 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Private Facial Diagnosis as an Edge Service for Parkinson's DBS Treatment Valuation
May 16, 2021
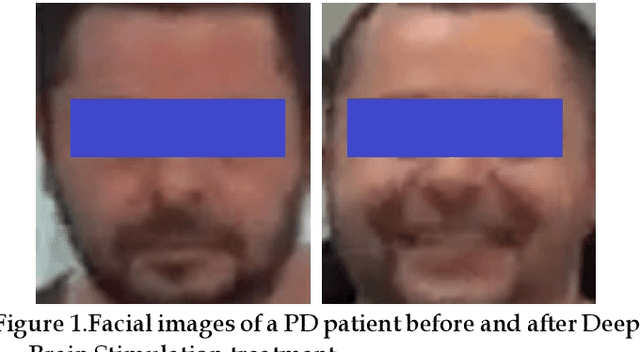

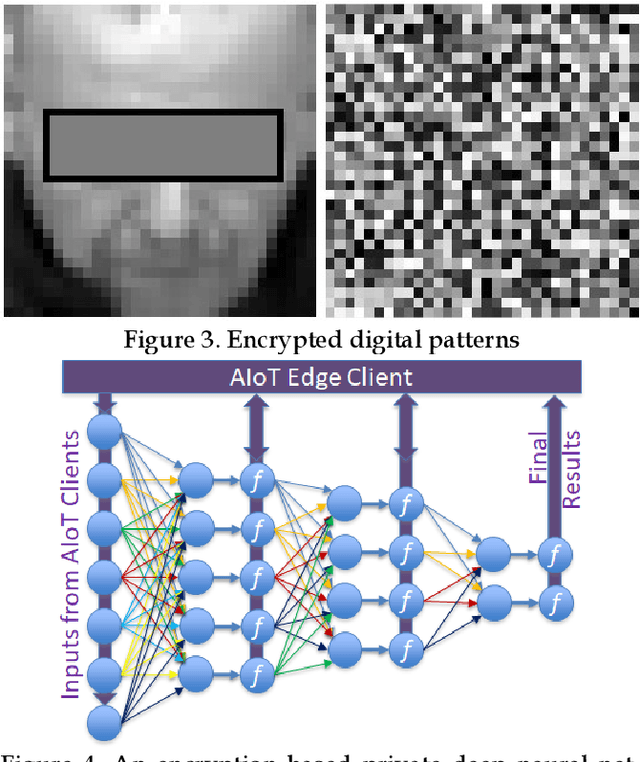
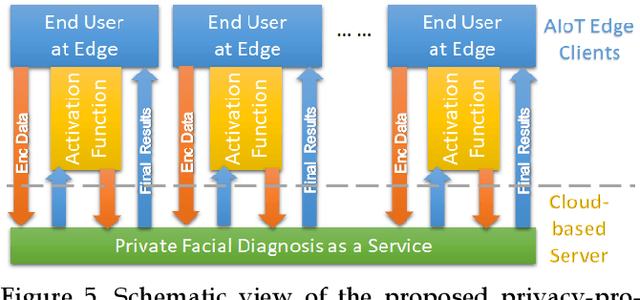
Facial phenotyping has recently been successfully exploited for medical diagnosis as a novel way to diagnose a range of diseases, where facial biometrics has been revealed to have rich links to underlying genetic or medical causes. In this paper, taking Parkinson's Diseases (PD) as a case study, we proposed an Artificial-Intelligence-of-Things (AIoT) edge-oriented privacy-preserving facial diagnosis framework to analyze the treatment of Deep Brain Stimulation (DBS) on PD patients. In the proposed framework, a new edge-based information theoretically secure framework is proposed to implement private deep facial diagnosis as a service over a privacy-preserving AIoT-oriented multi-party communication scheme, where partial homomorphic encryption (PHE) is leveraged to enable privacy-preserving deep facial diagnosis directly on encrypted facial patterns. In our experiments with a collected facial dataset from PD patients, for the first time, we demonstrated that facial patterns could be used to valuate the improvement of PD patients undergoing DBS treatment. We further implemented a privacy-preserving deep facial diagnosis framework that can achieve the same accuracy as the non-encrypted one, showing the potential of our privacy-preserving facial diagnosis as an trustworthy edge service for grading the severity of PD in patients.
