 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Integrating Holistic and Local Information to Estimate Emotional Reaction Intensity
May 09, 2023
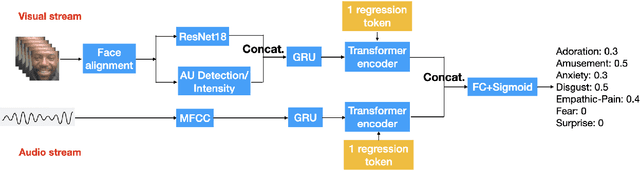
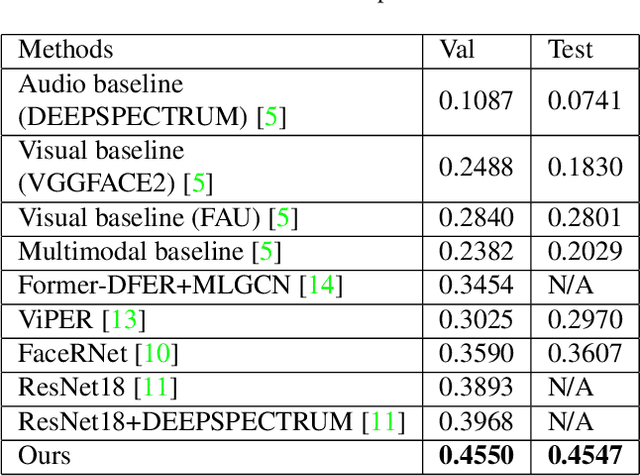
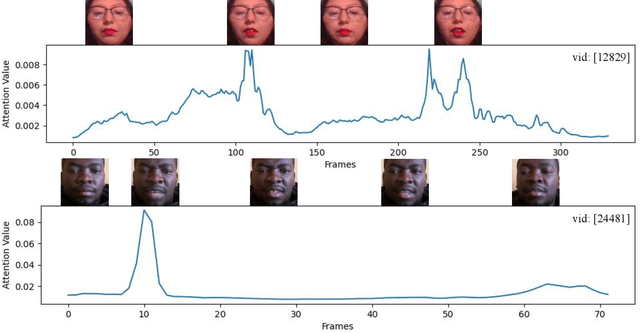
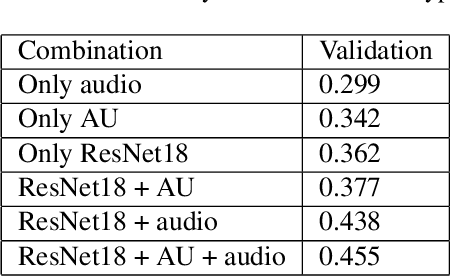
Video-based Emotional Reaction Intensity (ERI) estimation measures the intensity of subjects' reactions to stimuli along several emotional dimensions from videos of the subject as they view the stimuli. We propose a multi-modal architecture for video-based ERI combining video and audio information. Video input is encoded spatially first, frame-by-frame, combining features encoding holistic aspects of the subjects' facial expressions and features encoding spatially localized aspects of their expressions. Input is then combined across time: from frame-to-frame using gated recurrent units (GRUs), then globally by a transformer. We handle variable video length with a regression token that accumulates information from all frames into a fixed-dimensional vector independent of video length. Audio information is handled similarly: spectral information extracted within each frame is integrated across time by a cascade of GRUs and a transformer with regression token. The video and audio regression tokens' outputs are merged by concatenation, then input to a final fully connected layer producing intensity estimates. Our architecture achieved excellent performance on the Hume-Reaction dataset in the ERI Esimation Challenge of the Fifth Competition on Affective Behavior Analysis in-the-Wild (ABAW5). The Pearson Correlation Coefficients between estimated and subject self-reported scores, averaged across all emotions, were 0.455 on the validation dataset and 0.4547 on the test dataset, well above the baselines. The transformer's self-attention mechanism enables our architecture to focus on the most critical video frames regardless of length. Ablation experiments establish the advantages of combining holistic/local features and of multi-modal integration. Code available at https://github.com/HKUST-NISL/ABAW5.
