 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
One-Shot Face Video Re-enactment using Hybrid Latent Spaces of StyleGAN2
Feb 15, 2023
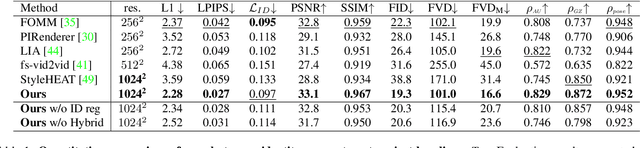
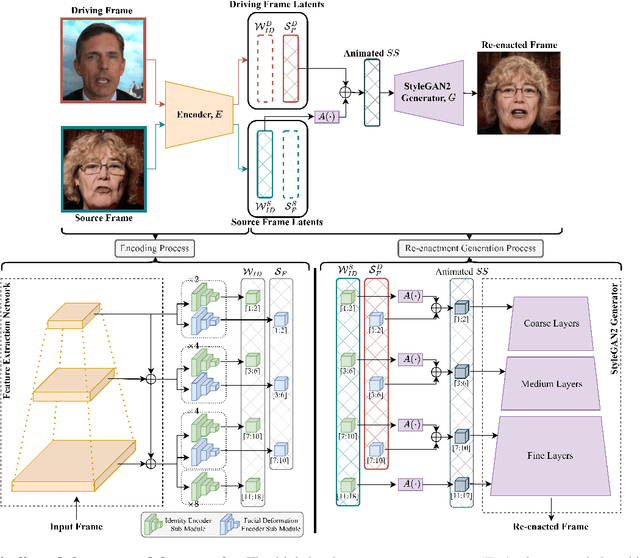
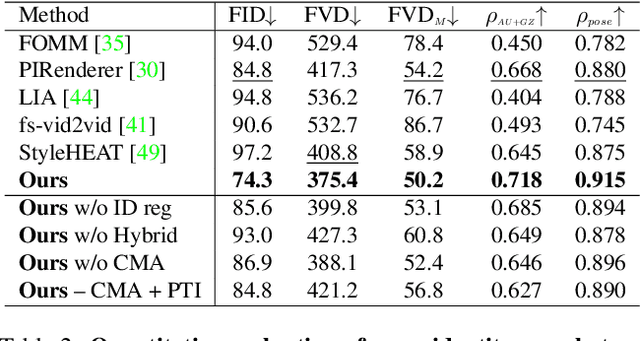
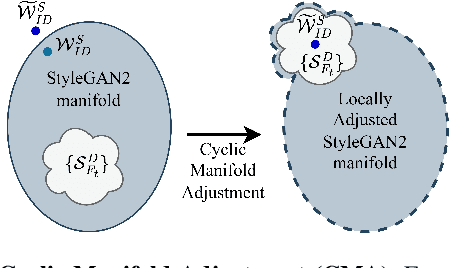
While recent research has progressively overcome the low-resolution constraint of one-shot face video re-enactment with the help of StyleGAN's high-fidelity portrait generation, these approaches rely on at least one of the following: explicit 2D/3D priors, optical flow based warping as motion descriptors, off-the-shelf encoders, etc., which constrain their performance (e.g., inconsistent predictions, inability to capture fine facial details and accessories, poor generalization, artifacts). We propose an end-to-end framework for simultaneously supporting face attribute edits, facial motions and deformations, and facial identity control for video generation. It employs a hybrid latent-space that encodes a given frame into a pair of latents: Identity latent, $\mathcal{W}_{ID}$, and Facial deformation latent, $\mathcal{S}_F$, that respectively reside in the $W+$ and $SS$ spaces of StyleGAN2. Thereby, incorporating the impressive editability-distortion trade-off of $W+$ and the high disentanglement properties of $SS$. These hybrid latents employ the StyleGAN2 generator to achieve high-fidelity face video re-enactment at $1024^2$. Furthermore, the model supports the generation of realistic re-enactment videos with other latent-based semantic edits (e.g., beard, age, make-up, etc.). Qualitative and quantitative analyses performed against state-of-the-art methods demonstrate the superiority of the proposed approach.
