 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A comprehensive survey on semantic facial attribute editing using generative adversarial networks
May 21, 2022

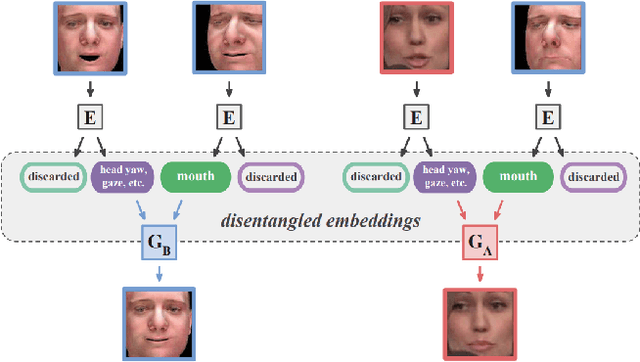
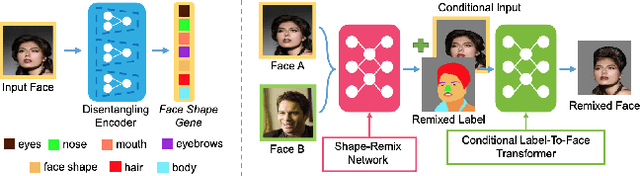
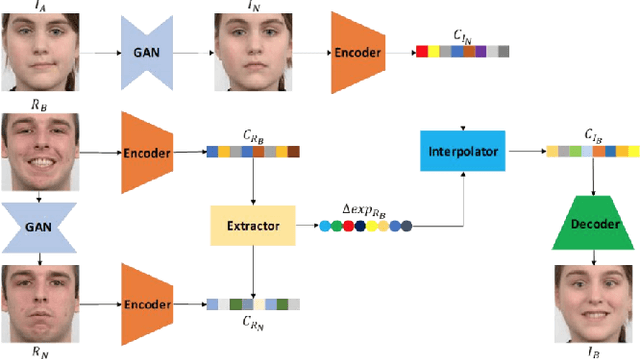
Generating random photo-realistic images has experienced tremendous growth during the past few years due to the advances of the deep convolutional neural networks and generative models. Among different domains, face photos have received a great deal of attention and a large number of face generation and manipulation models have been proposed. Semantic facial attribute editing is the process of varying the values of one or more attributes of a face image while the other attributes of the image are not affected. The requested modifications are provided as an attribute vector or in the form of driving face image and the whole process is performed by the corresponding models. In this paper, we survey the recent works and advances in semantic facial attribute editing. We cover all related aspects of these models including the related definitions and concepts, architectures, loss functions, datasets, evaluation metrics, and applications. Based on their architectures, the state-of-the-art models are categorized and studied as encoder-decoder, image-to-image, and photo-guided models. The challenges and restrictions of the current state-of-the-art methods are discussed as well.
