 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
An Examination of Bias of Facial Analysis based BMI Prediction Models
Apr 21, 2022
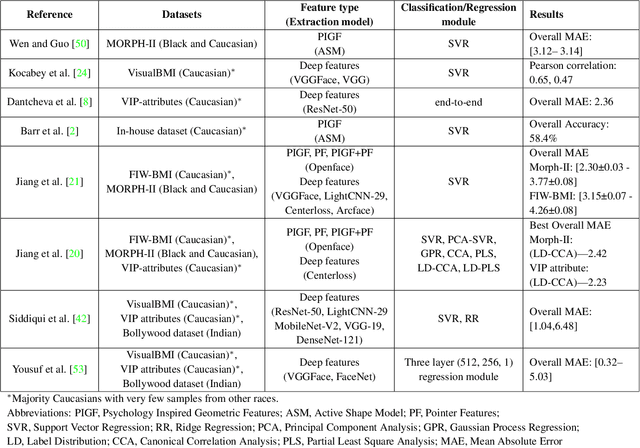


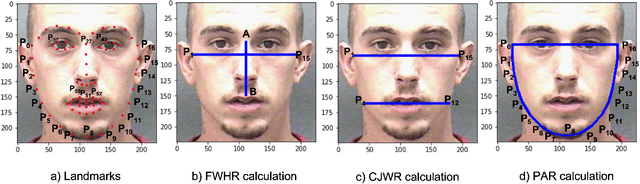
Obesity is one of the most important public health problems that the world is facing today. A recent trend is in the development of intervention tools that predict BMI using facial images for weight monitoring and management to combat obesity. Most of these studies used BMI annotated facial image datasets that mainly consisted of Caucasian subjects. Research on bias evaluation of face-based gender-, age-classification, and face recognition systems suggest that these technologies perform poorly for women, dark-skinned people, and older adults. The bias of facial analysis-based BMI prediction tools has not been studied until now. This paper evaluates the bias of facial-analysis-based BMI prediction models across Caucasian and African-American Males and Females. Experimental investigations on the gender, race, and BMI balanced version of the modified MORPH-II dataset suggested that the error rate in BMI prediction was least for Black Males and highest for White Females. Further, the psychology-related facial features correlated with weight suggested that as the BMI increases, the changes in the facial region are more prominent for Black Males and the least for White Females. This is the reason for the least error rate of the facial analysis-based BMI prediction tool for Black Males and highest for White Females.
Adaptive Graph-Based Feature Normalization for Facial Expression Recognition
Jul 22, 2022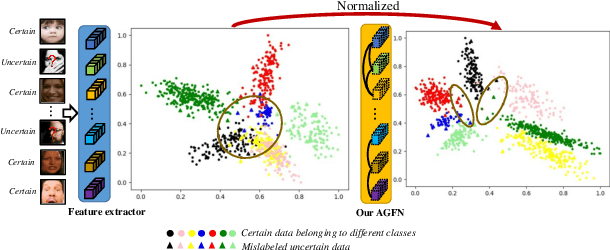
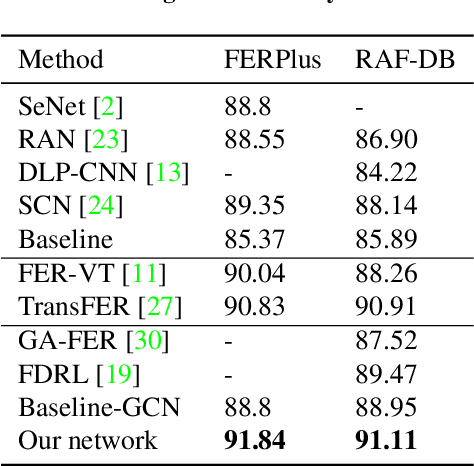
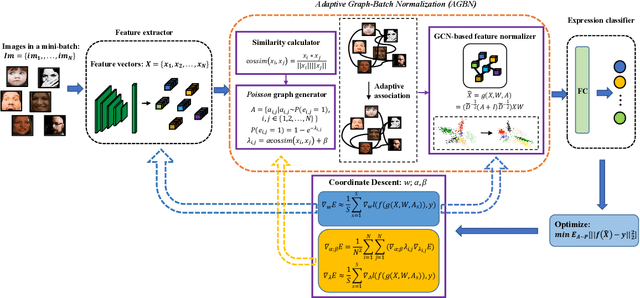
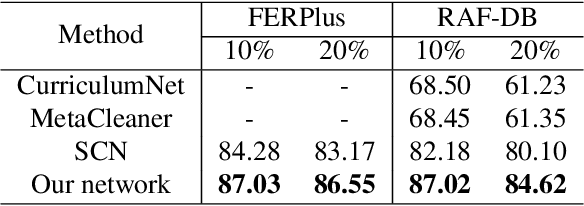
Facial Expression Recognition (FER) suffers from data uncertainties caused by ambiguous facial images and annotators' subjectiveness, resulting in excursive semantic and feature covariate shifting problem. Existing works usually correct mislabeled data by estimating noise distribution, or guide network training with knowledge learned from clean data, neglecting the associative