LipFormer: Learning to Lipread Unseen Speakers based on Visual-Landmark Transformers
Feb 04, 2023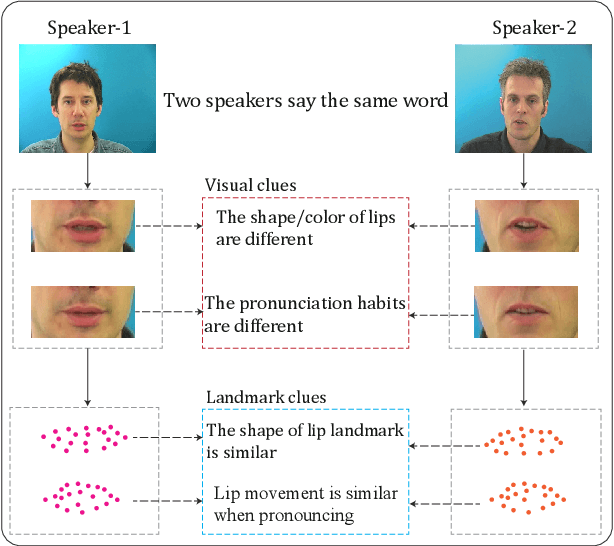
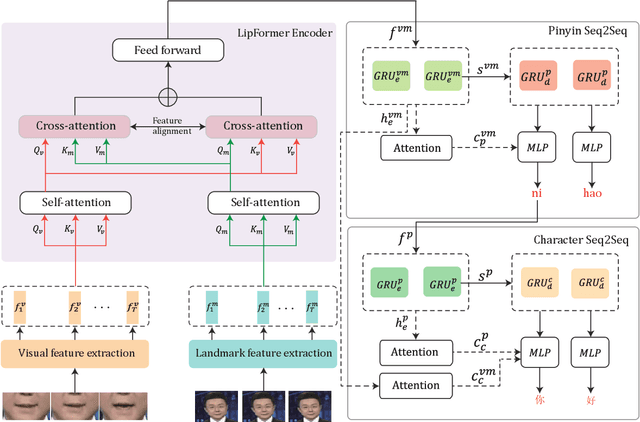
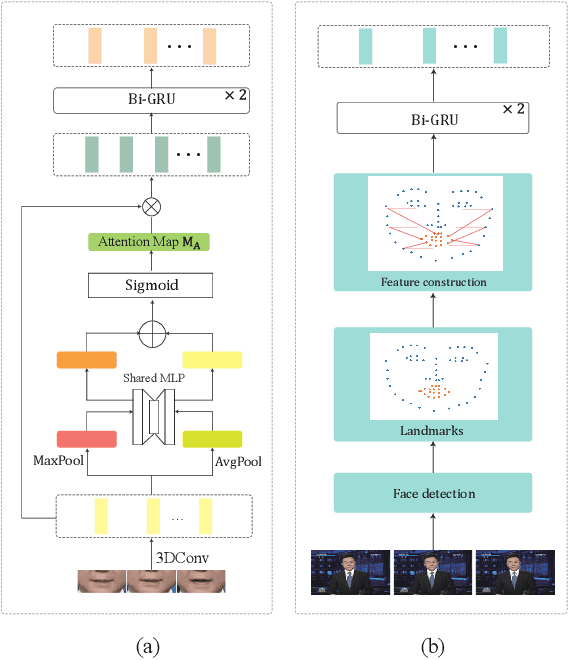

Lipreading refers to understanding and further translating the speech of a speaker in the video into natural language. State-of-the-art lipreading methods excel in interpreting overlap speakers, i.e., speakers appear in both training and inference sets. However, generalizing these methods to unseen speakers incurs catastrophic performance degradation due to the limited number of speakers in training bank and the evident visual variations caused by the shape/color of lips for different speakers. Therefore, merely depending on the visible changes of lips tends to cause model overfitting. To address this problem, we propose to use multi-modal features across visual and landmarks, which can describe the lip motion irrespective to the speaker identities. Then, we develop a sentence-level lipreading framework based on visual-landmark transformers, namely LipFormer. Specifically, LipFormer consists of a lip motion stream, a facial landmark stream, and a cross-modal fusion. The embeddings from the two streams are produced by self-attention, which are fed to the cross-attention module to achieve the alignment between visuals and landmarks. Finally, the resulting fused features can be decoded to output texts by a cascade seq2seq model. Experiments demonstrate that our method can effectively enhance the model generalization to unseen speakers.
