 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Inferring User Facial Affect in Work-like Settings
Nov 22, 2021

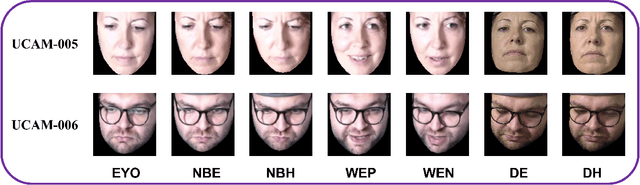

Unlike the six basic emotions of happiness, sadness, fear, anger, disgust and surprise, modelling and predicting dimensional affect in terms of valence (positivity - negativity) and arousal (intensity) has proven to be more flexible, applicable and useful for naturalistic and real-world settings. In this paper, we aim to infer user facial affect when the user is engaged in multiple work-like tasks under varying difficulty levels (baseline, easy, hard and stressful conditions), including (i) an office-like setting where they undertake a task that is less physically demanding but requires greater mental strain; (ii) an assembly-line-like setting that requires the usage of fine motor skills; and (iii) an office-like setting representing teleworking and teleconferencing. In line with this aim, we first design a study with different conditions and gather multimodal data from 12 subjects. We then perform several experiments with various machine learning models and find that: (i) the display and prediction of facial affect vary from non-working to working settings; (ii) prediction capability can be boosted by using datasets captured in a work-like context; and (iii) segment-level (spectral representation) information is crucial in improving the facial affect prediction.
Centre Symmetric Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022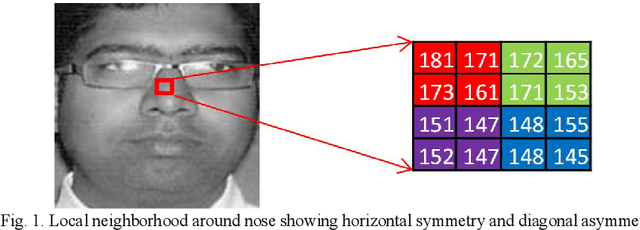
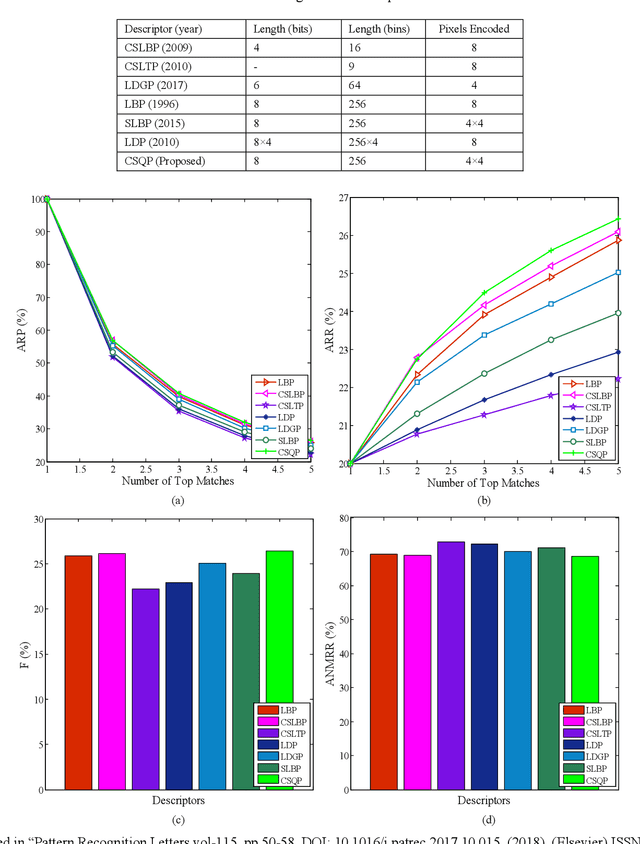

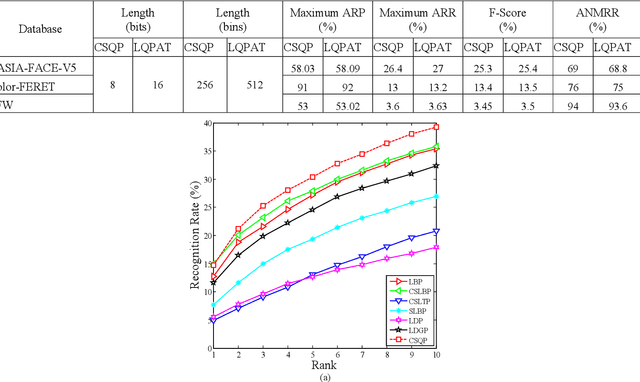
Facial features are defined as the local relationships that exist amongst the pixels of a facial image. Hand-crafted descriptors identify the relationships of the pixels in the local neighbourhood defined by the kernel. Kernel is a two dimensional matrix which is moved across the facial image. Distinctive information captured by the kernel with limited number of pixel achieves satisfactory recognition and retrieval accuracies on facial images taken under constrained environment (controlled variations in light, pose, expressions, and background). To achieve similar accuracies under unconstrained environment local neighbourhood has to be increased, in order to encode more pixels. Increasing local neighbourhood also increases the feature length of the descriptor. In this paper we propose a hand-crafted descriptor namely Centre Symmetric Quadruple Pattern (CSQP), which is structurally symmetric and encodes the facial asymmetry in quadruple space. The proposed descriptor efficiently encodes larger neighbourhood with optimal number of binary bits. It has been shown using average entropy, computed over feature images encoded with the proposed descriptor, that the CSQP captures more meaningful information as compared to state of the art descriptors. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand-crafted descriptors (CSLBP, CSLTP, LDP, LBP, SLBP and LDGP) on bench mark databases namely; LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under controlled as well as uncontrolled variations in pose, illumination, background and expressions.
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
Feb 27, 2023

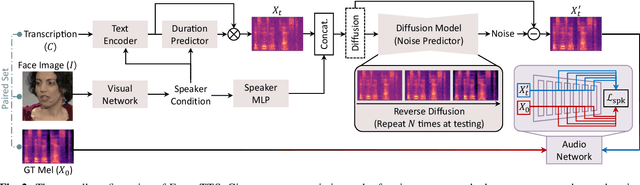
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a face-styled diffusion text-to-speech (TTS) model within a unified framework learnt from visible attributes, called Face-TTS. This is the first time that face images are used as a condition to train a TTS model. We jointly train cross-model biometrics and TTS models to preserve speaker identity between face images and generated speech segments. We also propose a speaker feature binding loss to enforce the similarity of the generated and the ground truth speech segments in speaker embedding space. Since the biometric information is extracted directly from the face image, our method does not require extra fine-tuning steps to generate speech from unseen and unheard speakers. We train and evaluate the model on the LRS3 dataset, an in-the-wild audio-visual corpus containing background noise and diverse speaking styles. The project page is https://facetts.github.io.