"Glitch in the Matrix!": A Large Scale Benchmark for Content Driven Audio-Visual Forgery Detection and Localization
May 05, 2023
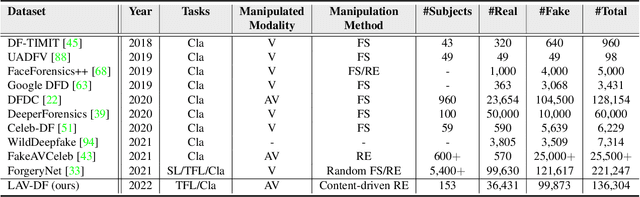
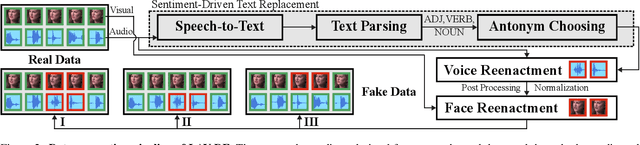
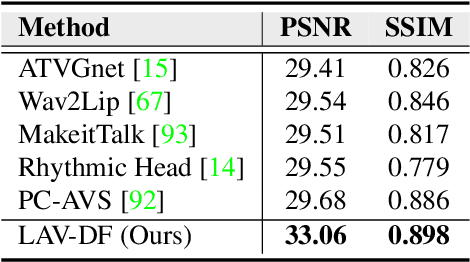
Most deepfake detection methods focus on detecting spatial and/or spatio-temporal changes in facial attributes. This is because available benchmark datasets contain mostly visual-only modifications. However, a sophisticated deepfake may include small segments of audio or audio-visual manipulations that can completely change the meaning of the content. To addresses this gap, we propose and benchmark a new dataset, Localized Audio Visual DeepFake (LAV-DF), consisting of strategic content-driven audio, visual and audio-visual manipulations. The proposed baseline method, Boundary Aware Temporal Forgery Detection (BA-TFD), is a 3D Convolutional Neural Network-based architecture which efficiently captures multimodal manipulations. We further improve (i.e. BA-TFD+) the baseline method by replacing the backbone with a Multiscale Vision Transformer and guide the training process with contrastive, frame classification, boundary matching and multimodal boundary matching loss functions. The quantitative analysis demonstrates the superiority of BA- TFD+ on temporal forgery localization and deepfake detection tasks using several benchmark datasets including our newly proposed dataset. The dataset, models and code are available at https://github.com/ControlNet/LAV-DF.
Learning a 3D Morphable Face Reflectance Model from Low-cost Data
Mar 21, 2023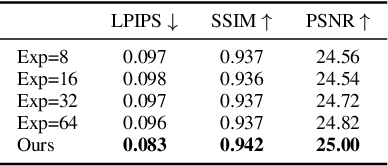
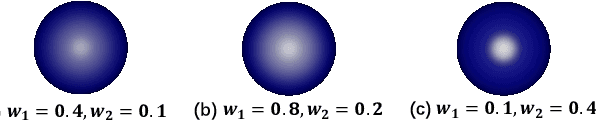
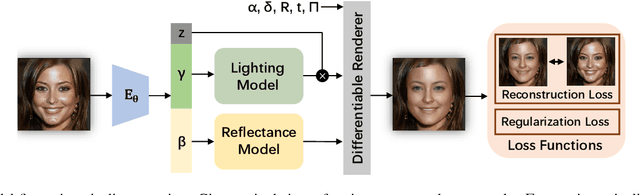

Modeling non-Lambertian effects such as facial specularity leads to a more realistic 3D Morphable Face Model. Existing works build parametric models for diffuse and specular albedo using Light Stage data. However, only diffuse and specular albedo cannot determine the full BRDF. In addition, the requirement of Light Stage data is hard to fulfill for the research communities. This paper proposes the first 3D morphable face reflectance model with spatially varying BRDF using only low-cost publicly-available data. We apply linear shiness weighting into parametric modeling to represent spatially varying specular intensity and shiness. Then an inverse rendering algorithm is developed to reconstruct the reflectance parameters from non-Light Stage data, which are used to train an initial morphable reflectance model. To enhance the model's generalization capability and expressive power, we further propose an update-by-reconstruction strategy to finetune it on an in-the-wild dataset. Experimental results show that our method obtains decent rendering results with plausible facial specularities. Our code is released \href{https://yxuhan.github.io/ReflectanceMM/index.html}{\textcolor{magenta}{here}}.
