 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
DisCO: Portrait Distortion Correction with Perspective-Aware 3D GANs
Feb 23, 2023
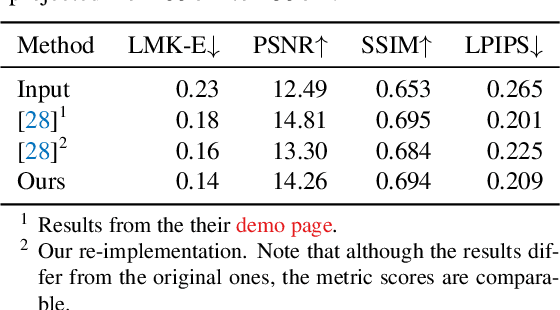

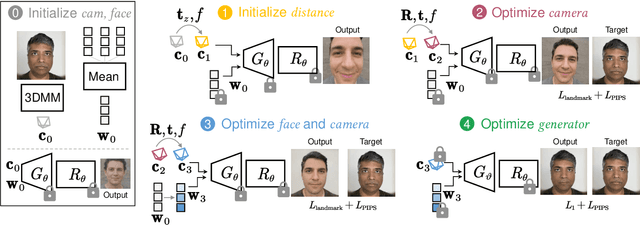
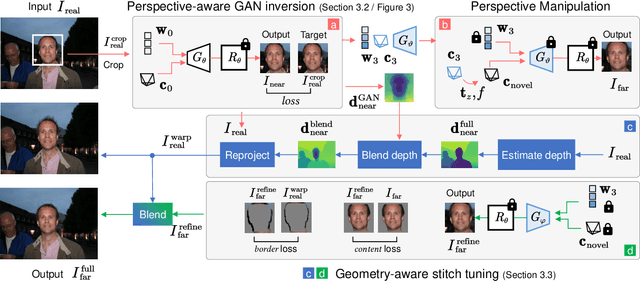
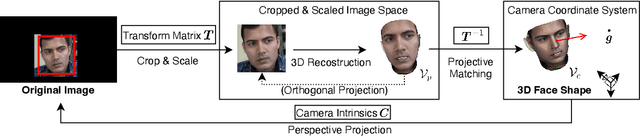
Close-up facial images captured at close distances often suffer from perspective distortion, resulting in exaggerated facial features and unnatural/unattractive appearances. We propose a simple yet effective method for correcting perspective distortions in a single close-up face. We first perform GAN inversion using a perspective-distorted input facial image by jointly optimizing the camera intrinsic/extrinsic parameters and face latent code. To address the ambiguity of joint optimization, we develop focal length reparametrization, optimization scheduling, and geometric regularization. Re-rendering the portrait at a proper focal length and camera distance effectively corrects these distortions and produces more natural-looking results. Our experiments show that our method compares favorably against previous approaches regarding visual quality. We showcase numerous examples validating the applicability of our method on portrait photos in the wild.
Self-adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images
Sep 21, 2022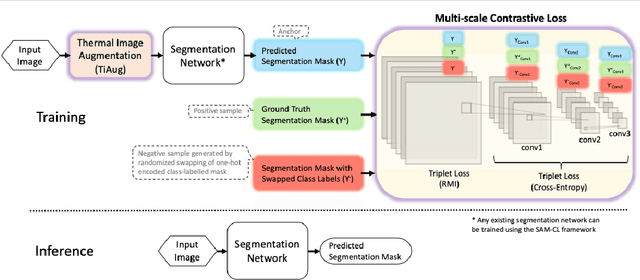
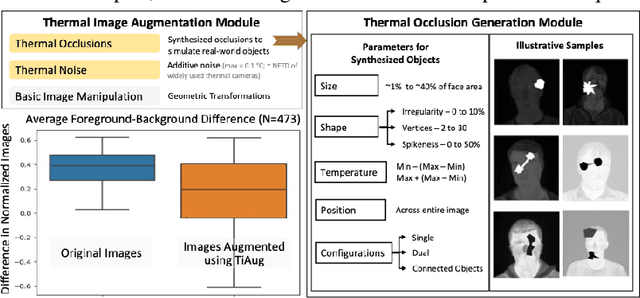
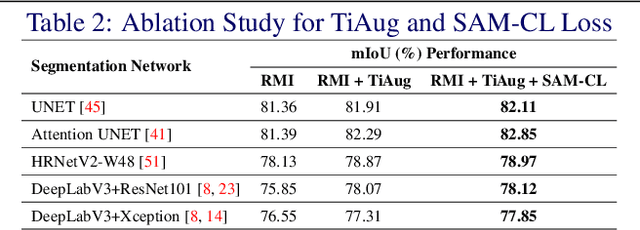
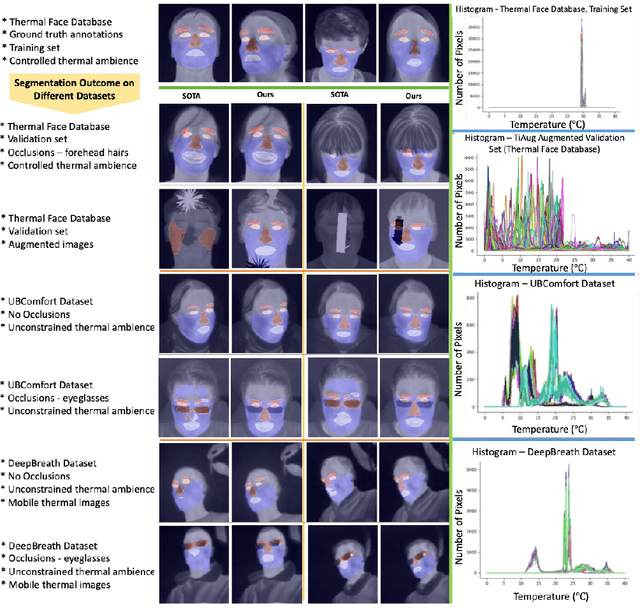
Reliable segmentation of thermal facial images in unconstrained settings such as thermal ambience and occlusions is challenging as facial features lack salience. Limited availability of datasets from such settings further makes it difficult to train segmentation networks. To address the challenge, we propose Self-Adversarial Multi-scale Contrastive Learning (SAM-CL) as a generic learning framework to train