GREAT Score: Global Robustness Evaluation of Adversarial Perturbation using Generative Models
May 03, 2023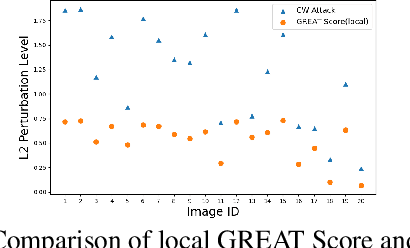
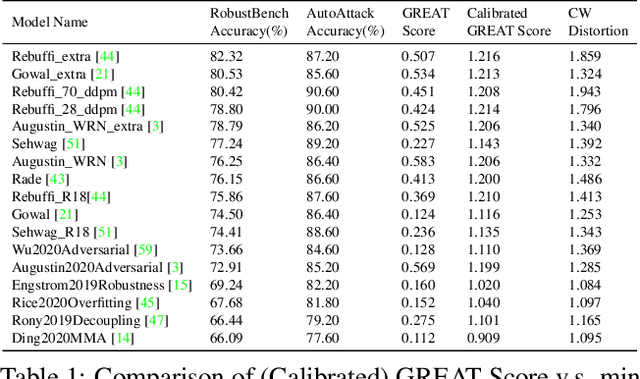
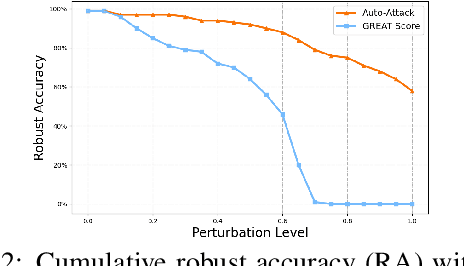
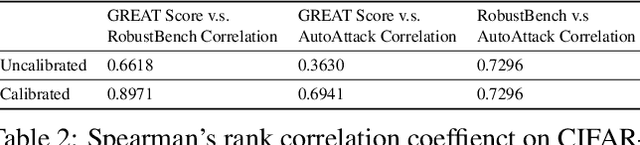
Current studies on adversarial robustness mainly focus on aggregating local robustness results from a set of data samples to evaluate and rank different models. However, the local statistics may not well represent the true global robustness of the underlying unknown data distribution. To address this challenge, this paper makes the first attempt to present a new framework, called GREAT Score , for global robustness evaluation of adversarial perturbation using generative models. Formally, GREAT Score carries the physical meaning of a global statistic capturing a mean certified attack-proof perturbation level over all samples drawn from a generative model. For finite-sample evaluation, we also derive a probabilistic guarantee on the sample complexity and the difference between the sample mean and the true mean. GREAT Score has several advantages: (1) Robustness evaluations using GREAT Score are efficient and scalable to large models, by sparing the need of running adversarial attacks. In particular, we show high correlation and significantly reduced computation cost of GREAT Score when compared to the attack-based model ranking on RobustBench (Croce,et. al. 2021). (2) The use of generative models facilitates the approximation of the unknown data distribution. In our ablation study with different generative adversarial networks (GANs), we observe consistency between global robustness evaluation and the quality of GANs. (3) GREAT Score can be used for remote auditing of privacy-sensitive black-box models, as demonstrated by our robustness evaluation on several online facial recognition services.
Deep Semantic Manipulation of Facial Videos
Nov 15, 2021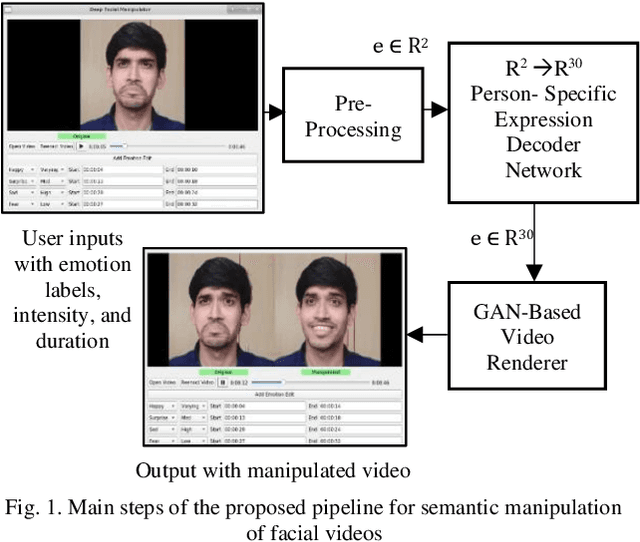
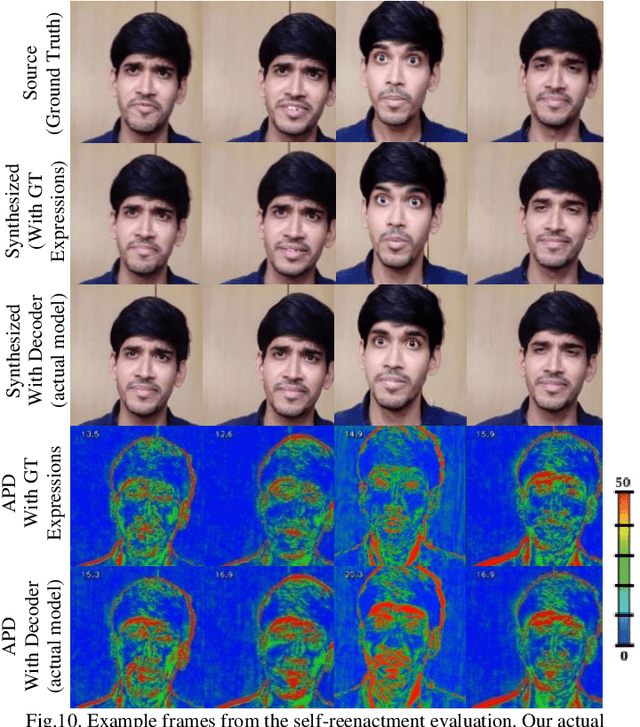

Editing and manipulating facial features in videos is an interesting and important field of research with a plethora of applications, ranging from movie post-production and visual effects to realistic avatars for video games and virtual assistants. To the best of our knowledge, this paper proposes the first method to perform photorealistic manipulation of facial expressions in videos. Our method supports semantic video manipulation based on neural rendering and 3D-based facial expression modelling. We focus on interactive manipulation of the videos by altering and controlling the facial expressions, achieving promising photorealistic results. The proposed method is based on a disentangled representation and estimation of the 3D facial shape and activity, providing the user with intuitive and easy-to-use control of the facial expressions in the input video. We also introduce a user-friendly, interactive AI tool that processes human-readable semantic labels about the desired emotion manipulations in specific parts of the input video and synthesizes photorealistic manipulated videos. We achieve that by mapping the emotion labels to valence-arousal (VA) values, which in turn are mapped to disentangled 3D facial expressions through an especially designed and trained expression decoder network. The paper presents detailed qualitative and quantitative experiments, which demonstrate the effectiveness of our system and the promising results it achieves. Additional results and videos can be found at the supplementary material (https://github.com/Girish-03/DeepSemManipulation).