relations of expressions. In this work, we propose an Adaptive Graph-based Feature Normalization (AGFN) method to protect FER models from data uncertainties by normalizing feature distributions with the association of expressions. Specifically, we propose a Poisson graph generator to adaptively construct topological graphs for samples in each mini-batches via a sampling process, and correspondingly design a coordinate descent strategy to optimize proposed network. Our method outperforms state-of-the-art works with accuracies of 91.84% and 91.11% on the benchmark datasets FERPlus and RAF-DB, respectively, and when the percentage of mislabeled data increases (e.g., to 20%), our network surpasses existing works significantly by 3.38% and 4.52%.
AvatarReX: Real-time Expressive Full-body Avatars
May 08, 2023

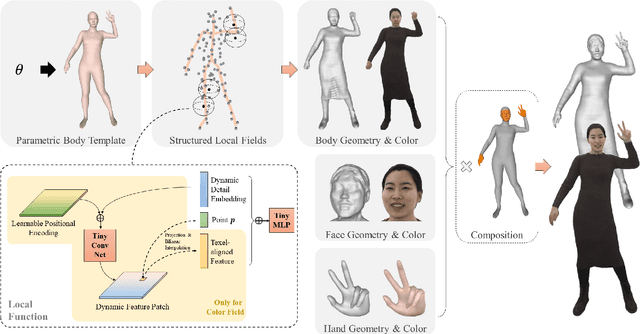
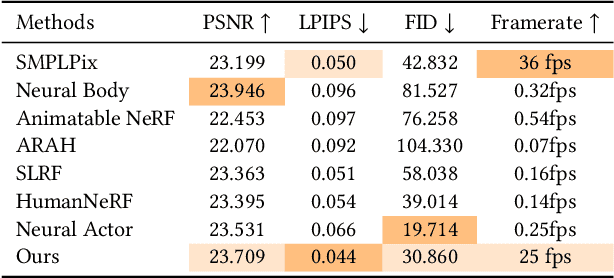
We present AvatarReX, a new method for learning NeRF-based full-body avatars from video data. The learnt avatar not only provides expressive control of the body, hands and the face together, but also supports real-time animation and rendering. To this end, we propose a compositional avatar representation, where the body, hands and the face are separately modeled in a way that the structural prior from parametric mesh templates is properly utilized without compromising representation flexibility. Furthermore, we disentangle the geometry and appearance for each part. With these technical designs, we propose a dedicated deferred rendering pipeline, which can be executed in real-time framerate to synthesize high-quality free-view images. The disentanglement of geometry and appearance also allows us to design a two-pass training strategy that combines volume rendering and surface rendering for network training. In this way, patch-level supervision can be applied to force the network to learn sharp appearance details on the basis of geometry estimation. Overall, our method enables automatic construction of expressive full-body avatars with real-time rendering capability, and can generate photo-realistic images with dynamic details for novel body motions and facial expressions.
