 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Diff-ID: An Explainable Identity Difference Quantification Framework for DeepFake Detection
Mar 30, 2023
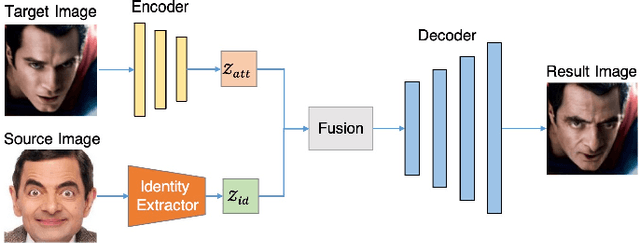
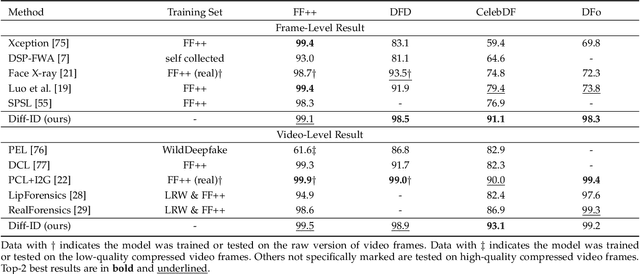


Despite the fact that DeepFake forgery detection algorithms have achieved impressive performance on known manipulations, they often face disastrous performance degradation when generalized to an unseen manipulation. Some recent works show improvement in generalization but rely on features fragile to image distortions such as compression. To this end, we propose Diff-ID, a concise and effective approach that explains and measures the identity loss induced by facial manipulations. When testing on an image of a specific person, Diff-ID utilizes an authentic image of that person as a reference and aligns them to the same identity-insensitive attribute feature space by applying a face-swapping generator. We then visualize the identity loss between the test and the reference image from the image differences of the aligned pairs, and design a custom metric to quantify the identity loss. The metric is then proved to be effective in distinguishing the forgery images from the real ones. Extensive experiments show that our approach achieves high detection performance on DeepFake images and state-of-the-art generalization ability to unknown forgery methods, while also being robust to image distortions.
Towards a Real-Time Facial Analysis System
Sep 21, 2021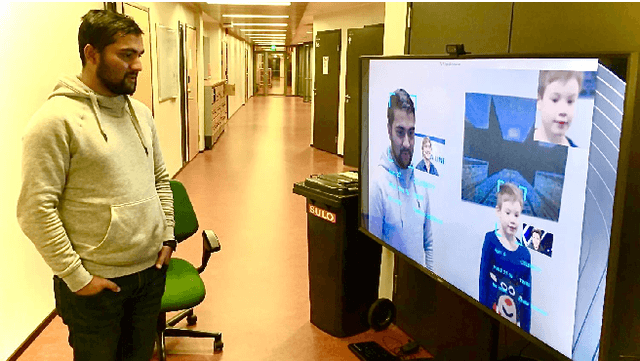
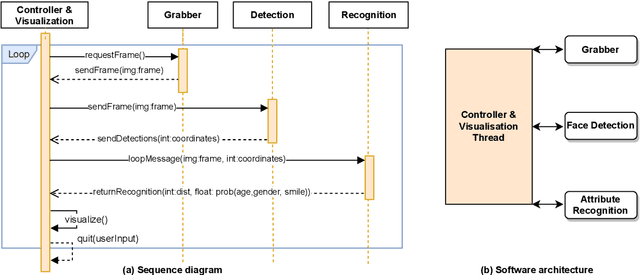
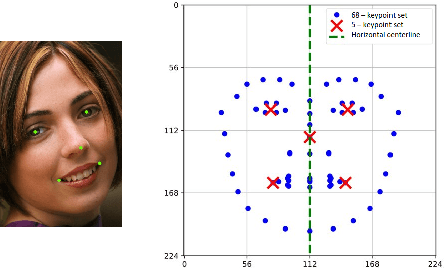
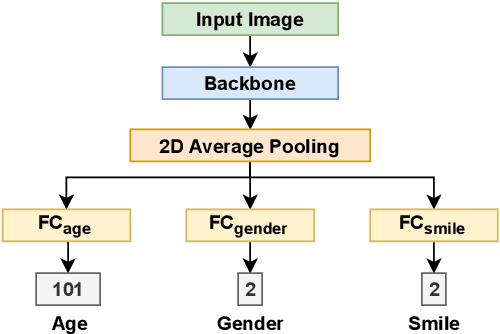
Facial analysis is an active research area in computer vision, with many practical applications. Most of the existing studies focus on addressing one specific task and maximizing its performance. For a complete facial analysis system, one needs to solve these tasks efficiently to ensure a smooth experience. In this work, we present a system-level design of a real-time facial analysis system. With a collection of deep neural networks for object detection, classification, and regression, the system recognizes age, gender, facial expression, and facial similarity for each person that appears in the camera view. We investigate the parallelization and interplay of individual tasks. Results on common off-the-shelf architecture show that the system's accuracy is comparable to the state-of-the-art methods, and the recognition speed satisfies real-time requirements. Moreover, we propose a multitask network for jointly predicting the first three attributes, i.e., age, gender, and facial expression. Source code and trained models are available at https://github.com/mahehu/TUT-live-age-estimator.
