 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
F3A-GAN: Facial Flow for Face Animation with Generative Adversarial Networks
May 13, 2022
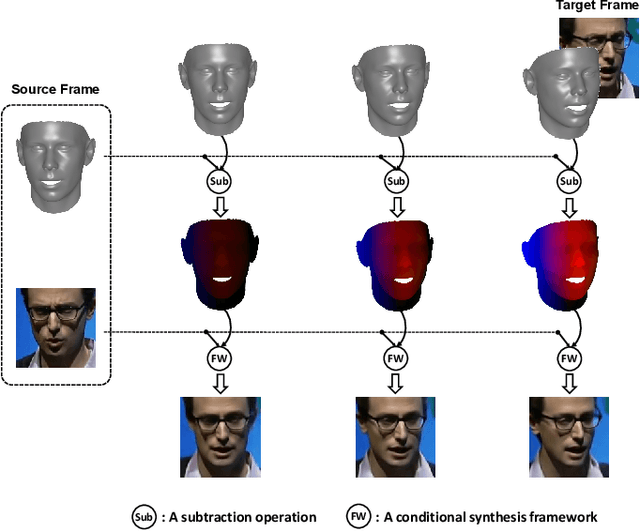



Formulated as a conditional generation problem, face animation aims at synthesizing continuous face images from a single source image driven by a set of conditional face motion. Previous works mainly model the face motion as conditions with 1D or 2D representation (e.g., action units, emotion codes, landmark), which often leads to low-quality results in some complicated scenarios such as continuous generation and largepose transformation. To tackle this problem, the conditions are supposed to meet two requirements, i.e., motion information preserving and geometric continuity. To this end, we propose a novel representation based on a 3D geometric flow, termed facial flow, to represent the natural motion of the human face at any pose. Compared with other previous conditions, the proposed facial flow well controls the continuous changes to the face. After that, in order to utilize the facial flow for face editing, we build a synthesis framework generating continuous images with conditional facial flows. To fully take advantage of the motion information of facial flows, a hierarchical conditional framework is designed to combine the extracted multi-scale appearance features from images and motion features from flows in a hierarchical manner. The framework then decodes multiple fused features back to images progressively. Experimental results demonstrate the effectiveness of our method compared to other state-of-the-art methods.
NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads
May 04, 2023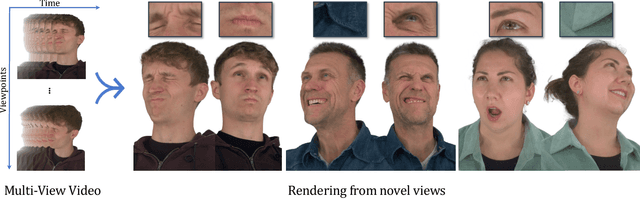
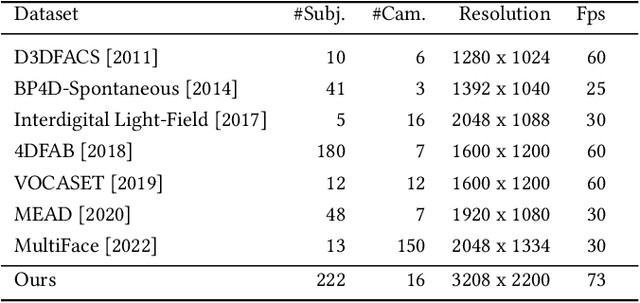

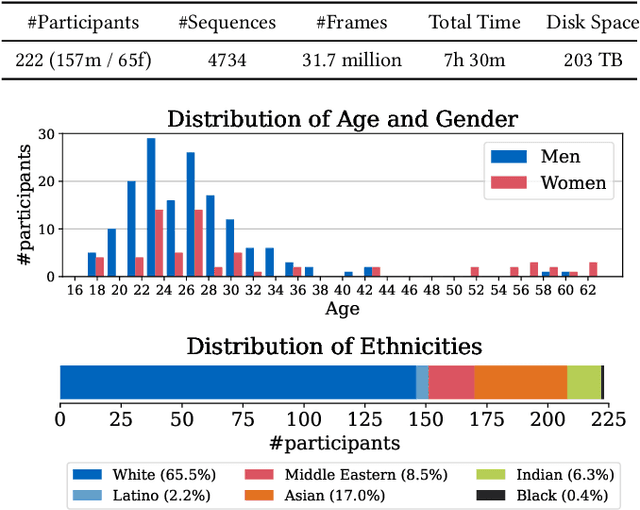
We focus on reconstructing high-fidelity radiance fields of human heads, capturing their animations over time, and synthesizing re-renderings from novel viewpoints at arbitrary time steps. To this end, we propose a new multi-view capture setup composed of 16 calibrated machine vision cameras that record time-synchronized images at 7.1 MP resolution and 73 frames per second. With our setup, we collect a new dataset of over 4700 high-resolution, high-framerate sequences of more than 220 human heads, from which we introduce a new human head reconstruction benchmark. The recorded sequences cover a wide range of facial dynamics, including head motions, natural expressions, emotions, and