Speaker Recognition in Realistic Scenario Using Multimodal Data
Feb 25, 2023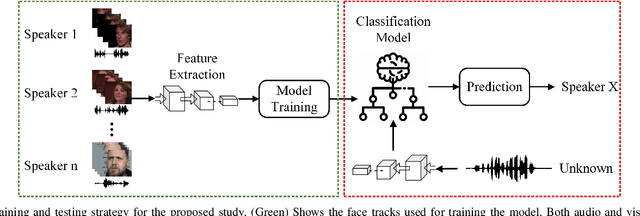
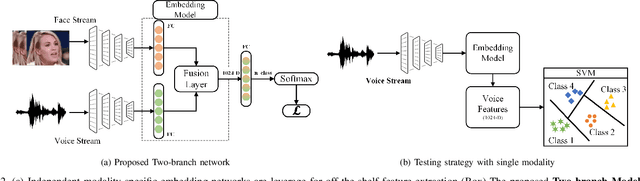
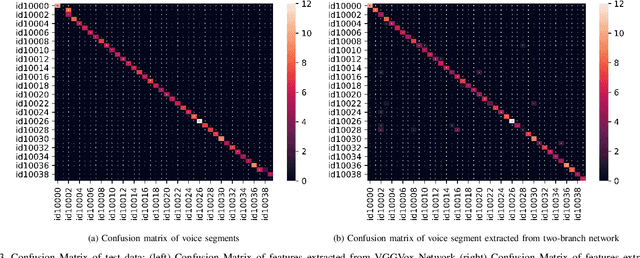
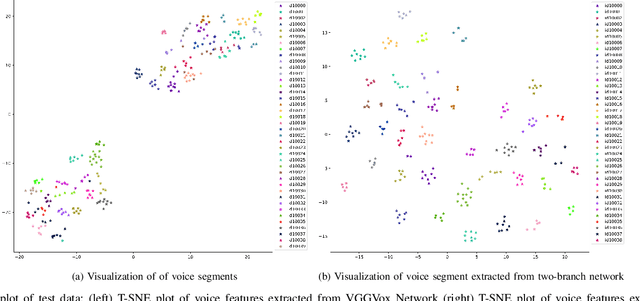
In recent years, an association is established between faces and voices of celebrities leveraging large scale audio-visual information from YouTube. The availability of large scale audio-visual datasets is instrumental in developing speaker recognition methods based on standard Convolutional Neural Networks. Thus, the aim of this paper is to leverage large scale audio-visual information to improve speaker recognition task. To achieve this task, we proposed a two-branch network to learn joint representations of faces and voices in a multimodal system. Afterwards, features are extracted from the two-branch network to train a classifier for speaker recognition. We evaluated our proposed framework on a large scale audio-visual dataset named VoxCeleb$1$. Our results show that addition of facial information improved the performance of speaker recognition. Moreover, our results indicate that there is an overlap between face and voice.
Reasoning Structural Relation for Occlusion-Robust Facial Landmark Localization
Dec 19, 2021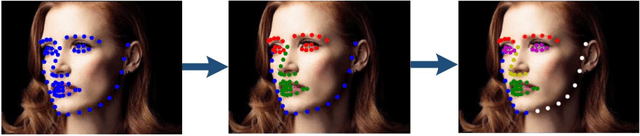
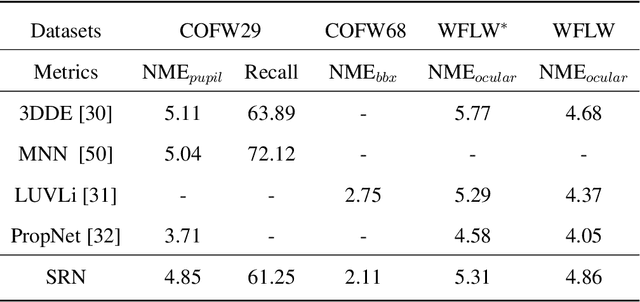
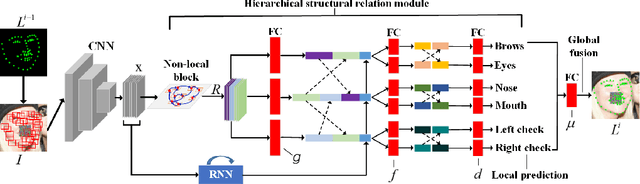
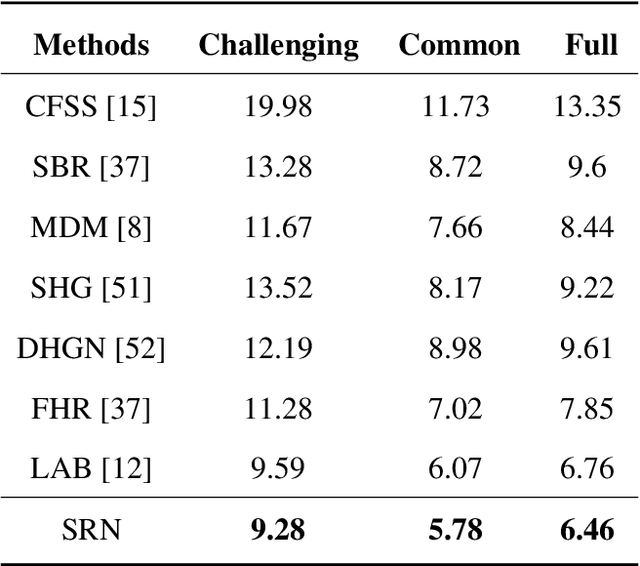
In facial landmark localization tasks, various occlusions heavily degrade the localization accuracy due to the partial observability of facial features. This paper proposes a structural relation network (SRN) for occlusion-robust landmark localization. Unlike most existing methods that simply exploit the shape constraint, the proposed SRN aims to capture the structural relations among different facial components. These relations can be considered a more powerful shape constraint against occlusion. To achieve this, a hierarchical structural relation module (HSRM) is designed to hierarchically reason the structural