Better Aligning Text-to-Image Models with Human Preference
Mar 25, 2023

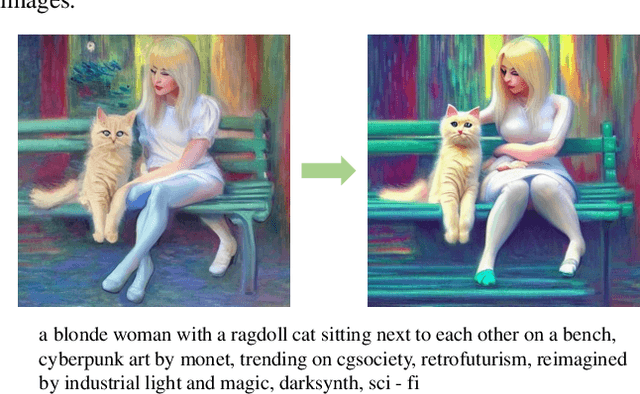
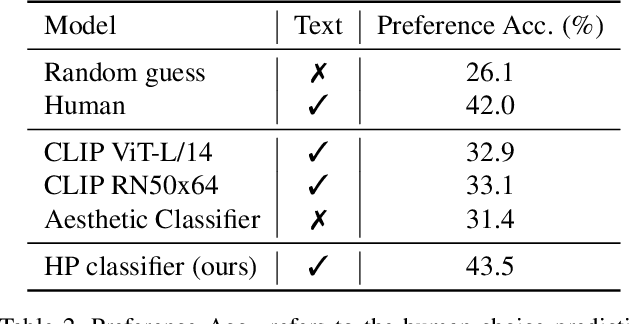
Recent years have witnessed a rapid growth of deep generative models, with text-to-image models gaining significant attention from the public. However, existing models often generate images that do not align well with human aesthetic preferences, such as awkward combinations of limbs and facial expressions. To address this issue, we collect a dataset of human choices on generated images from the Stable Foundation Discord channel. Our experiments demonstrate that current evaluation metrics for generative models do not correlate well with human choices. Thus, we train a human preference classifier with the collected dataset and derive a Human Preference Score (HPS) based on the classifier. Using the HPS, we propose a simple yet effective method to adapt Stable Diffusion to better align with human aesthetic preferences. Our experiments show that the HPS outperforms CLIP in predicting human choices and has good generalization capability towards images generated from other models. By tuning Stable Diffusion with the guidance of the HPS, the adapted model is able to generate images that are more preferred by human users.
