 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Multi-scale multi-modal micro-expression recognition algorithm based on transformer
Jan 08, 2023
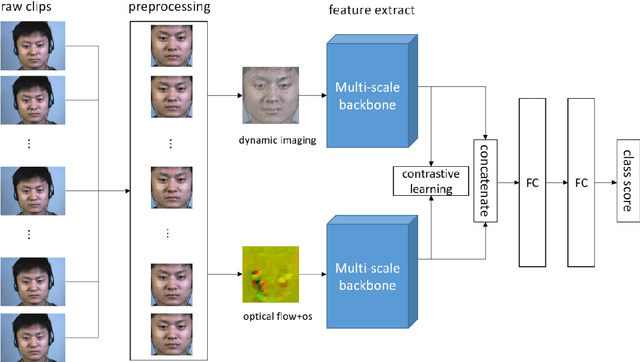

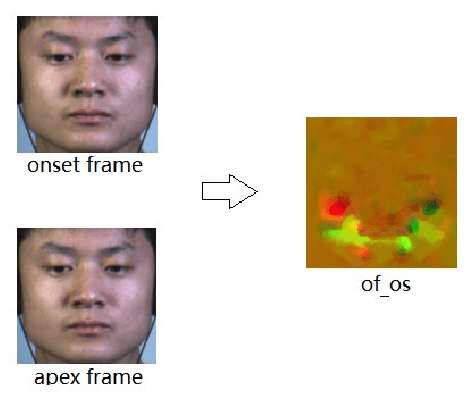
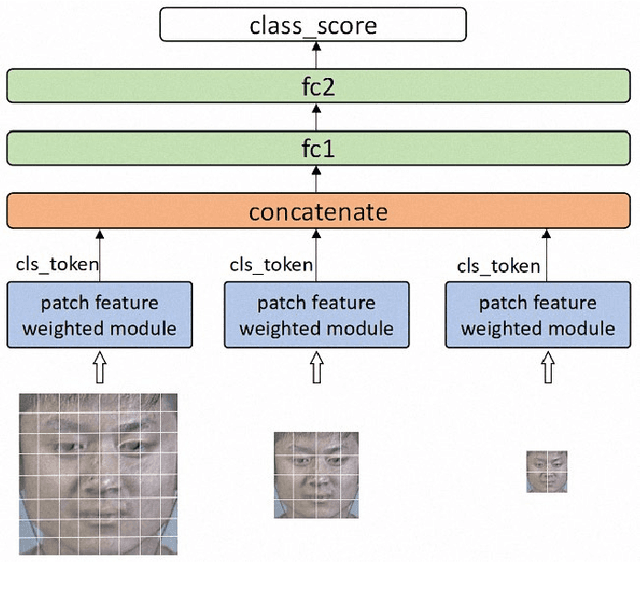
A micro-expression is a spontaneous unconscious facial muscle movement that can reveal the true emotions people attempt to hide. Although manual methods have made good progress and deep learning is gaining prominence. Due to the short duration of micro-expression occurrence and different scales of expressing in facial regions, existing algorithms cannot extract multi-modal multi-scale facial region features while taking into account contextual information to learn underlying features. Therefore, in order to solve the above problems, a multi-modal multi-scale algorithm based on transformer network is proposed in this paper, aiming to fully learn local multi-grained features of micro-expressions through two modal features of micro-expressions - motion features and texture features. To obtain local area features of the face at different scales, we learned patch features at different scales for both modalities, and then fused multi-layer multi-headed attention weights to obtain effective features by weighting the patch features, and combined cross-modal contrastive learning for model optimization. We conducted comprehensive experiments on three spontaneous datasets, and the results show the accuracy of the proposed algorithm in single measurement SMIC database is up to 78.73% and the F1 value on CASMEII of the combined database is up to 0.9071, which is at the leading level.
