 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Dec 07, 2021
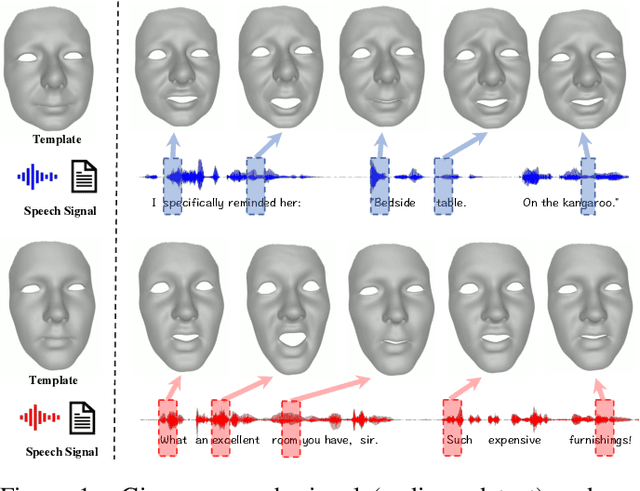
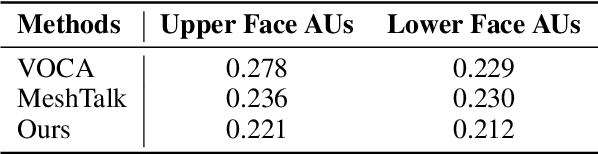
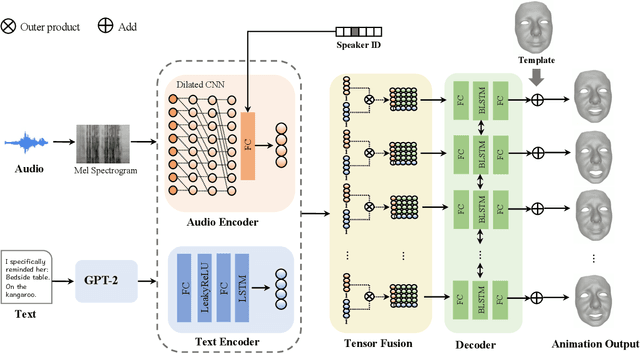
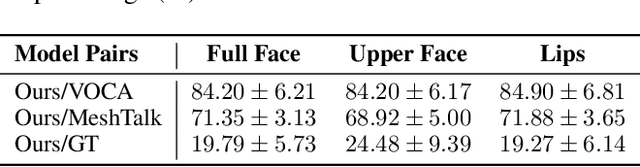
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.
WASD: A Wilder Active Speaker Detection Dataset
Mar 09, 2023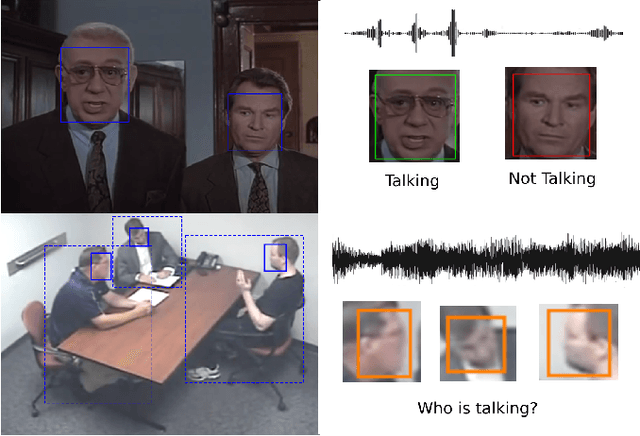

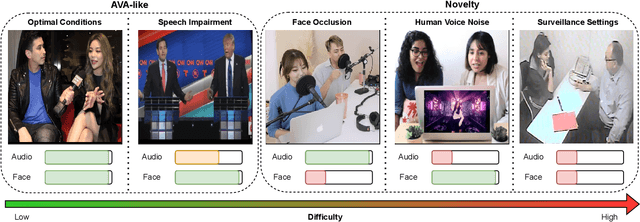
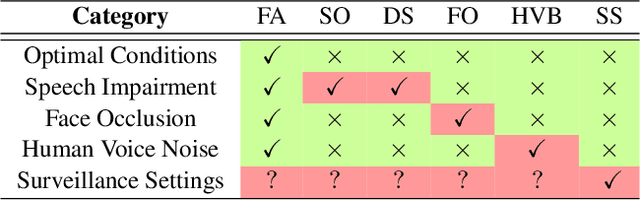
Current Active Speaker Detection (ASD) models achieve great results on AVA-ActiveSpeaker (AVA), using only sound and facial features. Although this approach is applicable in movie setups (AVA), it is not suited for less constrained conditions. To demonstrate this limitation, we propose a Wilder Active Speaker Detection (WASD) dataset, with increased difficulty by targeting the two key components of current ASD: audio and face. Grouped into 5 categories, ranging from optimal conditions to surveillance settings, WASD contains incremental challenges for ASD with tactical impairment of audio and face data. We select state-of-the-art models and assess their performance in two groups of WASD: Easy (cooperative settings) and Hard (audio and/or face are specifically degraded). The results show that: 1) AVA trained models maintain a state-of-the-art performance in WASD Easy group, while underperforming in the Hard one, showing the 2) similarity between AVA and Easy data; and 3) training in WASD does not improve models performance to AVA levels, particularly for audio impairment and surveillance settings. This shows that AVA does not prepare models for wild ASD and current approaches are subpar to deal with such conditions. The proposed dataset also contains body data annotations to provide a new source for ASD, and is available at https://github.com/Tiago-Roxo/WASD.