I2Edit: Towards Multi-turn Interactive Image Editing via Dialogue
Mar 20, 2023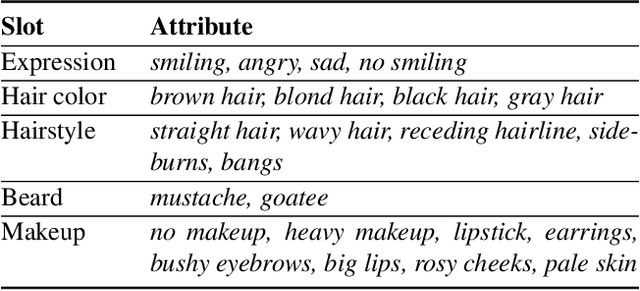

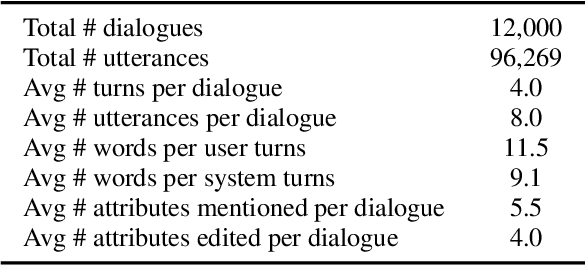
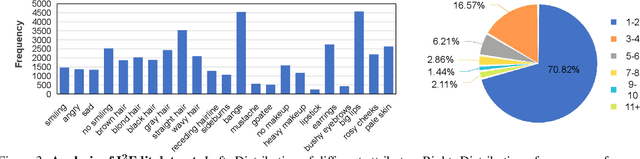
Although there have been considerable research efforts on controllable facial image editing, the desirable interactive setting where the users can interact with the system to adjust their requirements dynamically hasn't been well explored. This paper focuses on facial image editing via dialogue and introduces a new benchmark dataset, Multi-turn Interactive Image Editing (I2Edit), for evaluating image editing quality and interaction ability in real-world interactive facial editing scenarios. The dataset is constructed upon the CelebA-HQ dataset with images annotated with a multi-turn dialogue that corresponds to the user editing requirements. I2Edit is challenging, as it needs to 1) track the dynamically updated user requirements and edit the images accordingly, as well as 2) generate the appropriate natural language response to communicate with the user. To address these challenges, we propose a framework consisting of a dialogue module and an image editing module. The former is for user edit requirements tracking and generating the corresponding indicative responses, while the latter edits the images conditioned on the tracked user edit requirements. In contrast to previous works that simply treat multi-turn interaction as a sequence of single-turn interactions, we extract the user edit requirements from the whole dialogue history instead of the current single turn. The extracted global user edit requirements enable us to directly edit the input raw image to avoid error accumulation and attribute forgetting issues. Extensive quantitative and qualitative experiments on the I2Edit dataset demonstrate the advantage of our proposed framework over the previous single-turn methods. We believe our new dataset could serve as a valuable resource to push forward the exploration of real-world, complex interactive image editing. Code and data will be made public.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023