relations that represent both long- and short-distance spatial dependencies. Compared with existing network architectures, HSRM can efficiently model the spatial relations by leveraging its geometry-aware network architecture, which reduces the semantic ambiguity caused by occlusion. Moreover, the SRN augments the training data by synthesizing occluded faces. To further extend our SRN for occluded video data, we formulate the occluded face synthesis as a Markov decision process (MDP). Specifically, it plans the movement of the dynamic occlusion based on an accumulated reward associated with the performance degradation of the pre-trained SRN. This procedure augments hard samples for robust facial landmark tracking. Extensive experimental results indicate that the proposed method achieves outstanding performance on occluded and masked faces. Code is available at https://github.com/zhuccly/SRN.
HQ3DAvatar: High Quality Controllable 3D Head Avatar
Mar 25, 2023
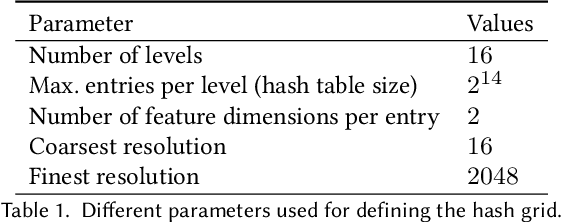
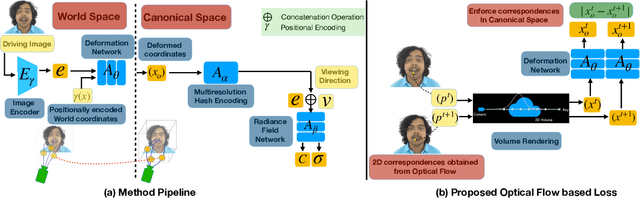
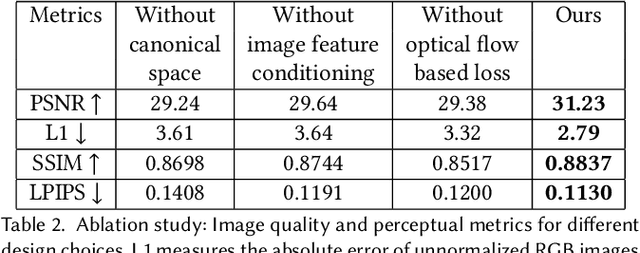
Multi-view volumetric rendering techniques have recently shown great potential in modeling and synthesizing high-quality head avatars. A common approach to capture full head dynamic performances is to track the underlying geometry using a mesh-based template or 3D cube-based graphics primitives. While these model-based approaches achieve promising results, they often fail to learn complex geometric details such as the mouth interior, hair, and topological changes over time. This paper presents a novel approach to building highly photorealistic digital head avatars. Our method learns a canonical space via an implicit function parameterized by a neural network. It leverages multiresolution hash encoding in the learned feature space, allowing for high-quality, faster training and high-resolution rendering. At test time, our method is driven by a monocular RGB video. Here, an image encoder extracts face-specific features that also condition the learnable canonical