CoNFies: Controllable Neural Face Avatars
Nov 16, 2022



Neural Radiance Fields (NeRF) are compelling techniques for modeling dynamic 3D scenes from 2D image collections. These volumetric representations would be well suited for synthesizing novel facial expressions but for two problems. First, deformable NeRFs are object agnostic and model holistic movement of the scene: they can replay how the motion changes over time, but they cannot alter it in an interpretable way. Second, controllable volumetric representations typically require either time-consuming manual annotations or 3D supervision to provide semantic meaning to the scene. We propose a controllable neural representation for face self-portraits (CoNFies), that solves both of these problems within a common framework, and it can rely on automated processing. We use automated facial action recognition (AFAR) to characterize facial expressions as a combination of action units (AU) and their intensities. AUs provide both the semantic locations and control labels for the system. CoNFies outperformed competing methods for novel view and expression synthesis in terms of visual and anatomic fidelity of expressions.
PERI: Part Aware Emotion Recognition In The Wild
Oct 18, 2022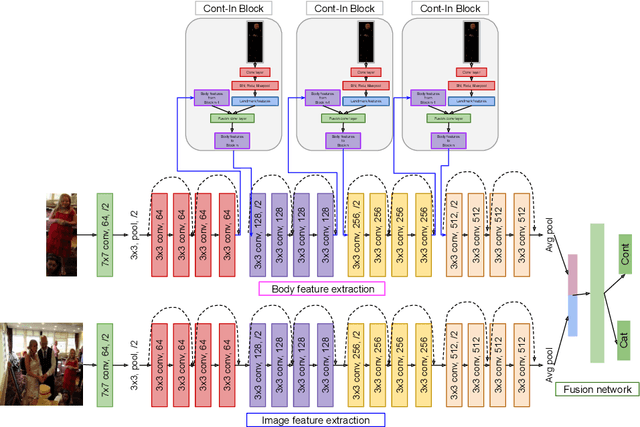
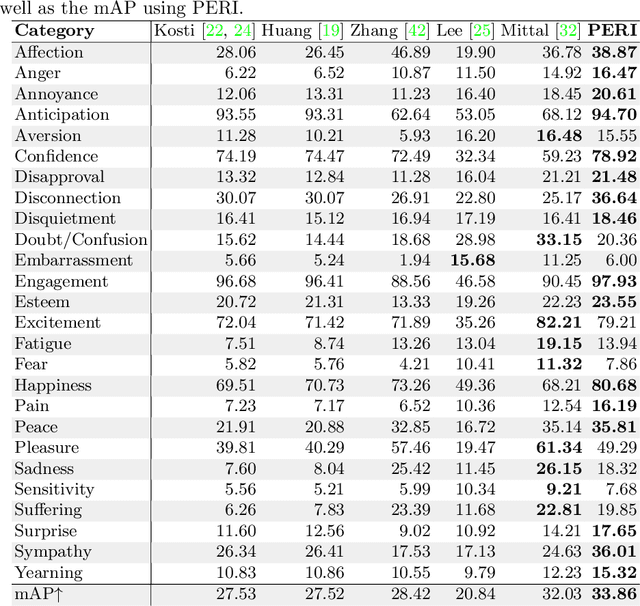
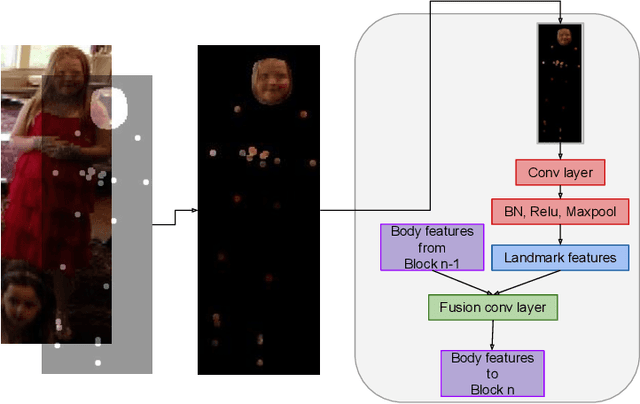
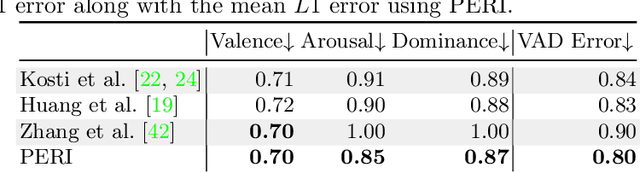