segmentation networks. SAM-CL framework constitutes SAM-CL loss function and a thermal image augmentation (TiAug) as a domain-specific augmentation technique to simulate unconstrained settings based upon existing datasets collected from controlled settings. We use the Thermal-Face-Database to demonstrate effectiveness of our approach. Experiments conducted on the existing segmentation networks- UNET, Attention-UNET, DeepLabV3 and HRNetv2 evidence the consistent performance gain from the SAM-CL framework. Further, we present a qualitative analysis with UBComfort and DeepBreath datasets to discuss how our proposed methods perform in handling unconstrained situations.
Super-Resolving Face Image by Facial Parsing Information
Apr 06, 2023



Face super-resolution is a technology that transforms a low-resolution face image into the corresponding high-resolution one. In this paper, we build a novel parsing map guided face super-resolution network which extracts the face prior (i.e., parsing map) directly from low-resolution face image for the following utilization. To exploit the extracted prior fully, a parsing map attention fusion block is carefully designed, which can not only effectively explore the information of parsing map, but also combines powerful attention mechanism. Moreover, in light of that high-resolution features contain more precise spatial information while low-resolution features provide strong contextual information, we hope to maintain and utilize these complementary information. To achieve this goal, we develop a multi-scale refine block to maintain spatial and contextual information and take advantage of multi-scale features to refine the feature representations. Experimental results demonstrate that our method outperforms the state-of-the-arts in terms of quantitative metrics and visual quality. The source codes will be available at https://github.com/wcy-cs/FishFSRNet.