spoken language. In order to reconstruct high-fidelity human heads, we propose Dynamic Neural Radiance Fields using Hash Ensembles (NeRSemble). We represent scene dynamics by combining a deformation field and an ensemble of 3D multi-resolution hash encodings. The deformation field allows for precise modeling of simple scene movements, while the ensemble of hash encodings helps to represent complex dynamics. As a result, we obtain radiance field representations of human heads that capture motion over time and facilitate re-rendering of arbitrary novel viewpoints. In a series of experiments, we explore the design choices of our method and demonstrate that our approach outperforms state-of-the-art dynamic radiance field approaches by a significant margin.
Single-Shot Implicit Morphable Faces with Consistent Texture Parameterization
May 04, 2023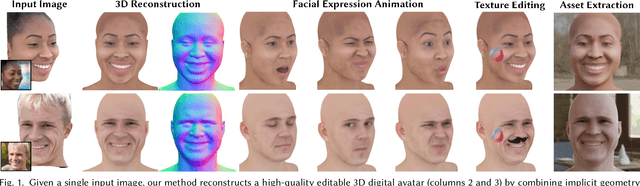

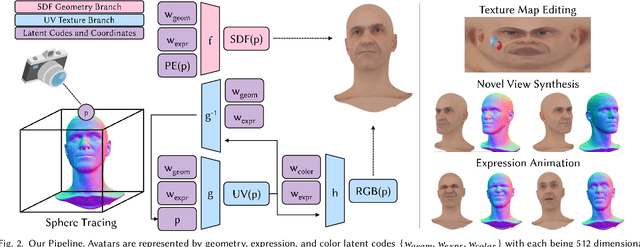
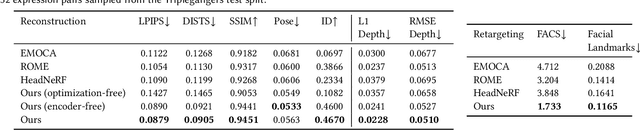
There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
Weakly-supervised Micro- and Macro-expression Spotting Based on Multi-level Consistency
May 04, 2023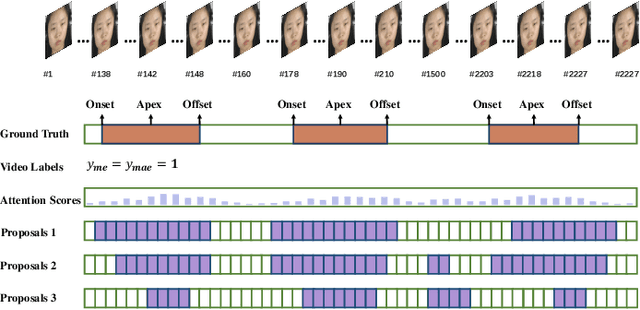
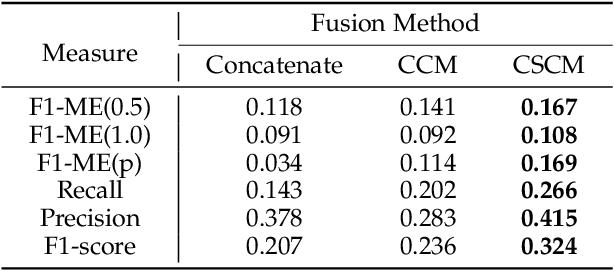
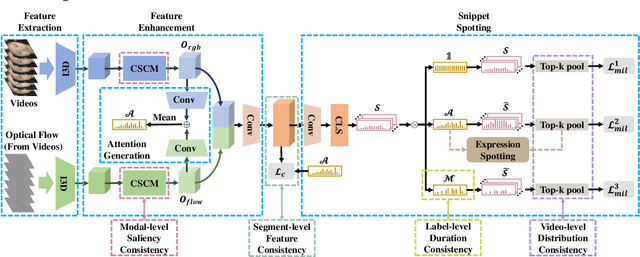
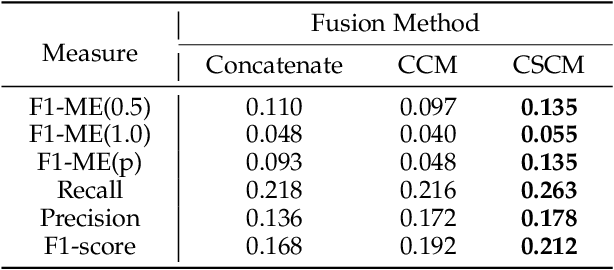
Most micro- and macro-expression spotting methods in untrimmed videos suffer from the burden of video-wise collection and frame-wise annotation. Weakly-supervised expression spotting (WES) based on video-level labels can potentially mitigate the complexity of frame-level annotation while achieving fine-grained frame-level spotting. However, we argue that existing weakly-supervised methods are based on multiple instance learning (MIL) involving inter-modality, inter-sample, and inter-task gaps. The inter-sample gap is primarily from the sample distribution and duration. Therefore, we propose a novel and simple WES framework, MC-WES, using multi-consistency collaborative mechanisms that include modal-level saliency, video-level distribution, label-level duration and segment-level feature consistency strategies to implement fine frame-level spotting with only video-level labels to alleviate the above gaps and merge prior knowledge. The modal-level saliency consistency strategy focuses on capturing key correlations between raw images and optical flow. The video-level distribution consistency strategy utilizes the difference of sparsity in temporal distribution. The label-level duration consistency strategy exploits the difference in the duration of facial muscles. The segment-level feature consistency strategy emphasizes that features under the same labels maintain similarity. Experimental results on two challenging datasets -- CAS(ME)$^2$ and SAMM-LV -- demonstrate that MC-WES is comparable to state-of-the-art fully-supervised methods.