Emotion recognition aims to interpret the emotional states of a person based on various inputs including audio, visual, and textual cues. This paper focuses on emotion recognition using visual features. To leverage the correlation between facial expression and the emotional state of a person, pioneering methods rely primarily on facial features. However, facial features are often unreliable in natural unconstrained scenarios, such as in crowded scenes, as the face lacks pixel resolution and contains artifacts due to occlusion and blur. To address this, in the wild emotion recognition exploits full-body person crops as well as the surrounding scene context. In a bid to use body pose for emotion recognition, such methods fail to realize the potential that facial expressions, when available, offer. Thus, the aim of this paper is two-fold. First, we demonstrate our method, PERI, to leverage both body pose and facial landmarks. We create part aware spatial (PAS) images by extracting key regions from the input image using a mask generated from both body pose and facial landmarks. This allows us to exploit body pose in addition to facial context whenever available. Second, to reason from the PAS images, we introduce context infusion (Cont-In) blocks. These blocks attend to part-specific information, and pass them onto the intermediate features of an emotion recognition network. Our approach is conceptually simple and can be applied to any existing emotion recognition method. We provide our results on the publicly available in the wild EMOTIC dataset. Compared to existing methods, PERI achieves superior performance and leads to significant improvements in the mAP of emotion categories, while decreasing Valence, Arousal and Dominance errors. Importantly, we observe that our method improves performance in both images with fully visible faces as well as in images with occluded or blurred faces.
