 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
TempT: Temporal consistency for Test-time adaptation
Mar 19, 2023

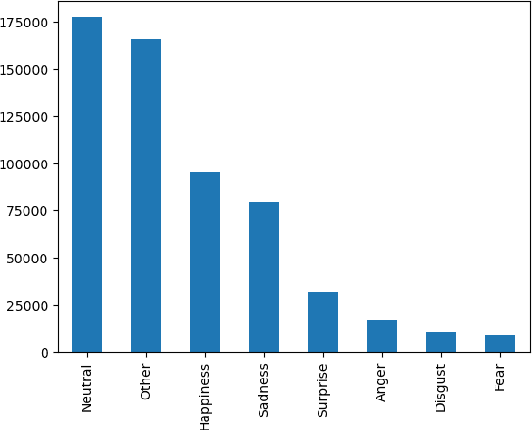
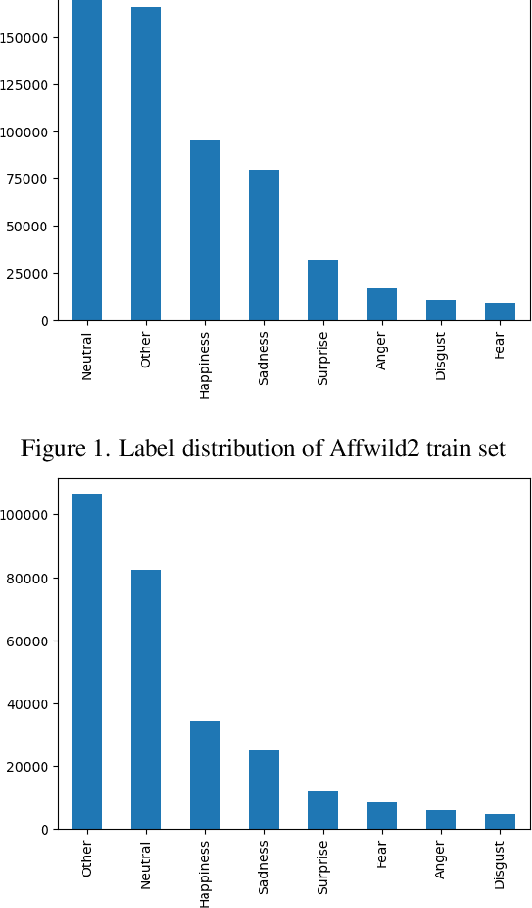

In this technical report, we introduce TempT, a novel method for test time adaptation on videos by ensuring temporal coherence of predictions across sequential frames. TempT is a powerful tool with broad applications in computer vision tasks, including facial expression recognition (FER) in videos. We evaluate TempT's performance on the AffWild2 dataset as part of the Expression Classification Challenge at the 5th Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). Our approach focuses solely on the unimodal visual aspect of the data and utilizes a popular 2D CNN backbone, in contrast to larger sequential or attention based models. Our experimental results demonstrate that TempT has competitive performance in comparison to previous years reported performances, and its efficacy provides a compelling proof of concept for its use in various real world applications.