space. This encourages deformation-dependent texture variations during training. We also propose a novel optical flow based loss that ensures correspondences in the learned canonical space, thus encouraging artifact-free and temporally consistent renderings. We show results on challenging facial expressions and show free-viewpoint renderings at interactive real-time rates for medium image resolutions. Our method outperforms all existing approaches, both visually and numerically. We will release our multiple-identity dataset to encourage further research. Our Project page is available at: https://vcai.mpi-inf.mpg.de/projects/HQ3DAvatar/
MagicEye: An Intelligent Wearable Towards Independent Living of Visually Impaired
Mar 24, 2023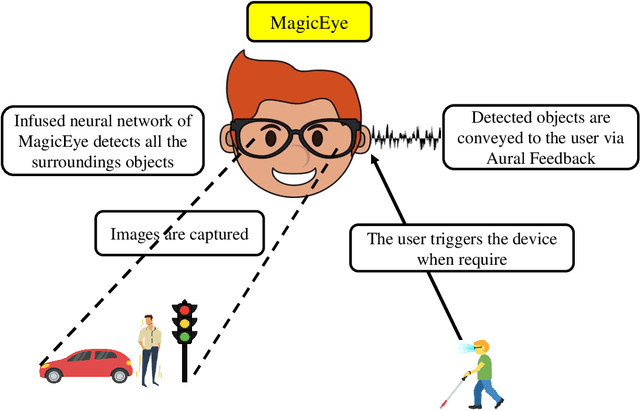
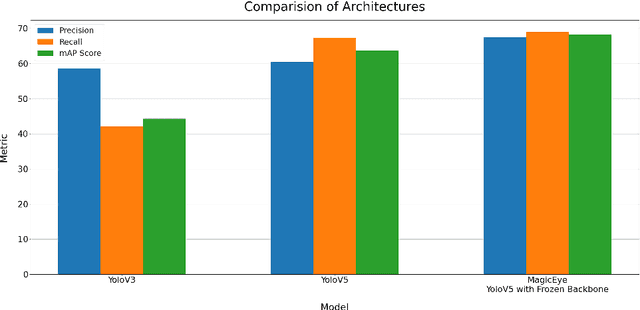
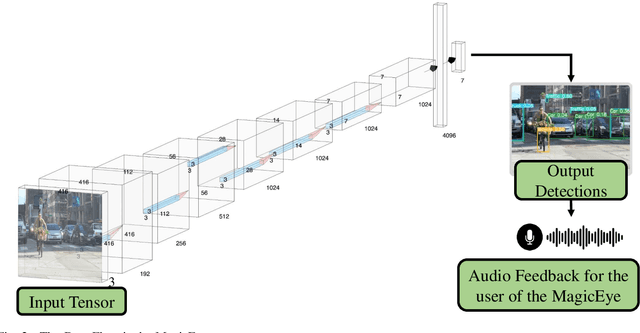
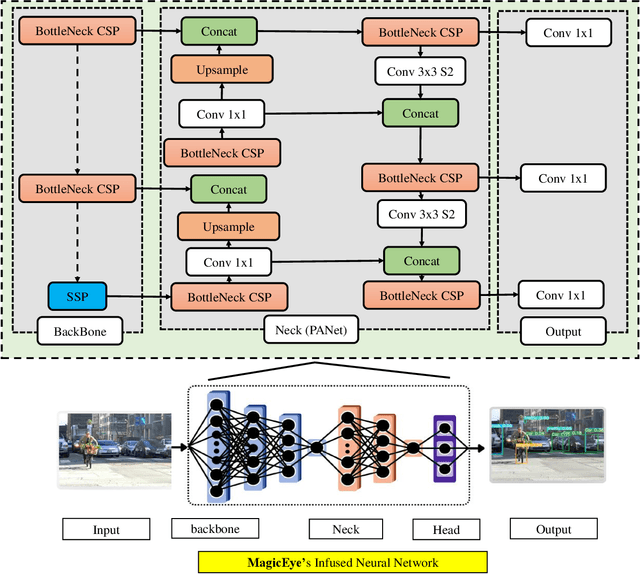
Individuals with visual impairments often face a multitude of challenging obstacles in their daily lives. Vision impairment can severely impair a person's ability to work, navigate, and retain independence. This can result in educational limits, a higher risk of accidents, and a plethora of other issues. To address these challenges, we present MagicEye, a state-of-the-art intelligent wearable device designed to assist visually impaired individuals. MagicEye employs a custom-trained CNN-based object detection model, capable of recognizing a wide range of indoor and outdoor objects frequently encountered in daily life. With a total of 35 classes, the neural network employed by MagicEye has been specifically designed to achieve high levels of efficiency and precision in object detection. The device is also equipped with facial recognition and currency identification modules, providing invaluable assistance to the visually impaired. In addition, MagicEye features a GPS sensor for navigation, allowing users to move about with ease, as well as a proximity sensor for detecting nearby objects without physical contact. In summary, MagicEye is an innovative