technologies. Therefore, we firstly use Generative Adversarial Networks (GANs) to generate enough high-quality facial expression data for subsequent training and recognition. We also verify the effectiveness of this approach. For the first time, this paper uses deep learning technologies to find common facial expressions of general and postured Terracotta Warriors. These results will provide an updated technical means for the research of art of the Terracotta Warriors and shine lights on the research of other ancient arts.
Cascaded Asymmetric Local Pattern: A Novel Descriptor for Unconstrained Facial Image Recognition and Retrieval
Jan 03, 2022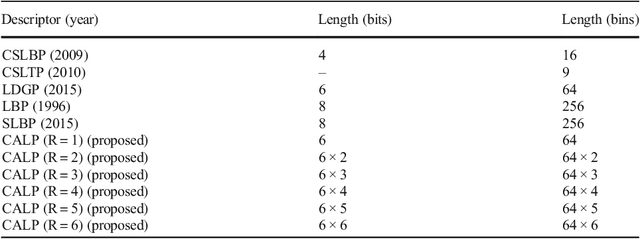
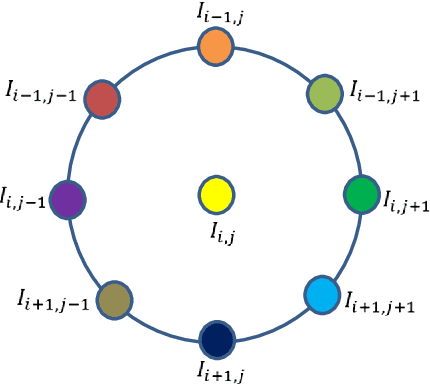
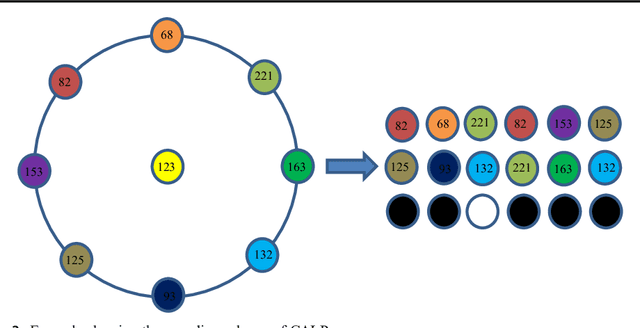

Feature description is one of the most frequently studied areas in the expert systems and machine learning. Effective encoding of the images is an essential requirement for accurate matching. These encoding schemes play a significant role in recognition and retrieval systems. Facial recognition systems should be effective enough to accurately recognize individuals under intrinsic and extrinsic variations of the system. The templates or descriptors used in these systems encode spatial relationships of the pixels in the local neighbourhood of an image. Features encoded using these hand crafted descriptors should be robust against variations such as; illumination, background, poses, and expressions. In this paper a novel hand crafted cascaded asymmetric local pattern (CALP) is proposed for retrieval and recognition facial image. The proposed descriptor uniquely encodes relationship amongst the neighbouring pixels in horizontal and vertical directions. The proposed encoding scheme has optimum feature length and shows significant improvement in accuracy under environmental and physiological changes in a facial image. State of the art hand crafted descriptors namely; LBP, LDGP, CSLBP, SLBP and CSLTP are compared with the proposed descriptor on most challenging datasets namely; Caltech-face, LFW, and CASIA-face-v5. Result analysis shows that, the proposed descriptor outperforms state of the art under uncontrolled variations in expressions, background, pose and illumination.