Deep Facial Synthesis: A New Challenge
Dec 31, 2021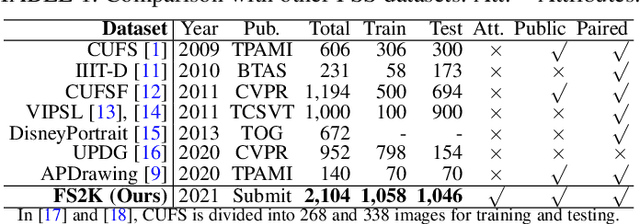


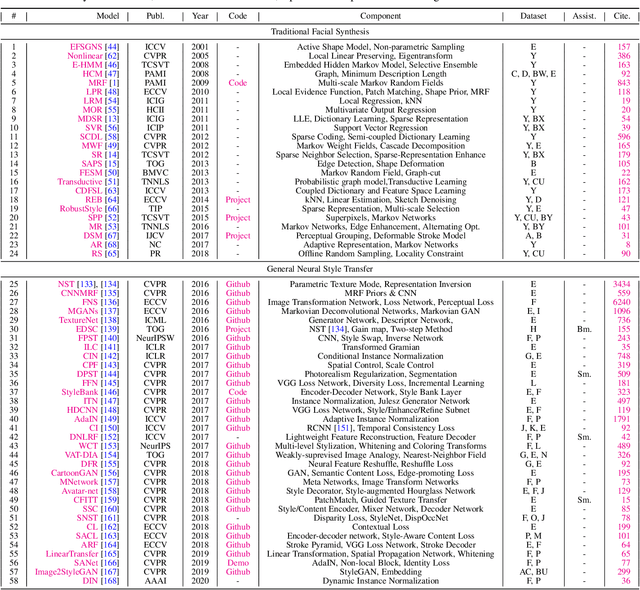
The goal of this paper is to conduct a comprehensive study on the facial sketch synthesis (FSS) problem. However, due to the high costs in obtaining hand-drawn sketch datasets, there lacks a complete benchmark for assessing the development of FSS algorithms over the last decade. As such, we first introduce a high-quality dataset for FSS, named FS2K, which consists of 2,104 image-sketch pairs spanning three types of sketch styles, image backgrounds, lighting conditions, skin colors, and facial attributes. FS2K differs from previous FSS datasets in difficulty, diversity, and scalability, and should thus facilitate the progress of FSS research. Second, we present the largest-scale FSS study by investigating 139 classical methods, including 24 handcrafted feature based facial sketch synthesis approaches, 37 general neural-style transfer methods, 43 deep image-to-image translation methods, and 35 image-to-sketch approaches. Besides, we elaborate comprehensive experiments for existing 19 cutting-edge models. Third, we present a simple baseline for FSS, named FSGAN. With only two straightforward components, i.e., facial-aware masking and style-vector expansion, FSGAN surpasses the performance of all previous state-of-the-art models on the proposed FS2K dataset, by a large margin. Finally, we conclude with lessons learned over the past years, and point out several unsolved challenges. Our open-source code is available at https://github.com/DengPingFan/FSGAN.
Semantic Adversarial Attacks on Face Recognition through Significant Attributes
Jan 28, 2023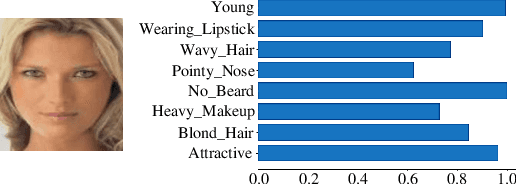
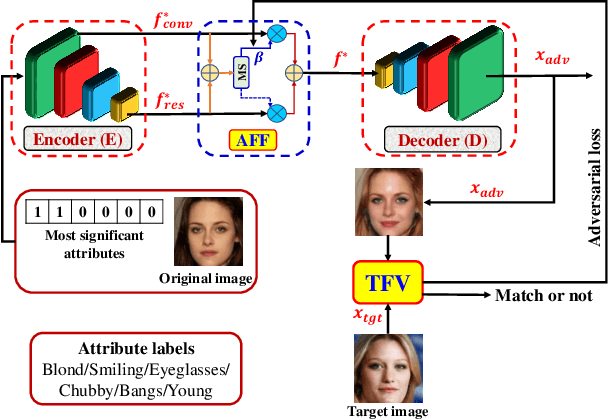
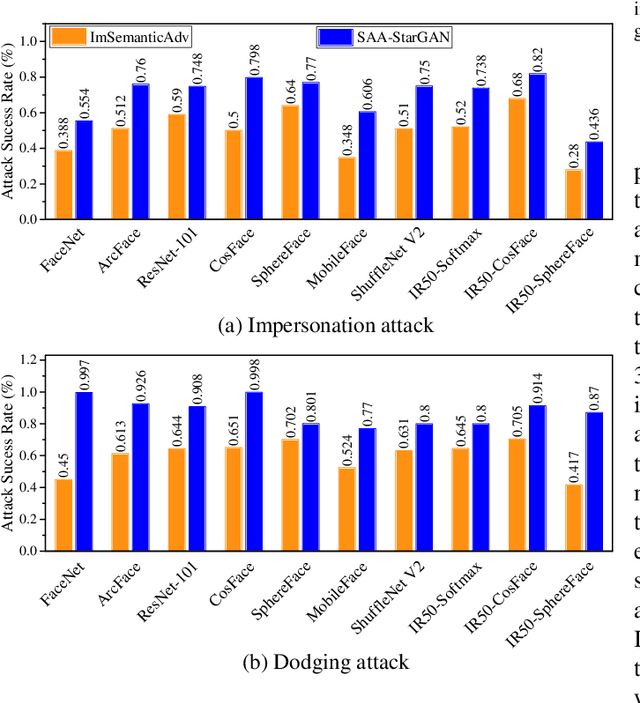

Face recognition is known to be vulnerable to adversarial face images. Existing works craft face adversarial images by indiscriminately changing a single attribute without being aware of the intrinsic attributes of the images. To this end, we propose a new Semantic Adversarial Attack called SAA-StarGAN that tampers with the significant facial attributes for each image. We predict the most significant attributes