BigSmall: Efficient Multi-Task Learning for Disparate Spatial and Temporal Physiological Measurements
Mar 21, 2023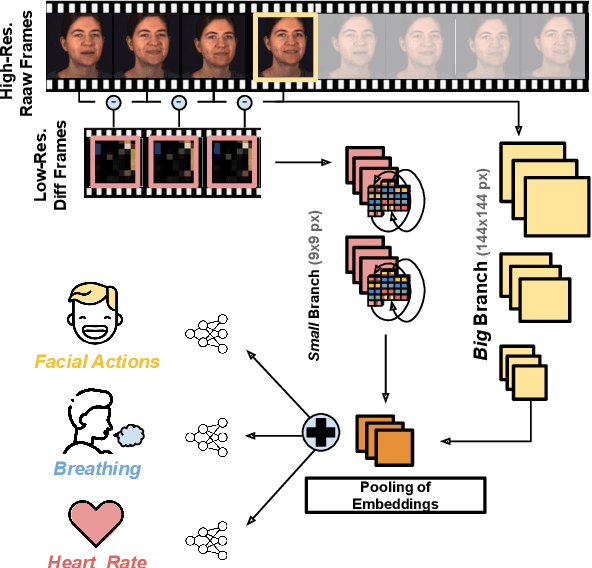

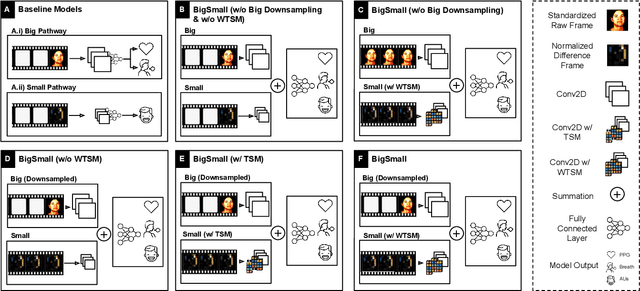
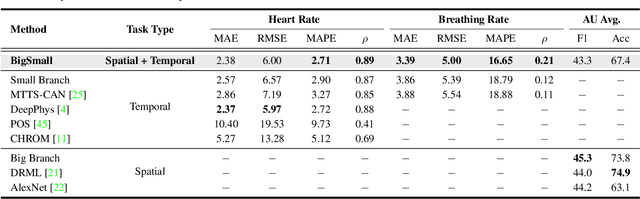
Understanding of human visual perception has historically inspired the design of computer vision architectures. As an example, perception occurs at different scales both spatially and temporally, suggesting that the extraction of salient visual information may be made more effective by paying attention to specific features at varying scales. Visual changes in the body due to physiological processes also occur at different scales and with modality-specific characteristic properties. Inspired by this, we present BigSmall, an efficient architecture for physiological and behavioral measurement. We present the first joint camera-based facial action, cardiac, and pulmonary measurement model. We propose a multi-branch network with wrapping temporal shift modules that yields both accuracy and efficiency gains. We observe that fusing low-level features leads to suboptimal performance, but that fusing high level features enables efficiency gains with negligible loss in accuracy. Experimental results demonstrate that BigSmall significantly reduces the computational costs. Furthermore, compared to existing task-specific models, BigSmall achieves comparable or better results on multiple physiological measurement tasks simultaneously with a unified model.