DiFaReli: Diffusion Face Relighting
Apr 21, 2023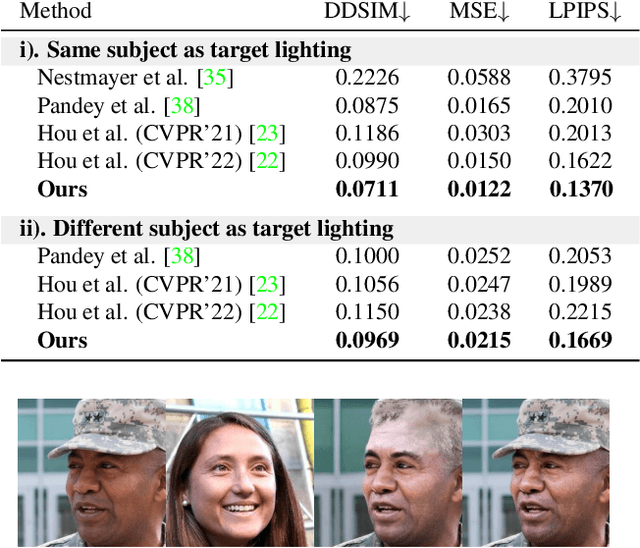
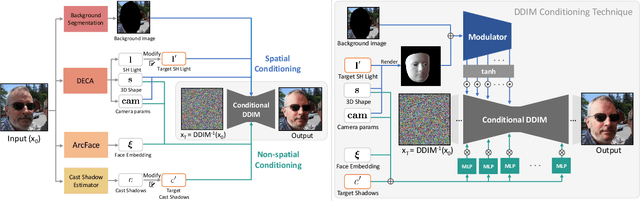
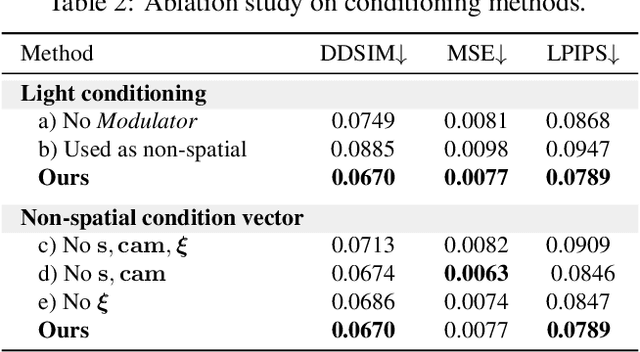

We present a novel approach to single-view face relighting in the wild. Handling non-diffuse effects, such as global illumination or cast shadows, has long been a challenge in face relighting. Prior work often assumes Lambertian surfaces, simplified lighting models or involves estimating 3D shape, albedo, or a shadow map. This estimation, however, is error-prone and requires many training examples with lighting ground truth to generalize well. Our work bypasses the need for accurate estimation of intrinsic components and can be trained solely on 2D images without any light stage data, multi-view images, or lighting ground truth. Our key idea is to leverage a conditional diffusion implicit model (DDIM) for decoding a disentangled light encoding along with other encodings related to 3D shape and facial identity inferred from off-the-shelf estimators. We also propose a novel conditioning technique that eases the modeling of the complex interaction between light and geometry by using a rendered shading reference to spatially modulate the DDIM. We achieve state-of-the-art performance on standard benchmark Multi-PIE and can photorealistically relight in-the-wild images. Please visit our page: https://diffusion-face-relighting.github.io
Adaptively Lighting up Facial Expression Crucial Regions via Local Non-Local Joint Network
Mar 26, 2022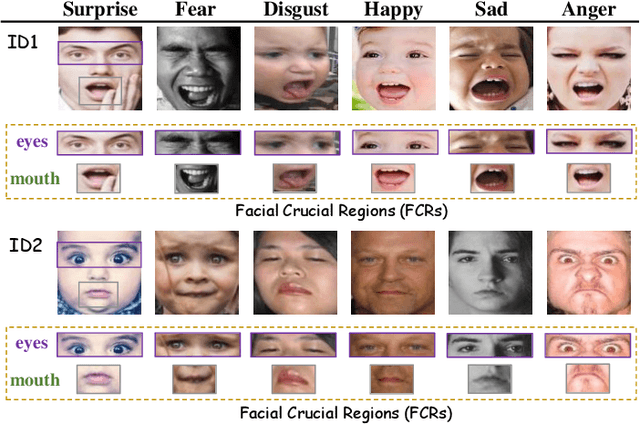
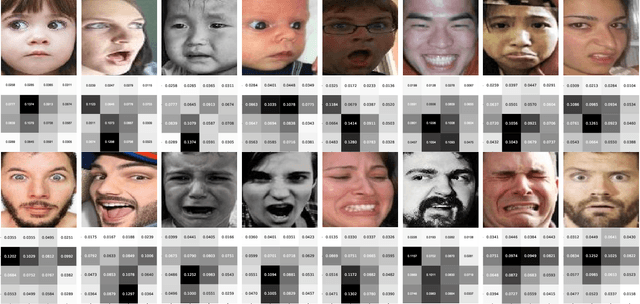
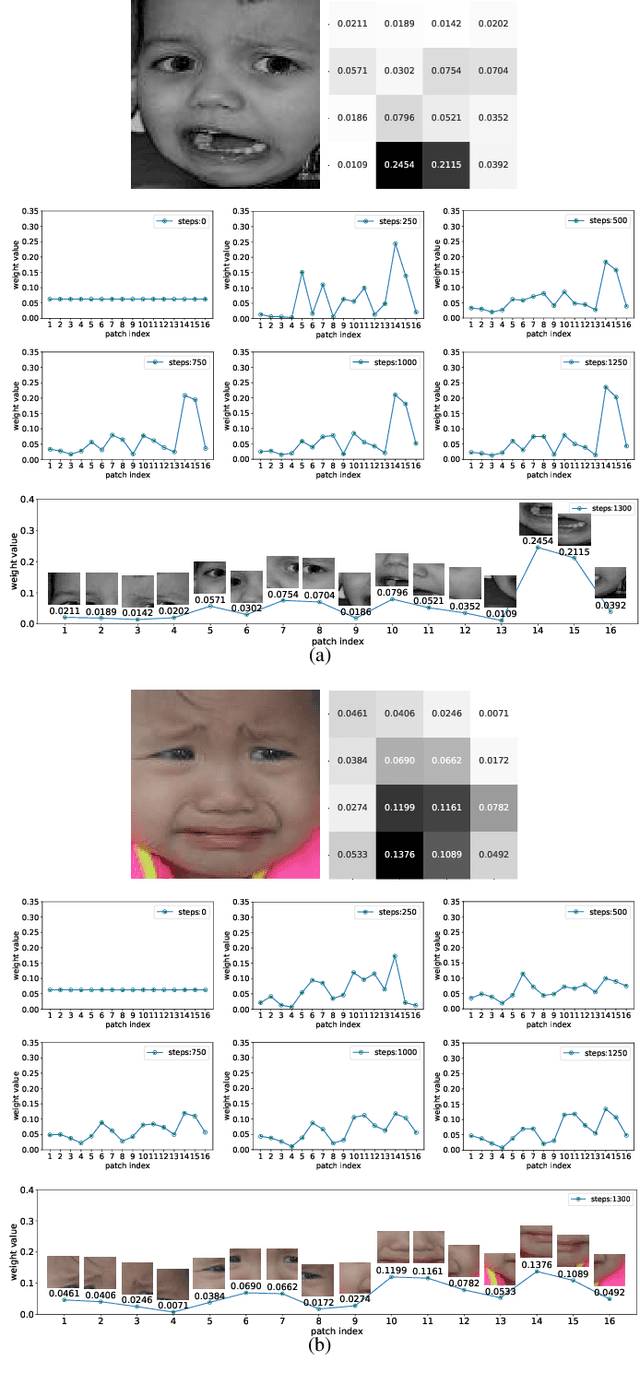
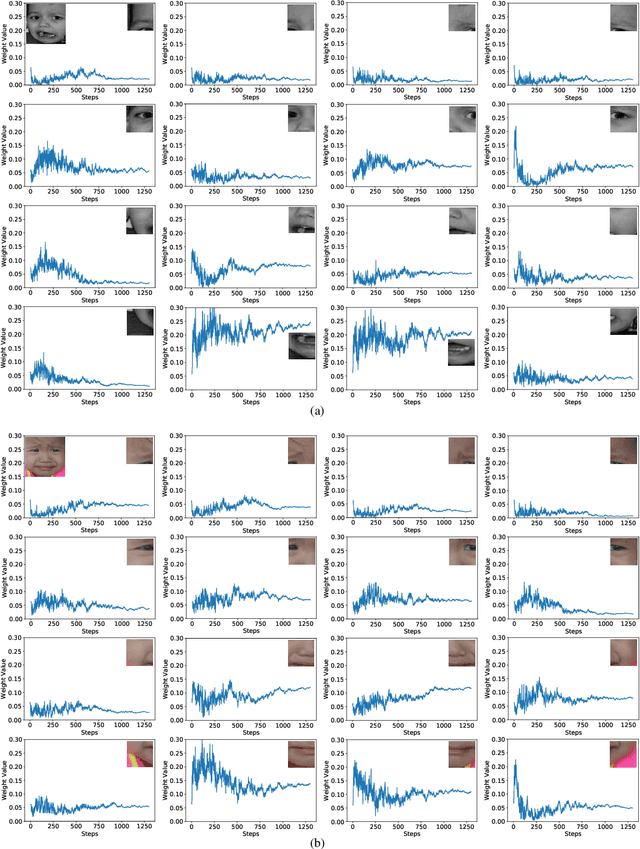