by applying the cosine similarity or probability score. The probability score method is based on training a Face Verification model for an attribute prediction task to obtain a class probability score for each attribute. The prediction process will help craft adversarial face images more easily and efficiently, as well as improve the adversarial transferability. Then, we change the most significant facial attributes, with either one or more of the facial attributes for impersonation and dodging attacks in white-box and black-box settings. Experimental results show that our method could generate diverse and realistic adversarial face images meanwhile avoid affecting human perception of the face recognition. SAA-StarGAN achieves an 80.5% attack success rate against black-box models, outperforming existing methods by 35.5% under the impersonation attack. Concerning the black-box setting, SAA-StarGAN achieves high attack success rates on various models. The experiments confirm that predicting the most important attributes significantly affects the success of adversarial attacks in both white-box and black-box settings and could enhance the transferability of the crafted adversarial examples.
AFFDEX 2.0: A Real-Time Facial Expression Analysis Toolkit
Feb 24, 2022

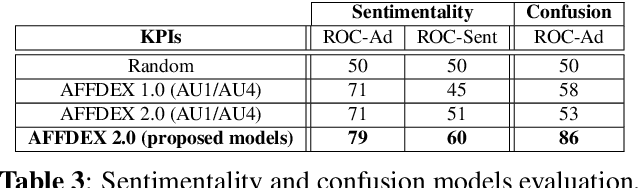

In this paper we introduce AFFDEX 2.0 - a toolkit for analyzing facial expressions in the wild, that is, it is intended for users aiming to; a) estimate the 3D head pose, b) detect facial Action Units (AUs), c) recognize basic emotions and 2 new emotional states (sentimentality and confusion), and d) detect high-level expressive metrics like blink and attention. AFFDEX 2.0 models are mainly based on Deep Learning, and are trained using a large-scale naturalistic dataset consisting of thousands of participants from different demographic groups. AFFDEX 2.0 is an enhanced version of our previous toolkit [1], that is capable of tracking efficiently faces at more challenging conditions, detecting more accurately facial expressions, and recognizing new emotional states (sentimentality and confusion). AFFDEX 2.0 can process multiple faces in real time, and is working across the Windows and Linux platforms.