Age-Invariant Face Embedding using the Wasserstein Distance
May 04, 2023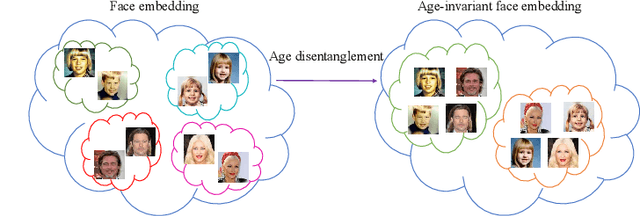
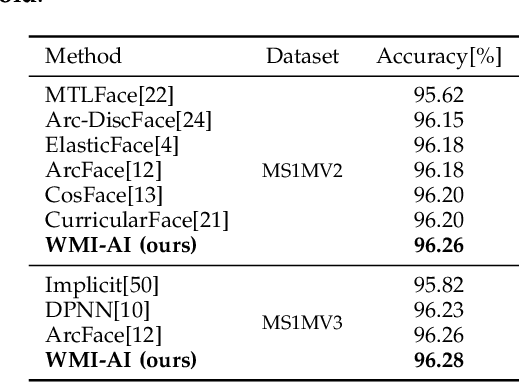

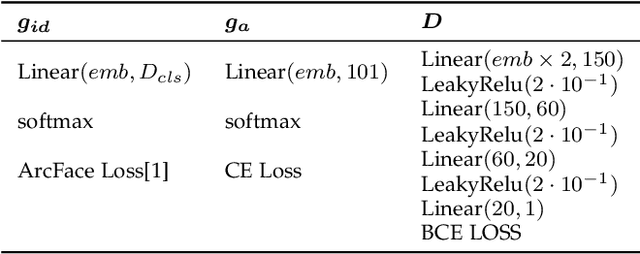
In this work, we study face verification in datasets where images of the same individuals exhibit significant age differences. This poses a major challenge for current face recognition and verification techniques. To address this issue, we propose a novel approach that utilizes multitask learning and a Wasserstein distance discriminator to disentangle age and identity embeddings of facial images. Our approach employs multitask learning with a Wasserstein distance discriminator that minimizes the mutual information between the age and identity embeddings by minimizing the Jensen-Shannon divergence. This improves the encoding of age and identity information in face images and enhances the performance of face verification in age-variant datasets. We evaluate the effectiveness of our approach using multiple age-variant face datasets and demonstrate its superiority over state-of-the-art methods in terms of face verification accuracy.
Enhanced Face Authentication With Separate Loss Functions
Feb 22, 2023The overall objective of the main project is to propose and develop a system of facial authentication in unlocking phones or applications in phones using facial recognition. The system will include four separate architectures: face detection, face recognition, face spoofing, and classification of closed eyes. In which, we consider the problem of face recognition to be the most important, determining the true identity of the person standing in front of the screen with absolute accuracy is what facial recognition systems need to achieve. Along with the development of the face recognition problem, the problem of the anti-fake face is also gradually becoming popular and equally important. Our goal is to propose and develop two loss functions: LMCot and Double Loss. Then apply them to the face authentication process.
CPNet: Exploiting CLIP-based Attention Condenser and Probability Map Guidance for High-fidelity Talking Face Generation
May 23, 2023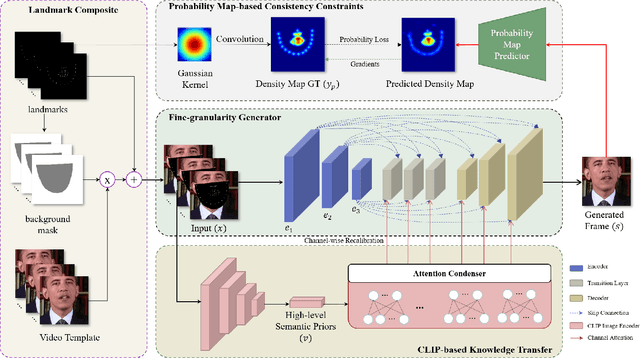