AU-aware graph convolutional network for Macro- and Micro-expression spotting
Mar 16, 2023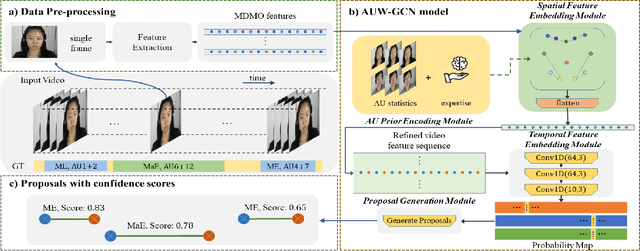


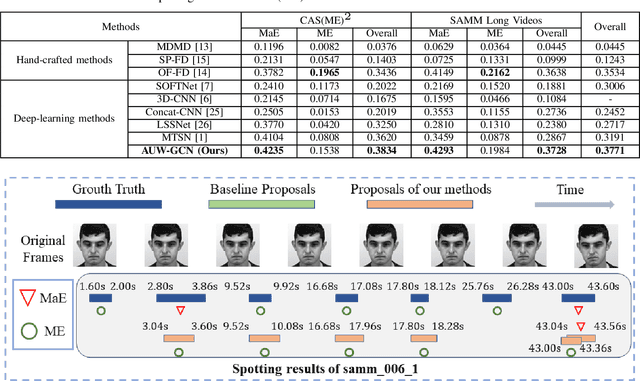
Automatic Micro-Expression (ME) spotting in long videos is a crucial step in ME analysis but also a challenging task due to the short duration and low intensity of MEs. When solving this problem, previous works generally lack in considering the structures of human faces and the correspondence between expressions and relevant facial muscles. To address this issue for better performance of ME spotting, this paper seeks to extract finer spatial features by modeling the relationships between facial Regions of Interest (ROIs). Specifically, we propose a graph convolutional-based network, called Action-Unit-aWare Graph Convolutional Network (AUW-GCN). Furthermore, to inject prior information and to cope with the problem of small datasets, AU-related statistics are encoded into the network. Comprehensive experiments show that our results outperform baseline methods consistently and achieve new SOTA performance in two benchmark datasets,CAS(ME)^2 and SAMM-LV. Our code is available at https://github.com/xjtupanda/AUW-GCN.
AvatarReX: Real-time Expressive Full-body Avatars
May 08, 2023

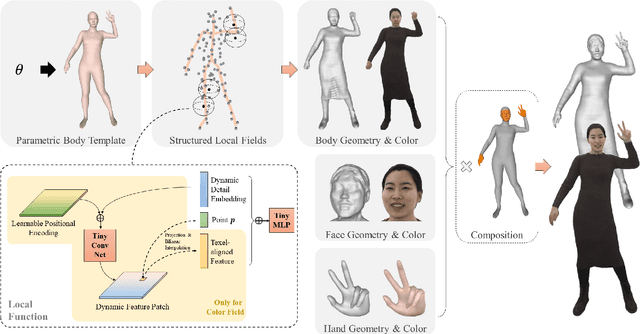
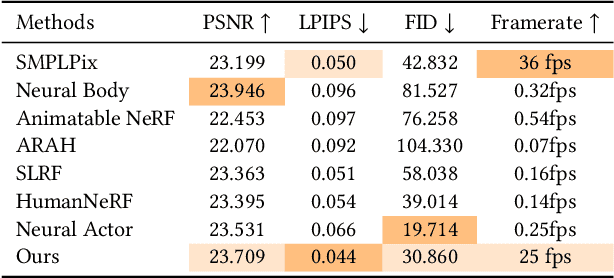
We present AvatarReX, a new method for learning NeRF-based full-body avatars from video data. The learnt avatar not only provides expressive control of the body, hands and the face together, but also supports real-time animation and rendering. To this end, we propose a compositional avatar representation, where the body, hands and the face are separately modeled in a way that the structural prior from parametric mesh templates is properly utilized without compromising representation flexibility. Furthermore, we disentangle the geometry and appearance for each part. With these technical designs, we propose a dedicated deferred rendering pipeline, which can be executed in real-time framerate to synthesize high-quality free-view images. The disentanglement of geometry and appearance also allows us to design a two-pass training strategy that combines volume rendering and surface rendering for network training. In this way, patch-level supervision can be applied to force the network to learn sharp appearance details on the basis of geometry estimation. Overall, our method enables automatic construction of expressive full-body avatars with real-time rendering capability, and can generate photo-realistic images with dynamic details for novel body motions and facial expressions.
Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis
Jul 24, 2022

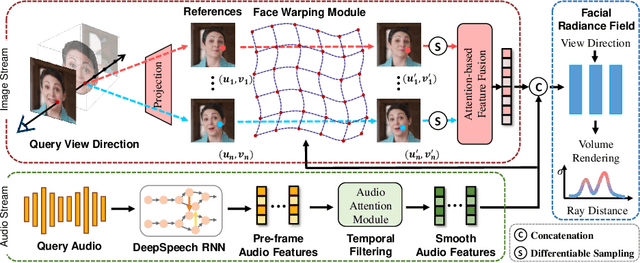
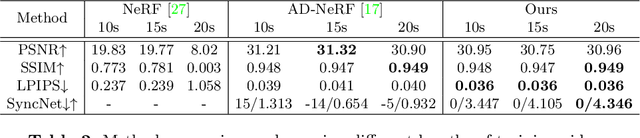
Talking head synthesis is an emerging technology with wide applications in film dubbing, virtual avatars and online education. Recent NeRF-based methods generate more natural talking videos, as they better capture the 3D structural information of faces. However, a specific model needs to be trained for each identity with a large dataset. In this paper, we propose Dynamic Facial Radiance Fields (DFRF) for few-shot talking head synthesis, which can rapidly generalize to an unseen identity with few training data. Different from the existing NeRF-based methods which directly encode the 3D geometry and appearance of a specific person into the network, our DFRF conditions face radiance field on 2D appearance images to learn the face prior. Thus the facial radiance field can be flexibly adjusted to the new identity with few reference images. Additionally, for better modeling of the facial deformations, we propose a differentiable face warping module conditioned on audio signals to deform all reference images to the query space. Extensive experiments show that with only tens of seconds of training clip available, our proposed DFRF can synthesize natural and high-quality audio-driven talking head videos for novel identities with only 40k iterations. We highly recommend readers view our supplementary video for intuitive comparisons. Code is available in https://sstzal.github.io/DFRF/.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023
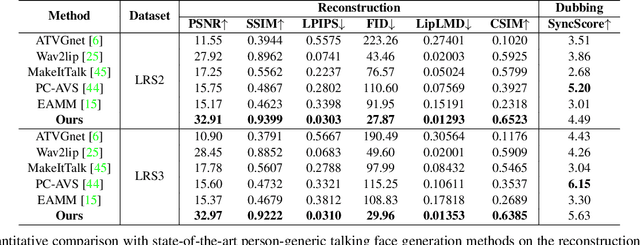
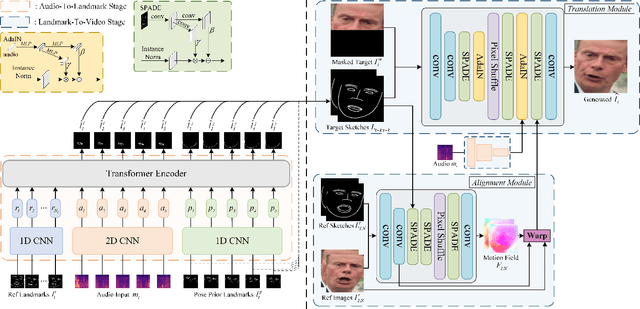
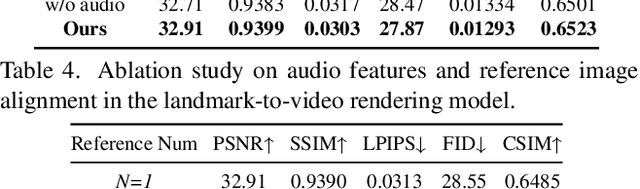
Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
NICOL: A Neuro-inspired Collaborative Semi-humanoid Robot that Bridges Social Interaction and Reliable Manipulation
May 15, 2023
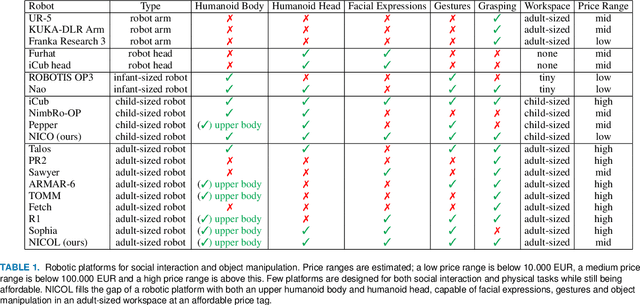

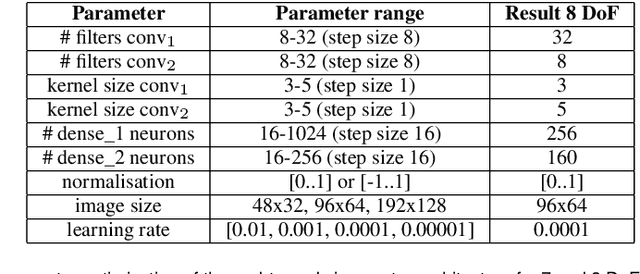
Robotic platforms that can efficiently collaborate with humans in physical tasks constitute a major goal in robotics. However, many existing robotic platforms are either designed for social interaction or industrial object manipulation tasks. The design of collaborative robots seldom emphasizes both their social interaction and physical collaboration abilities. To bridge this gap, we present the novel semi-humanoid NICOL, the Neuro-Inspired COLlaborator. NICOL is a large, newly designed, scaled-up version of its well-evaluated predecessor, the Neuro-Inspired COmpanion (NICO). While we adopt NICO's head and facial expression display, we extend its manipulation abilities in terms of precision, object size and workspace size. To introduce and evaluate NICOL, we first develop and extend