OrthoGAN:High-Precision Image Generation for Teeth Orthodontic Visualization
Dec 29, 2022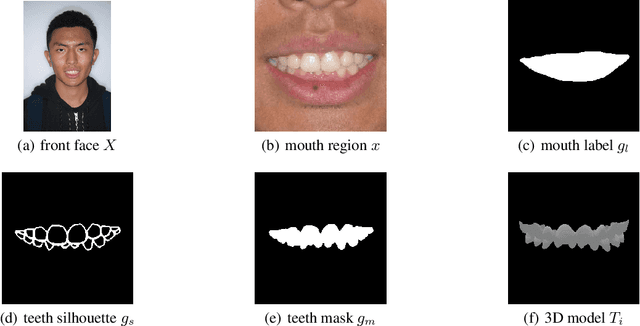
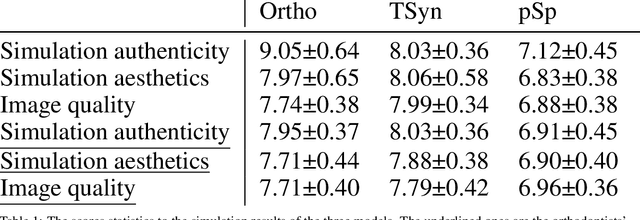
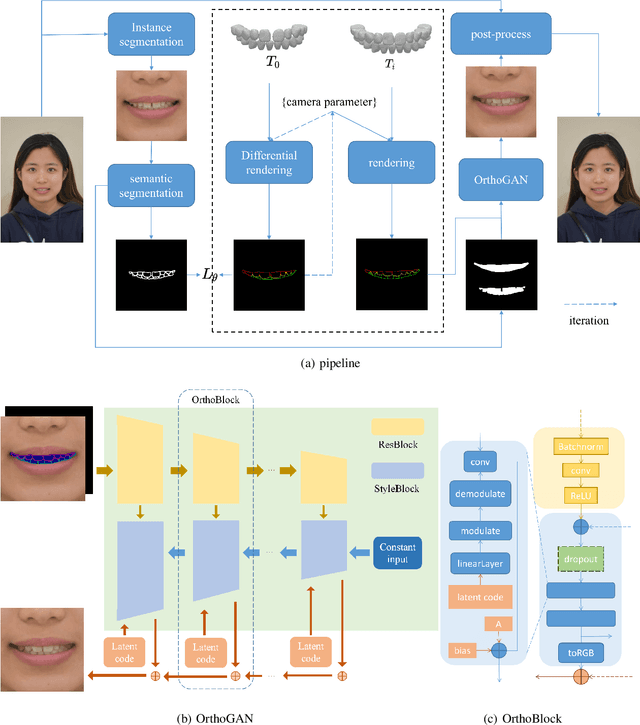
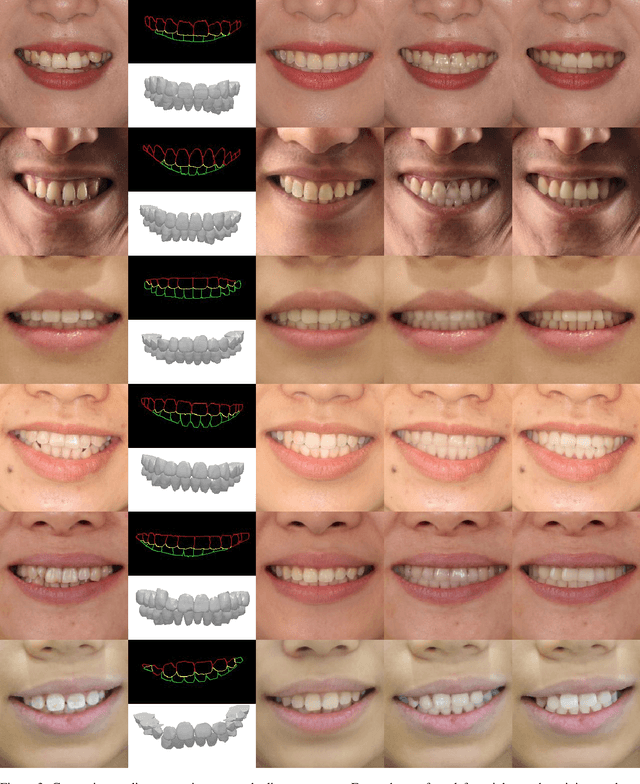
Patients take care of what their teeth will be like after the orthodontics. Orthodontists usually describe the expectation movement based on the original smile images, which is unconvincing. The growth of deep-learning generative models change this situation. It can visualize the outcome of orthodontic treatment and help patients foresee their future teeth and facial appearance. While previous studies mainly focus on 2D or 3D virtual treatment outcome (VTO) at a profile level, the problem of simulating treatment outcome at a frontal facial image is poorly explored. In this paper, we build an efficient and accurate system for simulating virtual teeth alignment effects in a frontal facial image. Our system takes a frontal face image of a patient with visible malpositioned teeth and the patient's 3D scanned teeth model as input, and progressively generates the visual results of the patient's teeth given the specific orthodontics planning steps from the doctor (i.e., the specification of translations and rotations of individual tooth). We design a multi-modal encoder-decoder based generative model to synthesize identity-preserving frontal facial images with aligned teeth. In addition, the original image color information is used to optimize the orthodontic outcomes, making the results more natural. We conduct extensive qualitative and clinical experiments and also a pilot study to validate our method.
