 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Face Super-Resolution with Progressive Embedding of Multi-scale Face Priors
Oct 12, 2022
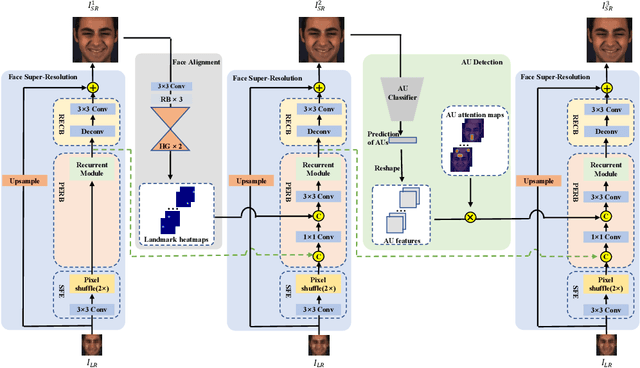
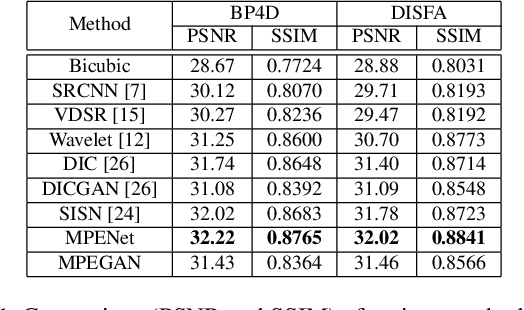

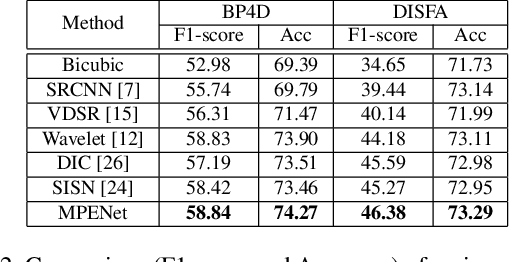
The face super-resolution (FSR) task is to reconstruct high-resolution face images from low-resolution inputs. Recent works have achieved success on this task by utilizing facial priors such as facial landmarks. Most existing methods pay more attention to global shape and structure information, but less to local texture information, which makes them cannot recover local details well. In this paper, we propose a novel recurrent convolutional network based framework for face super-resolution, which progressively introduces both global shape and local texture information. We take full advantage of the intermediate outputs of the recurrent network, and landmarks information and facial action units (AUs) information are extracted in the output of the first and second steps respectively, rather than low-resolution input. Moreover, we introduced AU classification results as a novel quantitative metric for facial details restoration. Extensive experiments show that our proposed method significantly outperforms state-of-the-art FSR methods in terms of image quality and facial details restoration.
A Federated Learning Scheme for Neuro-developmental Disorders: Multi-Aspect ASD Detection
Oct 31, 2022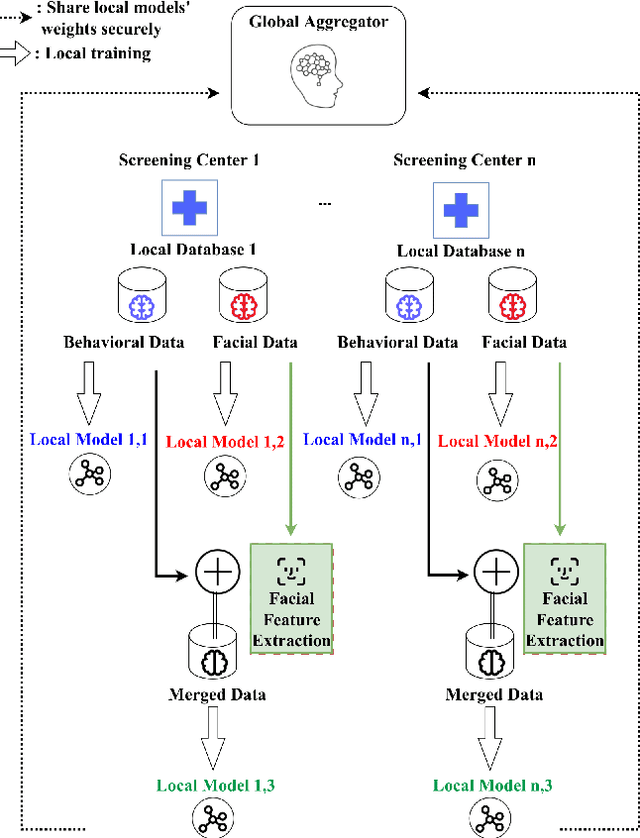


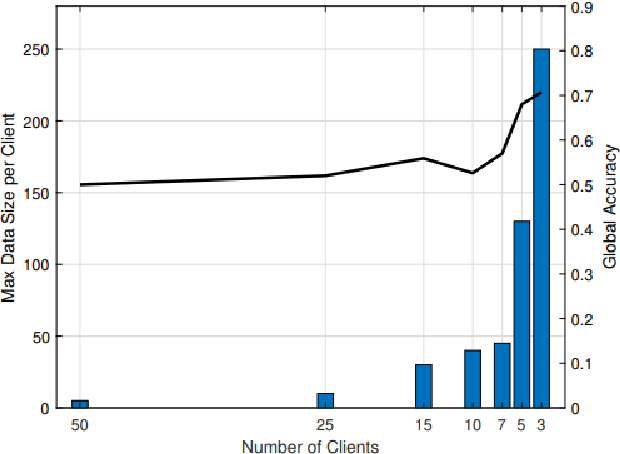
Autism Spectrum Disorder (ASD) is a neuro-developmental syndrome resulting from alterations in the embryological brain before birth. This disorder distinguishes its patients by special socially restricted and repetitive behavior in addition to specific behavioral traits. Hence, this would possibly deteriorate their social behavior among other individuals, as well as their overall interaction within their community. Moreover, medical research has proved that ASD also affects the facial characteristics of its patients, making