Fighting over-fitting with quantization for learning deep neural networks on noisy labels
Mar 21, 2023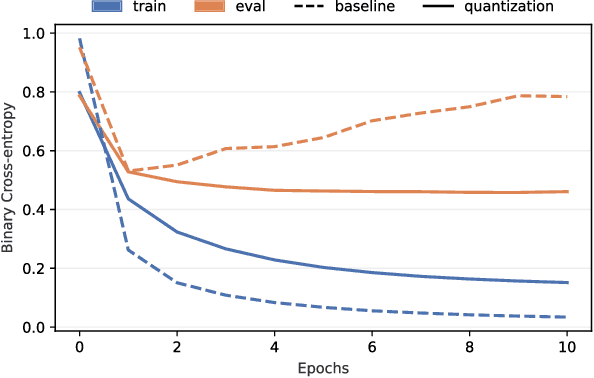
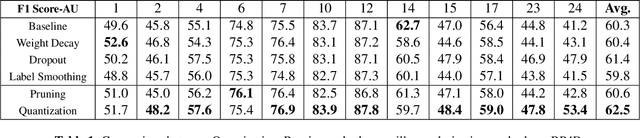
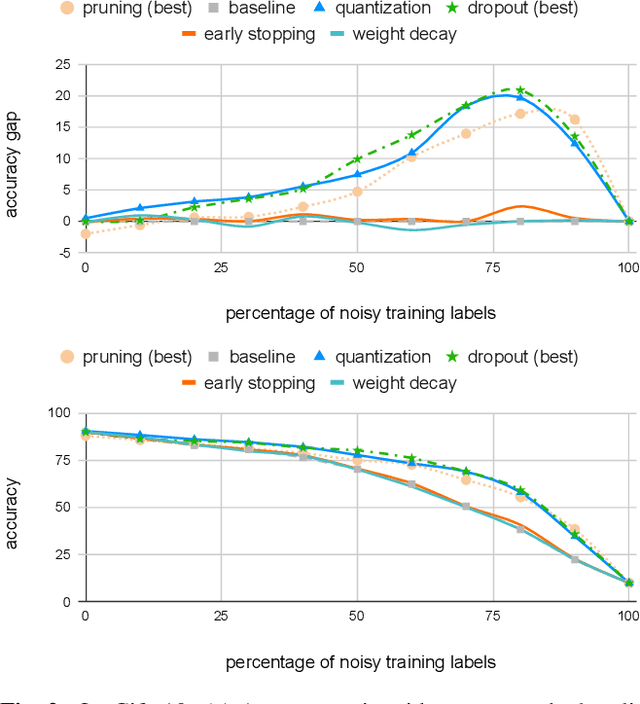
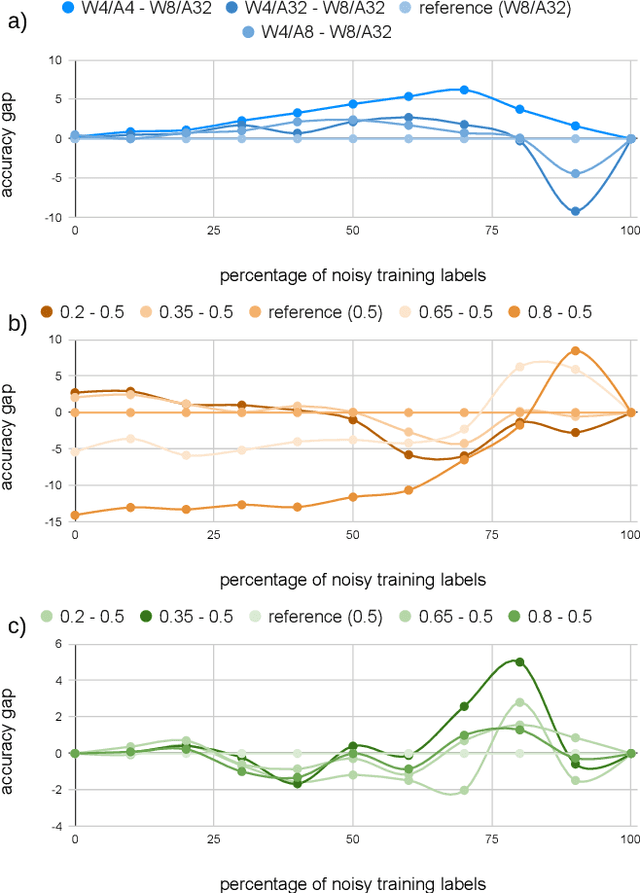
The rising performance of deep neural networks is often empirically attributed to an increase in the available computational power, which allows complex models to be trained upon large amounts of annotated data. However, increased model complexity leads to costly deployment of modern neural networks, while gathering such amounts of data requires huge costs to avoid label noise. In this work, we study the ability of compression methods to tackle both of these problems at once. We hypothesize that quantization-aware training, by restricting the expressivity of neural networks, behaves as a regularization. Thus, it may help fighting overfitting on noisy data while also allowing for the compression of the model at inference. We first validate this claim on a controlled test with manually introduced label noise. Furthermore, we also test the proposed method on Facial Action Unit detection, where labels are typically noisy due to the subtlety of the task. In all cases, our results suggests that quantization significantly improve the results compared with existing baselines, regularization as well as other compression methods.