Facial Depth and Normal Estimation using Single Dual-Pixel Camera
Nov 25, 2021
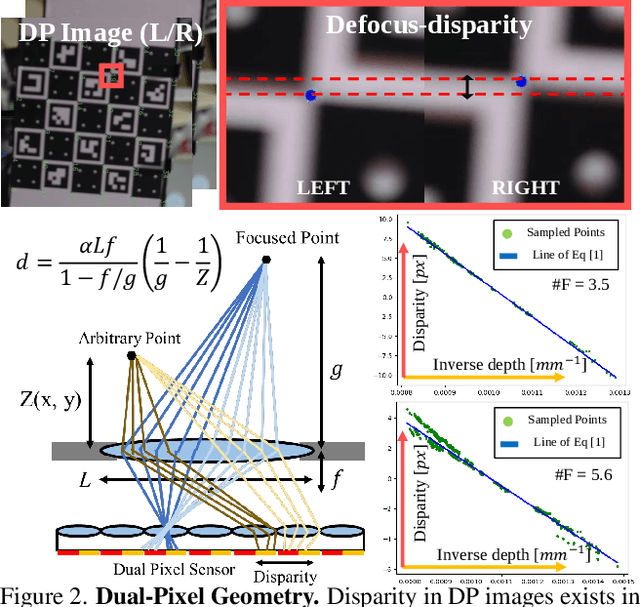

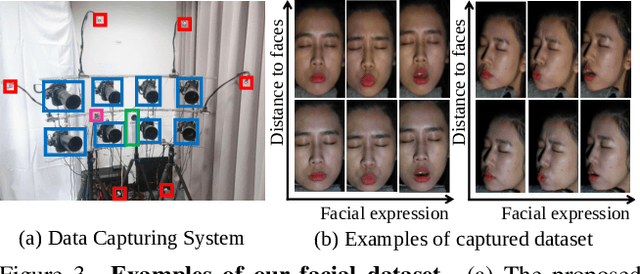
Many mobile manufacturers recently have adopted Dual-Pixel (DP) sensors in their flagship models for faster auto-focus and aesthetic image captures. Despite their advantages, research on their usage for 3D facial understanding has been limited due to the lack of datasets and algorithmic designs that exploit parallax in DP images. This is because the baseline of sub-aperture images is extremely narrow and parallax exists in the defocus blur region. In this paper, we introduce a DP-oriented Depth/Normal network that reconstructs the 3D facial geometry. For this purpose, we collect a DP facial data with more than 135K images for 101 persons captured with our multi-camera structured light systems. It contains the corresponding ground-truth 3D models including depth map and surface normal in metric scale. Our dataset allows the proposed matching network to be generalized for 3D facial depth/normal estimation. The proposed network consists of two novel modules: Adaptive Sampling Module and Adaptive Normal Module, which are specialized in handling the defocus blur in DP images. Finally, the proposed method achieves state-of-the-art performances over recent DP-based depth/normal estimation methods. We also demonstrate the applicability of the estimated depth/normal to face spoofing and relighting.
NeRFFaceEditing: Disentangled Face Editing in Neural Radiance Fields
Nov 15, 2022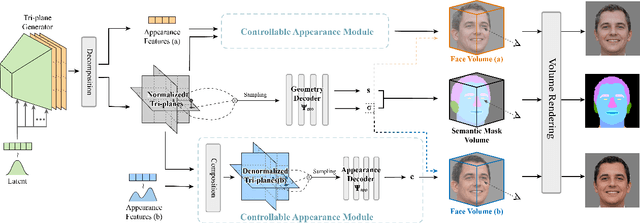
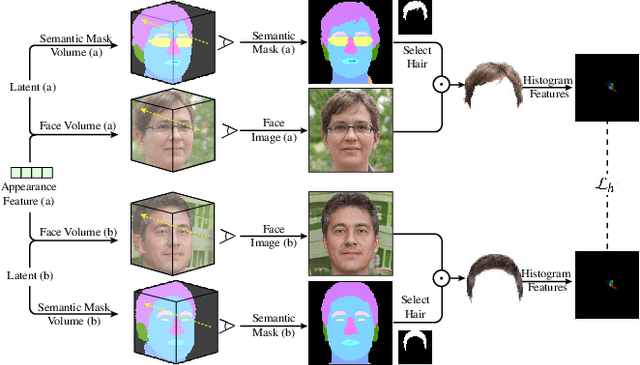


Recent methods for synthesizing 3D-aware face images have achieved rapid development thanks to neural radiance fields, allowing for high quality and fast inference speed. However, existing solutions for editing facial geometry and appearance independently usually require retraining and are not optimized for the recent work of generation, thus tending to lag behind the generation process. To address these issues, we introduce NeRFFaceEditing, which enables editing and decoupling geometry and appearance in the pretrained tri-plane-based neural radiance field while retaining its high quality and fast inference speed. Our key idea for disentanglement is to use the statistics of the tri-plane to represent the high-level appearance of its corresponding facial volume. Moreover, we leverage a generated 3D-continuous semantic mask as an intermediary for geometry editing. We devise a geometry decoder (whose output is unchanged when the appearance changes) and an appearance decoder. The geometry decoder aligns the original facial volume with the semantic mask volume. We also enhance the disentanglement by explicitly regularizing rendered images with the same appearance but different geometry to be similar in terms of color distribution for each facial component separately. Our method allows users to edit via semantic masks with decoupled control of geometry and appearance. Both qualitative and quantitative evaluations show the superior geometry and appearance control abilities of our method compared to existing and alternative solutions.