Benchmarking Shadow Removal for Facial Landmark Detection and Beyond
Nov 27, 2021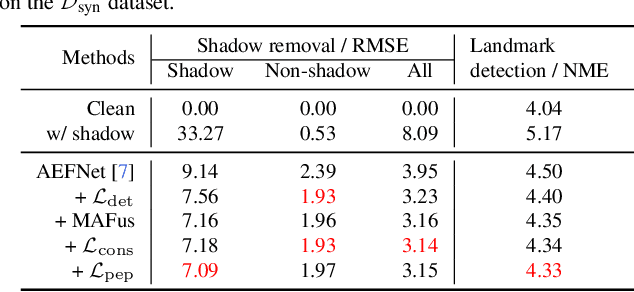
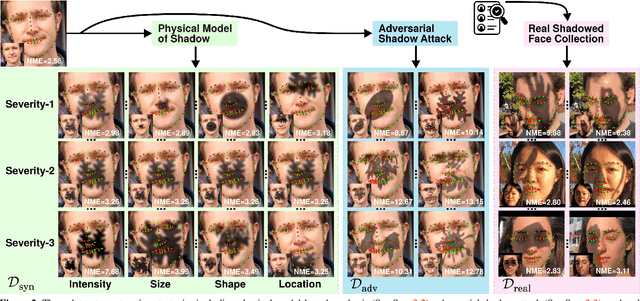
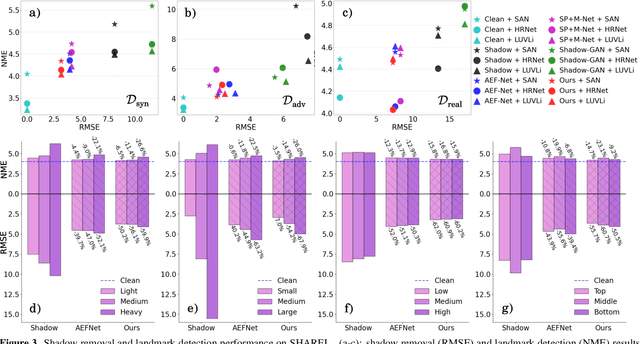
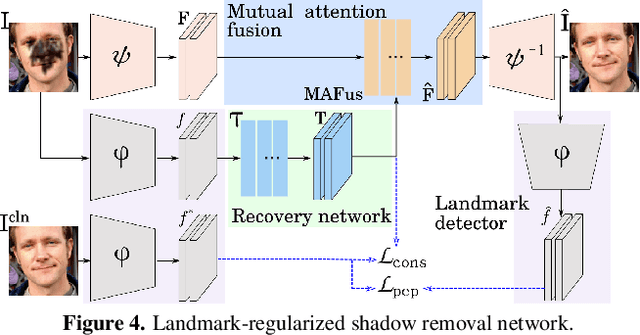
Facial landmark detection is a very fundamental and significant vision task with many important applications. In practice, facial landmark detection can be affected by a lot of natural degradations. One of the most common and important degradations is the shadow caused by light source blocking. While many advanced shadow removal methods have been proposed to recover the image quality in recent years, their effects to facial landmark detection are not well studied. For example, it remains unclear whether shadow removal could enhance the robustness of facial landmark detection to diverse shadow patterns or not. In this work, for the first attempt, we construct a novel benchmark to link two independent but related tasks (i.e., shadow removal and facial landmark detection). In particular, the proposed benchmark covers diverse face shadows with different intensities, sizes, shapes, and locations. Moreover, to mine hard shadow patterns against facial landmark detection, we propose a novel method (i.e., adversarial shadow attack), which allows us to construct a challenging subset of the benchmark for a comprehensive analysis. With the constructed benchmark, we conduct extensive analysis on three state-of-the-art shadow removal methods and three landmark detectors. The observation of this work motivates us to design a novel detection-aware shadow removal framework, which empowers shadow removal to achieve higher restoration quality and enhance the shadow robustness of deployed facial landmark detectors.
Multi-scale multi-modal micro-expression recognition algorithm based on transformer
Jan 11, 2023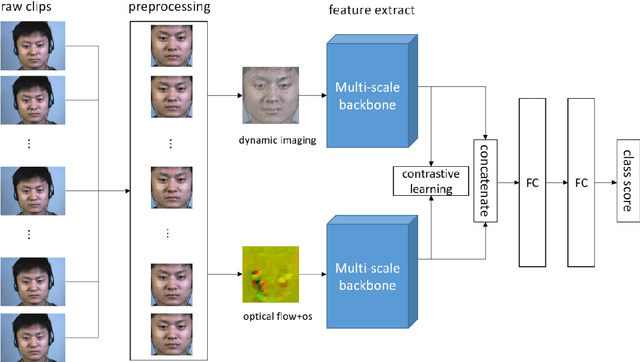

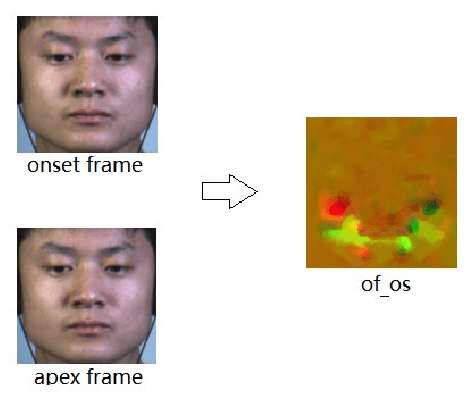
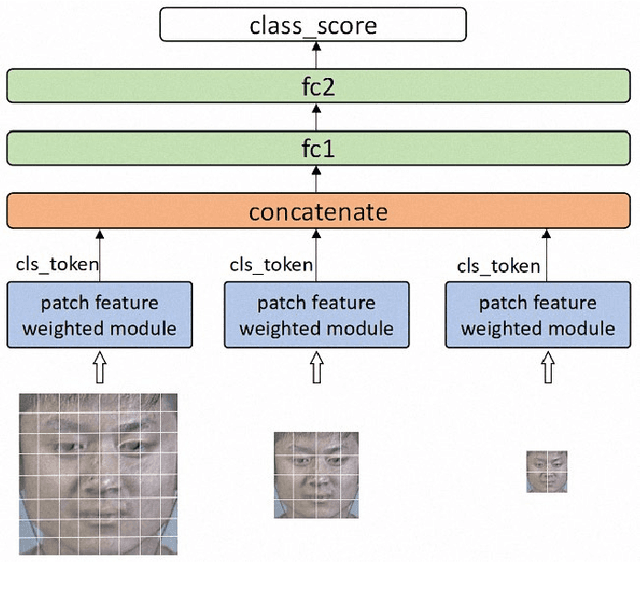
