 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Towards Realistic Landmark-Guided Facial Video Inpainting Based on GANs
Feb 14, 2024
Facial video inpainting plays a crucial role in a wide range of applications, including but not limited to the removal of obstructions in video conferencing and telemedicine, enhancement of facial expression analysis, privacy protection, integration of graphical overlays, and virtual makeup. This domain presents serious challenges due to the intricate nature of facial features and the inherent human familiarity with faces, heightening the need for accurate and persuasive completions. In addressing challenges specifically related to occlusion removal in this context, our focus is on the progressive task of generating complete images from facial data covered by masks, ensuring both spatial and temporal coherence. Our study introduces a network designed for expression-based video inpainting, employing generative adversarial networks (GANs) to handle static and moving occlusions across all frames. By utilizing facial landmarks and an occlusion-free reference image, our model maintains the user's identity consistently across frames. We further enhance emotional preservation through a customized facial expression recognition (FER) loss function, ensuring detailed inpainted outputs. Our proposed framework exhibits proficiency in eliminating occlusions from facial videos in an adaptive form, whether appearing static or dynamic on the frames, while providing realistic and coherent results.
Application of the NIST AI Risk Management Framework to Surveillance Technology
Mar 22, 2024This study offers an in-depth analysis of the application and implications of the National Institute of Standards and Technology's AI Risk Management Framework (NIST AI RMF) within the domain of surveillance technologies, particularly facial recognition technology. Given the inherently high-risk and consequential nature of facial recognition systems, our research emphasizes the critical need for a structured approach to risk management in this sector. The paper presents a detailed case study demonstrating the utility of the NIST AI RMF in identifying and mitigating risks that might otherwise remain unnoticed in these technologies. Our primary objective is to develop a comprehensive risk management strategy that advances the practice of responsible AI utilization in feasible, scalable ways. We propose a six-step process tailored to the specific challenges of surveillance technology that aims to produce a more systematic and effective risk management practice. This process emphasizes continual assessment and improvement to facilitate companies in managing AI-related risks more robustly and ensuring ethical and responsible deployment of AI systems. Additionally, our analysis uncovers and discusses critical gaps in the current framework of the NIST AI RMF, particularly concerning its application to surveillance technologies. These insights contribute to the evolving discourse on AI governance and risk management, highlighting areas for future refinement and development in frameworks like the NIST AI RMF.
Deepfake Generation and Detection: A Benchmark and Survey
Mar 26, 2024In addition to the advancements in deepfake generation, corresponding detection technologies need to continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing the current state of the art in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss the development of generation and detection technology frameworks. Then, we discuss the development of several related sub-fields and focus on researching four mainstream deepfake fields: popular face swap, face reenactment, talking face generation, and facial attribute editing, as well as foreign detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential works published in top conferences/journals. Finally, we analyze the challenges and future research directions of the discussed fields. We closely follow the latest developments in https://github.com/flyingby/Awesome-Deepfake-Generation-and-Detection.
Superior and Pragmatic Talking Face Generation with Teacher-Student Framework
Mar 26, 2024Talking face generation technology creates talking videos from arbitrary appearance and motion signal, with the "arbitrary" offering ease of use but also introducing challenges in practical applications. Existing methods work well with standard inputs but suffer serious performance degradation with intricate real-world ones. Moreover, efficiency is also an important concern in deployment. To comprehensively address these issues, we introduce SuperFace, a teacher-student framework that balances quality, robustness, cost and editability. We first propose a simple but effective teacher model capable of handling inputs of varying qualities to generate high-quality results. Building on this, we devise an efficient distillation strategy to acquire an identity-specific student model that maintains quality with significantly reduced computational load. Our experiments validate that SuperFace offers a more comprehensive solution than existing methods for the four mentioned objectives, especially in reducing FLOPs by 99\% with the student model. SuperFace can be driven by both video and audio and allows for localized facial attributes editing.