Deepfake Detection of Occluded Images Using a Patch-based Approach
Apr 10, 2023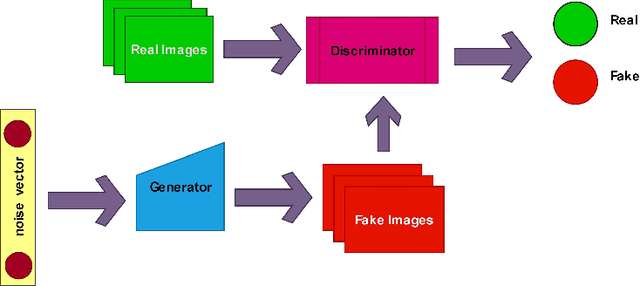
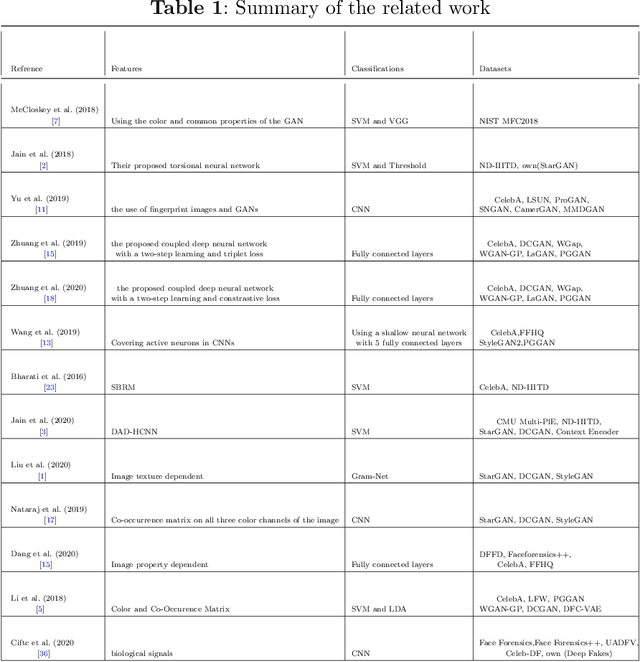

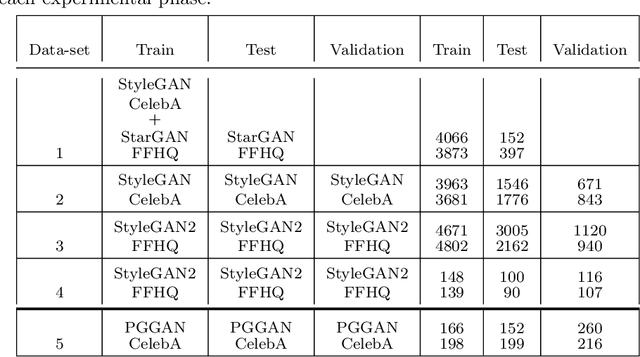
DeepFake involves the use of deep learning and artificial intelligence techniques to produce or change video and image contents typically generated by GANs. Moreover, it can be misused and leads to fictitious news, ethical and financial crimes, and also affects the performance of facial recognition systems. Thus, detection of real or fake images is significant specially to authenticate originality of people's images or videos. One of the most important challenges in this topic is obstruction that decreases the system precision. In this study, we present a deep learning approach using the entire face and face patches to distinguish real/fake images in the presence of obstruction with a three-path decision: first entire-face reasoning, second a decision based on the concatenation of feature vectors of face patches, and third a majority vote decision based on these features. To test our approach, new datasets including real and fake images are created. For producing fake images, StyleGAN and StyleGAN2 are trained by FFHQ images and also StarGAN and PGGAN are trained by CelebA images. The CelebA and FFHQ datasets are used as real images. The proposed approach reaches higher results in early epochs than other methods and increases the SoTA results by 0.4\%-7.9\% in the different built data-sets. Also, we have shown in experimental results that weighing the patches may improve accuracy.