Ethically aligned Deep Learning: Unbiased Facial Aesthetic Prediction
Nov 09, 2021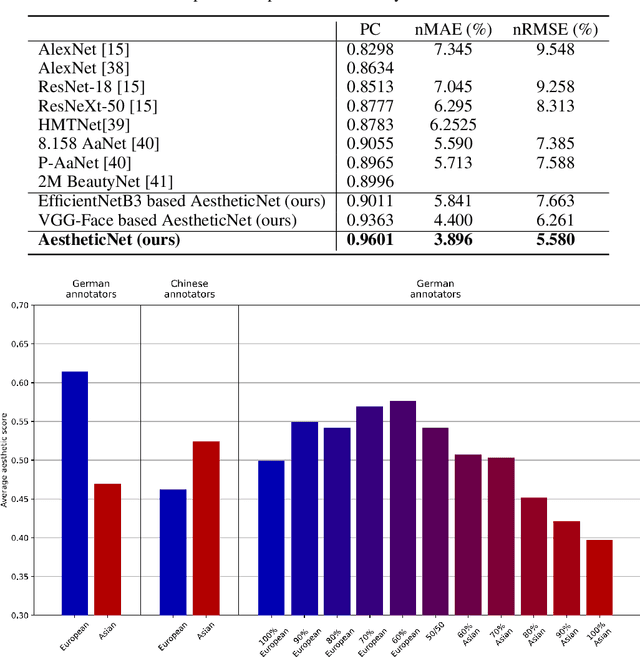
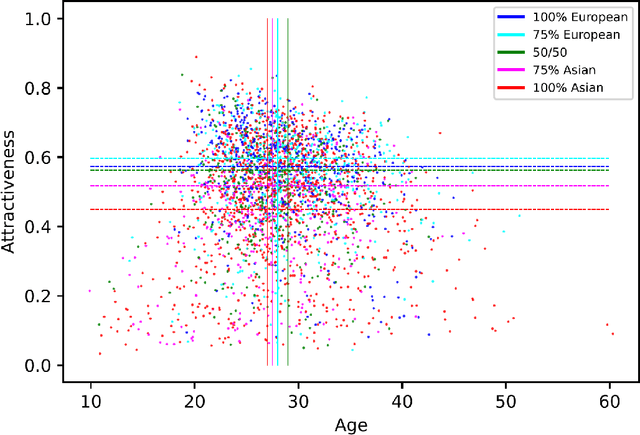
Facial beauty prediction (FBP) aims to develop a machine that automatically makes facial attractiveness assessment. In the past those results were highly correlated with human ratings, therefore also with their bias in annotating. As artificial intelligence can have racist and discriminatory tendencies, the cause of skews in the data must be identified. Development of training data and AI algorithms that are robust against biased information is a new challenge for scientists. As aesthetic judgement usually is biased, we want to take it one step further and propose an Unbiased Convolutional Neural Network for FBP. While it is possible to create network models that can rate attractiveness of faces on a high level, from an ethical point of view, it is equally important to make sure the model is unbiased. In this work, we introduce AestheticNet, a state-of-the-art attractiveness prediction network, which significantly outperforms competitors with a Pearson Correlation of 0.9601. Additionally, we propose a new approach for generating a bias-free CNN to improve fairness in machine learning.