Testing MediaPipe Holistic for Linguistic Analysis of Nonmanual Markers in Sign Languages
Mar 25, 2024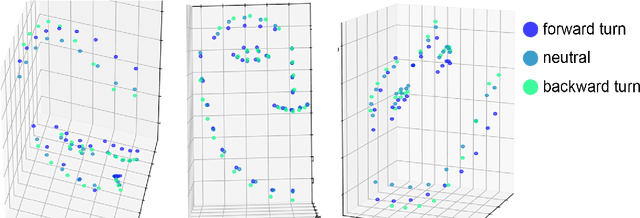
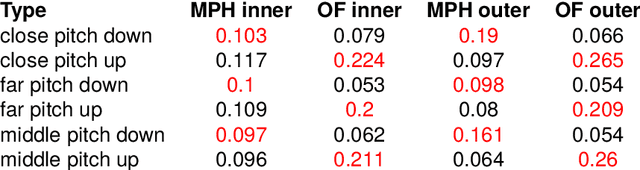
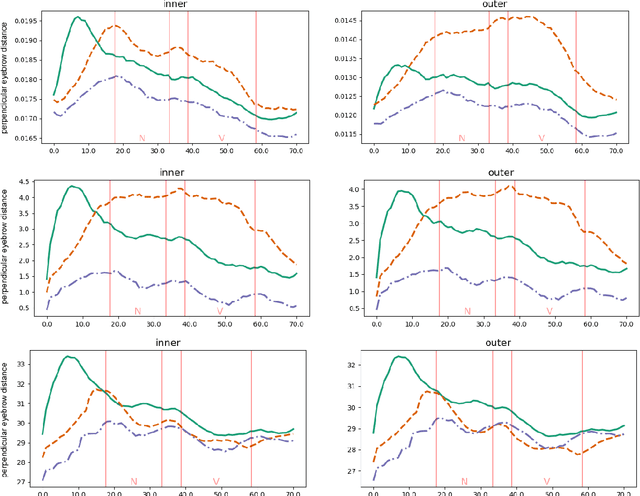
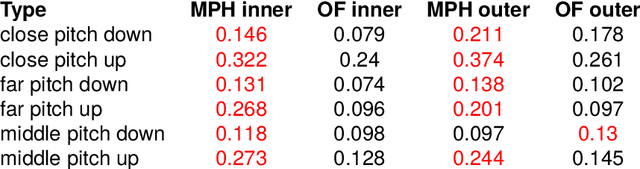
Advances in Deep Learning have made possible reliable landmark tracking of human bodies and faces that can be used for a variety of tasks. We test a recent Computer Vision solution, MediaPipe Holistic (MPH), to find out if its tracking of the facial features is reliable enough for a linguistic analysis of data from sign languages, and compare it to an older solution (OpenFace, OF). We use an existing data set of sentences in Kazakh-Russian Sign Language and a newly created small data set of videos with head tilts and eyebrow movements. We find that MPH does not perform well enough for linguistic analysis of eyebrow movement - but in a different way from OF, which is also performing poorly without correction. We reiterate a previous proposal to train additional correction models to overcome these limitations.
Test-Time Domain Generalization for Face Anti-Spoofing
Mar 28, 2024Face Anti-Spoofing (FAS) is pivotal in safeguarding facial recognition systems against presentation attacks. While domain generalization (DG) methods have been developed to enhance FAS performance, they predominantly focus on learning domain-invariant features during training, which may not guarantee generalizability to unseen data that differs largely from the source distributions. Our insight is that testing data can serve as a valuable resource to enhance the generalizability beyond mere evaluation for DG FAS. In this paper, we introduce a novel Test-Time Domain Generalization (TTDG) framework for FAS, which leverages the testing data to boost the model's generalizability. Our method, consisting of Test-Time Style Projection (TTSP) and Diverse Style Shifts Simulation (DSSS), effectively projects the unseen data to the seen domain space. In particular, we first introduce the innovative TTSP to project the styles of the arbitrarily unseen samples of the testing distribution to the known source space of the training distributions. We then design the efficient DSSS to synthesize diverse style shifts via learnable style bases with two specifically designed losses in a hyperspherical feature space. Our method eliminates the need for model updates at the test time and can be seamlessly integrated into not only the CNN but also ViT backbones. Comprehensive experiments on widely used cross-domain FAS benchmarks demonstrate our method's state-of-the-art performance and effectiveness.