A Unified Compression Framework for Efficient Speech-Driven Talking-Face Generation
Apr 02, 2023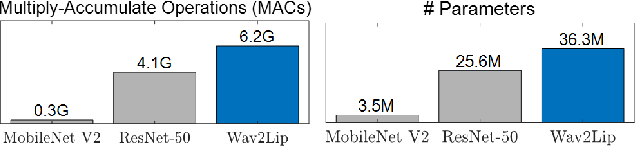
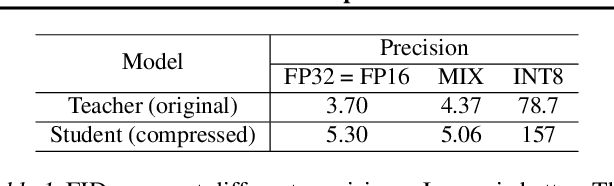
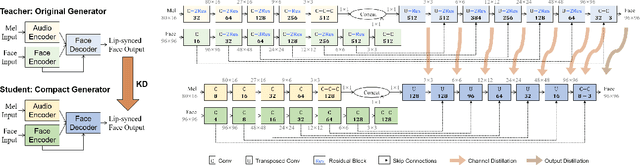
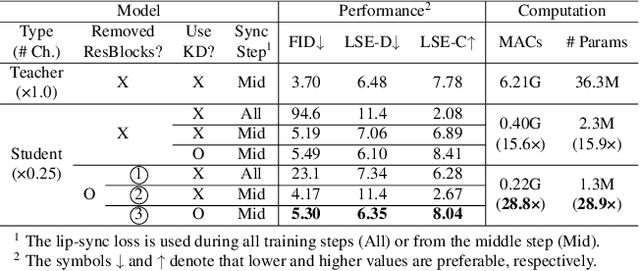
Virtual humans have gained considerable attention in numerous industries, e.g., entertainment and e-commerce. As a core technology, synthesizing photorealistic face frames from target speech and facial identity has been actively studied with generative adversarial networks. Despite remarkable results of modern talking-face generation models, they often entail high computational burdens, which limit their efficient deployment. This study aims to develop a lightweight model for speech-driven talking-face synthesis. We build a compact generator by removing the residual blocks and reducing the channel width from Wav2Lip, a popular talking-face generator. We also present a knowledge distillation scheme to stably yet effectively train the small-capacity generator without adversarial learning. We reduce the number of parameters and MACs by 28$\times$ while retaining the performance of the original model. Moreover, to alleviate a severe performance drop when converting the whole generator to INT8 precision, we adopt a selective quantization method that uses FP16 for the quantization-sensitive layers and INT8 for the other layers. Using this mixed precision, we achieve up to a 19$\times$ speedup on edge GPUs without noticeably compromising the generation quality.
Automatic Quantification of Facial Asymmetry using Facial Landmarks
Mar 20, 2021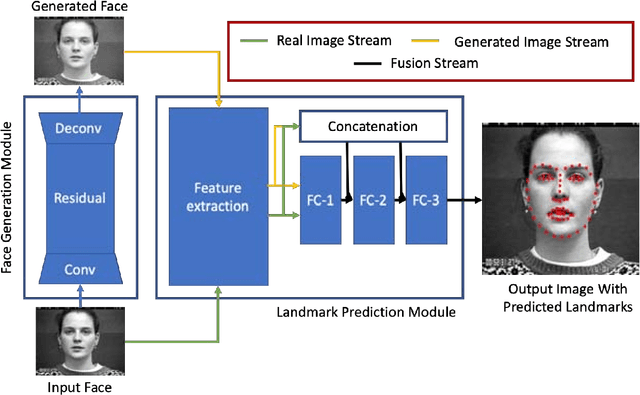
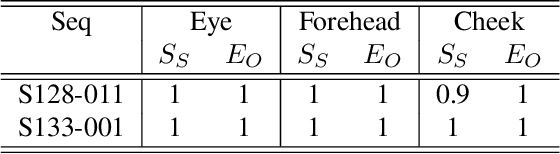

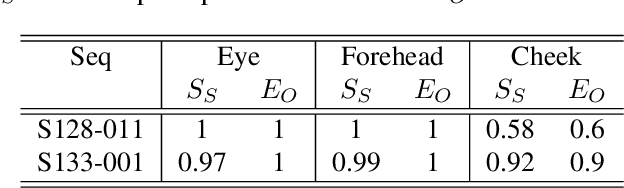
One-sided facial paralysis causes uneven movements of facial muscles on the sides of the face. Physicians currently assess facial asymmetry in a subjective manner based on their clinical experience. This paper proposes a novel method to provide an objective and quantitative asymmetry score for frontal faces. Our metric has the potential to help physicians for diagnosis as well as monitoring the rehabilitation of patients with one-sided facial paralysis. A deep learning based landmark detection technique is used to estimate style invariant facial landmark points and dense optical flow is used to generate motion maps from a short sequence of frames. Six face regions are considered corresponding to the left and right parts of the forehead, eyes, and mouth. Motion is computed and compared between the left and the right parts of each region of interest to estimate the symmetry score. For testing, asymmetric sequences are synthetically generated from a facial expression dataset. A score equation is developed to quantify symmetry in both symmetric and asymmetric face sequences.