and highly advanced wearable device that has been designed to address the many challenges faced by individuals with visual impairments. It is equipped with state-of-the-art object detection and navigation capabilities that are tailored to the needs of the visually impaired, making it one of the most promising solutions to assist those who are struggling with visual impairments.
FRA: A novel Face Representation Augmentation algorithm for face recognition
Jan 27, 2023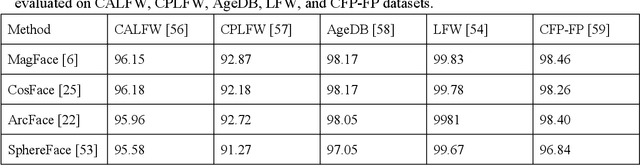
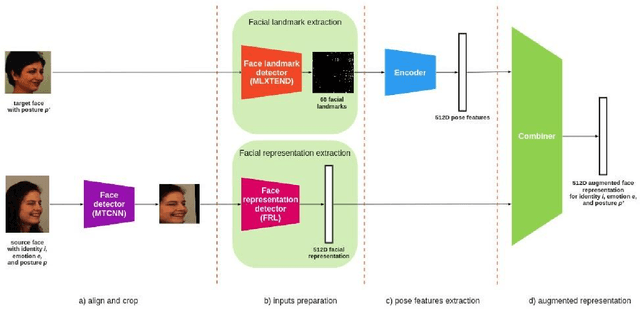

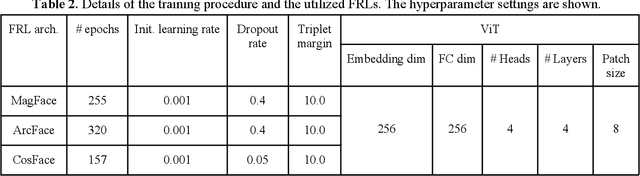
A low amount of training data for many state-of-the-art deep learning-based Face Recognition (FR) systems causes a marked deterioration in their performance. Although a considerable amount of research has addressed this issue by inventing new data augmentation techniques, using either input space transformations or Generative Adversarial Networks (GAN) for feature space augmentations, these techniques have yet to satisfy expectations. In this paper, we propose a novel method, named the Face Representation Augmentation (FRA) algorithm, for augmenting face datasets. To the best of our knowledge, FRA is the first method that shifts its focus towards manipulating the face embeddings generated by any face representation learning algorithm in order to generate new embeddings representing the same identity and facial emotion but with an altered posture. Extensive experiments conducted in this study convince the efficacy of our methodology and its power to provide noiseless, completely new facial representations to improve the training procedure of any FR algorithm. Therefore, FRA is able to help the recent state-of-the-art FR methods by providing more data for training FR systems. The proposed method, using experiments conducted on the Karolinska Directed Emotional Faces (KDEF) dataset, improves the identity classification accuracies by 9.52 %, 10.04 %, and 16.60 %, in comparison with the base models of MagFace, ArcFace, and CosFace, respectively.