Facial expression recognition (FER) is still one challenging research due to the small inter-class discrepancy in the facial expression data. In view of the significance of facial crucial regions for FER, many existing researches utilize the prior information from some annotated crucial points to improve the performance of FER. However, it is complicated and time-consuming to manually annotate facial crucial points, especially for vast wild expression images. Based on this, a local non-local joint network is proposed to adaptively light up the facial crucial regions in feature learning of FER in this paper. In the proposed method, two parts are constructed based on facial local and non-local information respectively, where an ensemble of multiple local networks are proposed to extract local features corresponding to multiple facial local regions and a non-local attention network is addressed to explore the significance of each local region. Especially, the attention weights obtained by the non-local network is fed into the local part to achieve the interactive feedback between the facial global and local information. Interestingly, the non-local weights corresponding to local regions are gradually updated and higher weights are given to more crucial regions. Moreover, U-Net is employed to extract the integrated features of deep semantic information and low hierarchical detail information of expression images. Finally, experimental results illustrate that the proposed method achieves more competitive performance compared with several state-of-the art methods on five benchmark datasets. Noticeably, the analyses of the non-local weights corresponding to local regions demonstrate that the proposed method can automatically enhance some crucial regions in the process of feature learning without any facial landmark information.
Sparsifying Bayesian neural networks with latent binary variables and normalizing flows
May 05, 2023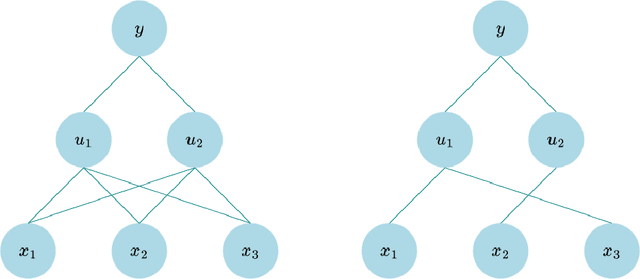