MetaMorphosis: Task-oriented Privacy Cognizant Feature Generation for Multi-task Learning
May 13, 2023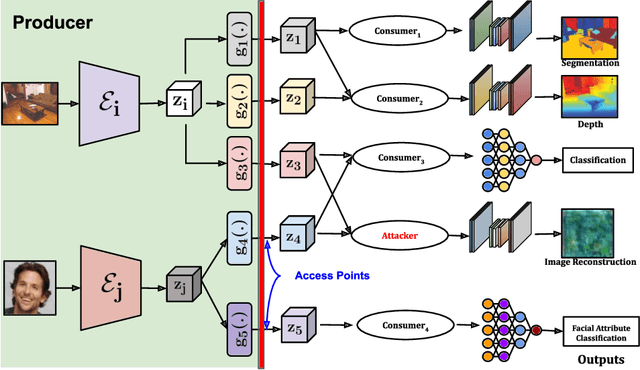

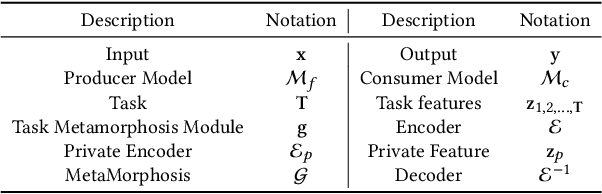
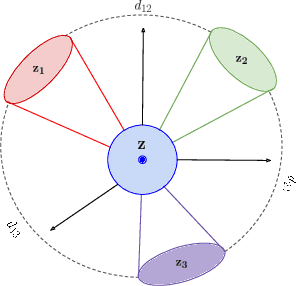
With the growth of computer vision applications, deep learning, and edge computing contribute to ensuring practical collaborative intelligence (CI) by distributing the workload among edge devices and the cloud. However, running separate single-task models on edge devices is inefficient regarding the required computational resource and time. In this context, multi-task learning allows leveraging a single deep learning model for performing multiple tasks, such as semantic segmentation and depth estimation on incoming video frames. This single processing pipeline generates common deep features that are shared among multi-task modules. However, in a collaborative intelligence scenario, generating common deep features has two major issues. First, the deep features may inadvertently contain input information exposed to the downstream modules (violating input privacy). Second, the generated universal features expose a piece of collective information than what is intended for a certain task, in which features for one task can be utilized to perform another task (violating task privacy). This paper proposes a novel deep learning-based privacy-cognizant feature generation process called MetaMorphosis that limits inference capability to specific tasks at hand. To achieve this, we propose a channel squeeze-excitation based feature metamorphosis module, Cross-SEC, to achieve distinct attention of all tasks and a de-correlation loss function with differential-privacy to train a deep learning model that produces distinct privacy-aware features as an output for the respective tasks. With extensive experimentation on four datasets consisting of diverse images related to scene understanding and facial attributes, we show that MetaMorphosis outperforms recent adversarial learning and universal feature generation methods by guaranteeing privacy requirements in an efficient way for image and video analytics.