ABAW: Valence-Arousal Estimation, Expression Recognition, Action Unit Detection & Emotional Reaction Intensity Estimation Challenges
Mar 20, 2023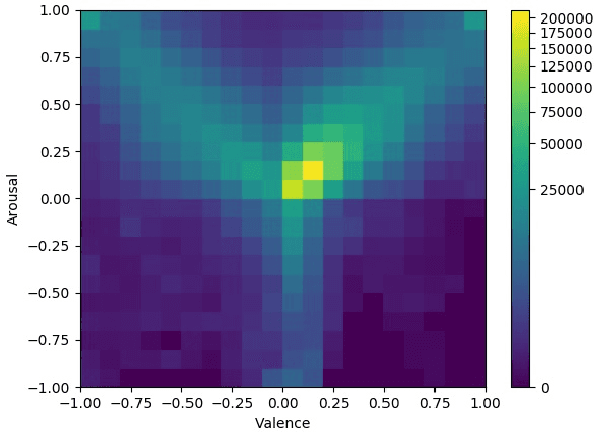
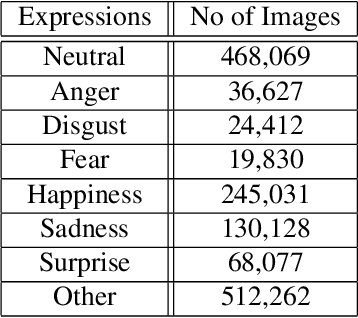
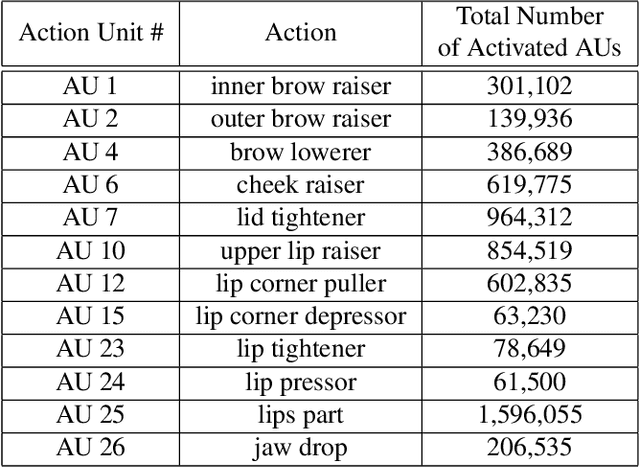

The fifth Affective Behavior Analysis in-the-wild (ABAW) Competition is part of the respective ABAW Workshop which will be held in conjunction with IEEE Computer Vision and Pattern Recognition Conference (CVPR), 2023. The 5th ABAW Competition is a continuation of the Competitions held at ECCV 2022, IEEE CVPR 2022, ICCV 2021, IEEE FG 2020 and CVPR 2017 Conferences, and is dedicated at automatically analyzing affect. For this year's Competition, we feature two corpora: i) an extended version of the Aff-Wild2 database and ii) the Hume-Reaction dataset. The former database is an audiovisual one of around 600 videos of around 3M frames and is annotated with respect to:a) two continuous affect dimensions -valence (how positive/negative a person is) and arousal (how active/passive a person is)-; b) basic expressions (e.g. happiness, sadness, neutral state); and c) atomic facial muscle actions (i.e., action units). The latter dataset is an audiovisual one in which reactions of individuals to emotional stimuli have been annotated with respect to seven emotional expression intensities. Thus the 5th ABAW Competition encompasses four Challenges: i) uni-task Valence-Arousal Estimation, ii) uni-task Expression Classification, iii) uni-task Action Unit Detection, and iv) Emotional Reaction Intensity Estimation. In this paper, we present these Challenges, along with their corpora, we outline the evaluation metrics, we present the baseline systems and illustrate their obtained performance.