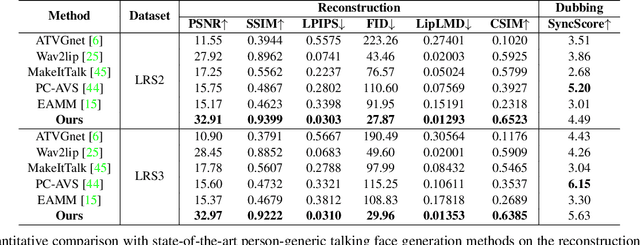
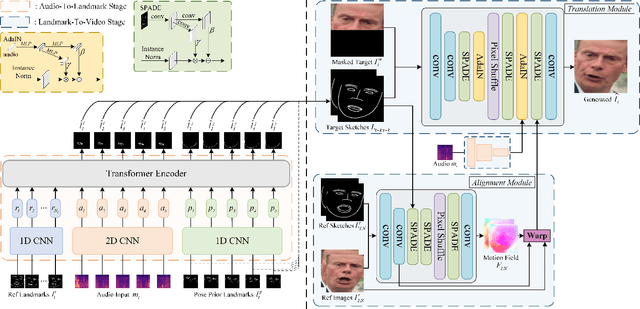
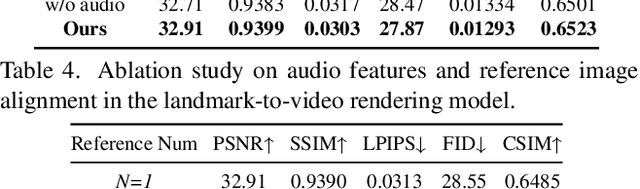
Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
NICOL: A Neuro-inspired Collaborative Semi-humanoid Robot that Bridges Social Interaction and Reliable Manipulation
May 15, 2023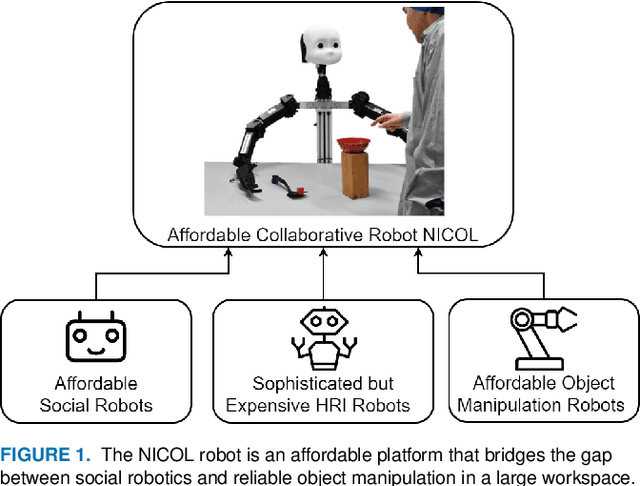
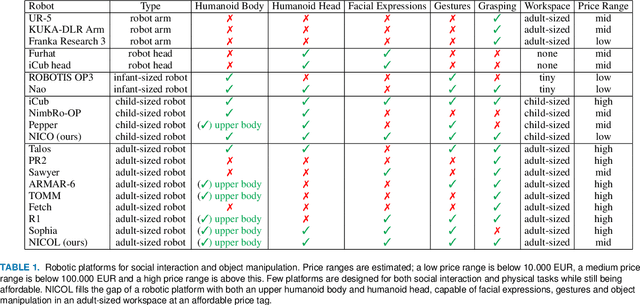

Robotic platforms that can efficiently collaborate with humans in physical tasks constitute a major goal in robotics. However, many existing robotic platforms are either designed for social interaction or industrial object manipulation tasks. The design of collaborative robots seldom emphasizes both their social interaction and physical collaboration abilities. To bridge this gap, we present the novel semi-humanoid NICOL, the Neuro-Inspired COLlaborator. NICOL is a large, newly designed, scaled-up version of its well-evaluated predecessor, the Neuro-Inspired COmpanion (NICO). While we adopt NICO's head and facial expression display, we extend its manipulation abilities in terms of precision, object size and workspace size. To introduce and evaluate NICOL, we first develop and extend different neural and hybrid neuro-genetic visuomotor approaches initially developed for the NICO to the larger NICOL and its more complex kinematics. Furthermore, we present a novel neuro-genetic approach that improves the grasp accuracy of the NICOL to over 99%, outperforming the state-of-the-art IK solvers KDL, TRACK-IK and BIO-IK. Furthermore, we introduce the social interaction capabilities of NICOL, including the auditory and visual capabilities, but also the face and emotion generation capabilities. Overall, this article presents for the first time the humanoid robot NICOL and, thereby, with the neuro-genetic approaches, contributes to the integration of social robotics and neural visuomotor learning for humanoid robots.