the syndrome recognizable from distinctive signs within an individual's face. Given that as a motivation behind our work, we propose a novel privacy-preserving federated learning scheme to predict ASD in a certain individual based on their behavioral and facial features, embedding a merging process of both data features through facial feature extraction while respecting patient data privacy. After training behavioral and facial image data on federated machine learning models, promising results are achieved, with 70\% accuracy for the prediction of ASD according to behavioral traits in a federated learning environment, and a 62\% accuracy is reached for the prediction of ASD given an image of the patient's face. Then, we test the behavior of regular as well as federated ML on our merged data, behavioral and facial, where a 65\% accuracy is achieved with the regular logistic regression model and 63\% accuracy with the federated learning model.
Cluster-based Deep Ensemble Learning for Emotion Classification in Internet Memes
Feb 16, 2023
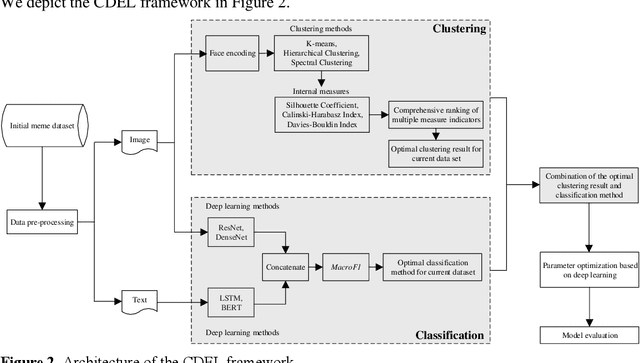

Memes have gained popularity as a means to share visual ideas through the Internet and social media by mixing text, images and videos, often for humorous purposes. Research enabling automated analysis of memes has gained attention in recent years, including among others the task of classifying the emotion expressed in memes. In this paper, we propose a novel model, cluster-based deep ensemble learning (CDEL), for emotion classification in memes. CDEL is a hybrid model that leverages the benefits of a deep learning model in combination with a clustering algorithm, which enhances the model with additional information after clustering memes with similar facial features. We evaluate the performance of CDEL on a benchmark dataset for emotion classification, proving its effectiveness by outperforming a wide range of baseline models and achieving state-of-the-art performance. Further evaluation through ablated models demonstrates the effectiveness of the different components of CDEL.