Bridging the Emotional Semantic Gap via Multimodal Relevance Estimation
Feb 03, 2023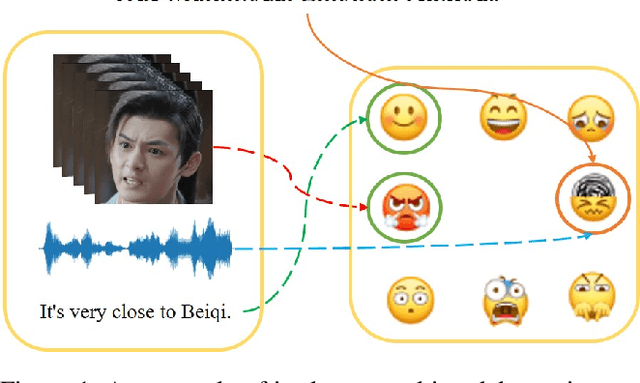

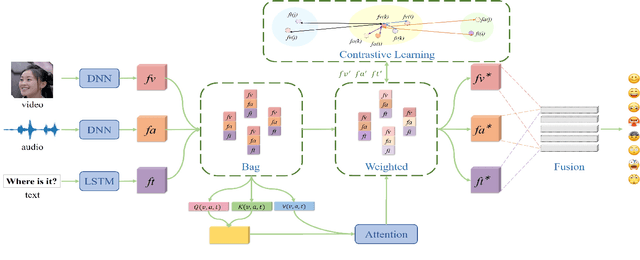
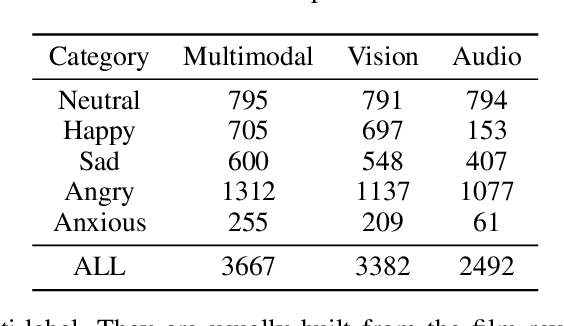
Human beings have rich ways of emotional expressions, including facial action, voice, and natural languages. Due to the diversity and complexity of different individuals, the emotions expressed by various modalities may be semantically irrelevant. Directly fusing information from different modalities may inevitably make the model subject to the noise from semantically irrelevant modalities. To tackle this problem, we propose a multimodal relevance estimation network to capture the relevant semantics among modalities in multimodal emotions. Specifically, we take advantage of an attention mechanism to reflect the semantic relevance weights of each modality. Moreover, we propose a relevant semantic estimation loss to weakly supervise the semantics of each modality. Furthermore, we make use of contrastive learning to optimize the similarity of category-level modality-relevant semantics across different modalities in feature space, thereby bridging the semantic gap between heterogeneous modalities. In order to better reflect the emotional state in the real interactive scenarios and perform the semantic relevance analysis, we collect a single-label discrete multimodal emotion dataset named SDME, which enables researchers to conduct multimodal semantic relevance research with large category bias. Experiments on continuous and discrete emotion datasets show that our model can effectively capture the relevant semantics, especially for the large deviations in modal semantics. The code and SDME dataset will be publicly available.
A Planning-Based Explainable Collaborative Dialogue System
Feb 19, 2023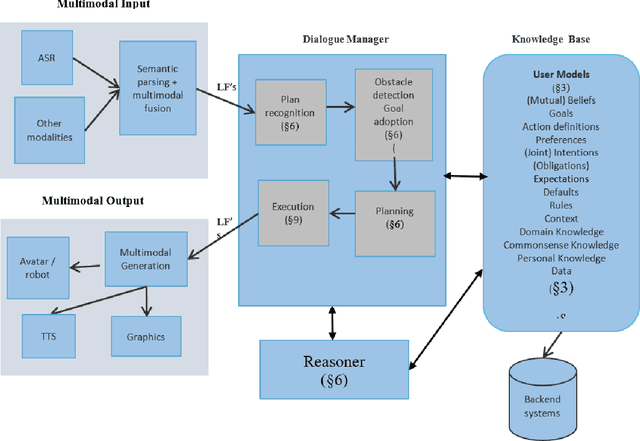
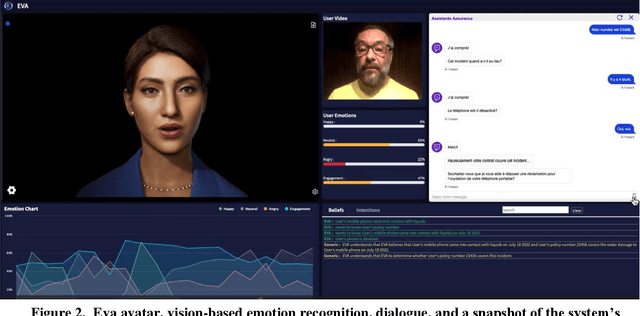

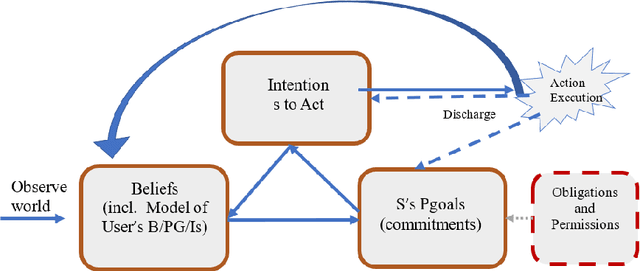
Eva is a multimodal conversational system that helps users to accomplish their domain goals through collaborative dialogue. The system does this by inferring users' intentions and plans to achieve those goals, detects whether obstacles are present, finds plans to overcome them or to achieve higher-level goals, and plans its actions, including speech acts,to help users accomplish those goals. In doing so, the system maintains and reasons with its own beliefs, goals and intentions, and explicitly reasons about those of its user. Belief reasoning is accomplished with a modal Horn-clause meta-interpreter. The planning and reasoning subsystems obey the principles of persistent goals and intentions, including the formation and decomposition of intentions to