ABAW : Facial Expression Recognition in the wild
Mar 17, 2023
The fifth Affective Behavior Analysis in-the-wild (ABAW) competition has multiple challenges such as Valence-Arousal Estimation Challenge, Expression Classification Challenge, Action Unit Detection Challenge, Emotional Reaction Intensity Estimation Challenge. In this paper we have dealt only expression classification challenge using multiple approaches such as fully supervised, semi-supervised and noisy label approach. Our approach using noise aware model has performed better than baseline model by 10.46% and semi supervised model has performed better than baseline model by 9.38% and the fully supervised model has performed better than the baseline by 9.34%
LC-NeRF: Local Controllable Face Generation in Neural Randiance Field
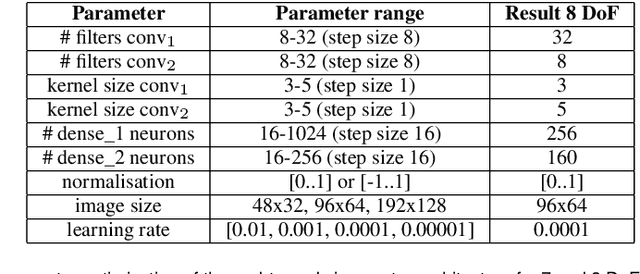
Feb 19, 2023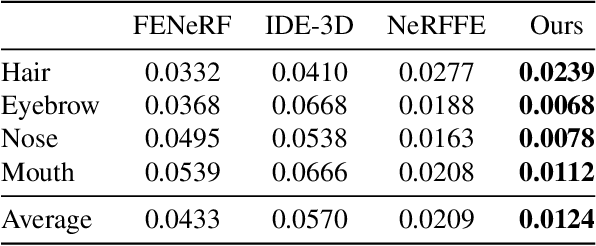
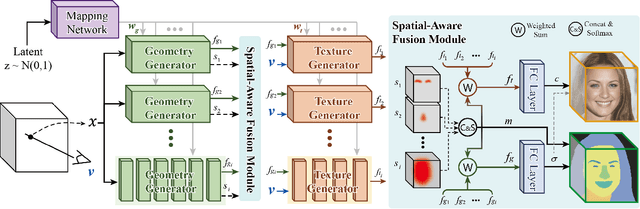
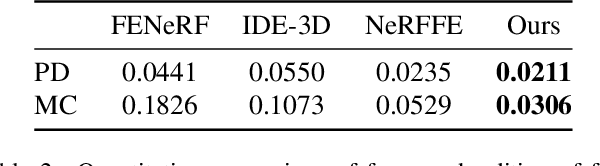

3D face generation has achieved high visual quality and 3D consistency thanks to the development of neural radiance fields (NeRF). Recently, to generate and edit 3D faces with NeRF representation, some methods are proposed and achieve good results in decoupling geometry and texture. The latent codes of these generative models affect the whole face, and hence modifications to these codes cause the entire face to change. However, users usually edit a local region when editing faces and do not want other regions to be affected. Since changes to the latent code affect global generation results, these methods do not allow for fine-grained control of local facial regions. To improve local controllability in NeRF-based face editing, we propose LC-NeRF, which is composed of a Local Region Generators Module and a Spatial-Aware Fusion Module, allowing for local geometry and texture control of local facial regions. Qualitative and quantitative evaluations show that our method provides better local editing than state-of-the-art face editing methods. Our method also performs well in downstream tasks, such as text-driven facial image editing.