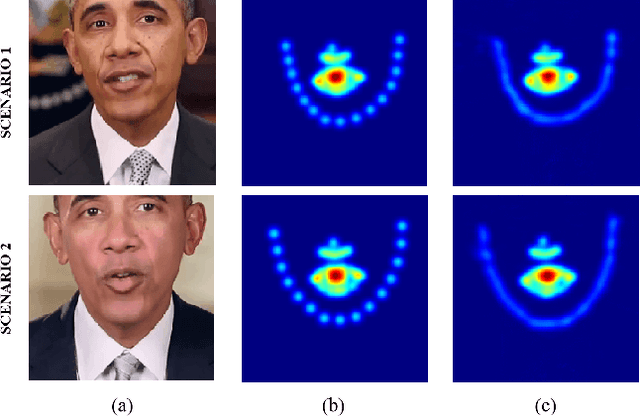
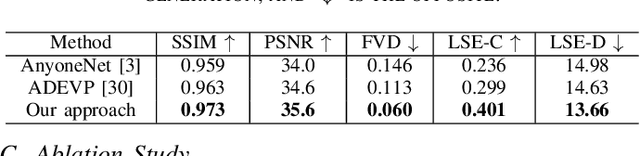
Recently, talking face generation has drawn ever-increasing attention from the research community in computer vision due to its arduous challenges and widespread application scenarios, e.g. movie animation and virtual anchor. Although persevering efforts have been undertaken to enhance the fidelity and lip-sync quality of generated talking face videos, there is still large room for further improvements of synthesis quality and efficiency. Actually, these attempts somewhat ignore the explorations of fine-granularity feature extraction/integration and the consistency between probability distributions of landmarks, thereby recurring the issues of local details blurring and degraded fidelity. To mitigate these dilemmas, in this paper, a novel CLIP-based Attention and Probability Map Guided Network (CPNet) is delicately designed for inferring high-fidelity talking face videos. Specifically, considering the demands of fine-grained feature recalibration, a clip-based attention condenser is exploited to transfer knowledge with rich semantic priors from the prevailing CLIP model. Moreover, to guarantee the consistency in probability space and suppress the landmark ambiguity, we creatively propose the density map of facial landmark as auxiliary supervisory signal to guide the landmark distribution learning of generated frame. Extensive experiments on the widely-used benchmark dataset demonstrate the superiority of our CPNet against state of the arts in terms of image and lip-sync quality. In addition, a cohort of studies are also conducted to ablate the impacts of the individual pivotal components.
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
May 25, 2023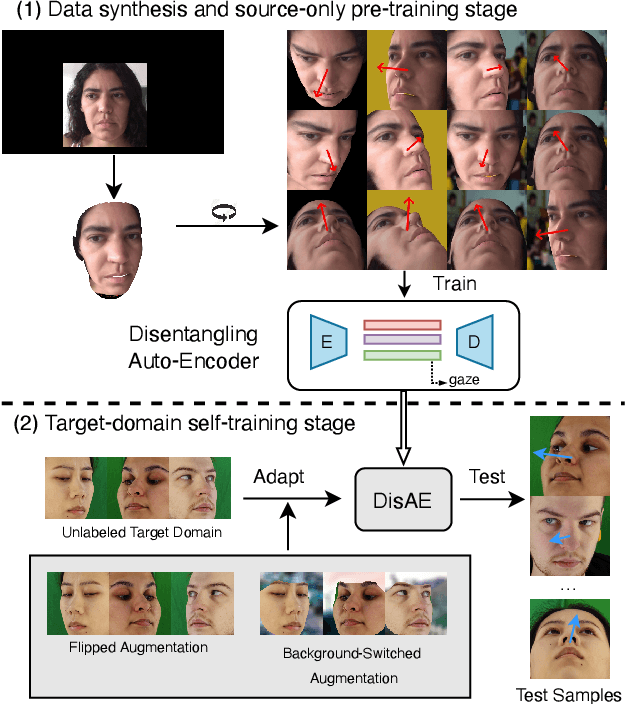
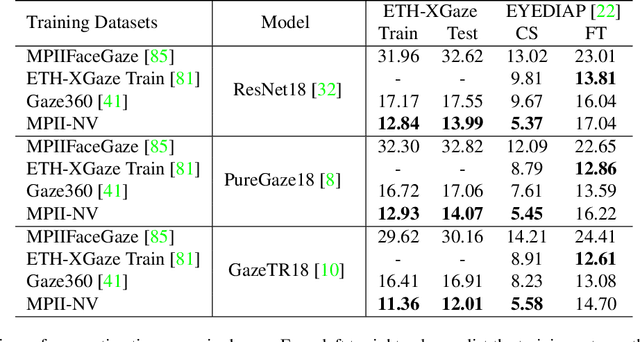
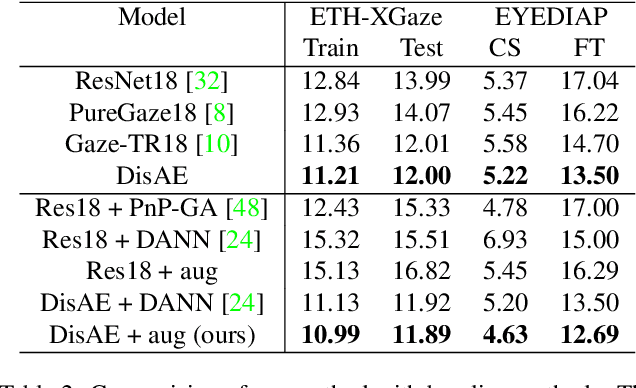
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play a significant role in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, we show that the model only using monocular-reconstructed synthetic training data can perform comparably to real data with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at \url{https://github.com/ut-vision/AdaptiveGaze}.