perform complex actions, as well as the conditions under which they can be given up. In virtue of its planning process, the system treats its speech acts just like its other actions -- physical acts affect physical states, digital acts affect digital states, and speech acts affect mental and social states. This general approach enables Eva to plan a variety of speech acts including requests, informs, questions, confirmations, recommendations, offers, acceptances, greetings, and emotive expressions. Each of these has a formally specified semantics which is used during the planning and reasoning processes. Because it can keep track of different users' mental states, it can engage in multi-party dialogues. Importantly, Eva can explain its utterances because it has created a plan standing behind each of them. Finally, Eva employs multimodal input and output, driving an avatar that can perceive and employ facial and head movements along with emotive speech acts.
Cascaded Asymmetric Local Pattern: A Novel Descriptor for Unconstrained Facial Image Recognition and Retrieval
Jan 03, 2022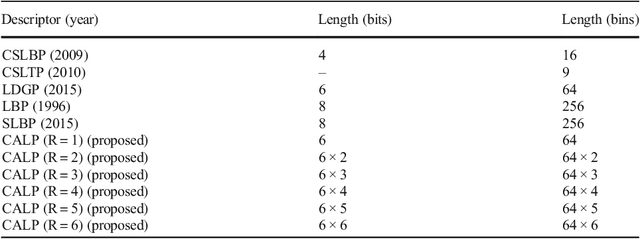
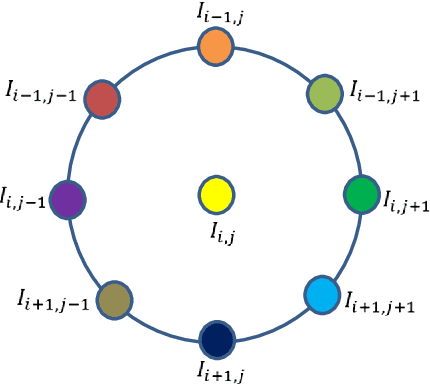
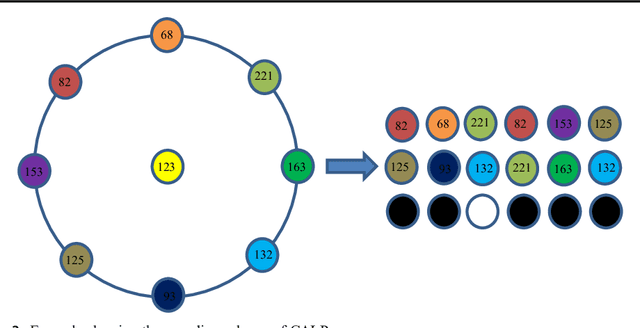

Feature description is one of the most frequently studied areas in the expert systems and machine learning. Effective encoding of the images is an essential requirement for accurate matching. These encoding schemes play a significant role in recognition and retrieval systems. Facial recognition systems should be effective enough to accurately recognize individuals under intrinsic and extrinsic variations of the system. The templates or descriptors used in these systems encode spatial relationships of the pixels in the local neighbourhood of an image. Features encoded using these hand crafted descriptors should be robust against variations such as; illumination, background, poses, and expressions. In this paper a novel hand crafted cascaded asymmetric local pattern (CALP) is proposed for retrieval and recognition facial image. The proposed descriptor uniquely encodes relationship amongst the neighbouring pixels in horizontal and vertical directions. The proposed encoding scheme has optimum feature length and shows significant improvement in accuracy under environmental and physiological changes in a facial image. State of the art hand crafted descriptors namely; LBP, LDGP, CSLBP, SLBP and CSLTP are compared with the proposed descriptor on most challenging datasets namely; Caltech-face, LFW, and CASIA-face-v5. Result analysis shows that, the proposed descriptor outperforms state of the art under uncontrolled variations in expressions, background, pose and illumination.