What happens in Face during a facial expression? Using data mining techniques to analyze facial expression motion vectors
Sep 12, 2021
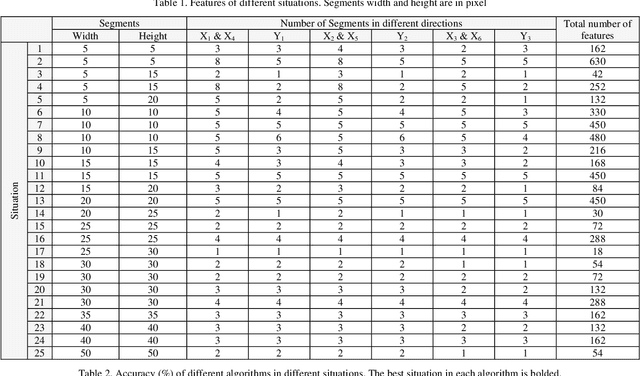


One of the most common problems encountered in human-computer interaction is automatic facial expression recognition. Although it is easy for human observer to recognize facial expressions, automatic recognition remains difficult for machines. One of the methods that machines can recognize facial expression is analyzing the changes in face during facial expression presentation. In this paper, optical flow algorithm was used to extract deformation or motion vectors created in the face because of facial expressions. Then, these extracted motion vectors are used to be analyzed. Their positions and directions were exploited for automatic facial expression recognition using different data mining techniques. It means that by employing motion vector features used as our data, facial expressions were recognized. Some of the most state-of-the-art classification algorithms such as C5.0, CRT, QUEST, CHAID, Deep Learning (DL), SVM and Discriminant algorithms were used to classify the extracted motion vectors. Using 10-fold cross validation, their performances were calculated. To compare their performance more precisely, the test was repeated 50 times. Meanwhile, the deformation of face was also analyzed in this research. For example, what exactly happened in each part of face when a person showed fear? Experimental results on Extended Cohen-Kanade (CK+) facial expression dataset demonstrated that the best methods were DL, SVM and C5.0, with the accuracy of 95.3%, 92.8% and 90.2% respectively.
Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network
Feb 08, 2022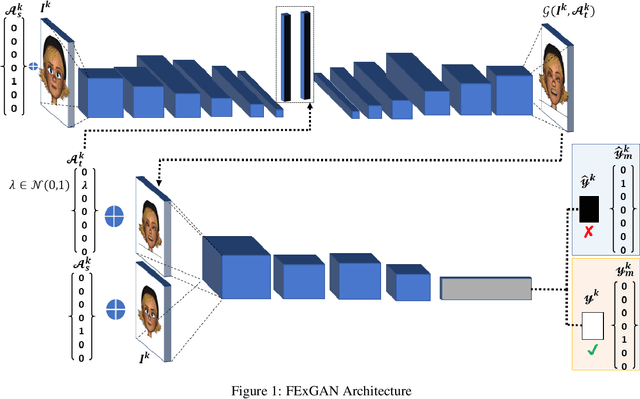
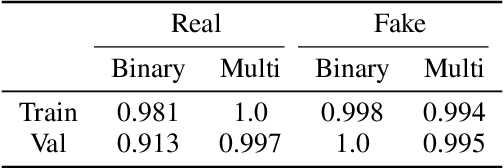
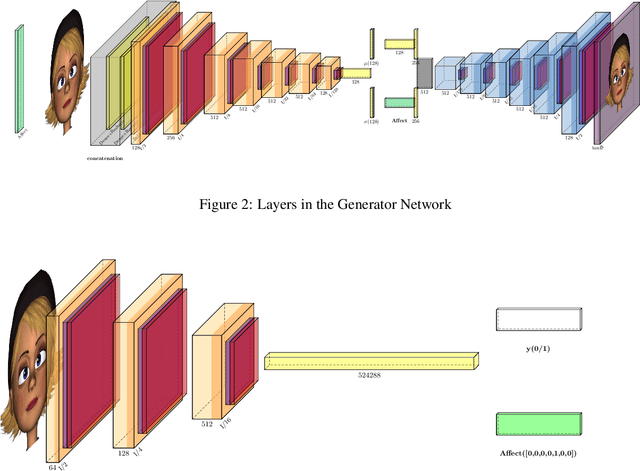

Facial expressions are a form of non-verbal communication that humans perform seamlessly for meaningful transfer of information. Most of the literature addresses the facial expression recognition aspect however, with the advent of Generative Models, it has become possible to explore the affect space in addition to mere classification of a set of expressions. In this article, we propose a generative model architecture which robustly generates a set of facial expressions for multiple character identities and explores the possibilities of generating complex expressions by combining the simple ones.
Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
Jan 06, 2023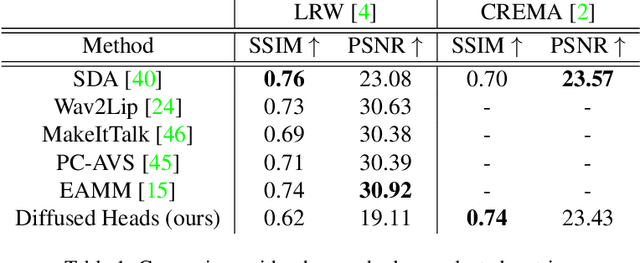
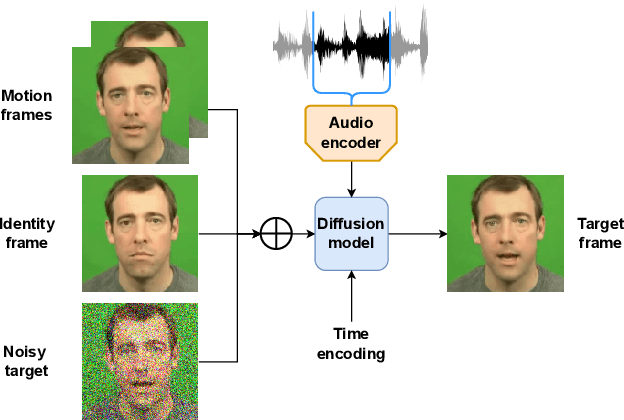

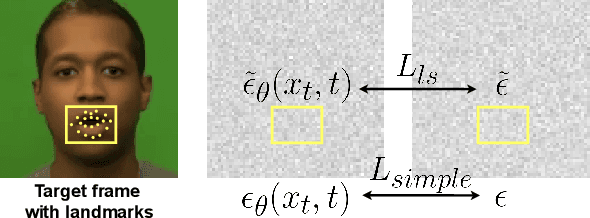
Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.