Generating Dataset For Large-scale 3D Facial Emotion Recognition
Sep 16, 2021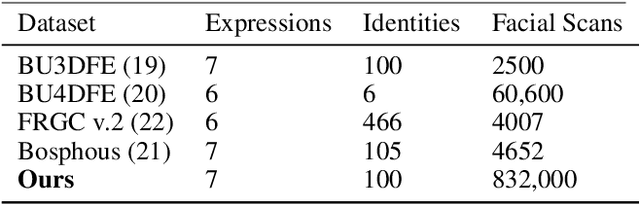
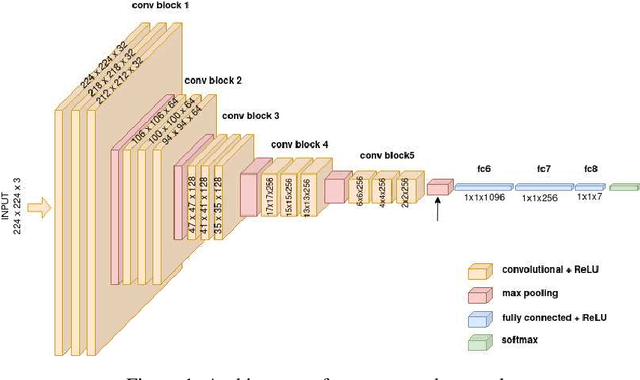
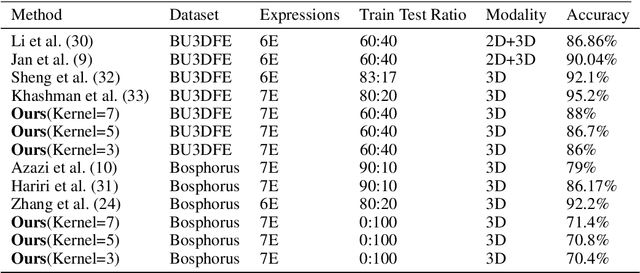
The tremendous development in deep learning has led facial expression recognition (FER) to receive much attention in the past few years. Although 3D FER has an inherent edge over its 2D counterpart, work on 2D images has dominated the field. The main reason for the slow development of 3D FER is the unavailability of large training and large test datasets. Recognition accuracies have already saturated on existing 3D emotion recognition datasets due to their small gallery sizes. Unlike 2D photographs, 3D facial scans are not easy to collect, causing a bottleneck in the development of deep 3D FER networks and datasets. In this work, we propose a method for generating a large dataset of 3D faces with labeled emotions. We also develop a deep convolutional neural network(CNN) for 3D FER trained on 624,000 3D facial scans. The test data comprises 208,000 3D facial scans.
Are Face Detection Models Biased?
Nov 07, 2022

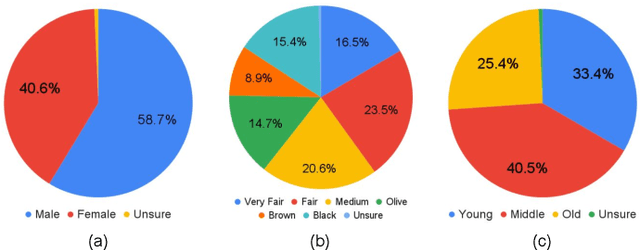

The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. Research in bias focuses primarily on facial recognition and attribute prediction with scarce emphasis on face detection. Existing studies consider face detection as binary classification into 'face' and 'non-face' classes. In this work, we investigate possible bias in the domain of face detection through facial region localization which is currently unexplored. Since facial region localization is an essential task for all face recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Most existing face detection datasets lack suitable annotation for such analysis. Therefore, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. Utilizing the extensive annotations from F2LA, an experimental setup is designed to study the performance of four pre-trained face detectors. We observe (i) a high disparity in detection accuracies across gender and skin-tone, and (ii) interplay of confounding factors beyond demography. The F2LA data and associated annotations can be accessed at http://iab-rubric.org/index.php/F2LA.
Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars
Nov 21, 2022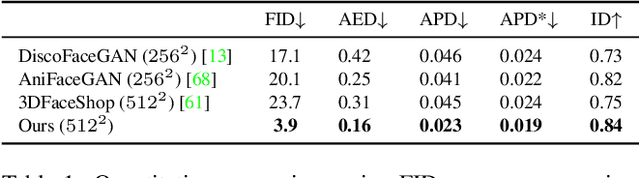
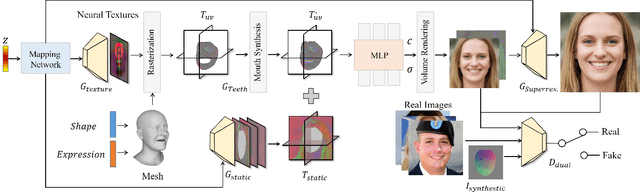
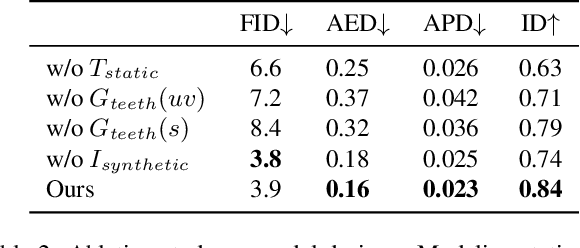
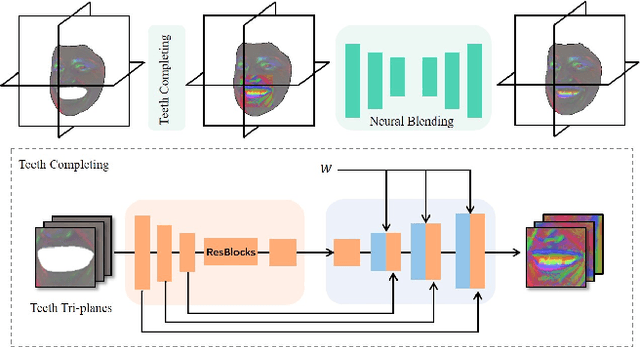
3D-aware generative adversarial networks (GANs) synthesize high-fidelity and multi-view-consistent facial images using only collections of single-view 2D imagery. Towards fine-grained control over facial attributes, recent efforts incorporate 3D Morphable Face Model (3DMM) to describe deformation in generative radiance fields either explicitly or implicitly. Explicit methods provide fine-grained expression control but cannot handle topological changes caused by hair and accessories, while implicit ones can model varied topologies but have limited generalization caused by the unconstrained deformation fields. We propose a novel 3D GAN framework for unsupervised learning of generative, high-quality and 3D-consistent facial avatars from unstructured 2D images. To achieve both deformation accuracy and topological flexibility, we propose a 3D representation called Generative Texture-Rasterized Tri-planes. The proposed representation learns Generative Neural Textures on top of parametric mesh templates and then projects them into three orthogonal-viewed feature planes through rasterization, forming a tri-plane feature representation for volume rendering. In this way, we combine both fine-grained expression control of mesh-guided explicit deformation and the flexibility of implicit volumetric representation. We further propose specific modules for modeling mouth interior which is not taken into account by 3DMM. Our method demonstrates state-of-the-art 3D-aware synthesis quality and animation ability through extensive experiments. Furthermore, serving as 3D prior, our animatable 3D representation boosts multiple applications including one-shot facial avatars and 3D-aware stylization.