Whose Emotion Matters? Speaker Detection without Prior Knowledge
Dec 08, 2022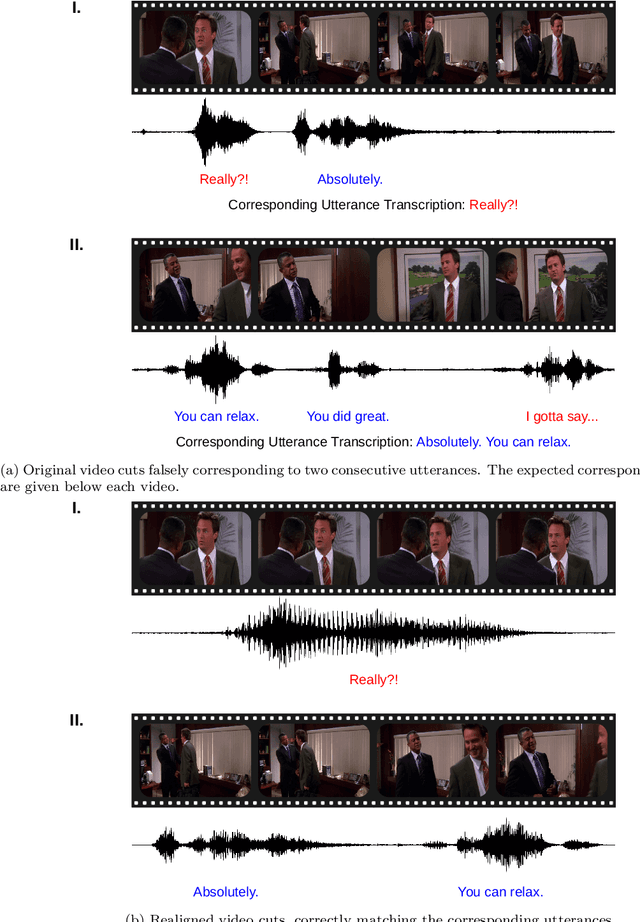

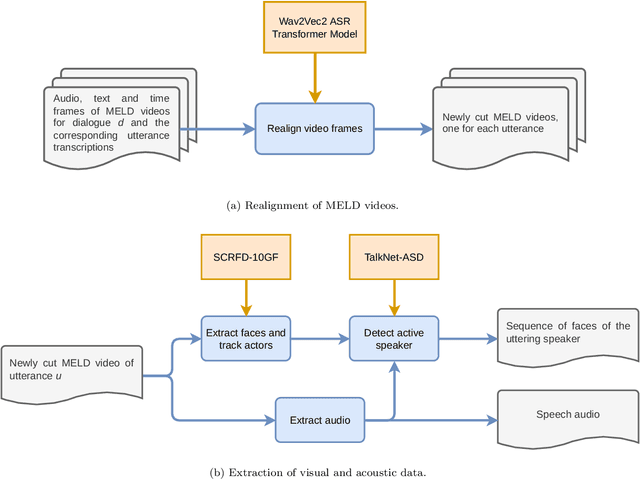
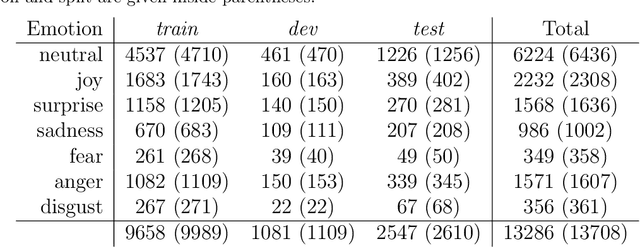
The task of emotion recognition in conversations (ERC) benefits from the availability of multiple modalities, as offered, for example, in the video-based MELD dataset. However, only a few research approaches use both acoustic and visual information from the MELD videos. There are two reasons for this: First, label-to-video alignments in MELD are noisy, making those videos an unreliable source of emotional speech data. Second, conversations can involve several people in the same scene, which requires the detection of the person speaking the utterance. In this paper we demonstrate that by using recent automatic speech recognition and active speaker detection models, we are able to realign the videos of MELD, and capture the facial expressions from uttering speakers in 96.92% of the utterances provided in MELD. Experiments with a self-supervised voice recognition model indicate that the realigned MELD videos more closely match the corresponding utterances offered in the dataset. Finally, we devise a model for emotion recognition in conversations trained on the face and audio information of the MELD realigned videos, which outperforms state-of-the-art models for ERC based on vision alone. This indicates that active speaker detection is indeed effective for extracting facial expressions from the uttering speakers, and that faces provide more informative visual cues than the visual features state-of-the-art models have been using so far.
Uncover Common Facial Expressions in Terracotta Warriors: A Deep Learning Approach
May 11, 2021