Recursive Joint Attention for Audio-Visual Fusion in Regression based Emotion Recognition
Apr 17, 2023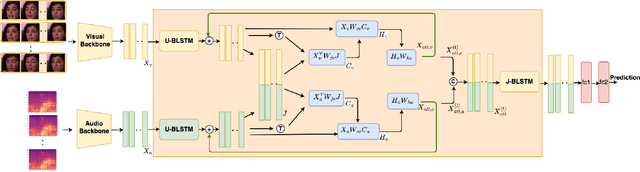

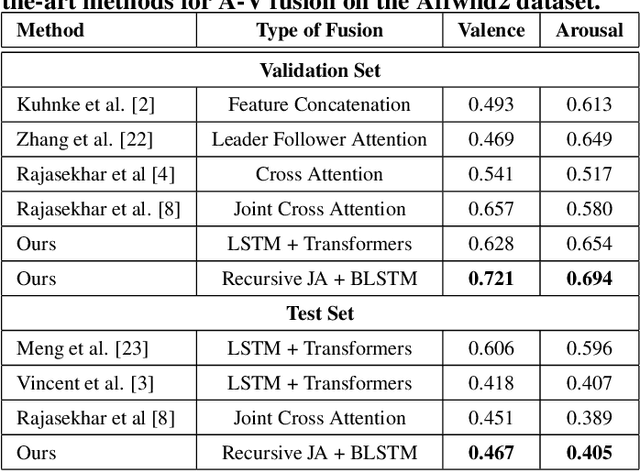
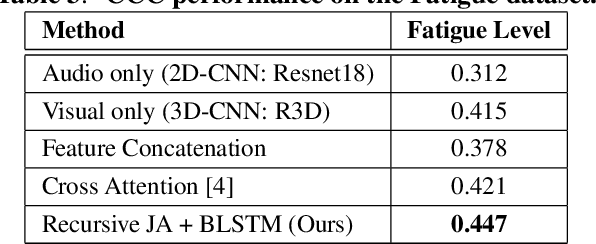
In video-based emotion recognition (ER), it is important to effectively leverage the complementary relationship among audio (A) and visual (V) modalities, while retaining the intra-modal characteristics of individual modalities. In this paper, a recursive joint attention model is proposed along with long short-term memory (LSTM) modules for the fusion of vocal and facial expressions in regression-based ER. Specifically, we investigated the possibility of exploiting the complementary nature of A and V modalities using a joint cross-attention model in a recursive fashion with LSTMs to capture the intra-modal temporal dependencies within the same modalities as well as among the A-V feature representations. By integrating LSTMs with recursive joint cross-attention, our model can efficiently leverage both intra- and inter-modal relationships for the fusion of A and V modalities. The results of extensive experiments performed on the challenging Affwild2 and Fatigue (private) datasets indicate that the proposed A-V fusion model can significantly outperform state-of-art-methods.
FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Nov 04, 2021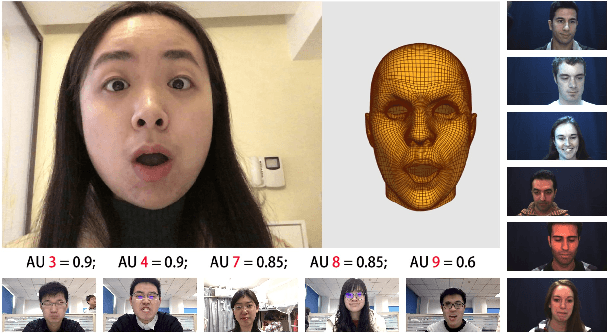
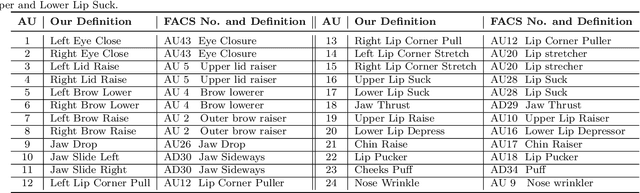
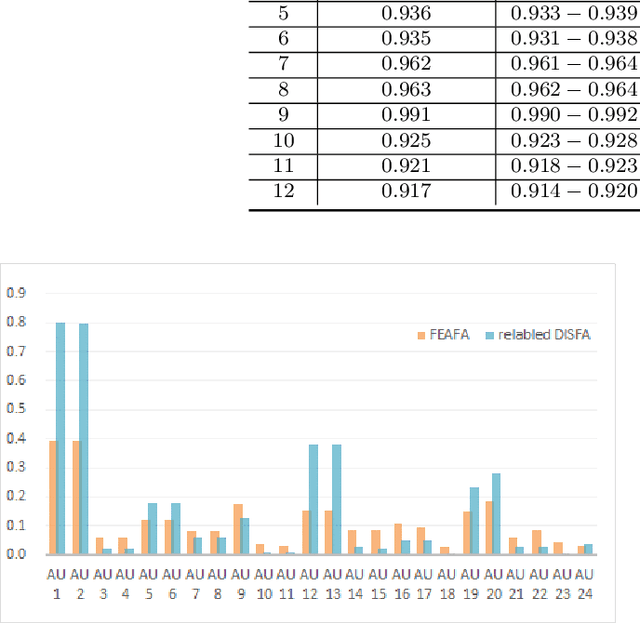
Nearly all existing Facial Action Coding System-based datasets that include facial action unit (AU) intensity information annotate the intensity values hierarchically using A--E levels. However, facial expressions change continuously and shift smoothly from one state to another. Therefore, it is more effective to regress the intensity value of local facial AUs to represent whole facial expression changes, particularly in the fields of expression transfer and facial animation. We introduce an extension of FEAFA in combination with the relabeled DISFA database, which is available at https://www.iiplab.net/feafa+/ now. Extended FEAFA (FEAFA+) includes 150 video sequences from FEAFA and DISFA, with a total of 230,184 frames being manually annotated on floating-point intensity value of 24 redefined AUs using the Expression Quantitative Tool. We also list crude numerical results for posed and spontaneous subsets and provide a baseline comparison for the AU intensity regression task.
Identity masking effectiveness and gesture recognition: Effects of eye enhancement in seeing through the mask
Jan 20, 2023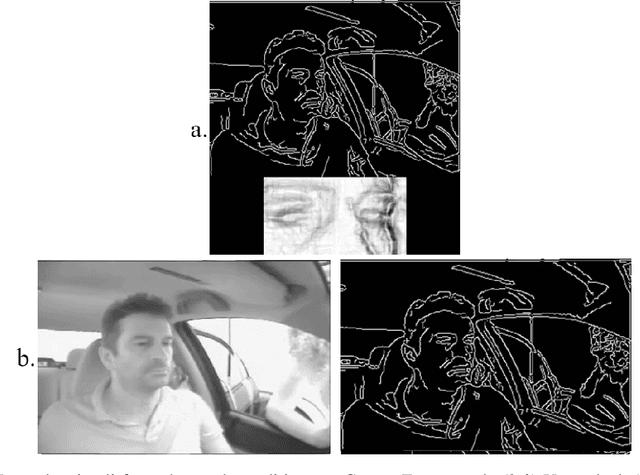

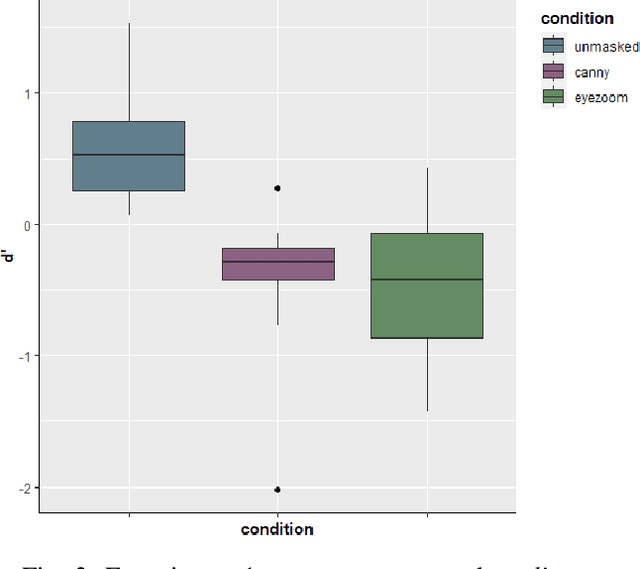
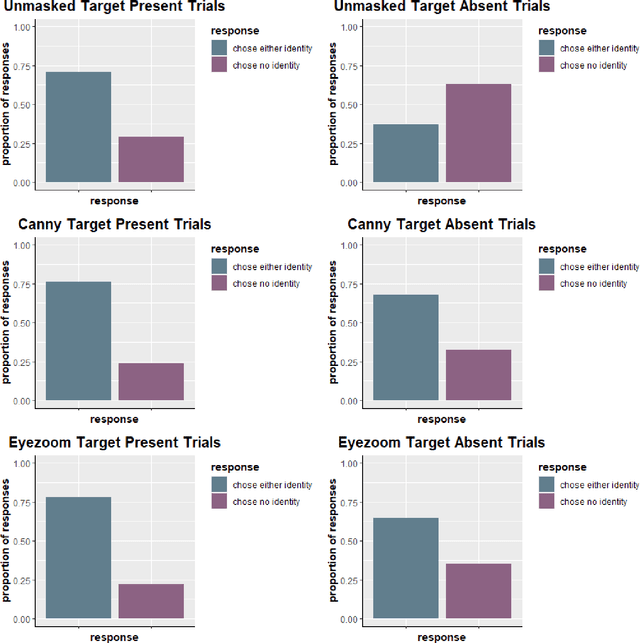