Fighting noise and imbalance in Action Unit detection problems
Mar 06, 2023

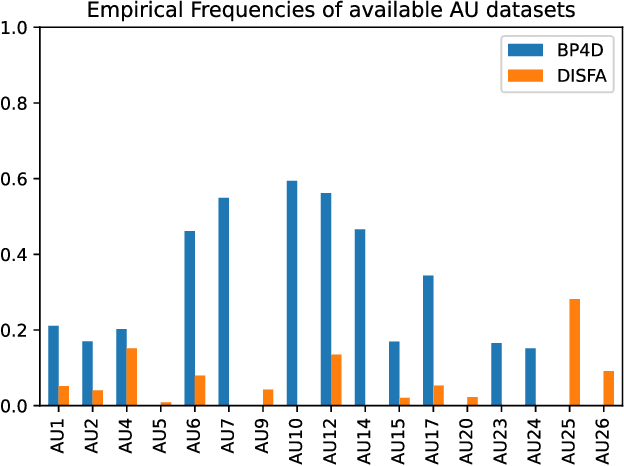
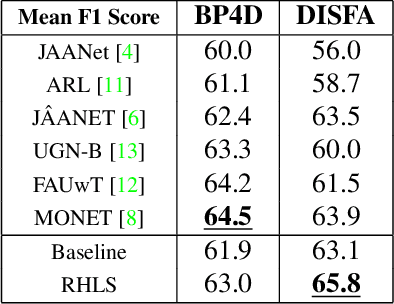
Action Unit (AU) detection aims at automatically caracterizing facial expressions with the muscular activations they involve. Its main interest is to provide a low-level face representation that can be used to assist higher level affective computing tasks learning. Yet, it is a challenging task. Indeed, the available databases display limited face variability and are imbalanced toward neutral expressions. Furthermore, as AU involve subtle face movements they are difficult to annotate so that some of the few provided datapoints may be mislabeled. In this work, we aim at exploiting label smoothing ability to mitigate noisy examples impact by reducing confidence [1]. However, applying label smoothing as it is may aggravate imbalance-based pre-existing under-confidence issue and degrade performance. To circumvent this issue, we propose Robin Hood Label Smoothing (RHLS). RHLS principle is to restrain label smoothing confidence reduction to the majority class. In that extent, it alleviates both the imbalance-based over-confidence issue and the negative impact of noisy majority class examples. From an experimental standpoint, we show that RHLS provides a free performance improvement in AU detection. In particular, by applying it on top of a modern multi-task baseline we get promising results on BP4D and outperform state-of-the-art methods on DISFA.
Research on facial expression recognition based on Multimodal data fusion and neural network
Sep 26, 2021
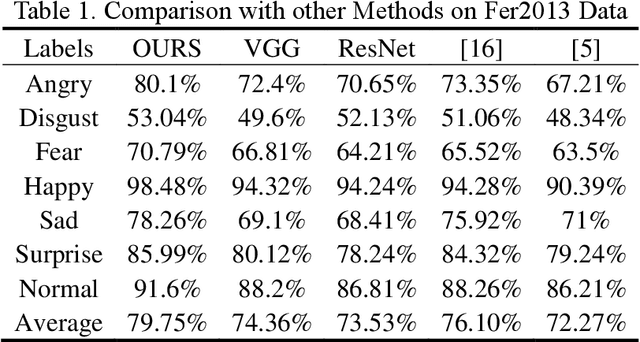
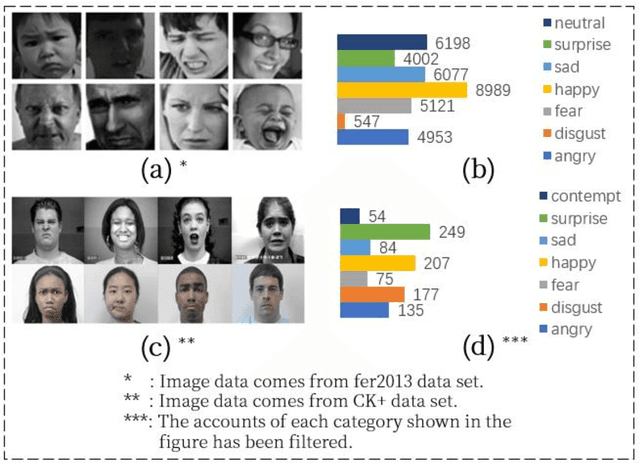
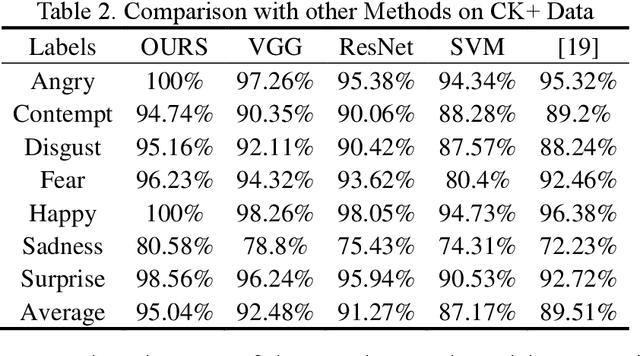
Facial expression recognition is a challenging task when neural network is applied to pattern recognition. Most of the current recognition research is based on single source facial data, which generally has the disadvantages of low accuracy and low robustness. In this paper, a neural network algorithm of facial expression recognition based on multimodal data