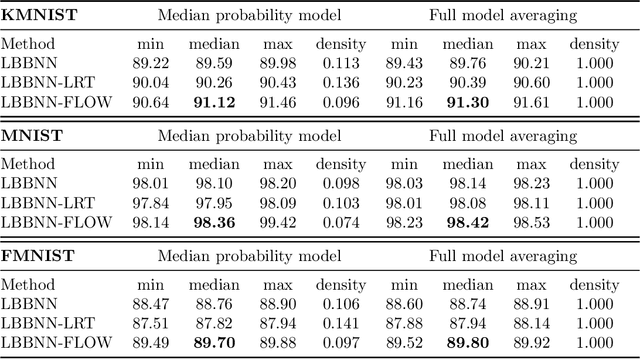
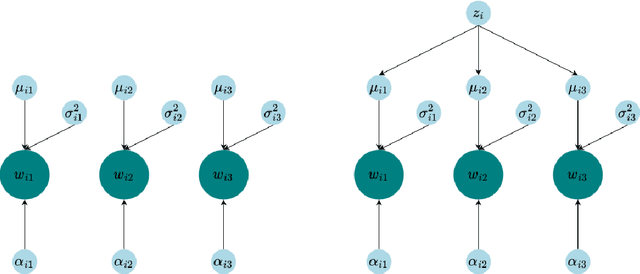
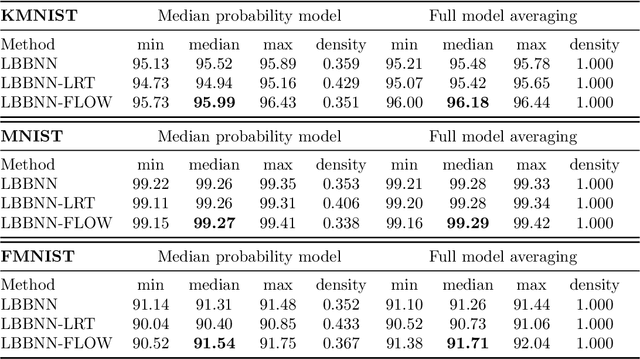
Artificial neural networks (ANNs) are powerful machine learning methods used in many modern applications such as facial recognition, machine translation, and cancer diagnostics. A common issue with ANNs is that they usually have millions or billions of trainable parameters, and therefore tend to overfit to the training data. This is especially problematic in applications where it is important to have reliable uncertainty estimates. Bayesian neural networks (BNN) can improve on this, since they incorporate parameter uncertainty. In addition, latent binary Bayesian neural networks (LBBNN) also take into account structural uncertainty by allowing the weights to be turned on or off, enabling inference in the joint space of weights and structures. In this paper, we will consider two extensions to the LBBNN method: Firstly, by using the local reparametrization trick (LRT) to sample the hidden units directly, we get a more computationally efficient algorithm. More importantly, by using normalizing flows on the variational posterior distribution of the LBBNN parameters, the network learns a more flexible variational posterior distribution than the mean field Gaussian. Experimental results show that this improves predictive power compared to the LBBNN method, while also obtaining more sparse networks. We perform two simulation studies. In the first study, we consider variable selection in a logistic regression setting, where the more flexible variational distribution leads to improved results. In the second study, we compare predictive uncertainty based on data generated from two-dimensional Gaussian distributions. Here, we argue that our Bayesian methods lead to more realistic estimates of predictive uncertainty.