Toward Affective XAI: Facial Affect Analysis for Understanding Explainable Human-AI Interactions
Jun 16, 2021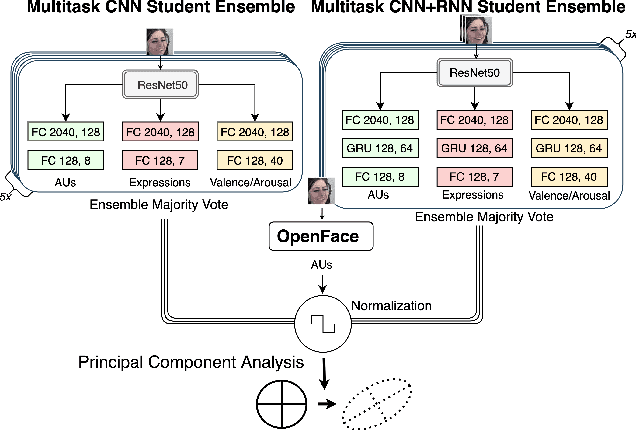
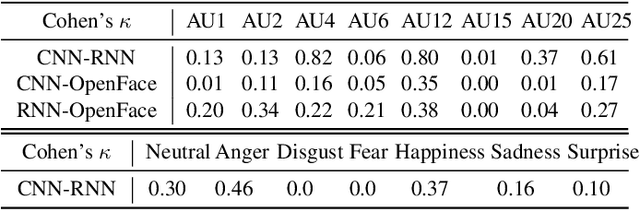
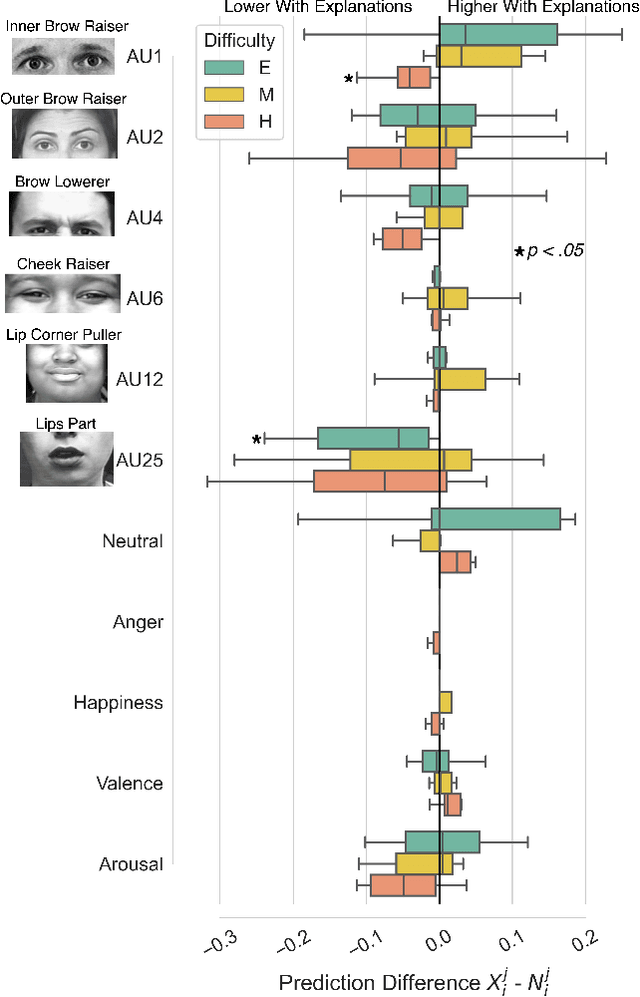
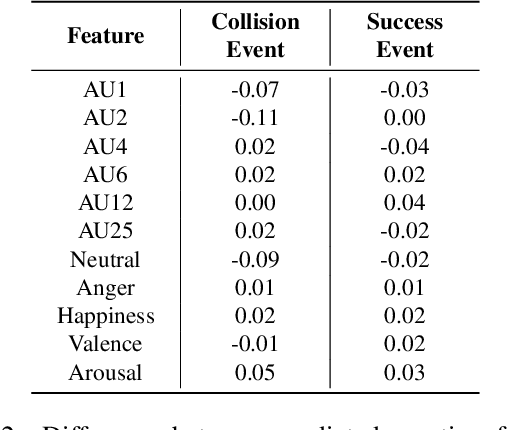
As machine learning approaches are increasingly used to augment human decision-making, eXplainable Artificial Intelligence (XAI) research has explored methods for communicating system behavior to humans. However, these approaches often fail to account for the emotional responses of humans as they interact with explanations. Facial affect analysis, which examines human facial expressions of emotions, is one promising lens for understanding how users engage with explanations. Therefore, in this work, we aim to (1) identify which facial affect features are pronounced when people interact with XAI interfaces, and (2) develop a multitask feature embedding for linking facial affect signals with participants' use of explanations. Our analyses and results show that the occurrence and values of facial AU1 and AU4, and Arousal are heightened when participants fail to use explanations effectively. This suggests that facial affect analysis should be incorporated into XAI to personalize explanations to individuals' interaction styles and to adapt explanations based on the difficulty of the task performed.