Facial Emotion Characterization and Detection using Fourier Transform and Machine Learning
Dec 06, 2021

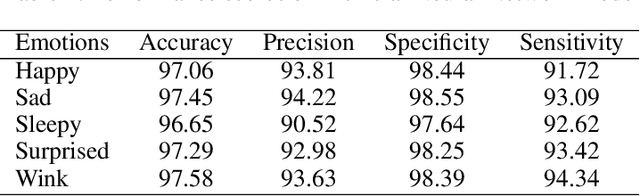
We present a Fourier-based machine learning technique that characterizes and detects facial emotions. The main challenging task in the development of machine learning (ML) models for classifying facial emotions is the detection of accurate emotional features from a set of training samples, and the generation of feature vectors for constructing a meaningful feature space and building ML models. In this paper, we hypothesis that the emotional features are hidden in the frequency domain; hence, they can be captured by leveraging the frequency domain and masking techniques. We also make use of the conjecture that a facial emotions are convoluted with the normal facial features and the other emotional features; however, they carry linearly separable spatial frequencies (we call computational emotional frequencies). Hence, we propose a technique by leveraging fast Fourier transform (FFT) and rectangular narrow-band frequency kernels, and the widely used Yale-Faces image dataset. We test the hypothesis using the performance scores of the random forest (RF) and the artificial neural network (ANN) classifiers as the measures to validate the effectiveness of the captured emotional frequencies. Our finding is that the computational emotional frequencies discovered by the proposed approach provides meaningful emotional features that help RF and ANN achieve a high precision scores above 93%, on average.
Full-Body Cardiovascular Sensing with Remote Photoplethysmography
Mar 16, 2023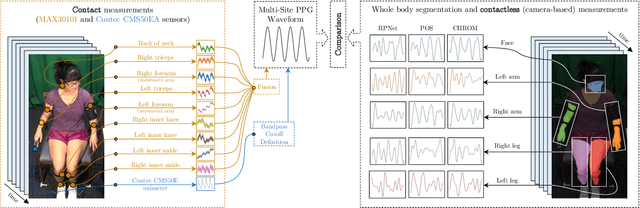


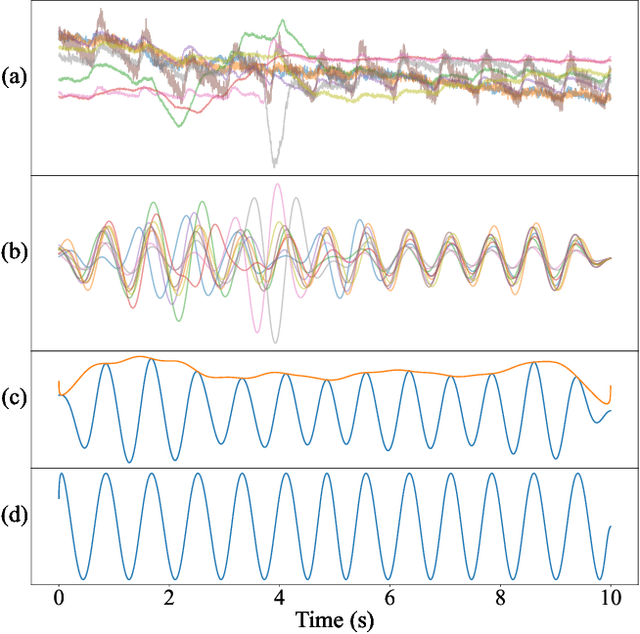
Remote photoplethysmography (rPPG) allows for noncontact monitoring of blood volume changes from a camera by detecting minor fluctuations in reflected light. Prior applications of rPPG focused on face videos. In this paper we explored the feasibility of rPPG from non-face body regions such as the arms, legs, and hands. We collected a new dataset titled Multi-Site Physiological Monitoring (MSPM), which will be released with this paper. The dataset consists of 90 frames per second video of exposed arms, legs, and face, along with 10 