K-Act2Emo: Korean Commonsense Knowledge Graph for Indirect Emotional Expression
Mar 23, 2024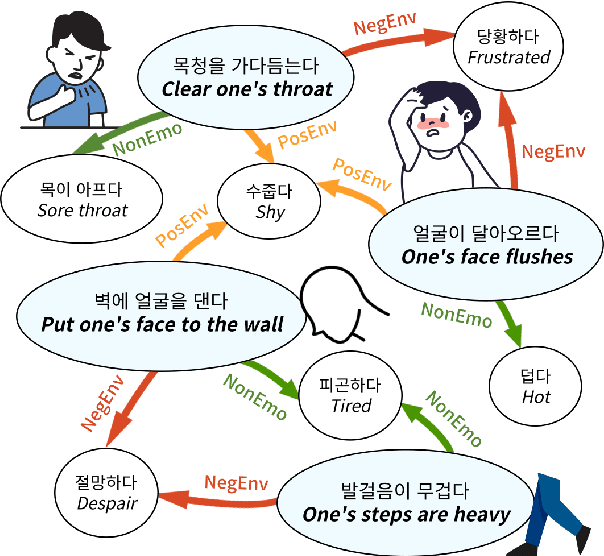



In many literary texts, emotions are indirectly conveyed through descriptions of actions, facial expressions, and appearances, necessitating emotion inference for narrative understanding. In this paper, we introduce K-Act2Emo, a Korean commonsense knowledge graph (CSKG) comprising 1,900 indirect emotional expressions and the emotions inferable from them. We categorize reasoning types into inferences in positive situations, inferences in negative situations, and inferences when expressions do not serve as emotional cues. Unlike existing CSKGs, K-Act2Emo specializes in emotional contexts, and experimental results validate its effectiveness for training emotion inference models. Significantly, the BART-based knowledge model fine-tuned with K-Act2Emo outperforms various existing Korean large language models, achieving performance levels comparable to GPT-4 Turbo.
WaveFace: Authentic Face Restoration with Efficient Frequency Recovery
Mar 19, 2024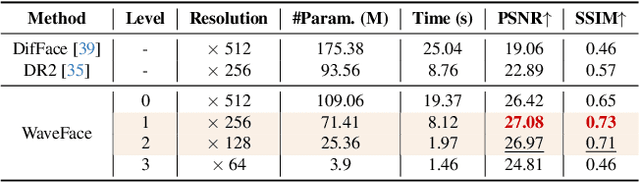
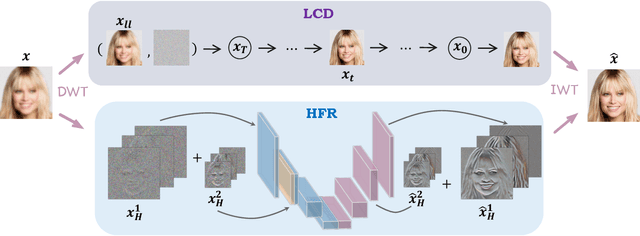
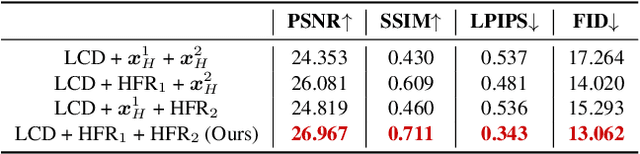

Although diffusion models are rising as a powerful solution for blind face restoration, they are criticized for two problems: 1) slow training and inference speed, and 2) failure in preserving identity and recovering fine-grained facial details. In this work, we propose WaveFace to solve the problems in the frequency domain, where low- and high-frequency components decomposed by wavelet transformation are considered individually to maximize authenticity as well as efficiency. The diffusion model is applied to recover the low-frequency component only, which presents general information of the original image but 1/16 in size. To preserve the original identity, the generation is conditioned on the low-frequency component of low-quality images at each denoising step. Meanwhile, high-frequency components at multiple decomposition levels are handled by a unified network, which recovers complex facial details in a single step. Evaluations on four benchmark datasets show that: 1) WaveFace outperforms state-of-the-art methods in authenticity, especially in terms of identity preservation, and 2) authentic images are restored with the efficiency 10x faster than existing diffusion model-based BFR methods.