Hybrid Facial Expression Recognition (FER2013) Model for Real-Time Emotion Classification and Prediction
Jun 19, 2022

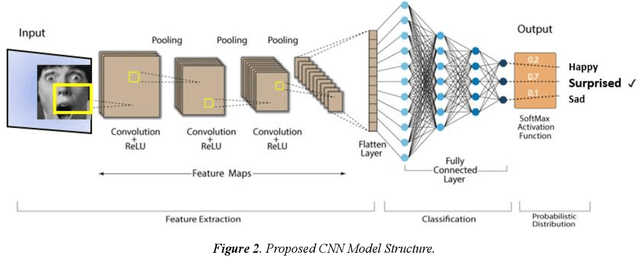

Facial Expression Recognition is a vital research topic in most fields ranging from artificial intelligence and gaming to Human-Computer Interaction (HCI) and Psychology. This paper proposes a hybrid model for Facial Expression recognition, which comprises a Deep Convolutional Neural Network (DCNN) and Haar Cascade deep learning architectures. The objective is to classify real-time and digital facial images into one of the seven facial emotion categories considered. The DCNN employed in this research has more convolutional layers, ReLU Activation functions, and multiple kernels to enhance filtering depth and facial feature extraction. In addition, a haar cascade model was also mutually used to detect facial features in real-time images and video frames. Grayscale images from the Kaggle repository (FER-2013) and then exploited Graphics Processing Unit (GPU) computation to expedite the training and validation process. Pre-processing and data augmentation techniques are applied to improve training efficiency and classification performance. The experimental results show a significantly improved classification performance compared to state-of-the-art (SoTA) experiments and research. Also, compared to other conventional models, this paper validates that the proposed architecture is superior in classification performance with an improvement of up to 6%, totaling up to 70% accuracy, and with less execution time of 2098.8s.
Exploring Phonetic Context in Lip Movement for Authentic Talking Face Generation
May 31, 2023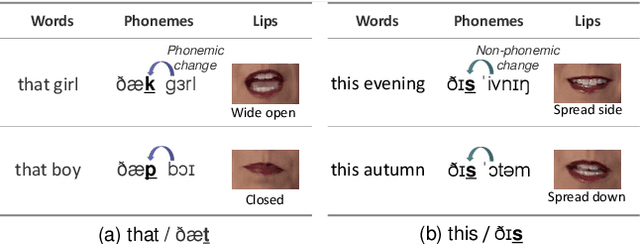
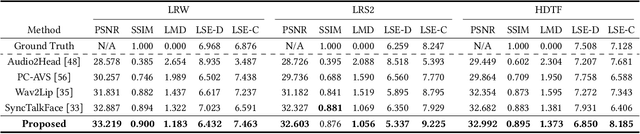
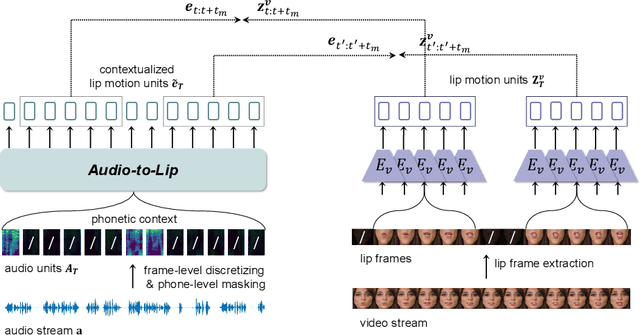
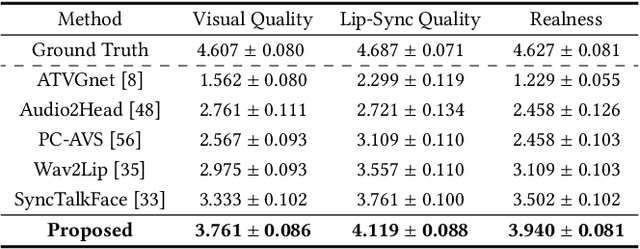
Talking face generation is the task of synthesizing a natural face synchronous to driving audio. Although much progress has been made in terms of visual quality, lip synchronization, and facial motion of the talking face, current works still struggle to overcome issues of crude and asynchronous lip movement, which can result in puppetry-like animation. We identify that the prior works commonly correlate lip movement with audio at the phone level. However, due to co-articulation, where an isolated phone is influenced by the preceding or following phones, the articulation of a phone varies upon the phonetic context. Therefore, modeling lip motion with