X-Avatar: Expressive Human Avatars
Mar 09, 2023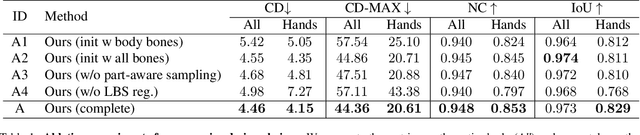
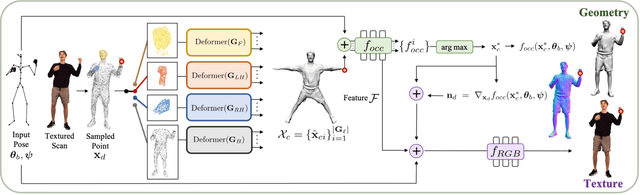
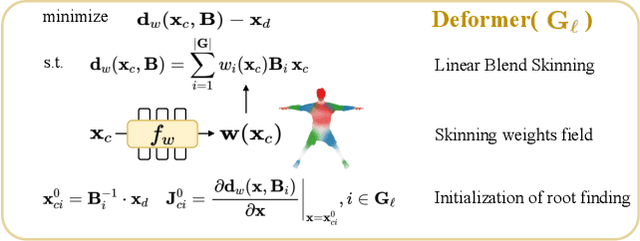
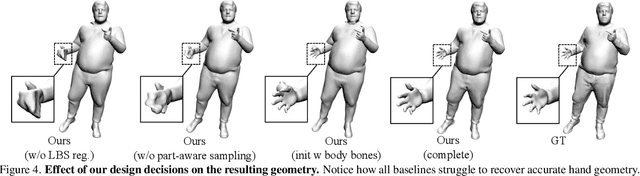
We present X-Avatar, a novel avatar model that captures the full expressiveness of digital humans to bring about life-like experiences in telepresence, AR/VR and beyond. Our method models bodies, hands, facial expressions and appearance in a holistic fashion and can be learned from either full 3D scans or RGB-D data. To achieve this, we propose a part-aware learned forward skinning module that can be driven by the parameter space of SMPL-X, allowing for expressive animation of X-Avatars. To efficiently learn the neural shape and deformation fields, we propose novel part-aware sampling and initialization strategies. This leads to higher fidelity results, especially for smaller body parts while maintaining efficient training despite increased number of articulated bones. To capture the appearance of the avatar with high-frequency details, we extend the geometry and deformation fields with a texture network that is conditioned on pose, facial expression, geometry and the normals of the deformed surface. We show experimentally that our method outperforms strong baselines in both data domains both quantitatively and qualitatively on the animation task. To facilitate future research on expressive avatars we contribute a new dataset, called X-Humans, containing 233 sequences of high-quality textured scans from 20 participants, totalling 35,500 data frames.
Facial Expression Analysis Using Decomposed Multiscale Spatiotemporal Networks
Mar 21, 2022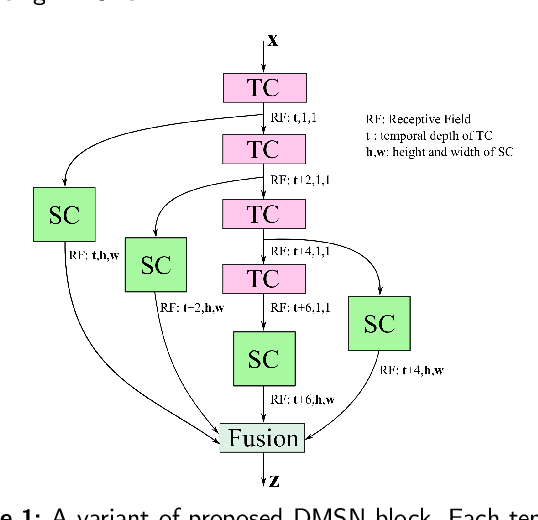
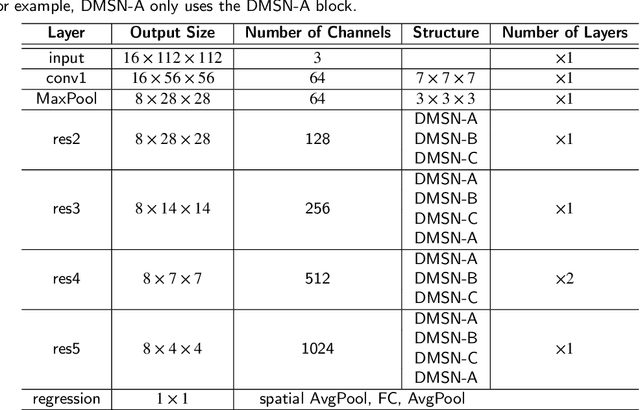
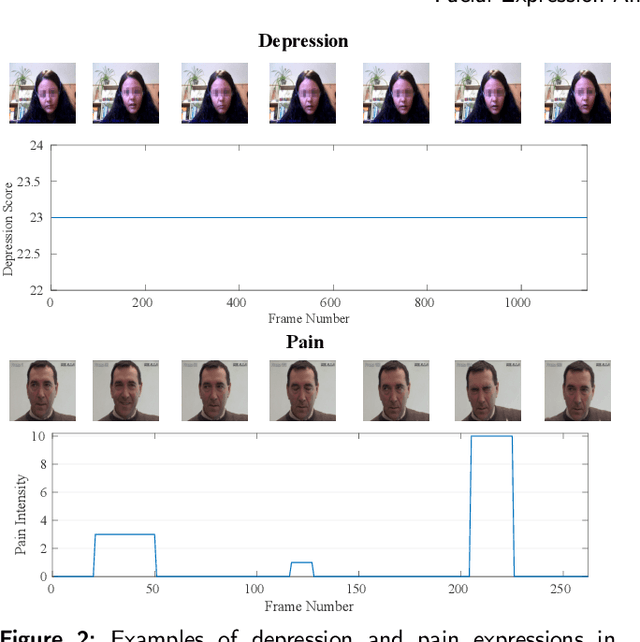
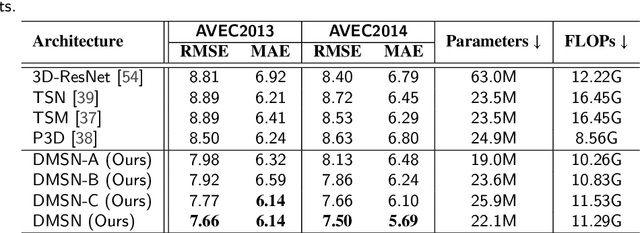
Video-based analysis of facial expressions has been increasingly applied to infer health states of individuals, such as depression and pain. Among the existing approaches, deep learning models composed of structures for multiscale spatiotemporal processing have shown strong potential for encoding facial dynamics. However, such models have high computational