* 5 pages, 4 figures
Learning Multi-dimensional Edge Feature-based AU Relation Graph for Facial Action Unit Recognition
May 02, 2022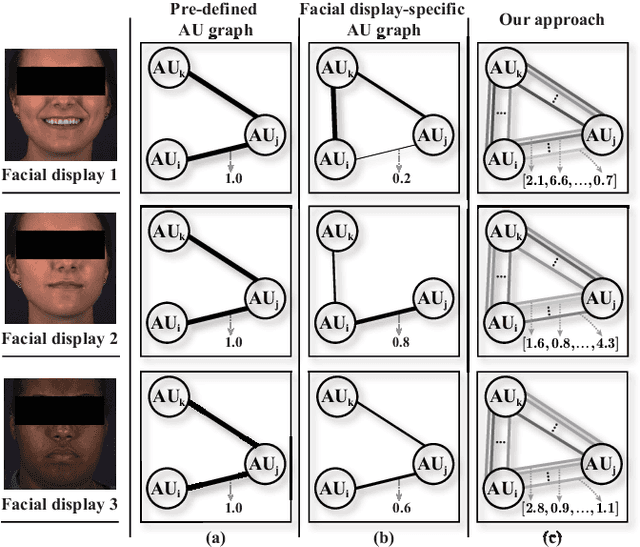
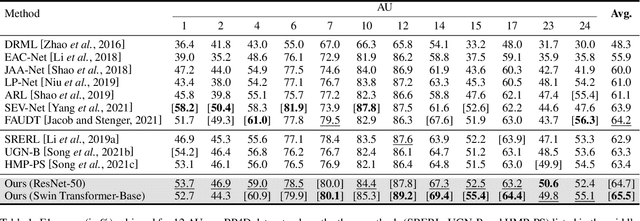
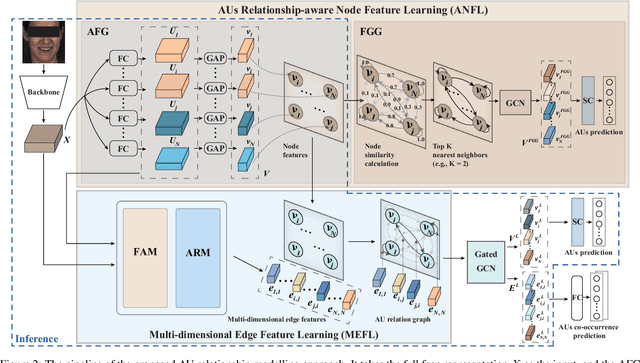
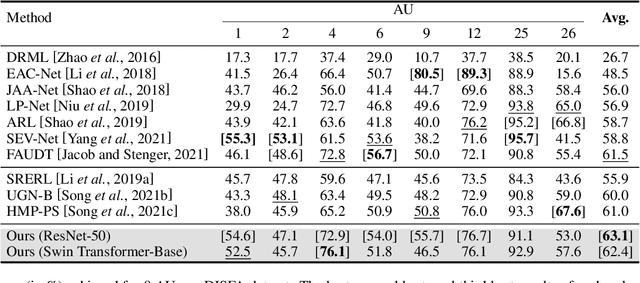
The activations of Facial Action Units (AUs) mutually influence one another. While the relationship between a pair of AUs can be complex and unique, existing approaches fail to specifically and explicitly represent such cues for each pair of AUs in each facial display. This paper proposes an AU relationship modelling approach that deep learns a unique graph to explicitly describe the relationship between each pair of AUs of the target facial display. Our approach first encodes each AU's activation status and its association with other AUs into a node feature. Then, it learns a pair of multi-dimensional edge features to describe multiple task-specific relationship cues between each pair of AUs. During both node and edge feature learning, our approach also considers the influence of the unique facial display on AUs' relationship by taking the full face representation as an input. Experimental results on BP4D and DISFA datasets show that both node and edge feature learning modules provide large performance improvements for CNN and transformer-based backbones, with our best systems achieving the state-of-the-art AU recognition results. Our approach not only has a strong capability in modelling relationship cues for AU recognition but also can be easily incorporated into various backbones. Our PyTorch code is made available.