A micro-expression is a spontaneous unconscious facial muscle movement that can reveal the true emotions people attempt to hide. Although manual methods have made good progress and deep learning is gaining prominence. Due to the short duration of micro-expression and different scales of expressed in facial regions, existing algorithms cannot extract multi-modal multi-scale facial region features while taking into account contextual information to learn underlying features. Therefore, in order to solve the above problems, a multi-modal multi-scale algorithm based on transformer network is proposed in this paper, aiming to fully learn local multi-grained features of micro-expressions through two modal features of micro-expressions - motion features and texture features. To obtain local area features of the face at different scales, we learned patch features at different scales for both modalities, and then fused multi-layer multi-headed attention weights to obtain effective features by weighting the patch features, and combined cross-modal contrastive learning for model optimization. We conducted comprehensive experiments on three spontaneous datasets, and the results show the accuracy of the proposed algorithm in single measurement SMIC database is up to 78.73% and the F1 value on CASMEII of the combined database is up to 0.9071, which is at the leading level.
RobustSwap: A Simple yet Robust Face Swapping Model against Attribute Leakage
Mar 28, 2023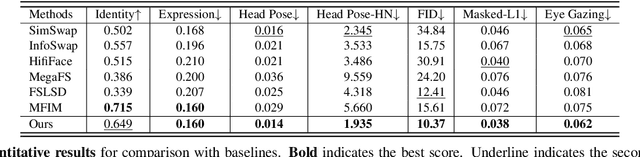

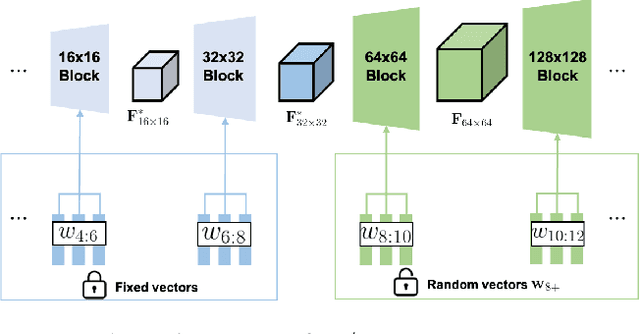
Face swapping aims at injecting a source image's identity (i.e., facial features) into a target image, while strictly preserving the target's attributes, which are irrelevant to identity. However, we observed that previous approaches still suffer from source attribute leakage, where the source image's attributes interfere with the target image's. In this paper, we analyze the latent space of StyleGAN and find the adequate combination of the latents geared for face swapping task. Based on the findings, we develop a simple yet robust face swapping