Transformer-based Multimodal Information Fusion for Facial Expression Analysis
Mar 23, 2022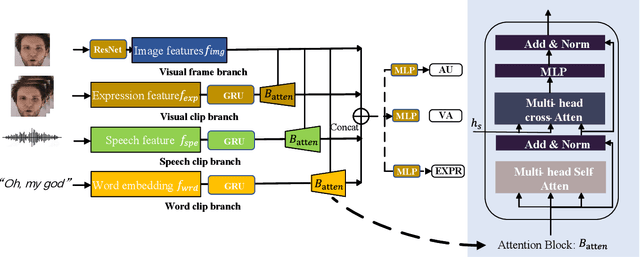
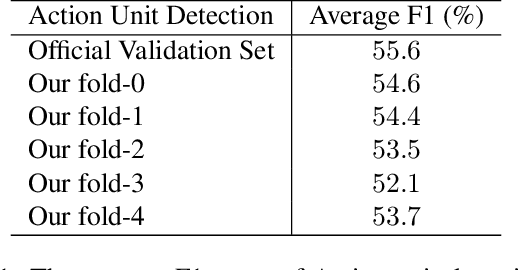
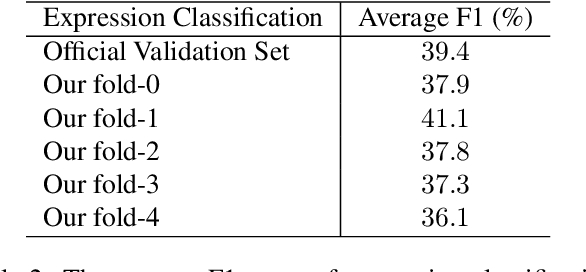
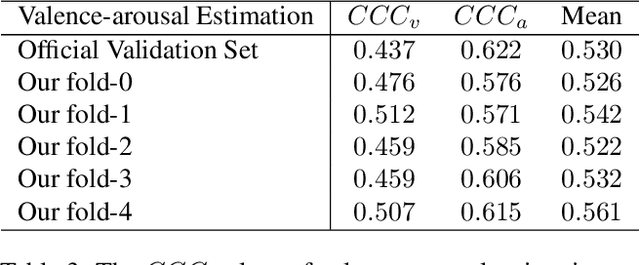
Facial expression analysis has been a crucial research problem in the computer vision area. With the recent development of deep learning techniques and large-scale in-the-wild annotated datasets, facial expression analysis is now aimed at challenges in real world settings. In this paper, we introduce our submission to CVPR2022 Competition on Affective Behavior Analysis in-the-wild (ABAW) that defines four competition tasks, including expression classification, action unit detection, valence-arousal estimation, and a multi-task-learning. The available multimodal information consist of spoken words, speech prosody, and visual expression in videos. Our work proposes four unified transformer-based network frameworks to create the fusion of the above multimodal information. The preliminary results on the official Aff-Wild2 dataset are reported and demonstrate the effectiveness of our proposed method.
Seeing What You Said: Talking Face Generation Guided by a Lip Reading Expert
Mar 29, 2023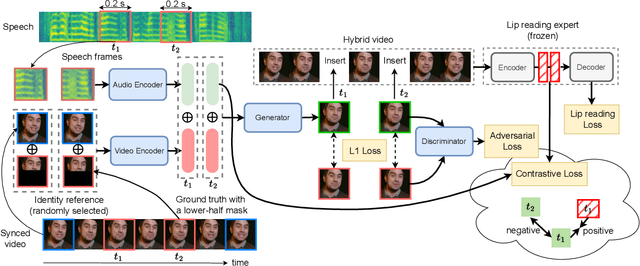
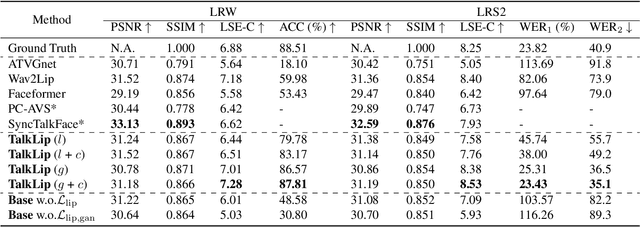
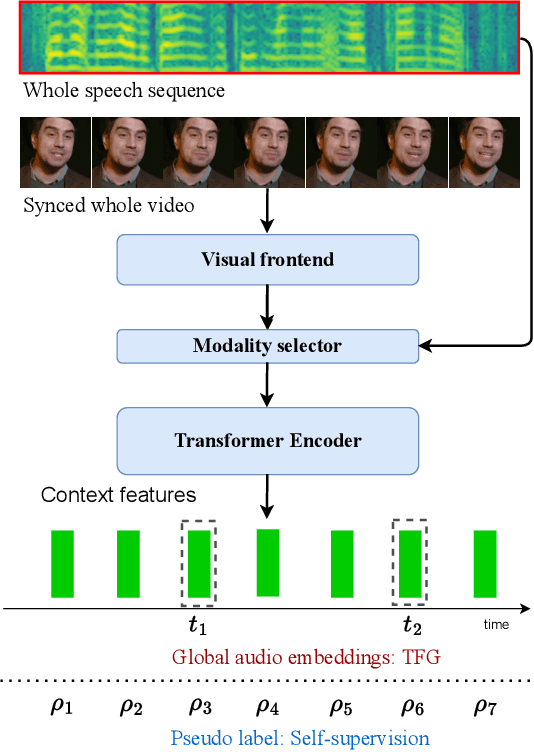
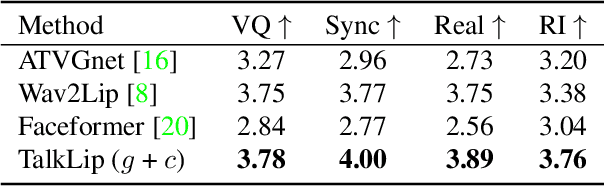
Talking face generation, also known as speech-to-lip generation, reconstructs facial motions concerning lips given coherent speech input. The previous studies revealed the importance of lip-speech synchronization and visual quality. Despite much progress, they hardly focus on the content of lip movements i.e., the visual intelligibility of the spoken words, which is an important aspect of generation quality. To address the problem, we propose using a lip-reading expert to improve the intelligibility of the generated lip regions by penalizing the incorrect generation results. Moreover, to compensate for data scarcity, we train the lip-reading expert in an audio-visual self-supervised manner. With a