synchronized PPG recordings. We performed baseline heart rate estimation experiments from non-face regions with several state-of-the-art rPPG approaches, including chrominance-based (CHROM), plane-orthogonal-to-skin (POS) and RemotePulseNet (RPNet). To our knowledge, this is the first evaluation of the fidelity of rPPG signals simultaneously obtained from multiple regions of a human body. Our experiments showed that skin pixels from arms, legs, and hands are all potential sources of the blood volume pulse. The best-performing approach, POS, achieved a mean absolute error peaking at 7.11 beats per minute from non-facial body parts compared to 1.38 beats per minute from the face. Additionally, we performed experiments on pulse transit time (PTT) from both the contact PPG and rPPG signals. We found that remote PTT is possible with moderately high frame rate video when distal locations on the body are visible. These findings and the supporting dataset should facilitate new research on non-face rPPG and monitoring blood flow dynamics over the whole body with a camera.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023

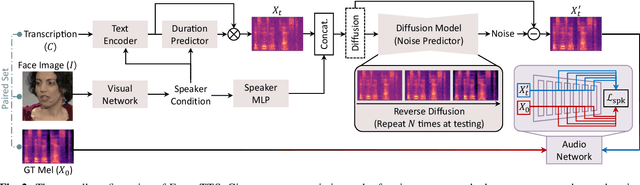
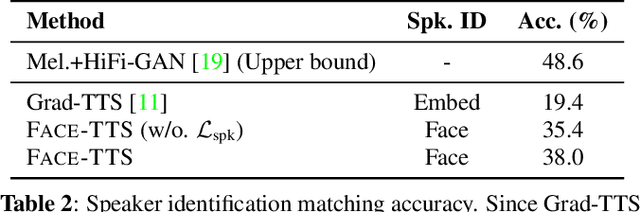
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
A Dataless FaceSwap Detection Approach Using Synthetic Images
Dec 05, 2022
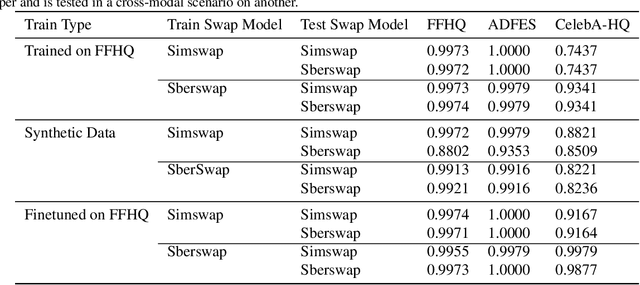

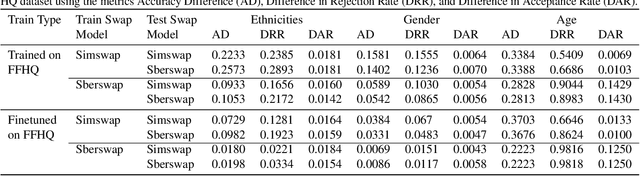
Face swapping technology used to create "Deepfakes" has advanced significantly over the past few years and now enables us to create realistic facial manipulations. Current deep learning algorithms to detect deepfakes have shown promising results, however, they require large amounts of training data, and as we show they are biased towards a particular ethnicity. We propose a deepfake detection methodology that eliminates the need for any real data by making use of synthetically generated data using StyleGAN3. This not only performs at par with the traditional training methodology of using real data but it shows better generalization capabilities when finetuned with a small amount of real data. Furthermore, this also reduces biases created by facial image datasets that might have sparse data from particular ethnicities.