fusion is proposed. The algorithm is based on the multimodal data, and it takes the facial image, the histogram of oriented gradient of the image and the facial landmarks as the input, and establishes CNN, LNN and HNN three sub neural networks to extract data features, using multimodal data feature fusion mechanism to improve the accuracy of facial expression recognition. Experimental results show that, benefiting by the complementarity of multimodal data, the algorithm has a great improvement in accuracy, robustness and detection speed compared with the traditional facial expression recognition algorithm. Especially in the case of partial occlusion, illumination and head posture transformation, the algorithm also shows a high confidence.
ABAW: Valence-Arousal Estimation, Expression Recognition, Action Unit Detection & Emotional Reaction Intensity Estimation Challenges
Mar 10, 2023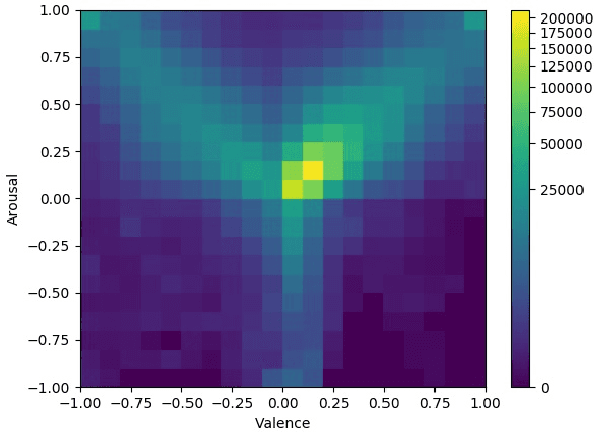
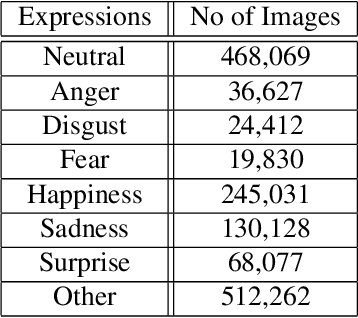
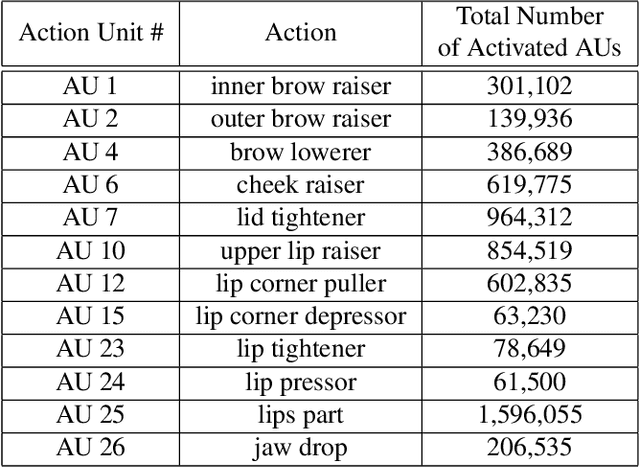

The fifth Affective Behavior Analysis in-the-wild (ABAW) Competition is part of the respective ABAW Workshop which will be held in conjunction with IEEE Computer Vision and Pattern Recognition Conference (CVPR), 2023. The 5th ABAW Competition is a continuation of the Competitions held at ECCV 2022, IEEE CVPR 2022, ICCV 2021, IEEE FG 2020 and CVPR 2017 Conferences, and is dedicated at automatically analyzing affect. For this year's Competition, we feature two corpora: i) an extended version of the Aff-Wild2 database and ii) the Hume-Reaction dataset. The former database is an audiovisual one of around 600 videos of around 3M frames and is annotated with respect to:a) two continuous affect dimensions -valence (how positive/negative a person is) and arousal (how active/passive a person is)-; b) basic expressions (e.g. happiness, sadness, neutral state); and c) atomic facial muscle actions (i.e., action units). The latter dataset is an audiovisual one in which reactions of individuals to emotional stimuli have been annotated with respect to seven emotional expression intensities. Thus