Can advanced deep learning technologies be applied to analyze some ancient humanistic arts? Can deep learning technologies be directly applied to special scenes such as facial expression analysis of Terracotta Warriors? The big challenging is that the facial features of the Terracotta Warriors are very different from today's people. We found that it is very poor to directly use the models that have been trained on other classic facial expression datasets to analyze the facial expressions of the Terracotta Warriors. At the same time, the lack of public high-quality facial expression data of the Terracotta Warriors also limits the use of deep learning technologies. Therefore, we firstly use Generative Adversarial Networks (GANs) to generate enough high-quality facial expression data for subsequent training and recognition. We also verify the effectiveness of this approach. For the first time, this paper uses deep learning technologies to find common facial expressions of general and postured Terracotta Warriors. These results will provide an updated technical means for the research of art of the Terracotta Warriors and shine lights on the research of other ancient arts.
InfAnFace: Bridging the infant-adult domain gap in facial landmark estimation in the wild
Oct 17, 2021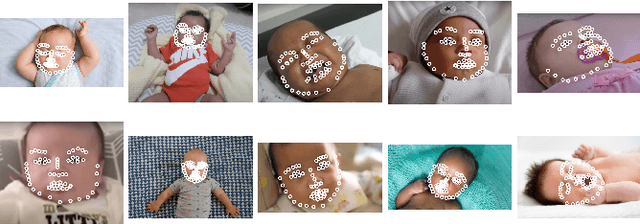
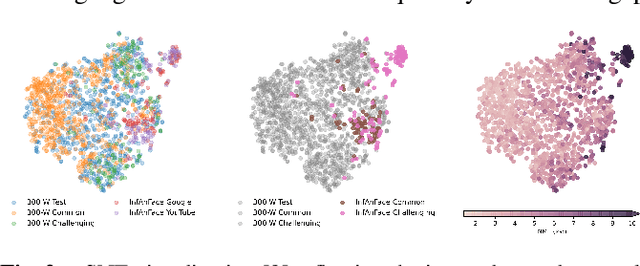
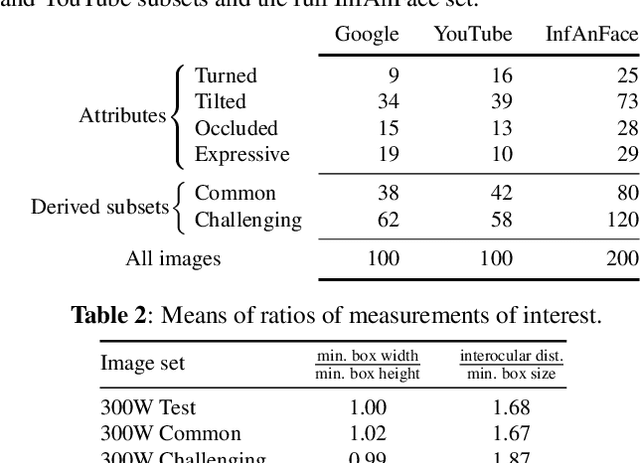
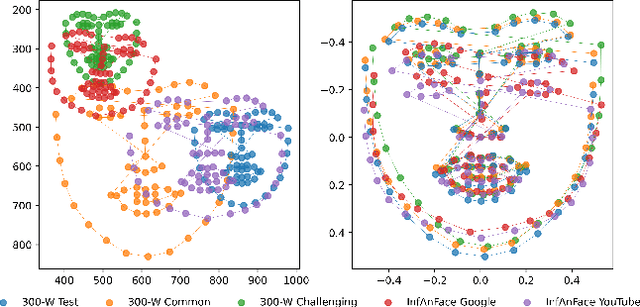
There is promising potential in the application of algorithmic facial landmark estimation to the early prediction, in infants, of pediatric developmental disorders and other conditions. However, the performance of these deep learning algorithms is severely hampered by the scarcity of infant data. To spur the development of facial landmarking systems for infants, we