model, RobustSwap, which is resistant to the potential source attribute leakage. Moreover, we exploit the coordination of 3DMM's implicit and explicit information as a guidance to incorporate the structure of the source image and the precise pose of the target image. Despite our method solely utilizing an image dataset without identity labels for training, our model has the capability to generate high-fidelity and temporally consistent videos. Through extensive qualitative and quantitative evaluations, we demonstrate that our method shows significant improvements compared with the previous face swapping models in synthesizing both images and videos. Project page is available at https://robustswap.github.io/
Identity-Preserving Knowledge Distillation for Low-resolution Face Recognition
Mar 15, 2023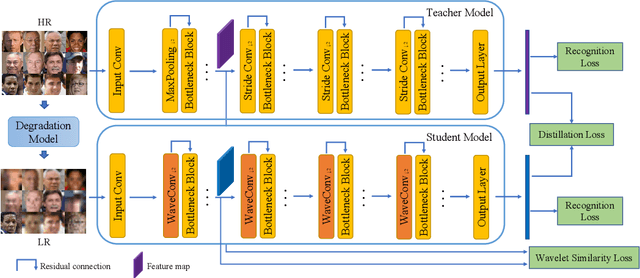
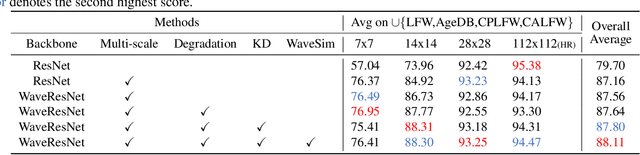
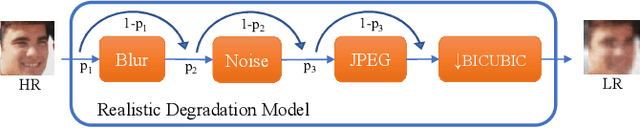
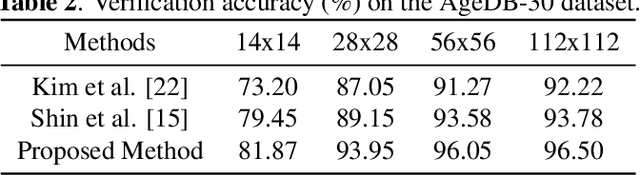
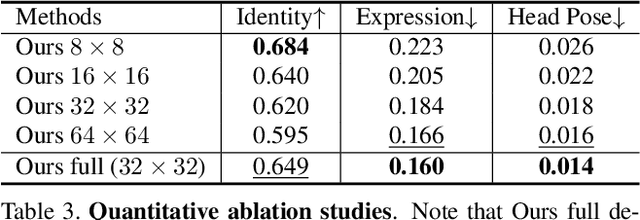
Low-resolution face recognition (LRFR) has become a challenging problem for modern deep face recognition systems. Existing methods mainly leverage prior information from high-resolution (HR) images by either reconstructing facial details with super-resolution techniques or learning a unified feature space. To address this issue, this paper proposes a novel approach which enforces the network to focus on the discriminative information stored in the low-frequency components of a low-resolution (LR) image. A cross-resolution knowledge distillation paradigm is first employed as the learning framework. An identity-preserving network, WaveResNet, and a wavelet similarity loss are then designed to capture low-frequency details and boost performance. Finally, an image degradation model is conceived to simulate more realistic LR training data. Consequently, extensive experimental results show that the proposed method consistently outperforms the baseline model and other state-of-the-art methods across a variety of image resolutions.