complexity, making for a difficult deployment of these solutions. To address this issue, we introduce a new technique to decompose the extraction of multiscale spatiotemporal features. Particularly, a building block structure called Decomposed Multiscale Spatiotemporal Network (DMSN) is presented along with three variants: DMSN-A, DMSN-B, and DMSN-C blocks. The DMSN-A block generates multiscale representations by analyzing spatiotemporal features at multiple temporal ranges, while the DMSN-B block analyzes spatiotemporal features at multiple ranges, and the DMSN-C block analyzes spatiotemporal features at multiple spatial sizes. Using these variants, we design our DMSN architecture which has the ability to explore a variety of multiscale spatiotemporal features, favoring the adaptation to different facial behaviors. Our extensive experiments on challenging datasets show that the DMSN-C block is effective for depression detection, whereas the DMSN-A block is efficient for pain estimation. Results also indicate that our DMSN architecture provides a cost-effective solution for expressions that range from fewer facial variations over time, as in depression detection, to greater variations, as in pain estimation.
The Face of Populism: Examining Differences in Facial Emotional Expressions of Political Leaders Using Machine Learning
Apr 19, 2023
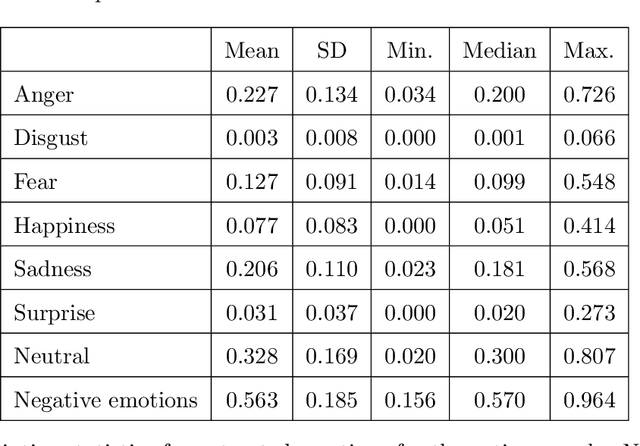
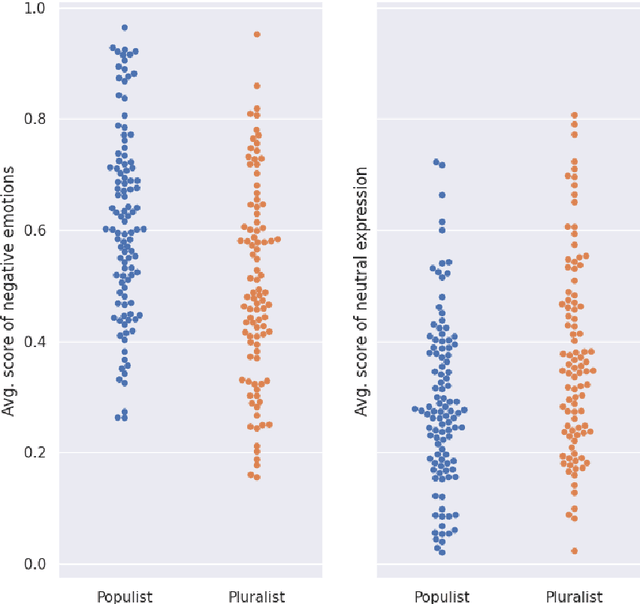
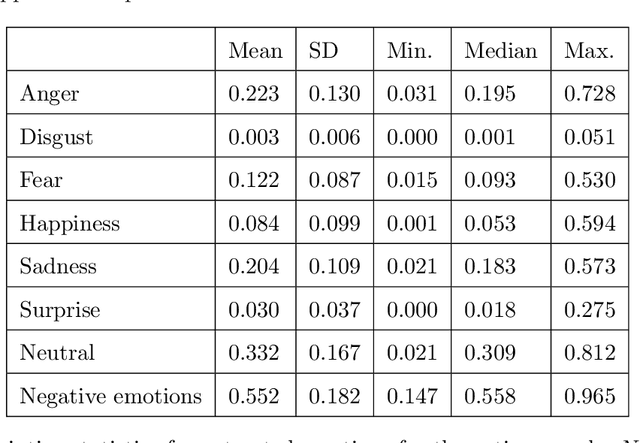
Online media has revolutionized the way political information is disseminated and consumed on a global scale, and this shift has compelled political figures to adopt new strategies of capturing and retaining voter attention. These strategies often rely on emotional persuasion and appeal, and as visual content becomes increasingly prevalent in virtual space, much of political communication too has come to be marked by evocative video content and imagery. The present paper offers a novel approach to analyzing material of this kind. We apply a deep-learning-based computer-vision algorithm to a sample of 220 YouTube videos depicting political leaders from 15 different countries, which is based on an existing