AI-Enhanced Intensive Care Unit: Revolutionizing Patient Care with Pervasive Sensing
Mar 11, 2023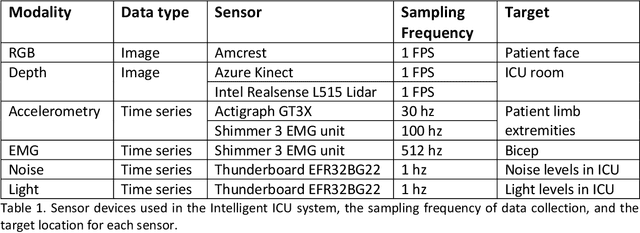
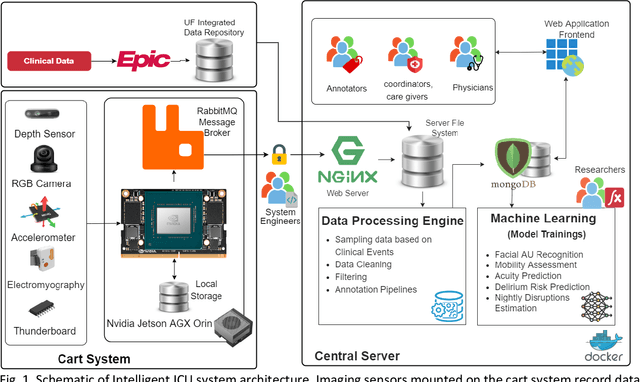
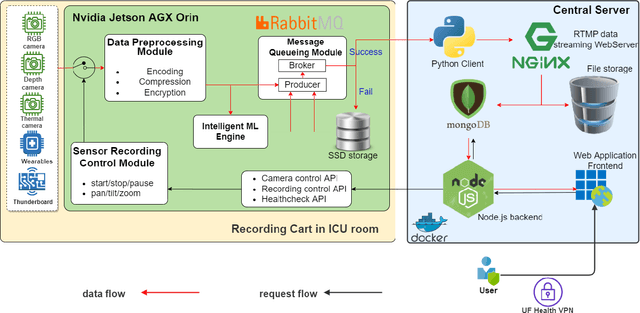
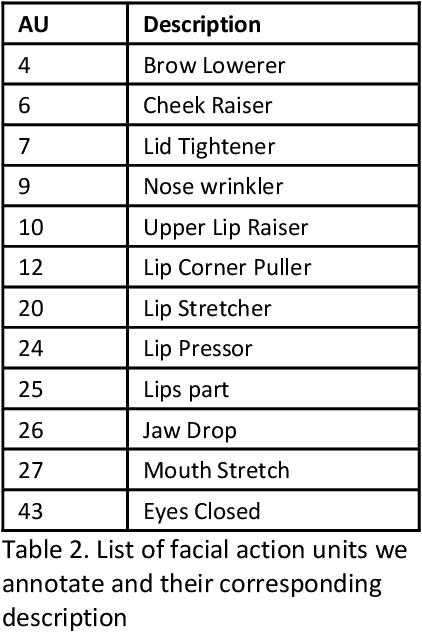
The intensive care unit (ICU) is a specialized hospital space where critically ill patients receive intensive care and monitoring. Comprehensive monitoring is imperative in assessing patients conditions, in particular acuity, and ultimately the quality of care. However, the extent of patient monitoring in the ICU is limited due to time constraints and the workload on healthcare providers. Currently, visual assessments for acuity, including fine details such as facial expressions, posture, and mobility, are sporadically captured, or not captured at all. These manual observations are subjective to the individual, prone to documentation errors, and overburden care providers with the additional workload. Artificial Intelligence (AI) enabled systems has the potential to augment the patient visual monitoring and assessment due to their exceptional learning capabilities. Such systems require robust annotated data to train. To this end, we have developed pervasive sensing and data processing system which collects data from multiple modalities depth images, color RGB images, accelerometry, electromyography, sound pressure, and light levels in ICU for developing intelligent monitoring systems for continuous and granular acuity, delirium risk, pain, and mobility assessment. This paper presents the Intelligent Intensive Care Unit (I2CU) system architecture we developed for real-time patient monitoring and visual assessment.