lip-reading expert, we propose a novel contrastive learning to enhance lip-speech synchronization, and a transformer to encode audio synchronically with video, while considering global temporal dependency of audio. For evaluation, we propose a new strategy with two different lip-reading experts to measure intelligibility of the generated videos. Rigorous experiments show that our proposal is superior to other State-of-the-art (SOTA) methods, such as Wav2Lip, in reading intelligibility i.e., over 38% Word Error Rate (WER) on LRS2 dataset and 27.8% accuracy on LRW dataset. We also achieve the SOTA performance in lip-speech synchronization and comparable performances in visual quality.
Facial Image Reconstruction from Functional Magnetic Resonance Imaging via GAN Inversion with Improved Attribute Consistency
Jul 03, 2022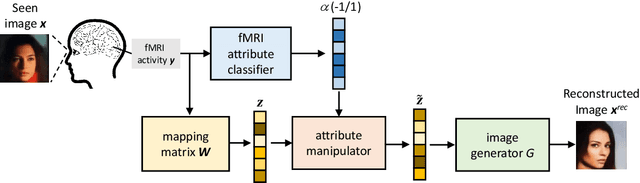


Neuroscience studies have revealed that the brain encodes visual content and embeds information in neural activity. Recently, deep learning techniques have facilitated attempts to address visual reconstructions by mapping brain activity to image stimuli using generative adversarial networks (GANs). However, none of these studies have considered the semantic meaning of latent code in image space. Omitting semantic information could potentially limit the performance. In this study, we propose a new framework to reconstruct facial images from functional Magnetic Resonance Imaging (fMRI) data. With this framework, the GAN inversion is first applied to train an image encoder to extract latent codes in image space, which are then bridged to fMRI data using linear transformation. Following the attributes identified from fMRI data using an attribute classifier, the direction in which to manipulate attributes is decided and the attribute manipulator adjusts the latent code to improve the consistency between the seen image and the reconstructed image. Our experimental results suggest that the proposed framework accomplishes two goals: (1) reconstructing clear facial images from fMRI data and (2) maintaining the consistency of semantic characteristics.