different neural and hybrid neuro-genetic visuomotor approaches initially developed for the NICO to the larger NICOL and its more complex kinematics. Furthermore, we present a novel neuro-genetic approach that improves the grasp accuracy of the NICOL to over 99%, outperforming the state-of-the-art IK solvers KDL, TRACK-IK and BIO-IK. Furthermore, we introduce the social interaction capabilities of NICOL, including the auditory and visual capabilities, but also the face and emotion generation capabilities. Overall, this article presents for the first time the humanoid robot NICOL and, thereby, with the neuro-genetic approaches, contributes to the integration of social robotics and neural visuomotor learning for humanoid robots.
I2Edit: Towards Multi-turn Interactive Image Editing via Dialogue
Mar 20, 2023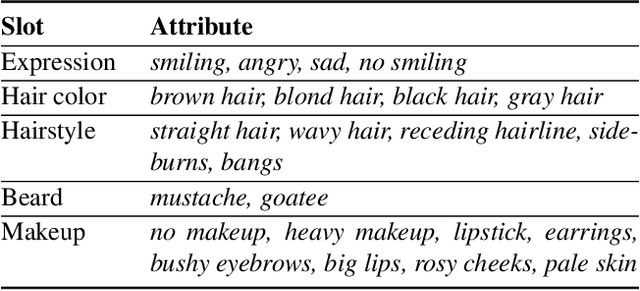

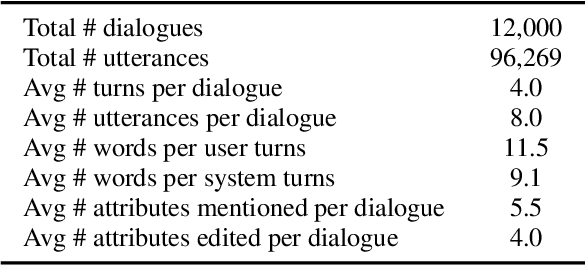
Although there have been considerable research efforts on controllable facial image editing, the desirable interactive setting where the users can interact with the system to adjust their requirements dynamically hasn't been well explored. This paper focuses on facial image editing via dialogue and introduces a new benchmark dataset, Multi-turn Interactive Image Editing (I2Edit), for evaluating image editing quality and interaction ability in real-world interactive facial editing scenarios. The dataset is constructed upon the CelebA-HQ dataset with images annotated with a multi-turn dialogue that corresponds to the user editing requirements. I2Edit is challenging, as it needs to 1) track the dynamically updated user requirements and edit the images accordingly, as well as 2) generate the appropriate natural language response to communicate with the user. To address these challenges, we propose a framework consisting of a dialogue module and an image editing module. The former is for user edit requirements tracking and generating the corresponding indicative responses, while the latter edits the images conditioned on the tracked user edit requirements. In contrast to previous works that simply treat multi-turn interaction as a sequence of single-turn interactions, we extract the user edit requirements from the whole dialogue history instead of the current single turn. The extracted global user edit requirements enable us to directly edit the input raw image to avoid error accumulation and attribute forgetting issues. Extensive quantitative and qualitative experiments on the I2Edit dataset demonstrate the advantage of our proposed framework over the previous single-turn methods. We believe our new dataset could serve as a valuable resource to push forward the exploration of real-world, complex interactive image editing. Code and data will be made public.