the phonetic context can generate more spatio-temporally aligned and stable lip movement. In this respect, we investigate the phonetic context in lip motion for authentic talking face generation. We propose a Context-Aware Lip-Sync framework (CALS), which leverages phonetic context to generate more spatio-temporally aligned and stable lip movement. The CALS comprises an Audio-to-Lip module and a Lip-to-Face module. The former explicitly maps each phone to a contextualized lip motion unit, which guides the latter in synthesizing a target identity with context-aware lip motion. In addition, we introduce a discriminative sync critic that enforces accurate lip displacements within the phonetic context through audio-visual sync loss and visual discriminative sync loss. From extensive experiments on LRW, LRS2, and HDTF datasets, we demonstrate that the proposed CALS effectively enhances spatio-temporal alignment, greatly improving upon the state-of-the-art on visual quality, lip-sync quality, and realness. Finally, we show the authenticity of the generated video through a lip readability test and achieve 97.7% of relative word prediction accuracy to real videos.
Learning Facial Liveness Representation for Domain Generalized Face Anti-spoofing
Aug 16, 2022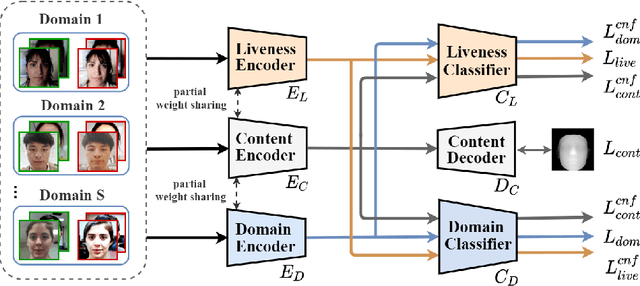
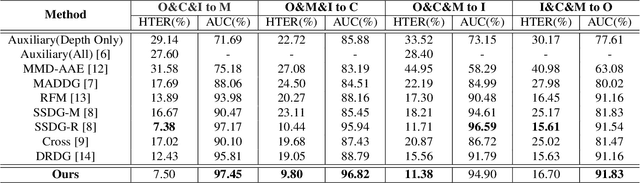
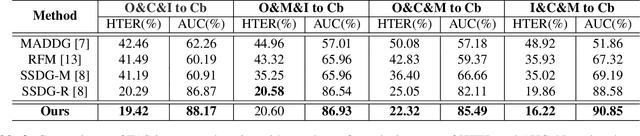
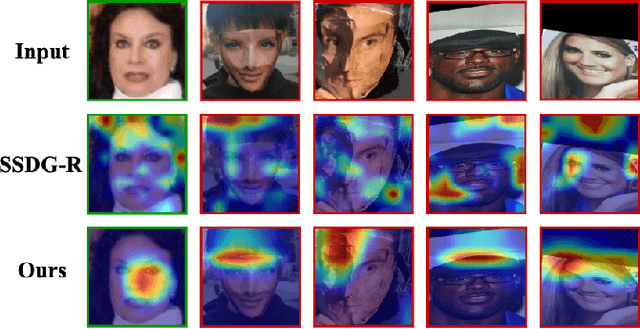
Face anti-spoofing (FAS) aims at distinguishing face spoof attacks from the authentic ones, which is typically approached by learning proper models for performing the associated classification task. In practice, one would expect such models to be generalized to FAS in different image domains. Moreover, it is not practical to assume that the type of spoof attacks would be known in advance. In this paper, we propose a deep learning model for addressing the aforementioned domain-generalized face anti-spoofing task. In particular, our proposed network is able to disentangle facial liveness representation from the irrelevant ones (i.e., facial content and image domain features). The resulting liveness representation exhibits sufficient domain invariant properties, and thus it can be applied for performing domain-generalized FAS. In our experiments, we conduct experiments on five benchmark datasets with various settings, and we verify that our model performs favorably against state-of-the-art approaches in identifying novel types of spoof attacks in unseen image domains.