Domain-specific Learning of Multi-scale Facial Dynamics for Apparent Personality Traits Prediction
Sep 09, 2022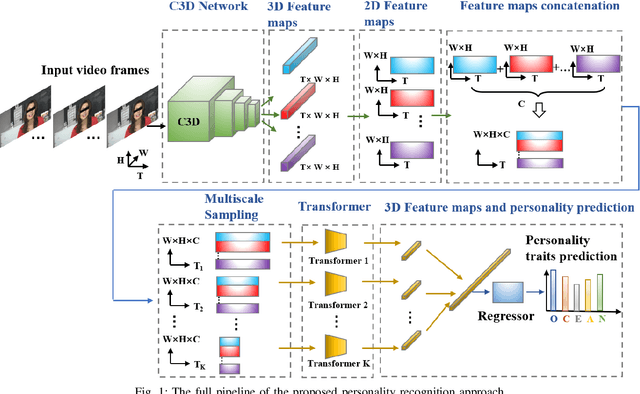
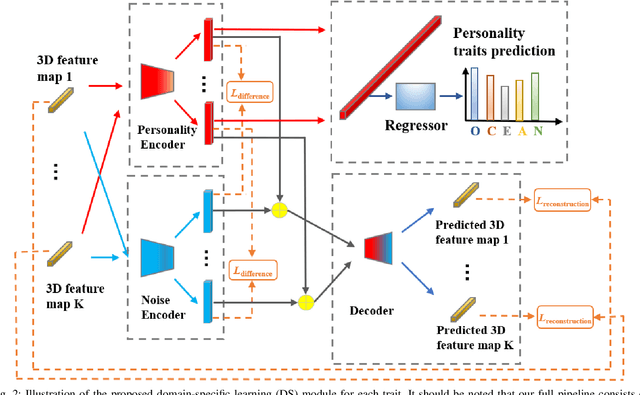
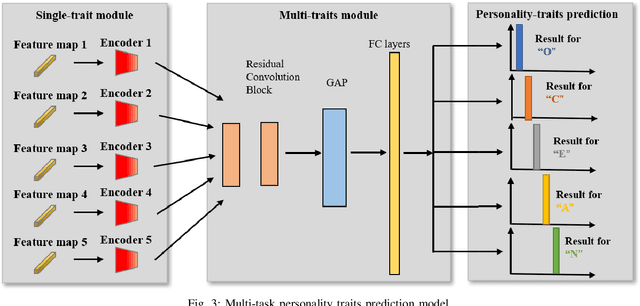
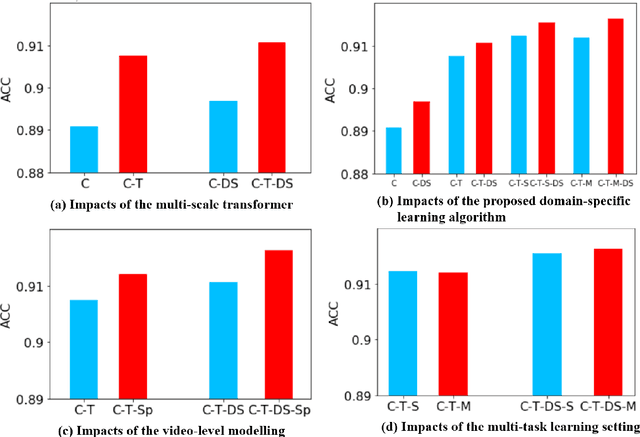
Human personality decides various aspects of their daily life and working behaviors. Since personality traits are relatively stable over time and unique for each subject, previous approaches frequently infer personality from a single frame or short-term behaviors. Moreover, most of them failed to specifically extract person-specific and unique cues for personality recognition. In this paper, we propose a novel video-based automatic personality traits recognition approach which consists of: (1) a \textbf{domain-specific facial behavior modelling} module that extracts personality-related multi-scale short-term human facial behavior features; (2) a \textbf{long-term behavior modelling} module that summarizes all short-term features of a video as a long-term/video-level personality representation and (3) a \textbf{multi-task personality traits prediction module} that models underlying relationship among all traits and jointly predict them based on the video-level personality representation. We conducted the experiments on ChaLearn First Impression dataset, and our approach achieved comparable results to the state-of-the-art. Importantly, we show that all three proposed modules brought important benefits for personality recognition.