Interruptions detection in video conferences
Feb 25, 2023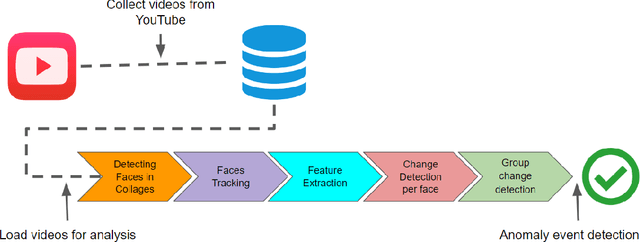
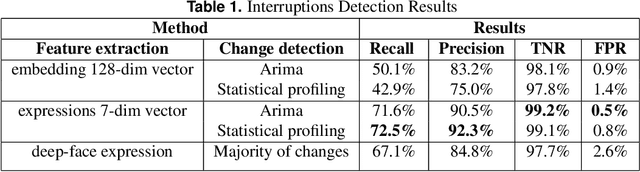
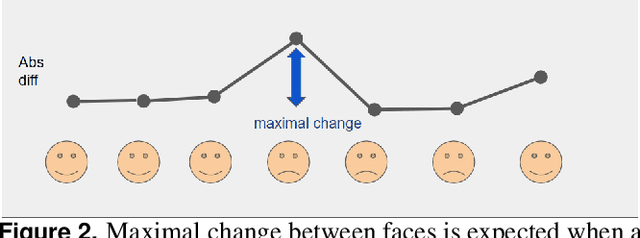
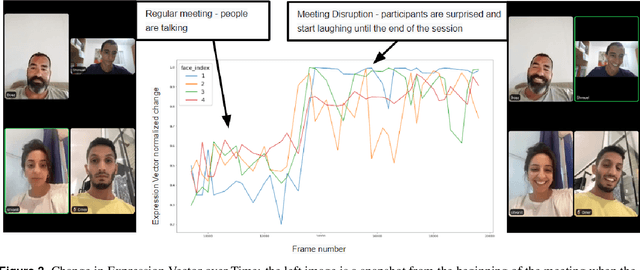
In recent years, video conferencing (VC) popularity has skyrocketed for a wide range of activities. As a result, the number of VC users surged sharply. The sharp increase in VC usage has been accompanied by various newly emerging privacy and security challenges. VC meetings became a target for various security attacks, such as Zoombombing. Other VC-related challenges also emerged. For example, during COVID lockdowns, educators had to teach in online environments struggling with keeping students engaged for extended periods. In parallel, the amount of available VC videos has grown exponentially. Thus, users and companies are limited in finding abnormal segments in VC meetings within the converging volumes of data. Such abnormal events that affect most meeting participants may be indicators of interesting points in time, including security attacks or other changes in meeting climate, like someone joining a meeting or sharing a dramatic content. Here, we present a novel algorithm for detecting abnormal events in VC data. We curated VC publicly available recordings, including meetings with interruptions. We analyzed the videos using our algorithm, extracting time windows where abnormal occurrences were detected. Our algorithm is a pipeline that combines multiple methods in several steps to detect users' faces in each video frame, track face locations during the meeting and generate vector representations of a facial expression for each face in each frame. Vector representations are used to monitor changes in facial expressions throughout the meeting for each participant. The overall change in meeting climate is quantified using those parameters across all participants, and translating them into event anomaly detection. This is the first open pipeline for automatically detecting anomaly events in VC meetings. Our model detects abnormal events with 92.3% precision over the collected dataset.