Style Transfer for 2D Talking Head Animation
Mar 22, 2023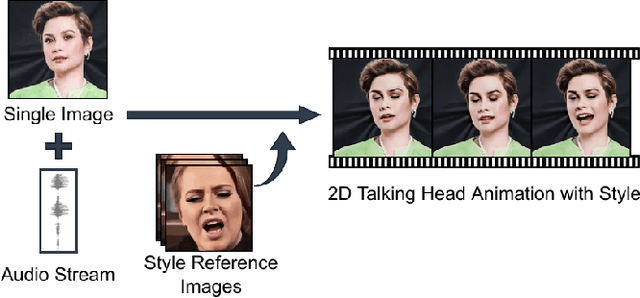
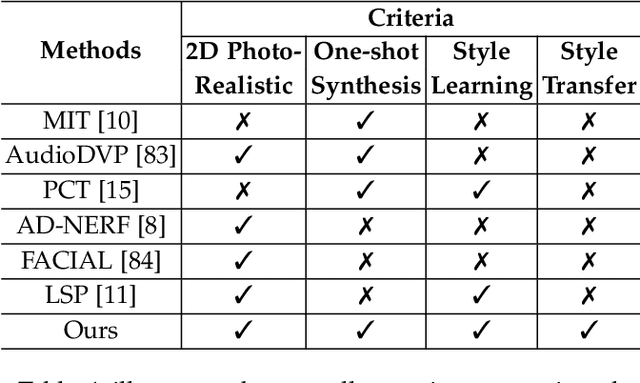
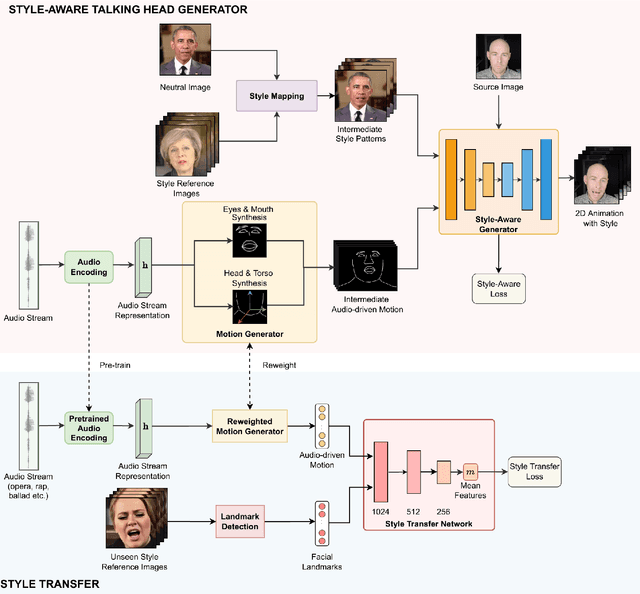
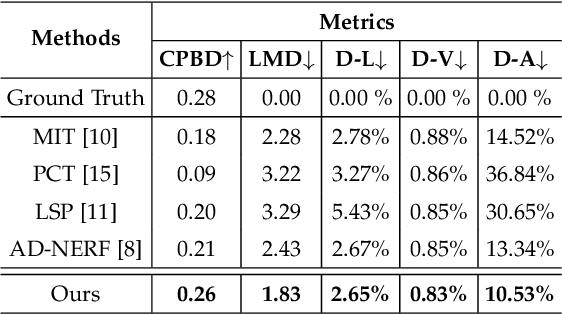
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.