trained convolutional neural network architecture provided by the Python library fer. The algorithm returns emotion scores representing the relative presence of 6 emotional states (anger, disgust, fear, happiness, sadness, and surprise) and a neutral expression for each frame of the processed YouTube video. We observe statistically significant differences in the average score of expressed negative emotions between groups of leaders with varying degrees of populist rhetoric as defined by the Global Party Survey (GPS), indicating that populist leaders tend to express negative emotions to a greater extent during their public performance than their non-populist counterparts. Overall, our contribution provides insight into the characteristics of visual self-representation among political leaders, as well as an open-source workflow for further computational studies of their non-verbal communication.
Open Set Classification of GAN-based Image Manipulations via a ViT-based Hybrid Architecture
Apr 11, 2023

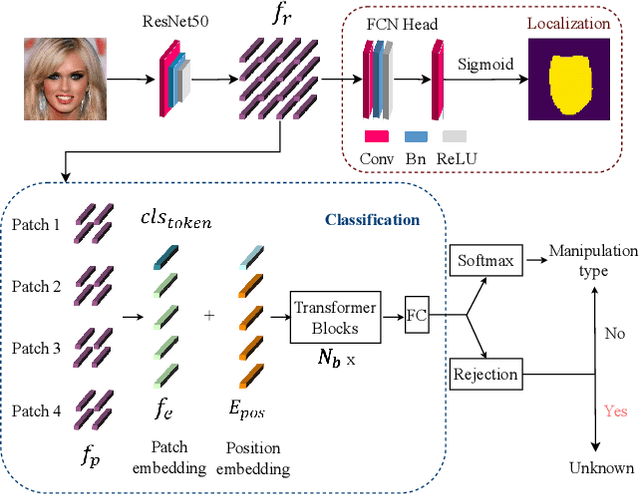
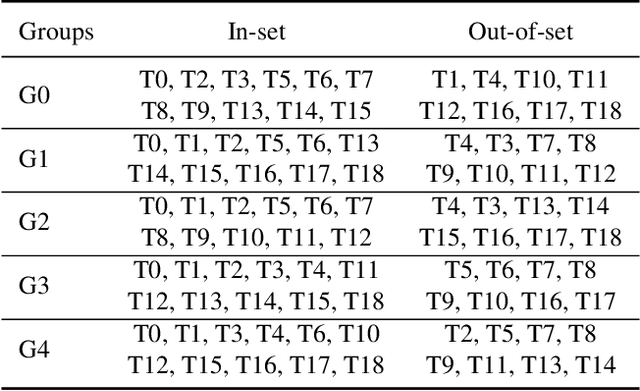
Classification of AI-manipulated content is receiving great attention, for distinguishing different types of manipulations. Most of the methods developed so far fail in the open-set scenario, that is when the algorithm used for the manipulation is not represented by the training set. In this paper, we focus on the classification of synthetic face generation and manipulation in open-set scenarios, and propose a method for classification with a rejection option. The proposed method combines the use of Vision Transformers (ViT) with a hybrid approach for simultaneous classification and localization. Feature map correlation is exploited by the ViT module, while a localization branch is employed as an attention mechanism to force the model to learn per-class discriminative features associated with the forgery when the manipulation is performed locally in the image. Rejection is performed by considering several strategies and analyzing the model output layers. The effectiveness of the proposed method is assessed for the task of classification of facial attribute editing and GAN attribution.