Domain Generalisation for Apparent Emotional Facial Expression Recognition across Age-Groups
Oct 18, 2021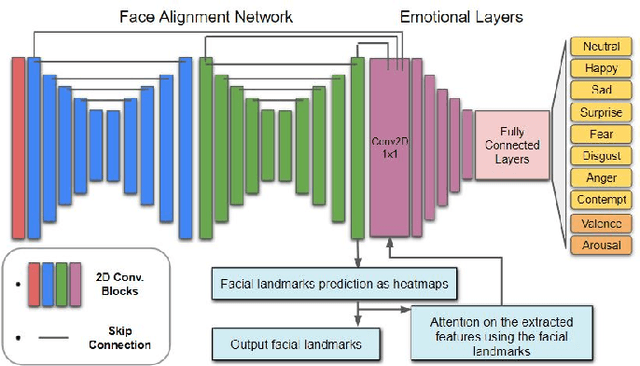
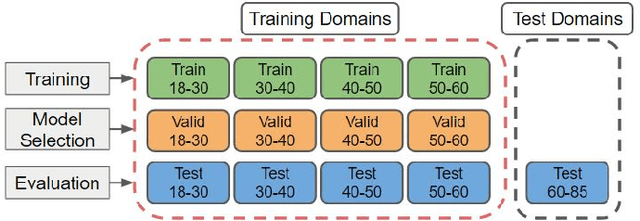
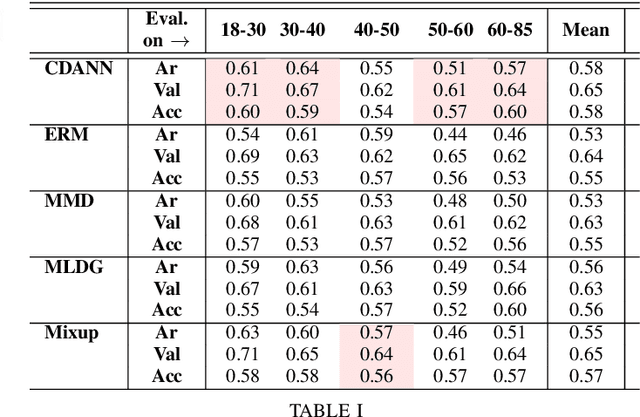
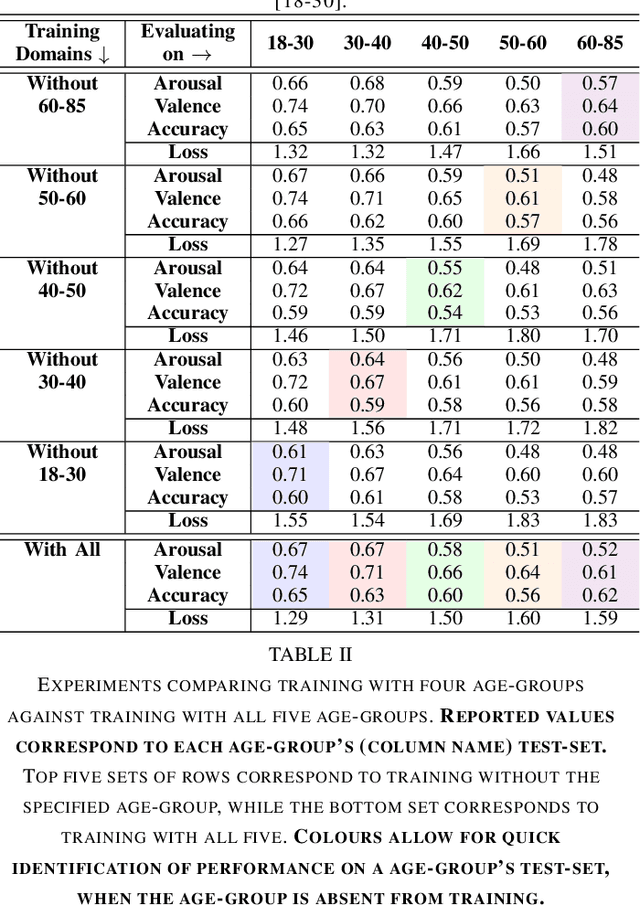
Apparent emotional facial expression recognition has attracted a lot of research attention recently. However, the majority of approaches ignore age differences and train a generic model for all ages. In this work, we study the effect of using different age-groups for training apparent emotional facial expression recognition models. To this end, we study Domain Generalisation in the context of apparent emotional facial expression recognition from facial imagery across different age groups. We first compare several domain generalisation algorithms on the basis of out-of-domain-generalisation, and observe that the Class-Conditional Domain-Adversarial Neural Networks (CDANN) algorithm has the best performance. We then study the effect of variety and number of age-groups used during training on generalisation to unseen age-groups and observe that an increase in the number of training age-groups tends to increase the apparent emotional facial expression recognition performance on unseen age-groups. We also show that exclusion of an age-group during training tends to affect more the performance of the neighbouring age groups.
CoNFies: Controllable Neural Face Avatars
Nov 16, 2022