Learning Representations for Masked Facial Recovery
Dec 28, 2022The pandemic of these very recent years has led to a dramatic increase in people wearing protective masks in public venues. This poses obvious challenges to the pervasive use of face recognition technology that now is suffering a decline in performance. One way to address the problem is to revert to face recovery methods as a preprocessing step. Current approaches to face reconstruction and manipulation leverage the ability to model the face manifold, but tend to be generic. We introduce a method that is specific for the recovery of the face image from an image of the same individual wearing a mask. We do so by designing a specialized GAN inversion method, based on an appropriate set of losses for learning an unmasking encoder. With extensive experiments, we show that the approach is effective at unmasking face images. In addition, we also show that the identity information is preserved sufficiently well to improve face verification performance based on several face recognition benchmark datasets.
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
Aug 22, 2022
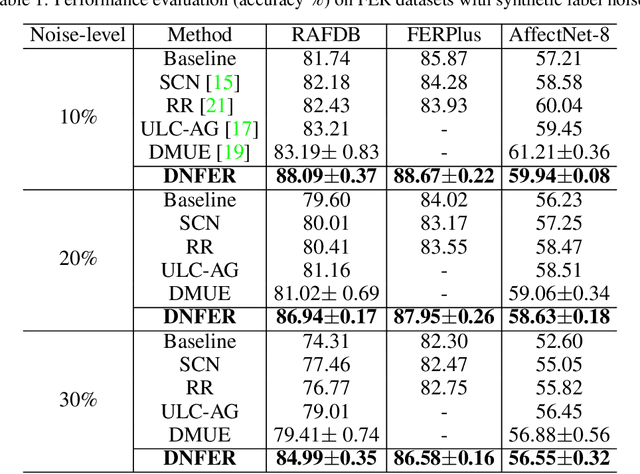
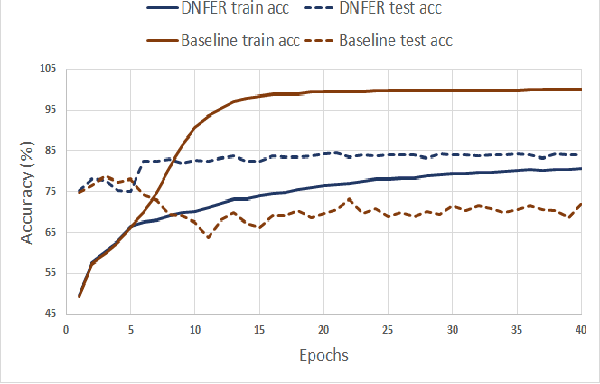
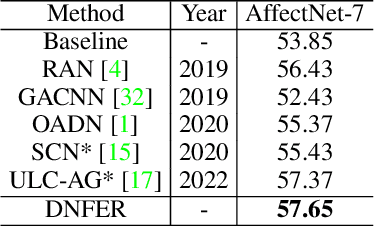
The real-world facial expression recognition (FER) datasets suffer from noisy annotations due to crowd-sourcing, ambiguity in expressions, the subjectivity of annotators and inter-class similarity. However, the recent deep networks have strong capacity to memorize the noisy annotations leading to corrupted feature embedding and poor generalization. To handle noisy annotations, we propose a dynamic FER learning framework (DNFER) in which clean samples are selected based on dynamic class specific threshold during training. Specifically, DNFER is based on supervised training using selected clean samples and unsupervised consistent training using all the samples. During training, the mean posterior class probabilities of each mini-batch is used as dynamic class-specific threshold to select the clean samples for supervised training. This threshold is independent of noise rate and does not need any clean data unlike other methods. In addition, to learn from all samples, the posterior distributions between weakly-augmented image and strongly-augmented image are aligned using an unsupervised consistency loss. We demonstrate the robustness of DNFER on both synthetic as well as on real noisy annotated FER datasets like RAFDB, FERPlus, SFEW and AffectNet.