Privileged Attribution Constrained Deep Networks for Facial Expression Recognition
Mar 24, 2022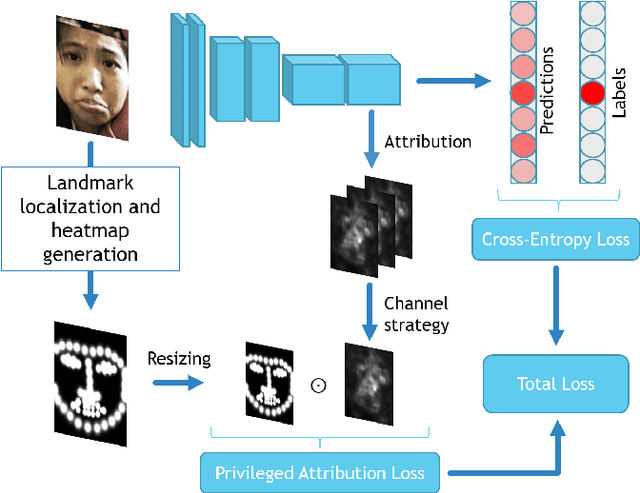

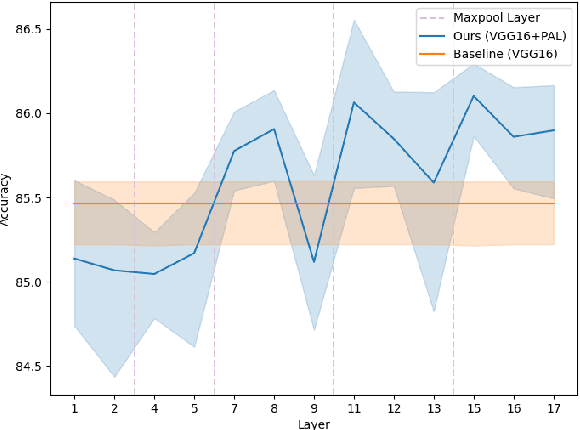
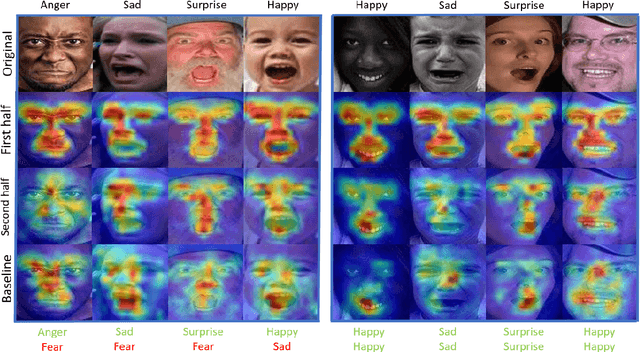
Facial Expression Recognition (FER) is crucial in many research domains because it enables machines to better understand human behaviours. FER methods face the problems of relatively small datasets and noisy data that don't allow classical networks to generalize well. To alleviate these issues, we guide the model to concentrate on specific facial areas like the eyes, the mouth or the eyebrows, which we argue are decisive to recognise facial expressions. We propose the Privileged Attribution Loss (PAL), a method that directs the attention of the model towards the most salient facial regions by encouraging its attribution maps to correspond to a heatmap formed by facial landmarks. Furthermore, we introduce several channel strategies that allow the model to have more degrees of freedom. The proposed method is independent of the backbone architecture and doesn't need additional semantic information at test time. Finally, experimental results show that the proposed PAL method outperforms current state-of-the-art methods on both RAF-DB and AffectNet.