AniArtAvatar: Animatable 3D Art Avatar from a Single Image
Mar 26, 2024We present a novel approach for generating animatable 3D-aware art avatars from a single image, with controllable facial expressions, head poses, and shoulder movements. Unlike previous reenactment methods, our approach utilizes a view-conditioned 2D diffusion model to synthesize multi-view images from a single art portrait with a neutral expression. With the generated colors and normals, we synthesize a static avatar using an SDF-based neural surface. For avatar animation, we extract control points, transfer the motion with these points, and deform the implicit canonical space. Firstly, we render the front image of the avatar, extract the 2D landmarks, and project them to the 3D space using a trained SDF network. We extract 3D driving landmarks using 3DMM and transfer the motion to the avatar landmarks. To animate the avatar pose, we manually set the body height and bound the head and torso of an avatar with two cages. The head and torso can be animated by transforming the two cages. Our approach is a one-shot pipeline that can be applied to various styles. Experiments demonstrate that our method can generate high-quality 3D art avatars with desired control over different motions.
Biased Binary Attribute Classifiers Ignore the Majority Classes
Mar 21, 2024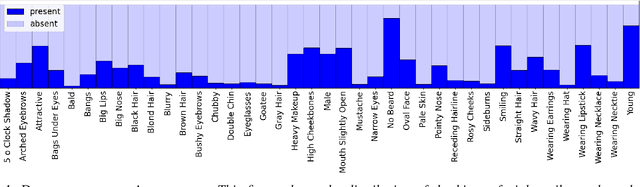
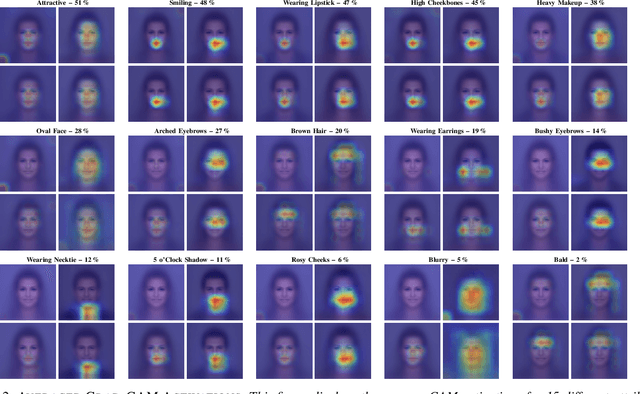
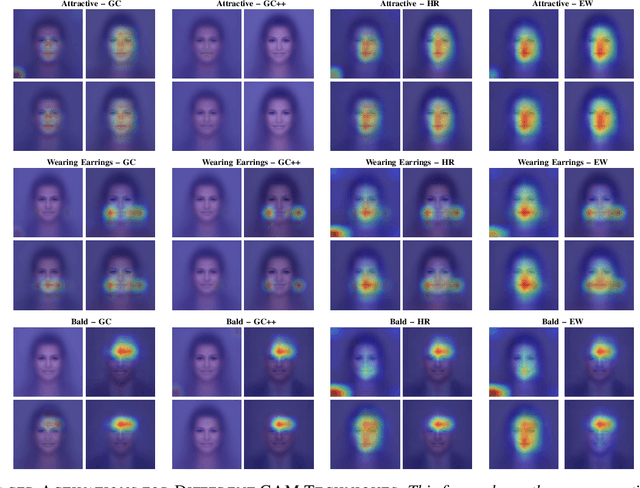

To visualize the regions of interest that classifiers base their decisions on, different Class Activation Mapping (CAM) methods have been developed. However, all of these techniques target categorical classifiers only, though most real-world tasks are binary classification. In this paper, we extend gradient-based CAM techniques to work with binary classifiers and visualize the active regions for binary facial attribute classifiers. When training an unbalanced binary classifier on an imbalanced dataset, it is well-known that the majority class, i.e. the class with many training samples, is mostly predicted much better than minority class with few training instances. In our experiments on the CelebA dataset, we verify these results, when training an unbalanced classifier to extract 40 facial attributes simultaneously. One would expect that the biased classifier has learned to extract features mainly for the majority classes and that the proportional energy of the activations mainly reside in certain specific regions of the image where the attribute is located. However, we find very little regular activation for samples of majority classes, while the active regions for minority classes seem mostly reasonable and overlap with our expectations. These results suggest that biased classifiers mainly rely on bias activation for majority classes. When training a balanced classifier on the imbalanced data by employing attribute-specific class weights, majority and minority classes are classified similarly well and show expected activations for almost all attributes