Neural Radiance Fields (NeRF) are compelling techniques for modeling dynamic 3D scenes from 2D image collections. These volumetric representations would be well suited for synthesizing novel facial expressions but for two problems. First, deformable NeRFs are object agnostic and model holistic movement of the scene: they can replay how the motion changes over time, but they cannot alter it in an interpretable way. Second, controllable volumetric representations typically require either time-consuming manual annotations or 3D supervision to provide semantic meaning to the scene. We propose a controllable neural representation for face self-portraits (CoNFies), that solves both of these problems within a common framework, and it can rely on automated processing. We use automated facial action recognition (AFAR) to characterize facial expressions as a combination of action units (AU) and their intensities. AUs provide both the semantic locations and control labels for the system. CoNFies outperformed competing methods for novel view and expression synthesis in terms of visual and anatomic fidelity of expressions.
Generating Dataset For Large-scale 3D Facial Emotion Recognition
Sep 16, 2021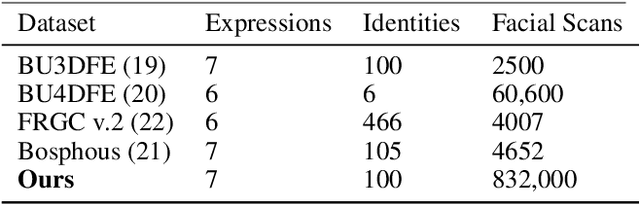
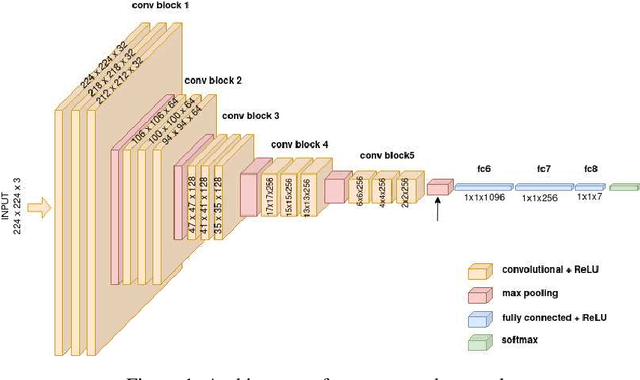
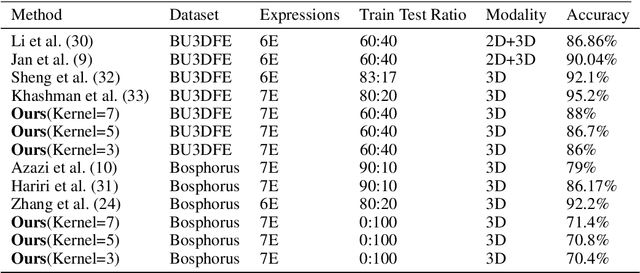
The tremendous development in deep learning has led facial expression recognition (FER) to receive much attention in the past few years. Although 3D FER has an inherent edge over its 2D counterpart, work on 2D images has dominated the field. The main reason for the slow development of 3D FER is the unavailability of large training and large test datasets. Recognition accuracies have already saturated on existing 3D emotion recognition datasets due to their small gallery sizes. Unlike 2D photographs, 3D facial scans are not easy to collect, causing a bottleneck in the development of deep 3D FER networks