Face identity masking algorithms developed in recent years aim to protect the privacy of people in video recordings. These algorithms are designed to interfere with identification, while preserving information about facial actions. An important challenge is to preserve subtle actions in the eye region, while obscuring the salient identity cues from the eyes. We evaluated the effectiveness of identity-masking algorithms based on Canny filters, applied with and without eye enhancement, for interfering with identification and preserving facial actions. In Experiments 1 and 2, we tested human participants' ability to match the facial identity of a driver in a low resolution video to a high resolution facial image. Results showed that both masking methods impaired identification, and that eye enhancement did not alter the effectiveness of the Canny filter mask. In Experiment 3, we tested action preservation and found that neither method interfered significantly with driver action perception. We conclude that relatively simple, filter-based masking algorithms, which are suitable for application to low quality video, can be used in privacy protection without compromising action perception.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Mar 30, 2023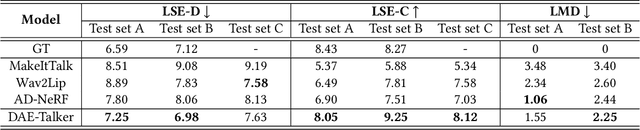
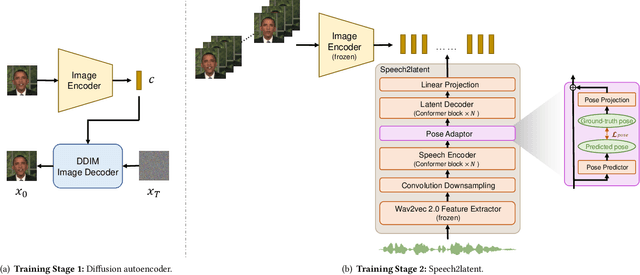

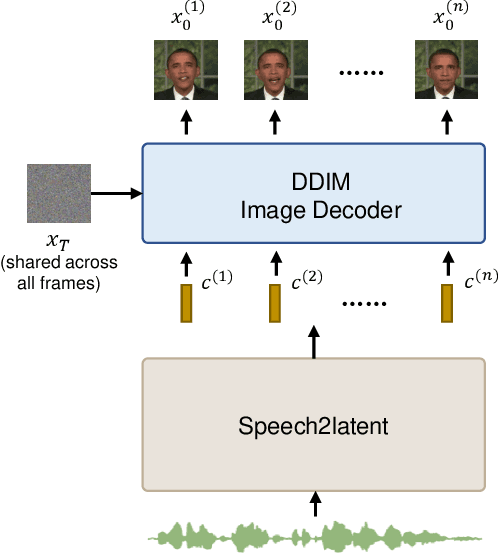
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.