introduce InfAnFace, a diverse, richly-annotated dataset of infant faces. We use InfAnFace to benchmark the performance of existing facial landmark estimation algorithms that are trained on adult faces and demonstrate there is a significant domain gap between the representations learned by these algorithms when applied on infant vs. adult faces. Finally, we put forward the next potential steps to bridge that gap.
Unsupervised Anomaly Appraisal of Cleft Faces Using a StyleGAN2-based Model Adaptation Technique
Nov 12, 2022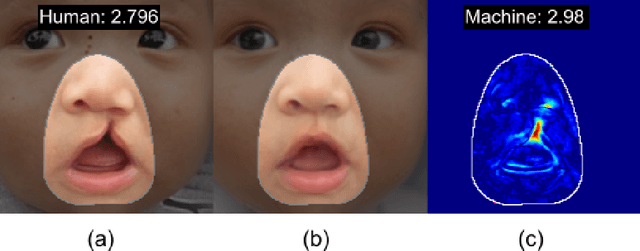
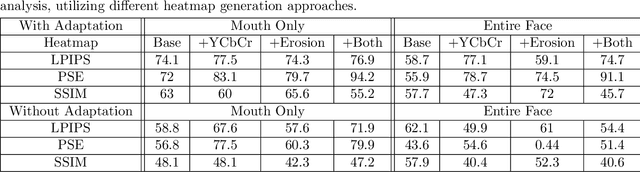
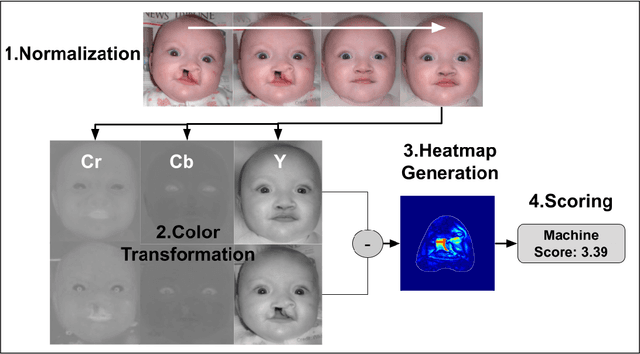
This paper presents a novel machine learning framework to consistently detect, localize and rate congenital cleft lip anomalies in human faces. The goal is to provide a universal, objective measure of facial differences and reconstructive surgical outcomes that matches human judgments. The proposed method employs the StyleGAN2 generative adversarial network with model adaptation to produce normalized transformations of cleft-affected faces in order to allow for subsequent measurement of deformity using a pixel-wise subtraction approach. The complete pipeline of the proposed framework consists of the following steps: image preprocessing, face normalization, color transformation, morphological erosion, heat-map generation and abnormality scoring. Heatmaps that finely discern anatomic anomalies are proposed by exploiting the features of the considered framework. The proposed framework is validated through computer simulations and surveys containing human ratings. The anomaly scores yielded by the proposed computer model correlate closely with the human ratings of facial differences, leading to 0.942 Pearson's r score.