and datasets. In this work, we propose a method for generating a large dataset of 3D faces with labeled emotions. We also develop a deep convolutional neural network(CNN) for 3D FER trained on 624,000 3D facial scans. The test data comprises 208,000 3D facial scans.
PERI: Part Aware Emotion Recognition In The Wild
Oct 18, 2022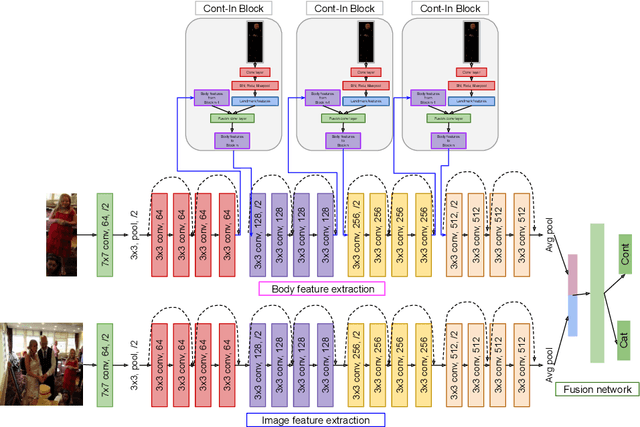
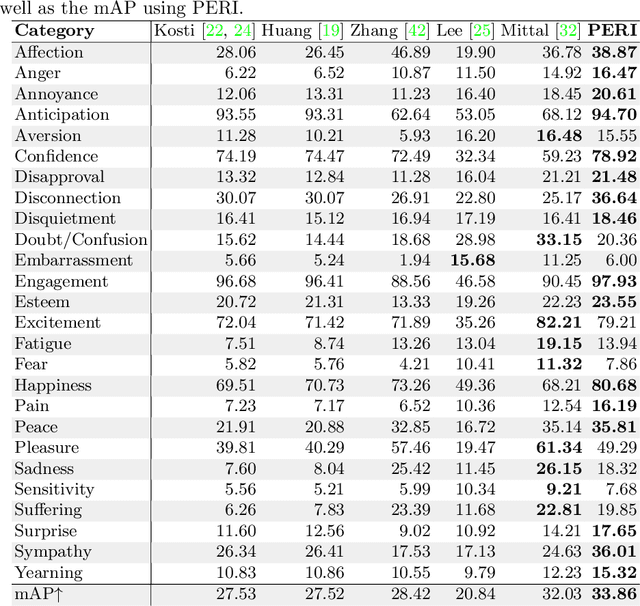
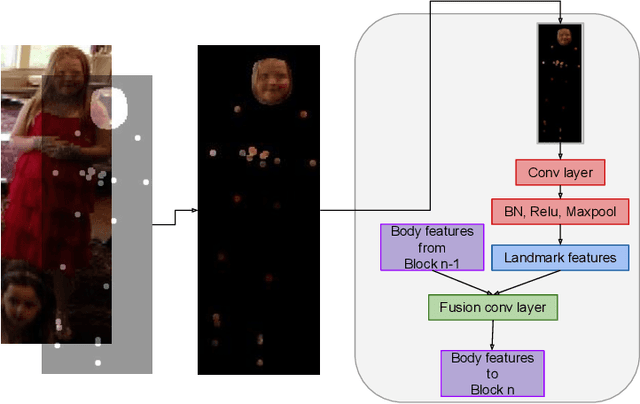
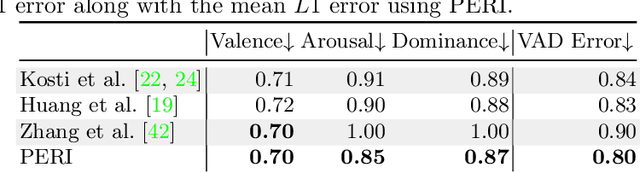
Emotion recognition aims to interpret the emotional states of a person based on various inputs including audio, visual, and textual cues. This paper focuses on emotion recognition using visual features. To leverage the correlation between facial expression and the emotional state of a person, pioneering methods rely primarily on facial features. However, facial features are often unreliable in natural unconstrained scenarios, such as in crowded scenes, as the face lacks pixel resolution and contains artifacts due to occlusion and blur. To address this, in the wild emotion recognition exploits full-body person crops as well as the surrounding scene context. In a bid to use body pose for emotion recognition, such methods fail to realize the potential that facial expressions, when available, offer. Thus, the aim of this paper is two-fold. First, we demonstrate our method, PERI, to leverage both body pose and facial landmarks. We create part aware spatial (PAS) images by extracting key regions from the input image using a mask generated from both body pose and facial landmarks. This allows us to exploit body pose in addition to facial context whenever available. Second, to reason from the