Causal Intervention for Subject-Deconfounded Facial Action Unit Recognition
Apr 17, 2022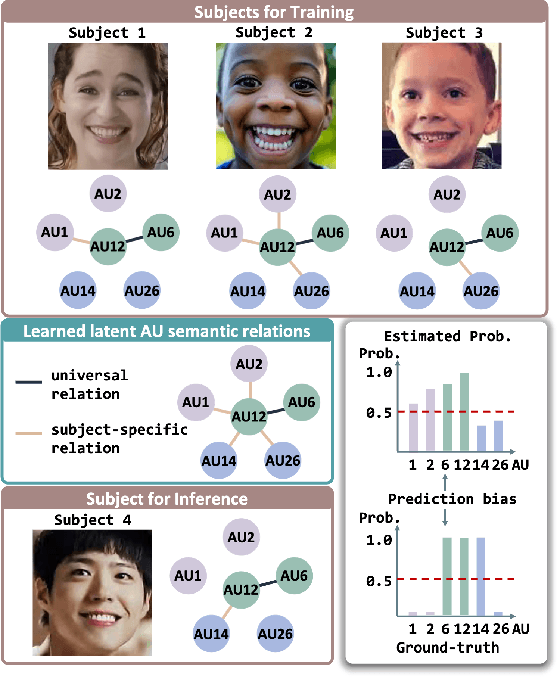
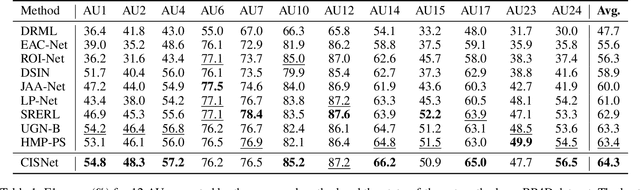
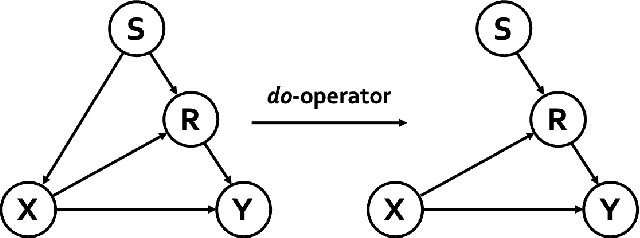
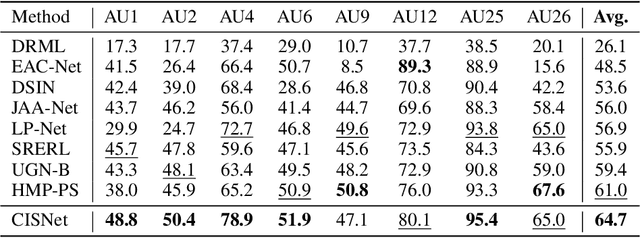
Subject-invariant facial action unit (AU) recognition remains challenging for the reason that the data distribution varies among subjects. In this paper, we propose a causal inference framework for subject-invariant facial action unit recognition. To illustrate the causal effect existing in AU recognition task, we formulate the causalities among facial images, subjects, latent AU semantic relations, and estimated AU occurrence probabilities via a structural causal model. By constructing such a causal diagram, we clarify the causal effect among variables and propose a plug-in causal intervention module, CIS, to deconfound the confounder \emph{Subject} in the causal diagram. Extensive experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of our CIS, and the model with CIS inserted, CISNet, has achieved state-of-the-art performance.