Adaptive Graph-Based Feature Normalization for Facial Expression Recognition
Jul 22, 2022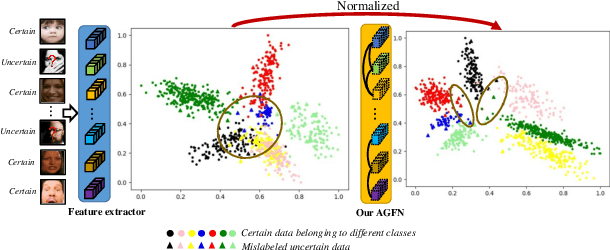
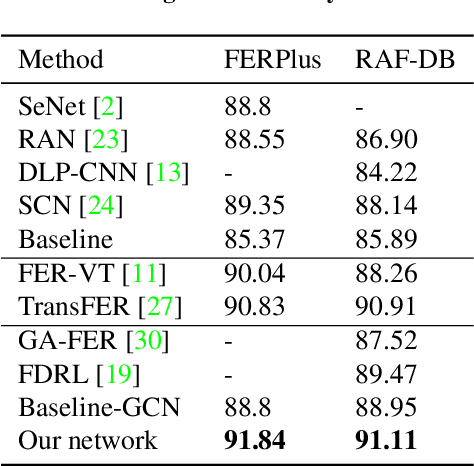
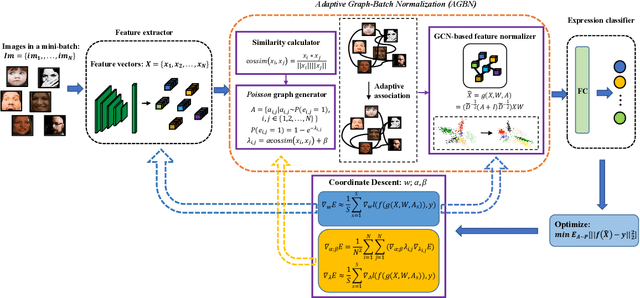
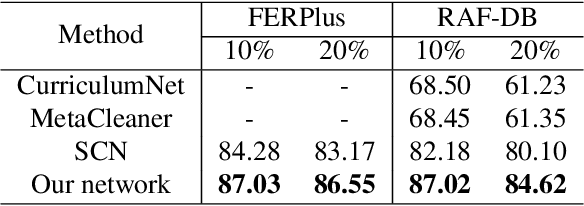
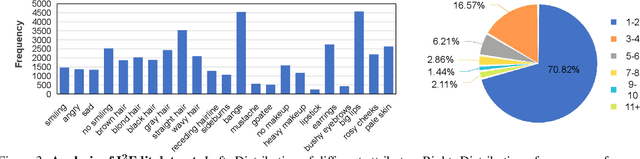
Facial Expression Recognition (FER) suffers from data uncertainties caused by ambiguous facial images and annotators' subjectiveness, resulting in excursive semantic and feature covariate shifting problem. Existing works usually correct mislabeled data by estimating noise distribution, or guide network training with knowledge learned from clean data, neglecting the associative relations of expressions. In this work, we propose an Adaptive Graph-based Feature Normalization (AGFN) method to protect FER models from data uncertainties by normalizing feature distributions with the association of expressions. Specifically, we propose a Poisson graph generator to adaptively construct topological graphs for samples in each mini-batches via a sampling process, and correspondingly design a coordinate descent strategy to optimize proposed network. Our method outperforms state-of-the-art works with accuracies of 91.84% and 91.11% on the benchmark datasets FERPlus and RAF-DB, respectively, and when the percentage of mislabeled data increases (e.g., to 20%), our network surpasses existing works significantly by 3.38% and 4.52%.