Face Emotion Recognization Using Dataset Augmentation Based on Neural Network
Oct 23, 2022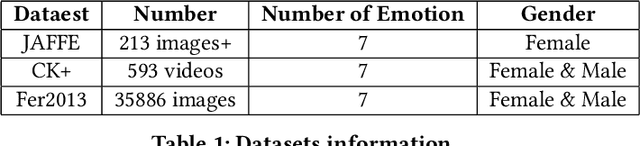
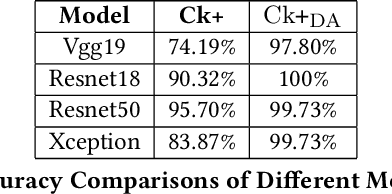

Facial expression is one of the most external indications of a person's feelings and emotions. In daily conversation, according to the psychologist, only 7\% and 38\% of information is communicated through words and sounds respective, while up to 55\% is through facial expression. It plays an important role in coordinating interpersonal relationships. Ekman and Friesen recognized six essential emotions in the nineteenth century depending on a cross-cultural study, which indicated that people feel each basic emotion in the same fashion despite culture. As a branch of the field of analyzing sentiment, facial expression recognition offers broad application prospects in a variety of domains, including the interaction between humans and computers, healthcare, and behavior monitoring. Therefore, many researchers have devoted themselves to facial expression recognition. In this paper, an effective hybrid data augmentation method is used. This approach is operated on two public datasets, and four benchmark models see some remarkable results.
Evaluation of Self-taught Learning-based Representations for Facial Emotion Recognition
Apr 26, 2022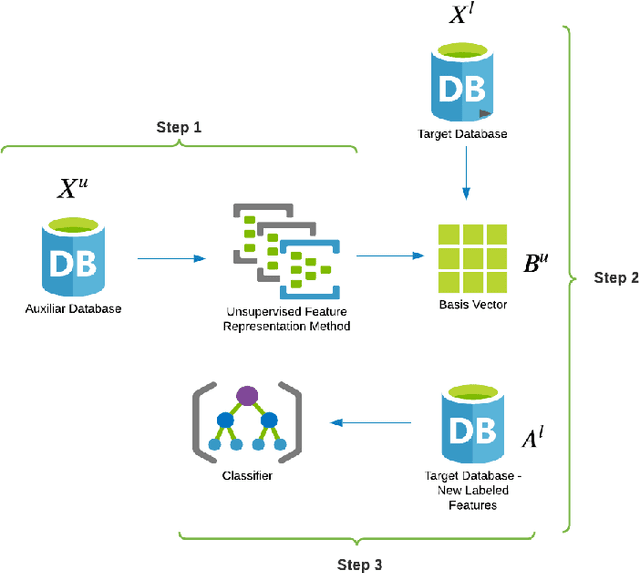
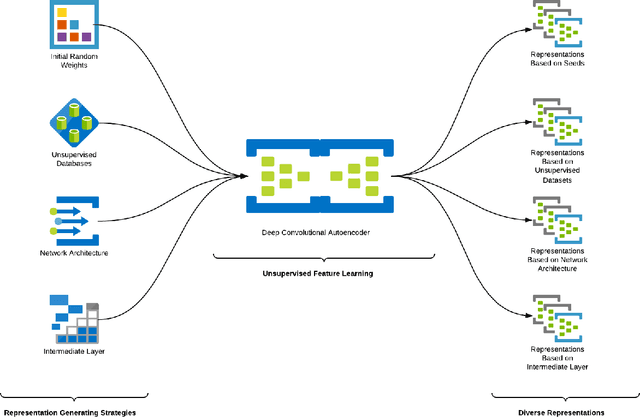


This work describes different strategies to generate unsupervised representations obtained through the concept of self-taught learning for facial emotion recognition (FER). The idea is to create complementary representations promoting diversity by varying the autoencoders' initialization, architecture, and training data. SVM, Bagging, Random Forest, and a dynamic ensemble selection method are evaluated as final classification methods. Experimental results on Jaffe and Cohn-Kanade datasets using a leave-one-subject-out protocol show that FER methods based on the proposed diverse representations compare favorably against state-of-the-art approaches that also explore unsupervised feature learning.