the 5th ABAW Competition encompasses four Challenges: i) uni-task Valence-Arousal Estimation, ii) uni-task Expression Classification, iii) uni-task Action Unit Detection, and iv) Emotional Reaction Intensity Estimation. In this paper, we present these Challenges, along with their corpora, we outline the evaluation metrics, we present the baseline systems and illustrate their obtained performance.
NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
Nov 15, 2022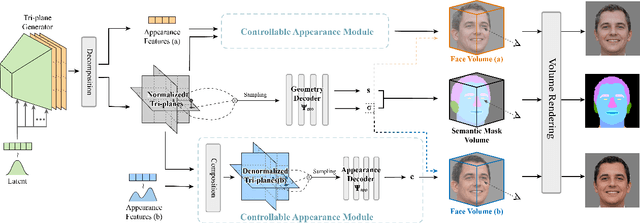
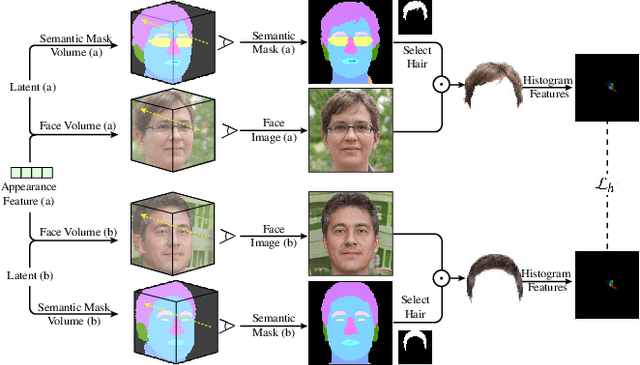


Recent methods for synthesizing 3D-aware face images have achieved rapid development thanks to neural radiance fields, allowing for high quality and fast inference speed. However, existing solutions for editing facial geometry and appearance independently usually require retraining and are not optimized for the recent work of generation, thus tending to lag behind the generation process. To address these issues, we introduce NeRFFaceEditing, which enables editing and decoupling geometry and appearance in the pretrained tri-plane-based neural radiance field while retaining its high quality and fast inference speed. Our key idea for disentanglement is to use the statistics of the tri-plane to represent the high-level appearance of its corresponding facial volume. Moreover, we leverage a generated 3D-continuous semantic mask as an intermediary for geometry editing. We devise a geometry decoder (whose output is unchanged when the appearance changes) and an appearance decoder. The geometry decoder aligns the original facial volume with the semantic mask volume. We also enhance the disentanglement by explicitly regularizing rendered images with the same appearance but different geometry to be similar in terms of color distribution for each facial component separately. Our method allows users to edit via semantic masks with decoupled control of geometry and appearance. Both qualitative and quantitative evaluations show the superior geometry and appearance control abilities of our method compared to existing and alternative solutions.