PAS images, we introduce context infusion (Cont-In) blocks. These blocks attend to part-specific information, and pass them onto the intermediate features of an emotion recognition network. Our approach is conceptually simple and can be applied to any existing emotion recognition method. We provide our results on the publicly available in the wild EMOTIC dataset. Compared to existing methods, PERI achieves superior performance and leads to significant improvements in the mAP of emotion categories, while decreasing Valence, Arousal and Dominance errors. Importantly, we observe that our method improves performance in both images with fully visible faces as well as in images with occluded or blurred faces.
A Dataless FaceSwap Detection Approach Using Synthetic Images
Dec 05, 2022
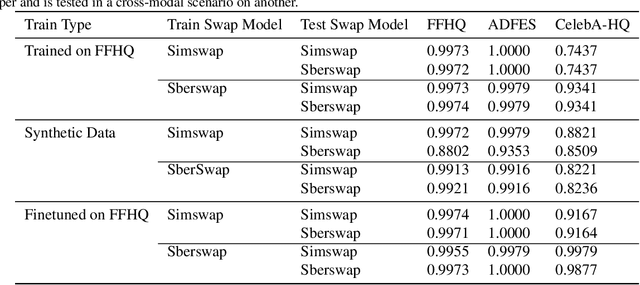

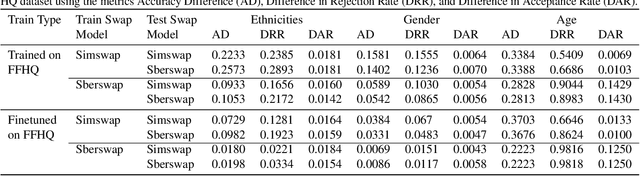
Face swapping technology used to create "Deepfakes" has advanced significantly over the past few years and now enables us to create realistic facial manipulations. Current deep learning algorithms to detect deepfakes have shown promising results, however, they require large amounts of training data, and as we show they are biased towards a particular ethnicity. We propose a deepfake detection methodology that eliminates the need for any real data by making use of synthetically generated data using StyleGAN3. This not only performs at par with the traditional training methodology of using real data but it shows better generalization capabilities when finetuned with a small amount of real data. Furthermore, this also reduces biases created by facial image datasets that might have sparse data from particular ethnicities.