Style Transfer for 2D Talking Head Animation
Mar 17, 2023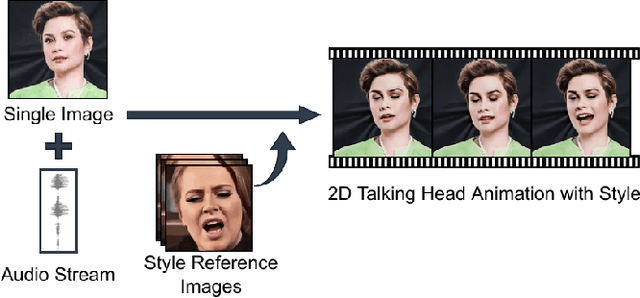
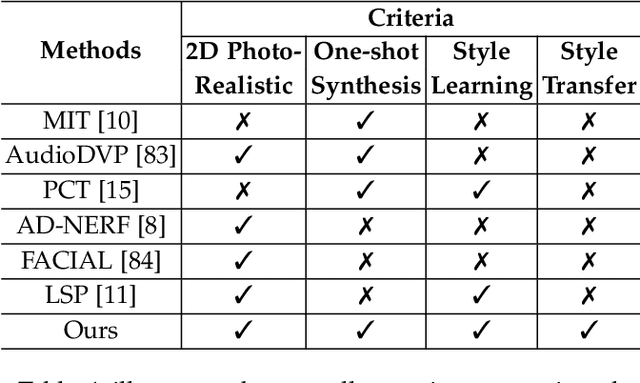
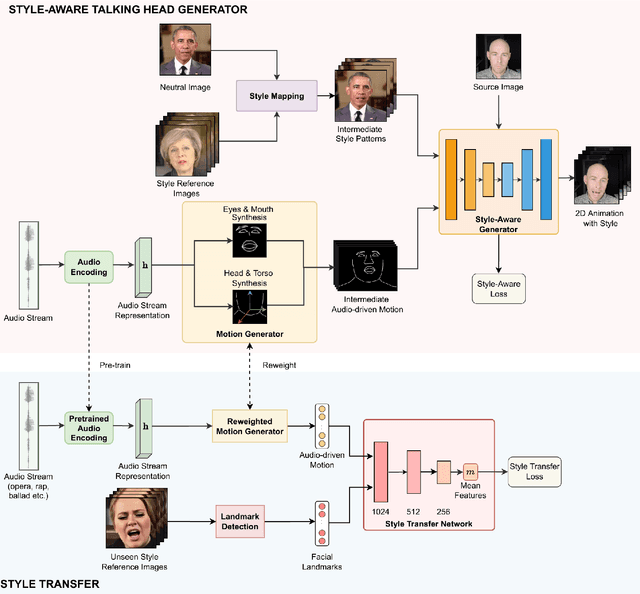
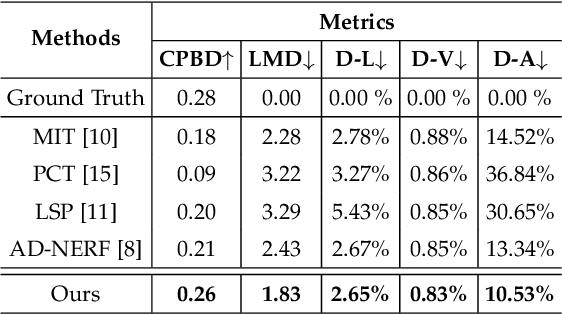
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
CHAMPAGNE: Learning Real-world Conversation from Large-Scale Web Videos
Mar 17, 2023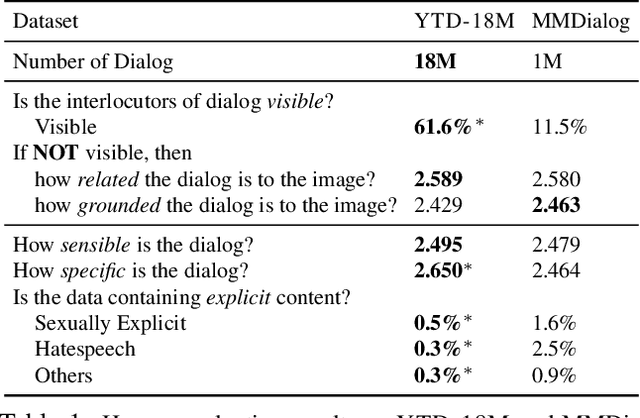
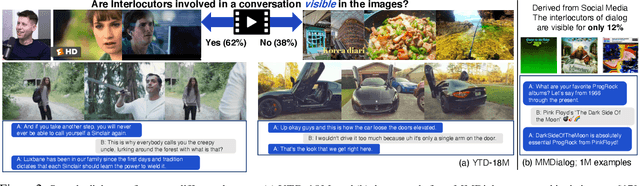
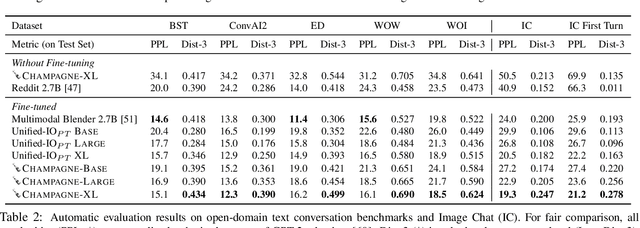
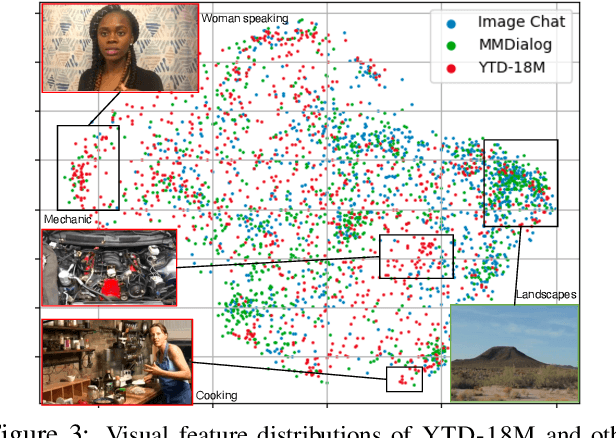
Visual information is central to conversation: body gestures and facial expressions, for example, contribute to meaning that transcends words alone. To date, however, most neural conversational models are limited to just text. We introduce CHAMPAGNE, a generative model of conversations that can account for visual contexts. To train CHAMPAGNE, we collect and release YTD-18M, a large-scale corpus of 18M video-based dialogues. YTD-18M is constructed from web videos: crucial to our data collection pipeline is a pretrained language model that converts error-prone automatic transcripts to a cleaner dialogue format while maintaining meaning. Human evaluation reveals that YTD-18M is more sensible and specific than prior resources (MMDialog, 1M dialogues), while maintaining visual-groundedness. Experiments demonstrate that 1) CHAMPAGNE learns to conduct conversation from YTD-18M; and 2) when fine-tuned, it achieves state-of-the-art results on four vision-language tasks focused on real-world conversations. We release data, models, and code at https://seungjuhan.me/champagne.
Altering Facial Expression Based on Textual Emotion
Dec 02, 2021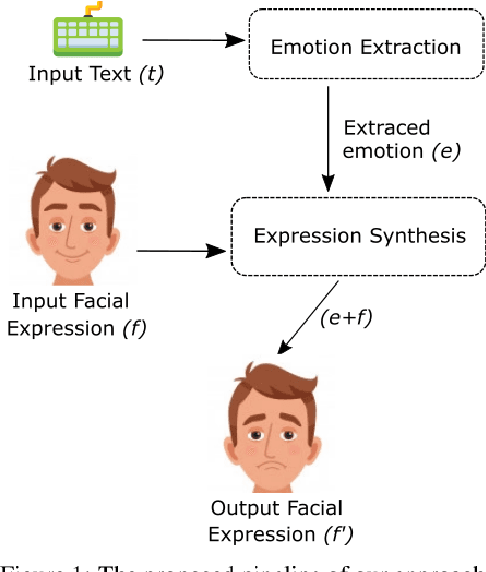
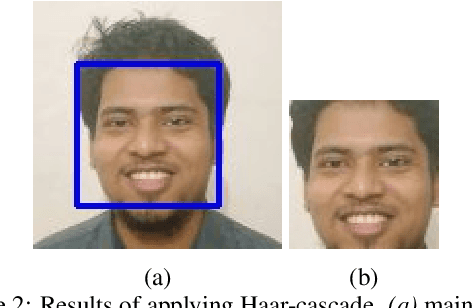
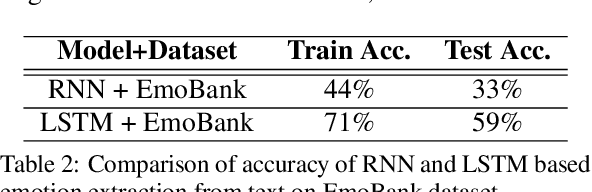
Faces and their expressions are one of the potent subjects for digital images. Detecting emotions from images is an ancient task in the field of computer vision; however, performing its reverse -- synthesizing facial expressions from images -- is quite new. Such operations of regenerating images with different facial expressions, or altering an existing expression in an image require the Generative Adversarial Network (GAN). In this paper, we aim to change the facial expression in an image using GAN, where the input image with an initial expression (i.e., happy) is altered to a different expression (i.e., disgusted) for the same person. We used StarGAN techniques on a modified version of the MUG dataset to accomplish this objective. Moreover, we extended our work further by remodeling facial expressions in an image indicated by the emotion from a given text. As a result, we applied a Long Short-Term Memory (LSTM) method to extract emotion from the text and forwarded it to our expression-altering module. As a demonstration of our working pipeline, we also create an application prototype of a blog that regenerates the profile picture with different expressions based on the user's textual emotion.